AI 基础知识十四 手写Transformer架构代码
简介
本文基于libtorch手写完整Transformer架构代码包含
1.编码器 Encoder
2.解码器 Decoder
3.多头注意力 MultiHeadAttention
4.前馈网络 FFN
将 十一本章 “Transformer简单示例” 的libtorch库自带Transformer 换成 我们手写MyTransformer 来验证结果
Transformer架构分析
自已手写的功能肯定不如libtorch库自带Transformer功能完整,本着最简单原则,实现论文基本功能点,也能实现翻译任务,能够实现多头注意力的编写 基本上就完成了 50%,剩下的都是些拼装工作。功能分析如图有4点,1,2,4 目前未知实现细节,3是 只有一个 多头注意力要加掩码操作,解码器要配一个掩码。
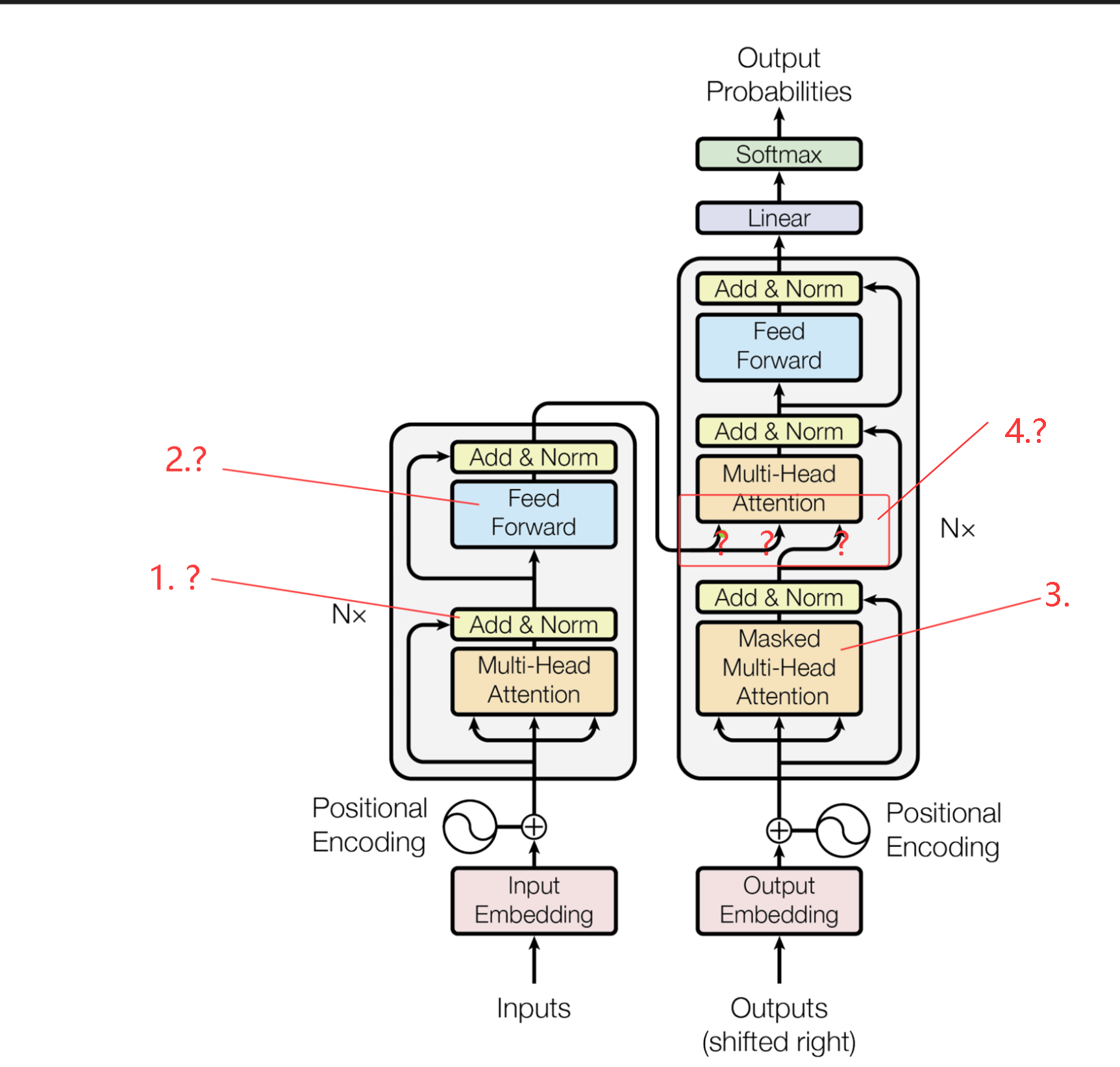
1. 层归一化 直接引用libtorch库的 torch::nn::LayerNorm功能作用
1. 训练超级稳定
2. 加速收敛
3. 特征维度: 零均值(0)、单位方差(1)
2. 前馈网络

激活函数为ReLU 实现也简单
3. 目标掩码 也就上三角 实现也简单
torch::Tensor generate_square_subsequent_mask(int64_t sz)
{
auto mask = torch::triu(torch::ones({ sz, sz }, torch::kFloat32), 1);
mask = mask.masked_fill(mask == 1, -std::numeric_limits<float>::infinity());
return mask;
}4. 从编码器输出结果流向解码器分别是K和V 见论文,解码器经过多头注意力掩码输出的是Q
注意 编码器结果只有一个值,也就是K和V相同

MyTransformer代码实现
1. 前馈网络 FFN
class FeedForwardNetImpl : public torch::nn::Module
{
public:
FeedForwardNetImpl(int64_t dim=512, int64_t dff=2048)
{
ffn = register_module("SeqFFN", torch::nn::Sequential(torch::nn::Linear(dim, dff),
torch::nn::ReLU(),
torch::nn::Linear(dff, dim)
));
}
auto forward(torch::Tensor x)
{
return ffn->forward(x);
}
torch::nn::Sequential ffn{};
};
TORCH_MODULE(FeedForwardNet);
只要知道维度和网络节点数,用torch::nn::Sequential组装简单化
2.MultiHeadAttention
把上一章内容修改一下,接收Q,K,V,mask参数,然后对Q,K,V权重变转(做神经网络输出),最后QKV运算
class MultiHeadAttentionImpl : public torch::nn::Module
{
public:
//q k v : [seq, batch, dim]
torch::Tensor forward(torch::Tensor& q, torch::Tensor& k, torch::Tensor& v,torch::Tensor mask = {})
{
auto q1 = Q->forward(q);
auto k1 = Q->forward(k);
auto v1 = Q->forward(v);
return ScaledDotProductAttention(q1, k1, v1, mask);
}
};
TORCH_MODULE(MultiHeadAttention);
3.编码器 Encoder
Transformer有一个或多个编码器,用一个类EncoderLayer实现编码器全部功能,再用一个类Encoders实现多个编码器同时工作, 用torch::nn::ModuleList将EncoderLayer关联起来
class EncoderLayerImpl : public torch::nn::Module
{
public:
EncoderLayerImpl(int64_t dim, int64_t head, int64_t dff)
{
torch::nn::LayerNormOptions normOpt({ dim });
norm1 = register_module("norm1", torch::nn::LayerNorm(normOpt));
norm2 = register_module("norm2", torch::nn::LayerNorm(normOpt));
ffn = register_module("ffn", FeedForwardNet(dim, dff));
attention = register_module("attention", MultiHeadAttention(dim, head));
}
auto forward(torch::Tensor x)
{
auto y = attention->forward(x,x,x);
y = norm1->forward(x + y); /// 残差连接
auto y2 = ffn->forward(y);
return norm2->forward(y + y2); /// 残差连接
}
FeedForwardNet ffn{ nullptr };
torch::nn::LayerNorm norm1{ nullptr }, norm2{ nullptr };
MultiHeadAttention attention{ nullptr };
};
TORCH_MODULE(EncoderLayer);
class EncodersImpl : public torch::nn::Module
{
public:
EncodersImpl(int64_t dim, int64_t head, int64_t ffn, int64_t layers)
{
moduleLayers = register_module("moduleLayers", torch::nn::ModuleList());
for (int i = 0; i < layers; i++)
{
moduleLayers->push_back(EncoderLayer(dim, head, ffn));
}
}
auto forward(torch::Tensor x)
{
for each(auto& item in *moduleLayers)
{
x = item->as<EncoderLayer>()->forward(x);
}
return x;
}
torch::nn::ModuleList moduleLayers{ nullptr };
};
TORCH_MODULE(Encoders);
4. 解码器 Decoder
跟编码器结构差不多,这里只列不同点
1.DecoderLayer 的 forward 要求 目标序列,编码器输出,目标掩码
class DecoderLayerImpl : public torch::nn::Module
{
public:
auto forward(torch::Tensor& tgt, torch::Tensor& memory,torch::Tensor tgtmask)
{
auto y = MaskAttention(tgt, tgtmask);
//cout << "y\n" << y.sizes() << endl;
//cout << "memory\n" << memory.sizes() << endl;
auto y2 = attention2->forward(y, memory, memory);
auto y3 = norm2->forward(y+y2); // 残差连接
auto y4 = ffn->forward(y3);
return norm3->forward(y3 + y4); // 残差连接
}
private:
torch::Tensor MaskAttention(torch::Tensor x, torch::Tensor mask)
{
attention->forward(x,x,x, mask);
}
};
class DecodersImpl : public torch::nn::Module
{
public:
torch::nn::ModuleList moduleLayers{ nullptr };
};
TORCH_MODULE(Decoders);5.MyTransformer
基本功能都有了这部组装一下
class MyTransformerImpl : public torch::nn::Module
{
public:
MyTransformerImpl(int64_t dim, int64_t head, int64_t ffn, int64_t layerEncoder, int64_t layerDecoder)
{
src_emb = register_module("src_emb", torch::nn::Embedding(torch::nn::EmbeddingOptions(src_vocab_size, dim)));
tgt_emb_ = register_module("tgt_emb", torch::nn::Embedding(torch::nn::EmbeddingOptions(tgt_vocab_size, dim)));
pos_encoder = register_module("pos_encoder", PositionalEncoding(dim, max_vocab_len));
encoders = register_module("Encoders", Encoders(dim, head, ffn, layerEncoder));
decoders = register_module("Decoders", Decoders(dim, head, ffn, layerDecoder));
fc = register_module("fc", torch::nn::Linear(dim, tgt_vocab_size));
}
torch::Tensor forward(torch::Tensor src, torch::Tensor tgt)
{
}
torch::Tensor predict(torch::Tensor src)
{
}
private:
torch::Tensor generate_square_subsequent_mask(int64_t sz)
{
auto mask = torch::triu(torch::ones({ sz, sz }, torch::kFloat32), 1);
mask = mask.masked_fill(mask == 1, -std::numeric_limits<float>::infinity());
return mask;
}
Encoders encoders{nullptr};
Decoders decoders{nullptr};
torch::nn::Embedding src_emb{ nullptr };
torch::nn::Embedding tgt_emb_{ nullptr };
PositionalEncoding pos_encoder{ nullptr };
torch::nn::Linear fc{ nullptr };
};
TORCH_MODULE(MyTransformer);6. 入口程序
void HandwrittenTransformerMain()
{
torch::manual_seed(6);
std::string model_path = "MyTransformer_model2.pt";
MyTransformer model(dim_model,2, dim_feed,1,1);
std::ifstream filem(model_path);
bool bmodel = filem.is_open();
if (!bmodel || true)
{
TrainData2(model);
torch::save(model, model_path);
}
else
{
torch::load(model, model_path);
std::cout << "load model ...." << std::endl;
}
filem.close();
TestData2(model);
}7. 训练代码
class MyTransformerImpl : public torch::nn::Module
{
public:
torch::Tensor forward(torch::Tensor src, torch::Tensor tgt)
{
auto none_mask = torch::Tensor();
auto tgt_mask = generate_square_subsequent_mask(tgt.size(1));
//[batch, seq] --> [seq, batch]
src = src.permute({ 1,0 });
tgt = tgt.permute({ 1,0 });
//std::cout << "input " << src << std::endl;
src = src_emb->forward(src) * std::sqrt(dim_model);
src = pos_encoder->forward(src);
tgt = tgt_emb_->forward(tgt) * std::sqrt(dim_model);
tgt = pos_encoder->forward(tgt);
return TransformerForward(src, tgt, tgt_mask);
}
private:
torch::Tensor TransformerForward(torch::Tensor& src,torch::Tensor& tgt,torch::Tensor tgtmask)
{
auto outputEncoder = encoders->forward(src);
auto outputDecoder = decoders->forward(tgt, outputEncoder, tgtmask);
return fc->forward(outputDecoder);
}
};
TORCH_MODULE(MyTransformer);8. 测试代码
class MyTransformerImpl : public torch::nn::Module
{
public:
torch::Tensor predict(torch::Tensor src)
{
//std::cout << src << std::endl;
auto srcemb = src_emb->forward(src) * std::sqrt(dim_model);
srcemb = pos_encoder->forward(srcemb);
auto memory = encoders->forward(srcemb);
std::vector<int64_t> tgtpad = GetWordId(tgt_vocab, "S");
int i = 0;
while (i < tgt_vocab_size * 2)
{
torch::Tensor tgt = torch::tensor(tgtpad, torch::kLong);
auto tgt_mask = generate_square_subsequent_mask(tgt.size(0));
///std::cout << "tgt_mask " << tgt_mask << std::endl;
auto tgt_emb = tgt_emb_->forward(tgt) * std::sqrt(dim_model);
tgt_emb = pos_encoder->forward(tgt_emb);
auto out = decoders->forward(tgt_emb, memory, tgt_mask);
out = fc->forward(out).squeeze(-2);
auto next_token = out.argmax(-1);
int64_t key = next_token[i].item<int64_t>();
tgtpad.push_back(key);
//tgtpad.insert(tgtpad.begin(), );
if ("E" == GetWordById(tgt_vocab, key))
{
break;
}
i++;
}
return torch::tensor(tgtpad, torch::kLong);
}
};
TORCH_MODULE(MyTransformer);运行效果和完整代码
运行效果:
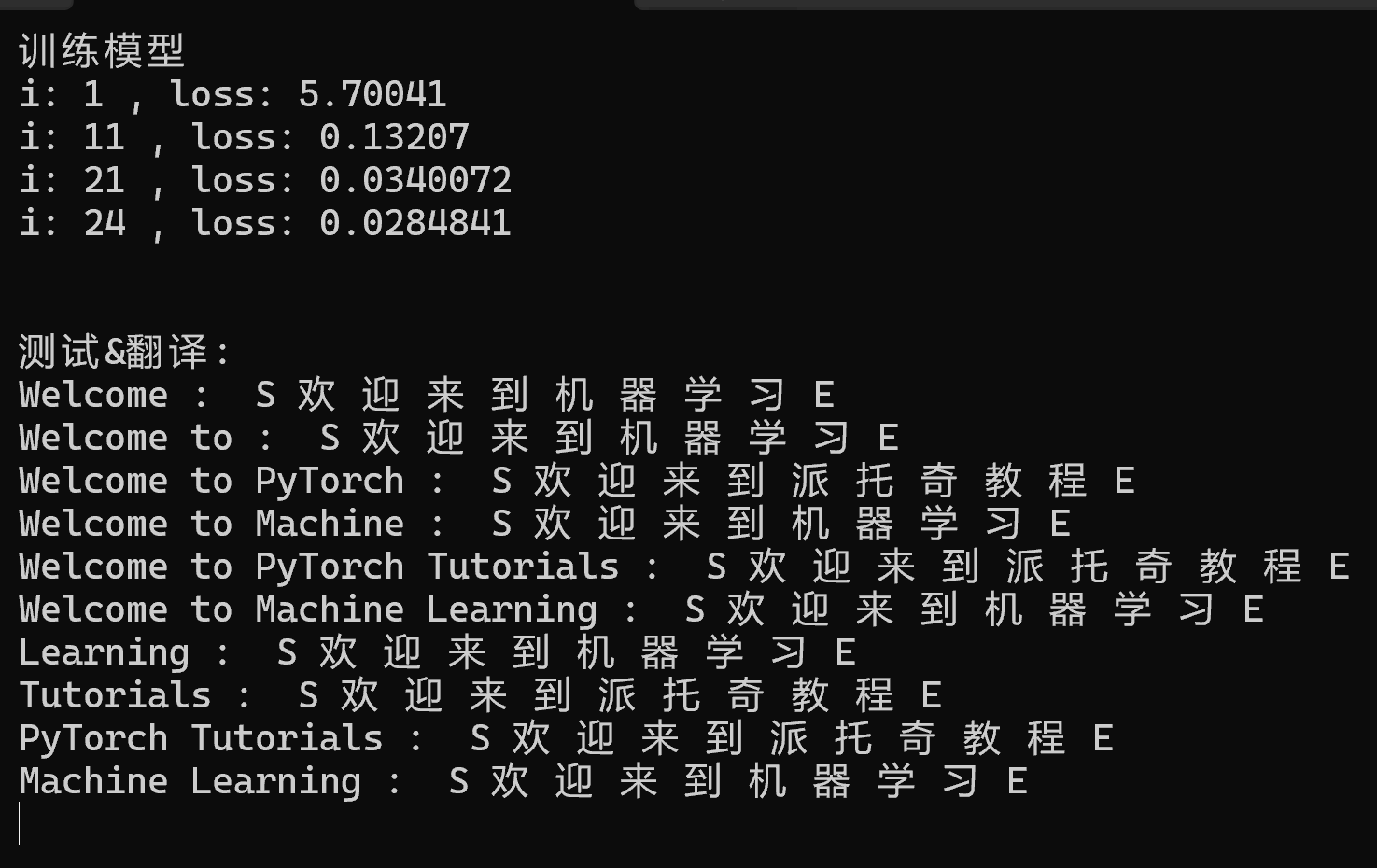
代码文件 TransformerTestData.h
#pragma once
#include <torch/torch.h>
#include <iostream>
#include <torch/serialize.h>
#include <regex>
#include <fstream>
#define dim_model 128
#define dim_feed 256
#define max_vocab_len 500
#define max_train 100
#define PadId 0
typedef const std::unordered_map< std::string, int64_t> TableVocab;
typedef std::vector<std::pair<int64_t, int64_t>> WordList;
/// <翻译>
/// Welcome to PyTorch Tutorials ---> 欢迎来到派托奇教程
/// Welcome to Machine Learning -----> 欢迎来到机器学习
/// </翻译>
extern TableVocab src_vocab;
extern TableVocab tgt_vocab;
extern int64_t src_vocab_size;
extern int64_t tgt_vocab_size;
std::vector<std::string> Split(const std::string& s);
std::string GetWordById(TableVocab& vocabId, int64_t dataid);
std::vector<int64_t> GetWordId(TableVocab& vocabId, std::string data);
WordList GetLoadDataWordId(std::pair<std::string, std::string> data);
class translatDataset : public torch::data::Dataset<translatDataset>
{
public:
translatDataset()
{
wordCount.push_back(GetLoadDataWordId({ "Welcome to PyTorch Tutorials Pad Pad Pad Pad Pad","欢 迎 来 到 派 托 奇 教 程" }));
wordCount.push_back(GetLoadDataWordId({ "Welcome to Machine Learning Pad Pad Pad Pad","欢 迎 来 到 机 器 学 习" }));
}
torch::optional<size_t> size() const
{
return wordCount.size();
}
torch::data::Example<torch::Tensor, torch::Tensor> get(size_t index) override
{
auto item = wordCount[index];
std::vector<int64_t> tmpinput;
std::vector<int64_t> tmptarget1;
for each(auto& i in item)
{
tmpinput.push_back(i.first);
tmptarget1.push_back(i.second);
}
auto input = torch::tensor(tmpinput, torch::kLong);
auto target = torch::tensor(tmptarget1, torch::kLong);
return { input, target };
}
public:
std::vector<WordList> wordCount;
};
std::pair<torch::Tensor, torch::Tensor> CreateDecoderInputOutput(torch::Tensor data);
class PositionalEncodingImpl :public torch::nn::Module
{
public:
PositionalEncodingImpl(int64_t d_model, int64_t max_len)
{
_d_model = d_model;
_max_len = max_len;
_posEncode = torch::zeros({ _max_len, _d_model }, torch::kFloat32);
Encoding();
register_buffer("posEncode", _posEncode);
}
torch::Tensor forward(torch::Tensor x)
{
if ((x.dim() == 2))
{
x = x.unsqueeze_(-2);
}
auto dim = x.size(0);
// std::cout <<"pos " << _posEncode.slice(0, 0, dim).sizes() << std::endl;
//std::cout <<"x " << x.sizes() << std::endl;
x = x + _posEncode.slice(0, 0, dim);
return x;
}
private:
void Encoding()
{
auto pos = torch::arange(0, _max_len, torch::kFloat32).reshape({ _max_len, 1 });
auto den_indices = torch::arange(0, _d_model, 2, torch::kFloat32);
auto den = torch::exp(-den_indices * std::log(10000.0f) / _d_model);
_posEncode.index_put_({ torch::indexing::Slice(), torch::indexing::Slice(0, _d_model, 2) }, torch::sin(pos * den));
_posEncode.index_put_({ torch::indexing::Slice(), torch::indexing::Slice(1, _d_model, 2) }, torch::cos(pos * den));
_posEncode.unsqueeze_(-2);
}
public:
torch::Tensor _posEncode;
int64_t _d_model = dim_model;
int64_t _max_len = max_vocab_len;
};
TORCH_MODULE(PositionalEncoding);
TransformerTestData.cpp
#include "TransformerTestData.h"
TableVocab src_vocab =
{
{"Pad",PadId},
{"Welcome",1},
{"to",2},
{"PyTorch",3},
{"Machine",4},
{"Tutorials",5},
{"Learning",6 }
};
TableVocab tgt_vocab =
{
{"Pad",PadId},
{"S",1},
{"E",2},
{"欢",3},
{"迎",4},
{"来",5},
{"到",6},
{"派",7},
{"托",8},
{"奇",9},
{"教",10},
{"程",11},
{"机",12},
{"器",13},
{"学",14},
{"习",15}
};
int64_t src_vocab_size = src_vocab.size();
int64_t tgt_vocab_size = tgt_vocab.size();
std::vector<std::string> Split(const std::string& s)
{
std::vector<std::string> res;
std::stringstream ss(s);
std::string word;
while (ss >> word)
{
res.push_back(word);
}
return res;
}
std::string GetWordById(TableVocab& vocabId, int64_t dataid)
{
std::string Word = { "0" };
for (auto& w : vocabId)
{
if (w.second == dataid)
{
Word = w.first;
break;
}
}
return Word;
}
std::vector<int64_t> GetWordId(TableVocab& vocabId, std::string data)
{
std::vector<int64_t> input;
for (auto ch : Split(data))
{
input.push_back(vocabId.at(ch));
}
return input;
}
WordList GetLoadDataWordId(std::pair<std::string, std::string> data)
{
std::vector<int64_t> input = GetWordId(src_vocab, data.first);
std::vector<int64_t> target = GetWordId(tgt_vocab, data.second);
WordList item;
for (int i = 0; i < input.size() && i < target.size(); i++)
{
item.push_back({ input.at(i),target.at(i) });
}
return item;
}
std::pair<torch::Tensor, torch::Tensor> CreateDecoderInputOutput(torch::Tensor data)
{
auto E = torch::tensor(GetWordId(tgt_vocab, "E"), torch::kLong).view({ 1,1 });
auto S = torch::tensor(GetWordId(tgt_vocab, "S"), torch::kLong).view({ 1,1 });
auto input = torch::cat({ S, data }, 1);
auto output = torch::cat({ data,E }, 1);
return { input ,output };
}
HandwrittenTransformer.cpp
#include <torch/torch.h>
#include <iostream>
#include <torch/serialize.h>
#include <regex>
//#include <iostream>
#include <fstream>
#include "TransformerTestData.h"
using namespace std;
class FeedForwardNetImpl : public torch::nn::Module
{
public:
FeedForwardNetImpl(int64_t dim=512, int64_t dff=2048)
{
ffn = register_module("SeqFFN", torch::nn::Sequential(torch::nn::Linear(dim, dff),
torch::nn::ReLU(),
torch::nn::Linear(dff, dim)
));
}
auto forward(torch::Tensor x)
{
return ffn->forward(x);
}
torch::nn::Sequential ffn{};
};
TORCH_MODULE(FeedForwardNet);
class MultiHeadAttentionImpl : public torch::nn::Module
{
public:
MultiHeadAttentionImpl(int64_t dim, int64_t head)
{
assert(dim % head == 0);
InitQKV(dim, head);
}
//q k v : [seq, batch, dim]
torch::Tensor forward(torch::Tensor& q, torch::Tensor& k, torch::Tensor& v,torch::Tensor mask = {})
{
auto q1 = Q->forward(q);
auto k1 = Q->forward(k);
auto v1 = Q->forward(v);
return ScaledDotProductAttention(q1, k1, v1, mask);
}
private:
void InitQKV(int64_t dim, int64_t head)
{
auto linear = torch::nn::LinearOptions(dim, dim).bias(false);
Q = register_module("q", torch::nn::Linear(linear));
K = register_module("k", torch::nn::Linear(linear));
V = register_module("v", torch::nn::Linear(linear));
Wo = register_module("Wo", torch::nn::Linear(linear)); // 输出投影
norm_fact = 1.0 / sqrt(dim);
Dk = dim / head;
H = head;
}
/// q: [seq, batch, dim]
torch::Tensor ScaledDotProductAttention(torch::Tensor q, torch::Tensor k, torch::Tensor v, torch::Tensor& mask)
{
/// k==v q可以不等于 k v
auto seq = q.size(0);
auto batch = q.size(1);
auto dim = q.size(2);
auto seq2 = k.size(0);
auto batch2 = k.size(1);
auto dim2 = k.size(2);
q = q.view({ seq,batch,H,Dk }); //q: [seq, batch, dim] -> [S, B, H, Dk]
k = k.view({ seq2,batch2,H,Dk });
v = v.view({ seq2,batch2,H,Dk });
q = q.permute({ 1,2,0,3 }); //[S, B, H, Dk] --->[B, H, S, Dk]
k = k.permute({ 1,2,0,3 });
v = v.permute({ 1,2,0,3 });
auto kt = k.permute({ 0,1,3,2 }); //kt: [B, H, S, Dk] --> [B, H, Dk, S]
//cout << "q\n" << q.sizes() << endl;
//cout << "kt\n" << kt.sizes() << endl;
auto attn_score = torch::matmul(q, kt);
attn_score = attn_score * norm_fact;
if (mask.defined())
{
attn_score += mask;
}
attn_score = torch::softmax(attn_score, -1); /// attn_score: [B, H, S, S]
auto out = torch::matmul(attn_score, v); // [B, H, S, S] * [B, H, S, Dk] -> out: [B, H, S, Dk]
out = out.transpose(1, 2).contiguous().view({ seq,batch, dim }); // [B, H, S, Dk] --> [B, S, H, Dk] -> [seq,batch, dim]
//cout <<"out\n" << out.squeeze() << endl;
out = Wo->forward(out);
return out;
}
torch::nn::Linear Q{ nullptr };
torch::nn::Linear K{ nullptr };
torch::nn::Linear V{ nullptr };
torch::nn::Linear Wo{ nullptr };
double norm_fact = 0;
int64_t Dk;
int64_t H;
};
TORCH_MODULE(MultiHeadAttention);
class EncoderLayerImpl : public torch::nn::Module
{
public:
EncoderLayerImpl(int64_t dim, int64_t head, int64_t dff)
{
torch::nn::LayerNormOptions normOpt({ dim });
norm1 = register_module("norm1", torch::nn::LayerNorm(normOpt));
norm2 = register_module("norm2", torch::nn::LayerNorm(normOpt));
ffn = register_module("ffn", FeedForwardNet(dim, dff));
attention = register_module("attention", MultiHeadAttention(dim, head));
}
auto forward(torch::Tensor x)
{
auto y = attention->forward(x,x,x);
y = norm1->forward(x + y); /// 残差连接
auto y2 = ffn->forward(y);
return norm2->forward(y + y2); /// 残差连接
}
FeedForwardNet ffn{ nullptr };
torch::nn::LayerNorm norm1{ nullptr }, norm2{ nullptr };
MultiHeadAttention attention{ nullptr };
};
TORCH_MODULE(EncoderLayer);
class EncodersImpl : public torch::nn::Module
{
public:
EncodersImpl(int64_t dim, int64_t head, int64_t ffn, int64_t layers)
{
moduleLayers = register_module("moduleLayers", torch::nn::ModuleList());
for (int i = 0; i < layers; i++)
{
moduleLayers->push_back(EncoderLayer(dim, head, ffn));
}
}
auto forward(torch::Tensor x)
{
for each(auto& item in *moduleLayers)
{
x = item->as<EncoderLayer>()->forward(x);
}
return x;
}
torch::nn::ModuleList moduleLayers{ nullptr };
};
TORCH_MODULE(Encoders);
class DecoderLayerImpl : public torch::nn::Module
{
public:
DecoderLayerImpl(int64_t dim, int64_t head, int64_t dff)
{
torch::nn::LayerNormOptions normOpt({ dim });
norm1 = register_module("norm1", torch::nn::LayerNorm(normOpt));
norm2 = register_module("norm2", torch::nn::LayerNorm(normOpt));
norm3 = register_module("norm3", torch::nn::LayerNorm(normOpt));
ffn = register_module("ffn", FeedForwardNet(dim, dff));
attention = register_module("attention", MultiHeadAttention(dim, head));
attention2 = register_module("attention2", MultiHeadAttention(dim, head));
}
auto forward(torch::Tensor& tgt, torch::Tensor& memory,torch::Tensor tgtmask)
{
auto y = MaskAttention(tgt, tgtmask);
//cout << "y\n" << y.sizes() << endl;
//cout << "memory\n" << memory.sizes() << endl;
auto y2 = attention2->forward(y, memory, memory);
auto y3 = norm2->forward(y+y2); // 残差连接
auto y4 = ffn->forward(y3);
return norm3->forward(y3 + y4); // 残差连接
}
private:
torch::Tensor MaskAttention(torch::Tensor x, torch::Tensor mask)
{
auto y = attention->forward(x,x,x, mask);
y = norm1->forward(x + y); // 残差连接
return y;
}
public:
FeedForwardNet ffn{ nullptr };
torch::nn::LayerNorm norm1{ nullptr }, norm2{ nullptr }, norm3{ nullptr };
MultiHeadAttention attention{ nullptr };
MultiHeadAttention attention2{ nullptr };
};
TORCH_MODULE(DecoderLayer);
class DecodersImpl : public torch::nn::Module
{
public:
DecodersImpl(int64_t dim, int64_t head, int64_t ffn, int64_t layers)
{
moduleLayers = register_module("moduleLayers2", torch::nn::ModuleList());
for (int i = 0; i < layers; i++)
{
moduleLayers->push_back(DecoderLayer(dim, head, ffn));
}
}
auto forward(torch::Tensor& tgt, torch::Tensor& memory, torch::Tensor tgtmask)
{
for each(auto& item in * moduleLayers)
{
tgt = item->as<DecoderLayer>()->forward(tgt, memory, tgtmask);
}
return tgt;
}
torch::nn::ModuleList moduleLayers{ nullptr };
};
TORCH_MODULE(Decoders);
class MyTransformerImpl : public torch::nn::Module
{
public:
MyTransformerImpl(int64_t dim, int64_t head, int64_t ffn, int64_t layerEncoder, int64_t layerDecoder)
{
src_emb = register_module("src_emb", torch::nn::Embedding(torch::nn::EmbeddingOptions(src_vocab_size, dim)));
tgt_emb_ = register_module("tgt_emb", torch::nn::Embedding(torch::nn::EmbeddingOptions(tgt_vocab_size, dim)));
pos_encoder = register_module("pos_encoder", PositionalEncoding(dim, max_vocab_len));
encoders = register_module("Encoders", Encoders(dim, head, ffn, layerEncoder));
decoders = register_module("Decoders", Decoders(dim, head, ffn, layerDecoder));
fc = register_module("fc", torch::nn::Linear(dim, tgt_vocab_size));
}
torch::Tensor forward(torch::Tensor src, torch::Tensor tgt)
{
auto none_mask = torch::Tensor();
auto tgt_mask = generate_square_subsequent_mask(tgt.size(1));
//[batch, seq] --> [seq, batch]
src = src.permute({ 1,0 });
tgt = tgt.permute({ 1,0 });
//std::cout << "input " << src << std::endl;
src = src_emb->forward(src) * std::sqrt(dim_model);
src = pos_encoder->forward(src);
tgt = tgt_emb_->forward(tgt) * std::sqrt(dim_model);
tgt = pos_encoder->forward(tgt);
return TransformerForward(src, tgt, tgt_mask);
}
torch::Tensor predict(torch::Tensor src)
{
//std::cout << src << std::endl;
auto srcemb = src_emb->forward(src) * std::sqrt(dim_model);
srcemb = pos_encoder->forward(srcemb);
auto memory = encoders->forward(srcemb);
std::vector<int64_t> tgtpad = GetWordId(tgt_vocab, "S");
int i = 0;
while (i < tgt_vocab_size * 2)
{
torch::Tensor tgt = torch::tensor(tgtpad, torch::kLong);
auto tgt_mask = generate_square_subsequent_mask(tgt.size(0));
///std::cout << "tgt_mask " << tgt_mask << std::endl;
auto tgt_emb = tgt_emb_->forward(tgt) * std::sqrt(dim_model);
tgt_emb = pos_encoder->forward(tgt_emb);
auto out = decoders->forward(tgt_emb, memory, tgt_mask);
out = fc->forward(out).squeeze(-2);
auto next_token = out.argmax(-1);
int64_t key = next_token[i].item<int64_t>();
tgtpad.push_back(key);
//tgtpad.insert(tgtpad.begin(), );
if ("E" == GetWordById(tgt_vocab, key))
{
break;
}
i++;
}
return torch::tensor(tgtpad, torch::kLong);
}
private:
torch::Tensor TransformerForward(torch::Tensor& src,torch::Tensor& tgt,torch::Tensor tgtmask)
{
auto outputEncoder = encoders->forward(src);
auto outputDecoder = decoders->forward(tgt, outputEncoder, tgtmask);
return fc->forward(outputDecoder);
}
torch::Tensor generate_square_subsequent_mask(int64_t sz)
{
auto mask = torch::triu(torch::ones({ sz, sz }, torch::kFloat32), 1);
mask = mask.masked_fill(mask == 1, -std::numeric_limits<float>::infinity());
return mask;
}
Encoders encoders{nullptr};
Decoders decoders{nullptr};
torch::nn::Embedding src_emb{ nullptr };
torch::nn::Embedding tgt_emb_{ nullptr };
PositionalEncoding pos_encoder{ nullptr };
torch::nn::Linear fc{ nullptr };
};
TORCH_MODULE(MyTransformer);
void TestData2(MyTransformer& model)
{
model->eval();
std::cout << "测试&翻译:" << std::endl;
std::vector<std::string> tests;
tests.push_back("Welcome");
tests.push_back("Welcome to");
tests.push_back("Welcome to PyTorch");
tests.push_back("Welcome to Machine");
tests.push_back("Welcome to PyTorch Tutorials");
tests.push_back("Welcome to Machine Learning");
tests.push_back("Learning");
tests.push_back("Tutorials");
tests.push_back("PyTorch Tutorials");
tests.push_back("Machine Learning");
for (auto ch : tests)
{
auto item = GetWordId(src_vocab, ch);
auto src = torch::tensor(item, torch::kLong);
auto result = model->predict(src);
// std::cout << std::regex_replace(ch, std::regex("Pad"), "") << " : ";
std::cout << ch << " : ";
for (int k = 0; k < result.numel(); k++)
{
std::cout << GetWordById(tgt_vocab, result[k].item<int64_t>()) << " ";
}
std::cout << std::endl;
}
}
void TrainData2(MyTransformer& model)
{
double accuracy = 0.03;
auto datasetTrain = translatDataset().map(torch::data::transforms::Stack<>());
auto train_data_loader = torch::data::make_data_loader(std::move(datasetTrain), torch::data::DataLoaderOptions().batch_size(1));
auto options = torch::nn::CrossEntropyLossOptions().ignore_index(PadId);
torch::nn::CrossEntropyLoss loss_fn(options);
torch::optim::Adam optimizer(model->parameters(), torch::optim::AdamOptions(1e-3));
model->train();
std::cout << "训练模型" << std::endl;
for (int i = 0; i < max_train; i++)
{
float total_loss = 0;
for (auto& item : *train_data_loader)
{
/// item.data, item.target : [batch, seq]
auto [tgtInput, tgtOutput] = CreateDecoderInputOutput(item.target);
auto tgtOut = model->forward(item.data, tgtInput);
auto output = tgtOut.reshape({ -1, tgt_vocab_size });
optimizer.zero_grad();
auto tgt = tgtOutput.squeeze(0);
auto loss = loss_fn(output, tgt);
total_loss += loss.item<float>();
torch::nn::utils::clip_grad_norm_(model->parameters(), 1.0);
loss.backward();
optimizer.step();
}
if (i % 10 == 0 || (i + 1 == max_train))
{
std::cout << "i: " << i + 1 << " , loss: " << total_loss << std::endl;
}
if (total_loss <= accuracy)
{
std::cout << "i: " << i + 1 << " , loss: " << total_loss << std::endl << std::endl;
break;
}
}
std::cout << std::endl;
}
void HandwrittenTransformerMain()
{
torch::manual_seed(6);
std::string model_path = "MyTransformer_model2.pt";
MyTransformer model(dim_model,2, dim_feed,1,1);
std::ifstream filem(model_path);
bool bmodel = filem.is_open();
if (!bmodel || true)
{
TrainData2(model);
torch::save(model, model_path);
}
else
{
torch::load(model, model_path);
std::cout << "load model ...." << std::endl;
}
filem.close();
TestData2(model);
}感谢大家的支持,如要问题欢迎提问指正。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)