多模态动态融合模型Predictive Dynamic Fusion阅读与代码分析5-校准机制与理论推导
参考文:Cao B, Xia Y, Ding Y, et al. Predictive Dynamic Fusion[J]. arXiv preprint arXiv:2406.04802, 2024.[2406.04802] Predictive Dynamic Fusion
一、校准机制
除了训练过程中不同模态的置信度之间的相互影响,在测试过程中,每个模态自己的判断也会拿出来进行分布均匀性校准。
原文:数据质量通常在开放环境中动态变化,导致预测不可避免地存在不确定性。为了降低复杂情况下 CoBelief 的潜在不确定性,我们进一步提出了一种相对校准 (RC),从多模态系统的角度校准预测的 CoBelief。这意味着每种模态的相对优势应随着其他模态质量的变化而动态变化,而不是保持静态。
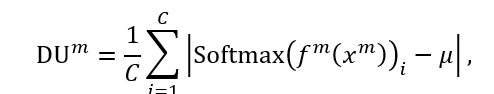
考虑到环境的变化,多模态系统中不同模态的不确定性应该是相对的,即每个模态的不确定性应随着其他模态的不确定性变化而动态变化。一个模态应该动态地感知其他模态的变化,并调整其对多模态系统的相对贡献。因此,我们引入相对校准 (RC) 来校准每个模态的相对不确定性。对于m第一个模态的相对校准可以表示如下 (在有两个模态的情况下,表示为m,n∈M)):
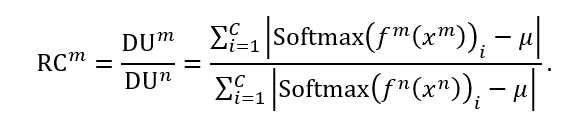
这个定义是什么个过程呢?举个例子
文字模态输出的判断结果是:喜悦0.9,自然0.9,沮丧0.9;图像的是:喜悦0.9,自然0.1,沮丧0.1;
那么C就是3,μ就是1/3,文字DU就会计算出0,图像DU会是4/3,文字的相对RC就会是0
但如果文字模态输出的判断结果是:喜悦0.9,自然0,沮丧0,那么C就是3,μ就是1/3,这个文字DU就会计算出4/3,文字的相对RC就会是1
也就是说,结果越趋近于一个单一结果,DU就会越高,而此模态比其他模态更趋近单一,那么RC就会越高。
然后让RC小于1的模态的置信度乘以RC,得到CCB,降低自己输出的比例。
总的来说就是:模态在各个结果的输出越相似,模态越不值得信任。
二、理论推导
我最讨厌的公式推导环节,所以放在很后面。
除了之前提到的一个凸函数性质和泛化误差定义,还有一个随机变量X,Y不独立,E(XY)=?的性质
https://wenku.baidu.com/view/faf4430510791711cc7931b765ce0508763275ab.html
答案是E(XY) = Cov(X,Y) + E(X)E(Y)
知道了就开始推公式吧
1、逻辑损失函数
逻辑损失函数是一个凸函数
证明:逻辑回归损失函数通常是凸函数(附平方差损失的非凸证明以及交叉熵损失函数求导)_逻辑回归损失函数是凸函数吗-CSDN博客
那么就可以看懂下面这个公式:
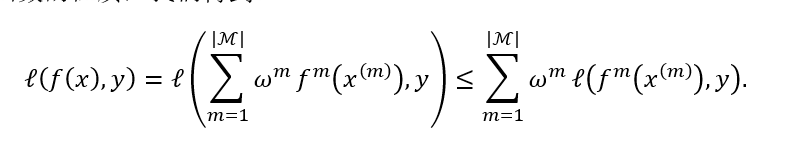
注意到,softmax作为一个归一化函数,所有的和是1,利用Loss是凸函数的性值们就可以推导这个不等式。那么下面这个关于泛化误差的不等式也是一个原理推导到的
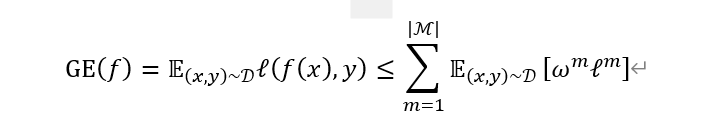
2、变换
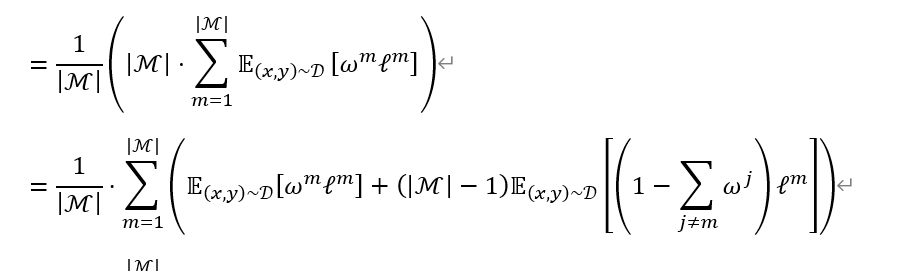
乘以模态数量M再除以,下一步再拆分出自身模态与其他模态,很简单很简单;注意到所有的和是1,所以那个1-(其他
的和)的变换也很好理解。
3、不独立的期望性值应用
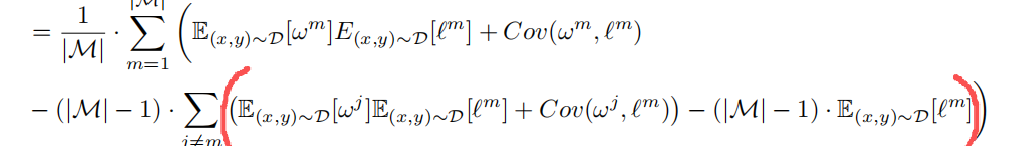
E(XY) = Cov(X,Y) + E(X)E(Y),这里是x,L是y,这个拆开也很好理解,这里少了对大括号,容易看蒙。
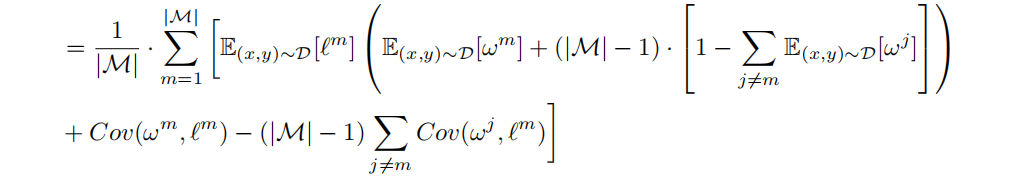
然后再把E[L]的项整理到一起放一边,cov放外边
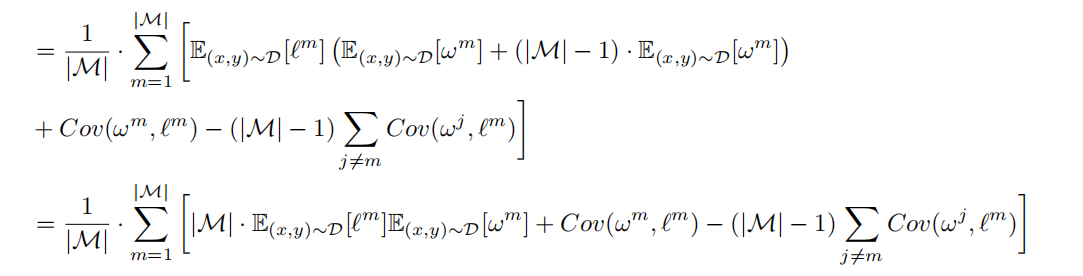
可以发现E[L]的项是可以整理合并的,理回最开始的模样。
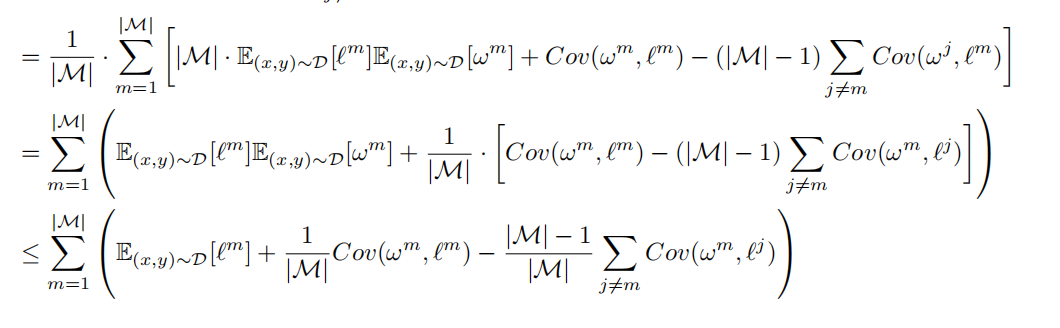
把M流畅的除回去,再利用小于1做一个近似,左边E相关的就是传统泛化误差上界的计算公式,,就能得到这个可以控制多模态泛化误差的上界公式。
4、结论
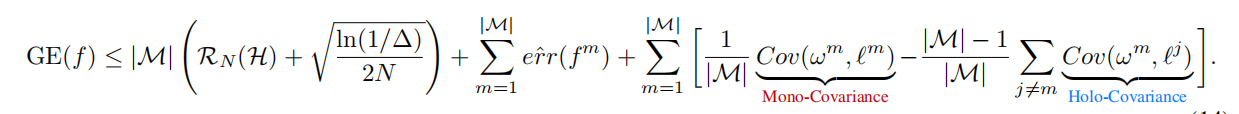
所以推导到模态的系数和损失的相关性越小越好,和其他模态损失的相关性越大越好,这样GE(f)的边界才越小。
然后利用Ptrue和Loss的正相关关系,可以用Ptrue替换Loss的位置,实验证明效果好,就这么换了
推完了睡觉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)