【数据库】为何“端边云”协同架构正在重塑大数据存储格局?
文章目录
01 引言:时序数据爆发下的架构之变
我们正处在一个由“万物互联”向“万物智联”转型的临界点。
根据 IDC 预测,到 2025 年,全球物联网设备产生的数据量将接近 80 ZB,其中超过 60% 是具有时间戳的时序数据。在传统的互联网大数据架构中,关系型数据库和 NoSQL 数据库曾长期占据主导地位。然而,在工业 4.0 的冲击下,这些通用数据库开始显露出“水土不服”的症状:当面临千万级并发写入、极高的数据压缩比需求以及复杂的时空维度分析时,传统架构往往伴随着高昂的存储成本和缓慢的查询响应。
在这片技术蓝海中,时序数据库应运而生。但面对市面上琳琅满目的时序数据库——无论是国外的老牌劲旅,还是国产的后起之秀——企业技术决策者往往陷入“选择困难症”。
本文将从大数据架构视角出发,深度剖析时序数据库选型的关键技术指标,并以 Apache IoTDB(及其 TimechoDB) 为例,阐述为何“端-边-云”协同、存算一体以及“时序大模型”的深度融合,正在成为下一代时序数据基础设施的标准范式。

02 选型维度:评估时序数据库的五个黄金指标
在技术选型评审会上,我们常常听到“这个数据库性能不错”这种模糊的评价。在工业场景中,稳定性、成本、效率是三位一体的硬性指标。基于大规模集群的运维经验,我们建议从以下五个维度建立量化评估模型:
| 评估维度 | 核心指标 | 工业场景痛点 |
|---|---|---|
| 写入吞吐能力 | 每秒写入数据点(Points/sec) | 高峰期千万级设备同时上报,普通数据库易发生写入阻塞 |
| 存储成本 | 压缩比(Compression Ratio) | 磁盘 I/O 受限,海量历史数据的长期保存成本呈指数级增长 |
| 查询延迟 | 亿级数据聚合查询响应时间(ms) | 在庞大规模数据中提取趋势,秒级以上的延迟无法满足实时监控需求 |
| 数据模型灵活性 | 树形模型 vs. 标签模型 | 工业设备层级复杂(工厂-产线-设备-测点),扁平化模型难以管理 |
| 智能分析能力 | 内置 AI 与数据处理(ETL) | 单纯存数据无法创造价值,需要库内计算与边缘协同 |
03 架构对决:通用时序数据库 vs. “端边云”原生设计
当前国际市场上的主流时序数据库(如 InfluxDB、TimescaleDB 等)多诞生于 DevOps 监控场景。它们的架构设计基于一个隐含假设:数据中心网络是稳定的,计算资源是无限的。
然而,工业物联网的现实是残酷的:
- 网络不稳:尤其在石油、矿山、交通等场景,断网是常态。
- 资源受限:边缘网关仅有 512MB 内存,无法运行厚重的数据库进程。
- 数据质量差:乱序、重复、延迟数据频繁出现。
这就引出了选型的核心分水岭:数据库是否具备“端-边-云”原生协同能力?
以 Apache IoTDB 为例,其设计哲学从一开始就瞄准了工业属性。它通过 “一等公民”的树状模型,完美映射了工业设备的层级路径(如 root.工厂1.产线A.设备B.温度)。相比于 InfluxDB 的 tags 扁平化结构,这种模型在进行跨维度聚合(如“查询所有位于华北地区的风机平均风速”)时,避免了大量的字符串标签索引开销,查询性能显著提升。
而在边缘侧,IoTDB 的轻量化版本(Edge Edition)体积极小,支持断网续传。当网络恢复时,边缘节点自动将经过压缩的 TsFile 文件同步至云端,这种架构不仅解决了弱网问题,还通过“计算下沉”在边缘侧完成了数据预处理,云端的存储压力随之减轻。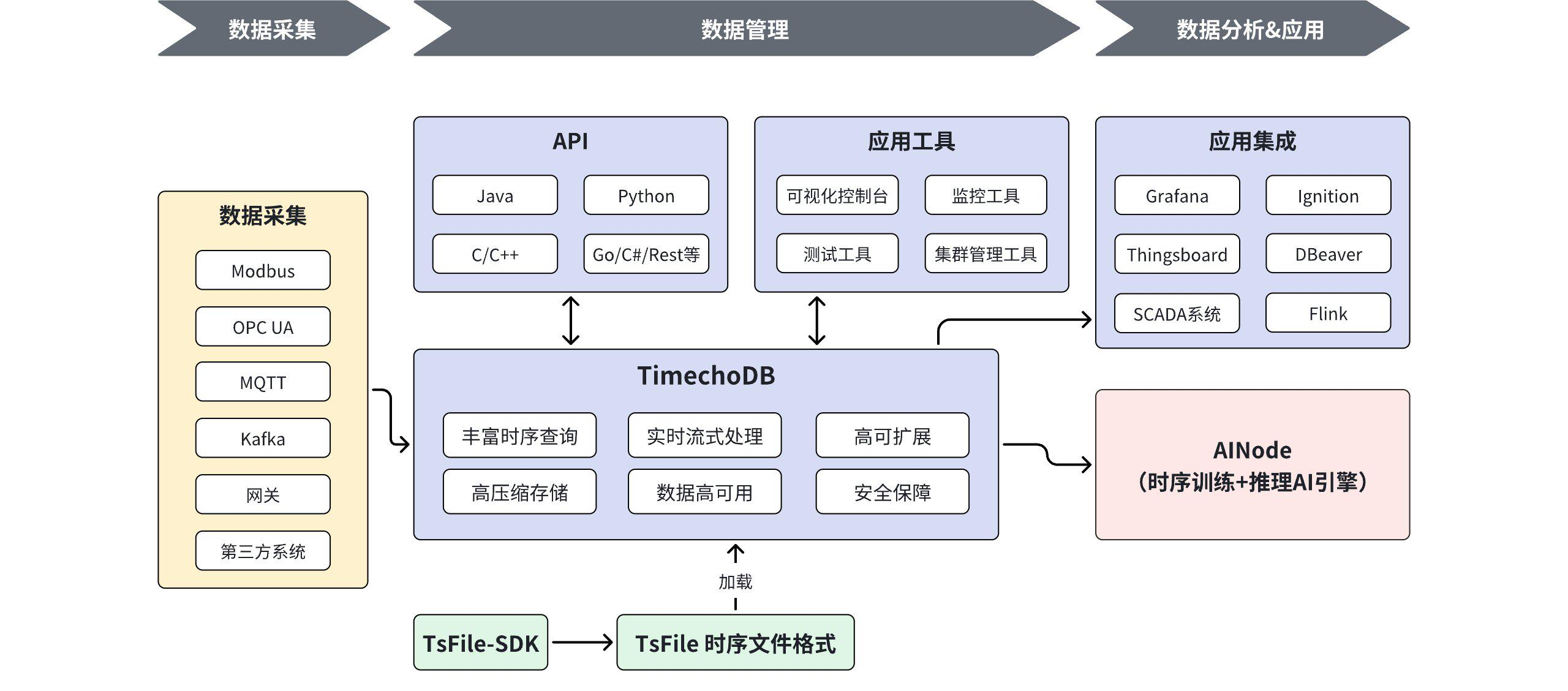
04 存储革命:TsFile —— 时序数据的“超级压缩器”
在选型时,很多团队只关注数据库的写入速度,却忽略了存储成本。一旦数据保留策略设为“永久”,硬盘很快就会被写满,云端的对象存储费用也会显著增加。
产品体系的核心技术底座是 Apache TsFile。这是一种专为时序数据设计的列式存储文件格式。它不仅仅是 IoTDB 的底层文件,更是贯穿“采-存-用”全生命周期的数据标准。
其高效性体现在 “编码 + 压缩” 的二阶魔法上:
- 编码:针对时间戳和整数/浮点数使用二阶差分编码或游程编码,不存储原始数值,而是存储“差值的变化量”,极大地减少了 bit 位占用。
- 压缩:在编码基础上,进一步使用压缩算法进行打包。
在真实的某新能源车企案例中,采用通用数据库存储驾驶日志需要 20TB 的空间,而在 IoTDB 中仅用了不到 1TB(压缩比超过 20:1)。
这种极致的压缩率,直接降低了企业的硬件采购成本和电力消耗,符合绿色计算的时代趋势。
05 智能跃迁:从“数据管理”到“智能决策”
数据库选型的终点不是“存下来”,而是“用得好”。传统的时序数据库分析能力仅限于 SQL 聚合(求均值、最大值等),这属于描述性统计,无法回答“未来会发生什么”的问题。
随着大模型技术的爆发,时序数据库正在与 AI 深度融合。天谋提出的时序大模型(Timer 系列) 正在打破这一壁垒。
传统的时序预测需要繁琐的数据清洗、特征工程和模型调参。而在新一代的 TimechoDB + AINode 架构中,时序大模型成为了数据库的内置能力。
应用场景示例:
在化工生产场景中,某企业利用 TimechoDB 内置的时序大模型实现了预测性维护。
- 传统方案:运维人员设定静态阈值,当传感器温度超过 90 度报警。这种方案误报率高,且无法发现缓慢的劣化趋势。
- IoTDB + AI 方案:系统利用 Timer-XL 模型,基于过去 7 天的工况数据进行训练,能够提前 30 分钟预测出温度异常偏离正常模式,精度提升了 40%。
实际操作: 这种 AI 能力的调用不再需要复杂的 Python 环境,而是通过 SQL 语句直接完成。
-- 调用内置时序大模型预测未来一小时的风速
SELECT forecast(root.wn.01.wind_speed, horizon=3600) FROM root.wn.01
06 实战与生态:SQL 接口与开箱即用的工具链
再先进的底层技术,如果使用门槛高,也难以推广。在 2024 年的今天,时序数据库的竞争也是 SQL 兼容性的竞争。
IoTDB 的 SQL 覆盖率非常全面。对于习惯使用关系型数据库的团队来说,学习成本极低。例如,创建时间序列、写入数据和查询数据的语法极其自然:
-- 1. 创建时间序列(自动推断数据类型)
CREATE TIMESERIES root.sg1.d1.s1 WITH DATATYPE=INT64;
-- 2. 高效写入数据(支持 Aligned 序列对齐,解决不同测点时间戳不一致问题)
insert into root.sg1.d1(timestamp, s1, s2, s3) aligned values(1, 1, 2, 3);
-- 3. 复杂查询:滑动窗口计算,每隔1小时计算过去1小时的平均值,滑动步长30分钟
SELECT AVG(s1) FROM root.sg1.d1
GROUP BY TIME(1h, 30m);
此外,在生态对接方面,TimechoDB 提供了标准 JDBC 驱动,可无缝对接 Grafana 进行可视化,支持 Hadoop/Spark 进行大规模离线分析,甚至可以通过 MQTT Broker 直接写入数据。
笔者曾参与过某智能工厂的 MES 系统改造。该工厂原先的数据链路是:设备 -> Kafka -> Flink -> HBase。链路冗长,运维复杂。改造后采用 IoTDB,利用其内置的采集能力,架构简化为:设备 -> IoTDB (Edge) -> IoTDB (Cloud)。研发效率提升 50%,硬件成本下降 70%。
07 总结与选型建议
时序数据库的选型,本质上是业务场景与技术架构的适配。
如果你只是在搭建个人的监控系统(如 Zabbix 替换),追求简单的安装体验,那么一些开源通用的时序 DB 或许足够。但如果你是工业制造、轨道交通、能源电力领域的企业,面临的是海量设备接入、复杂网络环境、长期低成本存储以及未来的智能化决策需求,那么 Apache IoTDB / TimechoDB 架构具备显著优势:
- 极致压缩:有效控制存储 TCO。
- 树状模型:天然适配工业设备资产模型。
- 边云一体:解决数据孤岛与网络延迟问题。
- 内生智能:拥抱时序大模型,让“预测”成为 SQL 的一部分。
官网:https://timecho.com
下载:https://iotdb.apache.org/zh/Download/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)