第七届全球校园人工智能算法精英大赛-算法巅峰赛产业命题赛第3赛季优化题--多策略混合算法
·
前言
全球校园人工智能算法精英大赛”是江苏省人工智能学会举办的面向全球具有正式学籍的全日制高等院校及以上在校学生举办的算法竞赛。其中的算法巅峰赛属于产业命题赛道,这是第3赛季,这次优化题的主题是 “碳中和”。

回顾
第七届全球校园人工智能算法精英大赛-算法巅峰赛产业命题赛第3赛季优化题–碳中和
对该文提到的 多策略模型,提供具体的代码及解读。
思路解析
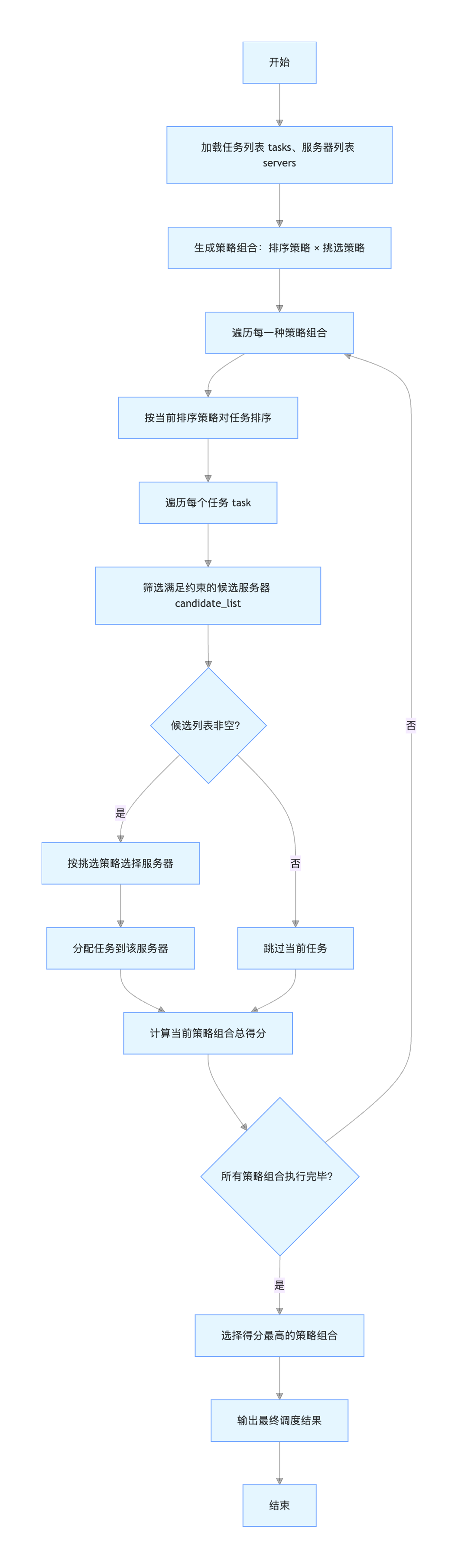
本算法保留经典贪心调度主框架,并对核心逻辑进行策略抽象与解耦,整体架构仅包含两类可插拔策略:
- sort_strategy:任务排序策略
- choice_strategy:服务器挑选策略
算法主流程
- 依据指定的 sort_strategy 对任务列表进行全局排序;
- 按序遍历每一个任务:
遍历所有服务器,筛选出分配后仍满足约束的候选服务器列表;
若候选列表非空,则通过 choice_strategy 从中选定目标服务器;
将当前任务分配至选定的服务器执行。
任务排序策略(sort_strategy)
- 按收益值降序排序
- 按收益 / 功耗比值降序排序
- 按收益 / 热度比值降序排序
- 按收益 /(功耗 + 热度) 比值降序排序
- 按热度值升序排序
服务器挑选策略(choice_strategy)
- FF(First-Fit):选择第一个满足约束的服务器
- BF(Best-Fit):按资源利用率来排序挑选服务器
- RF(Random-Fit):从候选集中随机选择一台服务器
- 带概率放弃的BF(Best-Fit):为最优挑选,引入随机概率放弃
多策略混合搜索机制
将N 种任务排序策略与M 种服务器挑选策略进行全组合遍历,形成 N×M 组调度方案。每组方案独立执行调度并计算得分,最终选取总收益最高的方案作为最优解。
设计特点
- 全程以任务(task)主导分配,结构清晰、易于实现与扩展;
- 策略完全解耦,新增排序 / 挑选规则无需修改主框架;
- 组合搜索自动挖掘最优策略搭配,大幅提升调度收益。
代码
多策略组合(代码由 Deepseek 生成)
#include <bits/stdc++.h>
using namespace std;
struct Task {
double gain, power, heat;
};
struct Server {
double power_limit, heat_limit;
};
// ====================== 你原题的热约束(完全不动)======================
class HeatChecker {
private:
const vector<Server>& servers;
double k;
int m;
public:
HeatChecker(const vector<Server>& servers, double k)
: servers(servers), k(k), m(servers.size()) {}
bool canPlace(const vector<double>& powers, const vector<double>& heats,
int pos, const Task& task) const {
if (task.power + powers[pos] > servers[pos].power_limit + 1e-9)
return false;
double self_heat = heats[pos] + task.heat;
double lh = (pos > 0) ? heats[pos - 1] * k : 0.0;
double rh = (pos < m - 1) ? heats[pos + 1] * k : 0.0;
if (self_heat + lh + rh > servers[pos].heat_limit + 1e-9)
return false;
if (pos > 0) {
double left_self = heats[pos - 1];
double left_influence = left_self + (heats[pos] + task.heat) * k;
if (pos - 1 > 0)
left_influence += heats[pos - 2] * k;
if (left_influence > servers[pos - 1].heat_limit + 1e-9)
return false;
}
if (pos < m - 1) {
double right_self = heats[pos + 1];
double right_influence = right_self + (heats[pos] + task.heat) * k;
if (pos + 1 < m - 1)
right_influence += heats[pos + 2] * k;
if (right_influence > servers[pos + 1].heat_limit + 1e-9)
return false;
}
return true;
}
};
// ====================== 策略模式:排序策略 ======================
class SortStrategy {
public:
virtual vector<int> sortTasks(const vector<Task>& tasks) const = 0;
virtual ~SortStrategy() = default;
};
class SortByGainDesc : public SortStrategy {
public:
vector<int> sortTasks(const vector<Task>& tasks) const override {
vector<int> order(tasks.size());
iota(order.begin(), order.end(), 0);
sort(order.begin(), order.end(), [&](int a, int b) {
return tasks[a].gain > tasks[b].gain;
});
return order;
}
};
class SortByGainPowerRatio : public SortStrategy {
public:
vector<int> sortTasks(const vector<Task>& tasks) const override {
vector<int> order(tasks.size());
iota(order.begin(), order.end(), 0);
sort(order.begin(), order.end(), [&](int a, int b) {
return tasks[a].gain / tasks[a].power > tasks[b].gain / tasks[b].power;
});
return order;
}
};
class SortByGainHeatRatio : public SortStrategy {
public:
vector<int> sortTasks(const vector<Task>& tasks) const override {
vector<int> order(tasks.size());
iota(order.begin(), order.end(), 0);
sort(order.begin(), order.end(), [&](int a, int b) {
return tasks[a].gain / tasks[a].heat > tasks[b].gain / tasks[b].heat;
});
return order;
}
};
class SortByGainTotalRatio : public SortStrategy {
public:
vector<int> sortTasks(const vector<Task>& tasks) const override {
vector<int> order(tasks.size());
iota(order.begin(), order.end(), 0);
sort(order.begin(), order.end(), [&](int a, int b) {
double ra = tasks[a].gain / (tasks[a].power + tasks[a].heat);
double rb = tasks[b].gain / (tasks[b].power + tasks[b].heat);
return ra > rb;
});
return order;
}
};
class SortByHeatAsc : public SortStrategy {
public:
vector<int> sortTasks(const vector<Task>& tasks) const override {
vector<int> order(tasks.size());
iota(order.begin(), order.end(), 0);
sort(order.begin(), order.end(), [&](int a, int b) {
return tasks[a].heat < tasks[b].heat;
});
return order;
}
};
// ====================== 策略模式:挑选策略 ======================
class ChoiceStrategy {
public:
virtual int select(const vector<int>& candidates,
const vector<double>& cur_p, const vector<double>& cur_h,
const vector<Server>& servers, double k,
const Task& task) const = 0;
virtual ~ChoiceStrategy() = default;
};
// FF 首次适应
class FirstFit : public ChoiceStrategy {
public:
int select(const vector<int>& candidates,
const vector<double>&, const vector<double>&,
const vector<Server>&, double,
const Task&) const override {
return candidates.empty() ? -1 : candidates[0];
}
};
// ====================== 【你专属的最优适应】完全用你的公式 ======================
class BestFit : public ChoiceStrategy {
public:
int select(const vector<int>& candidates,
const vector<double>& powers, const vector<double>& heats,
const vector<Server>& servers, double k,
const Task& task) const override {
if (candidates.empty()) return -1;
int best_pos = -1;
double min_score = 1e18;
for (int pos : candidates) {
double power_ratio = (powers[pos] + task.power) / servers[pos].power_limit;
double heat_ratio = (heats[pos] + task.heat) / servers[pos].heat_limit;
double heat_spread = heats[pos] + task.heat;
if (pos > 0) heat_spread += heats[pos - 1] * k;
if (pos < (int)servers.size() - 1) heat_spread += heats[pos + 1] * k;
double heat_ratio_with_spread = heat_spread / servers[pos].heat_limit;
double score = max(power_ratio, heat_ratio_with_spread);
double remaining = min(
servers[pos].power_limit - powers[pos] - task.power,
servers[pos].heat_limit - heats[pos] - task.heat
);
score -= remaining / (servers[pos].power_limit + servers[pos].heat_limit) * 0.1;
// 分数越小越好
if (score < min_score) {
min_score = score;
best_pos = pos;
}
}
return best_pos;
}
};
// ====================== 调度器 ======================
pair<double, vector<int>> schedule(
const vector<Task>& tasks,
const vector<Server>& servers,
double k,
const SortStrategy& sort_strategy,
const ChoiceStrategy& choice_strategy)
{
int n = tasks.size();
int m = servers.size();
vector<int> order = sort_strategy.sortTasks(tasks);
HeatChecker checker(servers, k);
vector<int> ans(n, -1);
vector<double> cur_p(m, 0), cur_h(m, 0);
double total_gain = 0;
for (int id : order) {
const Task& t = tasks[id];
vector<int> candidates;
for (int j = 0; j < m; j++) {
if (checker.canPlace(cur_p, cur_h, j, t)) {
candidates.push_back(j);
}
}
int s = choice_strategy.select(candidates, cur_p, cur_h, servers, k, t);
if (s != -1) {
ans[id] = s;
cur_p[s] += t.power;
cur_h[s] += t.heat;
total_gain += t.gain;
}
}
return {total_gain, ans};
}
// ====================== 主函数:策略组合遍历 + 最优选择 ======================
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
int n, m;
double k;
cin >> n >> m >> k;
vector<Task> tasks(n);
for (int i = 0; i < n; i++) {
cin >> tasks[i].gain >> tasks[i].power >> tasks[i].heat;
}
vector<Server> servers(m);
for (int i = 0; i < m; i++) {
cin >> servers[i].power_limit >> servers[i].heat_limit;
}
vector<unique_ptr<SortStrategy>> sorts;
sorts.emplace_back(new SortByGainDesc());
sorts.emplace_back(new SortByGainPowerRatio());
sorts.emplace_back(new SortByGainHeatRatio());
sorts.emplace_back(new SortByGainTotalRatio());
sorts.emplace_back(new SortByHeatAsc());
vector<unique_ptr<ChoiceStrategy>> choices;
choices.emplace_back(new FirstFit());
choices.emplace_back(new BestFit());
double best_gain = -1;
vector<int> best_ans(n, -1);
for (auto& s : sorts) {
for (auto& c : choices) {
auto [gain, ans] = schedule(tasks, servers, k, *s, *c);
if (gain > best_gain) {
best_gain = gain;
best_ans = ans;
}
}
}
for (int i = 0; i < n; i++) {
cout << best_ans[i] + 1 << " \n"[i == n-1];
}
return 0;
}
效果评估
在基准测试集中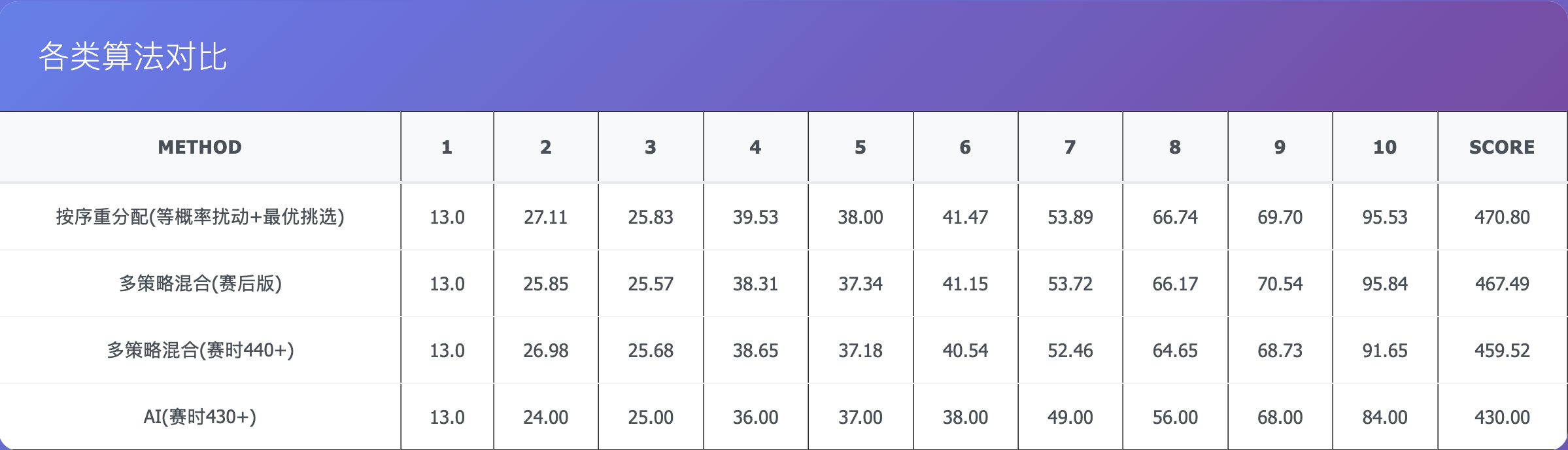
这个分值,接近赛时第一的分数,我猜测他可能用了类似解法。
这个算法中,贡献最大的是
- 按 收益/热度 比值 降序排序
- 采用 最优挑选策略,选择服务器
写在最后


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)