RAG跟微调的取舍问题
选择 RAG(检索增强生成) 还是 微调(Fine-tuning),取决于你的应用场景、数据特性、更新频率、成本预算和推理要求。两者并非互斥,很多时候可以互补使用。以下是系统的取舍分析:
一、核心区别一览
| 维度 | RAG | 微调 |
|---|---|---|
| 知识来源 | 外部检索库(向量数据库、搜索引擎) | 模型内部参数 |
| 更新知识 | 即时——只需增删文档,无需重训练 | 需要重新微调,周期长、成本高 |
| 引用来源 | 可以返回原文出处,可解释性强 | 难以追溯答案来源 |
| 幻觉风险 | 较低(答案受检索内容约束) | 较高(可能编造事实) |
| 推理延迟 | 较高(检索+生成两步) | 较低(仅生成) |
| 计算成本(推理) | 额外检索开销 + 生成 | 仅生成 |
| 计算成本(训练/准备) | 几乎为零(仅建索引) | 需要GPU时间和数据 |
| 领域适应性 | 依赖检索库质量 | 通过参数学习领域模式 |
| 典型应用 | 问答、客服、文档分析、事实核查 | 风格迁移、指令遵循、特定格式输出 |
二、何时选择 RAG?
✅ 适合 RAG 的场景:
-
知识频繁更新(如新闻、产品文档、法规政策)—— 微调无法实时跟进。
-
需要引用来源(如法律、医疗、金融领域)—— 答案必须可追溯。
-
处理大量长尾知识(如企业内部所有历史工单、科研论文库)—— 不可能全部存入模型参数。
-
降低幻觉要求高 —— 检索内容作为硬约束。
-
没有足够的训练数据 —— RAG 只需要文档,不需要标注问答对。
-
多租户/个性化知识(如每个用户有自己的文档库)—— 检索层天然隔离。
典型例子:
-
企业知识库问答(员工手册、技术文档)
-
智能客服(产品参数、售后政策)
-
法律/合同审查(必须引用条款)
三、何时选择微调?
✅ 适合微调的场景:
-
改变模型的行为或风格(如将通用模型变成“友好客服”或“正式报告生成器”)。
-
学习特定格式或结构(如生成 JSON、Markdown 表格、特定API参数)。
-
领域内术语/缩写标准化(如医疗、金融领域的专业说法)。
-
减少推理延迟(无法接受检索额外耗时,如实时对话)。
-
隐私/离线需求(模型必须完全本地部署,且不能外传文档到检索库)。
-
已有高质量标注数据(如数千条指令-回答对)。
典型例子:
-
将模型微调成“代码审查助手”输出特定格式的评审意见
-
让模型总是用“尊敬的客户…”开头回复
-
边缘设备上运行的对话模型(无法联网检索)
四、决策流程图(简化版)
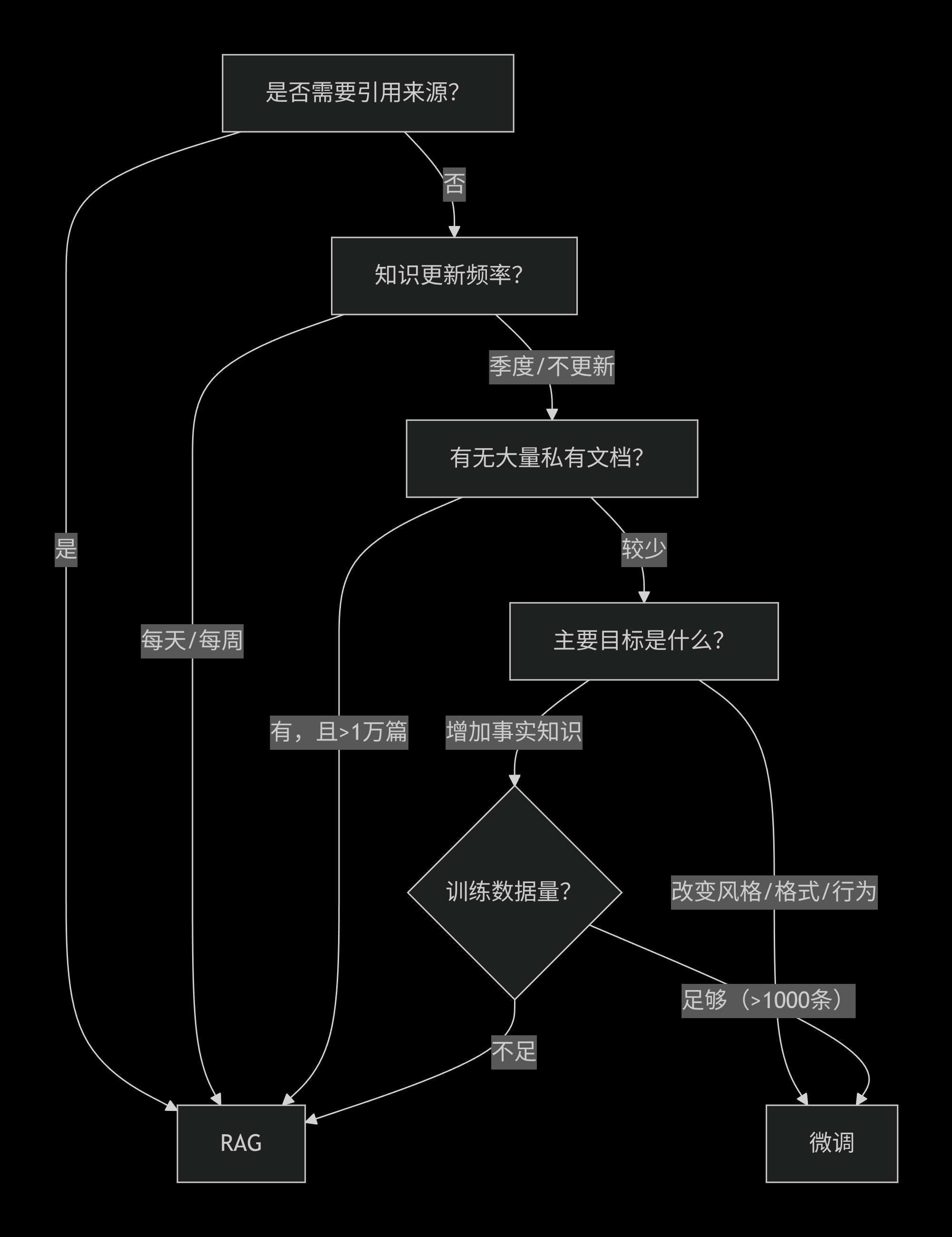
五、两者结合:RAG + 微调
很多生产系统采用混合策略:
-
微调用于指令/风格 + RAG 用于事实知识
-
微调使模型遵循特定回答格式(如“根据文档,答案是…”)
-
RAG 提供最新/私有内容
-
-
微调检索器(而不是生成器)
-
对嵌入模型微调,提升检索相关性
-
-
微调用于拒答/幻觉抑制
-
微调让模型在检索内容不相关时明确说“不知道”
-
典型架构:
用户提问 → RAG 检索相关文档 → 微调后的模型根据文档生成答案(并引用来源)
六、成本与效果对比(真实参考)
| 项目 | RAG | 微调 |
|---|---|---|
| 初始投入 | 低(搭建向量库,可用开源模型) | 中高(需要GPU、数据准备) |
| 维护成本 | 低(定期更新文档即可) | 高(每次知识更新需重训) |
| 效果上限 | 受检索质量限制 | 受数据质量和模型容量限制 |
| 可解释性 | 高(可显示检索片段) | 低(黑盒) |
| 延迟(中等长度) | 检索 100ms + 生成 2s | 生成 1.5s |
七、快速决策清单
优先 RAG 如果:
-
你需要答案来自你提供的特定文档。
-
文档每周都会变化。
-
用户要求看到原文出处。
-
你没有几千条标注好的问答对。
优先微调如果:
-
你需要模型学会某种输出格式或语气。
-
知识相对固定,且不需要引用来源。
-
推理延迟非常敏感(<500ms)。
-
你已有大量高质量的指令-回答数据。
两者都用如果:
-
你既要风格控制又要实时知识 —— 先微调格式,再挂 RAG。
-
检索结果不够精准 —— 微调嵌入模型提升检索。
一句话总结:
用 RAG 注入知识,用微调塑造行为。
如果知识是动态、可检索、需要出处的,选 RAG;如果目标是改变模型的“说话方式”或输出结构,选微调。多数生产级应用建议两者结合。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)