【世界模型】OpenWorldLib: A Unified Codebase and Definition of Advanced World Models

标题:OpenWorldLib:高级世界模型的统一代码库与定义
源代码:https://github.com/OpenDCAI/OpenWorldLib
文档:https://wcny4qa9krto.feishu.cn/wiki/XtPJwf5XQipP7RkeVv0ckyWlnNd
arXiv:https://arxiv.org/pdf/2604.04707
摘要
世界模型作为人工智能领域极具前景的研究方向已获得广泛关注,但其仍缺乏清晰统一的定义。本文提出OpenWorldLib,这是一个面向高级世界模型的全面、标准化推理框架。基于世界模型的发展历程,本文给出明确的定义:世界模型是以感知为核心,具备交互与长期记忆能力,用于理解和预测复杂世界的模型或框架。本文进一步系统梳理了世界模型的核心能力维度。基于该定义,OpenWorldLib将不同任务的模型整合至统一框架中,实现高效复用与协同推理。最后,本文对世界模型研究的潜在未来方向进行了补充思考与分析。
1 引言

图1 OpenWorldLib总体架构。本文提出的OpenWorldLib为现有世界模型相关任务构建了统一框架,涵盖物理世界输入的感知、理解、记忆与生成。
随着大语言模型(LLMs)与智能体(Agents)的逐步发展,模型迫切需要从虚拟场景应用转向真实世界落地。由此,世界模型开始进入大众视野,研究者愈发关注大模型在物理世界中的运行能力,而非局限于虚拟环境。
世界模型的概念最初由[40]提出,后续研究[5,12,42]将视频生成、三维生成等帧预测任务视为世界建模的形式。随着领域发展,后续研究探索了世界模型的应用场景,大量综述[11,26,30,32,46,47,58,70,82,88,91,120,131,145,146,148,167]与立场论文[10,59,137,139,152]对其进行了总结与分析。尽管已有诸多研究,世界模型的定义与范畴仍众说纷纭,尚未形成广泛认可的共识。
为给出世界模型的标准化定义,需从其核心目标出发:持续从真实世界学习并与之交互的能力。据此,本文将世界模型定义为:以从感知构建内部表征为核心,具备动作条件化仿真与长期记忆能力,用于理解和预测复杂世界动态的模型或框架。正如[152]所述,世界模型不依附于特定任务或架构,而是代表模型或框架应实现的能力层级,即感知、交互并记忆复杂世界的能力。
本文主要界定了哪些任务属于世界模型应具备的能力范畴,以及哪些任务常被误判为世界模型的目标能力。此外,由于世界模型需要多样化的能力支撑,亟需更系统化的调用方式。为此,本文构建了OpenWorldLib这一统一的世界模型推理框架,将交互式视频生成、三维生成、多模态推理、视觉-语言-动作(VLA)等任务的调用标准化至单一框架内。
本文主要贡献如下:
- 贡献1:给出世界模型的标准化定义,明确哪些任务应纳入世界模型的能力范畴。
- 贡献2:提出OpenWorldLib统一世界模型推理框架,助力该领域研究的体系化与标准化。
- 贡献3:对世界模型的未来发展方向展开进一步分析与探讨。
2 背景与相关工作
世界模型[40,41]通常由三个核心条件概率分布定义:
状态转移模型: p ( s t + 1 ∣ s t , a t ) 观测模型: p ( o t ∣ s t ) 奖励模型: r t ∼ p ( r t ∣ s t , a t ) \begin{array} {ll} \text{状态转移模型:} & p\left( s_{t+1} | s_{t}, a_{t}\right) \\ \text{观测模型:} & p\left( o_{t} | s_{t}\right) \\ \text{奖励模型:}& r_t \sim p(r_t | s_t, a_t) \end{array} 状态转移模型:观测模型:奖励模型:p(st+1∣st,at)p(ot∣st)rt∼p(rt∣st,at)
其中, s t s_t st表示隐状态,其内在包含记忆存储模块,用于管理复杂任务的长时依赖; a t a_t at表示时间步 t t t的动作,动作空间已拓展至涵盖多样化操作与生成、操控等任务专属输出; o t o_t ot表示感知观测(如视觉、音频、本体感受); r t r_t rt表示动作与环境交互获得的奖励。
尽管上述公式被广泛使用,许多形式上满足该条件概率分布的任务,并未真正服务于世界模型的核心目标,却常被混淆或泛化为世界模型研究。因此,本节结合前人研究定义与本文观点,明确划分哪些任务属于真正的世界模型研究范畴,哪些不属于。
2.1 世界模型相关任务
交互式视频生成。帧预测被世界模型研究者广泛视为最公认的范式[40],这使得交互式视频生成成为该领域的核心研究方向。早期方法主要基于回归模型[40,42,93,134]预测后续帧。近年来,领域转向利用扩散模型[44,48]实现更高质量的交互式视频生成,统一多模态方法[23,61,129,135,136]进一步提升了生成保真度与可控性。随着扩散模型推理速度的加快,游戏视频生成[65,111,138]与相机控制视频生成[6,92]成为备受关注的研究热点。此外,视频预测范式已成功融入视觉-语言-动作(VLA)模型[13,53,117]与自动驾驶系统[45,104,153]。通过融入帧预测估计,这些模型的预测稳定性与鲁棒性显著提升。尽管交互式视频生成仍是当前世界模型研究的基石,但需注意帧预测并非唯一实现范式。考虑到世界模型的最终目标是在复杂环境中实现长时交互,探索替代或互补的表征范式同样至关重要[137]。
多模态推理。世界模型的核心能力之一是对复杂物理世界的深度理解,因此多模态推理是衡量世界模型能力的关键指标。与世界模型密切相关的多模态推理任务不仅包括空间推理[17,24,33,64,94,105,108,133,142]与全模态推理[3,18,19,27,50,84,109,132,140,141,163,165],还涵盖时序推理[14,72,73,98,100]与因果推理[31,56]。近期,除传统显式推理方法外,利用隐式推理[5,126]分析真实世界复杂动态成为研究热点。通过脱离大语言模型(LLMs)传统的以文本为中心的预训练范式,隐式推理机制使模型能更高效地摄取与处理真实世界固有的复杂、高维、连续信息。
视觉-语言-动作。世界模型的最终目标是让智能体与物理世界交互,具身设备是与复杂环境交互的核心载体。因此,视觉-语言-动作(VLA)成为世界模型必须支持的关键能力。在机械臂操控领域,近期研究主要遵循两条技术路线:利用多模态大语言模型(MLLMs)直接预测动作[5,13,16,34,53,83,113,117,154],或将动作预测与视频生成结合[2,20,67,95,114,130],通过未来帧预测实现动作规划。此外,该VLA范式正广泛应用于更复杂的具身场景,包括动力学高度复杂难控的移动机器人[49,62],以及环境范围极广的自动驾驶系统[45,60,69,104,127,155,158,159,168],推动模型在真实世界的闭环交互能力发展。
2.2 三维与仿真器在世界模型中的作用
除依赖直接可观测感知的任务外,世界模型的核心部分还包括虚拟环境处理。为保障长时交互中物理空间的一致性,研究者常借助仿真器让模型进行结构化学习。交互式视频生成是对未来的视觉猜测,而三维表征则提供可验证的环境,让物理规则得以严格遵循[63,68,85,89,118,122,143,150,151,160]。
在此背景下,三维生成与重建是维持稳定世界状态的核心环节。近期研究如VGGT[123]、InfiniteVGGT[147]与OmniVGGT[103]采用视觉几何基础Transformer,将图像输入与真实几何结构关联。为处理来自真实世界的连续数据,部分模型现已支持持久化三维状态[125]或利用混合记忆实现长上下文重建[156],确保智能体移动时环境保持一致。此外,度量三维重建[55]、深度估计[81]与大视角合成[54]等新方法,使世界模型能从任意相机角度恢复精确的物理空间。通过学习置换等变视觉几何[128],这些模型能更好地适配不同类型的物理场景。
此外,仿真器作为世界模型的“沙盒”,助力模型从抽象思维落地为真实物理动作。此类仿真器要实现实时运行,需具备快速场景生成能力。例如FlashWorld[71]与混元系列[52,115,144,162]能在极短时间内生成高质量三维场景或资产,为世界模型提供即时的思路验证环境。近期研究还探索了强化学习在这些三维生成过程中的潜力[112]。借助这些显式三维表征与仿真工具,世界模型可超越像素预测层面,真正理解真实世界的物理规则。
2.3 非世界模型范畴的方法
除世界模型相关任务外,部分应用并未真正体现世界模型的能力,却常出现在同类讨论中。基于世界模型的公式与本文特定定义,本节明确哪些任务不属于该范畴。
此类认知误区的典型案例是文本生成视频。Sora发布时,许多人将其标注为“世界模拟器”。然而[167]指出,Sora并非完整的世界模拟器。尽管帧预测常与世界模型关联,但本文定义强调,核心不在于输出格式,而在于模型是否利用多模态输入分析与认知环境。帧预测仅为一种格式,真正关键的是模型能否精准理解复杂物理规则并与世界交互。文本生成视频缺乏此类复杂感知输入,即便生成视频体现了一定的物理理解能力,仍不属于世界模型的核心任务。
同理,代码生成、网络搜索[22,29]等任务借用了世界模型的长时交互结构应用于其他领域,但这类任务通常缺乏多模态输入,不涉及物理世界理解。尽管将该结构应用于新领域是有趣的探索方向,但此类任务不属于真正的世界模型。
即便涉及多模态[28]与长时交互的应用,如虚拟人视频生成[38,51,149],也未必符合定义。这类任务主要聚焦于娱乐场景,与探索、理解复杂物理世界关联甚微,因此并非世界模型的核心研究方向。
3 OpenWorldLib框架设计
基于第2节内容,世界模型需具备以下能力:接收复杂物理世界的输入、理解物理世界、在交互过程中维持长期记忆、支持多模态输出。尽管[152]提出了统一世界模型框架的设计思路,但该工作缺乏具体的工程实现,甚至未形成统一标准。本节详细阐述OpenWorldLib框架的具体设计,如图2所示。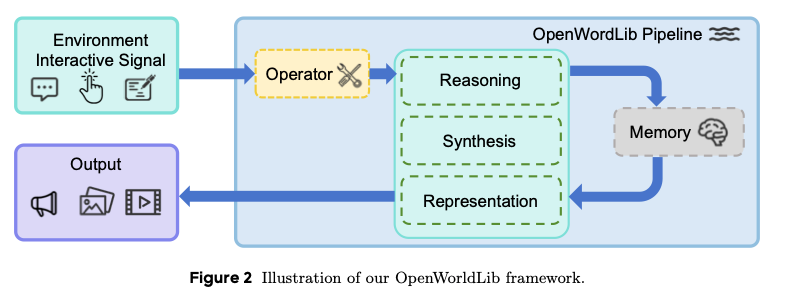
图2 OpenWorldLib框架的示意图。
OpenWorldLib流水线:环境、交互信号、算子、推理、记忆、合成、输出、表征
3.1 Operator
在OpenWorldLib框架中,算子(Operator) 模块是原始用户输入(或环境信号)与核心执行模块(合成、推理、表征)之间的关键桥梁。由于世界模型必须处理来自物理世界的复杂多模态输入(如文本提示、图像、连续控制动作、音频信号),算子模块被设计为对这些多样化数据流进行标准化处理。
具体而言,当流水线被调用时,原始输入会通过算子的process()方法进行路由。算子模块承担两大核心功能:
- 校验:确保输入数据的格式、形状与类型满足下游模型的要求。
- 预处理:将原始信号转换为标准化张量表征或结构化格式(如图像缩放、文本分词、动作空间归一化)。
为便于集成新的世界模型方法,本文定义了统一的算子模板。所有任务专属算子均继承自该基类,确保整个代码库的应用程序接口(API)保持一致。算子的定义如代码清单1所示。
from typing import Any, Dict, Union
class BaseOperator(object):
def __init__(self):
self.current_interaction = []
self.interaction_template = []
def get_interaction(self, interaction_list):
for act in interaction_list:
self.check_interaction(act)
self.current_interaction.append(interaction_list)
def check_interaction(self, interaction):
if interaction not in self.interaction_template:
raise ValueError(f"{interaction} not in template")
return True
def process_interaction(self):
raise NotImplementedError("子类必须实现process_interaction()方法。")
def process_perception(self):
raise NotImplementedError("子类必须实现process_perception()方法。")
代码清单1 OpenWorldLib中基础算子的模板定义
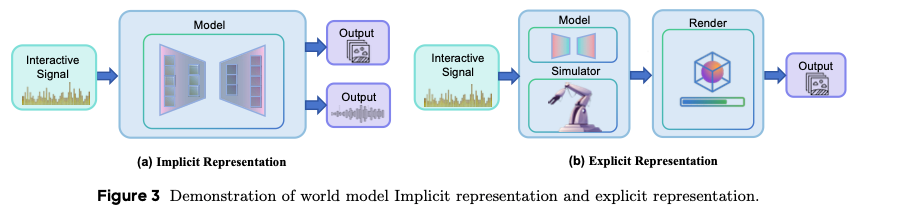
图3 世界模型隐式表征与显式表征示意图
3.2 合成模块
如图3隐式表征部分所示,世界模型的核心能力之一是利用内部学习到的动态特性,生成视觉、听觉等感官结果作为环境反馈。本文将这一隐式生成过程定义为模型的隐式表征。在OpenWorldLib框架中,合成(Synthesis) 模块是上游流水线标准化条件与用户、仿真器或机器人系统实际使用的多模态输出(视觉、听觉、具身)之间的生成桥梁。由于世界模型不仅要将预测转化为内部状态,还要转化为可观测的媒体与可执行指令,合成模块承载异构生成后端,同时保持跨模态的一致集成模式。
具体而言,当流水线运行生成路径时,会将经算子对齐的输入传递至对应合成后端,该后端在模态专属控制下执行推理,并返回结构化成果与简洁元数据,用于导出、评估或记忆存储。以下小节按视觉、音频与其他物理信号合成分支展开该模块的细节。
import torch
class BaseSynthesis(object):
def __init__(self):
"""
初始化合成模型,包括推理组件、辅助模块与处理工具。
"""
pass
@classmethod
def from_pretrained(cls, pretrained_model_path, args, device=None, **kwargs):
"""
加载预训练模型权重,返回可直接推理的合成实例。
"""
pass
def api_init(self, api_key, endpoint):
"""
为基于云的合成服务初始化API密钥与访问端点。
"""
pass
@torch.no_grad()
def predict(self):
"""
运行模型推理,生成图像、视频帧或其他合成媒体等输出结果。
"""
pass
代码清单2 OpenWorldLib中视觉(及其他生成)后端的基础合成模板定义
3.2.1 视觉合成
视觉合成层覆盖OpenWorldLib中面向图像与视频的生成任务:它将文本提示、参考图像、场景级规格等结构化条件转换为栅格输出(帧张量、解码片段或API返回成果),并附带元数据用于导出、评估或可选的记忆挂钩。通过这种方式,框架可提供场景随时间演变的可视化预测,这对于交互式仿真、定性检查以及快速对比不同未来状态或相机路径至关重要。当视觉证据需要与文本或控制信号配套时,这些输出也为多模态叙事与数据集式记录提供支撑。
在实际应用中,视觉合成层承担以下职责:
- 生成栈组合:将文本编码器、隐式解码器、基于扩散或流的核心模型与适配各任务的调度器/求解器相结合,并开放空间分辨率、时间跨度(帧预算)、引导风格等参数调节接口。
- 集成接口:支持基于检查点的流水线(从预训练资源统一构建、无梯度推理)与通过端点与凭证认证的托管服务封装,让本地与远程生成器共享统一的调用逻辑。
3.2.2 音频合成
音频合成层聚焦于结构化条件下的连续波形生成,常用条件包括文本、可选的视频衍生特征、时序或批次元数据,返回带采样率的波形与紧凑的结果记录,用于下游存储或指标计算。其作用是提供多模态输出的听觉部分,让场景不再局限于无声视频或纯文本反馈,这对于高感知丰富度环境与判断音画对齐至关重要[39]。
具体而言,音频合成层实现以下功能:
- 资源组装:通过单一工厂式入口,从预训练资源实例化神经音频生成器与任意辅助模块(如特征编码器),并明确设置设备与可复现性相关参数。
- 条件化波形合成:将经算子预处理的张量与提示映射为音频输出,提供统一推理入口,开放时长、随机种子、引导强度、采样步数预算等用户可控参数。
3.2.3 其他信号合成
除视觉与音频模态外,与环境的全面交互要求世界模型生成多样化的物理信号。其中,动作控制尤为关键,它是具身智能体主动操控物理世界的基础机制。因此,OpenWorldLib在该模块中重点支持视觉-语言-动作(VLA)信号生成。该合成层专为具身任务设计,实现以下功能:
- 策略初始化与空间对齐:从预训练权重加载专用物理策略(如VLA基础模型),并将离散类语言令牌、连续运动学状态等多样化动作表征,映射为适配目标仿真器或机器人硬件的统一接口。
- 上下文条件化动作合成:将丰富的多模态上下文(如实时视觉流、文本目标、本体感受历史)转换为落地的物理指令,模块输出可执行动作序列与核心控制元数据,驱动闭环环境交互。
3.3 推理模块
如图3隐式表征部分所示,世界模型必须超越单纯感知,实现对物理世界的理解:在下游生成或动作执行前,推断空间关系、整合多模态上下文、生成落地的语义解读。为满足这一需求,OpenWorldLib设计了专用的推理(Reasoning) 模块,为世界模型配备复杂物理推理所需的结构化理解能力。具体而言,推理模块分为三个子类别,对应世界模型必须处理的不同感知通道:
- 通用推理:能够统一处理文本、图像、音频、视频的多模态大语言模型(MLLMs)。
- 空间推理:专门从视觉观测中实现三维空间理解与目标定位的模型。
- 音频推理:对音频信号进行解读与推理的模型。
为便于集成新的面向推理的世界模型方法,本文定义了统一的BaseReasoning模板。所有任务专属推理类均继承自该基类,确保整个代码库的API保持一致。BaseReasoning的定义如代码清单3所示。
import torch
class BaseReasoning(object):
def __init__(self):
"""
初始化推理模型,为通用、空间或音频推理配备结构化理解能力。
"""
pass
@classmethod
def from_pretrained(cls, pretrained_model_path, device=None, **kwargs):
"""
加载预训练模型权重,返回可直接推理的推理实例。
"""
pass
def api_init(self, api_key, endpoint):
"""
为基于云的推理服务初始化API密钥与访问端点。
"""
pass
@torch.no_grad()
def inference(self):
"""
运行模型推理,整合多模态上下文、推断空间关系、生成落地的语义解读。
"""
pass
代码清单3 OpenWorldLib中基础推理模块的模板定义
3.4 表征模块
除利用内部能力理解世界的模型外,部分研究旨在构建人工定义的仿真器(如三维网格),这些仿真器为世界模型框架提供可测试的环境。由于这些结构化表征与可直接从世界采集的感知数据不同,本文将表征(Representation) 模块与合成模块分开设计,专门处理三维结构等显式表征。
具体而言,表征模块旨在弥合原始感知与结构化仿真之间的鸿沟,主要功能包括:
- 三维重建:将输入数据转换为显式三维输出,提供点云、深度图、相机位姿等结构化信息。
- 仿真支持:创建人工环境,让世界模型在坐标系中测试推理结果、验证预测动作的正确性。
- 服务集成:支持本地推理与云API,协助将这些显式表征导出至外部物理引擎。
为标准化这些模型的使用方式,本文提供统一的BaseRepresentation模板。所有任务专属表征类均继承自该基类,确保API一致。BaseRepresentation的定义如代码清单4所示。
class BaseRepresentation(object):
def __init__(self):
"""
初始化表征模型,包括架构设置、设备部署与数据类型配置。
"""
pass
@classmethod
def from_pretrained(cls, pretrained_model_path, device=None, **kwargs):
"""
加载预训练模型权重,返回可直接推理的实例。
"""
pass
def api_init(self, api_key, endpoint):
"""
为基于云的模型服务初始化API密钥与访问端点。
"""
pass
@torch.no_grad()
def get_representation(self, data):
"""
运行模型推理,生成点、深度图、相机位姿或掩码等三维输出。
"""
pass
代码清单4 OpenWorldLib中基础表征模块的模板定义
3.5 记忆模块
长期上下文记忆是交互式世界模型维持历史观测、推理链与交互状态的核心需求。OpenWorldLib设计了统一的记忆(Memory) 模块,用于管理多模态交互历史。
记忆模块是框架的持久化状态中心,记录来自感知、推理、生成与动作的结构化信息,并为多轮交互任务提供高效的上下文检索。具体而言,记忆模块实现以下功能:
- 历史存储:存储跨交互的文本、视觉特征、动作轨迹与场景状态。
- 上下文检索:选取相关历史,支持一致的推理与生成。
- 状态更新:每次流水线执行后记录新的交互结果。
- 会话管理:支持不同任务与会话的独立记忆。
为统一记忆管理,本文定义了统一的BaseMemory模板,所有任务专属记忆类均继承自该基类。BaseMemory的定义如代码清单5所示。
class BaseMemory(object):
"""通用多模态记忆系统模板"""
def __init__(self, capacity=None, **kwargs):
"""初始化记忆存储结构"""
self.storage = []
def record(self, data, metadata=None, **kwargs):
"""将当前交互数据与元数据存入记忆"""
pass
def select(self, context_query, **kwargs):
"""根据当前上下文检索相关记忆"""
pass
def compress(self, memory_items, **kwargs):
"""压缩与精炼记忆,减少冗余"""
pass
def manage(self, **kwargs):
"""管理记忆生命周期:更新、合并或清理过期数据"""
pass
代码清单5 OpenWorldLib中基础记忆模块的模板定义
3.6 流水线
为将算子、推理、合成、表征与记忆模块集成为连贯可用的系统,OpenWorldLib提供统一的流水线(Pipeline) 模块,作为顶层调度与执行入口。流水线封装了模型初始化、数据流、模块调用、记忆交互与结果后处理,通过简洁一致的API实现端到端世界模型推理。
流水线遵循标准前向执行工作流:接收原始用户或环境输入,路由至算子进行校验与预处理,查询记忆模块获取历史上下文,协调推理、合成、表征模块完成核心计算,最终返回结构化输出并更新记忆。该设计实现了模块实现的完全解耦,同时保证高效可靠的数据传输。流水线的核心职责包括:
- 统一模型初始化:通过单一
from_pretrained()接口加载预训练权重、配置设备、实例化所有子模块。 - 端到端推理:通过
__call__()方法实现单轮世界模型任务的一键前向推理。 - 多轮交互执行:通过
stream()方法支持带状态的连续交互,自动读写记忆。 - 模块化编排:根据任务类型动态调用推理、合成或表征模块,无需修改内部模块逻辑。
- 结果结构化:将输出整理为标准化格式,用于可视化、评估、日志记录或下游控制系统。
为保持框架全局一致性,所有任务专属流水线均继承自统一的BasePipeline模板,其定义如代码清单6所示。
import torch
from typing import Generator, List
class BasePipeline:
def __init__(self):
"""初始化核心子模块(算子、记忆、推理等)"""
pass
@classmethod
def from_pretrained(cls):
"""加载预训练权重,返回流水线实例"""
return cls()
def process(self, *args, **kwds):
"""输入校验与预处理(通过算子模块)"""
pass
def __call__(self, *args, **kwds):
"""单轮世界模型任务前向推理"""
pass
def stream(self, *args, **kwds) -> Generator[torch.Tensor, List[str], None]:
"""带持久化记忆的多轮连续交互"""
pass
代码清单6 OpenWorldLib中流水线的模板定义
Operator(算子):数据门卫 → 规整输入格式
Reasoning(推理):大脑思考 → 理解世界、做判断
Representation(表征):3D 建模 → 搭建物理世界沙盘
Synthesis(合成):输出生成 → 生成视频 / 音频 / 动作
Memory(记忆):经验账本 → 存历史、查上下文、保连贯
Pipeline(流水线):总指挥 → 按顺序调度所有模块
4 讨论
OpenWorldLib旨在为世界模型提供更清晰、标准化的定义与框架,推动世界模型的发展,让人工智能在复杂环境中更好地辅助人类。本节探讨世界模型的未来发展方向。
当前多数世界模型架构聚焦于帧预测,该范式与人类处理高密度感官输入的方式相符——人类本质上是在物理世界中“预训练”的,而大模型则在海量互联网文本语料上完成预训练[78,79]。但基于现有架构,视觉语言模型(VLMs)或许能提供可行方案。例如Bagel[161]基于Qwen架构成功实现多模态推理与多模态生成,这表明在互联网数据上预训练的大语言模型(LLMs)可具备世界模型所需的全部能力,彰显其作为基础底座的潜力。因此,在完全聚焦世界模型的特定结构设计前,应先考虑如何实现其全部必要功能,以达成与复杂世界的真实有效交互。
此外,由于大语言模型是世界模型的基础底座,以数据为中心的方法——包括多模态数据合成[74,90]、领域专属数据增强[15,164]、动态训练[80]、训练数据质量评估[76]——将在强化支撑世界模型能力的基础模型中发挥愈发重要的作用。
在真实世界交互中,帧预测比令牌预测保留更多信息,但其效率仍需大幅提升。要提升效率,需从硬件层面着手改进。当前计算机的字节组织天然适配令牌预测,即便模型尝试帧预测,实际计算中数据仍以令牌形式处理。要实现理想的世界模型,需要硬件迭代、基础模型结构变革(基于令牌的Transformer需进一步演进),以及复杂物理世界交互任务的全面落地。
5 评估
在介绍OpenWorldLib框架设计后,本节展示该框架的测试流程与评估结果。
5.1 实验设置
本文主要使用NVIDIA A800(80GB显存)与H200(141GB显存)显卡开展实验。未来计划在更广泛的硬件设备上评估本框架。
5.2 实验结果
5.2.1 交互式视频生成
视频生成的评估主要涵盖导航视频生成与交互式视频生成任务。视频生成对世界模型的意义在于,评估其对复杂世界的理解与记忆能力,同时辅助其他序列推理任务完成精准预测。执行视频生成任务时,世界模型必须生成符合特定任务精准视觉演化要求的视频。具体而言,这类任务的输入由视觉条件(如单张图像或图像序列)搭配多样化交互信号组成,交互信号包括文本指令、方向移动控制(前、后、左、右)与相机旋转指令。
图4 交互式视频生成结果展示
如图4所示,本文对多种方法的生成性能进行评估分析。在导航视频生成场景中,Matrix-Game-2[43,157]等早期方法生成速度快,但长时序生成过程中存在明显的色彩偏移问题。相比之下,Lingbot-World[116]、Hunyuan-GameCraft[65,111]、YUME-1.5[96,97]等近期模型可高质量支持导航视频生成,其中Hunyuan-WorldPlay[110]的整体视觉效果最优。
在交互式视频生成方面,尽管Wan-IT2V[121]可完成基础交互式生成,但难以维持物理一致性。此外,针对复杂交互操作生成任务,WoW[20]虽支持丰富功能,但其生成质量与物理真实度远不及Cosmos[1]。
5.2.2 多模态推理
在OpenWorldLib中,推理模块归类了需要世界模型解读多模态证据并生成显式、可验证结论的高级认知任务,涵盖空间推理[64,94](如解答几何与布局相关查询、梳理物体关系、基于视觉输入逐步空间推演)与全模态/通用推理[141](处理文本、图像、音频、视频混合模态,支持广泛指令遵循与多模态理解)。
该模块对世界模型的重要性在于,将内部感知与记忆转化为可执行信息:把观测结果转化为落地的决策、解释与规划,指导下游生成或控制。执行推理任务时,输入通常为指令或问题搭配可选的视觉信号(如图像、视频片段、音频片段),并编码为模型可处理的表征;输出主要为解码后的自然语言响应,部分全模态推理场景中还可额外生成音频与文本。
5.2.3 三维生成
OpenWorldLib中的三维生成流水线支持三维场景重建,实现对复杂真实世界环境的稳健表征。该流水线的感知输入通常为单张图像或图像序列,交互信号包括移动控制或相机视角调整(如极角、方位角、偏航角)。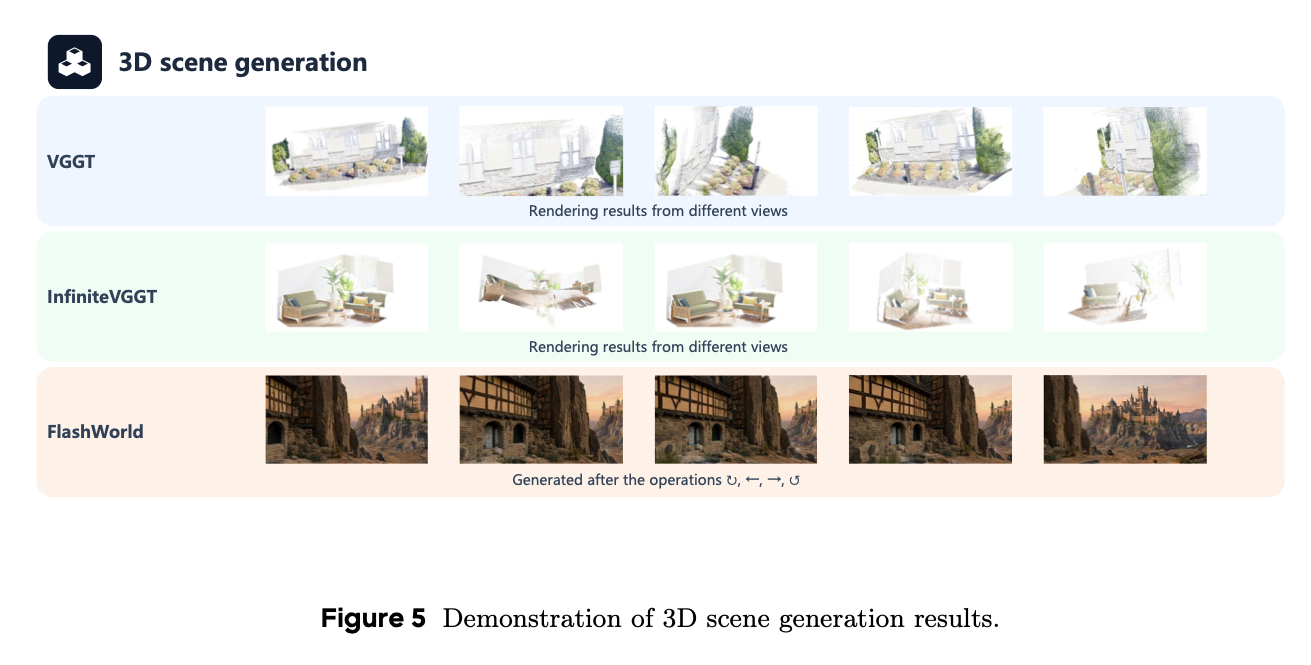
图5 三维场景生成结果展示
如图5所示,尽管VGGT[123]与InfiniteVGGT[147]可从不同视角生成三维场景,但仍存在明显局限。例如相机大幅移动时,这些模型常出现几何不一致问题,复杂区域纹理模糊,影响整体真实感。FlashWorld[71]等更快的方法提升了生成速度,但平衡形状稳定性与细节清晰度仍是主要挑战。尽管如此,三维生成作为实现真实物理仿真的关键技术,对世界模型的发展仍具有基础性重要意义。
5.2.4 视觉-语言-动作生成
与三维生成类似,仿真环境是世界模型评估不可或缺的组成部分,作为可控测试平台,用于具身视频合成与动作生成。为此,OpenWorldLib集成两种互补的基于仿真的范式:用于具身视频生成的AI2-THOR[57](支持照片级真实感场景渲染与智能体-环境动态交互)、用于视觉-语言-动作(VLA)评估的LIBERO[87](提供可复现、物理落地的操控环境)。
两种范式结合,严格评估世界模型在多样化交互场景中,将语义理解与物理动态、细粒度动作规划相结合的能力。如图6所示,本文展示LIBERO与AI2-THOR仿真环境的代表性评估案例,涵盖多样化操控任务与具身交互场景。
此外,本框架支持全套VLA方法的评估,典型案例包括 π 0 \pi_{0} π0[13]与 π 0.5 \pi_{0.5} π0.5[53]——二者基于PaliGemma视觉语言底座,结合混合专家(MoE)动作头,实现稳健的多任务泛化;本文还集成LingBot-VA[67],从生成视角出发,采用视频扩散架构联合建模视觉未来预测与连续动作合成。
图6 仿真器生成结果展示
6 结论
综上,OpenWorldLib提供了世界模型的标准化工作流与评估流水线。通过为交互式视频生成、三维场景重建等核心任务提供统一接口,本框架实现了多模态感知输入与多样化交互控制的标准化集成。本文期望OpenWorldLib能为研究社区提供实用参考,推动世界模型研究的未来探索与公平对比。
通过 OpenWorldLib 所有核心模块实现机器人执行「把红色杯子放到蓝色盘子上」任务。
总调度:Pipeline(流水线) 全程由它指挥,像“总指挥”一样按顺序调用所有模块,不用手动挨个操作。
1. Operator(算子)→ 输入门卫+格式化
输入:你说的话「把红色杯子放到蓝色盘子上」+ 桌面实拍照片
它只干2件事:
- 校验:检查语音转文字是否合法、照片尺寸/格式对不对
- 预处理:
- 文字 → 变成模型能读的分词张量
- 照片 → 缩放到标准尺寸、归一化像素值
输出:统一格式的干净数据(不提取特征、不思考、不生成)
2. Memory(记忆)→ 调取历史经验
它干1件事: 查之前有没有见过这个桌面、红杯、蓝盘?有没有做过类似放杯子的任务?
输出:历史上下文(比如“这个桌面无障碍物”)
3. Reasoning(推理模块)→ 大脑思考/做决策
核心:只思考、不生成画面、不建3D模型 拿到标准化数据+历史记忆,它开始“想明白”:
- 识别:找到红色杯子、蓝色盘子
- 空间推理:杯子在盘子左前方 5cm
- 物理推理:抓杯身、不能抓杯口、移动要平稳
- 动作规划:机械臂移动路径→抓取→抬起→平移→放置→松开
输出:决策+逻辑结论+动作规划(纯文本/逻辑数据)
4. Representation(表征模块)→ 3D物理沙盘构建
核心:把2D世界变成可仿真的3D物理世界 基于推理的空间结论,它干3件事:
- 3D重建:把照片转成点云、深度图、3D坐标
- 环境建模:搭建桌面、杯子、盘子的3D结构
- 仿真验证:在3D沙盘里预演,确保机器人不会撞东西
输出:结构化3D物理环境 + 安全运动轨迹
5. Synthesis(合成模块)→ 最终输出生成器
核心:把决策变成“看得见、用得了”的结果 分两路输出:
- 视觉合成:生成机器人执行动作的仿真视频/画面
- 动作合成:生成机器人电机能直接执行的控制指令(角度、位移)
输出:可视化视频 + 机器人可执行的动作信号
6. Memory(记忆)→ 存本次结果 把本次的物体位置、动作规划、执行效果存起来,下次任务直接用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)