从驯马到造车:Harness Engineering 将如何定义下一代 AI 应用

“给我一批足够快的马,我能超越风。但给我一套精良的马具,我能构建一个帝国。” —— 一位虚构的古代工程师
在人工智能的辽阔草原上,大型语言模型(LLM)正如同一匹匹潜力无限、动辄能吟诗作对、挥笔成画的“千里马”。它们的力量令人敬畏,但其与生俱来的野性——幻觉(Hallucination)、不确定性、以及偶尔的“脱缰”——也让无数满怀激情的开发者陷入了“模型很丰满,落地很骨感”的窘境。
我们中的许多人,最初都以为驾驭这匹烈马的关键在于掌握更精妙的口令,即 Prompt Engineering。我们像经验丰富的驯马师一样,尝试用各种华丽的辞藻、复杂的结构、甚至是充满“魔法”的咒语,试图让马儿精准地理解并执行我们的每一个意图。这在某种程度上是有效的,但很快我们就发现,这种“人肉对齐”的方式,更像是一门玄学,充满了偶然性,难以规模化,更无法保证工业级的稳定交付。每当模型版本迭代,或者任务复杂度稍有提升,昨日的“黄金咒语”可能瞬间沦为废纸。
于是,一部分先驱者意识到了问题所在:光有口令还不够,马儿需要更广阔的视野和更扎实的知识。Context Engineering 应运而生。我们开始为这匹马配备“GPS 导航”和“百科全书”——通过检索增强生成(Retrieval-Augmented Generation, RAG)等技术,将外部世界的实时、精准信息注入模型的认知边界。这极大地缓解了模型的“失忆症”和“臆想症”,让它能言之有物,回答也更具事实性。然而,这依然只是解决了“马”本身的问题,我们离一个能自动驾驶、可预测、可维护的“智能系统”还相去甚远。
今天,我们想探讨一个更宏大、更系统性的答案:Harness Engineering。
如果说 Prompt Engineering 是在“驯马”,Context Engineering 是在“强马”,那么 Harness Engineering 就是在“造车”。它不再仅仅关注如何与“马”(LLM)本身进行单点交互,而是致力于构建一个完整、精密、可靠的“马具”(Harness)系统。这套系统集成了缰绳(Prompt)、马鞍(Context)、车身(Tools)、道路规划(Orchestration)、以及一个永远清醒的“副驾驶”(Evaluation)。
这不再是一场关于“炼丹”的艺术,而是一场关乎“造车”的工程革命。本文将带你深入这场革命的核心,明确三者的边界,系统性地提出并阐释 Harness Engineering 的“六层架构”与“6 个落地指南模块”,并融合多个硬核工程案例,为你揭示如何从一个“AI 时代的驯马师”,进化为真正的“AI 架构师”。
Part 1: 边界之辩——Prompt、Context 与 Harness 的角色分野
在深入 Harness Engineering 的世界之前,我们必须清晰地厘清这三个紧密相连又截然不同的概念。它们代表了我们与大模型协作方式的三个演进阶段。
| 对比维度 | Prompt Engineering (提示工程) | Context Engineering (上下文工程) | Harness Engineering (驾驭工程) |
|---|---|---|---|
| 核心目标 | 在单次交互中,获得最佳的模型输出 | 为模型提供准确、相关的外部知识 | 构建稳定、可靠、可扩展的 LLM 应用系统 |
| 核心方法 | 设计提示词(指令、角色、示例、格式) | 检索增强生成(RAG)、知识图谱、数据库查询 | 系统架构设计、流程编排、工具调用、评估、治理 |
| 隐喻 | 驯马师的口令:通过语言让马理解意图 | 给马配备 GPS:让马知道它在哪,要去哪 | 制造自动驾驶汽车:构建完整的驾驭与控制系统 |
| 角色定位 | 对话设计师、AI 沟通师 | 知识架构师、数据工程师 | AI 系统架构师、可靠性工程师 |
| 复杂度 | 低,侧重于自然语言技巧 | 中,涉及数据处理、向量数据库、检索算法 | 高,需要综合的软件工程与系统设计能力 |
| 关注点 | 输出质量的“上限” | 输出的“事实性”与“时效性” | 系统的“稳定性”、“可维护性”与“可扩展性” |
1.1 Prompt Engineering:“咒语”的艺术与极限
Prompt Engineering 是我们与大模型打交道的第一课。它是一门“与 AI 对话的艺术”,核心在于如何通过精准的语言、清晰的指令、丰富的示例(Few-shot)和结构化的格式,引导模型在一次或几次交互内,生成我们期望的结果。
一个优秀的 Prompt 工程师,就像一位心理学家,深谙模型的“脾性”,知道如何用最经济的 Token 激发出模型最深层的能力。诸如思维链(Chain-of-Thought, CoT)、角色扮演、输出格式限定等技巧,都是这个阶段的宝贵产物。
然而,它的局限性也显而易见:
- 脆弱性:Prompt 对措辞、标点甚至空格都极为敏感,微小的改动可能导致输出质量的剧烈波动。
- 不可扩展:对于需要多步骤、多工具协作的复杂任务,单纯依靠一个庞大而复杂的 Prompt 很快会变成一场维护噩梦,难以调试和迭代。
- 知识局限:Prompt 无法解决模型固有的知识陈旧和事实性错误问题,它只能在模型已知的世界里“螺蛳壳里做道场”。
Prompt Engineering 是必要的,但它只是冰山一角。过度迷信“神级 Prompt”,如同试图用一套复杂的口令让一匹马自己去完成“取快递、做饭、打扫卫生”的全套家务,不切实际。
1.2 Context Engineering:为 AI 注入“记忆”与“知识”
Context Engineering 的兴起,标志着我们从“引导”模型,转向了“赋能”模型。其核心思想是,在向 LLM 提问之前,先从外部知识源(如文档库、数据库、API)中检索出与问题最相关的信息,并将这些信息作为“上下文”一同塞给模型。 Retrieval-Augmented Generation (RAG) 是其最典型的实现。
这就好比,我们不再只对马儿喊“去长安!”,而是在它耳边低语:“根据这份地图(Context),沿着这条标明的路线(Context),去长安东市的张屠户家(Context)。”
Context Engineering 带来了质的飞跃:
- 事实性保证:有效减少了模型“一本正经地胡说八道”的现象,因为它的回答被限定在所提供的上下文中。
- 知识实时更新:通过连接动态的外部知识库,模型得以“与时俱进”,能够回答关于最新事件和私有领域知识的问题。
- 可追溯性:当模型给出答案时,我们可以追溯到它所依据的原始上下文,这对于需要审计和解释的场景至关重要。
但 Context Engineering 并非终点。它主要解决了“信息输入”的问题,但对于复杂的“任务执行”过程,它依然力有不逮。当一个任务需要调用多个工具、执行一长串逻辑、并在中途根据结果进行动态决策时,仅仅提供上下文是不够的。
1.3 Harness Engineering:构建智能体的“自动驾驶系统”
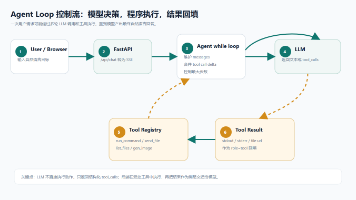
Harness Engineering 是一个真正意义上的系统工程学科。它将 LLM 视为一个强大的、但需要被“驾驭”的核心组件,而不是一个可以直接交互的终端。它的目标是构建一个围绕 LLM 的、健壮的、可观测的、可治理的应用程序。
Harness 不仅仅是 Prompt 和 Context 的简单叠加,它是一个包含以下组件的完整系统:
- 任务规划器 (Planner):将复杂的用户意图分解成一系列逻辑清晰的子任务。
- 工具箱 (Toolbox):封装了各种 API 和内部函数,让 LLM 能够与现实世界交互(查询数据库、发送邮件、调用服务等)。
- 流程编排器 (Orchestrator):像导演一样,管理和调度各个子任务的执行顺序、依赖关系和数据流。
- 记忆模块 (Memory):维护短期对话历史和长期用户偏好,使得交互连贯而个性化。
- 评估与治理模块 (Evaluator & Governance):持续监控系统的行为和输出质量,进行事实性校验、安全审查,并能根据预设规则进行干预、重试或回退。
从 Prompt 到 Context,再到 Harness,我们的视角从“如何让模型说出我想要的”,转变为“如何设计一个系统,让模型可靠地做出我想要的”。这是一种从“手工作坊”到“现代工厂”的认知升级,是从关注“对话”到关注“交付”的根本转变。
Part 2: Harness 的蓝图——系统化驾驭 AI 的“六层架构”
为了将 Harness Engineering 从一个模糊的概念变为可落地的工程实践,我们提出一个“六层架构”模型。这个模型自顶向下,从抽象的意图到具体的执行,完整地勾勒出一个健壮的 Harness 系统应具备的所有层次。
L1 - 意图与规划层 (Intent & Planning)
这是 Harness 的“大脑”,负责回答“用户真正想要什么?”以及“我们该如何分步实现它?”
在这一层,系统接收用户原始、可能模糊的输入(例如,“帮我规划下周去北京的出差行程,要覆盖所有核心客户”),并将其转化为一个结构化的、包含多个步骤的任务计划。这通常也需要一个 LLM(或一个专门微调过的模型)来扮演“规划师”的角色。
- 核心任务:意图识别、歧义消除、任务分解、依赖关系分析。
- 产出:一个有向无环图(DAG)或一个步骤序列,清晰地描述了要执行的动作及其顺序。例如:
[1. 查询核心客户列表] -> [2. 查询客户地址] -> [3. 规划最优拜访路线] -> [4. 查询航班与酒店] -> [5. 生成日程表]。
L2 - 角色与提示层 (Persona & Prompting)
这是 Harness 的“灵魂”,负责为每一个执行步骤中的 Agent 定制“人设”和“说话之道”。
与简单的 Prompt Engineering 不同,这一层是动态和自适应的。针对 L1 规划出的不同子任务,系统会动态生成或选择最合适的 Prompt 模板。
- 核心任务:
- 角色分配:为 Agent 指定一个角色(如“数据分析师”、“旅行规划专家”、“代码审查员”),能极大地提升其在特定任务上的表现。
- 动态提示生成:根据任务上下文、历史记录和可用工具,动态填充和调整 Prompt 的内容。
- 格式与约束:明确要求 Agent 以特定格式(如 JSON、XML)返回结果,以便于后续程序的解析和处理。
L3 - 能力与工具层 (Capabilities & Tools)
这是 Harness 的“双手”,让模型能够超越文本的限制,与真实世界进行交互。
在这一层,我们定义并封装了一系列“工具”,这些工具可以是任何形式的函数或 API 调用。LLM 负责“决定”在何时、使用哪个工具、以及传入什么参数。
- 核心任务:工具定义(函数签名、清晰的描述)、工具路由(当模型决定调用工具时,Harness 负责实际执行)、结果返回与格式化。
- 示例:
search_flight(origin, destination, date)、query_database(sql_query)、send_email(to, subject, body)。工具描述的清晰度,直接决定了模型能否正确使用它们。
L4 - 上下文与记忆层 (Context & Memory)
这是 Harness 的“记忆中枢”,负责管理所有驱动模型决策的信息。
这一层是 Context Engineering 的自然延伸和系统化升级,它管理着不同类型、不同生命周期的上下文。
- 核心任务:
- 短期记忆:管理当前对话的上下文窗口,处理指代消解等问题。
- 长期记忆:持久化存储用户的核心信息、偏好、历史交互摘要,实现个性化服务。
- 动态知识(RAG):通过检索系统,动态获取完成当前任务所需的外部知识。
- 上下文压缩与剪枝:在有限的上下文窗口内,智能地选择、总结和舍弃信息,确保最高效的信息密度。
L5 - 编排与治理层 (Orchestration & Governance)
这是 Harness 的“中枢神经系统”,确保所有任务能够顺畅、可靠地执行,并在出现问题时有路可退。
如果说 L1 的规划是“战略”,那么 L5 的编排就是“战术执行”。它负责驱动整个任务流程,处理各种异常情况,是系统可靠性的核心保障。
- 核心任务:
- 流程控制:基于 L1 的规划,依次或并行地调用 Agent、工具和其它服务。LangChain 中的
LCEL和 LangGraph 就是典型的编排工具。 - 错误处理与重试:当某个步骤失败时(例如,API 超时、模型返回格式错误),自动进行重试或执行预设的修复逻辑。
- 回退与降级:在关键任务上,如果主路径失败,可以切换到更稳定但效果稍差的“安全模式”路径,保证核心功能的可用性。
- 资源与成本治理:监控 Token 消耗、API 调用频率,设置熔断和限流策略,防止失控的 Agent 造成资源滥用。
- 流程控制:基于 L1 的规划,依次或并行地调用 Agent、工具和其它服务。LangChain 中的
硬核案例 1:LangChain 长链路的“残酷数学题”
为什么编排与治理如此重要?让我们来看一个简单的数学题。
假设我们构建了一个包含 20 个步骤的 Agent 工作流(这在复杂的自动化任务中并不少见)。再假设,我们经过精心调优,使得每一步的成功率都达到了非常理想的 95%。那么,整个工作流一次性顺利跑完的概率是多少呢?
P(total) = 0.95 ^ 20 ≈ 0.358
答案是 约36%。
这个结果令人震惊。一个看似每步都相当可靠的系统,其端到端的可靠性却低得令人发指。这就是“复杂系统中的脆弱性叠加”。任何一个环节的微小失误,都会被长长的链路指数级放大。
Harness Engineering 正是为此而生。它通过在编排层引入重试机制、错误捕获、状态检查点、条件分支和回退路径,将一个脆弱的线性链条,改造成一个具有弹性和自愈能力的健壮网络。这正是从“玩具”到“产品”的关键一步。
L6 - 观测与评估层 (Observation & Evaluation)
这是 Harness 的“眼睛”和“裁判”,持续度量系统的表现,并为改进提供数据依据。
一个没有评估的 Harness 系统,就像一辆没有仪表盘的汽车,你不知道它的速度、油耗,更不知道引擎是否即将过热。
- 核心任务:
- 可观测性 (Observability):记录每一次 LLM 调用的完整轨迹(Trace),包括输入的 Prompt、输出的 Response、调用的工具、消耗的 Token 和延迟。LangSmith 等工具就是为此设计的。
- 质量评估 (Evaluation):定义一套评估标准和数据集,自动化地、持续地度量系统输出的质量。评估维度可以包括:事实一致性、任务完成度、回答相关性、安全性、风格合规性等。
- 反馈闭环 (Feedback Loop):收集评估结果,特别是那些被标记为“差”的案例,将其作为宝贵的训练数据,用于微调模型(无论是规划模型还是执行模型)或优化 Prompt 模板。
硬核案例 2:Anthropic 的“裁判与运动员分离”思想
为什么大厂不相信“全能模型”?在 Anthropic 的 Agent 架构中,他们发现如果让同一个 AI 既当“写代码的”又当“检查代码的”,它极容易为了敷衍你而“护短”或产生幻觉盲区。
于是他们采用了**“生成与评估分离”**的双层 Harness 策略:
- 运动员(Generator Agent):只管埋头写代码、生成方案,不管对错。
- 裁判(Evaluator Agent):手里拿着一份详尽的检查清单(Rubric),专门挑毛病。它不直接干活,只负责验证运动员的产出是否符合架构规范、是否通过测试、是否存在安全漏洞。
这种高压的博弈循环,让 AI 处于不断的“自我对抗”中。裁判会无情打回不过关的代码,逼迫运动员重写。依靠外部架构构建的这种相互监督,才是 Anthropic 的 Agent 能够稳定执行长周期复杂任务的秘诀。
硬核案例 3:OpenAI 的 100 万行代码奇迹与机械化约束
OpenAI 曾披露过一个震撼的内部实验:3 名工程师不写一行代码,纯靠 Codex Agent 在 5 个月内生成了约 100 万行生产级代码。
他们是怎么做到的?答案是极其严苛的 “机械化架构约束” 和 “垃圾回收”。
- 把规矩写进 Linter(铁腕约束):传统开发中,架构规范靠资深工程师的 Code Review 维护。但在 Agent 一天几百个 PR 的吞吐量下,人工审查成了瓶颈。OpenAI 的解法是:把所有架构规则(如下层模块绝对不能反向依赖上层模块)变成自定义的 Linter。任何违反规则的代码都过不了 CI 系统。系统会直接把报错日志扔回给 AI,强迫它改到对为止。正如 Martin Fowler 网站的文章所评论的:“为了获得更高的 AI 自主性,运行时必须受到更严格的约束。增加信任需要的不是更多自由,而是更多限制。”
- 垃圾回收智能体(Garbage Collection Agent):他们发现,Agent 写代码越多,“技术熵增”越恐怖,系统会慢慢腐烂。于是他们设计了专门的“环卫工 Agent”。这个 Agent 没有任何业务 KPI,日夜在后台巡检,发现偏离标准的冗余代码、过时的文档说明,就自动提交重构 PR,保持整个代码库的健康。
硬核案例 4:Vercel 的反直觉经验 ——“砍掉 80% 的工具”
Vercel 在其 v0 产品的迭代中,得出了一个非常有意思的 Harness 经验:当 Agent 翻车时,不要急着给它加新工具,试试做减法。
他们发现,给 LLM 提供过多的工具选项(比如 50 个 API),反而会让模型陷入选择困难症,导致规划错误率飙升。正确的 Harness 做法是:利用上下文路由(Context Routing),在特定任务节点,只给 Agent 暴露当前最需要的 3-5 个核心工具。限制它的视野,反而能大幅提升它的专注度和成功率。
这六层架构共同构成了一个完整的 Harness 系统,它将原始的、混沌的 LLM 能力,约束和引导到一条清晰、可靠、可控的工程轨道上。
Part 3: Harness 的实践——从架构到落地的 6 个指南模块
理论的价值在于指导实践。六层架构为我们提供了“是什么”的蓝图,而接下来的“6 个落地指南模块”则聚焦于“怎么做”。这六个模块与六层架构既有映射关系,又可作为独立的实践清单,帮助你在实际项目中构建 Harness。
模块一:问题建模与目标拆解 (映射 L1)
在写下任何代码或 Prompt 之前,首要任务是清晰地定义问题。
- 定义“完成态”:用最精确的语言描述当任务成功完成时,系统应该产出什么。这会成为你后续所有设计的“北极星”。
- 识别任务类型:这是一个简单的问答任务,还是一个需要与外部世界交互的代理任务?是单轮交互还是多轮对话?
- 手动分解流程:想象你自己是这个 Agent,你需要哪些信息?需要执行哪些步骤?将这个“人肉执行”的过程记录下来,它就是你最初的任务规划草图。
- 识别歧义与边界:预想用户可能提出的模糊或超出范围的请求,并提前设计好澄清话术或拒绝策略。
模块二:能力映射与工具清单 (映射 L2, L3)
将拆解出的任务步骤,映射到具体的实现能力上。
- 盘点可用工具:梳理你的系统能提供的所有原子能力(API、数据库、函数等),并为它们编写清晰、简洁、对 LLM 友好的描述。
- 坏描述:
func_1(a, b) - 好描述:
# 计算两个数字的和. a: 第一个加数. b: 第二个加数.
- 坏描述:
- 能力-任务匹配:确定每个子任务需要哪个或哪些工具来完成。如果现有工具无法满足,就将其列为需要开发的新工具。
- 设计提示策略:为每个需要 LLM 参与的步骤设计初步的 Prompt。明确其角色、目标、可用工具以及期望的输出格式。
模块三:上下文塑形与知识资产 (映射 L4)
精心管理流入模型的每一份信息。
- 知识分类:区分你的知识源:哪些是几乎不变的“静态知识”(如产品手册)?哪些是需要频繁更新的“动态知识”(如新闻、库存)?
- 构建 RAG 流水线:为动态知识建立一套完整的 RAG 流程,包括文档分块(Chunking)、向量化(Embedding)、索引(Indexing)和检索(Retrieval)。
- 设计记忆机制:确定需要何种记忆。是仅需记住最近几轮对话的“滑动窗口”,还是需要一个能存储用户关键偏好的“结构化记忆库”?
- 上下文预算:时刻牢记模型的上下文窗口限制。在编排流程时,就要规划好每个步骤可以“消费”多少上下文,并准备好信息压缩和摘要的策略。
模块四:编排可靠性工程 (映射 L5)
将脆弱的 Agent 调用链,锻造成坚固的系统。
- 选择编排框架:利用 LangChain (LCEL/LangGraph), LlamaIndex, หรือ CrewAI 等成熟框架来构建你的任务流,避免重复造轮子。
- 实现全面的错误处理:为每一个可能失败的步骤(特别是 API 调用和 LLM 生成)包裹上
try-except块,并记录详细的错误信息。 - 设计智能重试:不要盲目重试。对于因模型“偶然犯傻”导致的格式错误,可以简单重试;对于因 API 超时导致的失败,可以增加等待时间后重试;对于因逻辑错误导致的失败,则应中断流程并报警。
- 建立“Plan B”:为核心功能路径设计回退方案。例如,如果一个复杂的、调用多个工具的 Agent 失败了,系统可以降级到一个更简单、仅使用 RAG 的问答模式,至少保证能给用户一个基础但安全的回答。
模块五:评估指标与裁判体系 (映射 L6)
建立你的“质量控制部门”。
-
创建“黄金数据集”:手动构建一个包含 50-100 个典型案例的评估数据集,每个案例都包含输入和“人类认可的”理想输出。这将是你衡量系统改进的基准。
-
定义评估维度:将“好”或“坏”分解为可量化的指标。例如:
- 正确性:生成的代码能否运行?答案是否符合事实?
- 完整性:是否回答了用户的所有问题?
- 安全性:是否包含有害或不当内容?
- 效率:调用了多少次工具?消耗了多少 Token?
-
部署裁判 Agent:基于你的评估维度,设计一个或多个“LLM-as-a-Judge” Agent。让它们自动化地对你的系统输出进行打分。
-
集成到 CI/CD:将评估流程集成到你的持续集成/持续部署(CI/CD)管道中。每当有代码或 Prompt 的变更,自动运行评估,确保没有引入“性能衰退”(Regression)。
模块六:闭环改进与数据飞轮 (映射 L5, L6)
让系统拥有自我进化的能力。
- 建立反馈渠道:除了自动化评估,还要提供方便的渠道让真实用户能够对结果进行“点赞”或“点踩”。
- 挖掘失败案例:重点关注那些在评估中得分低,或者被用户“点踩”的交互。这些是金矿。
- 根因分析:分析失败案例:是 Prompt 不好?是 RAG 没检索到正确文档?是工具出错了?还是规划的逻辑本身就有问题?
- 数据回灌:将这些分析过的失败案例及其正确答案,转化为高质量的微调(Fine-tuning)数据,定期对你的模型(特别是规划模型或裁判模型)进行迭代训练。这便形成了“数据飞轮”:应用产生数据 -> 数据驱动评估 -> 评估发现问题 -> 问题转化为训练数据 -> 训练提升模型 -> 模型改进应用。
遵循这六个模块,你就能一步步地将一个简单的 AI 想法,系统化地构建成一个健壮、可靠、且能持续进化的 Harness 应用。
Part 4: 真正的护城河——为什么说 Harness 远比 Model 重要
在 LLM 发展的早期,谁拥有更强大的基础模型,谁就拥有了最深的护城河。OpenAI 的 GPT 系列就是最好的证明。然而,随着技术的快速扩散和开源模型的崛起(如 Llama、Mistral、Claude),纯粹的模型能力差距正在迅速缩小。当大家都能轻易获得一匹“千里马”时,竞争的焦点自然就转移了。
在 2026 年的今天,真正的、可持续的护城河,不再是拥有模型,而是构建高效 Harness 的工程能力。
这个论断基于以下几点:
-
价值在应用,而非模型本身:用户不会为你的模型有多强大而付费,他们只会为你能解决他们什么问题而付费。而解决实际问题,需要的是一个完整的、可靠的应用系统,这正是 Harness 的定义。一个由 GPT-4 驱动但 Harness 设计拙劣的应用,其用户体验可能远不如一个由优化良好的开源模型驱动、但拥有顶级 Harness 的应用。
-
工程复杂度是隐性壁垒:构建一个“Hello, World”级的 RAG 应用可能只需要一天,但要构建一个如“六层架构”所述,具备高可靠性、可观测性和可治理性的生产级 Harness 系统,其工程复杂度不亚于任何一个传统的大型分布式系统。这其中涉及的领域知识、架构决策、以及无数的“know-how”,构成了难以被快速复制的壁垒。
-
数据飞轮构筑长期优势:如“模块六”所述,一个设计精良的 Harness 系统,其核心是一个强大的数据飞轮。通过持续的评估和反馈,系统能源源不断地从真实用户交互中学习,生成专属于这个应用场景的高质量数据。这些数据可以用来微调模型,使其在特定领域的能力远超通用模型,也可以用来优化 RAG 的检索策略,改进工具的使用方式。你的 Harness 越好,你获取高质量数据的效率就越高;你的数据质量越高,你迭代和改进 Harness 的速度就越快。 这个正反馈循环一旦建立,将形成强大的竞争优势。
-
评估体系定义了质量天花板:正如 OpenAI 的联合创始人 Andrej Karpathy 所说,构建 LLM 应用的挑战,很多时候是评估的挑战。你无法改进你无法衡量的东西。一个拥有成熟、自动化评估体系(Harness 的 L6 层)的团队,能够以十倍于竞争对手的速度进行实验、迭代和优化,因为他们能立刻知道每次改动是好是坏。这个“快速迭代”的能力,本身就是一道深不见底的护城河。
回顾 OpenAI 的发展史,其早期的成功不仅在于 GPT 模型本身,更在于他们围绕模型建立的强大评估和数据引擎。他们发布的 Codex 论文中,就详细阐述了如何创建一个名为 HumanEval 的评估基准,来严谨地衡量代码生成模型的“函数级正确性”。这种对评估的极致追求,正是 Harness 思维的体现。
因此,当行业进入“后模型时代”,企业和开发者的关注点应该从“我们用的是哪个模型?”转向“我们的 Harness 系统有多强?”。这包括我们的数据处理能力、流程编排能力、工具集成能力,以及最重要的——我们的评估和闭环迭代能力。
结语:从“马夫”到“AI 架构师”的身份转变
我们正处在一个激动人心的技术拐点。大型语言模型这匹“野马”,已经向我们展示了它颠覆一切的潜力。然而,历史一再证明,任何革命性的力量,最终都需要通过同样革命性的“工程化”来驯服和普及。蒸汽机需要铁路系统,电力需要电网,而 LLM,需要 Harness Engineering。
我们必须认识到,单纯的“Prompt 调优”或“RAG 搭建”,只是这场宏大变革的序曲。它们是必要的技能,但远不足以构建起未来的智能应用。真正的挑战和机遇,在于将我们深厚的软件工程经验——关于架构、关于可靠性、关于可观测性、关于系统化测试——与 LLM 的新范式相结合。
这意味着我们需要一次身份的转变:
- 从一个追逐“神级 Prompt”的 AI 炼丹师,转变为一个设计健壮数据流和评估体系的 AI 架构师。
- 从一个仅仅“使用”AI 的 应用开发者,转变为一个构建和驾驭 AI 系统的 Harness 工程师。
未来,决定一个 AI 应用成败的,将不再仅仅是其核心模型的聪明程度,更是其外围 Harness 系统的工程化深度。现在,正是我们拿起图纸,开始“造车”的最佳时机。
参考文献与延伸阅读
-
[OpenAI Codex 论文] Mark Chen, et al. (2021). “Evaluating Large Language Models Trained on Code.” arXiv:2107.03374.
- OpenAI 官方发布的关于 Codex 模型的技术报告,详细介绍了其如何在一个包含 164 个手写编程问题的数据集(HumanEval)上进行评估。这是理解“以评估驱动模型迭代”思想的经典文献。
-
[Anthropic “Constitutional AI” 论文] Yuntao Bai, et al. (2022). “Constitutional AI: Harmlessness from AI Feedback.” arXiv:2212.08073.
- Anthropic 提出“宪法 AI”的开创性论文,详细阐述了如何使用 AI 自身(而非人类)来进行反馈和对齐,是“LLM-as-a-Judge”和“裁判-运动员”分离思想的源头。
-
[LangChain 博客: Agent 评估准备清单] (2026). “Agent Evaluation Readiness Checklist.”
- LangChain 官方博客文章,提供了一份非常实用的清单,指导开发者如何从零开始建立 Agent 的评估体系,其中提到了
0.95^20的例子,强调了构建“黄金数据集”的重要性。
- LangChain 官方博客文章,提供了一份非常实用的清单,指导开发者如何从零开始建立 Agent 的评估体系,其中提到了
-
[Google Cloud: 提示工程指南] (2026). “Prompt Engineering for AI Guide.”
- Google 官方提供的提示工程最佳实践,清晰地定义了 Prompt Engineering 的角色和技巧。
-
[Redis 博客: 上下文工程最佳实践] (2025). “Context engineering: Best practices for an emerging discipline.”
- 一篇深入探讨 Context Engineering 的文章,明确了其与 Prompt Engineering 的区别,并强调了 RAG 在其中的核心地位。
-
[Alci.dev: 什么是评估框架] (2026). “What is an Evaluation Harness? Definition & examples.”
- 对
Evaluation Harness这一概念的清晰定义,并列举了业界主流的评估框架,如lm-eval-harness,HELM和OpenAI Evals,有助于理解评估层的生态。
- 对
-
[Anthropic 博客: 解密 AI Agent 的评估] (2026). “Demystifying evals for AI agents.”
- Anthropic 官方分享的关于如何评估不同类型 Agent(代码、研究、对话等)的最新思考,深入探讨了 LLM-as-a-Judge 在实践中的应用和挑战。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)