VLA:用代码实现 Pi0.5 的完整能力
Pi05因其强大的开放世界泛化能力而受到广泛关注。然而,Physical Intelligence 开源的代码并未完全展现该模型的全部潜力。在本文中,我将首先回顾 Physical Intelligence 发表的几篇论文,解读 Pi05 的优势与架构。接着,我将分析三个关键的实现细节,这些细节能够充分释放该模型的能力。
1. π0.5 存在的原因(“开放世界”动机)
在真实家庭环境中工作的机器人,需要的不仅仅是“执行训练中见过的任务”。它们必须能够泛化到新的房间、物体布局、光照条件以及长时序的任务结构中。π0.5 论文将这一问题定义为开放世界泛化——即在训练分布之外的场景中的表现能力。
但对从业者来说,有趣的部分在于:这如何转化为一个可运行的模型架构?
实际上,论文描述了一个相当清晰的双系统架构:
-
从 VLM(视觉-语言模型)推理出高层级的语义子任务 —— 系统 2
-
基于该子任务生成低层级的连续动作 —— 系统 1
然而,Physical Intelligence 开源的官方代码库(https://github.com/Physical-Intelligence/openpi)并未完全暴露这一架构,并且遗漏了一些重要部分。我在自己的代码库中尝试展现 π0.5 的完整能力,并使这一层次结构非常明确。
2. 快速回顾:作为流匹配 VLA 的 π0
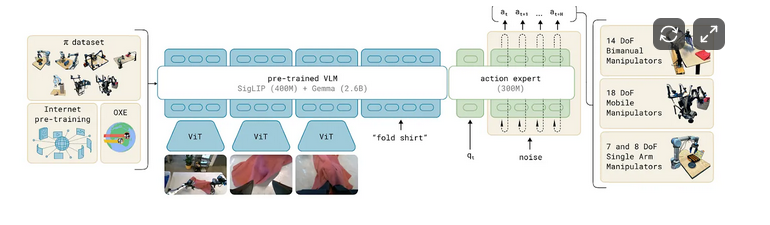
Pi0 概述
π0 的关键工程思路是将用于视觉-语言理解的预训练 VLM 与用于连续动作块的流匹配(类扩散)生成器配对使用。模态之间的融合通过分块因果注意力实现:视觉-语言标记仅在视觉-语言块内部进行注意力计算;本体感知状态标记关注自身以及视觉-语言块;而动作标记则关注之前的所有模态(视觉-语言 + 状态)以及之前的动作标记。这种方式在保持因果结构的同时,让动作能够以完整的上下文为条件——如下图所示。
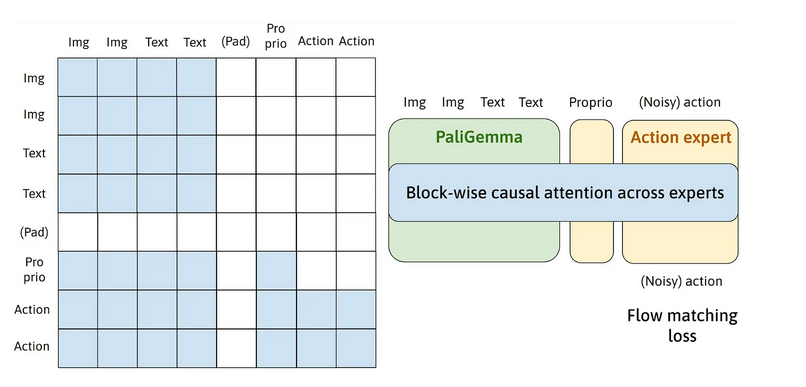
分块注意力(来自 Allen Ren 的 GitHub)
在代码库中,π0 的训练和推理流程如下:
-
构建多模态前缀(图像 + 语言标记)
-
构建动作/时间后缀
-
将前缀和后缀组合在一起
-
运行流去噪循环 → 输出连续动作
这更像是将高层级的语义理解与低层级的控制生成直接融合在一起。
3. 概念上的转变:π0.5 作为一个同时执行系统1和系统2的模型
尽管 π0 将预训练的 VLM 与流匹配动作专家结合在一起,但语义推理(系统2)与快速连续控制(系统1)之间的接口在很大程度上是隐式的:没有一个明确的机制来展示一个组件产生了什么信息,以及这些信息如何被另一个组件所使用。相比之下,π0.5 通过一个两阶段的系统2 → 系统1 设计使这种交互变得明确:在训练和推理过程中,模型首先生成中间的低层级子任务标记(系统2),然后让基于流的控制器以这些标记为条件,生成连续动作(系统1)。
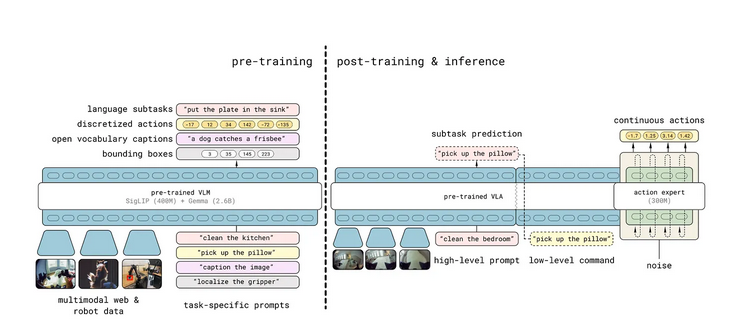
Pi05 架构
这里,我们重点关注后训练和推理,因为这是我们的代码要实现的部分。
如图所示,Pi05 成为一个分层的 VLA,具有两种不同的“解码模式”:
-
自回归标记解码(用于低层级的子任务标记)
-
流匹配去噪(用于连续的机器人动作)
这种双重性驱动了我们大部分的实现:
-
新的标记损失(子任务交叉熵损失、FAST 动作标记交叉熵损失)
-
新的区域掩码(按区域划分的标记监督)
-
不同的 KV 缓存设计,以高效支持逐标记解码
-
新的推理流程:首先采样低层级任务,然后采样动作
注意:原始的 π0.5 论文并未描述在后训练期间生成 FAST 动作标记。在后续的 Knowledge Insulation 论文中,FAST 动作标记作为额外的后训练信号被加入。我们的实现遵循这一更新的设置,因此在后训练期间也启用了 FAST 动作标记的生成/损失。
4. π0 Fast 的定位
在 π0 和 π0.5 之间,π0 Fast 引入了一种替代性的动作生成方法:它不再使用流匹配来生成连续动作,而是通过自回归方式生成动作。其关键的实现技巧是 FAST 动作分词器,该分词器将连续动作离散化为紧凑的标记序列,同时尽可能多地保留信息。这种分词化使得训练更加高效(标准的下一标记预测,更易于批处理),但纯自回归动作解码在推理时通常比基于流的块生成要慢。
π0.5 以有针对性的方式采用了 FAST。它并没有在整个控制器上都依赖自回归标记,而是在最有用武之地——即自回归中间生成阶段——使用 FAST 风格的标记解码,并借用了实现高效逐标记解码所需的增量 KV 缓存设计。如前所述,在我们的代码库中,FAST 动作标记在 π0.5 的预训练和后训练期间也作为监督信号被包含在内。
5. 知识隔离:训练更快,泛化更好
尽管 Pi05 展现了强大的泛化能力,但 Physical Intelligence 的研究人员发现它很难训练。他们将此归因于来自专家策略的梯度会破坏 VLM 骨干网络,并对其表征产生负面影响,这反过来又可能降低语言指令跟随的性能。
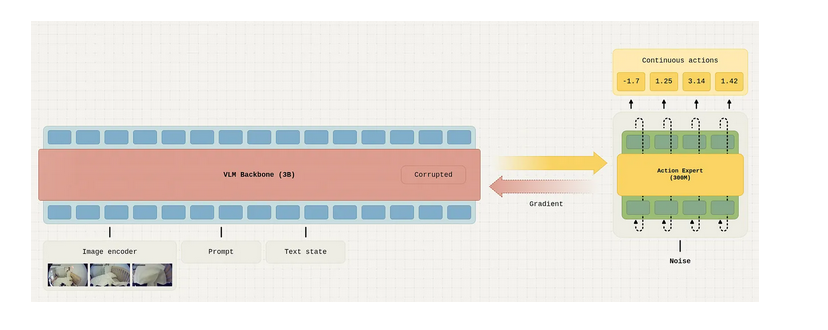
为了解决这个问题,研究人员提出了一种名为“知识绝缘”的新训练策略。其核心思想是阻断来自动作专家的梯度传播到 VLM 中,从而防止 VLM 的表征被破坏。同时,为了保持与任务相关的适应性,VLM 被训练来与子任务一起预测 FAST 离散动作标记,使其能够保留机器人任务的上下文并生成正确的动作。
6. Pi0 与 Pi05:代码层面究竟发生了什么变化?
我们现在对 Pi05 有了完整的认识,可以开始基于 Pi0 的代码库来实现这些思路了。在深入细节之前,我想先概述一下从 Pi0 到 Pi05 的架构变化,并突出关键的区别。
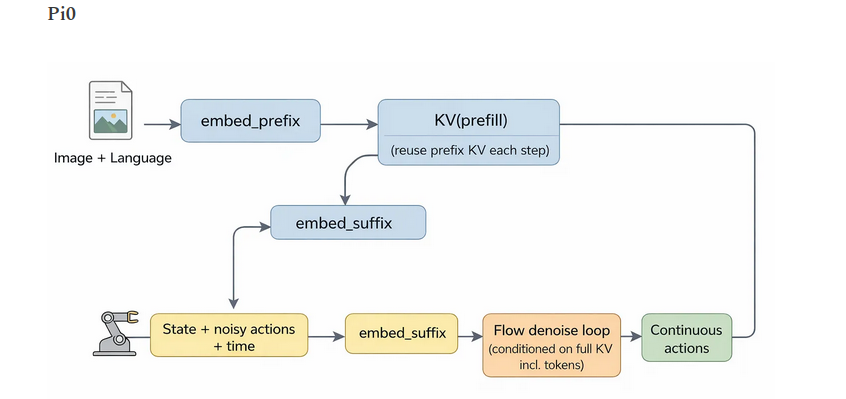
单阶段:前缀 → 流去噪 → 动作
损失:主要是流匹配 MSE
缓存:前缀复用
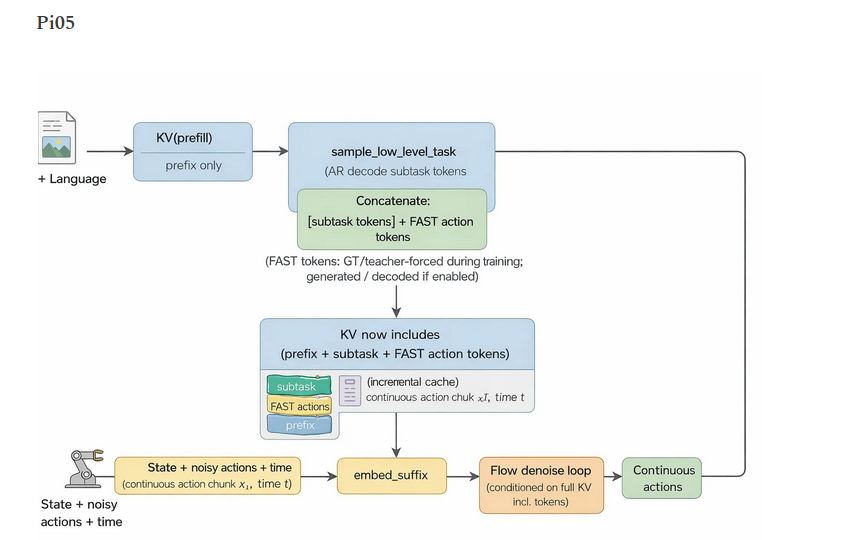
两阶段:
-
自回归生成子任务和 FAST 动作
-
以生成的标记为条件,运行流匹配生成连续动作
损失:多个目标的加权和
缓存:升级以支持高效的增量解码 + 在流阶段复用
主要区别在于模型如何生成子任务和 FAST 标记、如何组合多个损失,以及如何修改 KV 缓存。
7. 实现细节 1:用于启用子任务和离散动作生成的分词器
为了生成子任务和离散动作标记,我们在 tokenizer.py 文件中实现了 tokenize_high_low_prompt() 函数,该函数在训练期间使用。
def tokenize_high_low_prompt(
self,
high_prompt: str,
low_prompt: str,
state: np.ndarray | None = None,
actions: np.ndarray | None = None,
) -> tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray, np.ndarray, np.ndarray]:
"""Build the full token sequence for Pi05 hierarchical training.
Constructs a structured prompt that concatenates three segments in order:
[high-level task + state] + [subtask] + [FAST action tokens (optional)]
Depending on training mode, the token sequence looks like:
Flow matching mode (actions=None):
"Task: pick up cup. State: 127 64 ...; Subtask: move arm to cup.;\nAction: <EOS>"
FAST token mode (actions provided):
"Task: pick up cup. State: 127 64 ...; Subtask: move arm to cup;\nAction: <tok1><tok2>...|<EOS>"
Args:
high_prompt: High-level task description string, e.g. "Pick up the cup".
Will be normalized (lowercased, underscores replaced with spaces) and
punctuation-normalized to end with a period.
low_prompt: Low-level subtask description string, e.g. "Move arm to the cup".
This is the target the model is trained to predict autoregressively.
Same normalization applied as high_prompt.
state: Robot proprioceptive state vector of shape (state_dim,), assumed to be
normalized to [-1, 1]. Each dimension is discretized into 256 integer bins
and encoded as a space-separated string inside the language prompt.
actions: Optional continuous action trajectory of shape (action_horizon, action_dim),
assumed to be normalized to [-1, 1]. When provided together with a loaded
FAST tokenizer, the trajectory is encoded as discrete action tokens and
appended as segment 3. When None, only the subtask text is produced (flow
matching mode).
Returns:
A tuple of six parallel numpy arrays, all of length `max_len`:
tokens (np.ndarray, int, shape (max_len,)):
Token IDs for the full sequence. Padding positions contain 0.
mask (np.ndarray, bool, shape (max_len,)):
True for real (non-padding) tokens, False for padding positions.
Used to exclude padding from attention.
ar_mask (np.ndarray, int32, shape (max_len,)):
Autoregressive schedule consumed by `make_attn_mask`. A value of True (1)
marks a causal barrier — each position can only attend to positions with
an equal or smaller cumulative sum of this mask. All real token positions
are set to True so the sequence has fully causal (left-to-right) attention.
Padding positions are False (0).
loss_mask (np.ndarray, bool, shape (max_len,)):
True on positions where cross-entropy loss is computed. Covers both the
subtask region and the action token region; False on the task/state prefix
(segment 1) and on padding.
subtask_region_mask (np.ndarray, bool, shape (max_len,)):
True only on subtask tokens (segment 2). Used to compute a separately
weighted subtask loss (controlled by `subtask_loss_weight` in Pi05Config).
action_region_mask (np.ndarray, bool, shape (max_len,)):
True only on FAST action tokens (segment 3). Used to compute a separately
weighted action token loss (controlled by `fast_token_loss_weight` in
Pi05Config). All-False when no action tokens are present.
"""
cleaned_high_text = high_prompt.lower().strip().replace("_", " ").replace("\n", " ")
cleaned_low_text = low_prompt.lower().strip().replace("_", " ").replace("\n", " ")
# Pi05 encodes the robot state as a discretized string inside the language prompt
# (rather than as a continuous vector in the suffix), so the LLM can condition on it.
# Each state dimension is binned into one of 256 levels over [-1, 1].
discretized_state = np.digitize(state, bins=np.linspace(-1, 1, 256 + 1)[:-1]) - 1
state_str = " ".join(map(str, discretized_state))
# ── Segment 1: High-level task prompt + discretized state ──────────────────
# This is the conditioning context. No loss is computed here since the model
# receives this as given input, not as something it needs to predict.
if cleaned_high_text and cleaned_high_text[-1] in string.punctuation:
cleaned_high_text = cleaned_high_text[:-1]
cleaned_high_text += "."
sub_prompt_1 = f"Task: {cleaned_high_text}; State: {state_str}; Subtask: "
tokens_1 = self._tokenizer.encode(sub_prompt_1, add_bos=True)
ar_mask = [True] * len(tokens_1) # causal attention over the prefix
loss_mask = [False] * len(tokens_1) # no loss on task/state context
subtask_region_mask = [False] * len(tokens_1)
action_region_mask = [False] * len(tokens_1)
# ── Segment 2: Low-level subtask text ──────────────────────────────────────
# This is what the model must predict autoregressively given the task+state
# context above. Loss is computed on every token in this segment.
# The segment ending differs by training mode:
# - Flow matching mode: ends with ";\nAction: " + EOS, signalling the end
# of subtask generation and the start of continuous action denoising.
# - FAST token mode: ends with ";" only (no EOS yet), because the discrete
# action tokens will be appended as segment 3.
if cleaned_low_text and cleaned_low_text[-1] in string.punctuation:
cleaned_low_text = cleaned_low_text[:-1]
cleaned_low_text += "."
if actions is None or self._fast_tokenizer is None:
sub_prompt_2 = f"{cleaned_low_text};\nAction: "
tokens_2 = self._tokenizer.encode(sub_prompt_2, add_eos=True)
else:
sub_prompt_2 = f"{cleaned_low_text};"
tokens_2 = self._tokenizer.encode(sub_prompt_2)
ar_mask += [True] * len(tokens_2)
loss_mask += [True] * len(tokens_2) # compute loss on the predicted subtask
subtask_region_mask += [True] * len(tokens_2)
action_region_mask += [False] * len(tokens_2)
tokens = tokens_1 + tokens_2
# ── Segment 3 (optional): FAST discrete action tokens ──────────────────────
# Only present during FAST token training (hybrid or KI stage 1).
# The FAST tokenizer converts the continuous action trajectory into a compact
# sequence of discrete tokens. These are then mapped into the tail of the
# PaliGemma vocabulary (last 128 slots reserved for special use are skipped).
# Format: "\nAction: " + <fast_tokens> + "|" + EOS
# Loss is computed on all tokens in this segment (action_region_mask).
if actions is not None and self._fast_tokenizer is not None:
action_tokens_fast = self._fast_tokenizer(actions[None])[0]
# Map FAST token IDs into the PaliGemma vocabulary tail
action_tokens_pg = self._act_tokens_to_paligemma_tokens(action_tokens_fast)
action_seq = (
self._tokenizer.encode("\nAction: ")
+ action_tokens_pg.tolist()
+ self._tokenizer.encode("|", add_eos=True) # "|" marks end of action sequence
)
tokens += action_seq
ar_mask += [True] * len(action_seq)
loss_mask += [True] * len(action_seq)
subtask_region_mask += [False] * len(action_seq)
action_region_mask += [True] * len(action_seq)
# ── Padding / truncation to max_len ────────────────────────────────────────
# All six arrays must share the same fixed length so they can be batched.
# Padding positions are represented as 0 / False in every array.
tokens_len = len(tokens)
if tokens_len < self._max_len:
padding = [False] * (self._max_len - tokens_len)
mask = [True] * tokens_len + padding
tokens = tokens + padding
ar_mask = ar_mask + padding
loss_mask = loss_mask + padding
subtask_region_mask = subtask_region_mask + padding
action_region_mask = action_region_mask + padding
else:
if len(tokens) > self._max_len:
logging.warning(
f"Token length ({len(tokens)}) exceeds max length ({self._max_len}), truncating. "
"Consider increasing the `max_token_len` in your model config if this happens frequently."
)
tokens = tokens[: self._max_len]
mask = [True] * self._max_len
ar_mask = ar_mask[: self._max_len]
loss_mask = loss_mask[: self._max_len]
subtask_region_mask = subtask_region_mask[: self._max_len]
action_region_mask = action_region_mask[: self._max_len]
return (
np.asarray(tokens),
np.asarray(mask),
np.asarray(ar_mask, dtype=np.int32),
np.asarray(loss_mask),
np.asarray(subtask_region_mask),
np.asarray(action_region_mask),
)在训练期间,tokenize_high_low_prompt() 函数自回归地构建完整的固定长度标记序列,包括高层级提示、低层级子任务,以及可选的 FAST 动作标记,然后再将其输入到 Pi05 中。同时,该函数还会生成用于注意力计算和损失计算的掩码。整体结构如下所示。
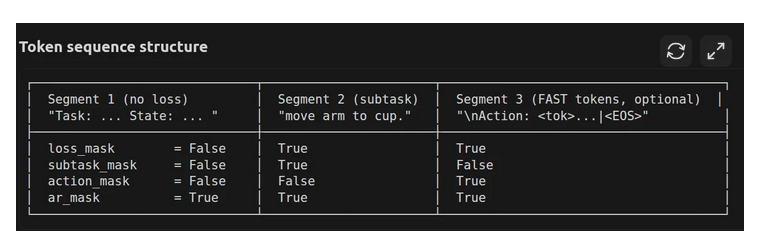
在推理期间,也会生成完整的标记以及 ar_mask,但由于不需要计算损失,因此不会生成 loss_mask。这一过程在 pi05.py 文件中的 sample_low_level_task() 函数中实现。
8. 实现细节 2:多目标训练与知识绝缘:从单一损失到三重损失
π0.5 论文明确讨论了将离散表示(子任务和离散动作标记)与连续流匹配相结合以实现高效推理。
在 pi05.py 文件的 compute_loss() 函数中(https://github.com/Ke-Wang1017/openpi_subtask/blob/main/src/openpi/models/pi05.py#L202),存在三种损失:
-
子任务标记交叉熵损失(语义子任务预测)
-
FAST 动作标记交叉熵损失(离散动作标记,通常来自类似 FAST 的分词器——根据论文,在 π0.5 预训练中使用)
-
流匹配均方误差损失(用于实时控制的连续动作)
我们为每个损失分配一个权重,使代码库能够同时支持知识绝缘和协同训练。
9. 实现细节 3:KV 缓存——工作原理及其重要性
Pi05 的推理包含两个生成阶段,它们共享同一个 Gemma LLM 骨干网络:
-
子任务和离散动作生成 —— 每次自回归解码一个文本标记(可能数百步)
-
动作生成 —— 使用相同的前缀上下文运行流匹配去噪(通常 10 次迭代)
如果没有高效的缓存,每生成一个新标记都需要在整个历史序列上重新计算注意力。在 200 步解码的情况下,这意味着 200 + 199 + 198 + ... + 1 = 约 20,000 次冗余的 K/V 计算。
Pi0 使用简单的 (K, V) 元组。当新标记到达时,新的 K/V 会被拼接(concatenate)到现有的 K/V 上。
这对 Pi0 来说没问题,因为它只对固定的前缀进行少量动作去噪传递——从未逐步增长缓存。但对于逐步解码而言,拼接意味着每一步都要分配一个新的、更大的数组。
因此,Pi05 将缓存契约改为三元组:(idx, K_cache, V_cache)。在 gemma_05.py 文件中:
在初始化时 —— 预分配完整的最大尺寸:
def _init_cache(self, k, v, cache_size):
prefill_len = k.shape[1]
pad_width = ((0, 0), (0, cache_size - prefill_len), (0, 0), (0, 0))
cache_dtype = k.dtype
k_cache = jnp.pad(k.astype(cache_dtype), pad_width)
v_cache = jnp.pad(v.astype(cache_dtype), pad_width)
idx = jnp.zeros((k.shape[0],), dtype=jnp.int32) + prefill_len
return idx, k_cache, v_cache然后在标记生成过程中,它会写入下一个槽位并移动指针:
def _update_cache(self, k, v, idx, k_cache, v_cache):
assert k.shape[1] == 1, "Only support kv-cache updates of length 1"
indices = (0, idx[0], 0, 0)
k_new = jax.lax.dynamic_update_slice(k_cache, k.astype(cache_dtype), indices)
v_new = jax.lax.dynamic_update_slice(v_cache, v.astype(cache_dtype), indices)
idx_new = idx + 1
return idx_new, k_new, v_new而在流匹配去噪过程中,KV 缓存是固定的,不会被更新。完整的代码流程可以在这里看到:
if kv_cache is None:
idx, k_cache, v_cache = self._init_cache(k, v, attn_mask.shape[-1])
k, v = k_cache, v_cache
else:
idx, k_cache, v_cache = kv_cache
if k.shape[1] == 1: # single token decode
idx, k_cache, v_cache = self._update_cache(k, v, idx, k_cache, v_cache)
k, v = k_cache, v_cache
else: # action denoising (multi-token suffix, cache not updated)
k = jnp.concatenate([k_cache, k], axis=1)
v = jnp.concatenate([v_cache, v], axis=1)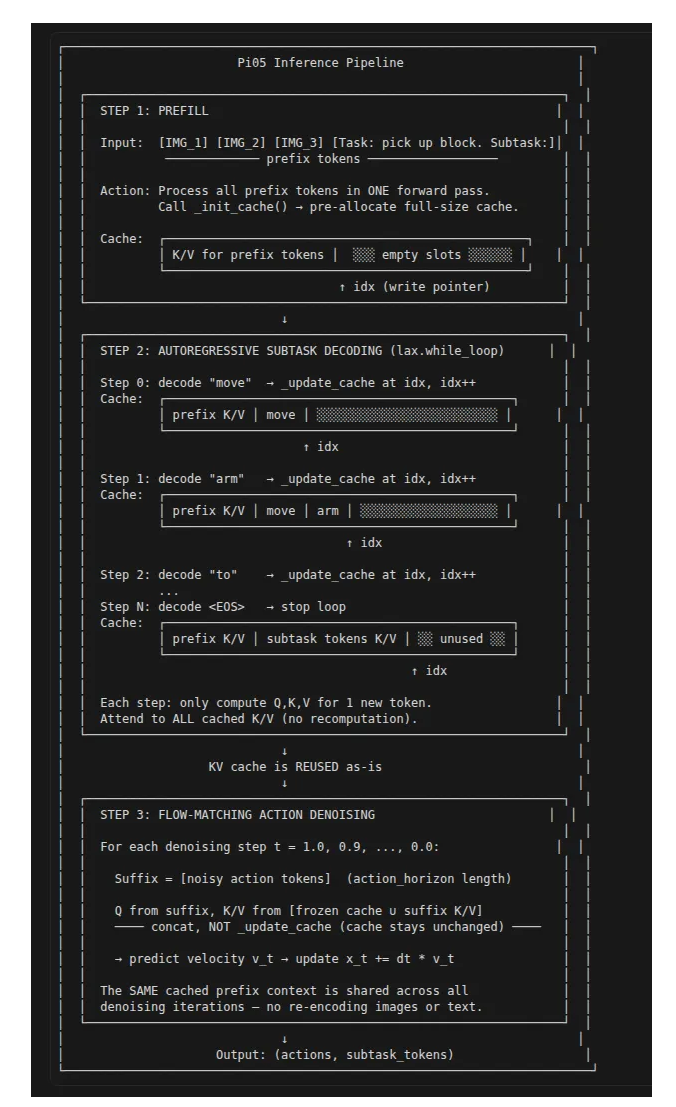
有了这些改动,Pi05 的全部潜力就可以被解锁了!
这并非易事,要感谢 Mu Li 和 Yijie Chen 在代码开发过程中的合作。
参考资料:
-
Pi Fast: https://arxiv.org/pdf/2501.09747
-
Physical Intelligence 开源代码: https://github.com/Physical-Intelligence/openpi
-
参考完整 Pi05 实现: https://github.com/Ke-Wang1017/openpi_subtask
-
这里声明一下,这篇论文原文来自https://kewang1017.substack.com/p/implementing-the-full-capability?r=17gtxg&utm_campaign=post&utm_medium=web&triedRedirect=true
我只是搬运,感谢作者的贡献。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)