体系结构论文(一百):ProofWright: Towards Agentic Formal Verification of CUDA
ProofWright: Towards Agentic Formal Verification of CUDA 【斯坦福和英伟达26年的paper】
这篇文章在做什么
这篇文章讨论的是一个非常关键、而且很容易被忽略的问题:
现在很多 agent 或 LLM 已经能自动生成 CUDA kernel,甚至还能优化性能,但这些代码到底靠不靠谱?如果只靠编译通过和单元测试,真的能相信它们没有 data race、没有越界、没有语义错误吗?
作者的答案是否定的。于是他们提出了 `ProofWright`,一个面向 LLM 生成 CUDA 代码的 agentic formal verification 框架。
这篇论文的目标不是“帮模型写出更快的 CUDA”,而是:
- 自动证明 memory safety
- 自动证明 thread safety / data-race freedom
- 在一部分场景下进一步证明 semantic equivalence,也就是生成的 CUDA 代码和原始 PyTorch 规格在语义上等价
这篇文章是在补“LLM 生成 GPU 代码之后最缺的一块”:可信性。
一、方向背景
作者先说一个了很基本但很重要的事实:CUDA kernel 的 bug 和普通顺序程序的 bug,不在一个量级。
原因包括:
- 大量线程并发执行
- 有 shared/global/local 等多种内存空间
- 指针和低层索引大量出现
- 同步原语复杂
- 性能优化常常会改变线程协作与访存模式
这意味着,很多 bug 不是“一个输入跑一下就看出来”的,而是:
- 只在某些特定输入长度下出现
- 只在某些线程块组合下出现
- 只在某些 thread interleaving 下暴露
- 或者根本没有 crash,但语义上不满足原规格
这也是为什么作者对当前 agentic CUDA generation pipeline 很不满意:现有方法大多只是编译 + 测试 + 性能反馈,不能给出真正强的 correctness guarantee。
为什么要做“形式验证 agent”
作者在引言和背景里抓住了两类问题。
1. False negative
动态测试看不到所有路径。某个 race condition 可能只在输入长度不是 4 的倍数时出现;你如果测试集里刚好没覆盖,就会漏掉。
2. Reward hacking
agent 可能学会“通过测试”而不是“实现规格”。例如:
- 偷偷复制 reference output
- 去掉必要同步换取更高性能
- 生成只在测试集上对的“投机代码”
这两个问题在 LLM 生成代码场景里会被放大。因为模型生成速度太快了,人工再去逐个 formal verify 几乎不可能。
所以作者认为,必须引入自动化的 formal verification 流程,而且还要做成 agentic 的,不然跟不上生成速度。

Listing 1:作者用一个 race condition 例子说“测试为什么不够”
论文一开始就给了一个由 GPT-4.1 生成的 sigmoid kernel 例子。这个 kernel 想做一个 vectorized sigmoid,每个线程处理 4 个 FP16 元素。
问题出在 tail-processing 逻辑上:
- 当输入长度不是 4 的倍数时
- 多个 block 中 `threadIdx.x == 0` 的线程会在尾部写同一段输出
- 从而产生 race condition
更关键的是:这个 bug 居然能通过编译和多轮单元测试。
这类例子非常有价值,因为它拿了一个实际由 LLM 生成、且测试真会漏掉的 CUDA 例子来说明。
二、ProofWright
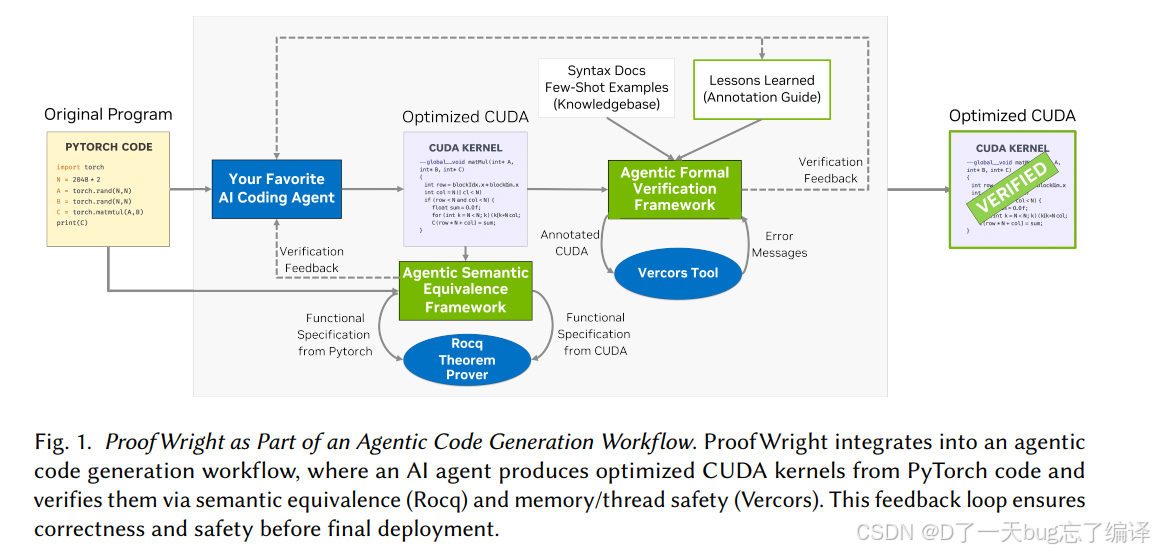
图 1 展示了 ProofWright 在整体 agentic code generation pipeline 里的位置。
作者并没有说“有了 ProofWright 就不需要测试或性能优化”,而是把它放在后期:
- 先让常规 agent 做生成、编译、单元测试、性能反馈
- 再把比较 promising 的候选交给 ProofWright 做高保证验证
这点很合理。因为形式验证通常比普通测试更重,不适合对所有候选都立即全量跑。
所以作者把它定位为“later-stage high-guarantee filter”。这个定位非常现实,也比“全自动从头到尾 formal-first”更靠谱。
ProofWright 的两大核心组件
整套系统由两个主要部分组成:
1. Agentic Formal Verification Framework
负责证明:
- memory safety
- thread safety / data race freedom
2. Agentic Semantic Equivalence Framework
负责证明:
- 生成的 CUDA kernel 是否符合原始 PyTorch 规格
这两个组件的划分是很清楚的。前者是“代码本身安不安全”,后者是“代码算的东西对不对”。
这是一个很好的设计,因为很多工作只做到前者就停了,但真正可信的“correctness”其实还要包括语义等价。
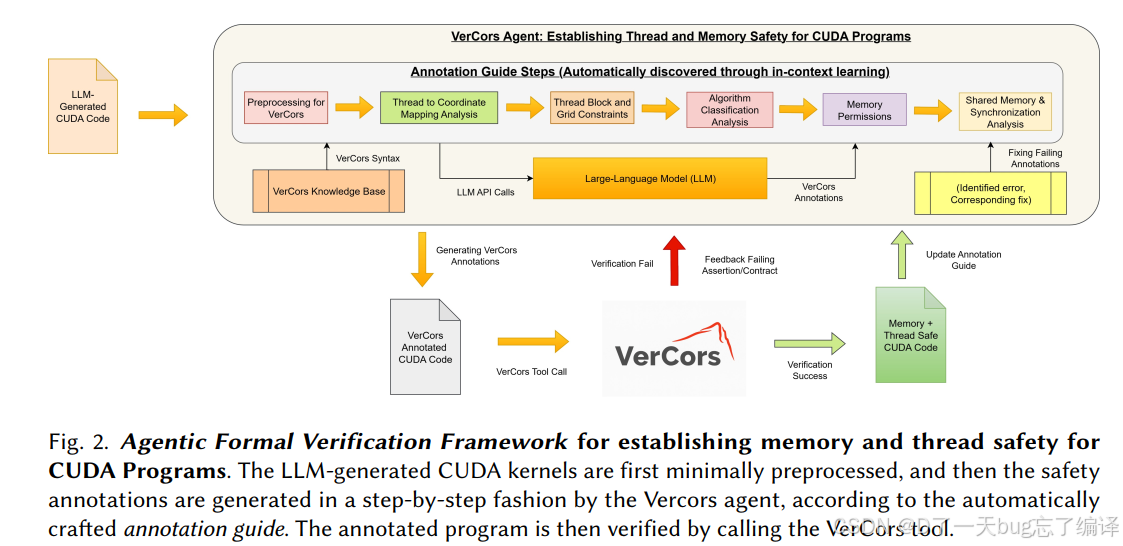
图 2 描述了第一个核心框架,也就是 VerCors Agent。
大致流程是:
- 对 CUDA kernel 做最小预处理
- LLM agent 按步骤生成 VerCors annotations
- 把这些注释送进 VerCors 验证器
- 根据反馈再修
这里最关键的不是“LLM 调用 VerCors”本身,而是作者发现:如果只是 naive prompt engineering,效果几乎灾难性地差。
所以他们专门引入了三类知识源:
- Knowledge Base
- Annotation Guide
- 错误修复数据库
这三者共同构成 agent 的“验证经验”。
为什么单纯 prompt formal verifier 会失败?
这篇文章最重要的一个结论之一就是:
“把 formal tool 接上 LLM”并不会自动变成好系统。
作者在实验里明确说了,naive integration fails spectacularly。
原因很容易理解:
- VerCors 语法本身就是低资源语言
- 公开语料很少
- 注释不是自然语言解释,而是精细的 formal contracts
- 不仅要写得像,还要写得对,还要能引导 SMT solver
所以这篇论文真正的技术价值,不在于“想到用 LLM 生成注释”,而在于它如何把这个任务拆成可行的 agentic workflow。
Knowledge Base
Knowledge Base 包含三部分:
- stripped-down VerCors 官方文档
- 一些手工验证通过的 CUDA few-shot examples
- error-fix pairs
其中 error-fix pairs 很有意思。作者会记录:
- 原始失败代码
- VerCors error
- 人类解释为什么失败
- 修复后的代码

图 3 展示了这种错误修复样例的结构。
这很像一个面向 verification 的“小型经验库”。和普通 codegen 不同,这里的关键不是多给几个成功案例,而是要让 agent 学会“VerCors 这类错通常该怎么修”。
Annotation Guide:这是整篇文章最有意思的设计之一
相比静态 Knowledge Base,我觉得更关键的是动态的 Annotation Guide。
作者发现,仅靠语法和 few-shot examples 还不够,因为:
- 模型容易 pattern match
- 新 kernel 结构一变就不会了
- 成功一次后也不会自动积累经验
于是他们让 agent 在每次成功验证后,自动总结新 insight,更新一份 generalized verification recipe,也就是 Annotation Guide。
这相当于让 agent 拥有一种“长期验证记忆”。
这点非常像 agentic system 里真正有价值的学习方式:不是 fine-tune 模型,而是让 workflow 持续积累可复用经验。
作者总结了 agent 自己学到的几个验证原则,例如:
1. Algorithm-class-aware verification
kernel 先按算法家族分类,比如:
- element-wise
- convolution-like
- reduction
不同类型对应不同 permission scheme 和 index reasoning 方法。
2. Thread-to-data mapping
agent 学会根据线程和数据的映射关系设计 helper functions,帮助 verifier 理解 index 是否 in-bounds,线程是否访问重叠位置。
3. Thread block / grid constraints
agent 会推导合适的 block/grid 维度条件,以及数组长度、非空性等前置条件。
这些经验很重要,因为它们说明系统不只是“抄几个例子”,而是在形成一种 domain-specific verification methodology。

Listing 3 给出的是一个矩阵乘 kernel 的 VerCors contract 和注释示例。它展示了 agent 需要做的事情远比“加几行注释”复杂:
- 识别哪些内存是 read,哪些是 write
- 为不同数组元素分配 permission
- 处理条件访问
- 生成 helper functions 帮助证明索引关系
- 给循环加 invariant

Listing 4 则是 agent 自动生成的 4D flatten helper function,把多维索引映射成线性地址,并给出前后条件。
这两个例子合起来说明一件事:ProofWright 成功的前提,不是模型会说形式化语言,而是它能把 CUDA kernel 的线程-数据关系翻译成 verifier 能吃下去的中间形式。
semantic equivalence
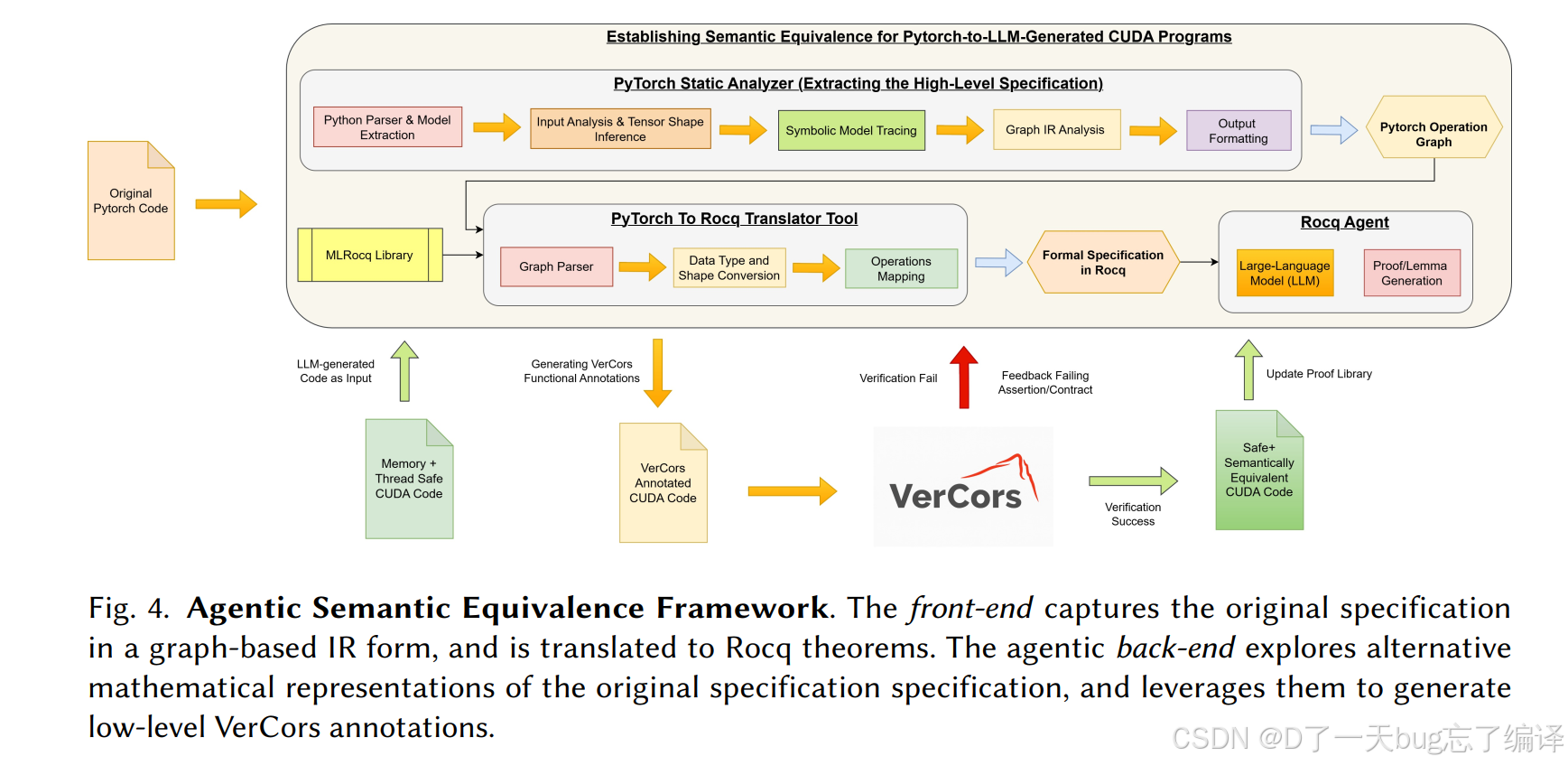
图 4 描述了语义等价证明框架。
这部分流程大致是:
- 从原始 PyTorch 程序里提取 computation graph
- 通过 MLRocq library 把图翻成 Rocq 里的形式化规格
- 让 Rocq agent 从 CUDA kernel 中综合出相应数学表示
- 构造 theorem 和 proof,证明两边等价
- 再把证明结果下放成 VerCors 的 functional annotations
它不再只是问“有没有越界、有没有 race”,而是问“这个 kernel 算的是不是和原规格同一件事”。
这是这篇文章比很多形式验证工作更进一步的地方。
为什么 semantic equivalence 明显比 memory/thread safety 更难?
因为 safety 证明本质上是在证明“不出事”,而 semantic equivalence 是在证明“恰好做对了应该做的事”。
前者需要:
- 索引范围正确
- 写权限不冲突
- 同步点足够
后者则需要:
- 高层 PyTorch 程序的语义被正确抽象
- CUDA 代码的数学行为被正确刻画
- 两者在所有条件下等价
这中间不只是 verifier 的问题,还包括规格抽取、形式化建模、lowering 是否可靠。
所以从一开始就应该预期:语义等价这一块会比 safety coverage 低很多。
PyTorch Static Analyzer 和 MLRocq
作者没有让 LLM 直接“读 PyTorch 然后编 theorem”,而是做了更稳的前端:
- PyTorch Static Analyzer 把高层规格变成 graph-based IR
- MLRocq library 提供常见 tensor / neural operation 的 Rocq 形式定义
- translator 把图映射到 Rocq 表示
这一点设计得很好,因为它把“高层规格抽取”从 LLM 幻觉空间里拿出来,尽量做成程序化、可信的过程。
作者还明确说,semantic equivalence front-end 不用 LLM,这样 formal specification process 本身更可信。
这是一个很成熟的系统设计决定。
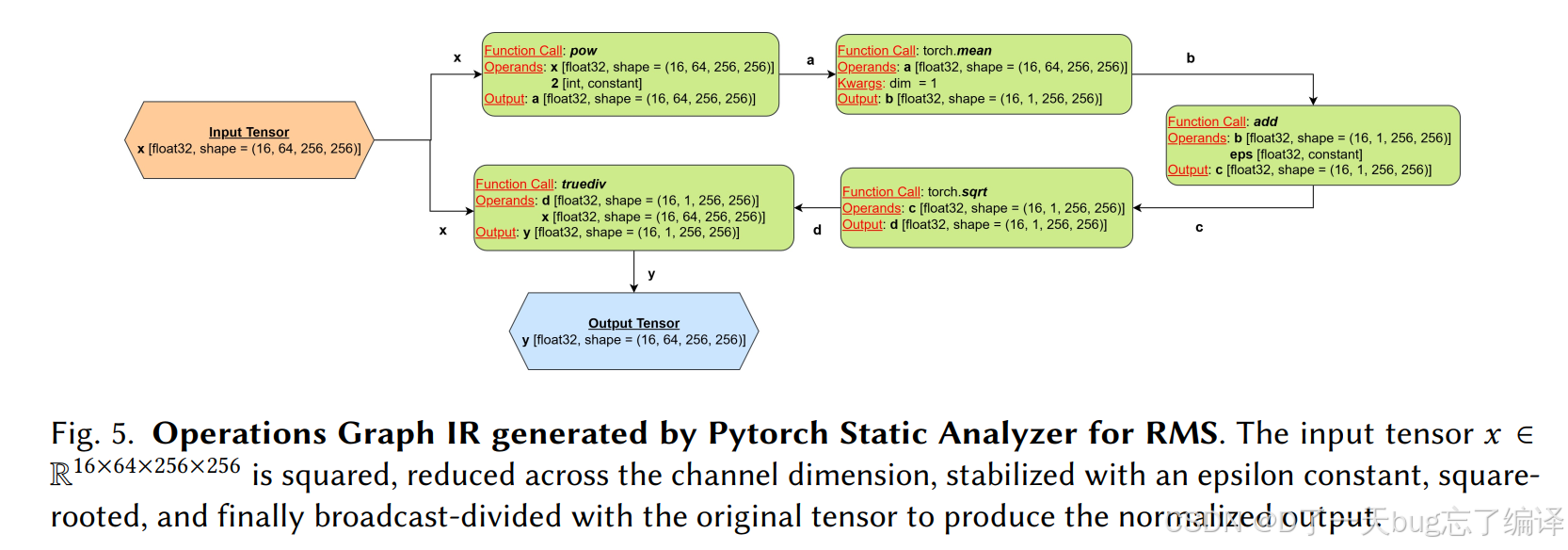
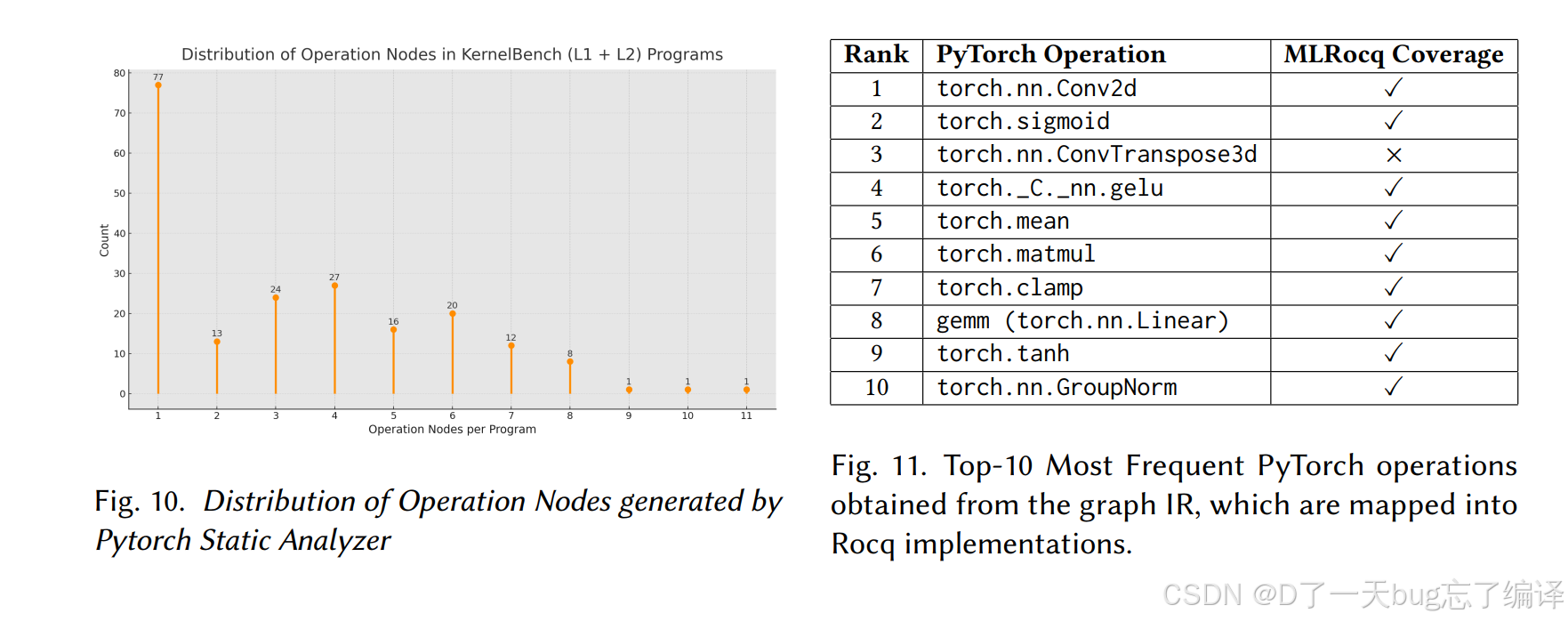
Figure 5 / Figure 10 / Figure 11:前端规格抽取本身做得不错
论文在语义等价部分给了几组 supporting result:
- Figure 5 展示 PyTorch 规格图的例子(如 RMS norm)
- Figure 10 给出 operation nodes 分布
- Figure 11 展示 top-10 常见 PyTorch op 及其 MLRocq coverage
作者报告:
- 静态分析器在 KernelBench L1/L2 上都能成功抽取规格
- MLRocq library 当前支持 99 个 PyTorch operations
- 对 KernelBench L1 的 op coverage 约 92%
这部分结果说明 semantic equivalence framework 的前端并不是主要瓶颈。它能比较稳定地把 PyTorch 规格抽成可形式化表示。
三、实验
作者把评估问题明确成 RQ1-RQ5:
- RQ1:能验证多少 memory/thread safety
- RQ2:开销有多大
- RQ3:知识库和 annotation guide 有多重要
- RQ4:semantic equivalence 前端能覆盖哪些规格
- RQ5:最终能对多少 kernel 建立“可信覆盖”
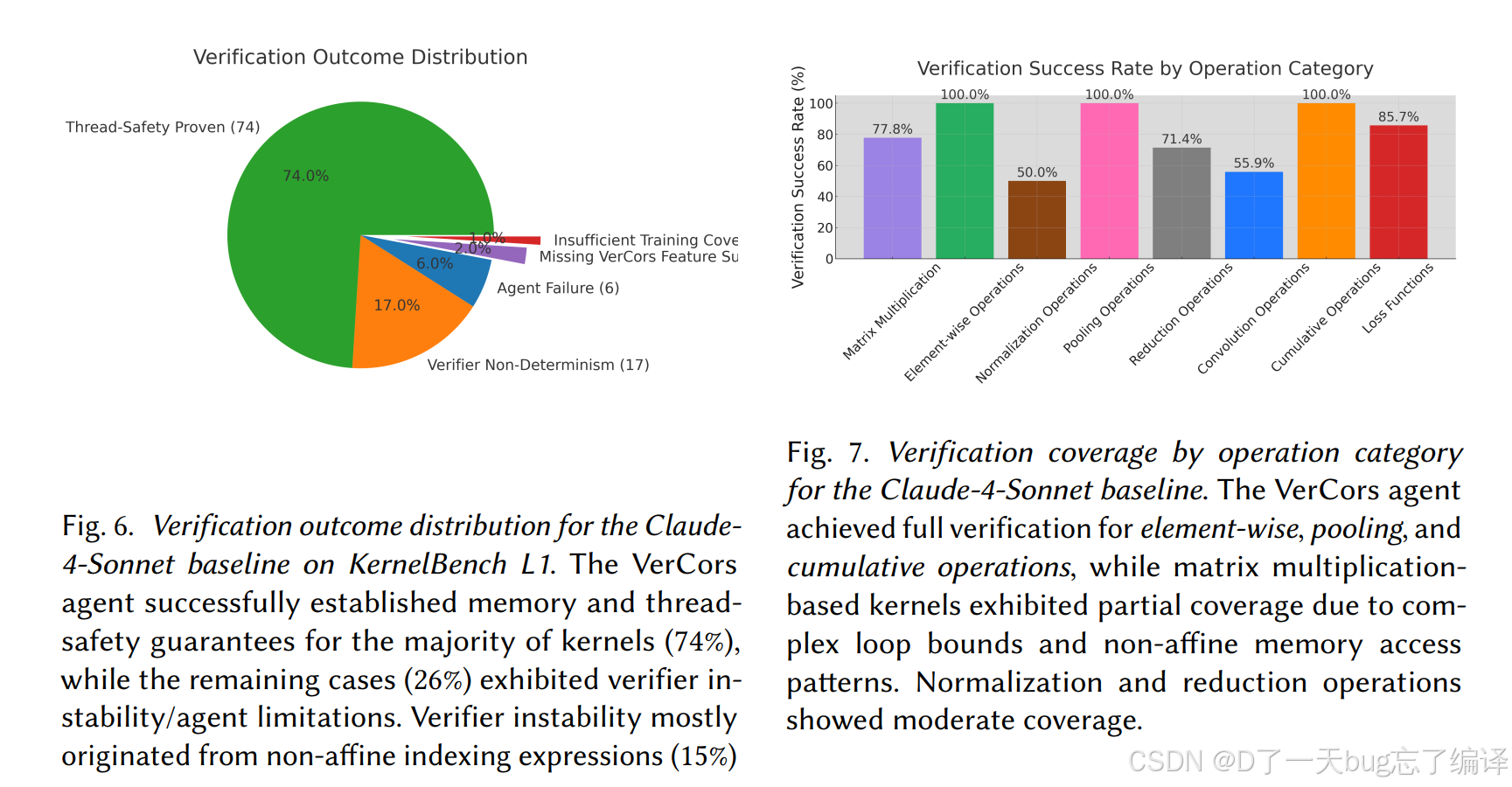
对 Claude-4-Sonnet 生成的 KernelBench L1 baseline,ProofWright 的 VerCors Agent:
- 成功建立 memory safety + thread safety 的比例是 74%
Figure 6 给出总体分布,Figure 7 给出按操作类别的 breakdown。
作者进一步把剩余失败分成两类:
- verifier instability:17%
- agent failure:9%
这个结果我认为是很有说服力的。
- 74% 不是一个夸张到不可信的数字
- 失败原因拆得也合理
- 作者没有把失败全甩锅给模型,而是承认 SMT instability 本身就是重要瓶颈
这比很多只报一个成功率、不给错误结构的论文要成熟得多。
作者举了一个很典型的例子:
- 明明某几个数组访问是 in-bounds
- 但 SMT solver 就是卡在非线性算术和多变量量化上,证不出来
最后手工加 frame statement,限制求解上下文之后,验证就过了。
这段分析很重要,因为它说明:
- 失败不总是 agent 不会
- 有时是 formal backend 本身的稳定性问题
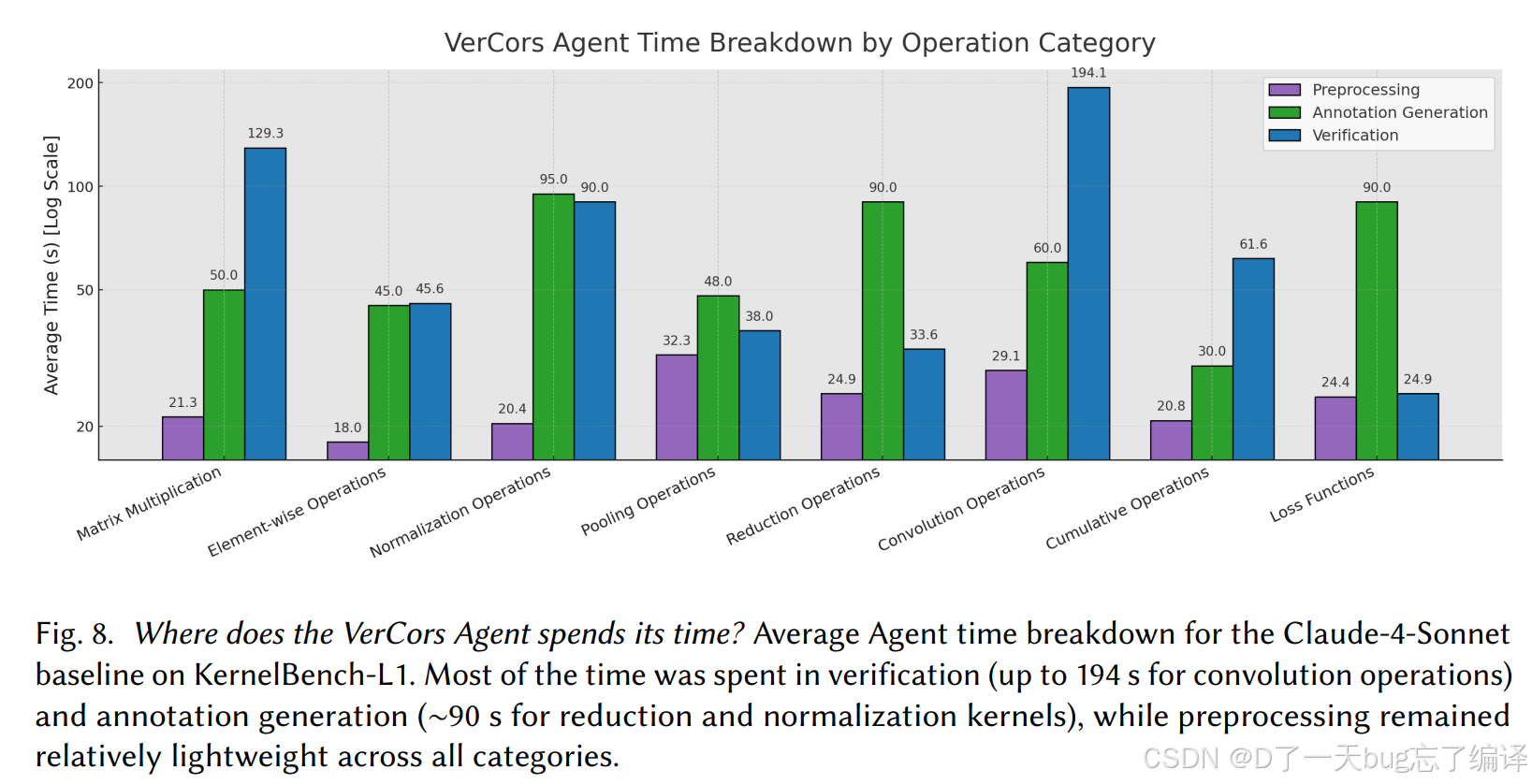
Figure 8 分析了 VerCors Agent 的时间开销,作者总结:
- annotation generation 大约 90 秒量级
- verification 阶段是主要瓶颈
- 某些复杂 convolution 类 kernel,verification 可到 194 秒
这个开销如果放在“每个训练 step 都做”显然太贵,但放在“后期对 promising kernel 做高保证过滤”这个定位上,是可以接受的。
也就是说,这个系统不是低开销 lint 工具,而是高价值、较重型的 correctness filter。
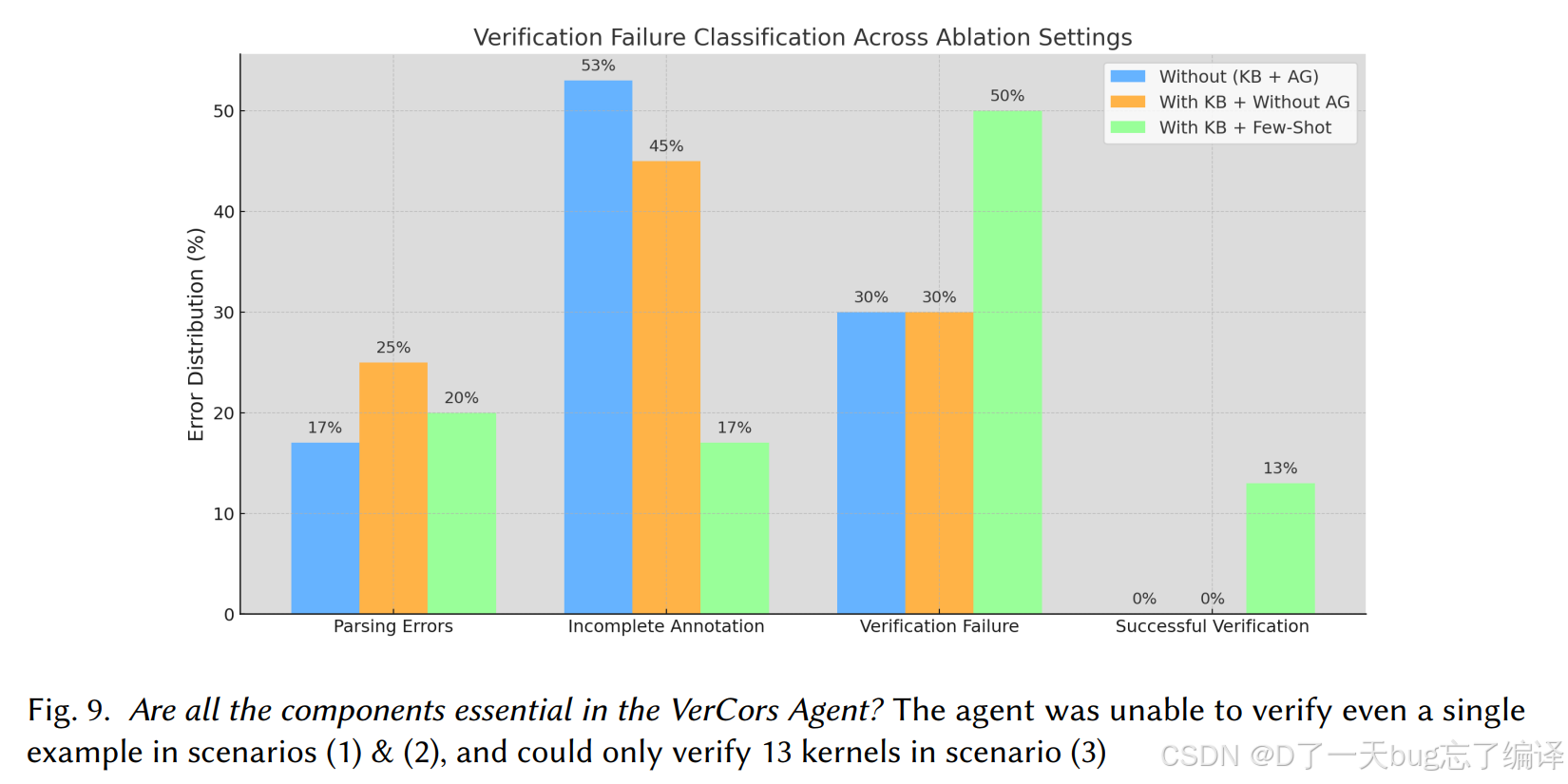
作者做了三种情形:
1. 没有 knowledge base,也没有 annotation guide
2. 只有 knowledge base,没有 annotation guide
3. 有 knowledge base 和少量 few-shot,但没有完善 guide
结果非常强烈:
- 前两种情况,一个 kernel 都没验证成功
- 第三种情况也只验证了 13 个 kernel
说明 naive LLM + formal tool 基本不可用。
而且这也证明了这篇文章的真正贡献不在“想到让 LLM 调用 verifier”,而在于:
- 如何构造长期记忆
- 如何组织经验性知识
- 如何把 proof-repair 过程变成可积累的 agent workflow

作者报告,semantic equivalence framework 的 front-end:
- 能处理 KernelBench L1/L2 共 200 个 PyTorch programs
- MLRocq 目前覆盖 99 个常见 op
- KernelBench L1 op coverage 约 92%
这说明 front-end specification abstraction 很有希望,甚至可以单独作为一个 PyTorch-to-formal-spec layer 使用。
但注意,这只是“能把规格抽出来”,不代表后面的 equivalence proof 一定能完成。
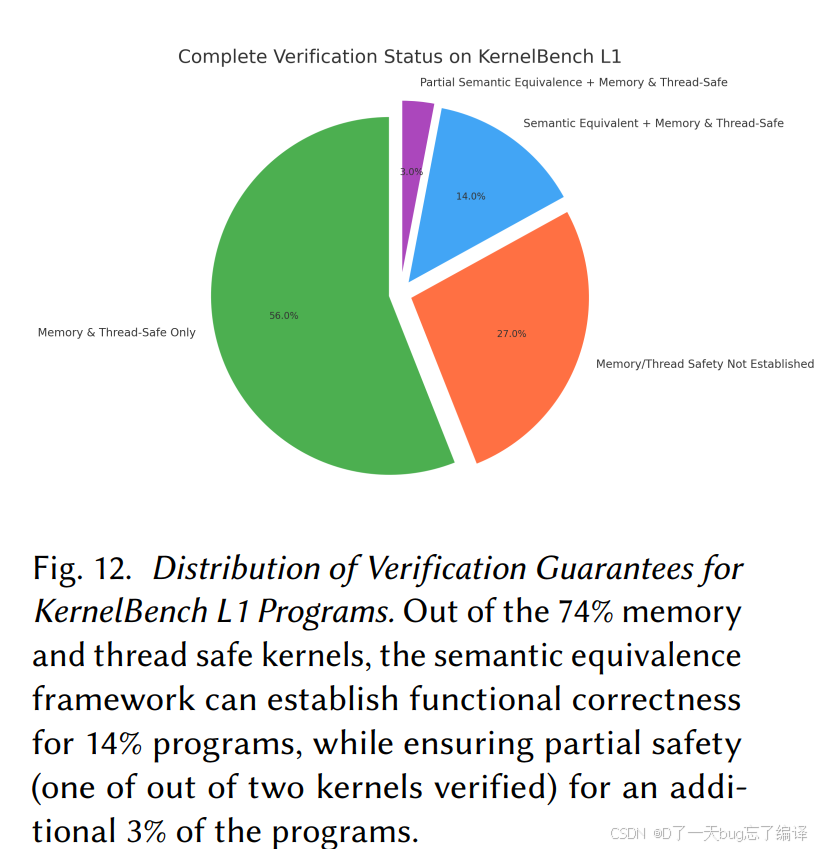
Figure 12:真正完整的 semantic equivalence coverage 只有 14%
这是这篇论文最需要客观看待的结果之一。
作者最终能够对 KernelBench L1 建立:
- memory safety + thread safety:74%
- 在此基础上进一步建立 full semantic equivalence:14%
- 另有约 3% 是 partial semantic equivalence
这 14% 主要是哪些 kernel?
- one-thread-to-one-output-element 的简单 element-wise / activation 类操作
而对 reduction、pooling、需要跨线程累积状态、shared memory 聚合的 kernel,当前框架很难完成完整语义证明。
- 这篇论文在 safety 上已经相当有成果
- 但在 full functional correctness 上,还处于早期阶段

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)