面向极端远距离视频人员重识别的尺度感知视觉 - 语言适配
Scale-Aware Vision-Language Adaptation for Extreme Far-Distance Video Person Re-identification
Ashwat Rajbhandari, Bharatesh Chakravarthi
亚利桑那州立大学 (Arizona State University)
{arajbhan, bshettah}@asu.edu
本文已被 CVPR 2026 空中监控中的人类感知与识别研讨会 (AERO-HPR) 接收
摘要
极端远距离视频人员重识别(ReID)由于尺度压缩、分辨率退化、运动模糊以及空 - 地视角不匹配而特别具有挑战性。随着相机高度和主体距离的增加,在近距离图像上训练的模型性能会显著下降。在这项工作中,我们研究了如何调整大规模视觉 - 语言模型以在这些条件下可靠地运行。从基于 CLIP 的基线开始,我们将视觉骨干网络从 ViT-B/16 升级为 ViT-L/14,并引入了骨干感知的选择性微调以稳定大型 Transformer 的适配。为了解决噪声和低分辨率轨迹片段(tracklets)的问题,我们 Incorporate 了一个轻量级的时间注意力池化机制,该机制抑制退化帧并强调信息丰富的观测值。我们保留了基于适配器和提示条件的跨视图学习,以减轻空 - 地域偏移,并通过改进的优化和 k-互惠重排序(k-reciprocal re-ranking)进一步细化检索。在 DetReIDX 压力测试基准上的实验表明,我们的方法在空对地(A2G)、地对空(G2A)和空对空(A2A)协议上分别达到了 46.69、41.23 和 22.98 的 mAP,对应于 35.73 的整体 mAP。这些结果表明,当与专注于稳定性的适配相结合时,大规模视觉 - 语言骨干网络显著增强了极端远距离视频人员 ReID 的鲁棒性。
1. 引言
人员重识别(ReID)旨在匹配非重叠相机视图下的个体 [1],并且随着视觉 Transformer、基于 CLIP 的文本编码器和大规模预训练 [2] 的发展而迅速进步。这些进展显著提高了标准地面基准上的性能,并使监控、 crowd 分析和公共安全应用成为可能。然而,极端远距离空中场景是在根本不同的视觉约束下运行的。随着无人机(UAV)的高度和主体距离的增加,行人通常只占据几个像素,并受到严重的尺度压缩、分辨率退化、运动模糊以及空中和地面相机之间强烈视角差异的影响,如图 1 所示。在这种情况下,细粒度的外观线索变得不可靠,为近距离图像开发的模型性能急剧下降。传统 ReID underlying 的假设,即足够的空间细节和一致的视角,不再适用。
最近的基于 UAV 的人员分析压力测试数据集和基准明确强调了这一局限性。特别是,DetReIDX [3] 被引入以评估长距离视角、空 - 地跨域匹配和会话级外观变化下的鲁棒性。该基准揭示,强大的检测和 ReID 基线在极端距离和视角变化下可能会崩溃。因此,提高性能需要明确考虑尺度退化和噪声视频轨迹片段的适配策略,而不是从传统设置直接迁移。
在这项工作中,我们探索了如何有效地调整大规模视觉 - 语言骨干网络以用于极端远距离视频 ReID。从 DetReIDX 的官方 CLIP ViT-B/16 基线开始,我们研究了骨干网络缩放和面向稳定性的微调。我们将视觉编码器升级为 ViT-L/14,并引入了骨干感知的选择性微调,以在启用高层域适配的同时保留预训练表示。为了提高对帧级退化的鲁棒性,我们 Incorporate 了一个轻量级的时间注意力池化机制,该机制强调噪声轨迹片段中的信息帧。我们进一步保留了基于提示的跨视图条件和适配器微调,以减轻空 - 地 域偏移,并通过优化的训练策略和 k-互惠重排序 [4] 细化检索性能。
在 DetReIDX 基准上, Across 空对空(A2A)、空对地(A2G)和地对空(G2A)协议 [3] 进行评估,我们的方法将查询加权整体 mAP 从 28.11 提高到 35.73,并在所有评估协议中取得了强劲增益,包括 A2G 上的 46.69,G2A 上的 41.23,以及 A2A 上的 22.98,证明了在跨视图和同视图极端远距离条件下的一致性改进。这些发现表明,当仔细适配时,大规模 CLIP 骨干网络显著提高了极端远距离视频人员 ReID 的鲁棒性。我们总结本工作的贡献如下:
- 我们提出了针对极端远距离空 - 地视频人员 ReID 的 CLIP 骨干网络缩放(ViT-B/16 到 ViT-L/14)的系统研究,证明了增加模型容量可以提高严重尺度压缩下的鲁棒性。
- 我们提出了一种专注于稳定性的适配策略,结合骨干感知的选择性微调、时间注意力池化和提示/适配器微调,以处理噪声、低分辨率视频轨迹片段。
- 我们引入了实用的优化改进,包括余弦调度和增强的数据增强,并在推理时启用 k-互惠重排序。
- 我们的方法在基准上达到了 35.73 的 mAP,相比基线(28.11)和最高公开报告分数(32.89)有了显著改进。
本文的其余部分组织如下。第 2 节回顾了地面和空中视频人员 ReID、视觉 - 语言适配和检索重排序的相关工作。第 3 节描述了 proposed 尺度感知适配框架,包括骨干网络缩放、选择性微调、时间注意力池化和优化改进。第 4 节展示了 DetReIDX 基准上的实验结果,包括实现细节和定量比较。第 5 节讨论了结果、局限性和未来改进。最后,第 6 节总结了本文。
2. 相关工作
人员 ReID 在基于图像和基于视频的设置中都得到了广泛研究。随着 Transformer 骨干网络和大规模预训练的采用,在传统地面基准上取得了显著进展。然而,极端远距离空中条件下的鲁棒性仍然 largely underexplored。我们回顾了地面 ReID、基于视频的时间建模、空中和跨视图基准、视觉 - 语言适配和检索重排序的相关工作。
2.1. 地面人员 ReID
早期的 ReID 研究主要集中在地面相机网络,其中行人以中等距离被捕获,具有足够的空间分辨率。Market-1501 [5] 和 DukeMTMC4ReID [6, 7] 等基准建立了标准化评估协议,并推动了判别性特征学习方法的快速发展。最近,基于 Transformer 的架构,包括 TransReID [8] 和相关的全局上下文建模框架,通过利用自注意力和大规模预训练展示了强大的性能。尽管取得了这些进展,大多数方法都是在相对稳定的成像条件下评估的。当应用于极端远距离空中场景时,其中人物实例被严重尺度压缩且包含有限的视觉细节,它们的性能会大幅下降。这一局限性强调了在没有明确适配尺度退化和视角差异的情况下,直接将地面 Transformer 模型迁移到空中设置的挑战。
2.2. 基于视频的 ReID 和时间建模
基于视频的 ReID 通过利用轨迹片段 across 的时间线索扩展了基于图像的匹配。MARS 基准引入了大规模视频评估,并激发了超越简单帧平均的序列聚合策略 [9]。早期方法采用循环架构或启发式池化,而最近的工作采用基于注意力的机制来强调信息帧并抑制噪声。诸如时空注意力(STA)[10] 和时间互补学习网络(TCLNet)[11] 等方法证明了自适应聚合在处理遮挡、姿势变化和运动 blur 方面的有效性。在极端远距离空中 footage 中,由于运动不稳定和严重的分辨率损失,轨迹片段通常包含严重退化的帧。在这种情况下,统一聚合可能会放大噪声,使得自适应时间加权 particularly important。
2.3. 空中和跨视图 ReID 基准
基于 UAV 的人员分析引入了传统仅地面数据集未捕获的挑战。UAV-Human [12] 和 P-DESTRE [13] 将 ReID 扩展到空中平台,结合了检测、跟踪以及短期和长期匹配任务。对于明确的空 - 地跨视图匹配,AG-ReID [14] 和相关数据集揭示了自上而下的 UAV 图像与水平地面相机图像之间的巨大外观差距。最近,DetReIDX(见表 1)被 proposed 为针对极端远距离条件的压力测试基准 [3]。它明确建模了高度变化、尺度压缩、跨视图不匹配和会话级外观漂移。实验发现表明,强大的检测和 ReID 基线在这种情况下可能会崩溃,强调了需要尺度感知和面向稳定性的适配策略。这些特征使得 DetReIDX 成为评估极端远距离空 - 地 ReID 鲁棒性的合适基准。
表 1. 用于人员检测、ReID、跟踪和动作识别的空中 - 地面基准数据集比较。
| 数据集 | 相机 | 格式 | PIDs | BBoxes | 高度 (m) | 距离 (m) |
|---|---|---|---|---|---|---|
| AG-ReID.v2 | UAV+CCTV | 静止 | 1615 | 100.6K | 15-45 | – |
| G2APS-ReID | UAV+CCTV | 静止 | 2788 | 200.8K | 20-60 | – |
| DetReIDX | DSLR+UAV | 视频 + 静止 | 334 | 13M | 5-120 | 10-120 |
2.4. 视觉 - 语言预训练和高效适配
视觉 - 语言模型(VLMs),特别是 CLIP,已通过大规模图像 - 文本预训练展示了强大的可转移性 [2]。基于 CLIP 的特征已被 Incorporate 到 ReID 框架中,以提高泛化能力并减轻语义类标签的缺失。诸如 CLIP-ReID 之类的方法利用提示学习来桥接身份监督和语义嵌入空间。除了提示优化之外,参数高效适配方法,包括适配器、低秩更新和条件提示(例如 CoOp 和 CoCoOp)[15],使得大型预训练骨干网络的稳定微调成为可能,同时减少过拟合风险。此类策略在极端远距离空 - 地 ReID 中 particularly relevant,其中严重的退化和有限的有效视觉细节增加了适配过程中表示漂移的风险。
2.5. 基于检索的 ReID 重排序
后处理仍然是基于检索的 ReID 系统的重要组成部分。特别是,k-互惠重排序通过利用嵌入空间中的互惠最近邻来细化相似性关系,导致 mAP 和排名准确性的 consistent improvements。通常需要仔细的参数调整以最大化给定骨干网络和特征分布的增益 [4]。与主要关注地面设置或中等空中条件的先前工作相比,我们针对 DetReIDX 评估的极端远距离制度。此类最近的基准评估表明,性能退化在跨视图设置(如 A2G 和 G2A 检索)中 particularly pronounced,其中视角不匹配和尺度变化最为严重。这突出了不仅需要提高整体性能,还需要解决特定协议挑战的适配策略的需求。因此,我们研究了如何系统地缩放和稳定适配大规模视觉 - 语言骨干网络,以解决严重的尺度压缩和噪声视频轨迹片段。第 3 节详细描述了我们的尺度感知适配框架。
3. 尺度感知适配框架
我们基于 DetReIDX 基准发布的官方基于 CLIP [2] 的视频 ReID 基线,并引入了一系列针对极端远距离(XFD)空 - 地场景定制的尺度感知修改。我们的方法侧重于三个关键方面:(1) 通过模型缩放增加骨干网络容量,(2) 稳定大型 Transformer 的适配,以及 (3) 通过自适应时间聚合和细化优化提高对退化视频轨迹片段的鲁棒性。我们首先描述基线框架,然后提出 proposed 修改。
3.1. 基线框架
我们采用为 DetReIDX 发布的官方基于 CLIP 的视频 ReID 基线。该框架在空 - 地跨视图条件下执行轨迹片段级检索,包括视觉 Transformer 骨干网络、基于提示的跨视图条件和参数高效适配模块。
表 2. 基线训练配置。
| 参数 | 阶段 1 | 阶段 2 |
|---|---|---|
| 优化器 | Adam | Adam |
| 基础学习率 | 3.5×10−43.5 \times 10^{-4}3.5×10−4 | 1×10−41 \times 10^{-4}1×10−4 |
| 最大 Epochs | 120 | 120 |
| 权重衰减 | 1×10−41 \times 10^{-4}1×10−4 | 2.5×10−42.5 \times 10^{-4}2.5×10−4 |
| 权重衰减 (Bias) | 1×10−41 \times 10^{-4}1×10−4 | 1×10−41 \times 10^{-4}1×10−4 |
| 每批图像数 | 16 | 16 |
| ID 损失权重 (λid\lambda_{id}λid) | 0.25 | - |
| 三元组损失权重 (λtri\lambda_{tri}λtri) | 1.0 | - |
| I2T/ T2I 权重 | 1.0 | - |
骨干网络和帧级特征提取。 基线采用 patch size 为 16×1616 \times 1616×16 的 Vision Transformer 骨干网络 (ViT-B/16)。在训练和测试期间,所有帧都调整为 256×128256 \times 128256×128 [16]。
轨迹片段构建和采样。 视频 ReID 在轨迹片段级执行。对于每个训练实例,采样固定长度的 L=16L=16L=16 帧序列并由骨干网络独立编码。采用 softmax 三元组采样策略以支持身份分类和度量学习 [17]。批大小设置为 16 个轨迹片段。在推理期间,使用相同的序列长度,并使用 ℓ2\ell_2ℓ2 归一化特征之间的余弦相似度进行检索。
基于提示的跨视图条件 (PBP)。 为了减少空 - 地 域不匹配,基线 Incorporate 了基于提示的跨视图条件。长度为 1 的提示被插入到 9 个 Transformer 层中。元数据信号,包括高度、水平距离和视角,被离散化为 bins(18 个高度,18 个距离,和 3 个角度 bins)并编码为条件输入。该设计将与视角和尺度变化相关的物理上下文注入到表示学习过程中。
训练策略。 基线使用结合身份分类、三元组度量学习和 CLIP 风格跨模态对齐的多项式目标进行训练。总体损失定义为:
L=λidLid+λtriLtri+λi2tLi2t+λt2iLt2i,(1) \mathcal{L}= \lambda_{id}\mathcal{L}_{id}+ \lambda_{tri}\mathcal{L}_{tri}+ \lambda_{i2t}\mathcal{L}_{i2t}+ \lambda_{t2i}\mathcal{L}_{t2i}, \quad (1) L=λidLid+λtriLtri+λi2tLi2t+λt2iLt2i,(1)
其中损失权重和优化参数总结在表 2 中。
阶段 1 训练侧重于具有余弦式衰减的稳定表示学习,带有一些 warm-up。
阶段 2 训练使用降低的学习率和多步调度执行进一步微调,以细化检索性能并提高排名稳定性。
表 3. 基线推理配置。
| 参数 | 设置 |
|---|---|
| 批大小 | 16 |
| 序列长度 | 16 |
| 特征归一化 | ℓ2\ell_2ℓ2 归一化 |
| 距离度量 | 余弦相似度 |
| 重排序 | 禁用 |
推理设置。 在评估期间,使用 16 帧的固定长度序列提取轨迹片段特征,并在检索前进行 ℓ2\ell_2ℓ2 归一化。余弦相似度用于距离计算。默认基线配置中禁用了重排序,考虑到它可能会降低学习到的表示。完整的推理配置总结在表 3 中。
通过适配器进行参数高效适配。 基线进一步使用轻量级适配器模块 [18] 作为将预训练 Transformer 适配到目标域的参数高效机制。基线提供的其他可选组件,如 VCAH 和 QATW,最初被禁用。时间注意力池化在基线中也被禁用,导致使用标准平均池化。
3.2. 尺度感知适配
图 2. proposed 基于 CLIP ViT-L/14 的视频 ReID 框架概述。 增强的轨迹片段由增强了 PBP 提示条件和适配器模块的 CLIP 骨干网络编码,微调期间仅解冻最后两个 Transformer 块。帧级特征通过时间注意力池化聚合,并使用身份和三元组损失进行优化。
虽然基线为极端远距离视频 ReID 提供了强大的基础,但在严重尺度压缩和重度帧退化下性能仍然有限。因此,我们引入了一些针对骨干网络容量、稳定大模型适配、鲁棒时间聚合、重排序和优化训练策略的 targeted modifications。proposed 管道的概述如图 2 所示。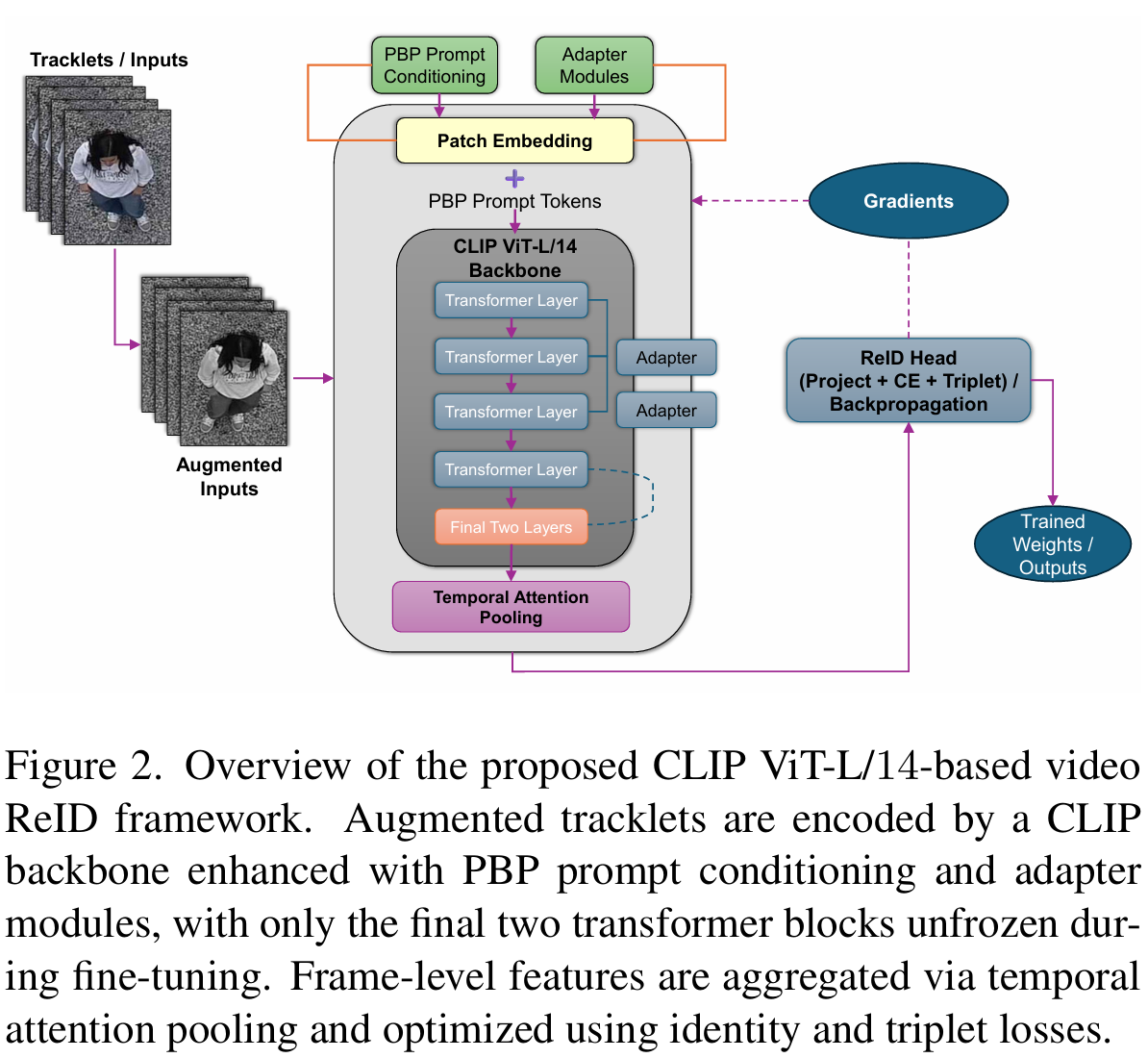
3.2.1. 骨干网络缩放:ViT-B/16 →\rightarrow→ ViT-L/14
我们通过将 CLIP 视觉编码器从 ViT-B/16 切换到更大的 ViT-L/14 骨干网络来修改基线配置,从而在严重分辨率退化和尺度压缩下增加表示容量。在非常远的距离设置中,行人区域通常只占据少量像素,细粒度的外观线索,如纹理和局部结构,变得不可靠。更大的 Transformer 骨干网络提供了改进的建模能力,以从此类退化输入中提取鲁棒的全局和中级特征 [2, 16]。ViT-B/16 产生 768 维嵌入,而 ViT-L/14 输出 1024 维嵌入。因此,我们调整相关的投影层、分类头、提示嵌入和适配器模块,以确保整个架构的维度一致性。这些调整严格是架构性的,不改变训练目标或数据采样策略。除了骨干网络升级和必要的维度对齐外,整体训练管道得以保留。该设计允许我们隔离骨干网络缩放的影响,同时保持与原始基线的可比性。
3.2.2. 骨干感知的选择性微调
微调大型 Transformer 的所有参数可能会退化在大规模预训练期间学习到的强特征表示,并导致极端远距离条件下的不稳定优化和过拟合。因此,基线没有在此数据集上训练整个架构,而是冻结了大多数骨干网络参数,专注于适配器和提示训练,而我们解冻了高层块(即块 22 和 23)进行适配。最后两个块被解冻,因为较早的层编码通用视觉特征。该策略保留了预训练模型的泛化能力,同时使高层表示能够适配目标域 [18, 19]。我们进一步使用差异学习率,为解冻的骨干网络块分配较小的学习率,为轻量级模块和头(例如提示/适配器和身份分类器)分配较大的学习率。具体而言,解冻的骨干网络块使用缩放为基础学习率 0.1×0.1\times0.1× 的学习率进行训练。这在适配更大的 ViT-L/14 模型时提高了训练稳定性,并有助于避免预训练权重的灾难性漂移。
3.2.3. 时间注意力池化
基线使用标准平均池化,因为注意力池化被禁用。然而,在极端远距离空中设置中,单个帧通常受到严重 blur、运动伪影、遮挡或极端尺度压缩的影响。因此,标准平均池化可能会允许退化帧对最终表示产生负面影响。为了解决这一限制,我们启用并引入了一种轻量级时间注意力机制,该机制根据特征响应自适应地加权帧 [10, 11]。
令 {ft}t=1T\{f_t\}_{t=1}^T{ft}t=1T 表示从轨迹片段中提取的帧级嵌入序列,其中在我们的设置中 T=16T=16T=16 且 ft∈RCf_t \in \mathbb{R}^Cft∈RC。
我们使用线性投影为每一帧学习标量注意力分数:
st=w⊤ft,(2) s_t = w^\top f_t, \quad (2) st=w⊤ft,(2)
其中 w∈RCw \in \mathbb{R}^Cw∈RC 是实现为全连接层的可学习参数向量。注意力权重通过在时间维度上的 softmax 归一化获得:
αt=exp(st)∑k=1Texp(sk).(3) \alpha_t = \frac{\exp(s_t)}{\sum_{k=1}^T \exp(s_k)}. \quad (3) αt=∑k=1Texp(sk)exp(st).(3)
最终轨迹片段表示计算为加权和:
z=∑t=1Tαtft.(4) z = \sum_{t=1}^T \alpha_t f_t. \quad (4) z=t=1∑Tαtft.(4)
该机制使模型能够抑制退化或不相关的帧,同时强调时间上一致和 discriminative 的观测值。在我们的实现中,时间注意力一致地应用于分类和检索前的中间和投影特征表示。与基线相比,这种自适应池化策略提高了极端分辨率退化和不稳定空中运动下的鲁棒性。
表 4. 与基线配置相比的优化改进。
| 参数 | 基线 (ViT-B/16) | ours (ViT-L/14) |
|---|---|---|
| 骨干网络 | ViT-B/16 | ViT-L/14 |
| 步长大小 | 16 | 14 |
| PBP 提示长度 | 1 | 4 |
| QATW 模块 | 禁用 | 启用 |
| 实例归一化 | 禁用 | 启用 |
| 阶段 1 训练 | ||
| 优化器 | Adam | Adam |
| 每批图像数 | 16 | 48 |
| 基础学习率 | 3.5×10−43.5 \times 10^{-4}3.5×10−4 | 2.0×10−42.0 \times 10^{-4}2.0×10−4 |
| 最大 Epochs | 120 | 50 |
| LR 调度 | 余弦退火 | 余弦退火 |
| 权重衰减 | 1×10−41 \times 10^{-4}1×10−4 | 1×10−41 \times 10^{-4}1×10−4 |
| 阶段 2 微调 | ||
| 优化器 | Adam | Adam |
| 每批图像数 | 16 | 24 |
| 基础学习率 | 1×10−41 \times 10^{-4}1×10−4 | 1×10−41 \times 10^{-4}1×10−4 |
| 最大 Epochs | 120 | 40 |
| LR 调度 | 多步 (60, 90) | 余弦退火 |
3.2.4. 优化策略
除了骨干网络缩放和选择性微调外,我们 refined 优化策略以更好地适应更大的 ViT-L/14 骨干网络,并提高极端远距离条件下的训练稳定性。与基线配置相比,我们调整了批大小、学习率、训练持续时间和调度策略,以平衡收敛速度和泛化。表 4 总结了基线和我们 refined 优化设置之间的关键差异。具体而言,我们将阶段 1 批大小从 16 增加到 48,以在每个迭代中向更大的骨干网络暴露更多的身份多样性。阶段 1 的基础学习率略有降低(从 3.5×10−43.5 \times 10^{-4}3.5×10−4 到 2.0×10−42.0 \times 10^{-4}2.0×10−4),以在训练更深的 ViT-L/14 架构时稳定优化。两个阶段的总训练 epoch 数也减少了(阶段 1: 120 →\rightarrow→ 50, 阶段 2: 120 →\rightarrow→ 40),反映了缩放骨干网络更快的收敛速度。在阶段 1 中,选择性解冻的骨干网络块使用缩放为基础学习率 0.1×0.1\times0.1× 的降低学习率进行训练,如 3.2.2 节所述,以防止预训练表示的不稳定。与在阶段 2 期间使用多步衰减的基线不同,我们的 refined 配置在两个训练阶段都采用余弦退火 [20]。这种平滑衰减调度避免了学习率的突然下降,并为选择性解冻的 Transformer 块提供了更稳定的适配。此外,启用 neck 处的实例归一化以进一步提高极端尺度退化下的鲁棒性。这些改进共同稳定了大模型适配,并改善了严重分辨率损失下的收敛行为。
3.2.5. 数据增强
为了提高 diverse 空中捕获条件下的鲁棒性,我们通过 Incorporate 训练期间的颜色抖动来扩展基线增强管道。具体而言,我们应用亮度、对比度、饱和度和色调的受控扰动,以模拟极端远距离图像中常见的照明变化和相机引起的颜色偏移。除了基线中使用的随机水平翻转和随机擦除外,这些颜色增强鼓励模型减少对脆弱颜色线索的依赖,而更多地依赖结构和身份一致的特征。在推理期间,我们进一步应用水平翻转增强,并平均从原始和翻转序列中提取的特征,以提高方向鲁棒性。
3.2.6. k-互惠重排序
为了进一步细化检索结果,我们在推理期间启用 k-互惠重排序作为后处理步骤。在计算 ℓ2\ell_2ℓ2 归一化查询和画廊嵌入之间的余弦距离后,初始距离矩阵使用 k-互惠编码进行细化,以提高嵌入空间中的邻居一致性。具体而言,我们应用参数为 (k1=28,k2=6,λ=0.28k_1 = 28, k_2 = 6, \lambda = 0.28k1=28,k2=6,λ=0.28) 的重排序。该过程通过考虑互惠最近邻重新评估相似性关系,减少局部特征噪声的影响,并提高检索鲁棒性。重排序仅应用于评估,不影响模型训练。此推理细化在平均精度均值 (mAP) 分数上产生了额外的改进。
4. 实验与结果
实验是在使用 NVIDIA A100 GPU 的高性能计算 (HPC) 集群上进行的。每次训练运行使用 8 个 CPU 核心和 48 GiB 系统内存。此设置足以在 proposed 适配策略下训练缩放的 ViT-L/14 骨干网络。
4.1. DetReIDX 数据集
我们在 DetReIDX 压力测试基准 [3] 上训练和评估我们的模型,该基准旨在评估极端远距离退化和空 - 地跨视图不匹配下的空中监控人员 ReID。最终基准分数计算为三个协议(A2G、G2A 和 A2A)上所有查询实例的平均精度均值 (mAP)。由于不同协议的查询数量显著不同,整体 mAP 反映了查询加权聚合,而不是跨域的简单平均。正式地,整体分数计算为:
mAPoverall=NA2G⋅mAPA2G+NG2A⋅mAPG2A+NA2A⋅mAPA2ANA2G+NG2A+NA2A(5) \text{mAP}_{\text{overall}} = \frac{N_{A2G} \cdot \text{mAP}_{A2G} + N_{G2A} \cdot \text{mAP}_{G2A} + N_{A2A} \cdot \text{mAP}_{A2A}}{N_{A2G} + N_{G2A} + N_{A2A}} \quad (5) mAPoverall=NA2G+NG2A+NA2ANA2G⋅mAPA2G+NG2A⋅mAPG2A+NA2A⋅mAPA2A(5)
其中 NA2GN_{A2G}NA2G、NG2AN_{G2A}NG2A 和 NA2AN_{A2A}NA2A 表示每个协议中的查询实例数。
我们使用平均精度均值 (mAP) 作为主要评估指标,遵循标准 ReID 协议。由于查询分布的不平衡,整体分数主要受 A2G 和 A2A 协议性能的影响,而 G2A 贡献相对较少。
4.2. 实现细节
骨干网络和训练设置。 视觉编码器从在大规模图像 - 文本数据上预训练的 CLIP ViT-L/14 检查点初始化。训练分两个阶段进行。在阶段 1 中,模型训练 50 个 epoch,批大小为 48 个轨迹片段,基础学习率为 2×10−42 \times 10^{-4}2×10−4。阶段 2 使用 24 的批大小和 1×10−41 \times 10^{-4}1×10−4 的基础学习率进行 40 个 epoch 的微调。选择性微调通过仅解冻最后两个 Transformer 块(resblocks.22 和 resblocks.23)来应用,而较早的层保持冻结。解冻的块使用缩放为基础率 0.1×0.1\times0.1× 的学习率进行优化,以保留预训练表示并稳定适配。Adam 在两个训练阶段都用作优化器。
提示和条件配置。 基于提示的跨视图条件在最终模型中启用,提示长度为 4,并在 9 个 Transformer 层中插入深度提示。基于离散化高度、距离和视角 bins 的相机和元数据条件如 3.1 节所述激活。适配器模块、QATW 模块和实例归一化也在最终配置中启用。
学习率调度和正则化。 两个训练阶段都使用余弦退火,以提供平滑的学习率衰减和稳定收敛。阶段 1 的权重衰减设置为 1×10−41 \times 10^{-4}1×10−4,阶段 2 为 2.5×10−42.5 \times 10^{-4}2.5×10−4。
数据处理和增强。 所有帧都调整为 256×128256 \times 128256×128 并归一化。每个轨迹片段由 16 个采样帧组成。在训练期间,我们应用随机水平翻转 (p=0.5p=0.5p=0.5)、随机擦除 (p=0.5p=0.5p=0.5)、亮度、对比度、饱和度和色调参数为 (0.1,0.1,0.1,0.05)(0.1, 0.1, 0.1, 0.05)(0.1,0.1,0.1,0.05) 的颜色抖动,以及 10 像素的填充。这些增强提高了对噪声的鲁棒性,并增强了空中退化条件下的泛化能力。
时间聚合和推理。 时间注意力池化将帧级嵌入聚合为轨迹片段级表示。轻量级线性注意力模块通过沿时间维度的 softmax 归一化计算自适应帧权重,使模型能够强调信息帧同时抑制退化帧。在推理期间,轨迹片段嵌入进行 ℓ2\ell_2ℓ2 归一化,余弦相似度用于检索。
K-互惠重排序。 为了进一步提高检索一致性,我们在推理期间应用 k-互惠重排序作为后处理步骤。在计算 ℓ2\ell_2ℓ2 归一化查询和画廊嵌入之间的余弦距离后,距离矩阵使用 k-互惠编码进行细化。除非另有说明,我们设置 k1=28k_1 = 28k1=28,k2=6k_2 = 6k2=6,和 λ=0.28\lambda = 0.28λ=0.28。重排序仅应用于评估,不影响模型训练。
表 5. VReID-XFD 上基线方法和我们的方法比较。
| 方法 | A→\rightarrow→A (R1, R5, R10, mAP) | A→\rightarrow→G (R1, R5, R10, mAP) | G→\rightarrow→A (R1, R5, R10, mAP) |
|---|---|---|---|
| VSLA [21] | 15.96, 26.10, 32.77, 13.83 | 28.96, 54.71, 69.13, 41.63 | 58.43, 65.17, 69.66, 26.26 |
| SINet [22] | 14.06, 24.51, 30.94, 12.85 | 25.62, 52.47, 66.57, 38.46 | 23.50, 49.44, 59.55, 16.98 |
| PSTA [23] | 13.00, 23.80, 30.30, 10.50 | 22.30, 46.90, 59.70, 34.40 | 40.40, 56.20, 59.60, 17.00 |
| BiCNet-TKS [24] | 13.30, 26.78, 36.57, 9.71 | 21.71, 44.85, 59.30, 33.28 | 41.57, 58.43, 65.17, 22.12 |
| DUT IIAU LAB [25] | 25.39, 39.58, 48.44, 20.13 | 37.77, 65.26, 75.31, 43.93 | 69.66, 80.90, 87.64, 35.44 |
| Ours (CLIP ViT-L/14) | 22.70, 30.91, 35.75, 22.98 | 41.42, 61.95, 74.16, 46.69 | 70.79, 71.91, 74.16, 41.23 |
图 3. DetReIDX 基准上基线方法、最佳公开结果和我们的方法的 mAP 比较。
4.3. 结果
我们使用 Eq.(5) 中定义的官方评估协议报告 DetReIDX 上的结果,其中整体 mAP 是在三个协议(A2G、G2A 和 A2A)上的所有查询实例上计算的。如表 5 和图 3 所示,我们的完整模型实现了 35.73 的整体 mAP,相比官方 CLIP ViT-B/16 基线提高了 +7.62,相比最佳公开结果提高了 +2.84。按协议划分,proposed 方法在 A2G 上达到 46.69,在 G2A 上达到 41.23,在 A2A 上达到 22.98,在所有三个设置中都优于最佳公开结果。最大的增益 observed 在 G2A 上,表明 proposed 稳定性感知适配在严重跨视图不匹配和尺度退化下 particularly effective。除了 mAP 之外,我们的方法还提高了两个跨视图协议中的 Rank-1,而 Rank-5 和 Rank-10 的增益相对较小。这表明 proposed 方法主要加强了 top-ranked 检索和整体排名质量,而不是均匀地提高排名列表中更深的位置。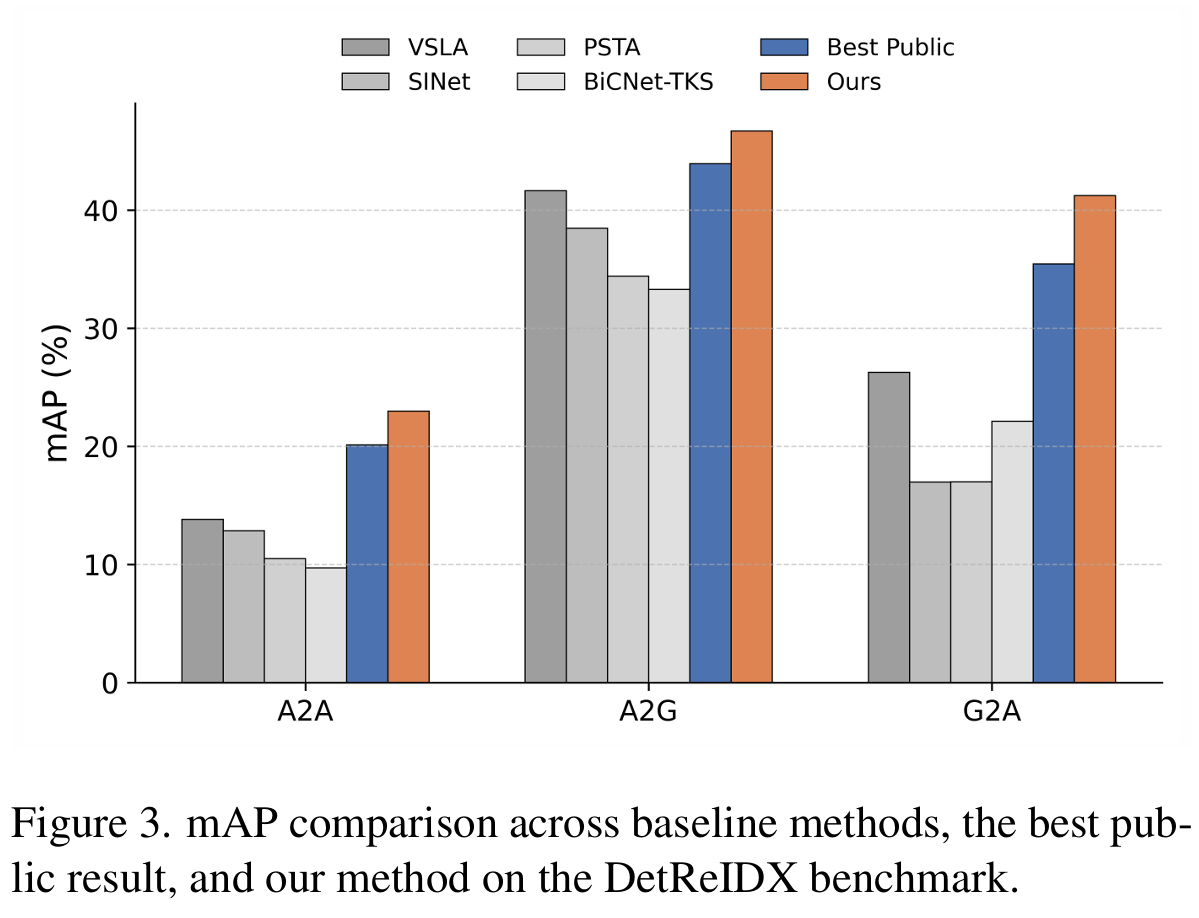
4.4. 消融研究
我们进行消融实验以量化 proposed 尺度感知适配框架中每个组件的贡献。所有结果均使用 Eq.(5) 定义的官方整体 mAP 报告。如表 6 所示,官方 CLIP ViT-B/16 基线实现了 28.11 的整体 mAP。应用优化改进产生了 28.18 的 modest gain,而启用 k-互惠重排序将性能提高到 29.40。进一步调整重排序配置将分数增加到 29.47, Incorporate 时间注意力池化将性能提高到 29.71。最终 ViT-B/16 配置达到 29.84,对应于相比基线 +1.73 的总改进。最大的增益来自骨干网络缩放和稳定性感知适配。将 ViT-B/16 替换为 ViT-L/14 并选择性适配更大的骨干网络将整体 mAP 提高到 35.73,产生相比基线 substantial +7.62 的改进。这些结果表明,重排序和时间注意力在较小的骨干网络内提供了 consistent complementary benefits,而增加的表示容量在与极端远距离退化下的稳定适配 coupled 时最为有效。
表 6. 使用 Eq. 5 在 DetReIDX 上的消融研究。
| 变体 | 骨干网络 | mAP (%) | Δ\DeltaΔ |
|---|---|---|---|
| CLIP ViT-B/16 | ViT-B/16 | 28.11 | +0.00 |
| + 优化 | ViT-B/16 | 28.18 | +0.07 |
| + k-互惠重排序 | ViT-B/16 | 29.40 | +1.29 |
| + 重排序调整 | ViT-B/16 | 29.47 | +1.36 |
| + 时间注意力池化 | ViT-B/16 | 29.71 | +1.60 |
| + 重排序调整 (最终) | ViT-B/16 | 29.84 | +1.73 |
| + 骨干网络缩放 + 适配 | ViT-L/14 | 35.73 | +7.62 |
5. 讨论
我们的结果表明,当适配保持稳定时,极端远距离视频人员 ReID 主要受益于增加的表示容量。将 CLIP 视觉编码器从 ViT-B/16 缩放到 ViT-L/14 产生了整体 mAP 的最大改进,表明更大的骨干网络能够更好地在严重尺度压缩和低分辨率观测下恢复 discriminative 线索。重要的是,这些增益仅在骨干网络缩放与面向稳定性的选择性微调 coupled 时实现,这有助于保留预训练特征空间,同时启用高层域适配。表 5 和图 3 进一步显示,proposed 方法提高了所有三个协议的 mAP,其中在跨视图设置 A2G 和 G2A 中 observed 最大增益。这表明选择性微调、提示条件适配和时间注意力的组合在强视角不匹配和尺度变化下 particularly effective。此外,重排序和时间注意力通过在推理时提高邻居一致性和抑制噪声轨迹片段内的退化帧,分别提供了 complementary improvements。
局限性。 虽然我们的方法在 A2A、A2G 和 G2A 上实现了最佳整体 mAP 和最佳协议级 mAP,但它并未在 every ranking metric 上优于先前方法。特别是,最佳公开结果在一些 Rank-5 和 Rank-10 比较上仍然更强,并且在 A2A 上也达到了更高的 Rank-1。这表明,虽然我们的方法提高了 top-ranked 检索质量和整体排名一致性,但在 deeper-list 检索和同视图空中匹配方面仍有改进空间。此外,我们的评估仅限于 DetReIDX 基准,当前的消融分析侧重于整体 mAP,这限制了对 individual components 的更细粒度协议级归因。最后,与基线相比,更大的 ViT-L/14 骨干网络和可选重排序引入了额外的计算成本和推理延迟。
未来工作。 几个方向可能进一步改进极端远距离 ReID。首先,协议级消融和检索校准可以提供更深入的 insight,了解哪些组件最有利于 A2G、G2A 和 A2A,并可能帮助改进 deeper-rank 检索行为。其次,更具表现力的尺度感知提示、元数据条件适配器或分层时间建模可能进一步提高严重高度、距离和运动变化下的鲁棒性。第三,在额外空中 ReID 基准上评估跨数据集泛化将提供 DetReIDX 之外鲁棒性的更强证据。最后,未来工作还应探索大型视觉 - 语言骨干网络的更高效适配策略,并考虑空中人员识别系统的隐私感知评估。
6. 结论
我们提出了一种用于极端远距离空 - 地场景中基于 CLIP 的视频人员重识别的尺度感知适配框架。通过将视觉骨干网络从 ViT-B/16 缩放到 ViT-L/14,并将其与面向稳定性的选择性微调、时间注意力池化、优化改进和 k-互惠重排序相结合,我们的方法在严重尺度压缩和跨视图不匹配下显著提高了检索鲁棒性。在 DetReIDX 基准上,我们的方法实现了 35.73 的整体 mAP,协议级 mAP 分别为 A2G 上的 46.69,G2A 上的 41.23,和 A2A 上的 22.98,优于官方基线和最佳公开结果。这些发现表明,当仔细适配时,大规模视觉 - 语言骨干网络为极端远距离视频人员 ReID 提供了有效的基础。
致谢
作者感谢亚利桑那州立大学的研究计算部门 [26] 提供有助于本工作报告结果的 HPC 和存储资源。
参考文献
[1] Lin Wu, Yang Wang, Jianhuang Gao, and Xuelong Li. Deep learning for person re-identification: A survey and outlook. arXiv preprint arXiv:2001.04193, 2020.
[2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[3] Khushal Hambarde, Emmanuel Mbongo, Nirav Menghani, Ajay Ramesh, Rogerio Schmidt Feris, and Hugo Proença. DetReIDX: A stress-test dataset for real-world UAV-based person recognition. arXiv preprint arXiv:2505.04793, 2025.
[4] Zhun Zhong, Liang Zheng, Donglin Cao, and Shaozi Li. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[5] Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qi Tian. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015.
[6] Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Performance measures and a data set for multi-target, multi-camera tracking. In European Conference on Computer Vision Workshops (ECCV Workshops), 2016.
[7] Zhedong Zheng, Liang Zheng, and Yi Yang. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017.
[8] Shuting He, Haoxi Wu, Peng Wang, Mengdan Zhang, Zhongzhan Huang, and Yonghong Tian. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
[9] Liang Zheng, Zhi Bie, Yifan Sun, Jingdong Wang, Chi Su, Shengjin Wang, and Qi Tian. MARS: A video benchmark for large-scale person re-identification. In European Conference on Computer Vision (ECCV), 2016.
[10] Yang Fu, Xiaoyang Wang, Yunchao Wei, and Thomas Huang. Spatial-temporal attention model for video-based person re-identification. In AAAI Conference on Artificial Intelligence (AAAI), 2019.
[11] Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. TCLNet: Temporal complementary learning for video person re-identification. In European Conference on Computer Vision (ECCV), 2020.
[12] Tianjiao Li, Jun Liu, Wei Zhang, Yun Ni, Wenqian Wang, and Zhiheng Li. UAV-Human: A large benchmark for human behavior understanding with unmanned aerial vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[13] S. V. Aruna Kumar, Ehsan Yaghoubi, Abhijit Das, B. S. Harish, and Hugo Proença. The P-DESTRE: A fully annotated dataset for pedestrian detection, tracking, and short/long-term re-identification from aerial devices. IEEE Transactions on Information Forensics and Security (TIFS), 16:1696–1708, 2021.
[14] Huy Nguyen, Kien Nguyen, Sridha Sridharan, and Clinton Fookes. Aerial-ground person re-identification. In IEEE International Conference on Multimedia and Expo (ICME), pages 2585–2590, 2023.
[15] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. arXiv preprint arXiv:2203.05557, 2022.
[16] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021.
[17] Alexander Hermans, Lucas Beyer, and Bastian Leibe. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, 2017.
[18] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mohammad Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. In International Conference on Machine Learning (ICML), 2019.
[19] Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022.
[20] Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations (ICLR), 2017.
[21] Shizhou Zhang, Wenlong Luo, De Cheng, Qingchun Yang, Lingyan Ran, Yinghui Xing, and Yanning Zhang. Cross-platform video person reid: A new benchmark dataset and adaptation approach. In European Conference on Computer Vision (ECCV), pages 270–287. Springer, 2024.
[22] Shutao Bai, Bingpeng Ma, Hong Chang, Rui Huang, and Xilin Chen. Salient-to-broad transition for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7339–7348, 2022.
[23] Yingquan Wang, Pingping Zhang, Shang Gao, Xia Geng, Hu Lu, and Dong Wang. Pyramid spatial-temporal aggregation for video-based person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12026–12035, 2021.
[24] Ruibing Hou, Hong Chang, Bingpeng Ma, Rui Huang, and Shiguang Shan. Bicnet-tks: Learning efficient spatial-temporal representation for video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2014–2023, 2021.
[25] Kailash A. Hambarde, Hugo Proença, Md Rashidunnabi, Pranita Samale, Qiwei Yang, Pingping Zhang, Zijing Gong, Yuhao Wang, Xi Zhang, Ruoshui Qu, Qiaoyun He, Yuhang Zhang, Thi Ngoc Ha Nguyen, Tien-Dung Mai, Cheng-Jun Kang, Yu-Fan Lin, Jin-Hui Jiang, Chih-Chung Hsu, Tamás Endrei, György Cserey, and Ashwat Rajbhandari. VReID-XFD: Video-based Person Re-identification at Extreme Far Distance Challenge Results, 2026. Submitted on 4 Jan 2026.
[26] Douglas M Jennewein, Johnathan Lee, Chris Kurtz, William Dizon, Ian Shaeffer, Alan Chapman, Alejandro Chiquete, Josh Burks, Amber Carlson, Natalie Mason, et al. The sol supercomputer at arizona state university. In Practice and Experience in Advanced Research Computing 2023: Computing for the Common Good, pages 296–301. 2023.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)