One API Docker 部署实战:从 0 搭建多模型统一接口管理平台
想把多个大模型服务统一收口,用一个接口地址对外提供能力,自己从零写网关、鉴权、额度和后台,工作量往往比预想的大很多。
One API 这类项目的意义,就在于先把“统一接入、令牌管理、渠道转发、配额控制”这一层搭起来。先跑通,再优化,这比一开始就铺太大摊子更务实。
一、项目背景
官方GitHub的项目地址:
https://github.com/songquanpeng/one-api
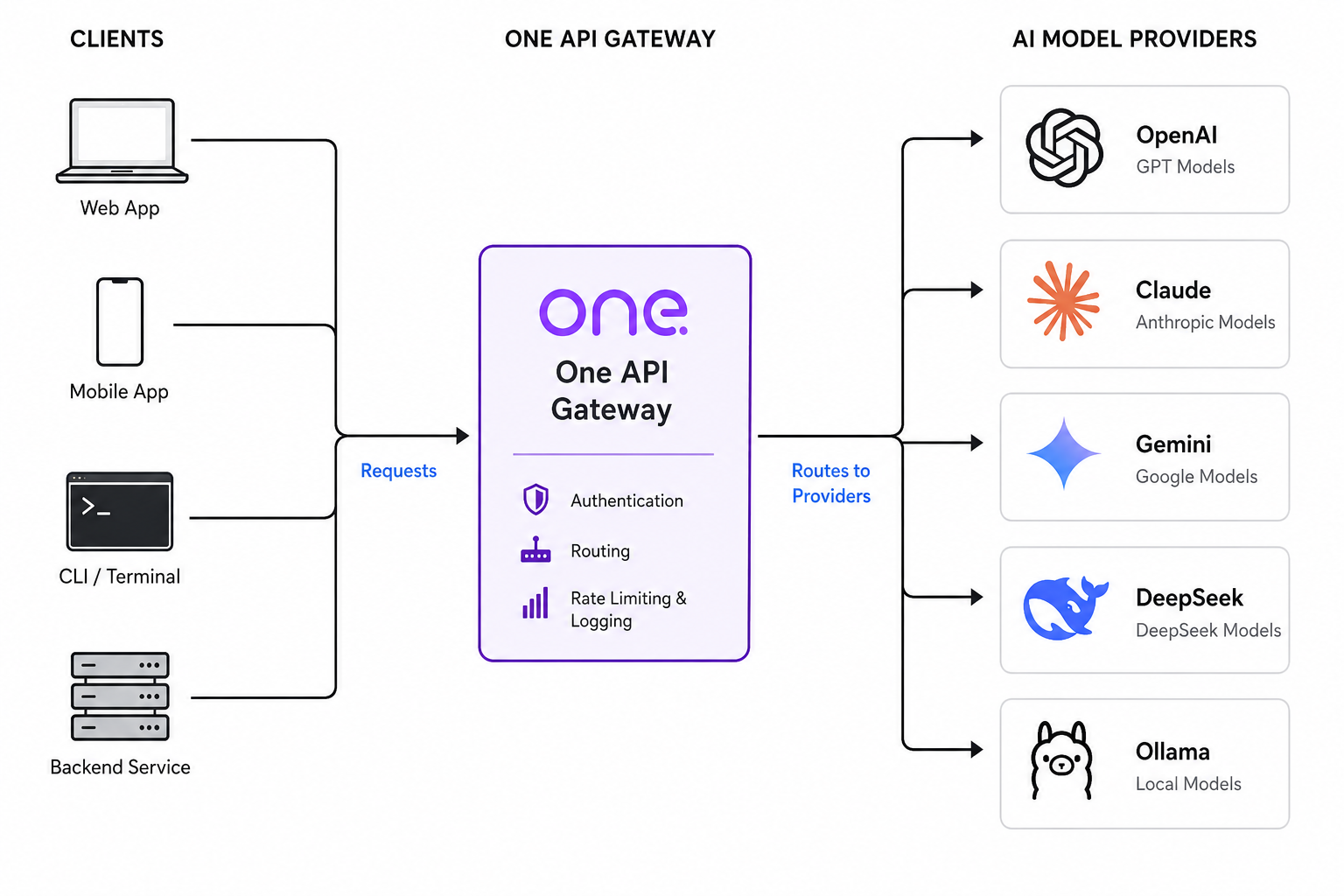
One API 是一个面向大模型接口统一接入与管理的开源项目,可以把不同来源的模型服务封装成一个兼容 OpenAI 风格的 API 入口。对于开发者来说,它最实用的地方不只是“能转发请求”,而是顺手把下面这些能力也整合到了一起:
- 上游渠道接入
- API 令牌管理
- 配额与额度控制
- 分组和模型权限管理
- 后台管理面板
如果你现在有下面这些需求,One API 基本都值得试一下:
- 想统一接入多个模型供应商
- 想给不同项目、不同成员分发独立 token
- 想做一个内部可控的 AI API 网关
- 想搭一个简单的 token 分发或接口中转平台
它之所以适合写成安装部署教程,原因很直接:
- 部署路径清晰:Docker 方式上手成本低
- 结果可验证:启动后能直接登录后台、建渠道、发 token、测接口
- 教程闭环完整:环境准备 → 安装部署 → 最小调用 → 验证结果 → 常见报错
不过也要提前说清楚:
One API 很适合做统一入口和管理层,但如果你准备拿它直接做公网商用系统,后续还需要自己补安全、日志、监控、限流、HTTPS、备份等工程化能力。开源项目能省很多轮子,但不会自动变成生产级全家桶。
二、本文环境说明
这篇文章采用的是优先跑通、门槛尽量低的部署路径,先把服务搭起来,再逐步完善配置。
环境信息
- 操作系统:Ubuntu 22.04 LTS
- 部署方式:Docker 单容器部署
- 数据库方案:SQLite
- 容器镜像:
justsong/one-api - 备用镜像:
ghcr.io/songquanpeng/one-api - 服务端口:3000
- 时区:Asia/Shanghai
为什么先用 SQLite
因为本文的目标不是一上来就搞复杂架构,而是先完成最小可运行闭环。
SQLite 的优势很明显:
- 不需要额外安装 MySQL
- 启动链路更短
- 更适合个人测试和教程演示
但也要明确它的边界:
- 个人测试、轻量使用:SQLite 没问题
- 多人协作、长期运行、较高并发:建议切换到 MySQL
硬件建议
- CPU:1 核以上
- 内存:2GB 起步
- 磁盘:10GB 以上
前置条件
建议你已经准备好:
- 一台 Ubuntu 服务器或本地 Linux 环境
- 可正常使用的 Docker
- 至少一个可用的上游模型 API Key
比如:
- OpenAI
- Claude
- Gemini
- DeepSeek
- 兼容 OpenAI 协议的第三方服务
- 本地 Ollama 服务
如果暂时没有上游 Key,也能把页面先跑起来,但接口调用这一步是测不通的。页面能开,只能说明服务活着,不代表业务链路已经通了。
三、安装前准备
1. 检查 Docker 是否可用
先确认系统中已经安装 Docker:
docker -v
如果没有安装,可以执行:
sudo apt update
sudo apt install -y docker.io
sudo systemctl enable docker
sudo systemctl start docker
安装完成后检查状态:
sudo systemctl status docker
只要看到类似 active (running) 的状态,说明 Docker 服务已经正常启动。
2. 创建数据持久化目录
One API 在 SQLite 模式下需要一个本地目录保存运行数据,建议提前创建:
sudo mkdir -p /home/ubuntu/data/one-api
sudo chmod -R 755 /home/ubuntu/data/one-api
如果你的实际用户不是 ubuntu,可以按自己的路径调整,比如:
sudo mkdir -p /opt/one-api/data
sudo chmod -R 755 /opt/one-api/data
这个目录主要用于保存:
- SQLite 数据文件
- 服务运行数据
- 其他持久化信息
容器本身是容易重建的,但数据目录如果不挂载,后面重启或重建容器时,很多配置就容易跟着一起消失。
3. 检查端口是否占用
本文默认使用 3000 端口,先确认一下有没有冲突:
sudo ss -lntp | grep 3000
如果没有输出,说明大概率没有进程占用这个端口。
如果已经被其他服务占用,可以把宿主机端口改成别的,比如 3001:3000。
4. 准备一个上游模型渠道
One API 本身只是统一入口,不会凭空提供模型能力。
所以你至少要准备一个上游可用的 API Key,第一次部署建议只接一个渠道,先把最小闭环走通。别一开始就把后台配成大型试验场,容易把自己绕进去。
四、安装与部署
1. 拉取并启动 One API 容器
直接执行下面的命令:
docker run --name one-api -d \
--restart always \
-p 3000:3000 \
-e TZ=Asia/Shanghai \
-v /home/ubuntu/data/one-api:/data \
justsong/one-api
这条命令的含义如下:
--name one-api:容器命名为one-api-d:后台运行--restart always:容器异常退出后自动重启-p 3000:3000:宿主机 3000 端口映射到容器 3000-e TZ=Asia/Shanghai:设置时区-v /home/ubuntu/data/one-api:/data:挂载持久化目录
如果镜像拉取失败,可以改用备用镜像:
docker run --name one-api -d \
--restart always \
-p 3000:3000 \
-e TZ=Asia/Shanghai \
-v /home/ubuntu/data/one-api:/data \
ghcr.io/songquanpeng/one-api
2. 查看容器状态
执行:
docker ps
正常情况下,你会看到类似结果:
CONTAINER ID IMAGE STATUS PORTS
xxxxxx justsong/one-api Up 10 seconds 0.0.0.0:3000->3000/tcp
只要状态显示为 Up,说明服务已经成功启动。
如果没有启动成功,不要先忙着删容器,先看看日志:
docker logs -f one-api
很多部署问题其实第一眼就能在日志里找到答案,比如:
- 端口冲突
- 目录权限问题
- 镜像拉取不完整
- 初始化异常
3. 访问后台页面
在浏览器中打开:
http://服务器IP:3000
如果你在本机测试,也可以直接访问:
http://localhost:3000
只要页面能加载出来,说明 Web 服务已经对外可访问。
4. 使用管理员账户登录
根据项目 README,One API 初始管理员账号通常为:
- 用户名:
root - 密码:
123456
首次登录后建议立刻完成以下操作:
- 修改默认管理员密码
- 检查后台页面是否完整加载
- 确认系统设置、渠道管理、令牌管理页面是否能正常打开
默认密码不改,哪怕你后面配置得再漂亮,也属于“门已经装好了,钥匙还插在锁上”。
五、配置说明
One API 的关键配置,主要集中在后台里的渠道管理和令牌管理。
如果这两块没配好,服务虽然能跑,但其实还不能真正对外提供可用接口。
1. 数据目录说明
本文挂载的持久化目录是:
/home/ubuntu/data/one-api
后续如果你升级镜像或重建容器,只要这个目录保留,通常数据也会继续保留。
2. 渠道配置说明
渠道可以理解为“上游模型服务来源”。
你需要把真实可用的模型服务配置到 One API,One API 才能帮你完成请求转发。
常见渠道包括:
- OpenAI
- Azure OpenAI
- Claude
- Gemini
- DeepSeek
- Ollama
- 其他兼容 OpenAI API 的服务
在后台新建渠道时,通常要关注以下信息:
- 渠道类型
- API Key
- Base URL
- 支持模型
- 分组
- 是否启用
这里最常见的坑不是“完全不会填”,而是“看起来填得差不多,实际刚好差一点”。
例如:
- Base URL 多写或少写路径
- 模型名称与上游真实模型名不一致
- 渠道未启用
- 渠道分组和 token 分组不一致
这些问题页面上看不明显,但接口一调用就会暴露。
3. 令牌配置说明
令牌是发给下游客户端使用的访问凭证。
客户端不应该直接拿你的上游 Key 去调用,而应该通过 One API 生成的 token 访问统一入口。
新建 token 时,建议关注:
- 令牌名称
- 有效期
- 配额 / 额度
- 分组
- 模型权限
- 是否启用
如果你是团队内部使用,可以为不同项目分发不同 token;
如果你是做 AI 接口管理或分发服务,这里就是后续做配额、隔离和计费逻辑的基础。
4. 关于数据库切换
本文先使用 SQLite,主要是为了快速跑通。
如果后续你需要长期运行,建议切换到 MySQL,并通过环境变量配置数据库连接:
-e SQL_DSN="root:123456@tcp(127.0.0.1:3306)/oneapi"
需要注意两点:
- 数据库
oneapi需要提前创建 - 容器访问数据库的地址要按实际网络环境填写
如果准备做多人长期使用,SQLite 够不够这个问题,不用想太久,通常答案都是:先能用,但最好别一直用。
六、跑通第一个 Demo
这一节是全文最关键的部分。
服务启动并不等于部署结束,真正的完成标准是:
- 后台能登录
- 渠道能配置
- token 能生成
- 接口能返回结果
只有这样,才算真正跑通了最小可用闭环。
1. 添加一个上游渠道
登录后台后,进入渠道管理页面,新增一个渠道。
第一次建议只配置一个最简单、最确定可用的上游来源。通常需要填写:
- 渠道类型
- API Key
- Base URL(如需要)
- 模型名称
- 分组
如果你用的是标准 OpenAI 或兼容接口,按官方说明填写即可。
如果你接的是第三方兼容服务,一定要确认 Base URL 是否准确。
这里特别提醒一个高频问题:
模型名一定要和上游实际支持的名称一致。
比如上游支持的是 gpt-3.5-turbo,你自己写了个别名,结果接口调用时八成会直接报错。
2. 创建测试 token
进入令牌管理页面,创建一个新 token。
第一次测试建议这样配置:
- 名称:
demo-token - 状态:启用
- 额度:给足测试额度
- 分组:与刚才的渠道保持一致
- 模型权限:选择刚才测试的模型
创建成功后,把生成的 token 复制保存,后面测试请求要用。
3. 用 curl 测试接口
假设你的 One API 地址是:
http://127.0.0.1:3000
可以执行下面的请求:
curl http://127.0.0.1:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-你的测试令牌" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "请回复:One API 部署成功"
}
]
}'
如果链路正常,你会看到类似下面的返回结果:
{
"id": "chatcmpl-xxx",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "One API 部署成功"
}
}
]
}
看到类似响应,说明从 token 到渠道再到上游模型的整条链路已经通了。
4. 用 Python 代码测试
如果你平时本来就是用 Python 接 OpenAI SDK,也可以直接这样验证:
from openai import OpenAI
client = OpenAI(
api_key="sk-你的测试令牌",
base_url="http://127.0.0.1:3000/v1"
)
resp = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "请回复:测试通过"}
]
)
print(resp.choices[0].message.content)
如果能正常打印回复内容,就说明 One API 已经可以作为 OpenAI 兼容接口层使用了。
七、效果验证
建议至少做下面 3 组验证,别只停留在“页面打开了”。
验证方式 1:查看容器状态
docker ps
成功标准:
- 容器状态为
Up - 没有反复重启
- 端口映射正常
验证方式 2:查看服务日志
docker logs --tail 100 one-api
成功标准:
- 没有持续报错
- 没有数据库初始化失败
- 没有监听端口失败
- 在发起请求后能看到对应访问日志
验证方式 3:验证模型接口
先测试模型列表接口:
curl http://127.0.0.1:3000/v1/models \
-H "Authorization: Bearer sk-你的测试令牌"
如果返回模型列表,说明基本鉴权和渠道权限已经没问题。
再测试聊天接口:
curl http://127.0.0.1:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-你的测试令牌" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "你好"}
]
}'
成功标准:
- 返回 JSON 数据
- 有正常的模型回答
- 后台能看到调用记录
- 配额或额度正常变化
如果这几项都成立,那就不是“看起来能用”,而是真的已经能用了。
八、常见报错与解决方案
这部分很重要。
很多人一遇到问题就想重装,但部署类问题十有八九都卡在环境、端口、模型名、权限分组和配置细节上。先看日志,再动手,比反复重建更省时间。
1. 容器启动失败或启动后秒退
常见现象
docker ps看不到容器docker ps -a里显示容器已经退出
排查命令
docker ps -a
docker logs one-api
解决方案
- 检查挂载目录是否存在
- 检查目录权限是否足够
- 检查 3000 端口是否被占用
- 尝试使用备用镜像重新启动
如有必要,也可以尝试下面这种方式:
docker run --name one-api -d \
--restart always \
--privileged=true \
-p 3000:3000 \
-e TZ=Asia/Shanghai \
-v /home/ubuntu/data/one-api:/data \
justsong/one-api
不过要注意,--privileged=true 不是常规首选,只是某些环境下的排查手段。能不用,尽量不用。
2. 页面能打开,但接口调用失败
常见原因
- 没有配置上游渠道
- API Key 填错
- Base URL 不正确
- 模型名不匹配
- token 没有对应权限
- token 额度不足
解决方案
- 到后台确认渠道是否已启用
- 检查模型名是否与上游实际一致
- 检查 token 分组和渠道分组是否一致
- 查看后台日志或容器日志定位具体错误
- 先用最基础、最确定可用的模型做测试
很多时候不是程序出问题,而是后台里“填得差不多”,结果关键字段差了一点点。
3. 报错“无可用渠道”
这个报错很常见,通常说明请求虽然进来了,但系统找不到匹配的上游渠道。
重点检查项
- 渠道是否启用
- 渠道是否配置了当前请求模型
- token 分组与渠道分组是否一致
- 请求模型名是否真实可用
解决方案
- 统一渠道和 token 的分组
- 暂时只保留一个渠道做测试
- 只测试一个确认存在的模型名
- 调通后再慢慢增加渠道和策略配置
4. 后台页面无法访问
排查命令
docker ps
sudo ufw status
解决方案
如果服务器开启了防火墙,需要放行 3000 端口:
sudo ufw allow 3000/tcp
如果是云服务器,还需要同步检查安全组规则。
很多“打不开”并不是服务没起来,而是外部访问路径根本没放通。
5. 域名访问后页面或接口异常
常见原因
前端通过 HTTPS 域名访问,但接口仍然走 HTTP,浏览器会拦截混合内容请求。
解决方案
- 使用 Nginx 做反向代理
- 给域名配置 HTTPS 证书
- 确保前端和接口统一使用 HTTPS
开发阶段本地访问可能没问题,一旦上域名,这类问题就容易暴露。
6. SQLite 能用,但长期使用不稳妥
常见表现
- 数据量增加后体验变差
- 多人使用时不够从容
- 后续维护不够方便
解决方案
切换到 MySQL,并在启动时增加数据库连接参数:
docker run --name one-api -d \
--restart always \
-p 3000:3000 \
-e TZ=Asia/Shanghai \
-e SQL_DSN="root:123456@tcp(127.0.0.1:3306)/oneapi" \
-v /home/ubuntu/data/one-api:/data \
justsong/one-api
同时提前创建数据库:
CREATE DATABASE oneapi DEFAULT CHARACTER SET utf8mb4;
7. 镜像拉取失败
常见原因
通常还是网络问题,和项目本身关系不大。
解决方案
优先尝试备用镜像:
ghcr.io/songquanpeng/one-api
如果仍然失败,就需要结合你当前服务器环境处理 Docker 镜像访问问题,比如使用代理或镜像加速。
九、进阶说明
当你已经把最小闭环跑通之后,后面可以往这些方向继续完善。
1. 切换 MySQL
适合多人使用、长期运行、对数据稳定性要求更高的场景。
2. 配置 Nginx + HTTPS
适合公网访问,避免直接暴露 3000 端口。
3. 接入多个上游渠道
可以根据成本、稳定性、模型效果做分流或备用。
4. 增加日志、监控和备份
适合准备长期使用的环境,尤其是公网服务。
5. 做二次开发
如果你的目标不是个人测试,而是业务接入,可以继续扩展:
- 套餐体系
- 支付能力
- 多用户管理
- 邀请返利
- 更细粒度的权限控制
One API 更像一个可用的底座,很多业务能力都可以在它之上往外长。
十、总结
如果你的目标是快速搭一个能工作的多模型统一接口平台,而不是从零手写整套网关、令牌体系和后台,那么 One API 确实是一个很务实的选择。
这篇文章完成的事情不复杂,但每一步都很关键:
- 把容器拉起来
- 把后台打开
- 把渠道配通
- 把 token 建出来
- 把接口真正测通
做到这里,对于个人开发者、小团队测试环境,甚至部分初期业务验证场景,已经足够用了。
后面要不要继续补 MySQL、Nginx、HTTPS、监控和二次开发,可以根据实际需求慢慢往上叠。部署这件事最怕的,从来不是功能不够,而是一开始想做得太全,结果第一步都没跑通。
十一、适合谁继续深入
下面几类读者,比较适合继续往下研究:
-
想做生产级 AI 网关的开发者
建议继续补数据库、反向代理、HTTPS、限流、日志和备份。 -
想做 AI token 分发或配额管理系统的团队
可以基于 One API 的用户、令牌、额度体系继续扩展业务逻辑。 -
想统一接入多家模型供应商的工程师
可以把 One API 作为内部统一 API 层来使用。 -
想研究源码和适配逻辑的开发者
可以重点看它的渠道管理、请求转发、鉴权和后台设计。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)