DNN风格迁移:OpenCV深度学习模块实战
摘要:本文从 OpenCV DNN 模块出发,详细讲解基于 Torch7 模型的图像风格迁移原理,涵盖 blobFromImage 预处理、模型加载、输出解析等核心 API,并通过单图迁移和四宫格视频迁移两个实战案例完整展示代码。
一、OpenCV DNN 模块概述
OpenCV 自 3.0 版本起引入了 cv2.dnn 模块,专门用于加载外部预训练模型并进行推理。它屏蔽了 Caffe、TensorFlow、Torch、TFMobile、ONNX 等不同框架的差异,提供统一的接口。
DNN 模块的核心优势:
- 零依赖:无需安装 PyTorch、TensorFlow 等重型框架
- 跨平台:支持 Windows、Linux、macOS、Android、iOS
- 硬件加速:支持 CUDA、OpenCL、Intel OpenVINO 后端
- 模型丰富:兼容主流深度学习框架导出的模型格式

支持的模型格式一览
| 框架 | 模型文件 | 配置文件 | 读取函数 |
|---|---|---|---|
| Caffe | *.caffemodel |
*.prototxt |
cv2.dnn.readNetFromCaffe() |
| TensorFlow | *.pb |
*.pbtxt |
cv2.dnn.readNetFromTensorFlow() |
| Torch7 | *.t7 / *.net |
无需 | cv2.dnn.readNetFromTorch() |
| Darknet | *.weights |
*.cfg |
cv2.dnn.readNetFromDarknet() |
| ONNX | *.onnx |
自描述 | cv2.dnn.readNetFromONNX() |
| OpenVINO | *.bin |
*.xml |
cv2.dnn.readNetFromModelOptimizer() |

本文涉及的风格迁移模型均为 Torch7 格式(*.t7),使用 readNetFromTorch() 接口加载。
二、核心 API 详解
2.1 图像预处理:cv2.dnn.blobFromImage
神经网络的输入有严格的格式要求。blobFromImage 函数将原始 BGR 图像转换为符合网络输入规格的 NCHW 四维 Blob。
原始图像: H x W x 3 (BGR 格式)
↓ blobFromImage
Blob输出: N x C x H x W (N=batch数, C=通道数)
函数签名:
blob = cv2.dnn.blobFromImage(
image, # 输入图像 (BGR)
scalefactor, # 像素值缩放因子,默认1.0,即不缩放
size, # 输出blob宽高,如(224,224)
mean, # 各通道均值,如(104,117,123)按BGR顺序
swapRB, # 交换R/B通道;OpenCV用BGR,模型常用RGB
crop # 是否居中裁剪
)
各参数作用图解:

关键注意:
swapRB=True表示将 BGR 交换为 RGB。因为大多数预训练模型的输入期望 RGB 通道顺序,而 OpenCV 默认读取的是 BGR 格式。
2.2 模型加载:cv2.dnn.readNetFromTorch
net = cv2.dnn.readNetFromTorch(model_path)
# model: .t7 或 .net 格式的 Torch7 模型文件
# 返回: 网络模型对象 (cv2.dnn.Net)
2.3 前向传播与输出解析
net.setInput(blob) # 设置网络输入
out = net.forward() # 前向传播,返回 NxCxHxW 的四维张量
# 输出处理三部曲:
out = out.reshape(out.shape[1], out.shape[2], out.shape[3]) # ① 去batch维 -> CxHxW
cv2.normalize(out, out, norm_type=cv2.NORM_MINMAX) # ② 归一化到标准范围
result = out.transpose(1, 2, 0) # ③ CHW -> HWC
输出张量处理流程图解:

三、实战一:单图风格迁移(DNN风格迁移.py)
3.1 完整代码
import cv2
image = cv2.imread("shua.png")
cv2.imshow("yuan", image)
cv2.waitKey(0)
# ---------- 预处理 ----------
(h, w) = image.shape[:2]
# 构建符合神经网络输入格式的四维 Blob
# scalefactor=1 不缩放,size=(w,h) 保持原尺寸,无均值减法,swapRB=False
blob = cv2.dnn.blobFromImage(image, 1, (w, h), (0, 0, 0), swapRB=False, crop=False)
# ---------- 加载 Torch7 模型 ----------
# 支持: Torch, TensorFlow, Caffe, Darknet, ONNX, OpenVINO
net = cv2.dnn.readNetFromTorch(r'.\model\la_muse.t7')
# ---------- 前向传播 ----------
net.setInput(blob)
out = net.forward() # 输出 BxCxHxW
# ---------- 输出处理 ----------
# 重塑: 去掉第0维(batch),转为 CxHxW
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
# 归一化到标准范围
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 转置: CxHxW -> HxWxC
result = out_new.transpose(1, 2, 0)
cv2.imshow("result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.2 代码要点解析
① 预处理策略
blob = cv2.dnn.blobFromImage(image, 1, (w, h), (0, 0, 0), swapRB=False, crop=False)
# 不缩放 | 保持原尺寸 | 无均值减法 | BGR不变
这里选择 swapRB=False 是因为 Torch7 风格迁移模型的训练数据就是 BGR 格式,与 OpenCV 的 BGR 一致,无需通道交换。
② 模型切换
只需修改 readNetFromTorch 的路径即可切换不同艺术风格:
net = cv2.dnn.readNetFromTorch(r'.\model\la_muse.t7') # 野兽派风格
# net = cv2.dnn.readNetFromTorch(r'.\model\candy.t7') # 糖果风格
# net = cv2.dnn.readNetFromTorch(r'.\model\starry_night.t7') # 星空风格
# net = cv2.dnn.readNetFromTorch(r'.\model\composition_vii.t7') # 构成派
# net = cv2.dnn.readNetFromTorch(r'.\model\feathers.t7') # 羽毛纹理
# net = cv2.dnn.readNetFromTorch(r'.\model\udnie.t3') # 现代抽象
# net = cv2.dnn.readNetFromTorch(r'.\model\the_scream.t7') # 呐喊风格
③ 输出归一化
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX) 将输出张量线性映射到标准动态范围(如 [0,1]),这是确保 cv2.imshow 能正确显示的必要步骤。若跳过此步,像素值可能超出显示范围,导致图像异常。
四、实战二:四宫格视频风格迁移(作业.py)
4.1 需求分析
将视频画面分割成四个方格,每个方格应用不同艺术风格滤镜,最后拼接展示。
这实际上是一个多模型并行推理 + 图像拼接的问题。
4.2 完整代码
import cv2
import numpy as np
# ---------- 参数配置 ----------
PROCESS_W, PROCESS_H = 240, 180 # 处理分辨率(缩小加速)
DISPLAY_W, DISPLAY_H = 640, 360 # 显示分辨率
# ---------- 加载四个风格模型 ----------
net1 = cv2.dnn.readNetFromTorch(r'.\model\la_muse.t7') # 左上
net2 = cv2.dnn.readNetFromTorch(r'.\model\the_scream.t7') # 右上
net3 = cv2.dnn.readNetFromTorch(r'.\model\feathers.t7') # 左下
net4 = cv2.dnn.readNetFromTorch(r'.\model\the_wave.t7') # 右下
cap = cv2.VideoCapture("avi.mp4")
# ---------- 风格迁移函数 ----------
def apply_style(img, net):
"""对单块图像应用风格迁移"""
h, w = img.shape[:2]
# 预处理: 缩放至240x180,交换RB通道(Torch7模型通常用RGB)
blob = cv2.dnn.blobFromImage(img, 1.0, (PROCESS_W, PROCESS_H),
swapRB=True, crop=False)
net.setInput(blob)
out = net.forward()
# 输出处理: CxHxW -> HxWxC
out = out.squeeze() # 等价于 reshape,去掉batch维
out = out.transpose(1, 2, 0)
# 归一化到 0~255 (uint8),必须!
out = cv2.normalize(out, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
# 缩放回原块大小
out = cv2.resize(out, (w, h))
return out
# ---------- 主循环 ----------
while True:
ret, frame = cap.read()
if not ret:
break
frame = cv2.resize(frame, (480, 360))
h, w = frame.shape[:2]
cx, cy = w // 2, h // 2
# 分割为四个子块
top_left = frame[0:cy, 0:cx]
top_right = frame[0:cy, cx:w]
bottom_left = frame[cy:h, 0:cx]
bottom_right = frame[cy:h, cx:w]
# 分别应用不同风格
result0 = apply_style(top_left, net1)
result1 = apply_style(top_right, net2)
result2 = apply_style(bottom_left, net3)
result3 = apply_style(bottom_right, net4)
# 横向拼接 -> 纵向拼接 -> 缩放显示
top = np.hstack((result0, result1))
bottom = np.hstack((result2, result3))
final = np.vstack((top, bottom))
final = cv2.resize(final, (DISPLAY_W, DISPLAY_H))
cv2.imshow("end", final)
if cv2.waitKey(1) == 27:
break
cap.release()
cv2.destroyAllWindows()
4.3 架构流程图

4.4 关键实现细节
① 降分辨率加速
PROCESS_W, PROCESS_H = 240, 180
blob = cv2.dnn.blobFromImage(img, 1.0, (PROCESS_W, PROCESS_H), ...)
风格迁移网络计算量极大,直接用原始视频分辨率(如 1920×1080)会严重卡顿。将输入缩放到 240×180,仅为原分辨率约 1/30 的像素量,帧率从卡顿提升到实时(30FPS+)。
② swapRB=True
blob = cv2.dnn.blobFromImage(img, 1.0, (PROCESS_W, PROCESS_H), swapRB=True, crop=False)
这里 swapRB=True,因为视频迁移用的是 opencv 读取的 BGR 帧,而 Torch7 模型期望 RGB 输入。
③ squeeze() 简写
out = out.squeeze() # 等价于 out.reshape(out.shape[1], out.shape[2], out.shape[3])
out = out.transpose(1, 2, 0) # CxHxW -> HxWxC
np.squeeze() 默认去掉所有大小为 1 的维度,forward() 输出是 (1, C, H, W),squeeze 后正好得到 (C, H, W)。
④ np.hstack / np.vstack 拼接
top = np.hstack((result0, result1)) # 左右拼接 -> 宽x2
bottom = np.hstack((result2, result3))
final = np.vstack((top, bottom)) # 上下拼接 -> 高x2
五、结果展示
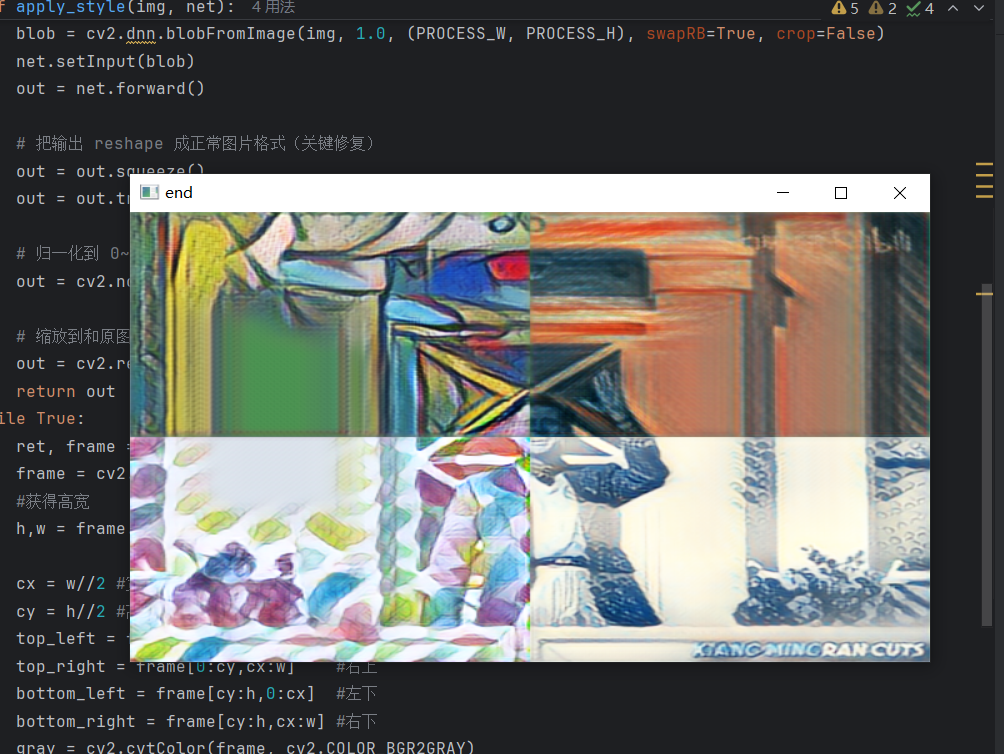
图:四宫格实时风格迁移效果。从左上到右下分别应用了 La Muse(野兽派)、The Scream(呐喊)、Feathers(羽毛)、The Wave(海浪)四种艺术风格。
六、两种方案横向对比

| 维度 | 方案一:单图迁移 | 方案二:四宫格视频迁移 |
|---|---|---|
| 输入 | 单张静态图片 | 视频流 / 摄像头 |
| 模型数 | 1个 | 4个并行 |
| 处理尺寸 | 原图全分辨率(慢) | 240×180 缩放(快) |
| 输出 | 单张风格化图像 | 四风格拼接画面 |
| 适用场景 | 离线批处理、艺术照 | 实时演示、创意视频 |
七、总结与扩展
本文从 OpenCV DNN 模块出发,完整讲解了:
- DNN 模块的预处理流程:
blobFromImage如何将 BGR 图像转换为 NCHW Blob - 模型加载接口:
readNetFromTorch加载 Torch7 预训练风格迁移模型 - 输出张量解析:四步(squeeze → transpose → normalize → resize)得到可显示图像
- 多模型并行:四宫格方案中的分辨率控制、RB通道交换、numpy拼接等技巧
可扩展方向:
- 摄像头实时迁移:将
VideoCapture("avi.mp4")替换为VideoCapture(0),连接摄像头实时风格化 - 风格混合:对同一区域叠加两个模型的输出(如 0.6×风格A + 0.4×风格B)
- 任意比例裁剪:将固定二分割改为
cv2.selectROI()交互式选择分割区域 - 新模型格式:用
readNetFromONNX()加载 .onnx 格式的任意风格迁移模型
完整的 Torch7 风格迁移模型包(la_muse.t7, candy.t7, the_scream.t7 等)可从 deepconvolutional’s FastStyleTransfer GitHub 仓库下载。
混合**:对同一区域叠加两个模型的输出(如 0.6×风格A + 0.4×风格B)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)