【晓天衡宇·评测社区】中文医疗榜单正式发布!
【榜单简介】
本榜单以ClinConsensus为核心评测基准,系统性地对14个主流大语言模型在中文医疗相关能力上开展对比评测。
ClinConsensus是一个由临床专家精心策划、验证和质量控制的中文医疗基准测试,包含了2500个开放式病例,涵盖从预防和干预到长期随访的完整医疗服务链,涉及 36 个医学专科、12 种常见临床任务类型,且复杂度逐步递增,用于评估大模型在医疗全方位场景下的医疗能力。
【查看完整榜单】👉🏻 https://skylenage.net/sla/leaderboard
【参评模型】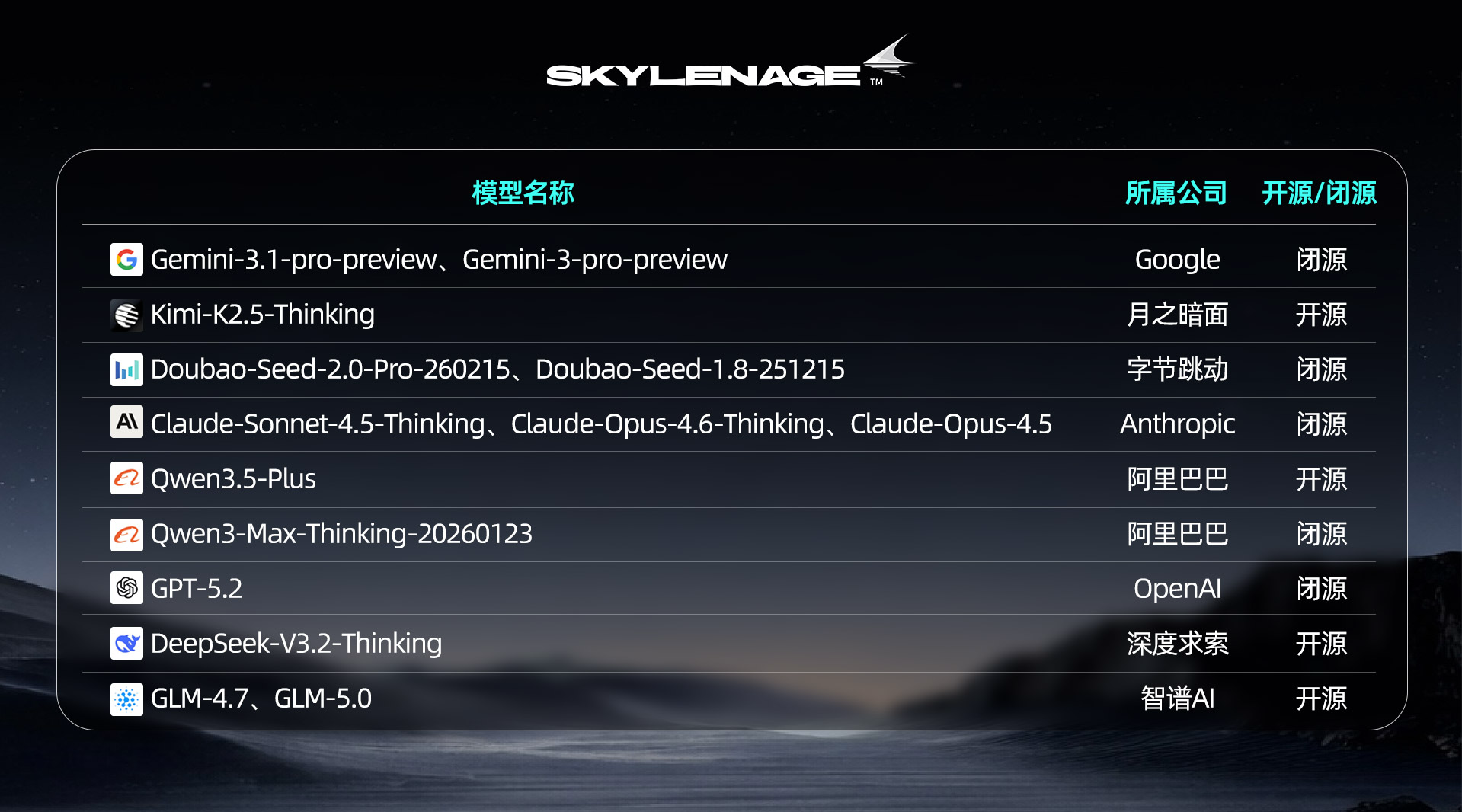
【评测集解读】
评测维度
当前版本的ClinConsensus将评测维度分为五个大类和12个细分类目,不同任务之间的难度差异较为明显。
整体来看,比较容易取得高分的主题包括:
-
日常询问-常见疾病科普
-
医疗随访-病情跟踪
-
判断疾病-鉴别诊断
-
治疗用药-个性化方案生成
整体更具挑战性的主题包括:
-
理解病情-医学命名实体识别(NER)
-
理解病情-临床文档摘要生成
-
理解病情-医学信息抽取(IE)
-
日常询问-用药注意事项
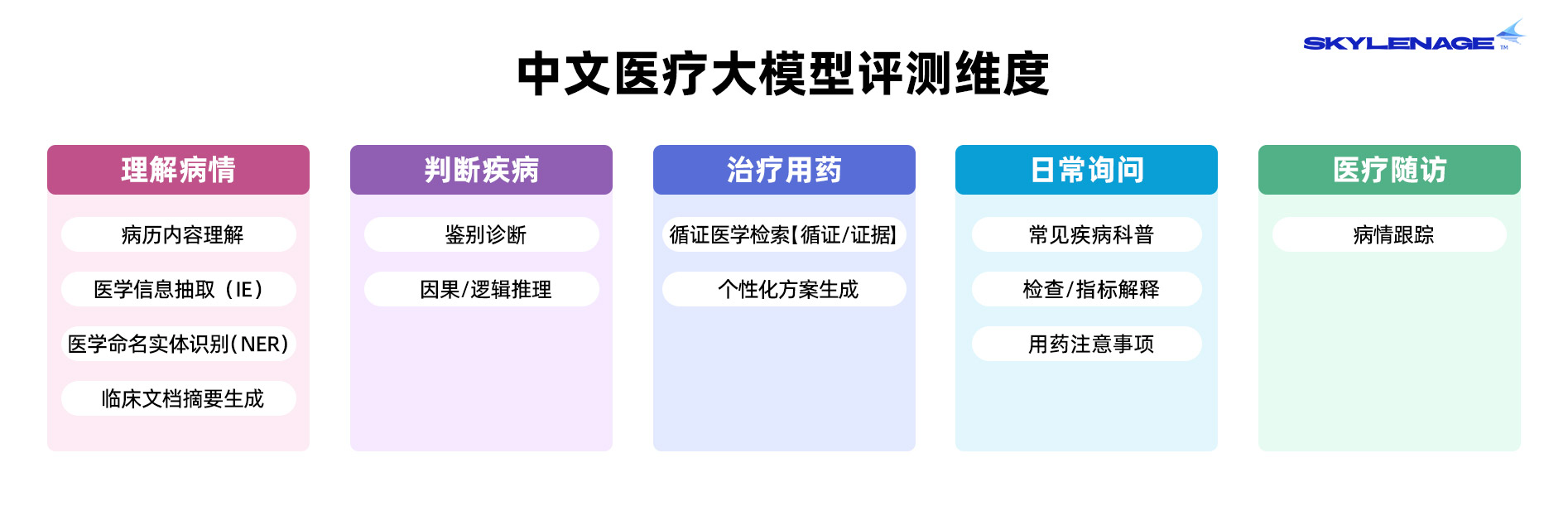
从任务分布看,本评测集更强调真实临床使用价值,其中“个性化方案生成”“鉴别诊断”“病历内容理解”等高价值任务占比较高,能够较好反映模型在复杂医疗决策场景下的能力上限与短板。
数据标准
榜单数据由中国临床专家团队根据真实病例或临床经验构建,旨在还原真实世界的开放复杂场景。数据集全面覆盖36个常见医学专科,兼顾普通消费者、患者及医务工作者等多元视角,并经过去标识化处理,以保证医学精准性和场景复杂性。
本评测集每个案例均配有 30 条专家 rubric,用于从安全性、完整性、临床合理性、可执行性和沟通质量等维度对模型回答进行细粒度评估,整套评测一共包含 75,000 个 rubric 判断点,可以做到精细评估模型在诊断推理、治疗决策、用药安全、检验结果解读等方面的能力。
同时,数据集按照任务数量和涉及专科数量划分为 L1、L2、L3 三个复杂度等级,以支持分层评测。为保证数据质量,构建过程中采用两阶段质量控制:首先利用多个强模型筛除过于简单的案例,其次由资深医生进行抽检审核,确保案例内容、评估标准和参考答案的临床合理性与一致性。
本次实验在 2500 个案例 × 每例 30 个 rubric 的设定下,对 14 个主流大模型 进行了统一评测。所有模型均完成了完整判分,整体 judge 覆盖率为 100%,未出现 RequestError 或 ParseError。
【评分标准】
本次榜单同时报告两类核心指标:
-
Rubric 命中率(accuracy):模型在全部 rubric 判断中的命中比例,反映整体合规性与完成度。
-
CACS@7:统计单条回答在 30 条 rubric 中达到不同阈值时的累计表现,用于衡量模型在复杂案例中的稳定性与高质量输出能力。
(注:历史内部脚本中曾将该指标误写为 CUS,当前统一记为 CACS。)
其中,命中率更适合用于衡量模型的“平均完成度”,而 CACS@7 与分主题结果更适合揭示模型在复杂任务中的稳定性与结构性短板。两者结合,能够更真实地呈现模型在实际医疗场景中的能力边界。
【榜单速览】
按总体 rubric 命中率排序,前五名如下: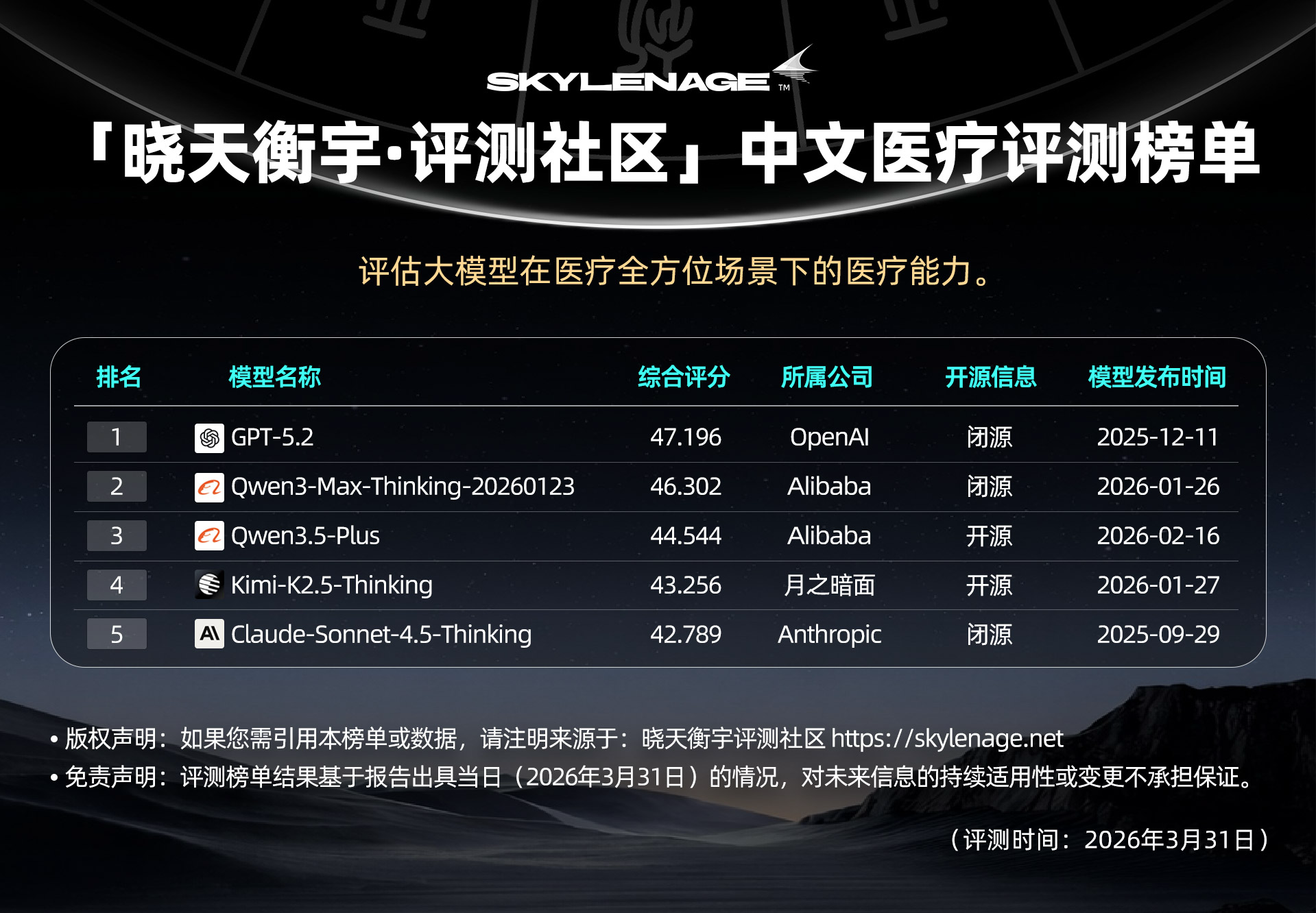
1.头部模型:
-
从总得分来看,GPT-5.2 以微弱优势领跑,并在医疗随访和判断疾病两个子项中表现极为突出,反映其在临床决策和患者管理场景中的技术深度。
-
Qwen的两款模型——Qwen3-Max-Thinking和Qwen3.5-Plus分列二三位,与 GPT-5.2 的差距较小,说明 Qwen 系列在复杂医疗任务中的综合推理和回答稳定性已经进入第一梯队,代表其在医疗专业能力上已具备国际竞争力,尤其在日常询问和治疗用药等项目中表现亮眼。
2.国产模型崛起:
作为国产模型的代表,除了阿里巴巴的 Qwen之外,Kimi-K2.5-Thinking位列第四,作为另一家国产头部企业,其在理解病情中得分较高,显示在病症解析和语义理解上的技术特色,三款模型在总分和子项得分上均展现稳定优势,体现国产模型在中文语境和医疗知识库构建上的技术积累。
3.国际模型竞争力:
OpenAI的GPT-5.2延续了其在医疗领域的领先地位,Claude-Sonnet-4.5-Thinking虽排名第五,但在医疗随访中的得分仅次于GPT-5.2,证明其在特定场景下的有效性。
4.专项得分能力:
-
GPT-5.2全面领先,尤其在常见疾病科普及需要长期病程管理和个性化建议的医疗随访测试中优势显著。
-
Qwen3-Max-Thinking:在病情理解及信息提取中得分超越GPT-5.2,可能得益于其对中文医学文献和临床指南的深入学习。
-
Kimi-K2.5-Thinking:在理解病情专项中得分高于部分国际模型,体现其在中文自然语言处理上的技术沉淀。
5.行业共同薄弱环节
-
交互式诊断思维缺失: 模型倾向于直接给出结论,缺乏临床医生必备的“主动追问”意识,导致潜在致命风险(如急症)的拦截率不足及诊断的可靠性不足。
-
医学诊断精准性不足,过度诊断倾向:模型无视临床诊疗过程中的不确定性、局限性及变异性,倾向于根据短期病情、症状体征等不完整信息直接给出病情诊断。依据不完整的诊断依据直接给出诊断时,未提示用户不确定性。缺乏对“序贯发生疾病”或“共病状态”的认识、缺乏对疾病分期的能力。
-
知识来源的不可追溯性: 提示词中未明确要求提供知识来源时,响应绝不主动提供知识来源。当提示词中明确要求提供知识来源时,知识来源往往不够明确,如指南缺乏具体名称、学会名称、发布年限;教科书缺乏年限标识;临床研究或基础研究缺乏具体研究文章名称、DOI等。
-
“时间维度”在诊断中的缺失: 难以理解“症状的时间顺序”优于“单次检查结果”的临床价值。
-
个性化方案制定: 无法基于用户的个人基础情况识别个性化的风险可能,并提供个性化的诊疗方案。
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网:https://skylenage.net/sla/leaderboard
【榜单结论】
目前,各模型之间存在较明显的性能差距,当前主流模型在面向患者的通俗解释、随访建议和常见诊断分层方面已经有较强能力,但在结构化医学信息抽取、医学实体识别、长病历压缩总结等高密度理解任务上,仍存在明显短板,并且目前中文医疗场景下的大模型能力已经出现明显分层:
-
第一梯队模型在复杂的开放式临床案例中,已经能够稳定完成较大比例的 expert rubric。
-
Qwen 系列在本轮测试中整体表现突出,尤其在高覆盖率和高稳定性两个维度同时保持竞争力。
-
GPT-5.2 仍然保持总体领先,说明在复杂病例理解、跨步骤推理和高标准 rubric 对齐方面仍具有优势。
-
中间梯队模型虽然在部分主题上表现接近头部模型,但在复杂主题下波动更大,稳定性仍需提升。
【了解更多】
中文医疗评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据
👇关注晓天衡宇•评测社区官方账号,获取更多大模型相关知识~ 欢迎加群沟通

|

|
|
|
(钉钉群) |
(微信群) |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)