Provider的介绍和引入,deepseek的接入实现
1.Provider的介绍和引入
1.LLMProvider的实现思路
这里我们的实现就采用了策略模式

举个例子
假设你现在要从宿舍去学校图书馆,但宿舍到图书馆之间有⼀段距离,你可以采⽤下属三⽅ 式去:
•
⾛路(最节省钱,但慢)
•
骑⾃⾏⻋(中等速度,中等花销)
•
坐校内公交⻋(最快,但贵)

//去机房方式策略的封装
class TransportStrategy {
public:
virtual void go() = 0;
};
class WalkStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "⾛路去机房🚶"; }
};
class BikeStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "骑⻋去机房🚴"; }
};
class BusStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "打⻋去机房🚕"; }
};
};
class Student {
private:
TransportStrategy* strategy;
public:
void setStrategy(TransportStrategy* s) { strategy = s; }
void goToLab() { strategy->go(); }
};
int main(){
Student me;
me.setStrategy(new WalkStrategy());
me.goToLab(); // 输出: ⾛路去机房🚶
me.setStrategy(new BusStrategy());
me.goToLab(); // 输出: 打⻋去机房🚕
return 0;
}程序⾮常美观且灵活,在使⽤时只需和TransportStrategy 打交道,不需要知道背后到底是
WalkStrategy、BikeStrategy或BusStrategy。如果想更换模式,只需要更换⼀个具体的策略对象即
可,程序基本不需要改动。
策略模式是设计模式的⼀种,它的核⼼思想是它定义了⼀些列算法,将每⼀个算法(或⾏为)封装起来, 使它们可以相互替换,⽽不⽤再代码中写⼀堆if-else/switch来决定⽤哪个算法。即把“做事的⽅ 式”抽象出来,运⾏时根据需要选择哪种⽅式去执⾏。
但当我们要在自己程序上去聊天时 我们需要具备的:大模型提供者 所以接下来我们要封装一个父类LLM提供者 提供这些功能 然后这些派生类去继承然后完成各自的功能即可。

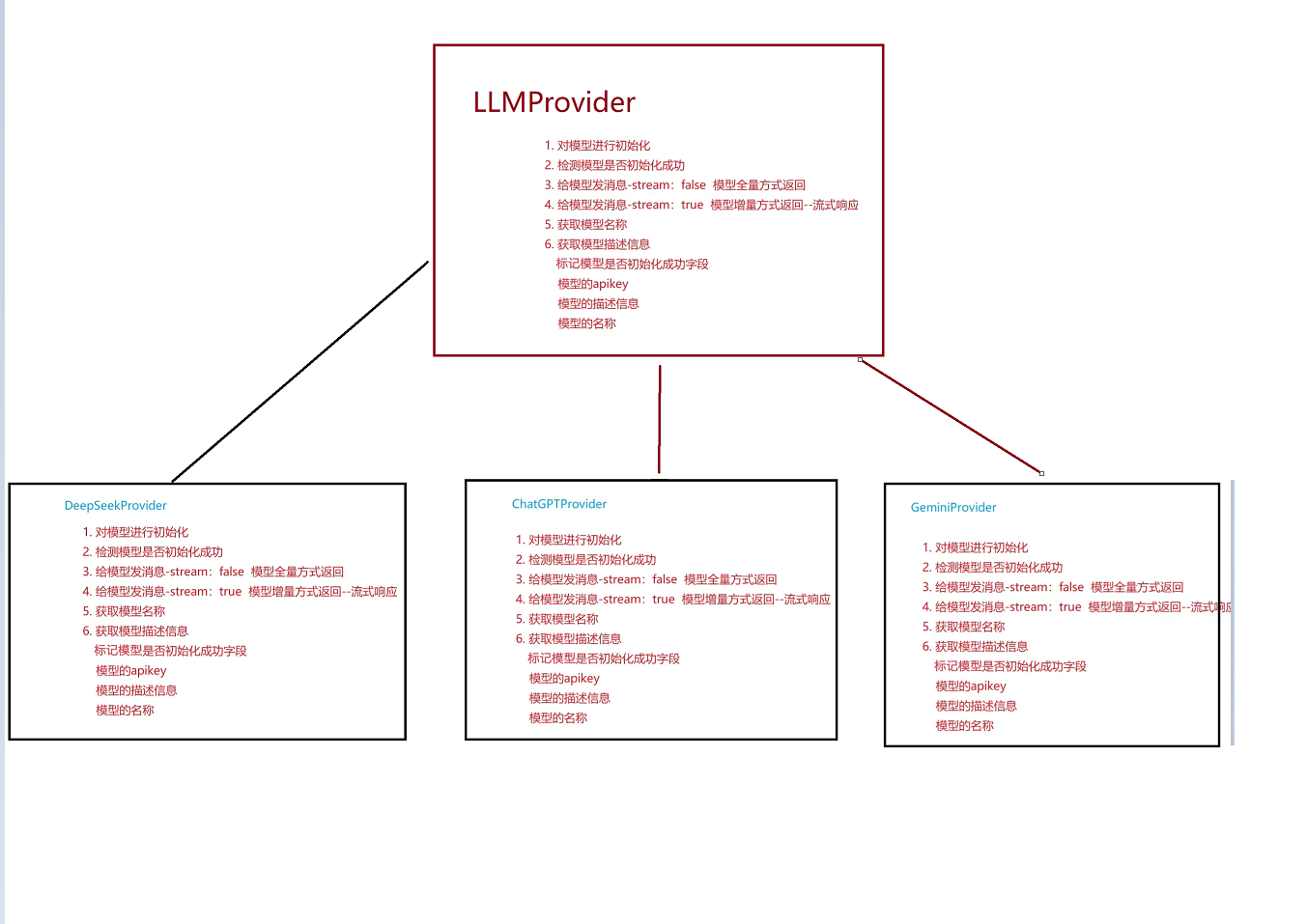
这样去继承我们就可以实习一个整体的功能然后局部的功能局部去实现 就避免了代码的重复
c++中基类的指针可以指向子类对象(运用了多态的机制) 然后我们发消息时用哪个看你传的是哪个大模型即可 然后将一些公共部分实现成虚函数即可

我们在实现LLMProvider时将其变为抽象类 也就是将其方法都变成=0 然后变为抽象类也就是接口类 规范了子类是实现的方法
这样当我们只需要去调用LLMProvider即可然后再由编译器自己去调用不同模型的Provider
这样就完成了实现

我们将这个LLMProvider这个类封装到include文件夹下面 因为他只是一个抽象类 并没有去实现什么
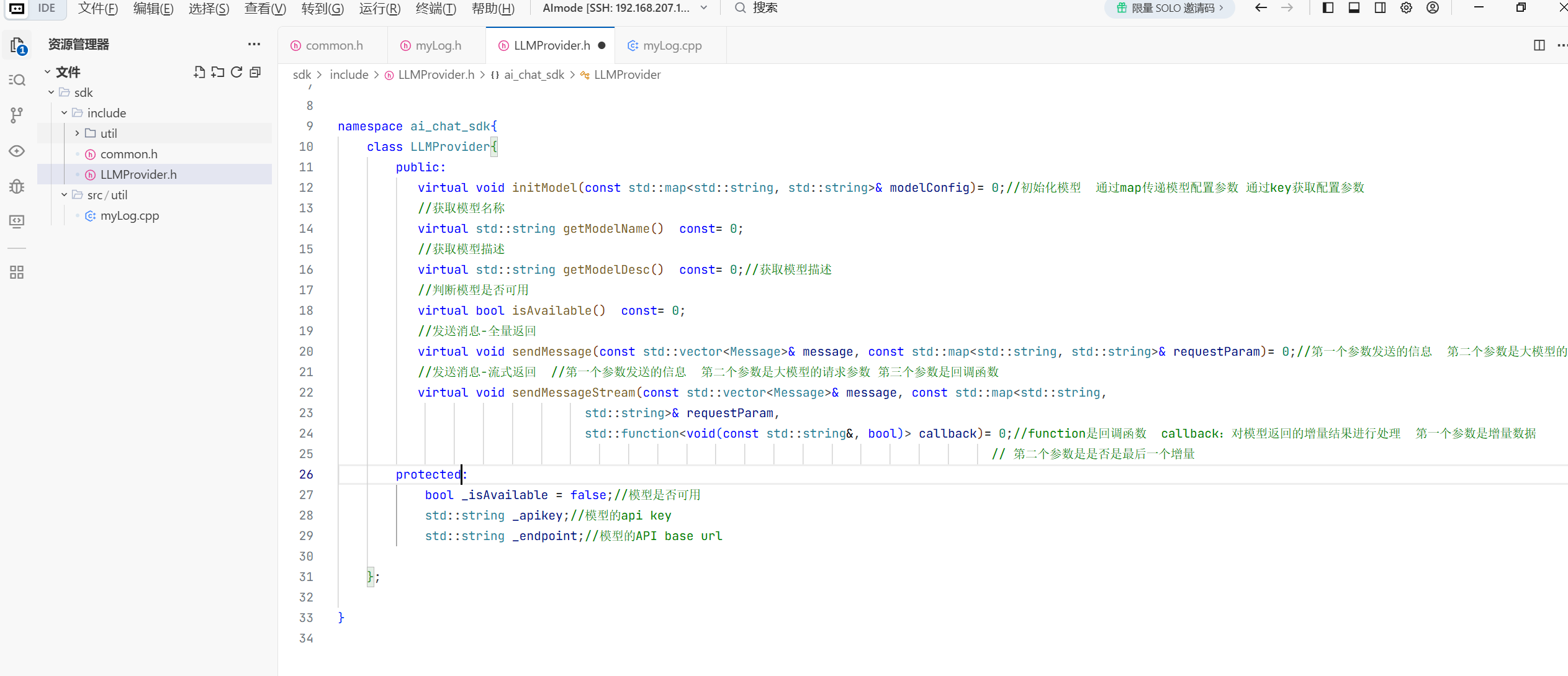
#include <string>
#include <map>
#include <vector>
#include "common.h"
#include <functional>
namespace ai_chat_sdk{
class LLMProvider{
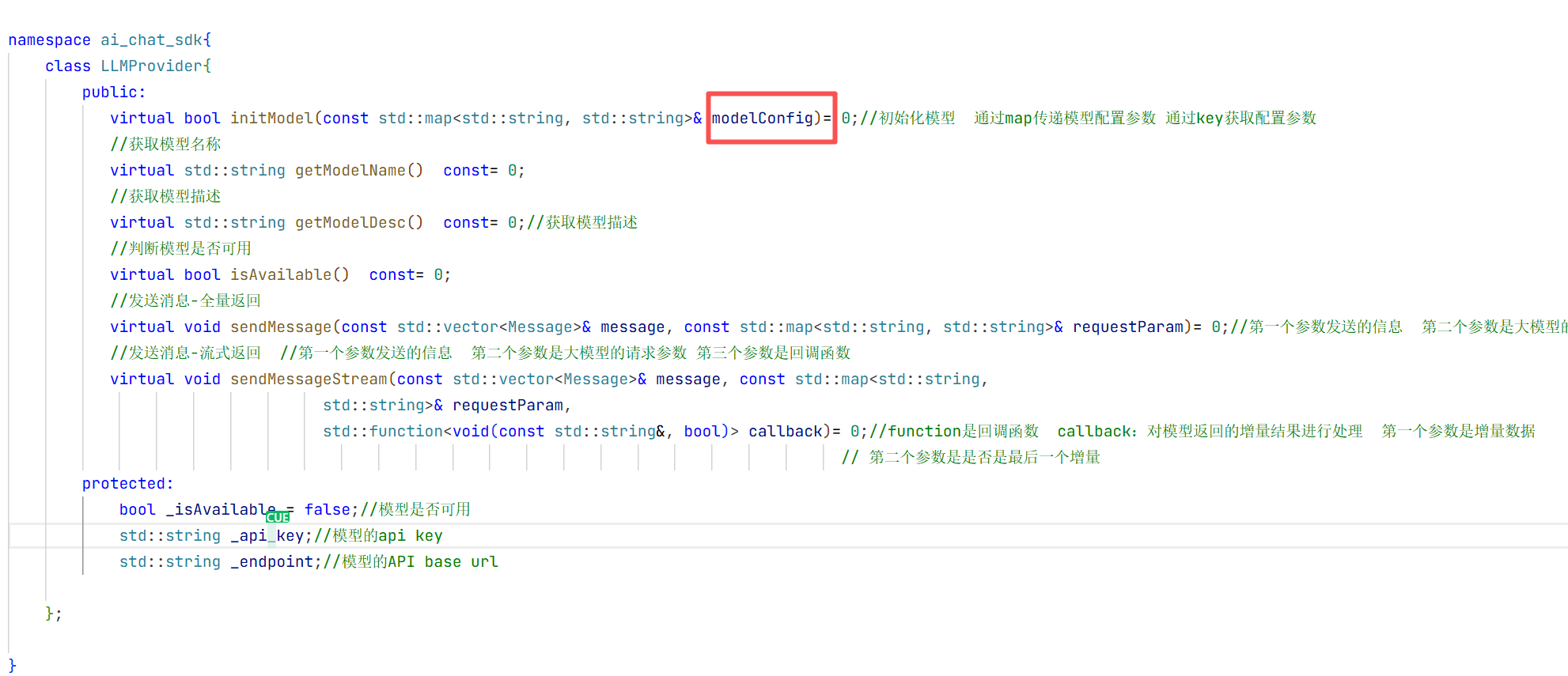
public:
virtual bool initModel(const std::map<std::string, std::string>& modelConfig)= 0;//初始化模型 通过map传递模型配置参数 通过key获取配置参数
//获取模型名称
virtual std::string getModelName() const= 0;
//获取模型描述
virtual std::string getModelDesc() const= 0;//获取模型描述
//判断模型是否可用
virtual bool isAvailable() const= 0;
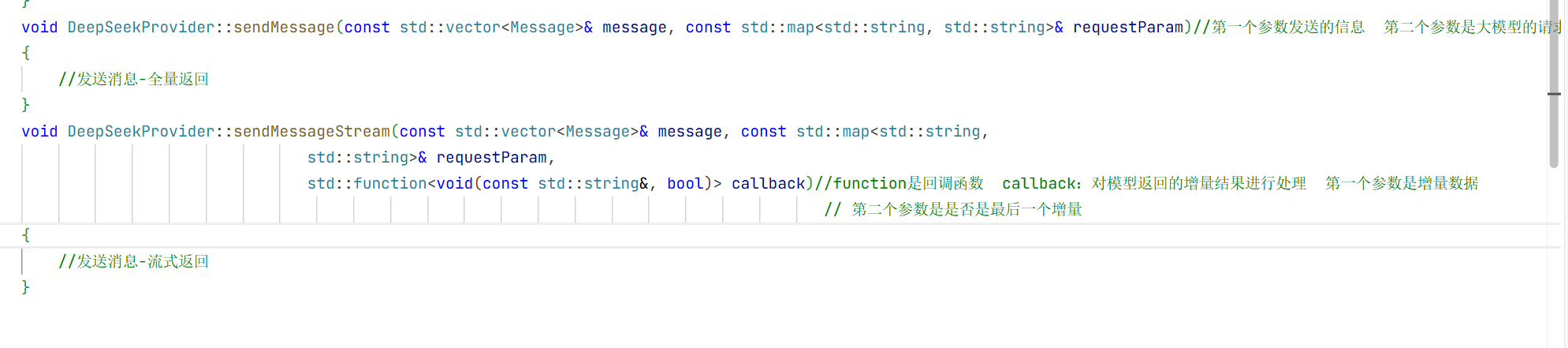
//发送消息-全量返回
virtual void sendMessage(const std::vector<Message>& message, const std::map<std::string, std::string>& requestParam)= 0;//第一个参数发送的信息 第二个参数是大模型的请求参数
//发送消息-流式返回 //第一个参数发送的信息 第二个参数是大模型的请求参数 第三个参数是回调函数
virtual void sendMessageStream(const std::vector<Message>& message, const std::map<std::string,
std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)= 0;//function是回调函数 callback:对模型返回的增量结果进行处理 第一个参数是增量数据
// 第二个参数是是否是最后一个增量
protected:
bool _isAvailable = false;//模型是否可用
std::string _apikey;//模型的api key
std::string _endpoint;//模型的API base url
};
}
这样顶层抽象类就实现好了 这样以后你用哪个大模型 底层弄好了 你就可以去封装自己大模型的类 再去调用这个顶层类 这样就避免的代码的冗余。
2.deepseek的接入封装:
1.deepseek的API介绍:
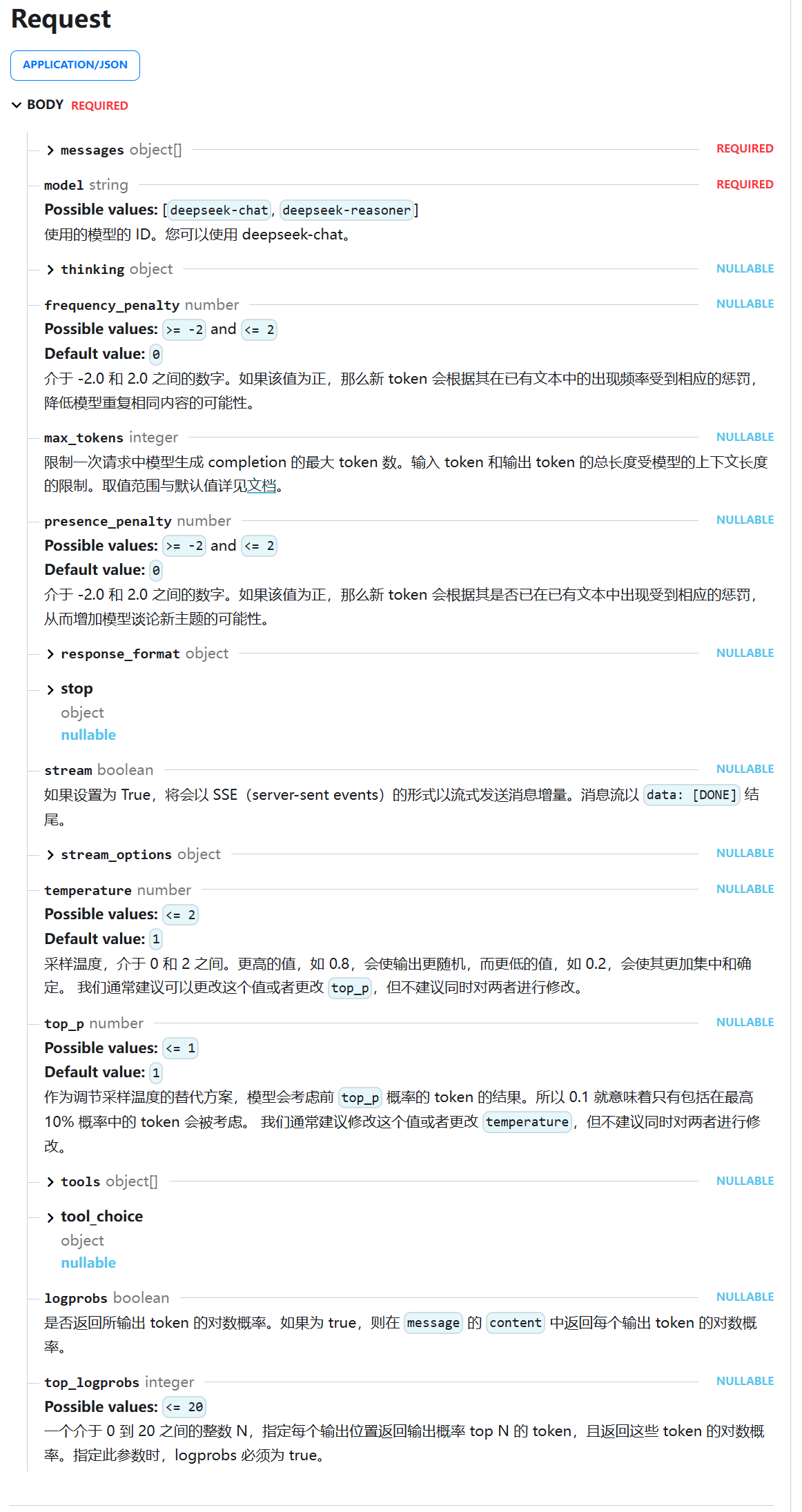

top_p的含义也就是控制动态选词的质量高低
如果我们去看deepseek对话需求文档我们可以看到调用要传很多的参数 但是我们实际在实现时可以不用传递这么多 只需要传递重要的就行
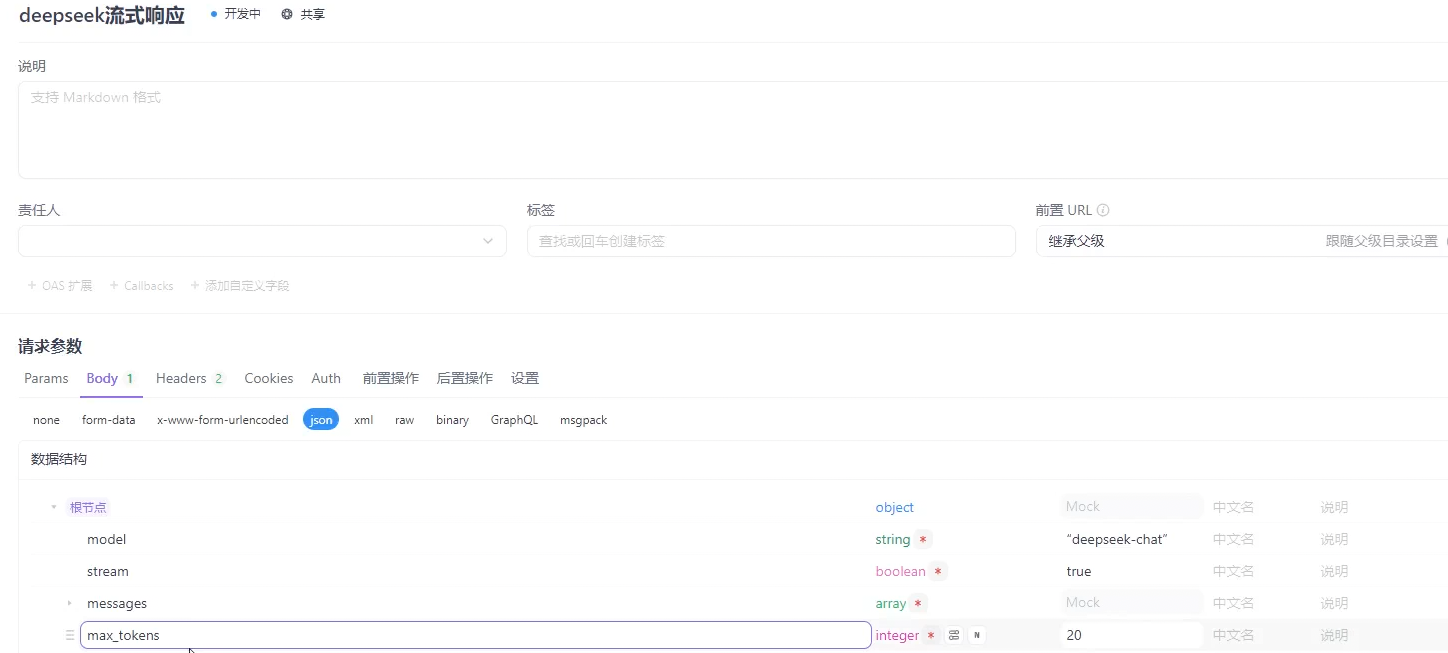
像我们在APIfox做的小验证我们只穿了 模型名称 输出流 消息 最大token数 也能完成调用
通过API调用的时候
注意:
•
⽆状态服务原则:DeepSeek的API基于⽆状态设计,每次请求视为独⽴会话。若需维护对话连续
性,必须由客⼾端主动管理并传递完整上下⽂。这与HTTP协议的⽆状态特性⼀致。
•
系统提⽰:若需保持⻆⾊设定,如始终以专家⾝份回答,每次请求必须包含系统级指令
•
对话历史:模型仅处理当前请求中的上下⽂,⽆法关联前序对话
这里需要注意的是假如你在APIfox第一次调用告诉了你的名字给大模型 第二发送我是谁的问题后 他会不记得 因为每次HTTP协议是独立的,就相当于你现在的这个调用 每一次对话都是独立的,
他不记得上下文。
但是当年在网页端去问deep seek同样的问题时 他会记得 因为deepseek官网后台 维护了与用户的聊天记录。
因为在APIfox调用时 没有维护与用户聊天记录 导致不知道与用户的聊天记录 所以每段对话是独立的 所以用API调用的时需要带上之前的聊天记录 才能根据上下文回答用户的问题。

我们根据回复的内容通过循环解析 找到这个content这个内容
2.deepseek的初始化:
1.deepseek头文件的实现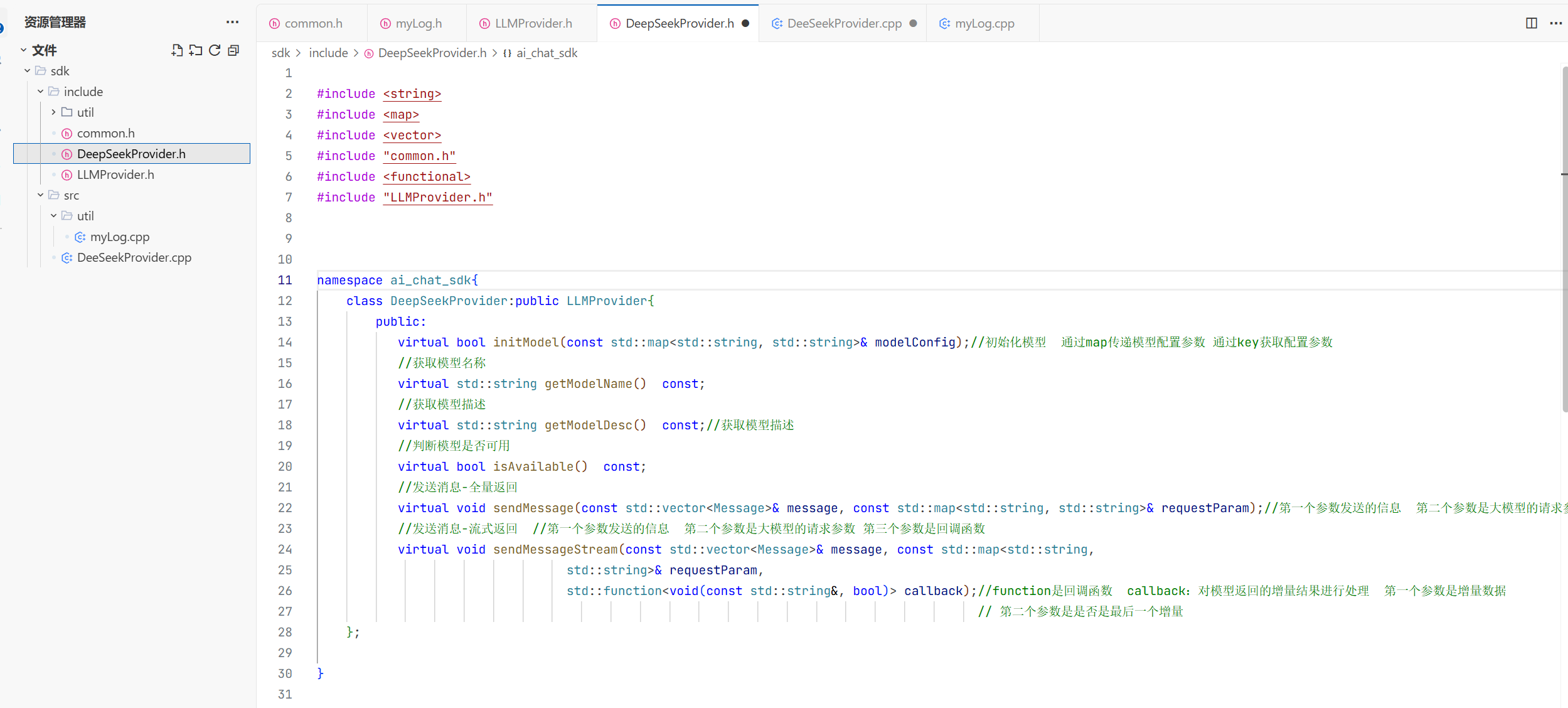
先在include下面创建支持deepseek初始化的头文件 做到头文件与源文件分离 直接继承父类 然后父类是保护成员但子类可以访问就不用写成员变量了
2.deepseek源文件的实现
再继续在src创建一个初始化deepseek的源文件即可 然后来进行初始化的实现
1.初始化模型的实现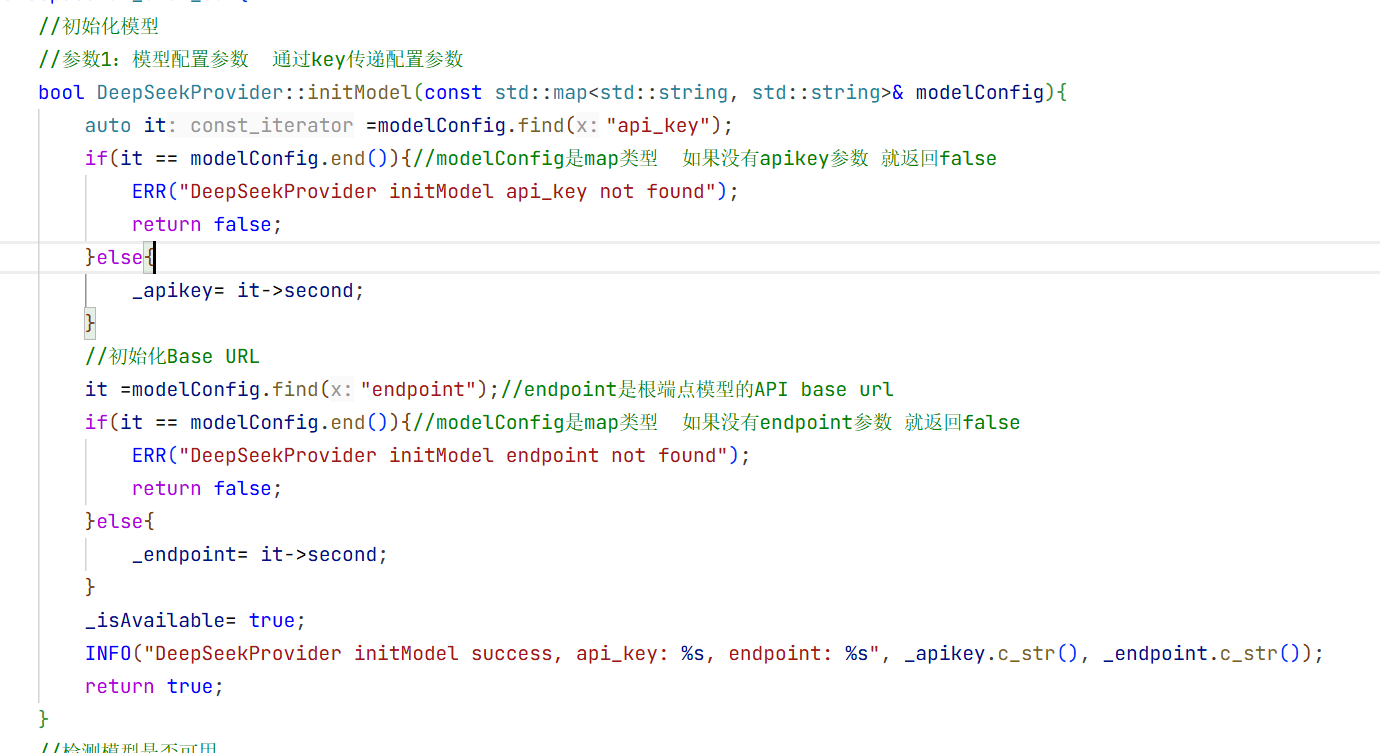
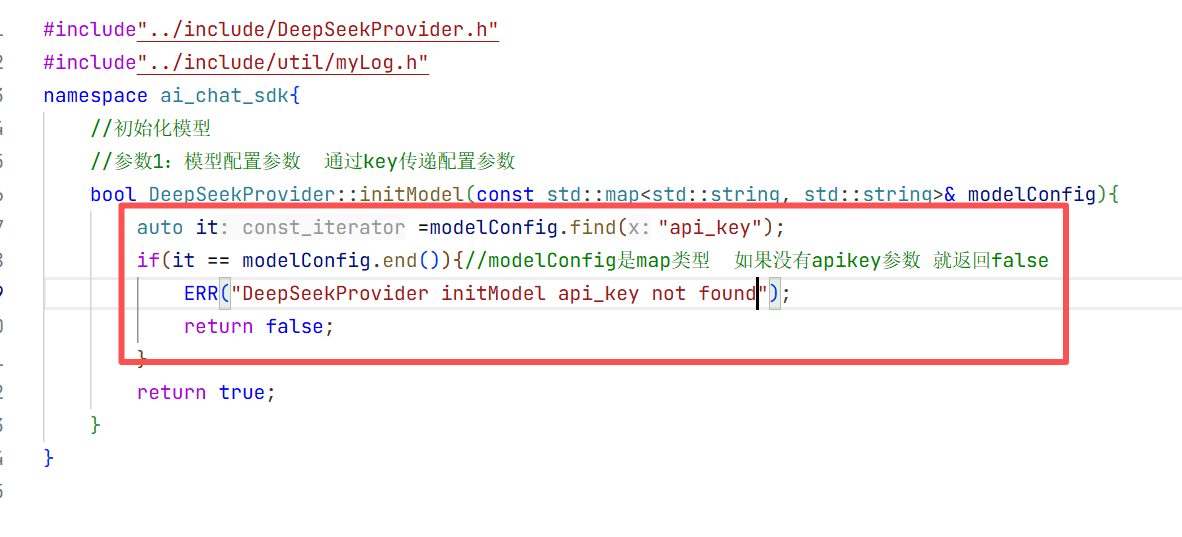
在cpp实现中我们去找这个map类型中的key值没找到说明你的api_key不存在 如果找到了就用map的value值去初始化api_key
2.检测模型和获取模型名称和描述模型信息
3.发送消息的实现(全量返回)

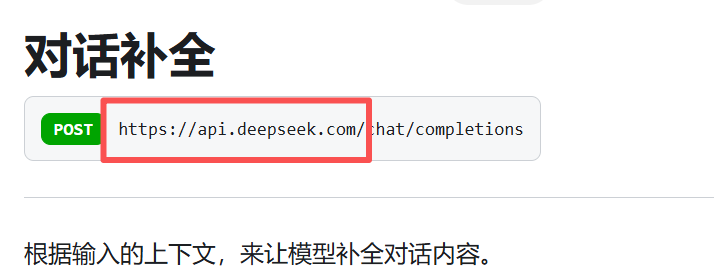
前面这个部分就相当于根端点 相当于endpoint 就初始化这个Base url 相当于就是一个网址
现在最重要的部分就是发送消息时 给模型发送的消息列表要构造好 我们之前介绍了如果用API调用的话 不发送历史消息模型是不知道我们上面的聊天内容的,所以我们要发送历史消息 第一个参数message就是消息列表,第二个参数就是请求参数 比如模型名称 消息列表 温度 token值 是否开启流式响应
相对于deepseek的服务器来说,sdk实际上就是一个http客户端

这里http客户端不需要我们手搓只需要调用第三方库 cpp-httplib的使用 包含这个头文件即可
这时候就跟我们在APIfox演示的一样要设置请求头 请求体


接下来就要设置请求头:
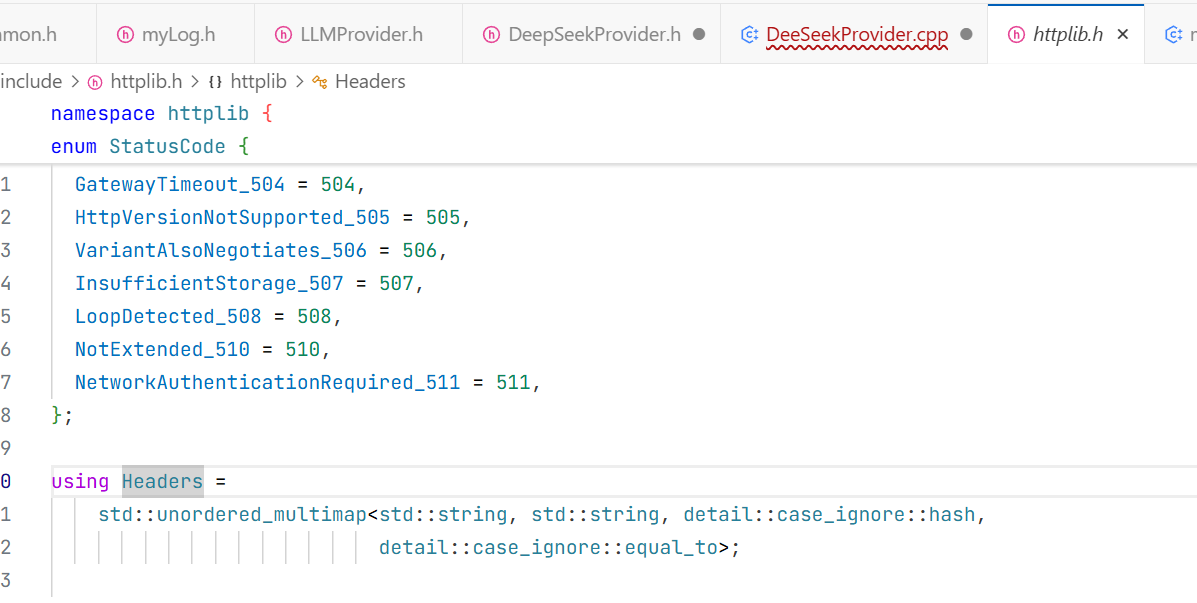
可以看到请求头封装的时候是一个哈希桶来实现的。

都是与接口测试时使用的参数类型是一样的。
解析响应体的实现


这个函数用来解析响应体的。
解析完响应体之后 我们要把返回来的答案解析出来 拿到关键的内容 所以这时候我们就要通过循环解析来拿到这个content。 接下来就要检测响应的json对象是否有content的内容

检测响应的json对象是否包含choices字段 如果包含再检测choices是否为数组,如果为数组检测是否为空 取choices[0]实际也是一个json对象replyconten然后再去当中找message中的content即可。
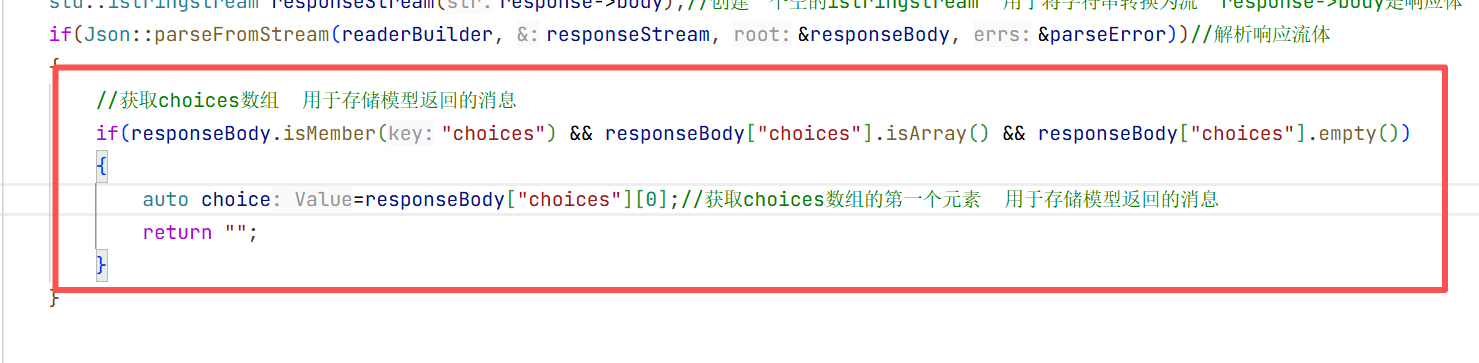
这一层只是获取到choice这部分 后面还要获取message里面的content

此时这一层再去寻找这一部分的主要内容
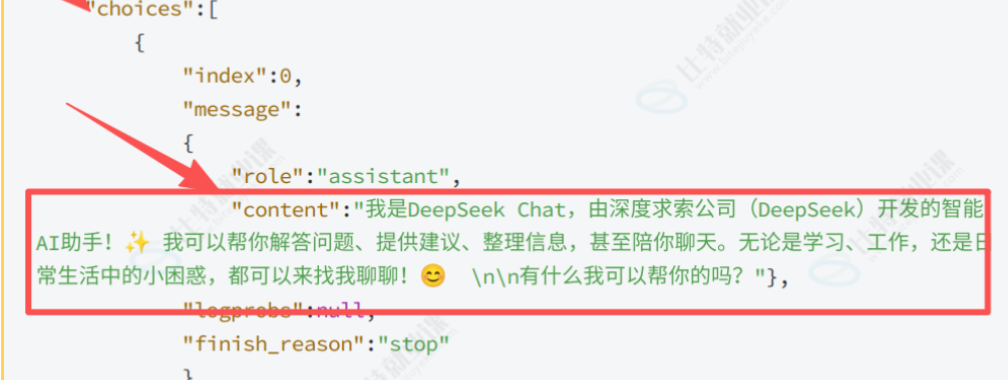

这就是整个解析的过程。
4.发送消息全量返回的测试:
1.测试代码的编写
为了保证代码的整洁 我们把测试代码和sdk文件夹分离开来 重新建立一个文件夹用来测试:
这个文件用来调用和测试大模型的方法 这里我们用gtest框架来进行调试
2.配置环境变量apikey


这里我们不在代码中展示接入大模型的apikey这是很私密的东西 所以我们要测试的话我们把获得到的apikey配置到环境变量中去执行上面的 把环境变量配置到文件中 这样就可以去调用了

这个名字要与你在配置环境变量中的名字要一样
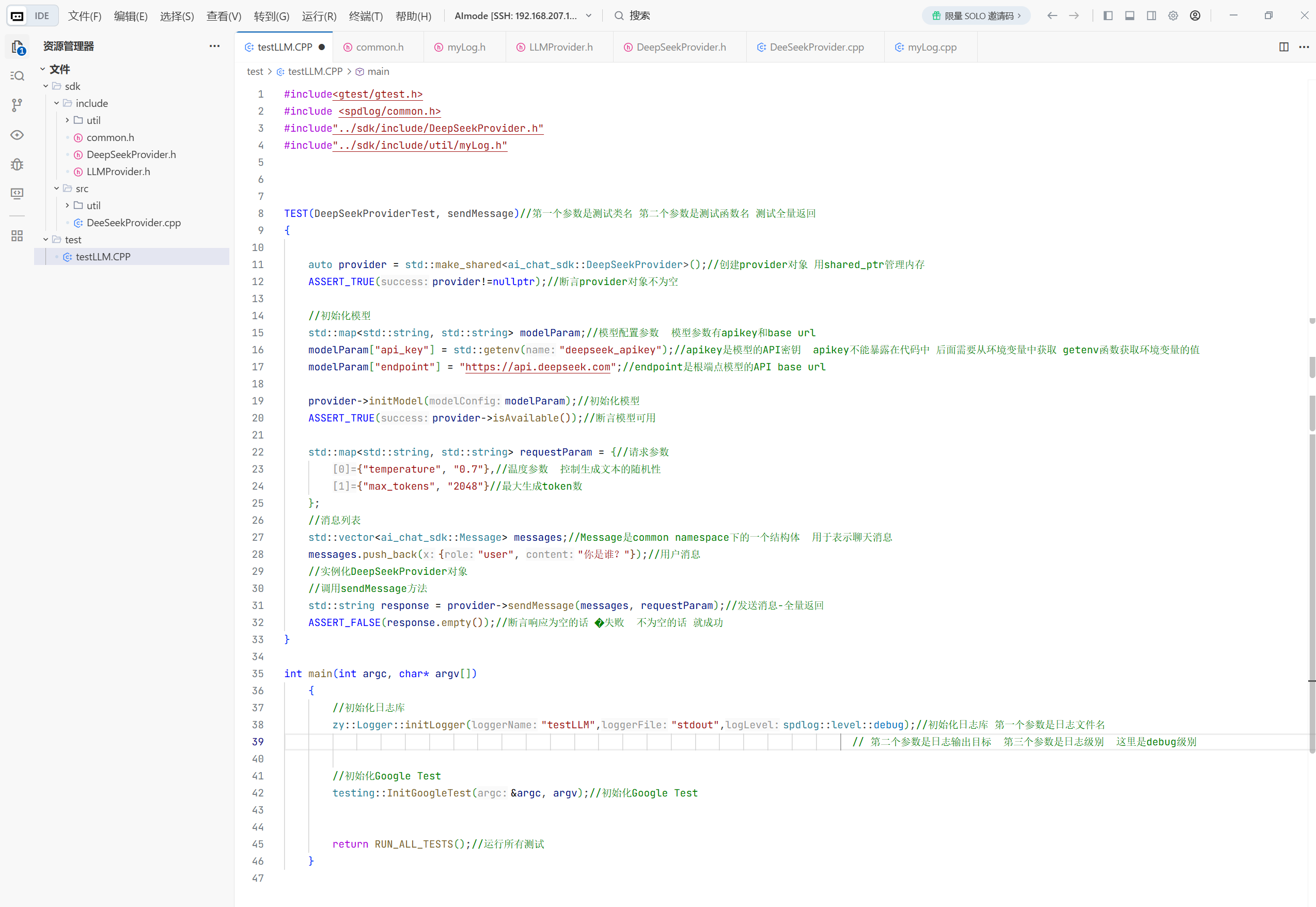
这就是测试发送消息全量返回的测试代码
写完这个代码我们还要去编写CMakeList 这样就可以直接编译然后运行
3.CMakeLists.txt文件的编写:
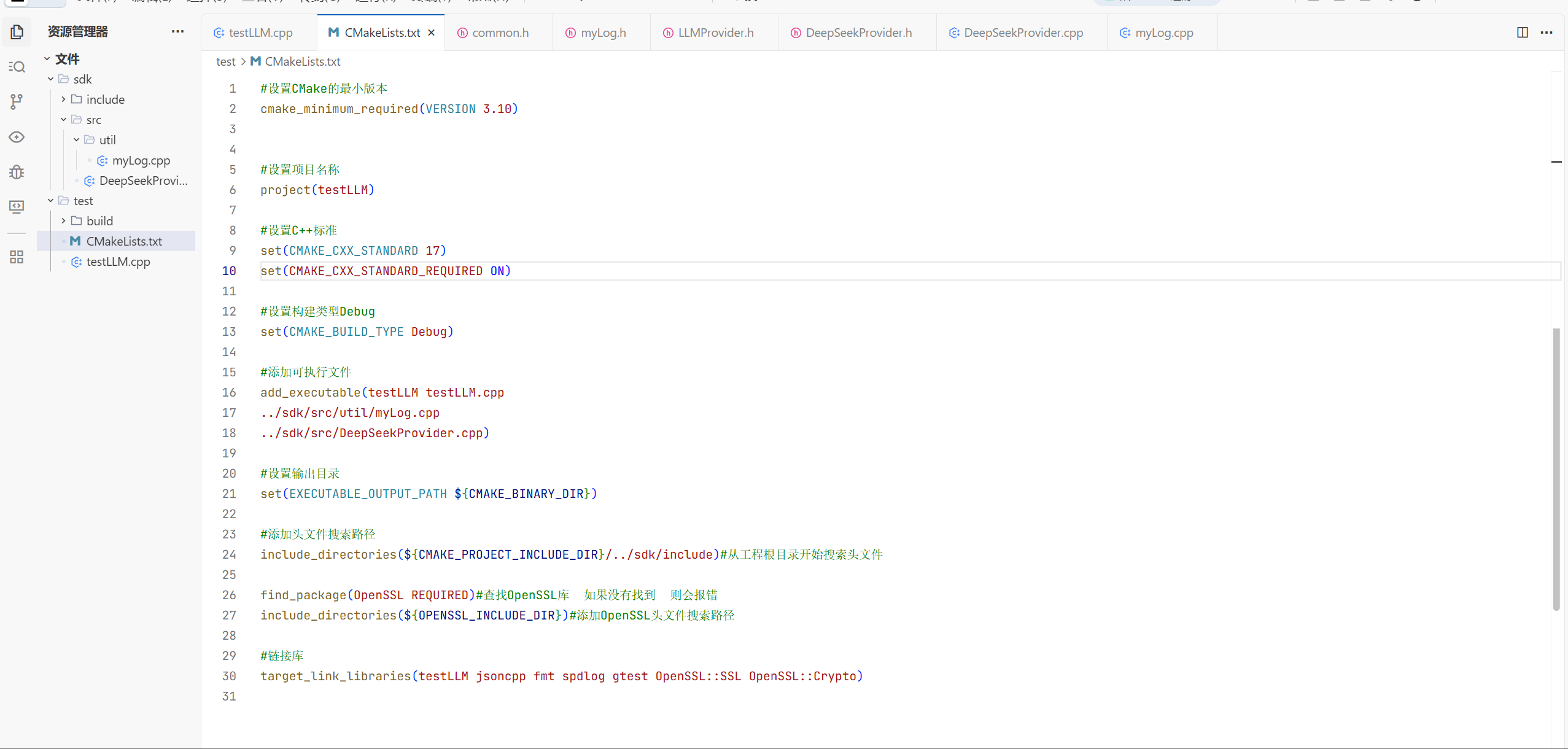
4.测试的问题:
首先进入到test的目录中


再在test目录下创建一个build目录 用来存放我们的测试用例

然后cmake一下去让他找上一个路径的CMakeLists.txt
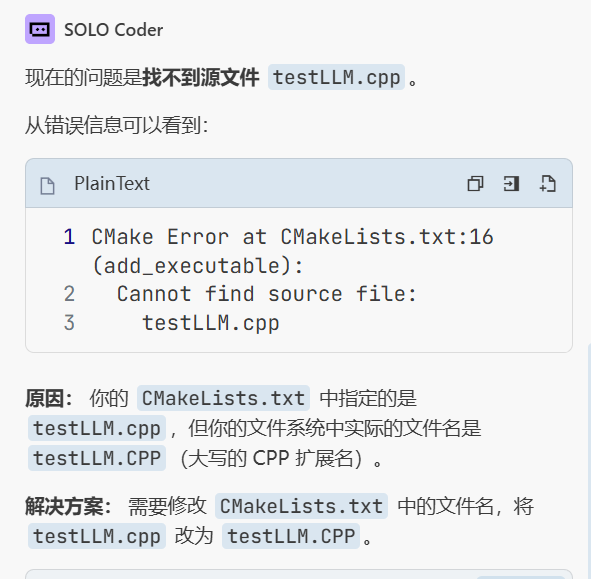
遇到的错误1 把testLLM.cpp拼成了大写的CPP导致编译不出来
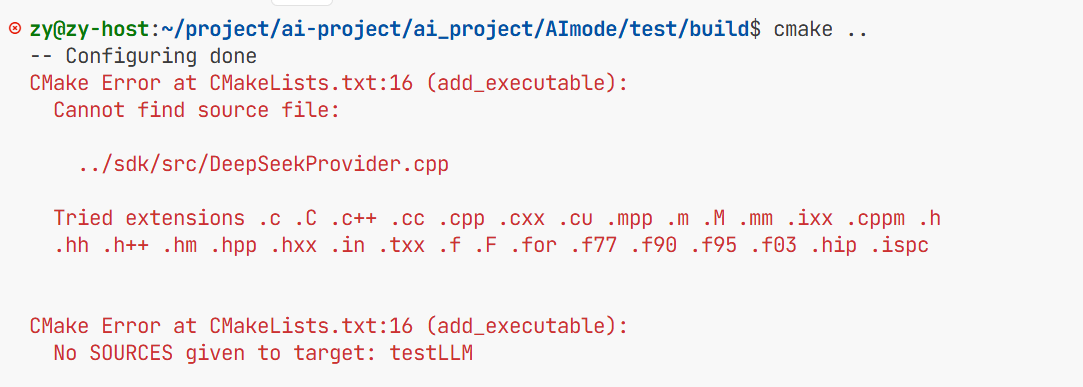
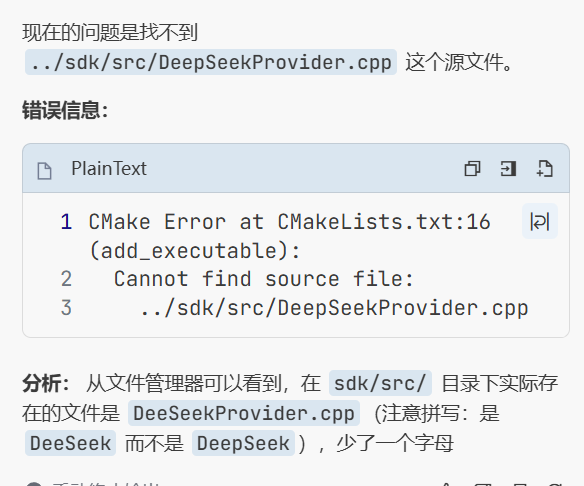
遇到的错误2 把Deepseekprovider.cpp少写了一个p
还要httplib这个默认是不支持http协议的 所以这里我们要将其改一下 让其支持
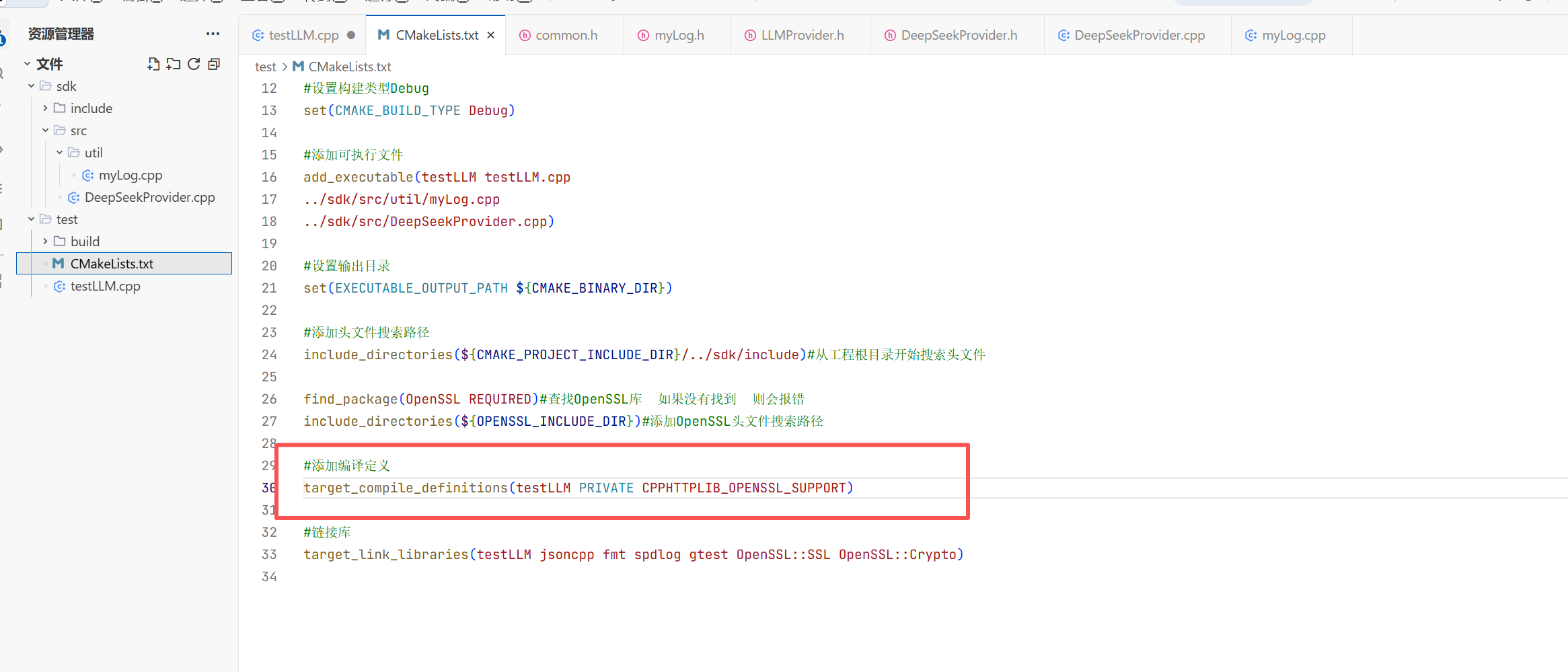
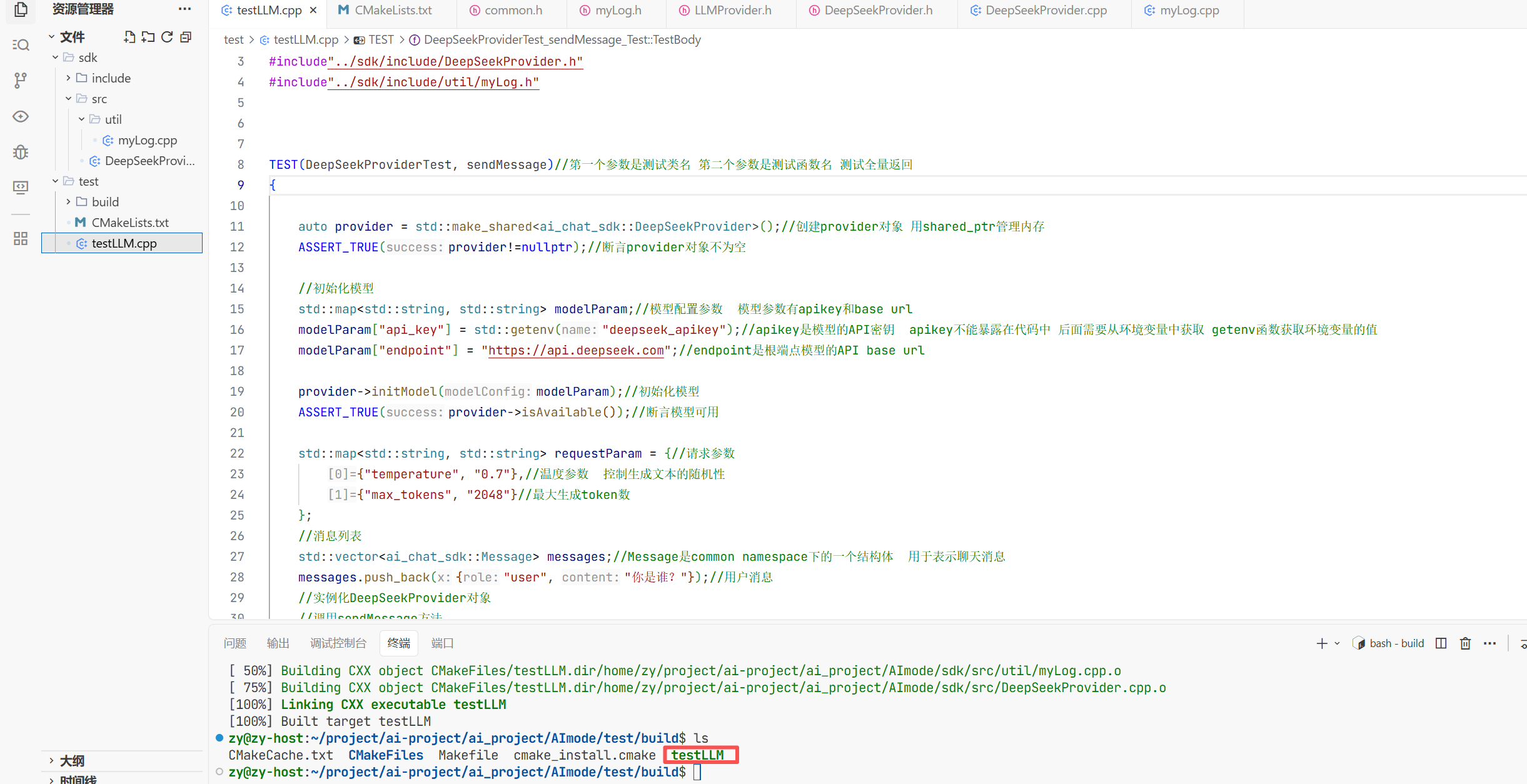
现在我们就成功编译出来了

但当我去./tetsLLM时虽然运行成功了但是报告了段错误根本原因是我没有更改环境变量 而我是直接把这个apikey传进去了
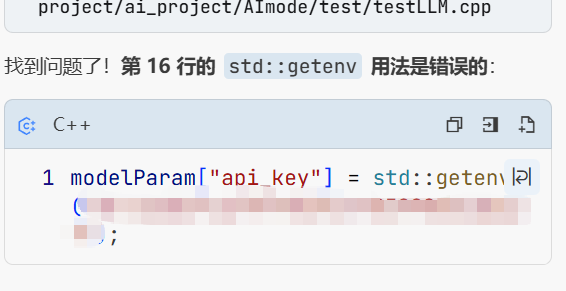
而这个gentenv这个函数是用来获取环境变量中的东西的而我这里环境变量找不到这个玩意 所以报错了
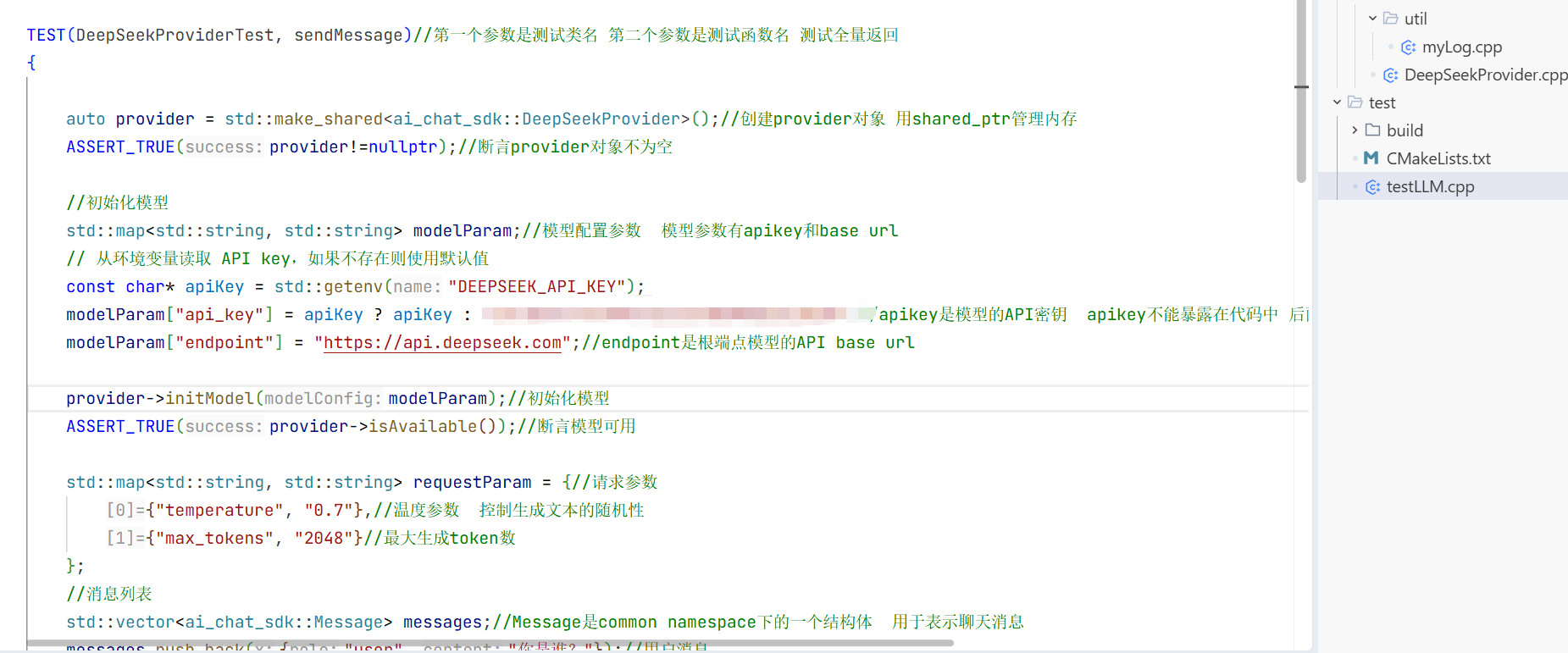
所以这里我直接用三目运算符看看是否存在不存在就显示的传我这个 在我后面把gat和genimi的apikey拿到之后再去把环境变量改掉 用getenv这个函数去隐匿的调用apikey。
这样完成后就能成功调用了
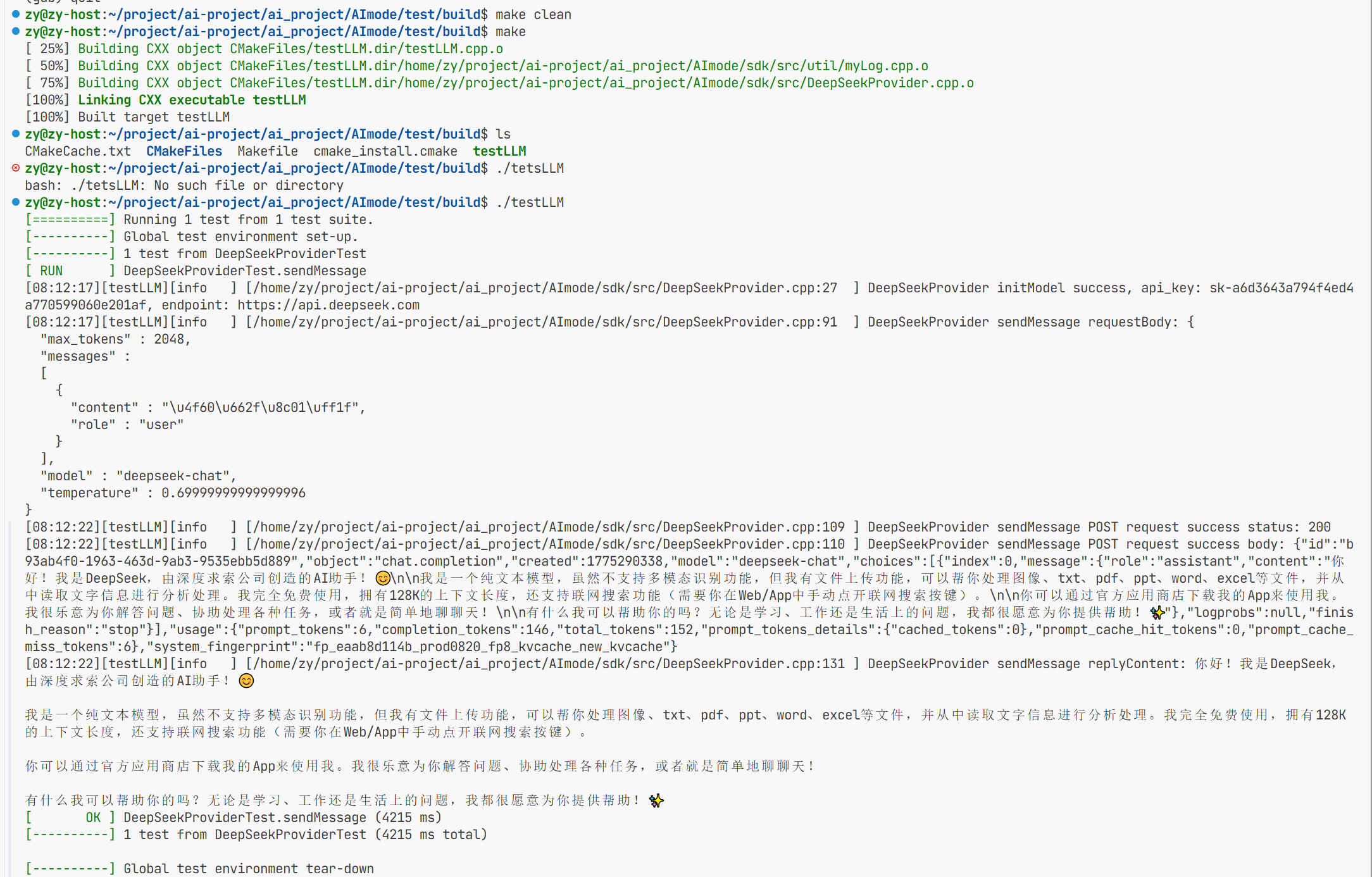

在这个文件目录下的第131行进行返回来的答案进行了解析并打印
这样全量返回的测试就结束了。聊天助手采用全量返回效果不怎么好 如果聊天时要求过多响应时间过长会不好 所以需要流式返回。
#include<gtest/gtest.h>
#include <spdlog/common.h>
#include <unistd.h>
#include"../sdk/include/DeepSeekProvider.h"
#include"../sdk/include/util/myLog.h"
TEST(DeepSeekProviderTest, sendMessage)//第一个参数是测试类名 第二个参数是测试函数名 测试全量返回
{
auto provider = std::make_shared<ai_chat_sdk::DeepSeekProvider>();//创建provider对象 用shared_ptr管理内存
ASSERT_TRUE(provider!=nullptr);//断言provider对象不为空
//初始化模型
std::map<std::string, std::string> modelParam;//模型配置参数 模型参数有apikey和base url
// 从环境变量读取 API key,如果不存在则使用默认值
const char* apiKey = std::getenv("DEEPSEEK_API_KEY");
modelParam["api_key"] = apiKey ? apiKey : "你的apikey";//apikey是模型的API密钥 apikey不能暴露在代码中 后面需要从环境变量中获取 getenv函数获取环境变量的值
modelParam["endpoint"] = "https://api.deepseek.com";//endpoint是根端点模型的API base url
provider->initModel(modelParam);//初始化模型
ASSERT_TRUE(provider->isAvailable());//断言模型可用
std::map<std::string, std::string> requestParam = {//请求参数
{"temperature", "0.7"},//温度参数 控制生成文本的随机性
{"max_tokens", "2048"}//最大生成token数
};
//消息列表
std::vector<ai_chat_sdk::Message> messages;//Message是common namespace下的一个结构体 用于表示聊天消息
messages.push_back({"user", "你是谁?"});//用户消息
//实例化DeepSeekProvider对象
//调用sendMessage方法
std::string response = provider->sendMessage(messages, requestParam);//发送消息-全量返回
ASSERT_FALSE(response.empty());//断言响应为空的话 �失败 不为空的话 就成功
}
int main(int argc, char* argv[])
{
//初始化日志库
zy::Logger::initLogger("testLLM","stdout",spdlog::level::debug);//初始化日志库 第一个参数是日志文件名
// 第二个参数是日志输出目标 第三个参数是日志级别 这里是debug级别
//初始化Google Test
testing::InitGoogleTest(&argc, argv);//初始化Google Test
return RUN_ALL_TESTS();//运行所有测试
}
5.发送消息的实现(流式返回)
流式响应:
1.http协议:
两次请求与响应之间是没有任何交集的
HTTP协议是严格的"请求-响应"模型,永远是客⼾端发起请求,服务器才能响应,服务器就像个"哑
巴",它知道更多内容,但是它⽆法主动告诉你。这种⼀问⼀答的模式对于⼤部分⽹⻚浏览器、数据提 交等场景已经⾜够了。
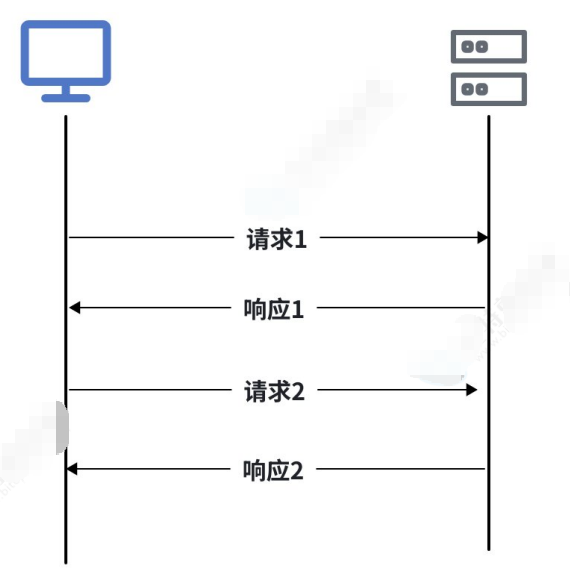
但是有些场景下,服务器需要主动向客⼾端推送⼀些实时数据,⽐如,在看体育直播时,服务器要及 时将⽐赛分数、⾦球球员等信息推送给客⼾端;在多⼈在线游戏中,服务器需要实时同步玩家的操作 和游戏状态;在使⽤导航类应⽤时,服务器需要实时推动导航信息等。
⼤佬们也发现这个问题了,在2004年的时候Ian Hickson就提出了SSE概念,Opera浏览器是第⼀个⽀ 持SSE的,2011年开始,⼀些主流浏览器(Chrome、Firefox、Safari)开始逐步⽀持SSE,2015年时 SSE规范才正式成为W3C的标准。
说白了我们需要实时更新时 不需要与客户端交互 只要发生变化就需要发送给我 所以我们这里就可以才用轮询的方式 其实也不是客户端主动发数据给我们 只是我们循环要求他不断输出数据
这样的话可能会导致很多无效的访问且可能都不是时时的消息。
2.SSE协议:
SSE是Server Send Event的缩写,即服务器发送事件,是建⽴在HTTP协议之上的开发标准,允许服务器主动向客⼾端(如浏览器)推送实时数据。

所以这种协议非常适合大模型这种实时推送数据
SSE通过单⼀的持久连接实现数据的实时传输,客⼾端⽆需频繁发起请求。
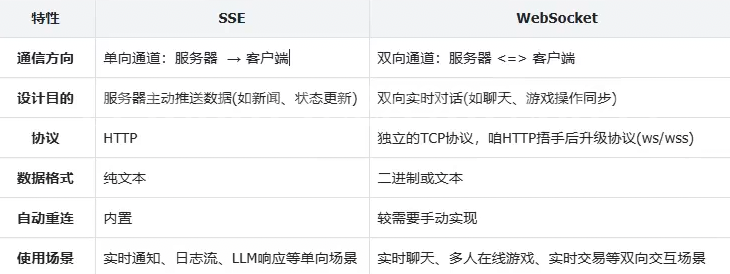
SSE协议特点
•
单向通信:服务器可以主动推送数据到客⼾端,但客⼾端⽆法直接通过SSE向服务器发送数据
•
基于HTTP协议:SSE使⽤标准的HTTP协议,⽆需额外的协议或端⼝配置,兼容性好易于实现
•
轻量级:SSE的实现更简单,代码量少,适合简单的实时数据推送场景
•
⾃动重连:如果连接断开,浏览器会⾃动尝试重新连接,⽆需开发者⼿动处理重连逻辑
•
⽀持事件类型:服务器可以发送不同类型事件,客⼾端可以根据事件类型执⾏不同的操作
•
⽀持消息ID:每条消息可以包含⼀个唯⼀的ID,⽤于断线重连后恢复消息流
数据格式:
每个事件可以包含以下字段:
•
data:消息内容(必须)•
event:事件类型(可选)
•
id:消息ID(可选)
•
retry:重连时间(可选,单位:毫秒)
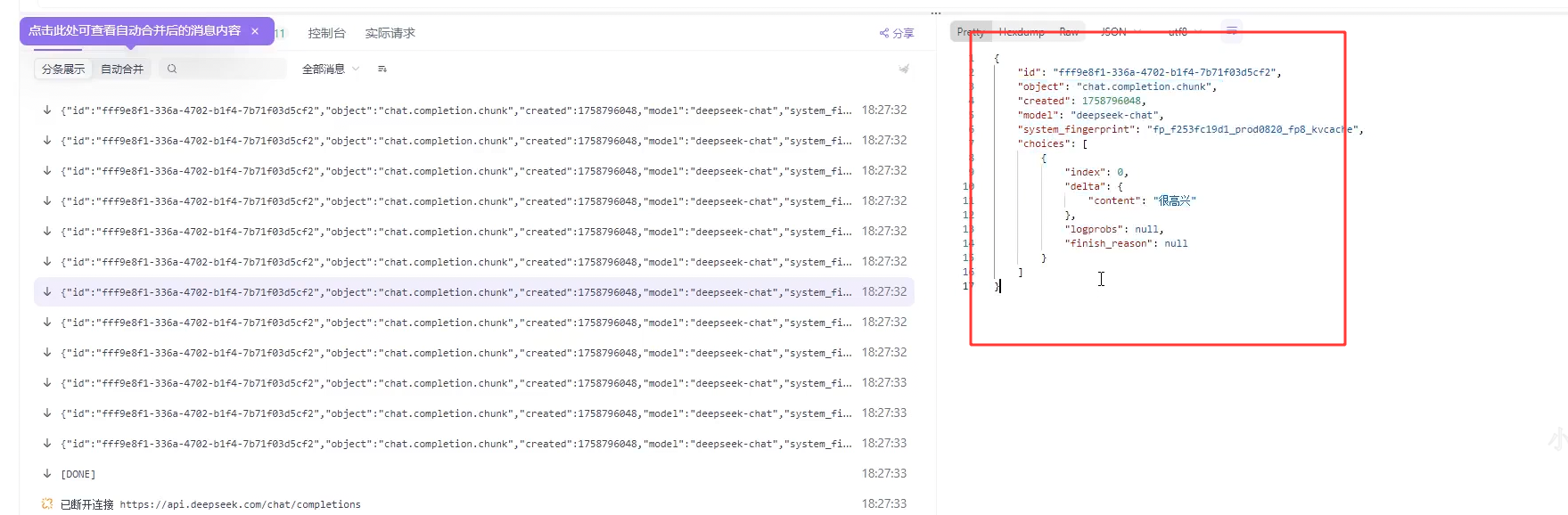
代码块
data: Hello, world!
event: message
id: 123
retry: 10000
data: Another message
每条消息以两个换⾏符 (\n\n) 结束,消息流传输完毕后会有专⻔的结束标记,不同实现结束标记不
同,⽐如data: [DONE]。
前⾯我们演⽰向DeepSeek、ChatGPT、Gemini等⼤模型提问时,这些⼤模型并不是⼀次性将完整回 答丢给⽤⼾,⽽是服务器边思考,边主动将思考结果吐(推送)给⽤⼾的,就和打字⼀样⼀点点输出,⽤⼾不需要⻓时间的等待,能及时看到服务器响应的结果,体验⽐较好,这种⽅式称为流式响应。SSE推 出后实际不温不⽕,⼤模型爆⽕后,正式⼤模型场景的需要,SSE协议就爆⽕了
SSE协议你客户端不发送请求 服务器不会主动给客户端发送协议
3.WebSocket协议
SSE协议有⼀个缺陷就是单向传输,即数据只能由服务器给客⼾端推送,在新闻推送、股票⾏情、体育⽐分等场景是⽐较合适的,因为这些场景客⼾端⽆需给服务器发数据。
但有些场景SSE就束⼿⽆策了。⽐如:你在你们宿舍的微信群⾥发了⼀个消息"谁去⻝堂帮我捎个饭", 服务器收到后需要"谁去⻝堂帮我捎个个饭"这条消息主动推送给群中其他⼈,其他⼈收到消息后,就 需要发消息回应你⽽不是不闻不问。此处由舍友回复"滚犊⼦",那服务器收到后⼜要推送给其他⼈... 该场景中,不仅需要服务器主动给客⼾端推送消息,也需要客⼾端给服务器发送消息。这种场景下 WebSocket协议就派上⽤场了。

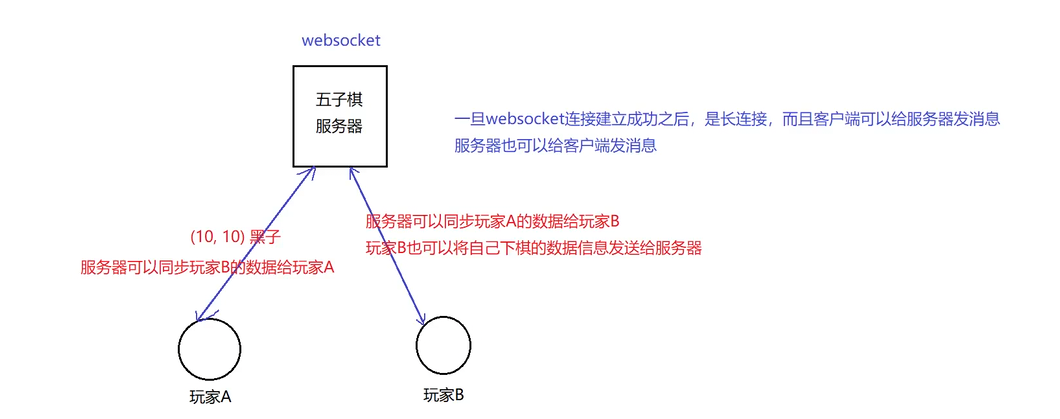
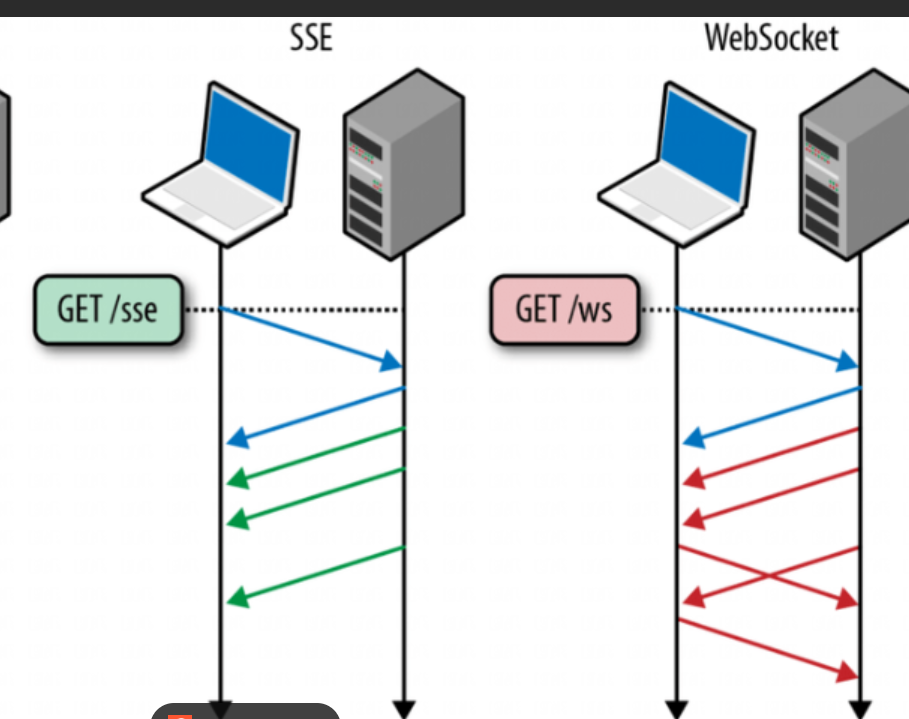
为什么DeepSeek的助⼿消息使⽤SSE,不使⽤websocket?
答:⼤模型的回复是服务器向客⼾端推送数据的单项数据流,在此期间客⼾端不需要给⼤模型服务器 发送消息,⽽SSE刚好是服务器主动单项给客⼾端推送数据,并且实现简单⾼效,因此⼤模型回复通常都使⽤SSE协议。而HTTP协议不记得上次问的内容所以也不用HTTP协议
4.了解HTTP的请求参数
HTTP普通响应体和流式响应体
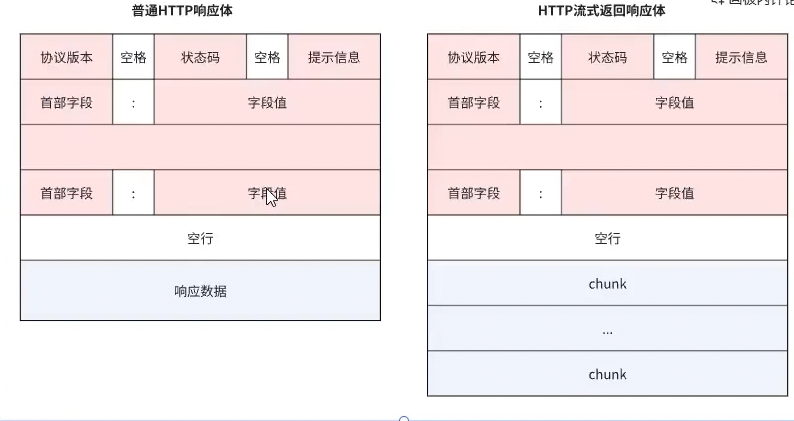
普通HTTP响应体中,⼀个响应包含⼀个响应头和⼀个响应体,
在HTTP流式返回响应体中,⼀个响应包含⼀个响应头和多个响应块。在流式返回时,会先返回响应 头,然后在逐个返回各个响应体,因此在发送流式响应时,需要在请求参数中告知HTTP服务器,响应 头和chunk该如何处理。

按住ctrl然后点击httplib调用的函数就能进入转到他定义的地方了

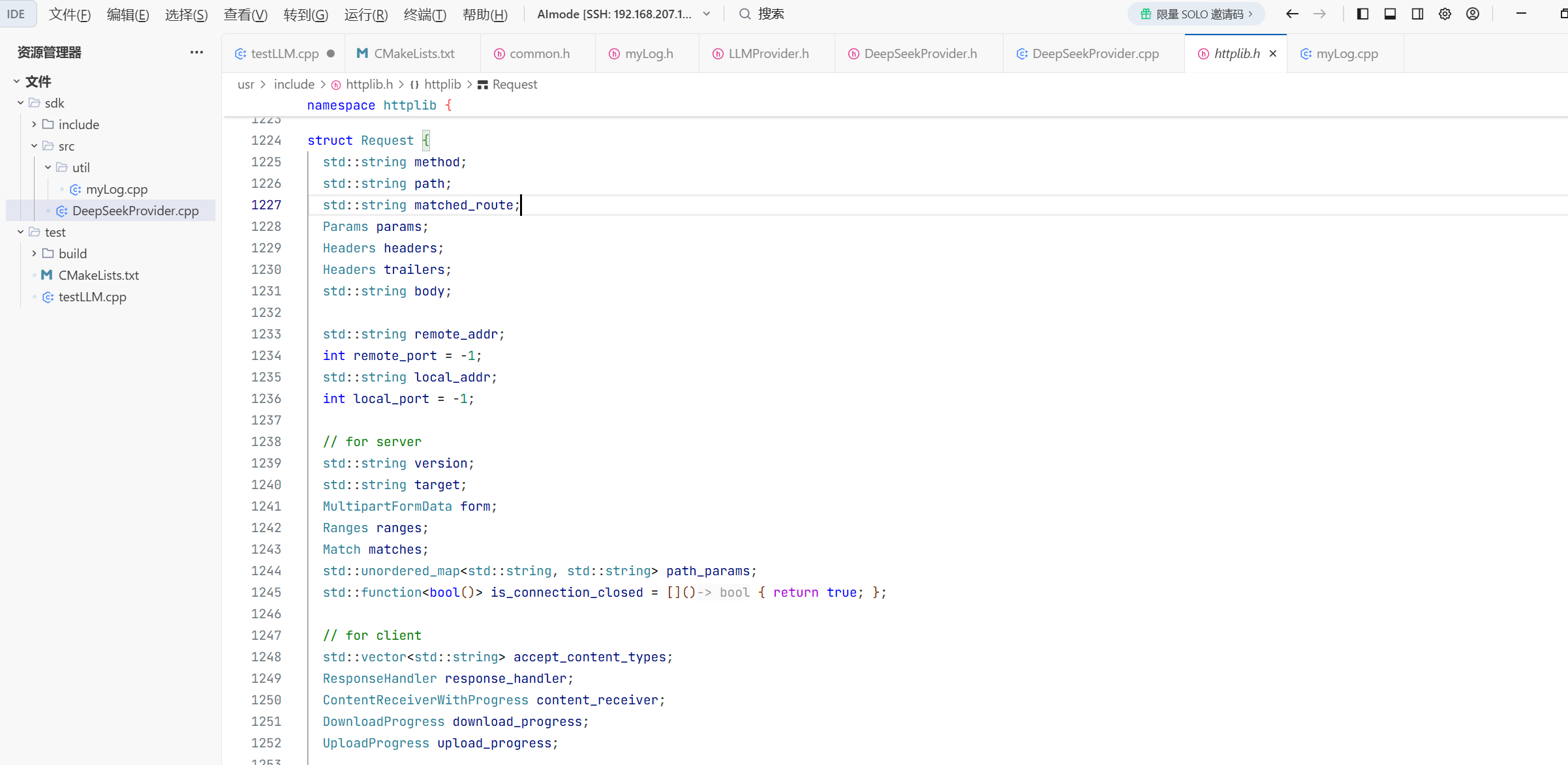
这就是所需要的参数
struct Request {
// 通⽤参数
std::string method; // 请求⽅法,GET、POST等
std::string path; // 资源路径,URL中域名之后的部分,⽐如:/api/users
Headers headers; // HTTP请求头,类型为 multimap<string, string>
std::string body; // HTTP请求体 存放服务器请求参数
// 查询参数:
Params params; // 查询参数,类型为 multimap<string, string>
//一般附加在URL的末尾 用于向服务器传输一些额外的数据
//比如查询商品的价格降序排序 这些都是查询参数 而不是路径
// 路径参数或路由参数, 类型为 unordered_map<string, string>
std::unordered_map<std::string, std::string> path_params;//是URL的变量部分,用于动态获取URL中特定的段落值 功能:比如获取指定用户的谋篇文章 GET/api/users_id/posts/post_id
// for client
ResponseHandler response_handler;//响应处理器 是一个函数包装器 对应满足条件的函数进行包装
ContentReceiverWithProgress content_receiver;//内容接收器 类型也是一个函数包装器
//content type 请求方式
};

response_handler 为响应处理回调函数,实际类型为 std::function<void(const
Response&)> ,如果发起请求时设置该函数,当客⼾端收到完整的HTTP响应头和⼀些体(如果存在) 后,会调⽤该函数,并传⼊构造好的Response对象。
content_recevier 内容接收回调函数,是处理流式处理响应的关键,类型为:
function<bool(const char* data, size_t len, uint64_t offset, uint64_t total)>
◦
data:指向当前接收到的数据块的指针
◦
len: 当前数据块的⻓度
◦
offset: 当前数据块在请求体中的偏移量
◦
total: 请求体的总⻓度
◦
返回值:true表⽰继续接收数据,false表⽰停⽌接收数据
设置该回调函数后,客⼾端不会等待整个响应体传输完再存到response.body中,⽽是每收到⼀⼩块
数据就⽴刻调⽤该回调函数,处理实时数据,
5.基本的实现
总的来说流式返回比全量返回多的是传一个stream,还有解析请求体的返回不一样 ,还要服务器返回一块数据后要定义一个数据处理的方式也就要解析传过来的内容

这就是基本设置这七个设置跟全量返回是差不多的只是改动了画方括号的地方
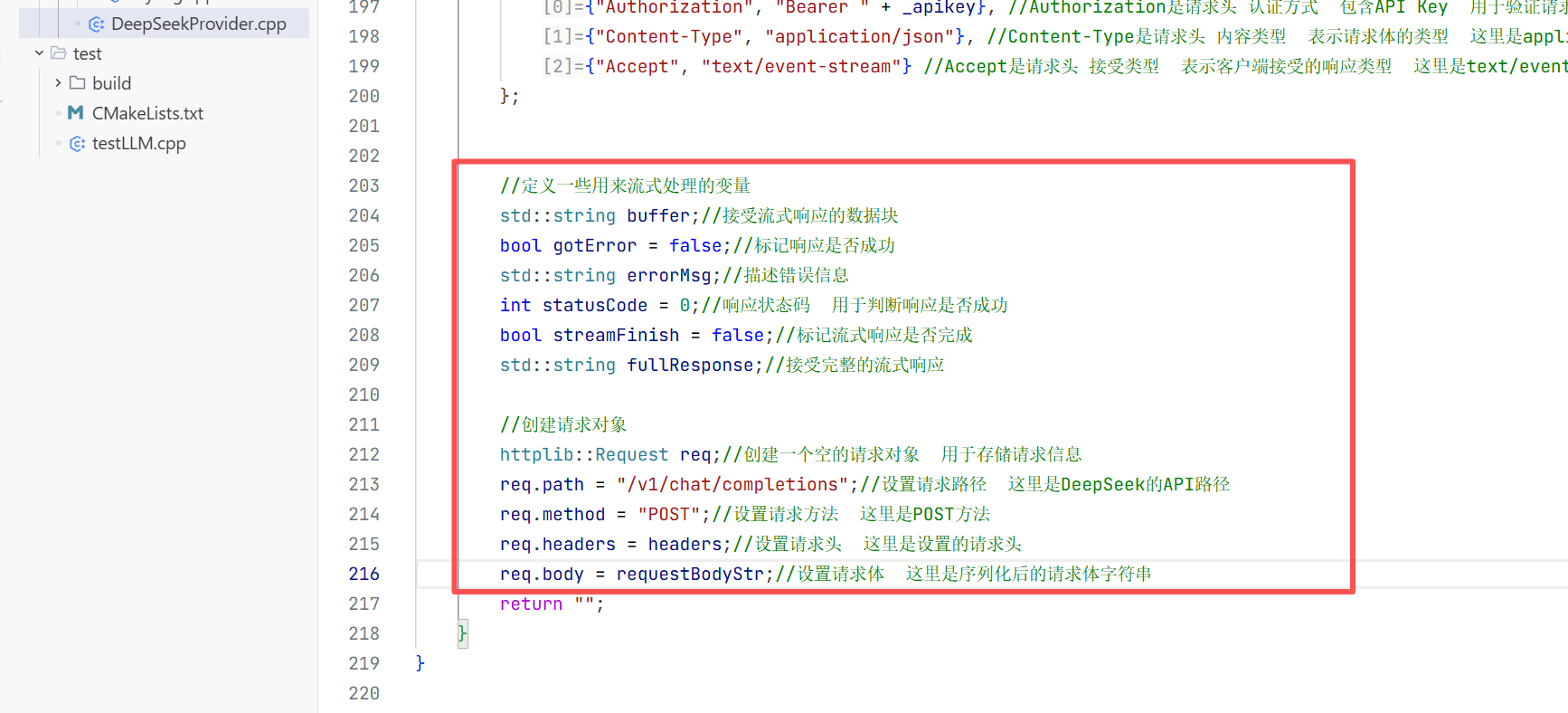
发送请求时与全量返回不一样的是这里需要在外边创建变量和对象 这样方便
6.响应处理器的实现

7.数据接受处理器的实现

因为是首个字段再加两个\n\n才到下一个字段 所以当我们截取第一个字段后 再加上两个字符从这个位置再去截取我们需要的内容

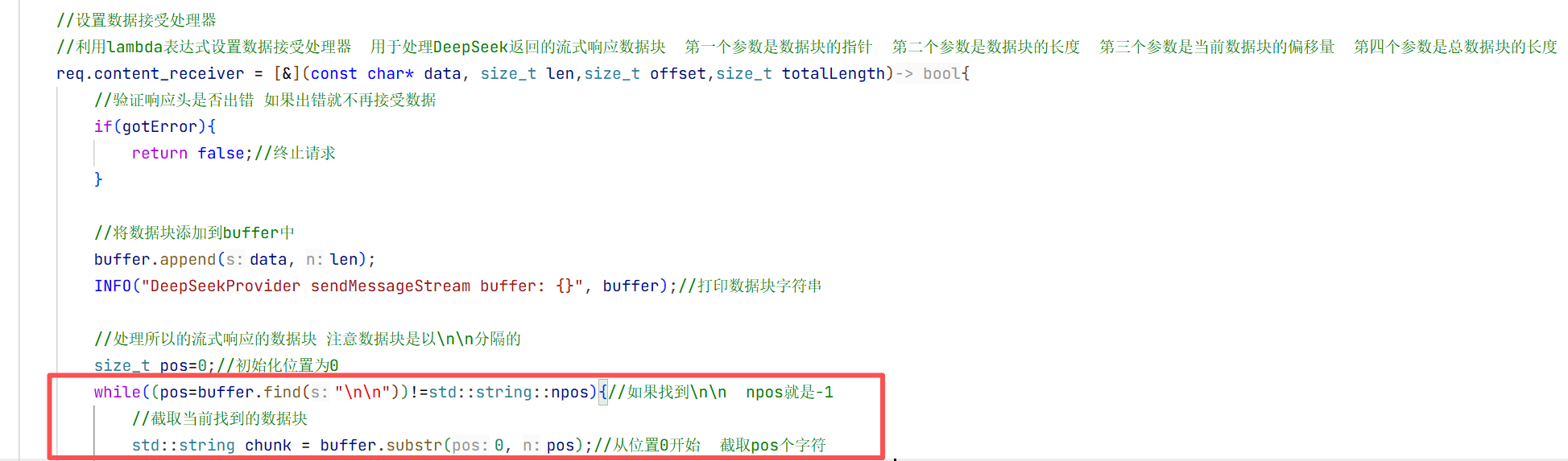
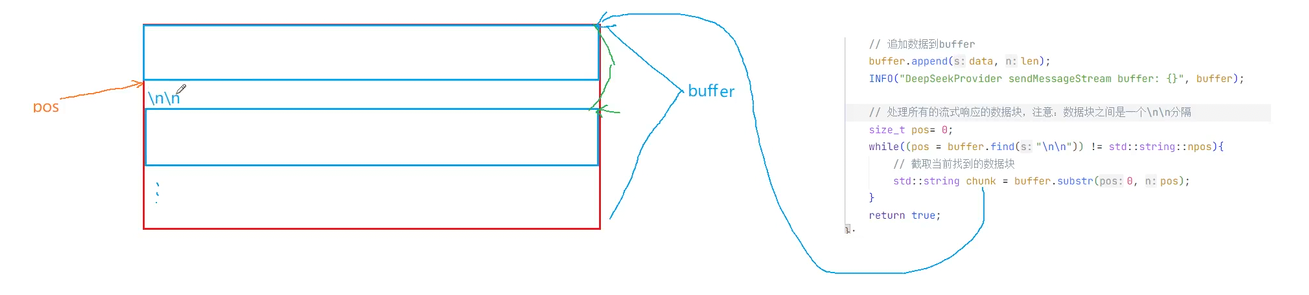
块和块之间用了两个\n去做分割 所以我们截取我们要的信息时要去把那两个\n\n给去掉

删除之后新buffer就是这个
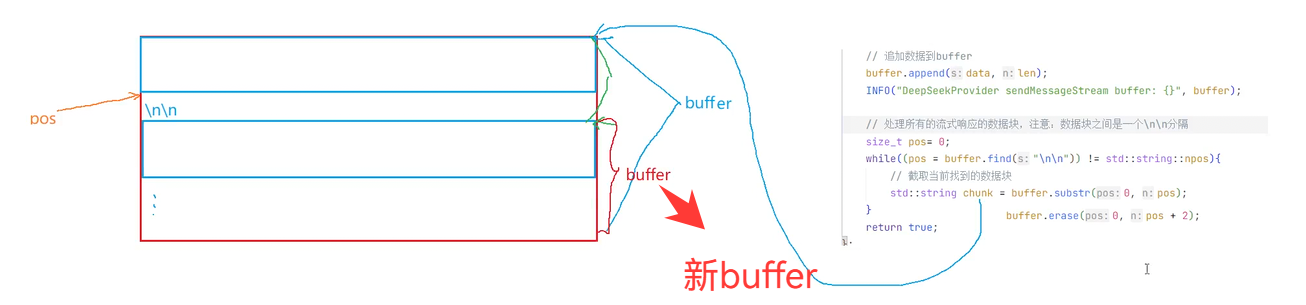
再去处理掉空行和注释

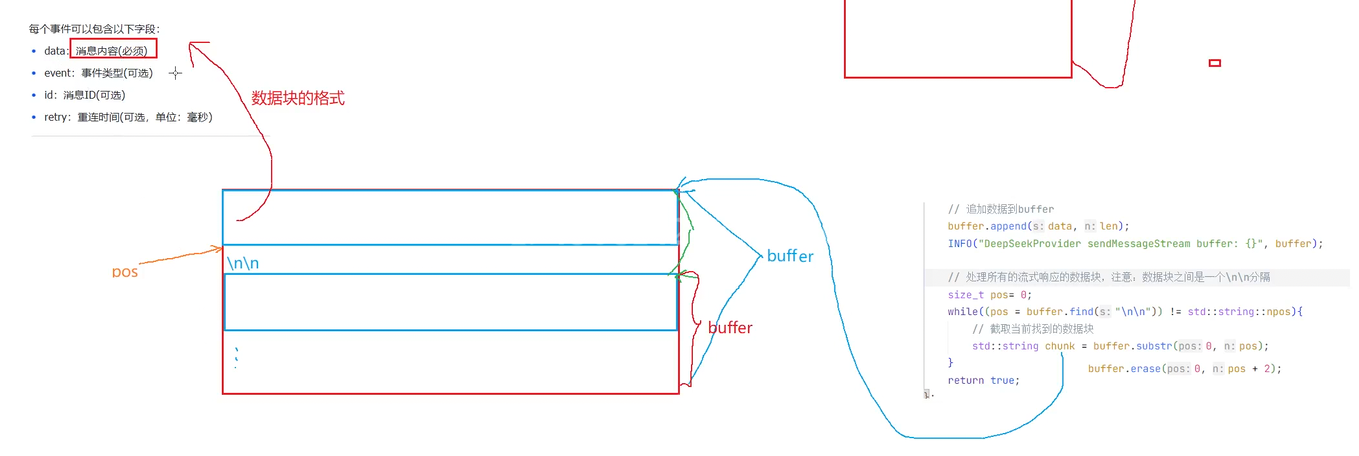
我们模型返回的消息存储在数据块中data : 的后面 所以我们要去拿取这个有效数据

如果前六个字符是data冒号空格 说明后面的就是我们需要的有效数据

光光到这还没有结束
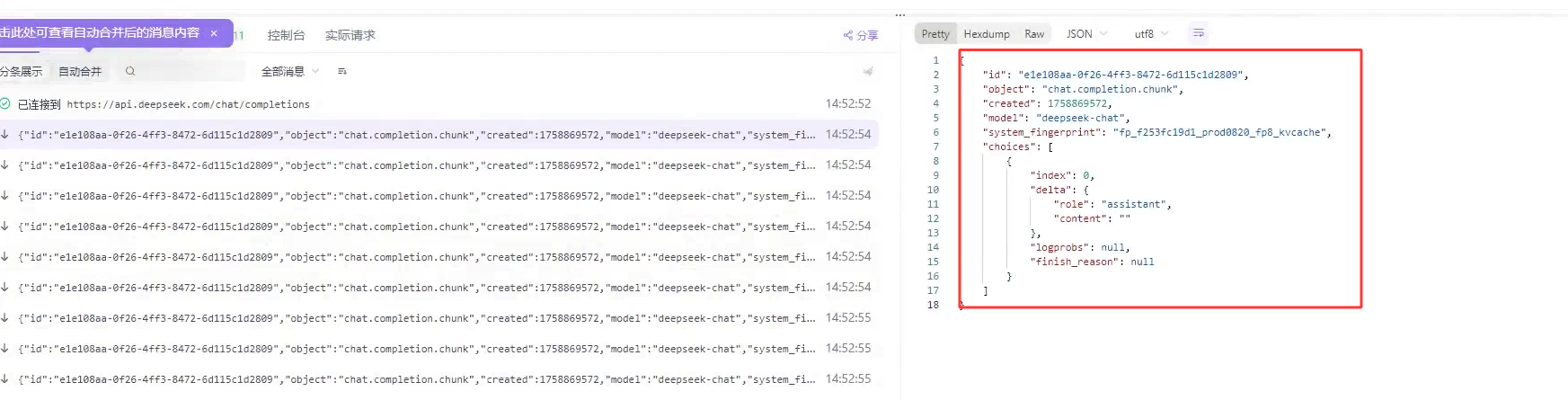
我们还要去反序列化 才能拿到这样的结果

此时我们就拿到反序列化的数据了
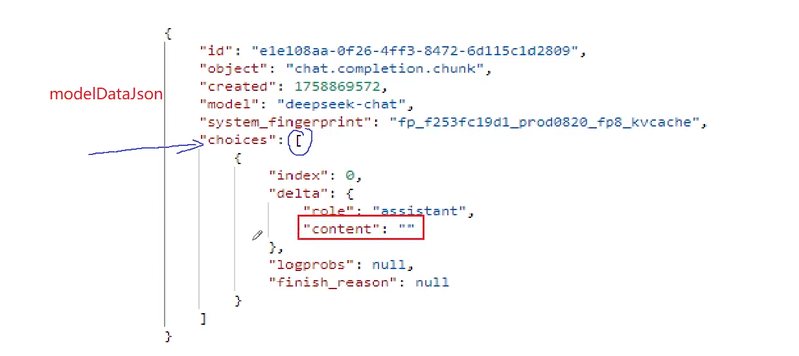
整个数据存储在modelDateJson中所以现在我们要去验证是否有choices这个数组 然后choices是否有元素 如果不为空就返回了内容就去拿第0个位置的元素
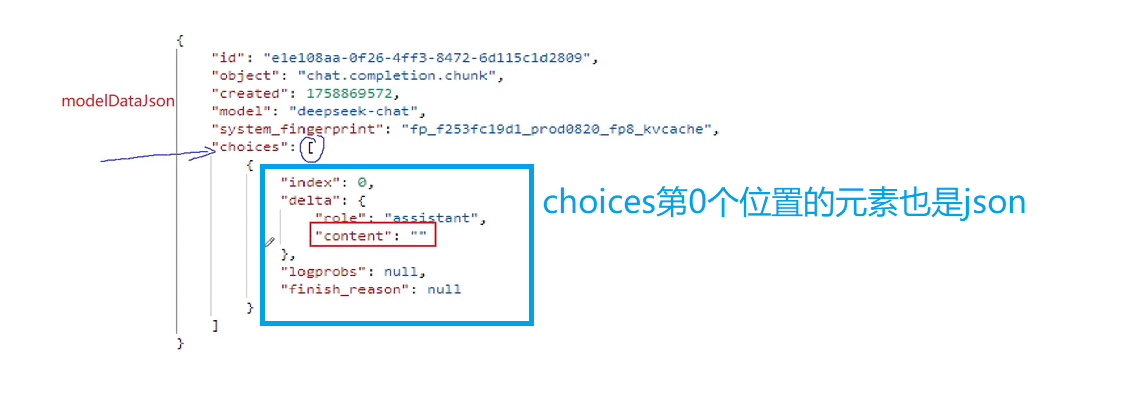
再去看这个json对象是否有delta这个字段 这个字段也是一个json对象 在这个delta看看是否包含conten 如果有就拿出来 这样就是我们想要的内容 就是一层套娃再套娃
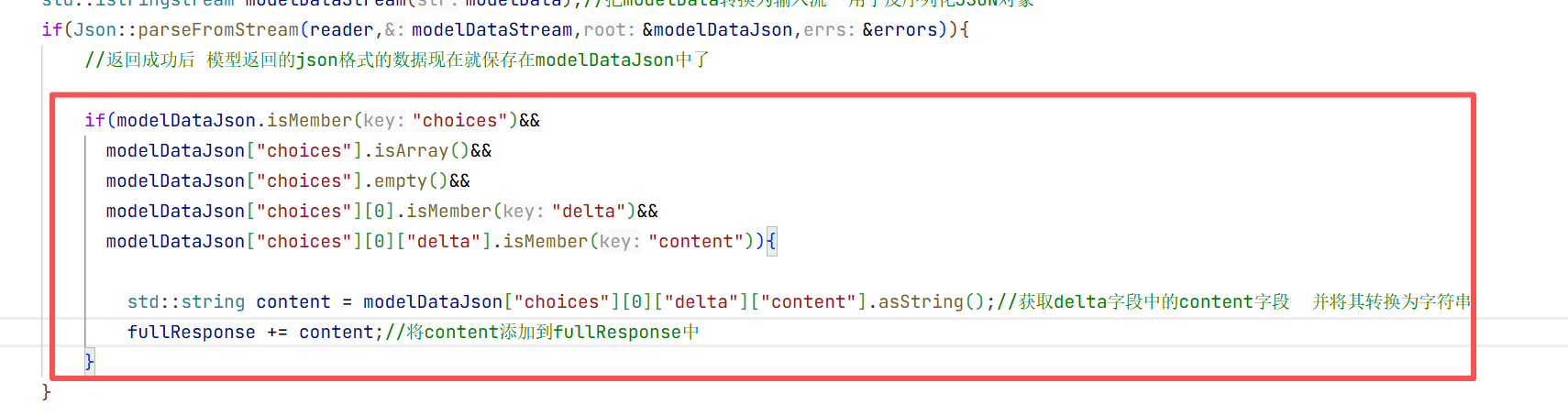
这个就是整个套娃的过程
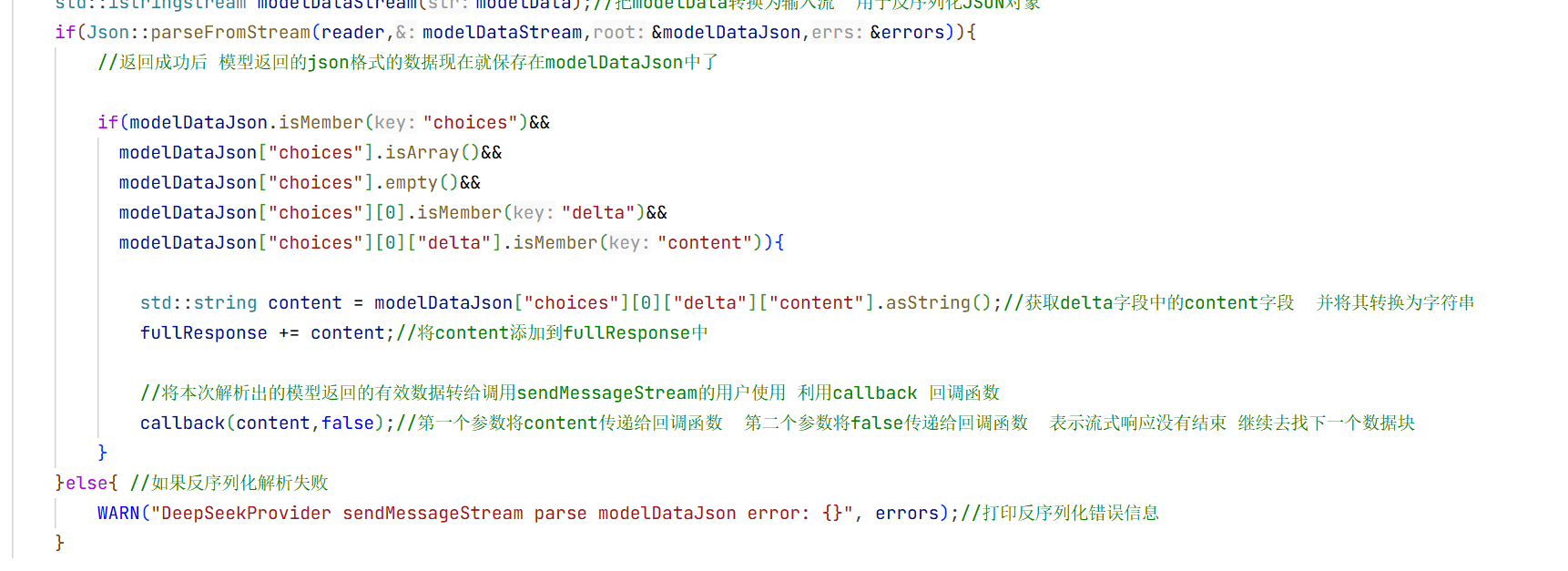

这就是整个数据接受处理器的实现
8.给模型发送请求:


明明我们上面设置了响应处理器的时候已经对结果进行了检测 那这里是在检测什么呢?
这两个检测是不一样的 在使用send这个方法时 send函数默认情况下是阻塞的,阻塞的机制适合小文件处理 简单API请求,一旦在Request中的content_receiver中设置之后send就是非阻塞的
一般适合流式响应和大文件的下载



所以在这里我们也要去检查返回值看看send目前是阻塞状态还是非阻塞状态
响应处理器只会响应一次 后后续由接收器去响应
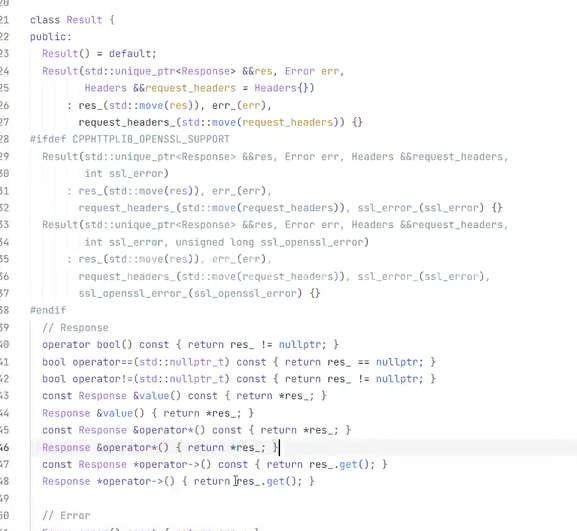
client的返回值是返回的是一个result对象

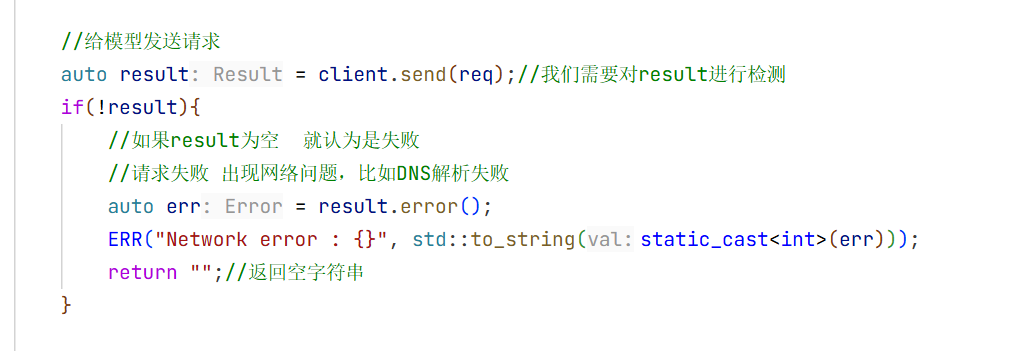
这就是整个流式返回的实现
//发送消息-流式返回
std::string DeepSeekProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& requestParam,
std::function<void(const std::string&, bool)> callback)//function是回调函数 callback:对模型返回的增量结果进行处理 第一个参数是增量数据
// 第二个参数是是否是最后一个增量
{
//发送消息-流式返回
//1.检测模型是否可用
if(!isAvailable())//如果模型不可用 就返回空字符串
{
ERR("DeepSeekProvider sendMessageStream model not available");//打印模型不可用错误信息
return "";
}
//2.构造请求参数
double temperature = 0.7;
int maxTokens = 2048;
//去找requestParam中是否有temperature和max_tokens参数 有就使用用户提供的参数值 没找到就使用默认值
if(requestParam.find("temperature") != requestParam.end()){
temperature = std::stod(requestParam.at("temperature"));//stod是将字符串转换为double类型
}
if(requestParam.find("max_tokens") != requestParam.end()){
maxTokens = std::stoi(requestParam.at("max_tokens"));//stoi是将字符串转换为int类型
}
//3.构造历史消息
Json::Value messagesArray(Json::arrayValue);//创建一个空的数组 用于存储历史消息
for(const auto& message : messages){//遍历messages向量 每个消息都添加到数组中
Json::Value messageObject;//创建一个空的对象
messageObject["role"] = message._role;//role是消息的角色 有user、assistant、system三种角色
messageObject["content"] = message._content;//content是消息的内容
messagesArray.append(messageObject);//将消息对象添加到数组中
}
//4.构造请求体
Json::Value requestBody;//创建一个空的对象 用于存储请求体
requestBody["model"] = getModelName();//获取模型的名称
requestBody["messages"] = messagesArray;//messages是历史消息数组 用于存储历史消息
requestBody["temperature"] = temperature;//temperature是温度参数 用于控制模型的随机性
requestBody["max_tokens"] = maxTokens;//max_tokens是最大token数 用于控制模型的输出长度
requestBody["stream"] = true;//stream是流式参数 用于控制是否返回流式结果
//5.序列化
Json::StreamWriterBuilder writeBuilder;//创建一个空的构建器 用于将Json::Value转换为字符串
writeBuilder["indentation"] = " ";//设置缩进为2个空格
std::string requestBodyStr = Json::writeString(writeBuilder, requestBody);//将Json::Value转换为字符串builder
INFO("DeepSeekProvider sendMessageStream requestBody: {}", requestBodyStr);//打印请求体字符串
//6。使用HTTPlib创建客户端
httplib::Client client(_endpoint.c_str());//创建一个HTTP客户端 用于发送HTTP请求 把根端点告诉客户端 客户端会根据根端点去发送请求
client.set_connection_timeout(30,0);//设置连接超时时间为30秒 0表示不设置超时时间
client.set_read_timeout(300,0);//设置读取超时时间为300秒(流式返回时需要设置为较大值) 0表示不设置超时时间
//7.设置请求头
httplib::Headers headers={
{"Authorization", "Bearer " + _apikey}, //Authorization是请求头 认证方式 包含API Key 用于验证请求
{"Content-Type", "application/json"}, //Content-Type是请求头 内容类型 表示请求体的类型 这里是application/json
{"Accept", "text/event-stream"} //Accept是请求头 接受类型 表示客户端接受的响应类型 这里是text/event-stream
};
//定义一些用来流式处理的变量
std::string buffer;//接受流式响应的数据块
bool gotError = false;//标记响应是否成功
std::string errorMsg;//描述错误信息
int statusCode = 0;//响应状态码 用于判断响应是否成功
bool streamFinish = false;//标记流式响应是否完成
std::string fullResponse;//接受完整的流式响应
//创建请求对象
httplib::Request req;//创建一个空的请求对象 用于存储请求信息
req.path = "/v1/chat/completions";//设置请求路径 这里是DeepSeek的API路径
req.method = "POST";//设置请求方法 这里是POST方法
req.headers = headers;//设置请求头 这里是设置的请求头
req.body = requestBodyStr;//设置请求体 这里是序列化后的请求体字符串
//设置响应处理器
//利用lambda表达式设置响应处理器 用于处理DeepSeek返回的流式响应
req.response_handler = [&](const httplib::Response& res){
if(res.status != 200){ //如果响应状态码不是200 就认为是失败
gotError = true;
errorMsg = "HTTP status code: " + std::to_string(res.status);
return false;//终止请求
}
return true; //继续接受流式响应数据块
};
//设置数据接受处理器
//利用lambda表达式设置数据接受处理器 用于处理DeepSeek返回的流式响应数据块 第一个参数是数据块的指针 第二个参数是数据块的长度 第三个参数是当前数据块的偏移量 第四个参数是总数据块的长度
req.content_receiver = [&](const char* data, size_t len,size_t offset,size_t totalLength){
//验证响应头是否出错 如果出错就不再接受数据
if(gotError){
return false;//终止请求
}
//将数据块添加到buffer中
buffer.append(data, len);
INFO("DeepSeekProvider sendMessageStream buffer: {}", buffer);//打印数据块字符串
//处理所以的流式响应的数据块 注意数据块是以\n\n分隔的
size_t pos=0;//初始化位置为0
while((pos=buffer.find("\n\n"))!=std::string::npos){//如果找到\n\n npos就是-1
//截取当前找到的数据块
std::string chunk = buffer.substr(0, pos);//从位置0开始 截取pos个字符
buffer.erase(0, pos+2);//删除buffer中从位置0开始的pos+2个字符 因为\n\n是2个字符
//解析该块响应数据中的模型返回的有效数据 现在chunk已经截取出来了 可以解析了
//处理空行和注释行 以':'开头的行是注释行 不需要解析
if(chunk.empty()||chunk[0]==':'){
continue;//如果chunk为空 或者 第一个字符是':' 就跳过
}
//获取模型返回的有效数据
if(chunk.compare(0,6,"data: ")==0){//如果chunk中没有data字段 就跳过
std::string modelData = chunk.substr(6);//从data: 后面开始截取 截取到chunk的结束
//检测是否为结束标记
if(modelData=="[DONE]"){
streamFinish = true;//设置流式响应完成标记为true
return true;//返回true 流式响应完成
}
//反序列化
Json::Value modelDataJson;//保存反序列化后的JSON对象
Json::CharReaderBuilder reader;
std::string errors;//保存反序列化错误信息
std::istringstream modelDataStream(modelData);//把modelData转换为输入流 用于反序列化JSON对象
if(Json::parseFromStream(reader,modelDataStream,&modelDataJson,&errors)){
//返回成功后 模型返回的json格式的数据现在就保存在modelDataJson中了
if(modelDataJson.isMember("choices")&&
modelDataJson["choices"].isArray()&&
modelDataJson["choices"].empty()&&
modelDataJson["choices"][0].isMember("delta")&&
modelDataJson["choices"][0]["delta"].isMember("content")){
std::string content = modelDataJson["choices"][0]["delta"]["content"].asString();//获取delta字段中的content字段 并将其转换为字符串
fullResponse += content;//将content添加到fullResponse中
//将本次解析出的模型返回的有效数据转给调用sendMessageStream的用户使用 利用callback 回调函数
callback(content,false);//第一个参数将content传递给回调函数 第二个参数将false传递给回调函数 表示流式响应没有结束 继续去找下一个数据块
}
}else{ //如果反序列化解析失败
WARN("DeepSeekProvider sendMessageStream parse modelDataJson error: {}", errors);//打印反序列化错误信息
}
}
}
return true;
};
//给模型发送请求
auto result = client.send(req);//我们需要对result进行检测
if(!result){
//如果result为空 就认为是失败
//请求失败 出现网络问题,比如DNS解析失败
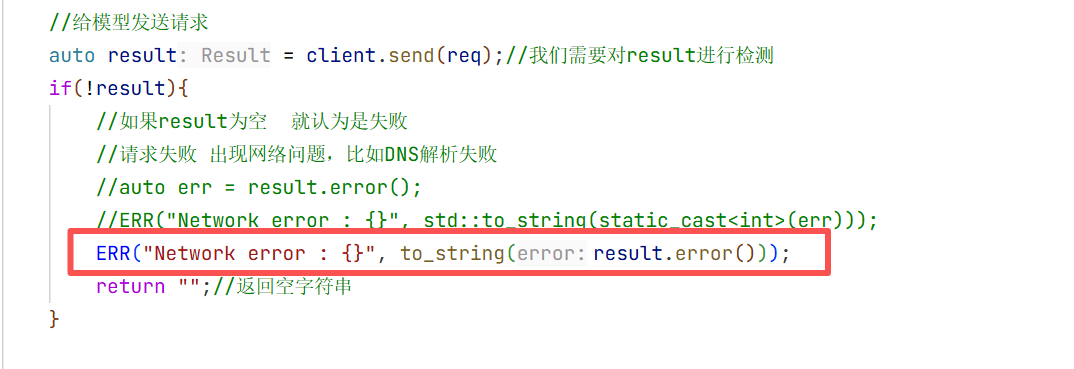
auto err = result.error();
ERR("Network error : {}", std::to_string(static_cast<int>(err)));
return "";//返回空字符串
}
// 确保流式操作正常结束
if(!streamFinish){
WARN("Stream ended without [DONE] marker");//如果流式响应没有结束标记 就打印警告日志
callback("", true);//将空字符串传递给回调函数 表示流式响应结束
}
return fullResponse;
}//end sendMessageStream 流式返回函数的结束6.发送消息流式返回的实现:
1.测试代码:


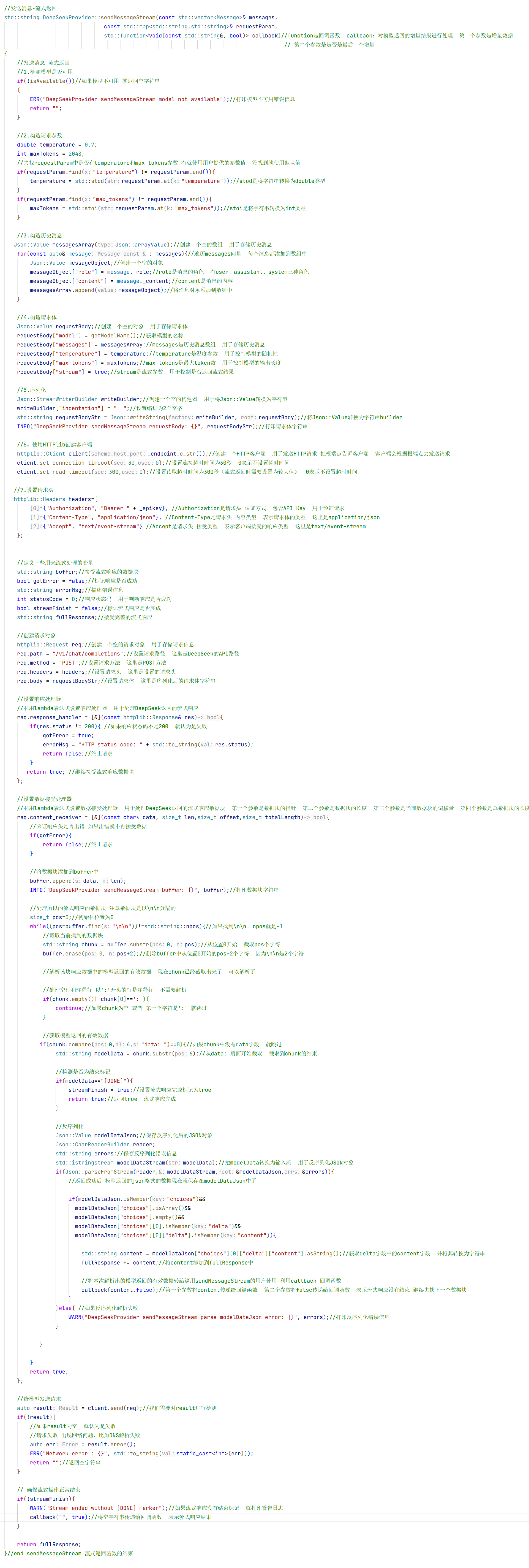
只需要改变一下调用方法即可 但这里流式返回需要三个参数 还需要一个回调函数
//调用sendMessageStream方法 -- 测试流式返回
auto writeChunk =[&](const std::string& chunk,bool last){//捕获列表放引用可以捕获上下文中的变量
INFO("chunk:{}",chunk);
if(last){
INFO("[DONE]");
}
};
std::string fullData = provider->sendMessageStream(messages, requestParam,writeChunk);//发送消息-流式返回 第一个参数是消息列表 第二个参数是请求参数
ASSERT_FALSE(fullData.empty());//断言响应为空的话 �失败 不为空的话 就成功
INFO("response:{}",fullData);这就是调用流式返回的代码。 CMakeLists不需要修改因为我们没有添加新的方法
2.测试的问题:
1


这个错误就是我们在调用日志库时发生了报错 也就是源代码这块erro发现了错误
错误产生的原因是我们借助httplib创建的客户端 然后如果不对 就打印报错的日志 spdlog库是没问题的 是因为我们使用不当spdlog打印时支持我们的常见类型 但是这个result不支持 是因为result是一个enum class 类型 通过类来定义枚举类型 这与传统定义enum类型是不同的

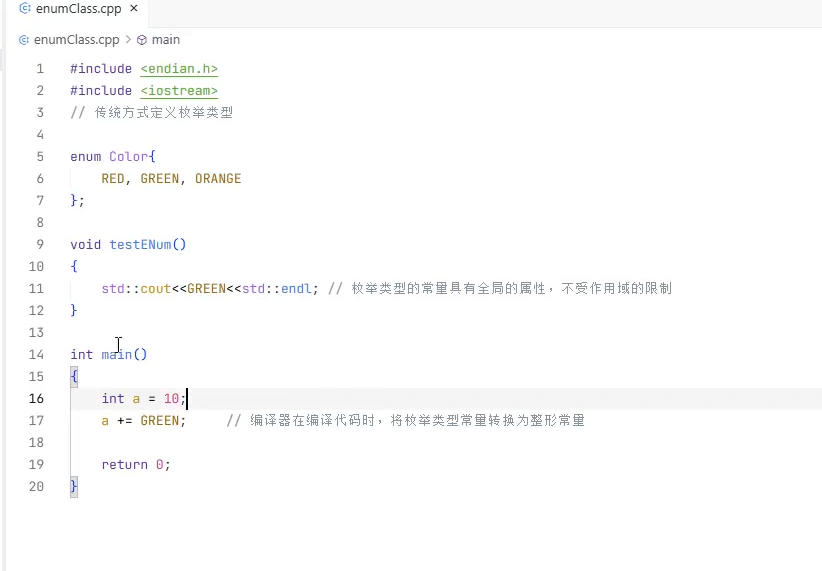
而c++11新语法enum class将枚举常量变成受作用域的限制 所以你要调用必须要有作用域限定符
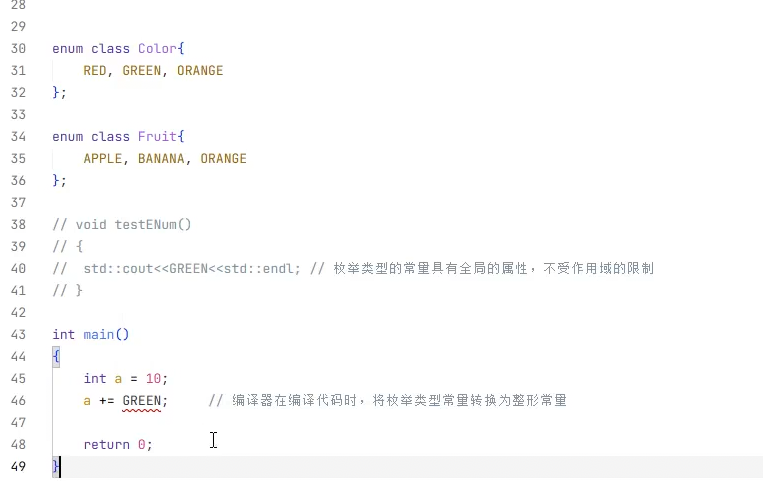

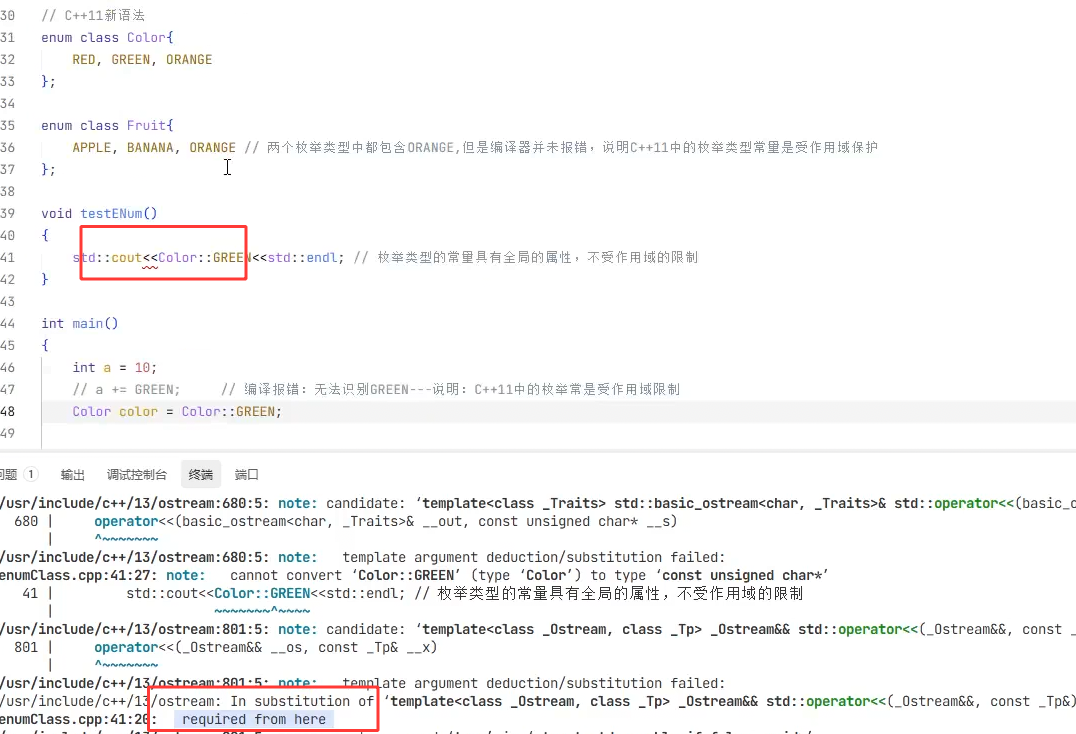
此处如果要调用的话 这个新语法不会隐士转换成int类型 所以这里要打印的话 这里需要封装重载输出运算符 或者 封装一个函数可以转换 然后外面调用也行
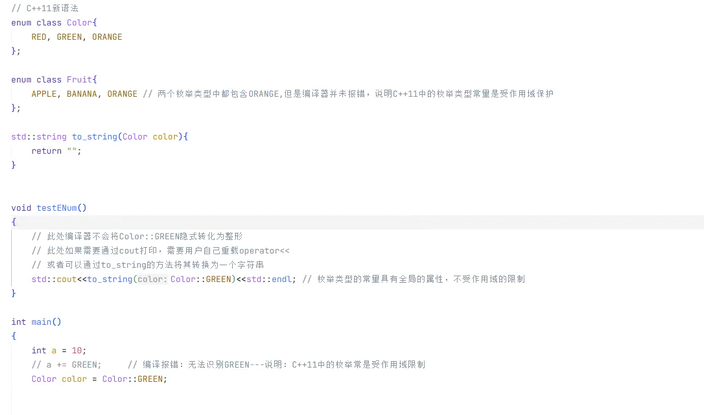
所以上面的报错也是这样 所以我们要加上转换方法 不然spdlog识别不了
2
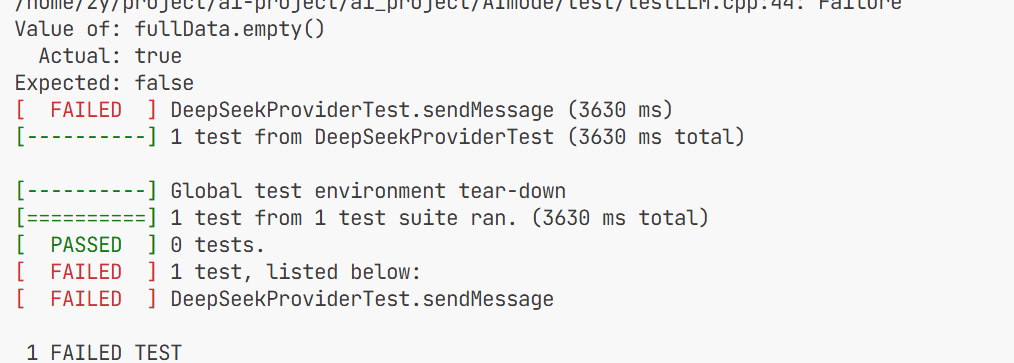
这是导致一直返回空数据 导致返回失败 然后我去检查了一下代码发现
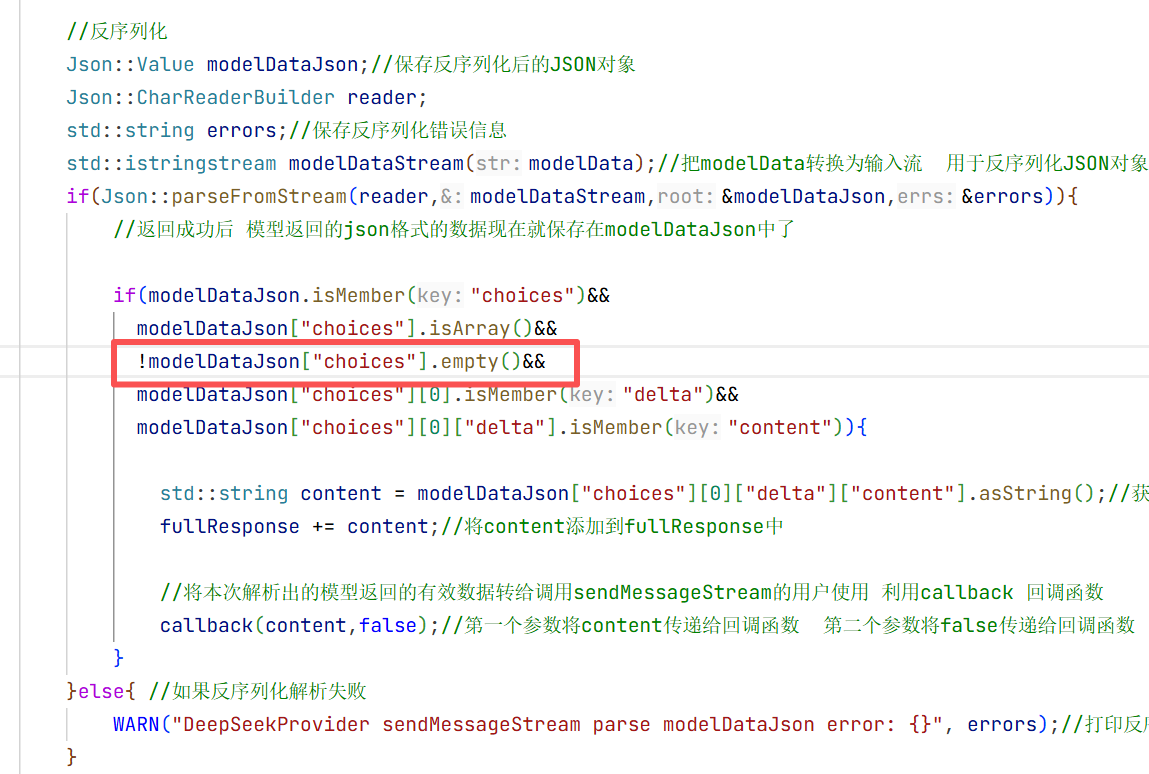
我在之前忘记加!要不然这个循环进不去无法拿到解析出来的数据导致流式响应返回的fullresponse一直为空 所以测试代码的fulldate一直为空所以会报错 修改之后:
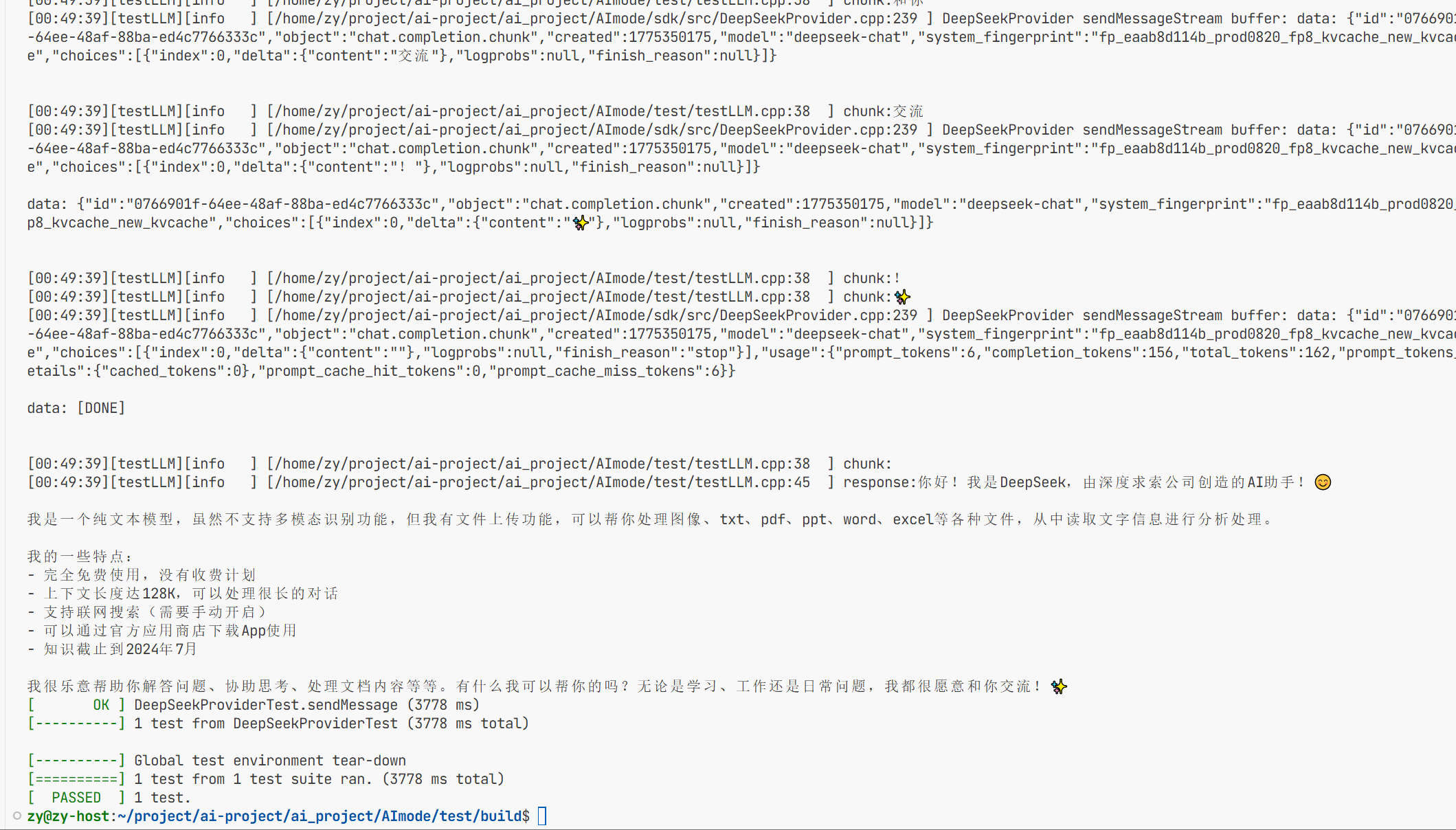
也是可以正确的响应了。
所以deepseek的接入已经实现完成了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)