不用真缺陷图也能训练:MIRAGE用VLM全自动生成工业异常样本,13000+图像对开源
导读:
———————————————————————————————————————————
工业异常检测面临一个根本矛盾:模型性能依赖异常样本,但真实缺陷图像极其稀缺。现有的合成方法要么需要真实异常作参考,要么需要30GB以上显存的GPU,要么生成的缺陷一眼就能看出是假的。
帕多瓦大学提出MIRAGE,用一条四阶段全自动pipeline解决这个问题——ChatGPT 5根据正常图像列出可能的缺陷类型,Gemini 2.5 Flash据此生成异常图像,CLIP过滤器自动剔除低质量结果,最后Grounding DINO与YOLOv26-L-Seg双分支融合生成像素级mask。整个流程不需要任何真实异常样本,不需要训练,mask生成仅需约3GB VRAM。在31人参与的人类感知实验中,MIRAGE的TrueSkill评分达到28.33,与真实缺陷图像的28.61仅差0.28分。用这些合成数据训练U-Net,在MVTec AD上取得I-AUROC 0.81、P-AUROC 0.92,在VisA上取得I-AUROC 0.74、P-AUROC 0.92。团队同步开源了覆盖27个工业类别的13000+组image-mask数据及全部pipeline代码。
论文信息
———————————————————————————————————————————
标题: MIRAGE: Model-agnostic Industrial Realistic Anomaly Generation and Evaluation for Visual Anomaly Detection
作者: Jinwei Hu, Francesco Borsatti, Arianna Stropeni, Davide Dalle Pezze, Manuel Barusco, Gian Antonio Susto
机构: University of Padova(帕多瓦大学),意大利
代码: https://github.com/vadnomalous/mirage
数据集: https://huggingface.co/datasets/visualanom/mirage_mvtec_visa
一、工业异常检测的"数据困境"
工业视觉异常检测(Visual Anomaly Detection, VAD)的主流方法通常只在正常样本上训练,但研究已反复证明,即使引入少量异常数据也能带来显著的性能提升。问题在于:真实缺陷图像在工业场景中极其稀缺,收集和标注的成本高昂。
为了绕过数据瓶颈,学界提出了多种合成异常的方案,但各有局限:
DRAEM:采用copy-paste加Perlin噪声纹理混合,生成的缺陷视觉上缺乏真实感
GLASS:在Perlin噪声基础上引入梯度引导,对弱缺陷有一定效果,但生成结果与真实缺陷的外观差异仍然明显
RealNet(SDAS):为每个类别训练一个DDPM(去噪扩散概率模型),计算开销大,扩展到新类别的成本高
AnomalyAny:目前的zero-shot生成方法中表现最好,使用冻结的Stable Diffusion加注意力引导优化,但需要至少30GB VRAM的GPU,生成速度慢,且与特定的Diffusion pipeline紧密耦合,难以随模型迭代升级
这些方法在"需要真实异常""需要昂贵硬件""生成质量不够""难以升级"四个维度上各有短板,始终没有一个方案能同时解决所有问题。
MIRAGE的设计目标正是填补这一空白:不需要任何真实异常样本,不需要训练,不需要本地GPU(生成阶段仅用API调用),并且生成模型可以随时替换升级。
二、四阶段全自动生成pipeline:从正常图像到带mask的异常样本
———————————————————————————————————————————
MIRAGE的核心设计原则是模型无关性(model agnosticism)——所有生成模型和VLM(视觉语言模型)都通过API黑盒调用,升级时只需更换API端点。整个pipeline分为四个阶段:
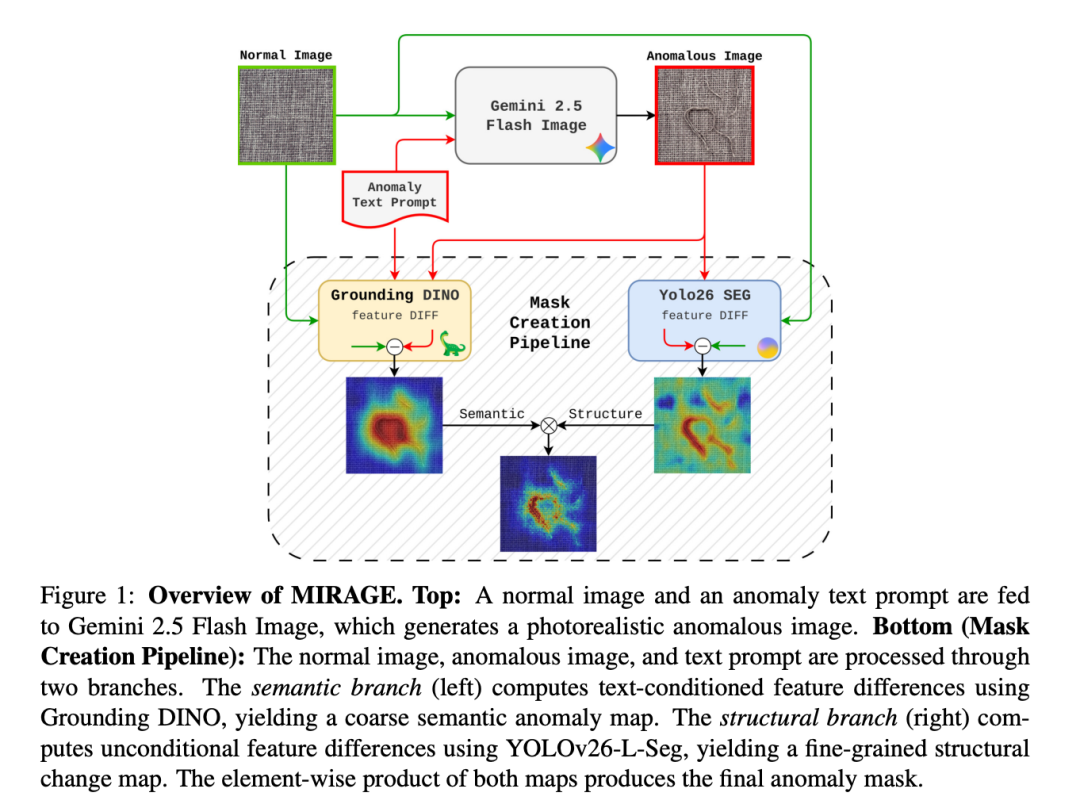
阶段一:VLM生成缺陷描述
输入5张正常参考图像给ChatGPT 5,通过结构化prompt要求其列出10种可能的制造缺陷类型。每种缺陷包含一个短名称和一段描述性句子,例如:"surface scratch: a thin, shallow linear mark across the surface, exposing a slightly lighter layer underneath"。
VLM仅基于正常图像工作,完全不接触任何异常域信息,实现了真正的零样本(zero-shot)缺陷定义。
阶段二:条件图像生成
将正常图像和缺陷描述一起输入Gemini 2.5 Flash Image,模型以原始正常图像为条件,保持场景布局、光照和纹理不变的同时引入指定缺陷。每个类别生成10种缺陷类型各50张,共计500张异常图像。
这一步仅需API调用,不需要本地GPU,也不需要下载任何模型权重。
阶段三:CLIP三条件质量过滤
生成模型偶尔会出现未能引入目标异常或产生不相关伪影的情况。MIRAGE使用CLIP计算四组image-text相似度,设置三个过滤条件:
C1:异常图像与异常prompt的对齐度 >= 正常图像与正常prompt的对齐度(确保语义连贯)
C2:异常图像与异常prompt的对齐度 >= 异常图像与正常prompt的对齐度(确认缺陷确实存在)
C3:异常图像与异常prompt的对齐度 >= 正常图像与异常prompt的对齐度(验证缺陷出现在生成图像中而非原图中)
三个条件全部满足才保留图像。计算开销很小,每张图像仅需一次CLIP前向传播。
阶段四:双分支语义变化检测生成mask
这是pipeline中技术密度最高的部分。朴素的像素差分会因生成模型引入的微妙全局变化(颜色偏移、纹理重渲染)而产生大量假阳性,因此MIRAGE设计了双分支融合方案:
语义分支使用Grounding DINO Tiny,一种开放集目标检测器。从缺陷描述中提取关键词作为文本条件,对正常图像和异常图像分别提取特征图,计算L2范数差分得到语义异常分数图。这一分支对描述的缺陷类型高度响应,但空间精度有限,只能做粗定位。
结构分支使用YOLOv26-L-Seg的分割变体,不使用文本条件,直接比较正常和异常图像在多个尺度上的视觉特征差异。浅层特征捕获精细的局部变化,深层特征反映更广泛的结构变形。这一分支提供高空间精度,但不具备语义选择能力。
两个分支的输出通过Hadamard积(逐元素乘积)融合——最终mask必须同时满足语义相关(与描述的缺陷类型一致)和结构变化(实际存在像素级修改),从而有效抑制任一分支单独产生的假阳性。
二值化阈值通过少量参考mask(每个缺陷类别5-8张,由Gemini 2.5 Flash Image V3生成)校准确定。整个mask生成pipeline在单张GPU上处理一张图约1秒,仅占用约3GB VRAM。

三、生成质量与下游效果:接近真实缺陷的视觉真实感
———————————————————————————————————————————
人类感知评估
论文组织了一项严格的人类感知研究:31名参与者进行1,550次配对投票,采用TrueSkill评分系统进行盲化随机评估。
|
方法 |
TrueSkill (μ ± σ) |
胜率 (%) |
|---|---|---|
|
Real images(真实图像) |
28.61 ± 0.80 |
73.8 |
| MIRAGE | 28.33 ± 0.80 | 67.2 |
|
AnomalyAny |
27.16 ± 0.79 |
59.2 |
|
RealNet |
23.54 ± 0.79 |
33.7 |
|
GLASS |
20.26 ± 0.84 |
14.4 |
MIRAGE的TrueSkill得分28.33与真实图像的28.61仅差0.28分,在所有生成方法中最接近真实图像。胜率67.2%明显高于AnomalyAny的59.2%,而RealNet和GLASS则分别只有33.7%和14.4%。

自动视觉质量指标
在MVTec AD的15个类别上,MIRAGE的平均Inception Score(IS)为2.68,平均Intra-Cluster LPIPS(IC-LPIPS)为0.38,两项指标均为所有方法中最高,表明生成图像质量最好且与真实缺陷的感知对齐度最高。
下游异常分割
用各方法生成的合成数据(每个类别100对image-mask)训练U-Net,在真实测试集上的分割结果:
MVTec AD(15个类别均值):
|
方法 |
I-AUROC |
P-AUROC |
|---|---|---|
|
AnomalyAny |
0.65 |
0.85 |
|
RealNet |
0.78 |
0.84 |
|
GLASS |
0.76 |
0.89 |
| MIRAGE | 0.81 | 0.92 |
VisA(12个类别均值):
|
方法 |
I-AUROC |
P-AUROC |
|---|---|---|
|
AnomalyAny |
0.59 |
0.86 |
|
RealNet |
0.68 |
0.84 |
|
GLASS |
0.67 |
0.91 |
| MIRAGE | 0.74 | 0.92 |
在MVTec AD上,MIRAGE的P-AUROC 0.92为所有方法最高,I-AUROC 0.81也排在首位。在VisA上,MIRAGE的I-AUROC 0.74和P-AUROC 0.92均为最高。综合两个数据集,MIRAGE在像素级异常分割上全面领先。
Mask质量
MIRAGE的双分支pipeline在MVTec AD上的像素级AUROC为0.9292,在VisA上为0.9265,大幅超过对比方法View-Delta的0.73。
四、消融实验:CLIP过滤和双分支融合各贡献了什么
_____________________________________________________________________________
CLIP过滤的效果
|
配置 |
MVTec AD I-AUROC |
MVTec AD P-AUROC |
VisA I-AUROC |
VisA P-AUROC |
|---|---|---|---|---|
|
无CLIP过滤 |
0.70 |
0.92 |
0.71 |
0.91 |
| 有CLIP过滤 | 0.80 | 0.92 | 0.74 | 0.92 |
CLIP过滤在MVTec AD上将I-AUROC从0.70提升到0.80(+0.10),在VisA上从0.71提升到0.74(+0.03)。P-AUROC保持不变或微升。这说明CLIP过滤的主要作用是移除语义错位或生成失败的样本,为下游分割模型提供更干净的训练集,对图像级判断的提升尤为明显。
双分支融合的设计逻辑
语义分支(Grounding DINO)负责"粗定位"——对描述的缺陷类型高度响应,但空间精度有限。结构分支(YOLOv26-L-Seg)负责"细分割"——捕获精细的像素级变化,但不具备语义选择能力。两者通过Hadamard积融合,要求某个像素同时被两个分支标记为异常才被保留,有效抑制了单分支的假阳性。
mask质量的数据也印证了这一设计:MVTec AD整体像素级AUROC 0.9292,VisA整体0.9265,在无需任何训练的条件下达到了相当高的精度。
五、总结与思考
MIRAGE用VLM+生成模型API+CLIP过滤+双分支mask检测,实现了全自动、无需真实异常样本、无需本地GPU训练的工业缺陷数据生成。人类感知评估与真实图像仅差0.28分,下游分割在MVTec AD和VisA上P-AUROC均达0.92。27个类别13000+组image-mask数据已开源。
设计上最值得注意的是模型无关性——所有生成模型和VLM通过API黑盒调用,模型升级只需换端点,不需要重新设计pipeline。CLIP过滤带来的I-AUROC +0.10(0.70→0.80)也说明大规模合成数据中自动质量控制不可或缺。局限性在于pipeline依赖API的质量和可用性,且当生成模型对图像整体外观改动过大时mask质量会下降。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)