X-World:可扩展端到端驾驶中可控自我为中心多摄像头世界模型
26年3月来自小鹏汽车的论文“X-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving”。
在端到端自动驾驶时代,可扩展且可靠的评估变得日益重要。在这一时代,视觉-语言-动作(VLA)策略直接将原始传感器数据流映射到驾驶动作。然而,当前的评估流程仍然严重依赖于实际道路测试,这不仅成本高昂,而且场景覆盖范围有限,难以复现。这些挑战促使开发一种能够根据预设动作生成逼真未来观测结果的真实世界模拟器,同时保持长期可控性和稳定性。提出 X-World,一个基于动作条件的多摄像头生成式世界模型,它直接在视频空间中模拟未来观测结果。给定同步的多视角摄像头历史记录和未来动作序列,X-World 可以生成跟随指令动作的未来多摄像头视频流。为了确保场景展开的可复现性和可编辑性,X-World 还支持对动态交通智体和静态道路元素的可选控制,并保留用于外观级控制(例如,天气和时间)的文本提示界面。除了世界模拟之外,X-World 还支持通过外观提示进行视频风格迁移,同时保留底层动作和场景动态。X-World 的核心是一个多视角潜在视频生成器,旨在明确地鼓励在各种控制信号下实现跨视角几何一致性和时间连贯性。实验表明,X-World 能够生成高质量的多视角视频,其特点包括:(i) 跨摄像头视角一致性强;(ii) 在长时间滚动过程中保持稳定的时间动态;(iii) 具有高度可控性,能够严格跟踪动作并忠实地遵循可选的场景控制。这些特性使得 X-World 成为可扩展且可复现评估的实用基础。其流式交互式滚动界面进一步使 X-World 非常适合通过闭环仿真进行端到端自动驾驶系统的在线强化学习。
数据格式
X-World 模型基于整理的数据集进行训练,该数据集包含大量高保真度的真实世界驾驶序列。这些序列的特点是其多样性,涵盖了各种外部环境、不同的自车行为以及复杂的多智体交互。每个数据样本构成一个 10 秒的时间段,并整合了以下多模态数据流:
• 多视角视频流:来自七个环绕摄像头的同步视频流。
• 动态物体轨迹:动态智能体(例如车辆、行人)的序列,这些动态智体通过高精度动态感知模型识别。
• 静态场景元素:从高精度静态感知模型获取的静态基础设施(例如车道、交通标志)的标注。
• 文本场景描述:由视觉语言模型 (VLM) 生成的驾驶场景自然语言描述。
视频数据以每秒 12 帧 (FPS) 的速率记录。每一帧都通过七个不同的、经过校准的摄像头视角提供全面的 360 度环视视图:前窄视角、前鱼眼视角、前左视角、前右视角、后左视角、后右视角和后视角。这些摄像头的精确空间配置和视场重叠旨在确保车辆周围的完整覆盖,如图左 (a) 所示。注:图右(b)是自我纵向动作的分布信息。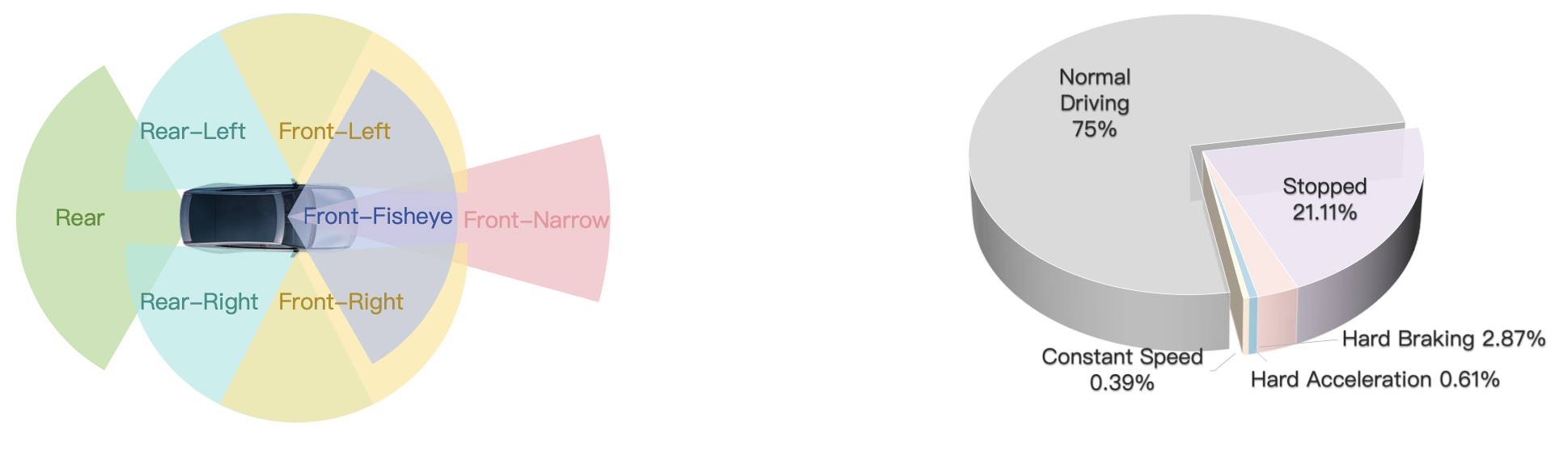
视频标注
为了在 X-World 中实现精细控制和语义理解,构建一个专为自动驾驶场景定制的大规模视频标注流程。与通用视频标注不同,该标注侧重于驾驶相关的属性,这些属性对于可控场景生成和后续评估至关重要。
标注方案。根据定量评估协议,每个视频片段都从四个主要维度进行标注:
• 宏观环境:天气(晴天、阴天、雨天等)、时间(黎明、白天、黄昏、夜晚)、光照条件和驾驶环境(区域类型 + 道路类型)。
• 路况:路面状况(平坦/崎岖)、坡度(上坡/下坡)和路况(干燥/潮湿/有水坑)。
• 交通基础设施:是否存在车道线、护栏、交通标志、交通信号灯、建筑物、植被和特殊设施(桥梁、施工区域、收费站)。
• 交通密度:五级等级,从“空旷”到“拥堵”。
自动化流程。给定数据集,采用基于VLM的自动化方法。对于每个 10 秒的视频片段,从每个 10 秒片段中的所有 7 个摄像头采集同步图像序列。多视角图像序列连同编码字幕模式的结构化提示一起输入到模型中。
示例。以下是流程生成的典型视频描述:
“视频拍摄于阳光明媚的白天,地点是一条平坦的城市高速公路,光线充足。道路两旁高楼林立,绿树成荫,清晰的白色车道线和路边护栏清晰可见。远处有一座人行天桥横跨道路。交通信号灯和标志清晰可见。车流量适中。”
这种结构化的、规则驱动的方法确保数据集中的每个视频片段都配有准确、一致且语义丰富的文本描述,为 X-World 的可控生成能力奠定了基础。
自动标注
为了理解数据的自然分布,实现对数据分布的更精细控制,并便于快速选择数据进行小规模特征验证,开发一个全面、结构清晰且粒度细化的三级标签分类体系。基于任务需求,定义四大类标签:
• 环境标签:描述场景层面的整体特征,包含 11 个子类别:天气、光照、路面状况、路面类型、道路曲率、道路坡度、道路结构、道路类型、交通状况、车道清晰度和车道数量状况。每个子类别包含若干细粒度标签,因此环境标签类别下共有 50 个三级标签。
• 静态标签:包含 24 个三级标签,分为道路标线、车道线、道路边界、交通标志、信号灯、交通信号灯和静态障碍物。
• 动态标签:重点描述五种类型的交通参与者。
• 自车行为标签:包含 21 个三级标签,主要分为纵向、横向、物体交互、场景交互和非合理行为。
该标签分类体系的构建主要依赖于四个信息源:(i) 高精度动态感知网络,主要用于静态标签;(ii) 高精度静态感知网络,主要用于动态标签;(iii) 结合高精度传感器获取的车辆姿态信息的鲁棒在线姿态估计系统,主要用于自车行为标签;以及 (iv) 通用VLM,主要用于环境标签。
数据分布
其投入大量的计算资源来标注整个训练数据集,从而能够全面分析自然数据分布,并基于统计分析和模型性能对训练集进行相应的调整。利用这些标签,进行大量的迭代实验,从中提取对模型训练有价值的指导。例如,上图 (b) 展示自车纵向行为的分布:绝大多数为正常驾驶(74.8%),其次是静止状态(21.0%),其余类别构成长尾分布。该分析直接指导数据收集——例如,如果模型在急加速时表现不佳,会优先采集更多此类样本以提高整体性能。
概述
现代具身智体(包括自动驾驶系统)主要通过摄像头感知和推理世界。因此,这些智体可获取的有效“世界状态”并非一个紧凑的潜变量向量,而是一个高维图像流,即视频。这样本文构建一个直接在与下游策略最相关的观测空间中运行的世界模型:动作条件视频。
如图所示,提出 X-World,这是一个生成式世界模型,它被构建为一个基于动作条件的多摄像头视频生成模型。给定一段同步的多视角摄像头视频流的简短历史记录,该模型可以预测执行特定未来动作序列后产生的未来摄像头观测结果。具体来说,模型以以下内容作为输入:(i) 来自 V 个摄像头的多摄像头视频历史记录 X1:V_t−L:t,代表场景的近期视觉上下文;(ii) 自车将要执行的未来驾驶动作 A_t:t+H;以及 (iii) 可选的场景控制条件 C,用于指定环境的可控方面。然后,它生成相应的多摄像头未来视频 Xˆ1:V_t+1:t+H,该视频 (i) 视觉上逼真,(ii) 在不同视角之间保持一致,以及 (iii) 忠实地执行指令动作。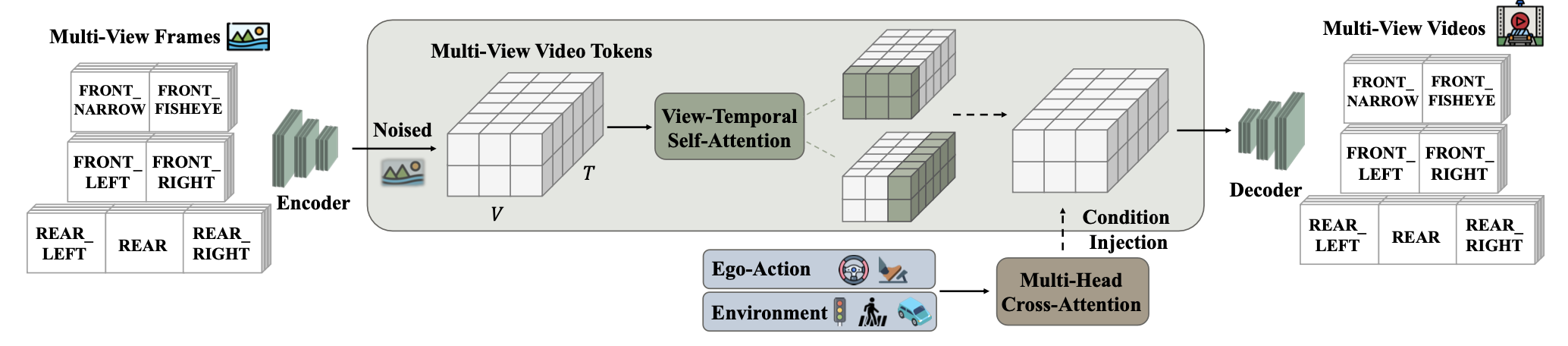
评估和训练的一个关键实际要求是可复现性:通常希望模拟器在特定条件下生成相同的未来(或一组受控的未来)。为此,模型可选地支持对动态交通主体(例如,周围车辆、行人)和静态道路元素(例如,车道拓扑结构、道路布局提示)的显式控制。当提供此类条件 C 时,模型可以生成场景一致且可复现的未来场景,从而实现受控的反事实部署、公平的基准测试和系统的压力测试。
模型设计
X-World 基于最先进的 WAN 2.2 [11] 构建,遵循其潜视频生成范式,该范式将视频 VAE 与基于 DiT 的潜去噪器 [10] 相结合。具体而言,与 WAN 2.2 5B [11] 一致,采用一种高压缩率的 3D 因果变分自编码器,实现 16 倍的空间压缩比和 4 倍的时间压缩比,生成通道维度为 48 的潜变量。在这种紧凑的时空潜变量空间中运行,显著降低计算和内存开销,从而 (i) 能够对更长的视频序列进行预训练,以更好地捕捉丰富的时空依赖关系,以及 (ii) 加快下游部署的推理速度。
为了解决多摄像头自动驾驶场景中几何一致性的关键挑战,引入一个定制的 DiT 模块,该模块专为 X-World 的多条件生成框架而设计。该设计有两个关键目标:(i) 强制执行具有强跨视角一致性的时空建模,以及 (ii) 在异构条件信号(例如,动作、摄像头参数、动态代理、静态道路元素和文本提示)下实现可控生成,并将跨条件干扰降至最低。
视角-时间自注意机制。架构的核心是一个视角-时间自注意模块,它显式地对时间维度和跨视角维度上的交互进行建模。具体来说,自注意机制在多个摄像头和多个时间步长上交替地对潜token执行,从而允许特征在不同视角之间对齐和交换信息,同时保持时间一致性。这种机制有助于在同步摄像头之间保持一致的几何形状、物体标识和运动模式。
条件注入策略。采用适合模态的条件注入机制来平衡表达能力和稳定性。具体来说,使用:(i)自适应层归一化来注入动作和扩散/流动时间步长;(ii)加性嵌入来注入摄像头参数;以及(iii)交叉注意机制来注入高级结构化条件,包括动态智体、静态道路元素和文本提示。
用于异构条件的解耦交叉注意机制。采用解耦的交叉注意层,以模块化的方式融合异构条件源。并非将所有条件都注入到单一的共享注意通路中,而是为不同的模态分配独立的交叉注意分支。保留 WAN 2.2 5B 中的原始文本条件分支,以支持可选的外观和场景级控制,例如天气、日期和其他全局属性。对于动态和静态控制,引入新的交叉注意分支。这种解耦减少条件类型之间的相互干扰,提高可控性,使模型能够更忠实地跟踪每个条件信号。
条件
X-World 提供一套全面的条件控制接口,能够对驾驶场景生成过程进行精细化操控。这些接口包括自车动作、动态代理、静态道路元素(例如车道线和边界)以及相机内部和外部参数。
自车动作。在世界模型中控制自车动作,可以实现基于规划机动动作的因果一致的未来仿真,这对于闭环规划和安全验证至关重要。
与高级指令条件不同,该模型能够通过输入一系列未来的运动学状态(速度、曲率、横滚和俯仰)来实现直接且连续的控制。考虑到这四个运动学变量的数值尺度差异,首先通过符号对数归一化 [13] 对每个变量进行归一化。为了捕捉标量值的细微差别,随后应用傅里叶特征编码。然后,使用多层感知器 (MLP) 将编码后的表示投影并对齐到潜空间维度。最后,引入时间戳嵌入,并通过adaLN-Zero [10] 将组合后的条件信号注入扩散模块。
动力学智体。在世界模型中控制动力学智体能够模拟多样化的交互式交通行为,这对于在真实的多智体场景下评估自动驾驶策略的鲁棒性和安全性至关重要。
为了表示动力学智体,首先从检测模型中提取它们的语义类别(例如,SUV、行人、自行车)和空间坐标。每个类别属性都通过umT5编码器[4]进行编码,而空间坐标则经过归一化处理,并使用傅里叶特征编码进一步处理,以保留精细的位置细节。然后,这些异构特征被连接起来,并通过多层感知器(MLP)投影到统一的特征维度。为了有效地控制生成过程,将生成的智体嵌入通过交叉注意层注入到潜空间中,使模型能够在每次去噪步骤中动态地关注相关的智体信息。这种设计能够灵活地控制多个交通参与者的行为和位置。
静态元素。在世界模型中控制静态道路元素(例如车道线、边界)可以实现对各种道路拓扑结构和交通规则的指定,这对于在不同的环境布局下生成符合场景且几何上合理的未来模拟至关重要。
与用于动力学智体的编码和注入方案类似,首先通过检测模型提取静态道路元素的语义类别和位置信息。类别标签使用 umT5 进行编码,而归一化的位置坐标则通过傅里叶特征编码嵌入。然后,这些表示通过多层感知器 (MLP) 投影并对齐到目标特征维度,随后通过交叉注意层注入到扩散潜空间中。然而,与动力学智体不同,静态元素在推理过程中需要更强的条件约束,以确保几何和语义的一致性。为此,在测试阶段采用无分类器引导 (CFG),并在训练阶段引入随机丢弃(dropout)策略。这种设计确保模型对不同级别的条件控制保持鲁棒性,并且能够在明确的静态约束下忠实地生成与场景一致的未来。
相机参数。在世界模型中控制相机内参和外参,可以生成基于不同传感器配置和视角的未来图像序列,从而适应各种车辆类型和相机设置。这种能力对于学习视角感知表示以及在闭环仿真中评估异构传感器配置下的规划模型至关重要。
相机内参和外参首先分别进行归一化,然后连接起来,并通过多层感知器(MLP)进行特征投影和维度对齐。得到的嵌入通过加性条件化模块直接注入到潜空间中。
I2V/V2V/C2V 统一
X-World 通过控制训练期间历史输入的长度来支持多种生成模式。令 L 表示提供给模型的干净历史帧的数量。当 L=1 时,模型以图像-到-视频(I2V)模式运行,其中第一个多相机帧锚定外观和几何形状,模型生成后续的未来帧。当 L>1 时,模型自然而然地变为视频-到-视频 (V2V) 模型,它基于多帧观测历史生成未来的多视角视频。当 L=0 时,模型生成的视频完全基于提供的动作和其他控制条件,称之为条件-到-视频 (C2V) 模型。
注:C2V 是一个有用的训练辅助产品,但严格来说它并非世界模型,因为它不依赖于当前观测状态,因此无法对状态转换进行建模。尽管如此,C2V 仍然具有实际价值:它能够在固定动作和场景控制下实现可控的数据合成和外观驱动的风格迁移(例如,改变天气或时间),从而补充了主要世界模型的功能。
训练
如图所示,模型分两个阶段进行训练。第一阶段将一个大型预训练视频生成器适配成一个完全可控的双向多摄像头世界模型,而第二阶段则将其转换为一个用于实时交互和长时域滚动的流式自回归模拟器。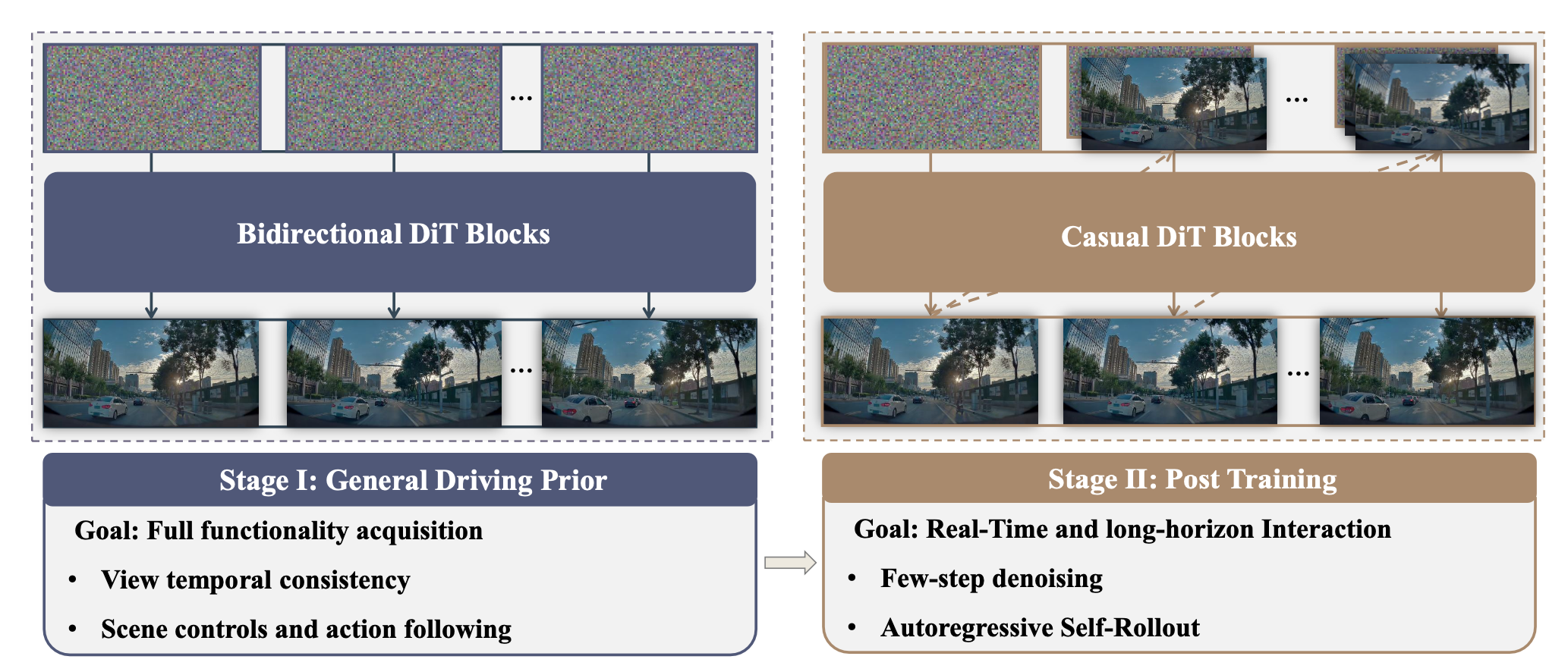
第一阶段:用于精确可控性的双向 I2V 训练
初始化。用 WAN 2.2 5B TI2V [11] 初始化 X-World。从WAN 继承的参数直接加载,而为多摄像头和多条件设置新引入的模块则随机初始化。
训练数据。第一阶段 (Stage-I) 使用同步的多摄像头短视频片段进行训练,每个片段包含 81 帧。每个样本都与相应的驾驶动作配对,并在可用时包含场景级文本描述和结构化的动态/静态控制信号。
修正流目标。令 y 表示要生成的目标潜视频(例如,未来多摄像头帧的潜序列),令 c 表示条件输入,其中包括历史潜值(当 L > 0 时)、动作、摄像头参数、可选的动态/静态控制以及文本提示。根据修正流[9],对 t ∼ U (0, 1) 进行采样,并构建数据样本 y_0 ∼ p_data (y | c) 与高斯噪声 y_1 ∼ N (0, 1) 之间的插值:
y_t = (1 − t)y_0 + ty_1.
修正流学习沿该修正路径的时变速度场 v_θ (y_t , t, c),使其与恒定目标流 y_1 − y_0 相匹配。第一阶段的训练目标是:L_RF(θ)。
结果与局限性。经过第一阶段的训练,获得一个功能齐全的双向世界模型,该模型能够生成具有精确可控性的高质量多摄像头未来场景。然而,与WAN类似,第一阶段 (Stage-I) 依赖于双向多步采样过程(通常高质量需要约 50 个精细化步骤),该过程离线生成完整的短视频片段,因此更适合短视频合成,而非低延迟、长时域的流媒体发布。
第二阶段 (Stage-II):用于流媒体长时域仿真的因果少步训练
第一阶段 (Stage-I) 生成一个强大的世界模型,最适合短视频生成。然而,由于它依赖于多步双向迭代过程,因此并不直接适用于实时交互式长时域发布。为了解决这一局限性,在第二阶段 (Stage-II) 中,将其转换为因果少步生成器。与离线生成完整视频片段的双向模型相比,我因果模型支持流媒体推理:它逐块生成并返回未来的视频,而无需等待整个序列生成完成。这实现低延迟交互,并自然地适用于闭环设置中的长时域展开。
分块因果架构。因果生成器天然支持自回归推理:未来的分块按顺序生成,每个分块仅以过去的上下文(历史观测、先前生成的分块以及动作/场景条件)为条件。在这种设置下,KV缓存通过重用先前分块的注意K/V进一步提高效率,避免每一步都重新计算过去上下文的注意,并大幅减少推理计算。借鉴 CausVid [16],将第一阶段的双向模型修改为分块因果模型。具体来说,将潜序列沿时间维度划分为连续的分块。在每个分块内,tokens仍然进行双向交互,以保持局部时空一致性和生成质量。然而,通过阻止token关注任何未来的分块来强制执行分块级因果关系。因此,该模型在保持丰富的块内建模能力的同时,实现了时间上的因果关系。这种设计提供了一种有利的权衡:它既支持在线生成和低延迟发布,又避免了严格的基于token因果视频生成中常见的质量下降问题。
少步自强制训练。为了在真实的发布条件下训练第二阶段的因果生成器,采用自强制训练[6]。该模型并非基于真实历史上下文(教师强制/扩散强制[3]),而是基于自身的自回归发布进行训练,这显著减少训练集与测试集之间的不匹配,而这种不匹配通常会导致长时程生成中误差的累积。具体来说,生成过程以分块方式进行,训练和推理均启用了KV缓存。对于每个新分块,首先使用标准高斯分布初始化其潜分布,然后基于先前生成的干净帧(以及动作和可选的动态/静态条件)执行四步去噪。这生成一个由第二阶段因果模型诱导的自展开分布。然后,使用分布匹配蒸馏(DMD,distribution matching distillation)损失[14, 15]优化模型,该损失最小化自展开分布与由第一阶段双向教师模型表示的目标分布之间的反向KL散度。通过在自生成的上下文中匹配教师分布,自强制方法可以减轻曝光偏差并减少自回归展开中的累积误差,从而实现更稳定的长时域生成。此外,由于每个分块都经过训练,以使用固定的、较小的去噪预算生成,因此最终模型自然而然地成为一个适用于实时流模拟的少步生成器。
利用展开KV缓存生成长视频。推理过程中,用固定大小的滚动KV缓存支持长时域展开。具体来说,分配一个预定容量的缓存来存储先前生成的视频块注意KV张量。随着视频块的逐个生成,新生成的KV会被添加到缓存中。当缓存达到容量上限时,会按照先进先出(FIFO)规则移除最旧的条目,从而确保模型始终关注最新上下文的滑动窗口。这种设计既保证内存使用量有限和运行时间稳定,又为连贯的长视频展开提供足够的近期时间上下文。
总而言之,第二阶段生成一个因果的、少步的、流式多视图生成世界模型,该模型保持第一阶段学习的可控性,同时实现端到端/VLA自动驾驶系统所需的实时交互和长视频生成,满足可扩展评估和在线强化学习训练的需求。
除了简单的视频生成之外,X-World 还可作为高保真、响应迅速且可控的平台,用于开发和验证下一代视觉-语言-动作 (VLA 2.0) 策略。
VLA 2.0 闭环评估引擎
虽然传统的基于 3DGS 的仿真评估能够精确地重现端到端驾驶模型的行驶轨迹,但它们无法处理自动驾驶模型进行大幅度变道,或行驶轨迹与真实车辆采集的日志完全不同的场景。X-World 作为生成式仿真器,能够实现 VLA 2.0 的全闭环测试。
响应式部署:与静态日志回放不同,X-World 能够响应自车实时规划的行驶轨迹。如果 VLA 2.0 执行突然制动或转向操作,X-World 会相应地更新未来的多视角观测数据,从而保持时间和因果关系的一致性。
安全关键指标:通过在 X-World 中运行 VLA 2.0,可以在一个与真实世界视觉分布高度相似的虚拟环境中测量高级性能指标,例如碰撞率、目标完成进度和乘坐舒适度。
场景 1(反事实行动展开)。在记录的视频中,自车选择等待前方车辆,而该车辆实际上已停放。在相同的初始场景下,用 X-World 展开一个基于替代策略行动的反事实未来:测试的策略模型决定绕过停放的车辆。 X-World 生成了一个与此操作一致的连贯的多摄像头未来场景,从而能够对策略是否能在确保安全的前提下采取更高效的行动进行可扩展的评估。
场景 2(针对安全关键压力测试的场景编辑)。在记录的视频中,自车直线行驶,从左前方经过一辆附近的黑色轿车。然后,编辑场景,插入一名骑自行车的人,他从黑色轿车后方突然出现,最初被轿车遮挡。在这种编辑条件下,X-World 生成具有一致遮挡和运动的高质量未来场景,并且测试的策略模型成功地在骑自行车的人之前停车,避让自行车,安全避免了碰撞。
这些示例共同表明,X-World 可以通过以下方式支持闭环评估:(i) 在同一场景下展开不同的自车行动;(ii) 通过可控的场景编辑生成逼真的、安全关键的反事实场景,从而为端到端/VLA 策略开发提供了一个实用的测试平台。
在线强化学习模拟器
为了弥合模仿学习与专家级表现之间的差距,用 X-World 作为在线强化学习 (RL) 的训练环境。
硬场景特化:我用 X-World 的可控性,在 VLA 2.0 通常表现不佳的场景(例如十字路口的“隐形人”或拥堵路段的犹豫不决的变道)中对其进行压力测试。
高效探索:通过在 X-World 中微调策略,VLA 模型可以探索各种不同的动作序列并获得即时的视觉反馈。这种迭代循环使模型能够学习从接近事故状态(在现实世界中过于危险而无法探索的场景)中恢复行为。
大规模数据合成与增强
X-World 充当生成式数据工厂的角色,合成难以通过车队车辆收集的稀有且高价值的数据资产。
极端情况生成:可以通过程序生成安全关键事件,例如极端天气条件、罕见车辆类型或异常行人行为,从而提供均衡的训练分布,缓解长尾问题。
海外扩展:为了支持全球战略,X-World 支持数据“零样本迁移”。通过基于本地化的外观提示(例如,欧洲道路标线、独特的交通标志或左侧通行规则)对模型进行条件化,可以将国内驾驶数据转化为海外训练资源,从而显著加快国际部署速度,而无需进行大量的本地数据收集。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)