投机推理技术原理
作者:昇腾实战派 * 疆浙户
关注公众号:AI模力圈
背景
随着大语言模型在实际应用中规模不断增长,推理阶段的性能瓶颈日益凸显。传统自回归生成方式每次仅输出一个 token,导致推理延迟高、硬件利用率低,难以满足实时性要求。为突破这一限制,投机推理(Speculative Decoding)作为一种关键性能优化技术应运而生。
投机推理(Speculative Decoding)是在大模型推理阶段广泛采用的一类性能优化技术,核心目标是在不降低输出质量(或在可控范围内)的前提下,显著降低推理时延并提高吞吐量。该方法已成为当前主流大模型推理系统的关键工程手段。
昇腾设备部署可通过vllm-ascend框架开启投机推理
投机推理的核心原理
基本思想
投机推理的基本思想是:
先由一个更小、更快的模型“猜测”未来若干个 token,再由目标大模型进行并行验证;验证通过的部分直接接受,未通过的部分回退并由大模型重新生成。
本质上是用计算便宜的预测,来减少计算昂贵的逐 token 自回归推理。
为什么需要投机推理:
大模型推理通常采用自回归的方式,每次前向传播只输出一个单词,这是限制推理速度的主要原因。token_1 -> token_2 -> token_3 -> ... -> token_n
这种方式的每一步都依赖于前一步的结果,会导致:难以并行、NPU利用率不高、长文本推理时延显著等问题。
核心流程
1.Draft(草稿生成)
- 使用一个小模型(Draft Model)
- 一次性预测未来 k 个 token(如 4~16 个)
2. Verify(并行验证)
- 使用目标大模型(Target Model)
- 并行计算这 k 个 token 的概率分布
- 逐个比对是否与草稿一致
3. 验证规则
- 若草稿 token ∈ 大模型高概率区间 → 接受
- 一旦出现不一致 → 回退到该位置
- 丢弃之后所有草稿 token
- 由大模型从该位置继续生成
4.示例推理流程
假设希望生成下一个 token 序列:
-
Draft 模型一次性生成:
[t1, t2, t3, t4] -
Target 模型并行计算概率:
P(t1 | ctx)P(t2 | ctx, t1)P(t3 | ctx, t1, t2)P(t4 | ctx, t1, t2, t3) -
验证结果:
t1 、t2 ✓t3 ✗ -
处理策略:
接受 t1、t2
丢弃 t3、t4
从 t3 开始由 Target 模型重新生成
如上图所示,每次迭代小模型都会生成一个文本序列,经过大模型验证后,绿色文本被接受,红色和蓝色的文本则被拒绝。这样每次迭代可以生成多个单词,推理速度大幅提升。此外,相比于模型压缩技术,投机采样不会损失模型的生成质量。
代码解读
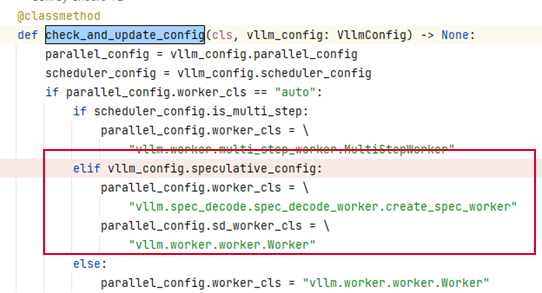
根据配置动态选择不同的工作器类:
- 如果配置中启用了投机推理(
vlm_config.speculative_config),则使用SpecDecodeWorker。 - 否则,使用普通的
Worker。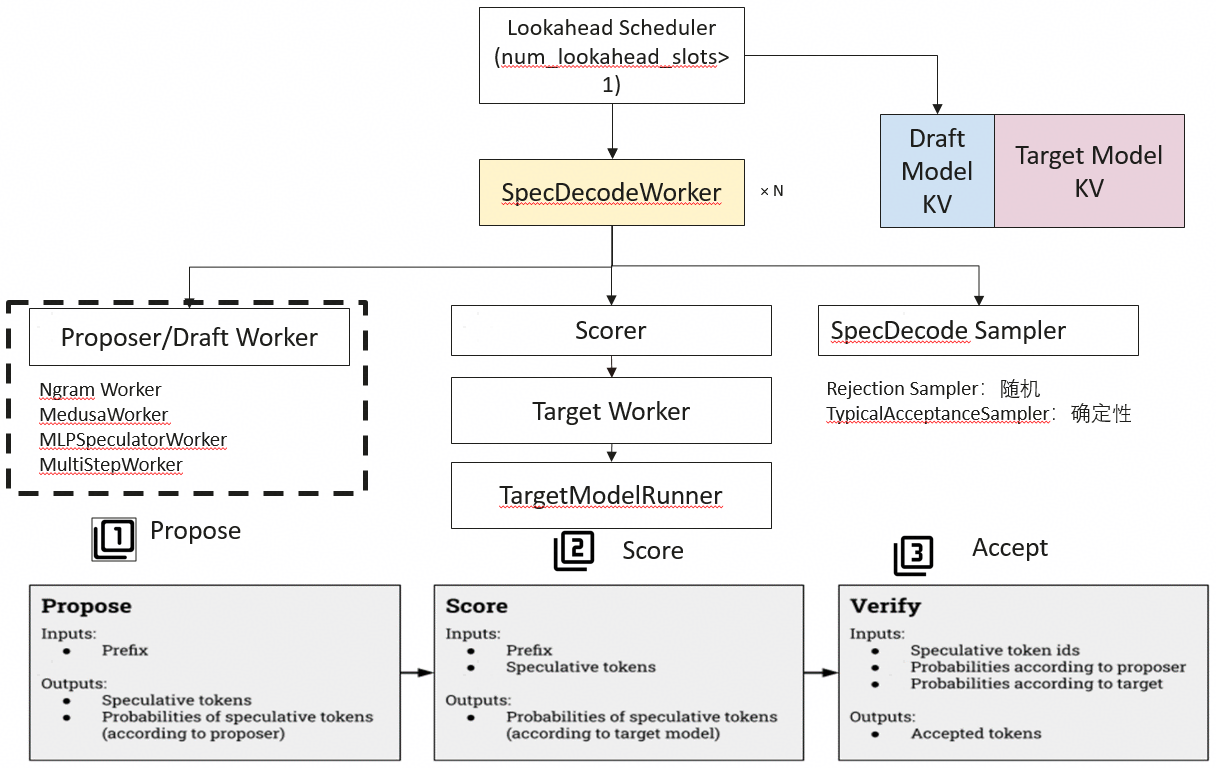
阶段1:调度与提案
- Lookahead Scheduler:
- 当
num_lookahead_slots > 1时激活,负责调度前瞻性任务。 - 将任务分发给 SpecDecodeWorker。
- 当
- SpecDecodeWorker:
- 接收任务,进行初步的解码处理。
- 内部可能包含多种提案器,如 Ngram Worker、MedusaWorker、MLPSpeculatorWorker、MultiStepWorker 等。
- Ngram Worker:轻量级预测模块,用于基于历史 token 的统计规律生成候选序列
- MedusaWorker:多头草稿生成器,源自 Google 提出的 Medusa 架构
- MLPSpeculatorWorker:基于多层感知器(MLP)的轻量级草稿模型执行单元。
- MultiStepWorker:负责协调多阶段、多轮次投机推理流程的调度与控制组件。
- 功能:基于当前前缀生成一组推测的 token 及其概率。
阶段2:评分
- Scorer:
- 接收 SpecDecodeWorker 生成的推测 tokens。
- 调用 Target Worker(即原始大模型)并行计算这些 tokens 的真实概率。
- 输入:Prefix + 推测 tokens。
- 输出:目标模型对每个推测 token 的概率评分。
- Target Worker:
- 将接受的 tokens 传递给目标模型进行最终处理。
- TargetModelRunner:
- 运行目标模型,输出最终结果。
阶段3:采样与接受
- SpecDecode Sampler:
- 使用采样器对比推测概率和目标模型概率。
- 常见的采样器包括:
- Rejection Sampler:拒绝不符合条件的 token。
- TypicalAcceptanceSampler:基于概率差异决定是否接受。
- 接受规则:如果随机采样值小于接受概率,则接受该 token;否则拒绝。
SpecDecodeWorker
进行服务前处理:
- Initialize & load model (初始化并加载模型)
- 初始化目标工作器(target worker)并加载目标模型(target model)。
- 初始化草稿工作器(draft worker)并加载草稿模型(draft model)。
- 初始化投机评分器(Speculative Scorer),并将其与目标工作器(target worker)关联。
- 初始化投机解码采样器(SpecDecode Sampler)。
- Profile memory usage (分析内存使用情况)
- 运行目标工作器(target worker),探测可用于KV缓存(KV cache)分配的显存空间。
- 将探测到的显存空间分配给目标工作器(target worker)和草稿工作器(draft worker),两者分配相同数量的内存块(block)。
- 可用于交换(swap)的CPU空间,目前不在目标工作器和草稿工作器之间划分,因为当前的投机推理实现不支持交换(swap)功能。
- Pre-allocate KV Blocks (预分配KV缓存块)
- 为目标工作器(target worker)预分配KV缓存块(KV blocks)。
- 为草稿工作器(draft worker)预分配KV缓存块(KV blocks)。
Driver 与 Non Driver
driver worker 与 non-driver worker 是 vLLM 推理框架中分布式执行器的两种核心工作进程,其主要区别如下:
核心职责区分
- driver worker(驱动工作进程)
- 角色定位:主控进程,通常与调度器(Scheduler)协同工作。
- 关键职能:
- 接收外部推理请求。
- 与 Prefill 节点进行网络通信,接收 KV Cache 数据。
- 管理共享内存,将接收到的数据通过
tensor_batch_copy线程写入与对应 non-driver worker 共享的内存块中。
- 执行特点:在
_run_workers()方法中,当不启用async_run_tensor_parallel_workers_only参数时,driver worker 会同步地在本进程内执行指定方法(如模型推理),并收集结果。
- non-driver worker(非驱动工作进程/远程TP工作进程)
- 角色定位:实际执行计算的工作进程,通常直接控制 NPU/GPU 等硬件。
- 关键职能:
- 从共享内存中读取 KV Cache。
- 通过 H2D (Host-to-Device) 线程将数据搬运至计算设备。
- 使用 Forward 线程下发计算算子,执行实际的模型前向推理。
- 执行特点:在
_run_workers()方法中,可通过设置async_run_tensor_parallel_workers_only=True实现仅在 non-driver workers 上异步执行任务并返回 Future 对象,从而避免阻塞 driver worker。
协同工作与资源绑定
- 通信纽带:二者通过共享内存进行高效数据交换(如 KV Cache),因此在高性能部署时通常被绑定在同一节点上,以避免跨片访问带来的性能损耗。
- 进程关系:一个 driver worker 通常与一个 non-driver worker 配对,共同完成从请求接收到结果计算的全流程。在分布式场景下,一个执行器(Executor)会管理一组这样的进程对。
设计价值
这种架构实现了控制流与数据流的解耦:driver worker 专注于请求调度与数据I/O,保障系统响应能力;non-driver worker 专注于高效计算,充分发挥硬件算力。二者分工协作,共同支撑高吞吐、低延迟的推理服务。
Driver SpecDecodeWorker处理逻辑
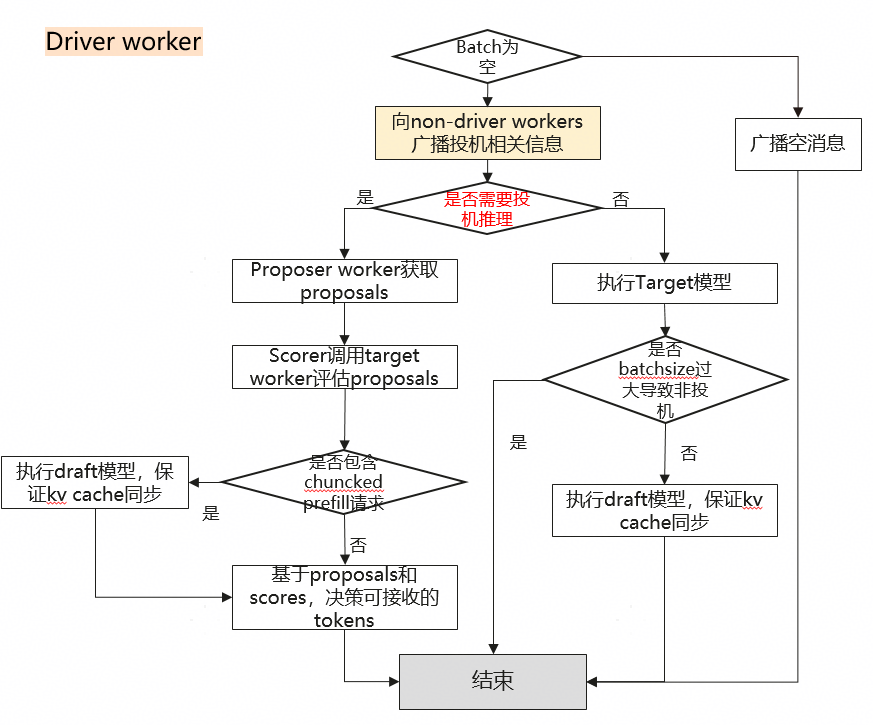
阶段一:初始判断(Batch是否为空?)
- 判断条件:Driver Worker首先检查当前待处理的Batch(批次请求)是否为空。
- **Batch为空 **:如果为空,说明没有实际任务需要处理。Driver Worker会向所有非驱动工作器广播一条空消息,整个流程结束。这通常用于系统空闲时的状态同步或心跳检测。
- **Batch不为空 **:如果有实际请求需要处理,流程进入核心决策环节。
阶段二:投机推理决策(是否需要投机推理?)
这是整个流程的决策核心。Driver Worker在广播了投机推理所需的元信息后,会根据预设策略(如当前系统负载、Batch大小、请求特性等)判断是否启用投机推理。
- **需要投机推理 **:当系统判断使用投机推理能带来性能提升时(通常是Batch较小,资源充足时),进入此路径。
- 生成提议:由专门的 Proposer Worker 调用一个轻量级的**Draft Model(草稿模型)**,为每个请求生成多个可能的下一个token(即“提议”)。
- 评估提议:Scorer(评分器) 会调用强大的 Target Model(目标模型) 来快速评估这些提议的合理性,并给出分数。
- 处理特殊请求:系统会检查Batch中是否包含“分块预填充请求”。
- 如果包含:为了保证Key-Value缓存的正确同步,需要先执行一次Draft模型的前向计算。
- 如果不包含:直接进入下一步。
- 决策与接受:根据Proposer提供的提议和Scorer给出的分数,系统决定接受哪些token。投机解码的成功之处在于,它能一次性接受多个正确的token,从而减少调用大模型(Target Model)的次数,极大提升生成速度。
- 不需要投机推理:当系统判断投机推理不划算时(例如Batch过大,资源紧张,投机本身的开销可能超过收益),采用标准推理路径。
- 直接执行目标模型:直接调用强大的Target Model进行处理。
- 异常情况处理:系统会判断Batch Size过大是否正是导致本次未采用投机推理的原因。
- 如果是:为了保证系统中Draft模型的KV Cache与Target模型同步,仍需执行一次Draft模型。
- 如果否:正常完成Target模型的推理。
阶段三:结束
所有路径执行完毕后,本次调度与推理流程结束,结果返回给用户或进入下一轮调度。
Non Driver SpecDecodeWorker处理逻辑
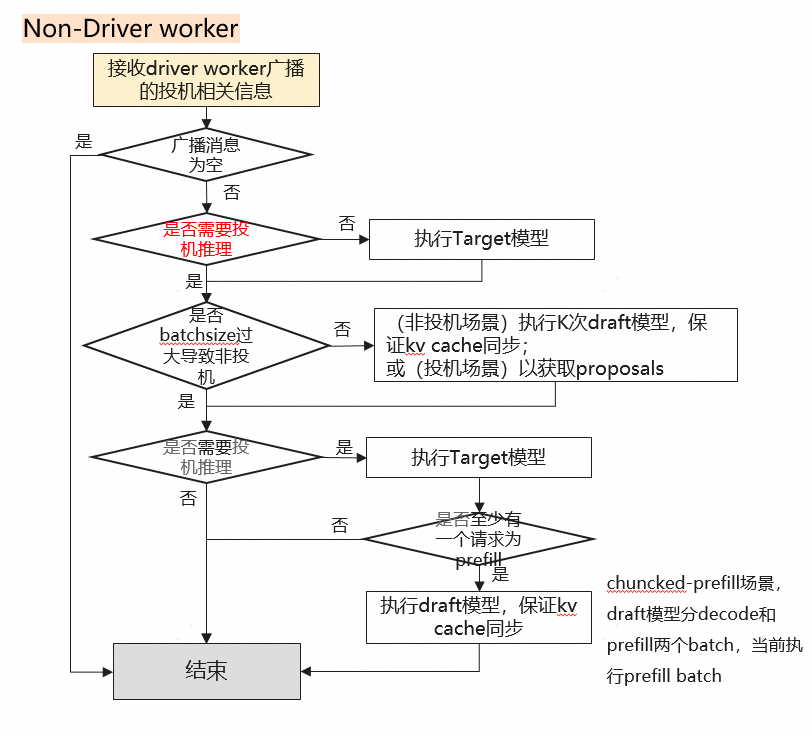
driver worker与non-driver worker之间传输的消息:
- num_lookahead_slots:投机token长度
- no_spec:prefill阶段、或batch过大、或所有请求投机长度为0
- disable_all_speculation:batch size大于配置值,则disable所有投机推理;后续该batch不会再进行投机推理
- run_spec_proposer_for_prefill:batch中是否至少有一个请求为prefill(一般prefill不支持投机推理,只有chuncked-prefill和multi step同时开启时支持投机推理)
在两种场景下,driver worker与non driver worker调用target和draft的顺序要保持一致
- 不需要投机推理:先target后draft同步kv cache
- 需要投机推理:decode阶段:先draft后target; chuncked-prefill和multi step同时开启时,先target再draft
Proposer / Draft Worker
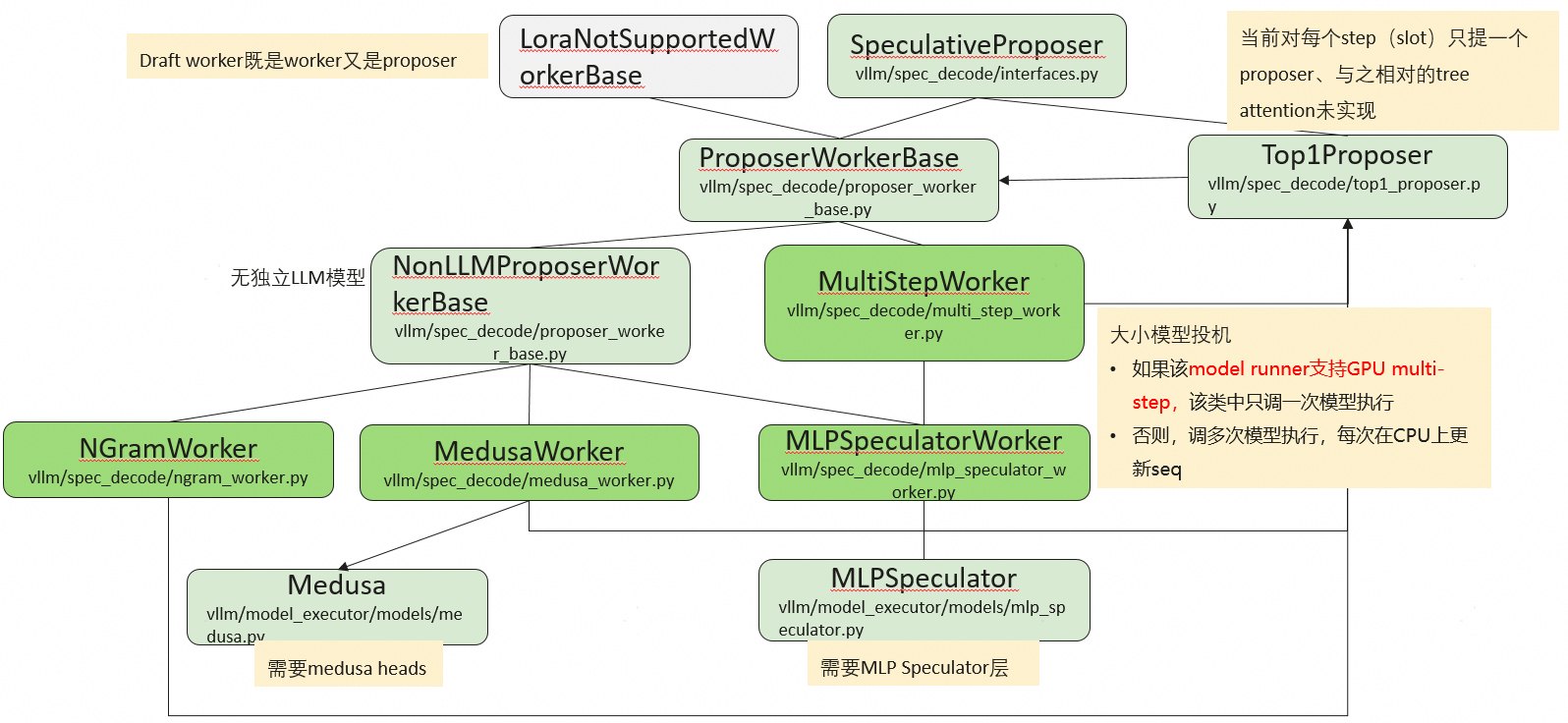
Draft Worker的双重角色:在投机推理框架中,Draft worker 既是一个执行计算的工作单元,也是一个负责提出候选序列的提案者。
核心类结构解析
- 基础接口与类:
SpeculativeProposer:定义了提案者应有的基本行为规范。LoraNotSupportedWorkerBase:一基础工作类,不支持LoRA适配器。
- 提案者工作基类:
ProposerWorkerBase是所有具体提案者的抽象基类. - 具体提案者实现:
ProposerWorkerBase有多个子类,代表了不同的提案策略:Top1Proposer:最简单的提案策略,总是选择概率最高的 token 作为候选。NonLLMProposerWorkerBase:不依赖完整的大型语言模型来生成提案,因此通常更轻量、更快速。衍生出多种具体实现:NGramWorker:基于N-gram语言模型进行预测,通过统计历史 token 序列来推测下一个最可能的token。MedusaWorker:依赖于专门的Medusa模型。Medusa模型在原始模型的基础上添加了多个“Medusa头”,能够同时预测多个未来的 token ,从而加速推理。MLPSpeculatorWorker:依赖于MLPSpeculator模型。使用多层感知机来学习并预测 token 序列。
MultiStepWorker:支持“大小模型投机”的经典范式。内部实现会根据硬件能力进行优化:- 如果底层模型运行器支持XPU多步执行,它会高效地一次性生成多个候选步骤。
- 否则,它会通过多次调用模型执行(可能涉及CPU上的序列状态更新)来模拟多步生成。
Score
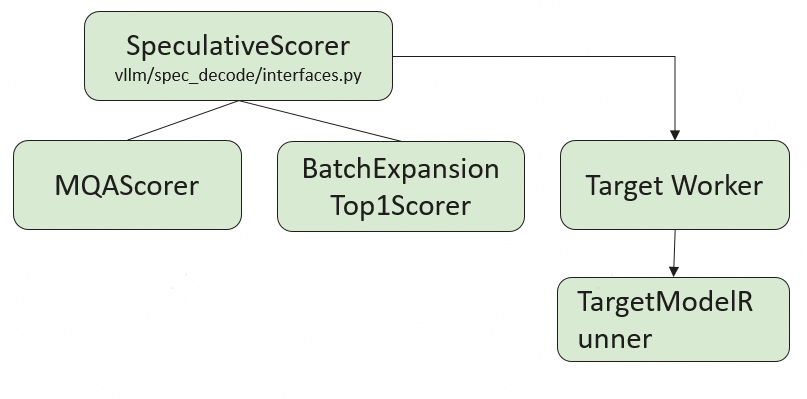
BatchExpansionTop1Scorer
-
适用场景:无专用MQA(Multi-Query Attention)内核的环境。
-
核心思想:通过序列扩展(Batch Expansion) 将每个输入序列复制K+1份(K为投机长度),送入目标模型并行计算概率。
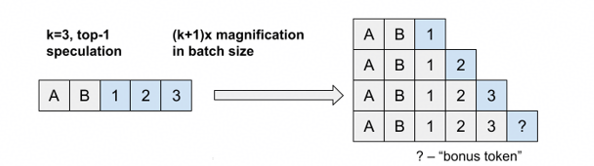
-
缺点:当Batch较大时,扩展会导致计算和内存开销显著增加,效率较低。
MQAScorer
- 适用场景:支持MQA优化内核的环境(如FlashAttention)。
- 核心优化:避免序列扩展,通过定制化的 Attention 内核实现多候选查询的并行计算。
- 对同一序列的多个候选 token,共享Key/Value的加载和 QK 计算,减少重复 I/O 和计算。
- 使用 Eager 模式执行目标模型,结合FlashAttention加速。
- 优势:显著降低Attention模块的计算瓶颈,适合高吞吐场景。
Accept
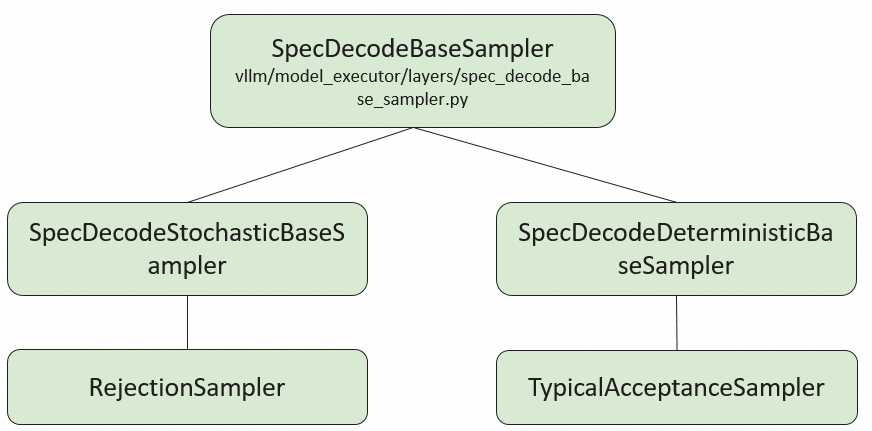
投机推理采样器的基类SpecDecodeBaseSampler及其两类子类,体现了采样策略的两种方向:
- 基类:SpecDecodeBaseSampler
- 作用:定义投机推理中采样器的统一接口,用于处理草案模型(draft model)生成的候选token序列和目标模型(target model)对这些token的概率评估结果。
- 子类分类:随机性 vs. 确定性
采样器分为两类,对应不同的接受策略:
(1)随机性采样器(SpecDecodeStochasticBaseSampler)
- 代表子类:
RejectionSampler(拒绝采样器):最终生成的 token 与 target 模型的分布对齐。 - 核心思路:通过随机采样使最终输出的token分布与目标模型的概率分布严格对齐,确保数学上的无损加速。
- 工作流程:
- 输入:draft模型生成的候选tokens + 目标模型对这些tokens的概率评估。
- 基于目标模型的概率进行随机采样,决定接受或拒绝草案token。
- 若拒绝,则根据目标模型分布重新采样修正。
- 特点:保证输出分布与原始大模型完全一致,但可能因随机性导致接受率波动。
(2)确定性采样器(SpecDecodeDeterministicBaseSampler)
- 代表子类:
TypicalAcceptanceSampler(典型接受采样器):选取被原始模型视为足够可能的候选Tokens。设置基于原始模型预测概率的阈值,如果候选Token的概率超过这个阈值,则将其接受 - 核心思路:通过设定硬阈值和熵相关阈值,直接判断是否接受草案token,减少随机性。
- 超参数:
- 硬阈值(ε):直接过滤低概率token。
- 熵依赖阈值(δ·exp(-H)):根据目标模型预测分布的熵动态调整阈值(熵越大,阈值越低)。
- 特点:接受规则明确,稳定性高,但可能引入轻微分布偏差。

- 当target模型在token x’上的概率大于在draft模型上的概率时,说明target模型对该token更有信心,可以直接采纳该token;
- 如果target模型在token x’上的概率小于在draft模型上的概率,则有一定的概率( target模型在token x’上的概率/在draft模型上的概率)被采纳
- 若token被拒绝(拒绝概率=1- target模型在token x’上的概率/在draft模型上的概率),需要重新采样,重采样的概率倾向于target模型概率较高且draft模型概率较低(?)的token

几种经典的投机采样方法
SpecInfer:
Accelerating large language model serving with tree-based speculative inference and verification (ASPLOS24)
在更早的投机采样工作中,小模型只产生一个候选词序列供大模型进行验证。由于小模型在参数量上的劣势,候选词通常不会被全部接受,因此候选词的接受率成为了影响投机采样算法性能的重要因素。SpecInfer 优化算法,可以利用小模型生成多个候选序列,然后利用Tree Decoding进行快速验证,通过生成更多的候选词来提升增加每次可能被接受的序列长度。这种方法随后受到了广泛应用。
Drafting
SpecInfer希望在Drafting得到多个候选序列,对此有两种思路:采用多个小模型生成多个序列;或者使用单个模型,在每次生成最后的Decoding阶段留下多个单词,从而产生分支,这种方法的根据在于通常被大模型接受的token都在top-k列表里。最后得到的序列合并后会是一个树形结构,树中的每个节点代表一个token,节点的父节点即为其在序列上的前一个token。
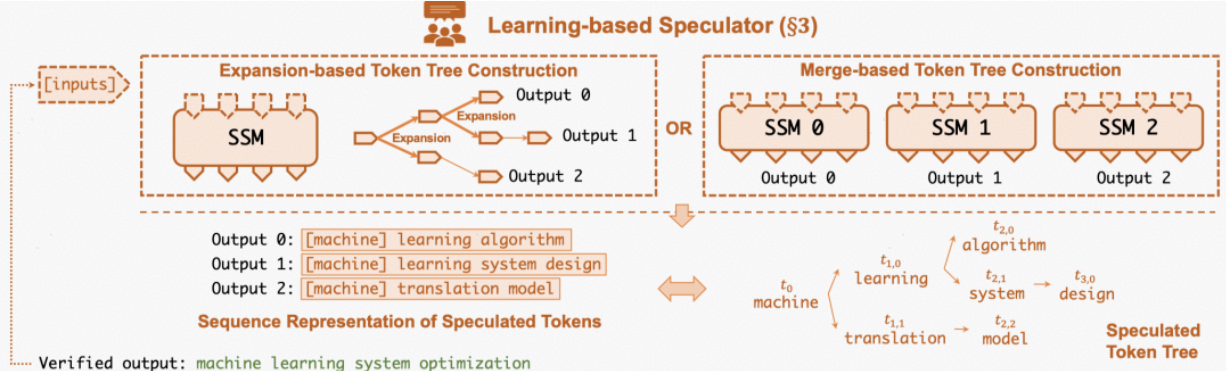
Tree Decoding
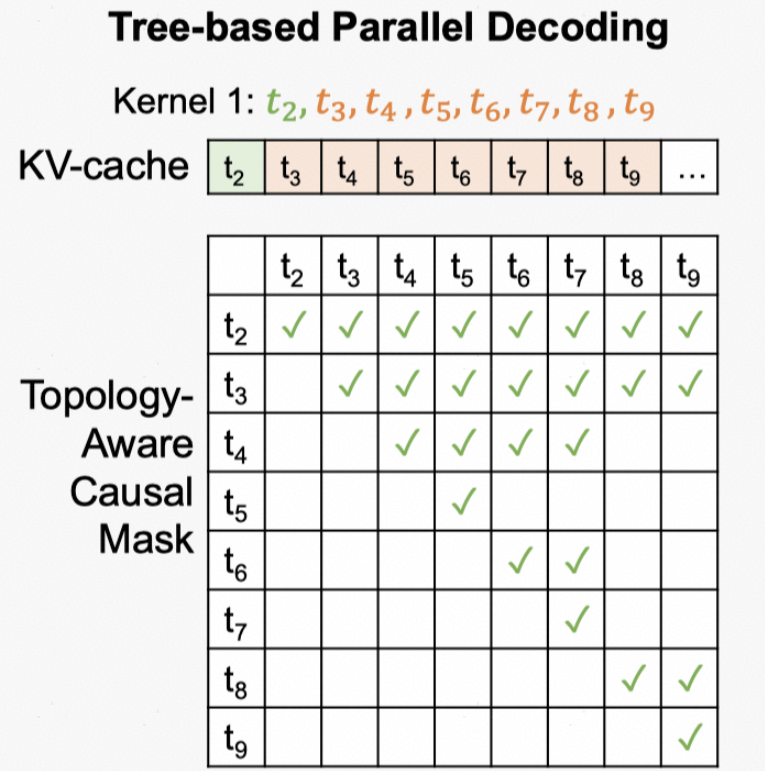
如果要用大模型对多个序列都进行验证,会产生大量的计算开销,这样很难带来推理速度提升,为此SpecInfer提出了Tree Decoding方法,可以一次对多个序列同时进行验证。
如下图,对于drafting生成的token tree,Tree Decoding将各个节点按照拓扑序展平为一个序列,然后为其生成一个特殊的Causal Mask。在这个Mask中,每个token与它祖先节点的格子上填1(如t9-t8),其余则填0(如t9-t4)。这样在Attention计算时,每个token只与它的祖先节点,也就是在序列上更早出现的单词进行计算。通过这种方式,Tree Decoding可以将多个分支序列合并到一次计算中完成,大幅提升了验证效率。
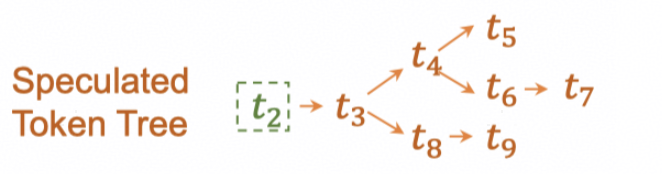
实验效果
SpecInfer相比其他的分布式推理框架有较大的速度提升,其中,Tree Decoding相比普通的投机采样算法有大概1.2-1.5倍的速度提升。
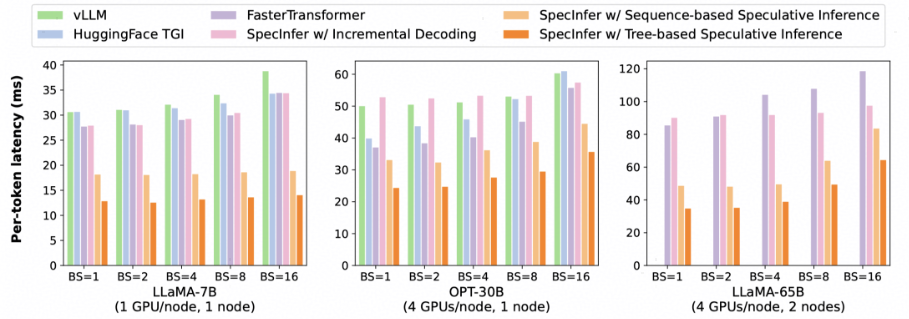
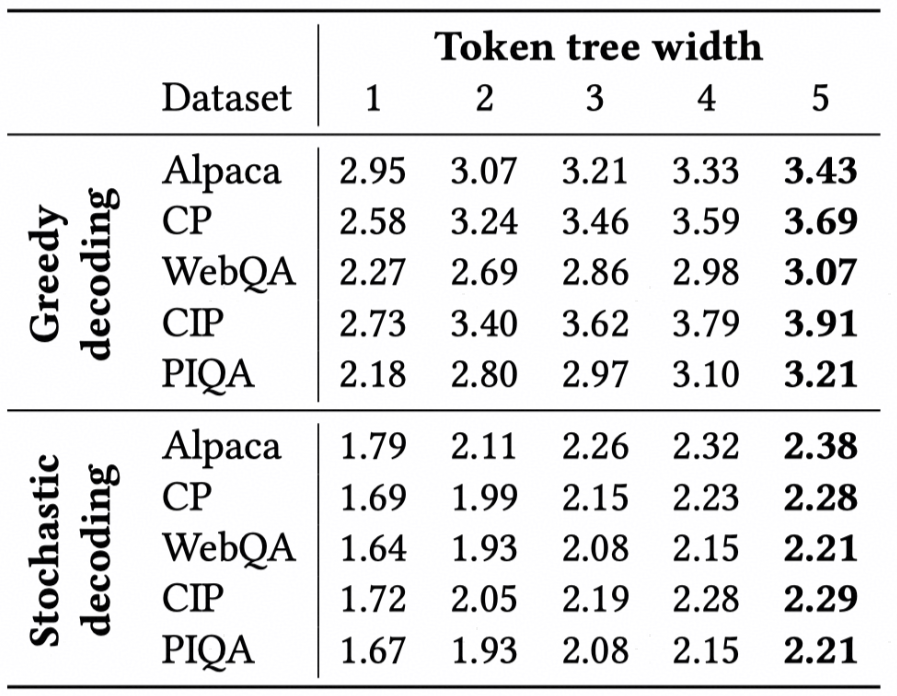
如下图所示,通过引入更多的分支序列(增大Token tree width),投机采样过程中的平均序列接受长度普遍得到了提升。而序列接受长度直接影响了投机采样的效率,这说明了该方法的有效性。
Medusa:
Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
理论上,SpecInfer及其类似工作的候选词接受率决定了它们的加速效果,然而实际效果却达不到这个程度,原因在于小模型本身的计算开销是无法被忽视的。Medusa则采用了一种更简单有效的方式,利用模型的隐藏层输出直接进行生成。
模型框架
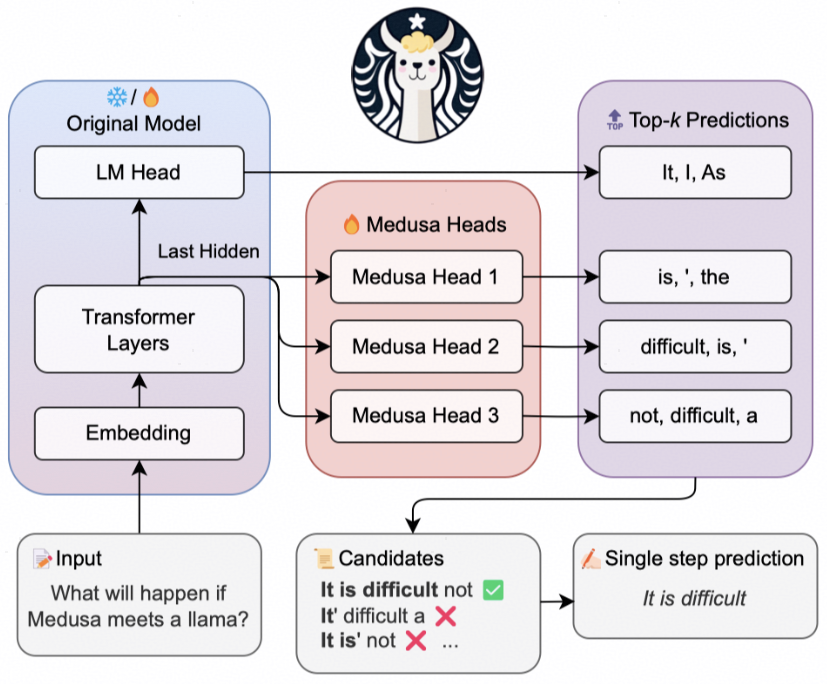
Medusa的投机采样过程与SpecInfer类似,首先生成多个候选序列,然后用Tree Decoding进行合并验证。Medusa的核心模块是生成候选词的Medusa Head,这个模块直接使用大模型的最后一个隐藏层输出作为输入,经过一个FFN生成候选词。其中第k个head会直接生成候选序列的第k个单词。序列中第一个单词直接由大模型生成,因此可以保证每个过程会输出一个单词。
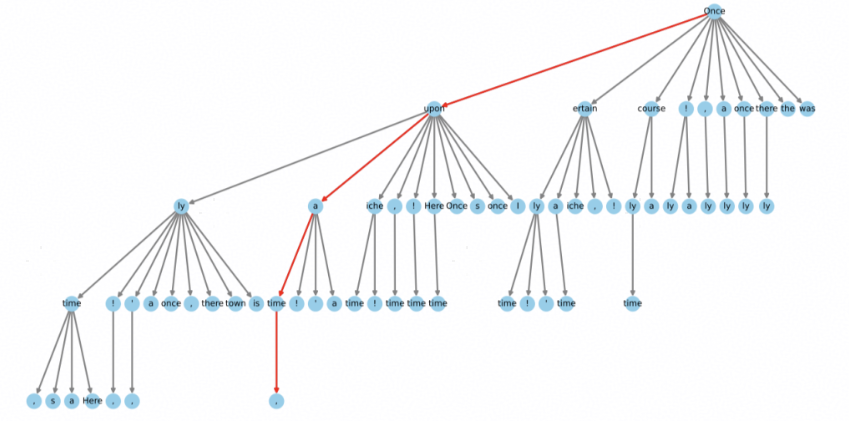
Medusa从每个head中选择top-k作为候选,将每个head的候选词按顺序组合可以得到候选序列。然后Medusa采用Tree Decoding对不同序列进行合并验证。验证所有组合会带来很大的开销。为此Medusa预先构建了如下所示的模版树,在生成token tree时可以只选择部分组合。这棵树由启发式方法生成,由于概率越大的节点产生的分支被接受的概率越大,这棵树在结构上整体左偏,因此排序更高的token会产生更多序列。
实验效果
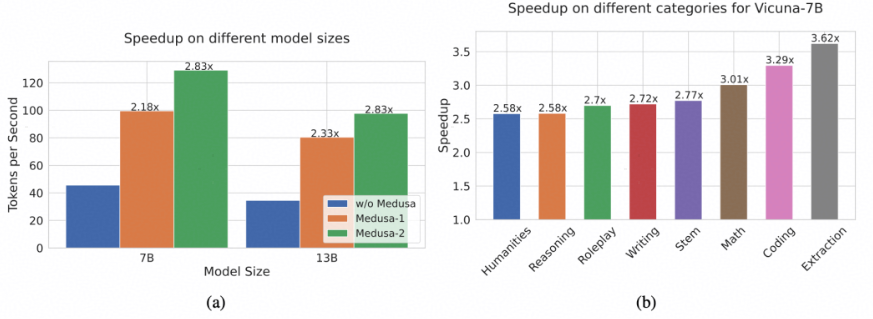
本文在Vicuna-7B/13B模型上进行了实验,Medusa可以带来2倍的推理加速效果,而几乎不损失模型生成质量。而采用了联合训练的Medusa-2能带来更强的加速效果,因为更好的Head能提升候选词的命中率。
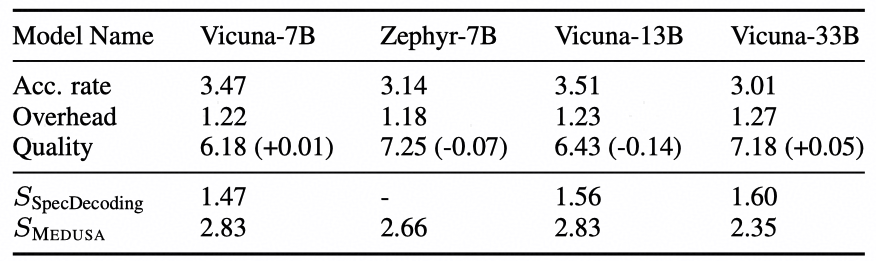
SpecInfer提出的Tree Decoding能提升候选词的命中率,而Medusa采用了高效的方法生成候选词。总的来说,投机采样利用了某些单词能够更容易预测的特性加速推理,如何在提升候选词质量的同时保证生成过程的高效性,是当前投机采样研究的关键问题。
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号【AI模力圈】。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)