被马斯克点赞的Attention Residuals到底有何魔力?来试试Attention Residuals改进的Vision Transformer !
今天来拜读一下被马斯克点赞的深夜点赞的文章。此文章来自于中国人工智能公司月之暗面(Moonshot AI)的Kimi团队近日发表一篇重磅论文。
论文地址:https://arxiv.org/abs/2603.15031

那么此论文的过人之处在哪里呢?一句话来说:
用可学习的深度注意力替代标准残差连接,让Transformer的每一层都能选择性地聚合所有前序层的特征,从而提升模型的表征能力。
举个通俗易懂的例子就是:
以前的标准做法是:每个专家只看上一个专家留下的笔记,然后加上自己的分析,再传给下一个人。这样有个问题,如果中间有人看漏了,后面的专家都会受影响。
而新方法就像:每个专家在分析的时候,可以直接看到前面所有专家的原始笔记。而且,这个专家还会根据自己的需要,有重点地从这些笔记里挑选最有用的信息,而不是全部照收。
这样做的好处是,每一层都能充分利用前面所有层提取到的信息,不容易丢失关键细节。
本期就将此新算法应用于西储大学故障诊断!来检测一下此算法的威力到底有多大!
基于Attention Residuals改进Vision Transformer的轴承故障诊断方法
一、整体技术路线
整体方案分为三个阶段:
1D振动信号 ──→ 时频变换 ──→ 2D时频图(64×64×3)
│
▼
Vision Transformer + Attention Residuals
│
▼
10类故障分类结果阶段一:信号预处理 —— 将1D振动信号通过时频变换转为2D图像(本项目为了体现模型的鲁棒性,特地对原始信号进行了加噪处理!代码中你可以方便的加任何程度的噪声!)
阶段二:模型构建 —— 搭建基于Attention Residuals改进的Vision Transformer
阶段三:训练与评估 —— 训练模型并通过多种指标全面评估诊断效果
二、数据集与预处理
2.1 数据集
采用经典的CWRU(凯斯西储大学)轴承数据集,包含10种工况:
|
编号 |
类别 |
说明 |
|
0 |
Normal |
正常状态 |
|
1 |
IR007 |
内圈故障,直径0.007英寸 |
|
2 |
B007 |
滚动体故障,直径0.007英寸 |
|
3 |
OR007@6 |
外圈故障,直径0.007英寸 |
|
4 |
IR014 |
内圈故障,直径0.014英寸 |
|
5 |
B014 |
滚动体故障,直径0.014英寸 |
|
6 |
OR014@6 |
外圈故障,直径0.014英寸 |
|
7 |
IR021 |
内圈故障,直径0.021英寸 |
|
8 |
B021 |
滚动体故障,直径0.021英寸 |
|
9 |
OR021@6 |
外圈故障,直径0.021英寸 |
每种工况320个样本,每个样本包含2048个采样点,采样频率12kHz。共3200个样本。
2.2 十种时频变换方法
为了将1D振动信号转化为2D时频图,我们实现了5种时频变换方法(你可以任远一个来测试),它们从不同的数学视角揭示信号的时频结构:
|
序号 |
方法 |
全称 |
核心原理 |
|
1 |
STFT |
短时傅里叶变换 |
滑动窗口分段FFT,最经典的时频分析方法 |
|
2 |
GASF |
Gramian角求和场 |
将信号映射到极坐标系后计算角度求和矩阵 |
|
3 |
GADF |
Gramian角差分场 |
与GASF类似,但计算角度差分矩阵 |
|
4 |
MTF |
Markov转移场 |
将信号分箱后构建转移概率矩阵 |
|
5 |
ST |
S变换 |
结合STFT和CWT的优点,频率自适应高斯窗 |
每种方法的处理流程统一为:
1D信号(2048点) ──→ 时频变换 ──→ 取绝对值 ──→ Resize到64×64 ──→ 归一化[0,1] ──→ 堆叠为3通道RGB(64×64×3)输出的(64, 64, 3) numpy数组保存为.npy文件,可直接输入到Vision Transformer中。
三、Attention Residuals原理详解
这是本文最核心的部分。我们先分析标准Transformer残差连接的问题,再详细介绍Attention Residuals如何解决这些问题。
3.1 标准残差连接的问题
标准Transformer采用PreNorm残差连接:
其中 是第 层的隐藏状态, 是第 层的变换函数(自注意力或FFN)。
这种设计存在两个固有缺陷:
缺陷一:PreNorm稀释问题。 随着网络加深,每一层的输出以权重1不断累加。假设有L层,第1层的特征 的最终贡献被稀释为 。层数越多,浅层特征的相对贡献越小——即使浅层特征对最终任务很重要,也会被深层的累加"淹没"。
缺陷二:均匀深度混合问题。 每一层只能直接访问上一层的输出 。如果第6层需要第1层提取的低级纹理特征,信息必须经过第2~5层层层传递,容易在传递过程中衰减甚至丢失。
3.2 Attention Residuals核心思想
Attention Residuals用可学习的深度注意力替代固定的残差连接:
其中注意力权重为:
各符号含义:
-
• :第 层的输出。 是初始embedding, 是第 层变换函数的输出。
-
• :第 层的伪查询向量(pseudo-query),是可学习参数。
-
• :对源向量做归一化,防止某些层因数值大而主导注意力。
-
• :对所有源层维度做归一化,产生概率分布。
直觉理解: 标准残差像"接力赛",信息只能一棒一棒往下传;而Attention Residuals像"开会",每一层可以直接"听取"所有前序层的汇报,并自主决定重点关注哪些层的信息。
3.3 三个关键设计细节
设计一:伪查询零初始化。 初始化为全零向量。此时所有logits为0,softmax输出均匀分布 ,即训练开始时每一层均匀地聚合所有前序层输出——等价于简单平均。随着训练推进,模型逐渐学会对不同层赋予不同的权重。这避免了训练初期的随机路由偏差。
设计二:RMSNorm归一化。 对每个源向量 做RMS归一化后再计算注意力logits。这保证注意力权重反映的是方向上的语义相似性,而非数值大小。否则,数值较大的层会不公平地主导注意力权重。
设计三:Attention和MLP子层各自独立的伪查询。 每个Transformer block中,自注意力子层和FFN子层各有一个独立的 ,可以学习不同的深度路由策略。自注意力可能更关注浅层的空间结构信息,而FFN可能更需要深层的高级语义特征。
3.4 前向传播过程
以一个6层的Transformer为例,完整的前向传播如下:
初始化: v_0 = PatchEmbedding(输入图像)
layer_outputs = [v_0]
Block 1:
├─ Attention子层:
│ h = AttnRes(layer_outputs, w_1^attn) # 深度注意力聚合
│ v_1 = SelfAttention(RMSNorm(h)) # 自注意力变换
│ layer_outputs = [v_0, v_1] # 列表增长
│
└─ MLP子层:
h = AttnRes(layer_outputs, w_1^mlp) # 深度注意力聚合(已包含v_1)
v_2 = MLP(RMSNorm(h)) # FFN变换
layer_outputs = [v_0, v_1, v_2] # 列表增长
Block 2:
├─ h = AttnRes([v_0, v_1, v_2], w_2^attn) # 可以看到所有前序层
│ v_3 = SelfAttention(RMSNorm(h))
│ layer_outputs = [v_0, v_1, v_2, v_3]
...
Block 6:
└─ ...
layer_outputs = [v_0, v_1, ..., v_12] # 最终有13个源向量
输出: h = RMSNorm(h_last)
分类 = ClassificationHead(h[:, 0]) # 取CLS token每经过一个block,layer_outputs列表增加2个元素(attention输出 + MLP输出)。最终6个block共产生12个子层输出加上初始embedding共13个源向量,最后一个block可以从这13个源中选择性聚合信息。
3.5 与标准Transformer的对比
|
特性 |
标准Transformer |
Attention Residuals |
|
残差连接 |
固定权重1,只看上一层 |
可学习softmax权重,看所有前序层 |
|
深层访问浅层特征 |
间接传递,逐层衰减 |
直接访问,无衰减 |
|
梯度流 |
深层梯度衰减 |
均匀分布,训练更稳定 |
|
额外参数 |
无 |
每子层一个 (极少量) |
|
额外内存 |
无 |
O(L·d),存储所有层输出 |
Attention Residuals的额外参数量极少。以本项目为例,hidden_dim=256,6个block×2个子层=12个伪查询,额外参数仅 个,占总参数量的不到0.1%。
四、模型架构:Vision Transformer + Attention Residuals
我们将Attention Residuals与Vision Transformer结合,构建了适用于时频图分类的故障诊断模型。
4.1 整体架构
输入: 时频图 [B, 3, 64, 64]
│
▼
┌─────────────────────┐
│ Patch Embedding │ Conv2d(3, 256, kernel=8, stride=8)
│ 8×8 patch → 64块 │ 输出: [B, 64, 256]
└─────────────────────┘
│
▼
┌─────────────────────┐
│ + CLS Token │ 可学习的分类token
│ + Position Embed │ 可学习的位置编码
│ + Dropout(0.1) │ 输出: [B, 65, 256]
└─────────────────────┘
│
▼
┌─────────────────────┐
│ Transformer Block │ ×6层
│ ┌─ AttnRes ────┐ │ 深度注意力聚合所有前序层
│ │ RMSNorm │ │
│ │ Self-Attn │ │ 4头双向自注意力
│ ├─ AttnRes ────┤ │ 深度注意力聚合(含本层attn输出)
│ │ RMSNorm │ │
│ │ MLP(4x) │ │ 256→1024→256, GELU激活
│ └───────────────┘ │
└─────────────────────┘
│
▼
┌─────────────────────┐
│ RMSNorm │
│ 取CLS Token [B,256] │
│ Linear → GELU │
│ Linear → 10类 │
└─────────────────────┘
│
▼
输出: [B, 10] 故障分类logits4.2 关键超参数
|
超参数 |
值 |
说明 |
|
Patch Size |
8×8 |
64/8=8,每边8个patch,共64个 |
|
Hidden Dim |
256 |
Transformer隐藏维度 |
|
Num Layers |
6 |
Transformer block数量 |
|
Num Heads |
4 |
多头注意力头数,每头64维 |
|
MLP Expand |
4 |
FFN扩展倍数,256→1024→256 |
|
Dropout |
0.1 |
各处Dropout比率 |
|
总参数量 |
约486万 |
其中AttnRes额外参数仅3072个 |
4.3 对照实验设计
为了验证Attention Residuals的改进效果,设计了两个模型进行对比:
-
• ViT-Standard:标准Vision Transformer,使用PreNorm + 固定残差连接,作为基线模型。
-
• ViT-FullAttnRes:用Attention Residuals替代标准残差连接的改进模型。
两个模型除了残差连接方式不同之外,其余结构(patch embedding、注意力、FFN、分类头)完全一致,确保对比实验的公平性。
4.4 实验结果
为了验证Attention Residuals的改进效果,设计了两个模型进行对比:
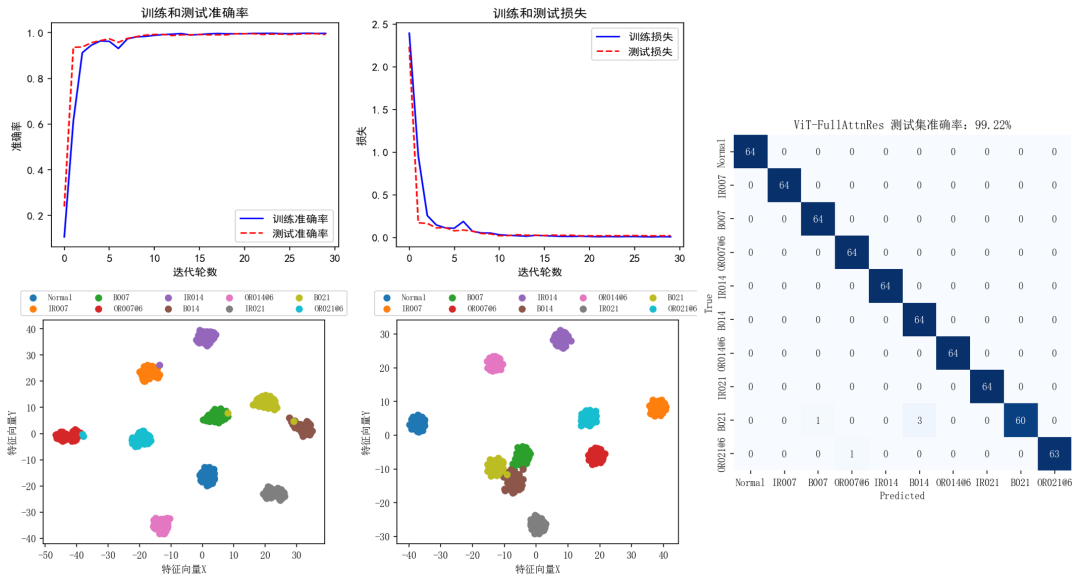
ST_ViT-FullAttnRes :
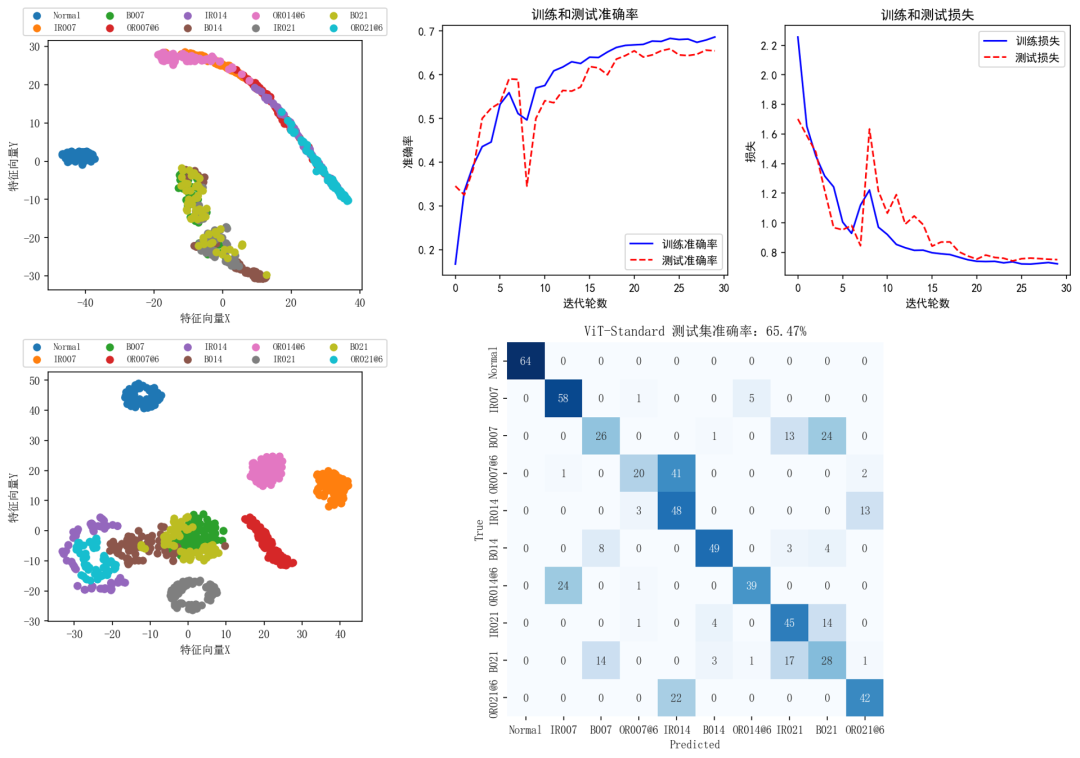
ST_ViT-Standard:
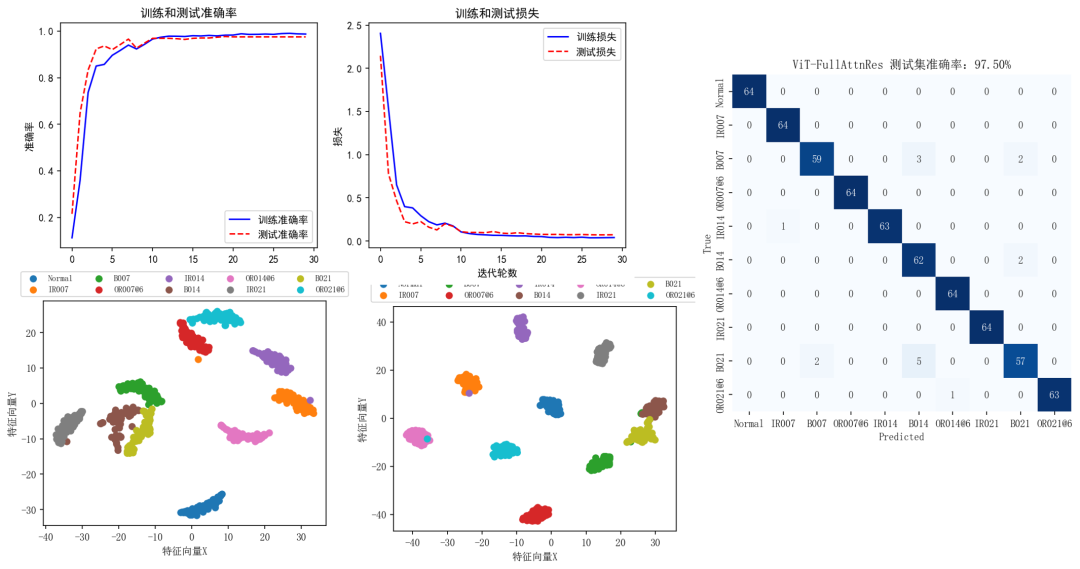
MTF_ViT-FullAttnRes:
MTF_ViT-Standard:
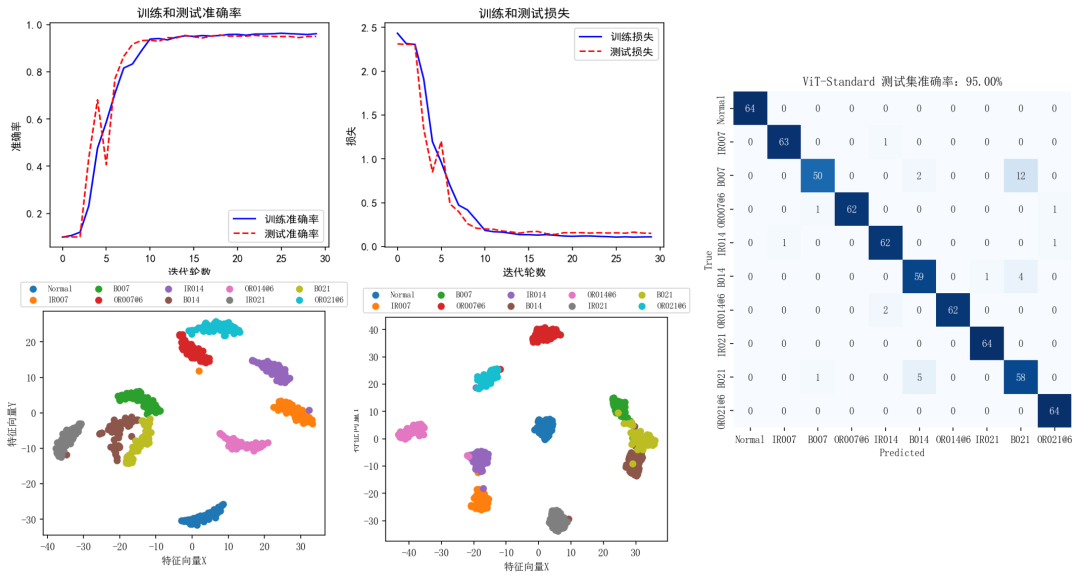
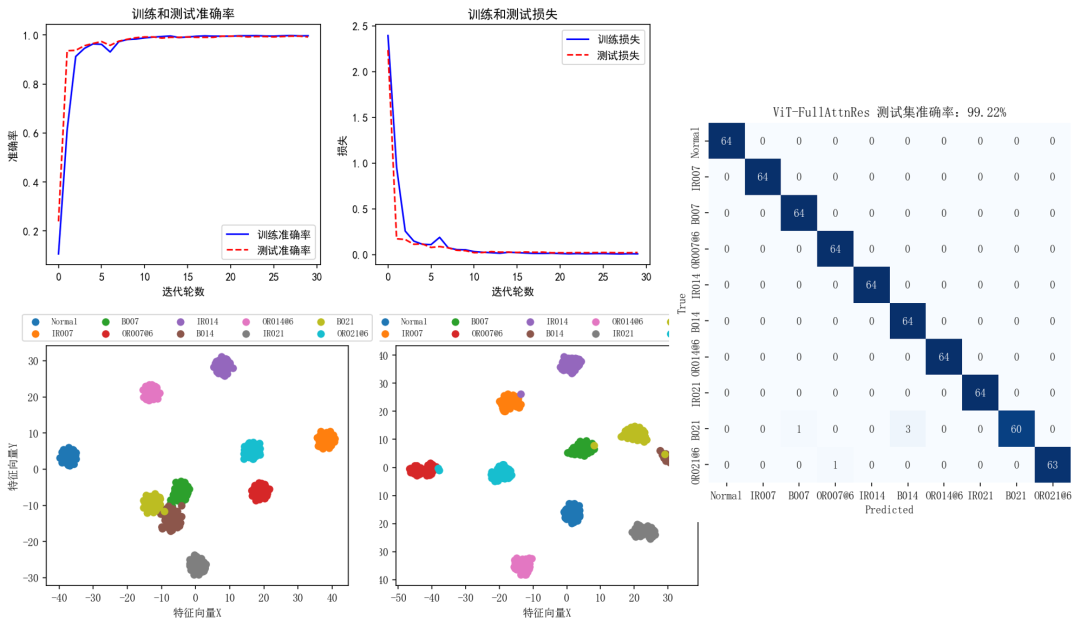
GADF_ViT-FullAttnRes
GADF_ViT-Standard:
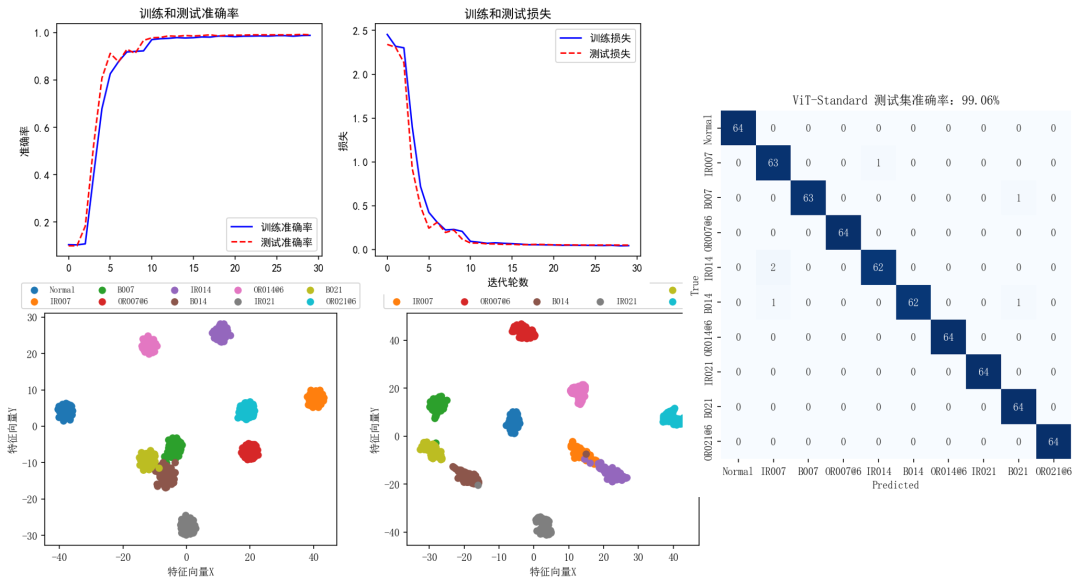
还有关于STFT和GASF的两个结果也很不错,这里就不再一一展示了。
需要注意:这里所有的结果都是在对西储大学数据加完噪声后的辨识结果。
整体来看用Attention Residuals替代标准残差连接的改进模型要比标准残差连接的Transformer模型要强一些。
五、代码结构与运行流程
5.1 项目目录

本项目可以自动生成准确率曲线对比、损失曲线对比、综合指标柱状图(Accuracy/Precision/Recall/F1/Kappa)以及各类别F1对比图。以其中一个结果为例,看一下结果文件夹都有啥:

六、总结
本文将Kimi团队提出的Attention Residuals方法应用于轴承故障诊断领域,主要贡献包括:
-
1. 方法创新:用可学习的深度注意力替代Vision Transformer中固定的残差连接,使模型能够自适应地聚合不同深度层次的特征表示,更好地捕捉振动信号时频图中的多尺度故障特征。
-
2. 系统化实验框架:构建了10种时频变换×2种模型的对比实验体系,可以全面评估Attention Residuals在不同输入表示下的诊断效果。
-
3. 完整工程实现:提供了从原始振动信号到最终诊断结果的完整pipeline,包括数据预处理、模型训练、结果可视化、多模型对比等功能,一键即可运行全部实验。
整理不易,点击下方阅读原文,或者跳转代码获取链接:
点击下方卡片获取

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)