大模型写论文到底靠不靠谱?PaperRecon这篇论文用51篇顶会论文给出了答案
研究背景
最近AI写科研论文这件事越来越普遍,甚至已经有人悄悄把AI写的论文投到顶会了——ICLR、ACL这些地方都出现了相关报道。这个趋势显然还会继续加速,毕竟"AI科学家"这个概念已经不再是科幻了。
但问题来了:AI写的论文到底写得怎么样?有没有乱编内容?这两个问题其实一直没有被认真回答过。以前的做法基本是让AI审稿人去给分,但这套路有个致命缺陷——研究发现AI审稿人反而会给幻觉更严重的论文打更高分,完全失效。
这篇论文提出了一套叫做 PaperRecon(论文重建评估) 的框架,核心思路很朴素:既然有原始论文,那就让AI去"还原"这篇论文,然后把生成版本和原版逐句对比,看看写得像不像、有没有编造内容。同时他们还配套发布了 PaperWrite-Bench,一个覆盖51篇2025年后顶会论文的测评基准。
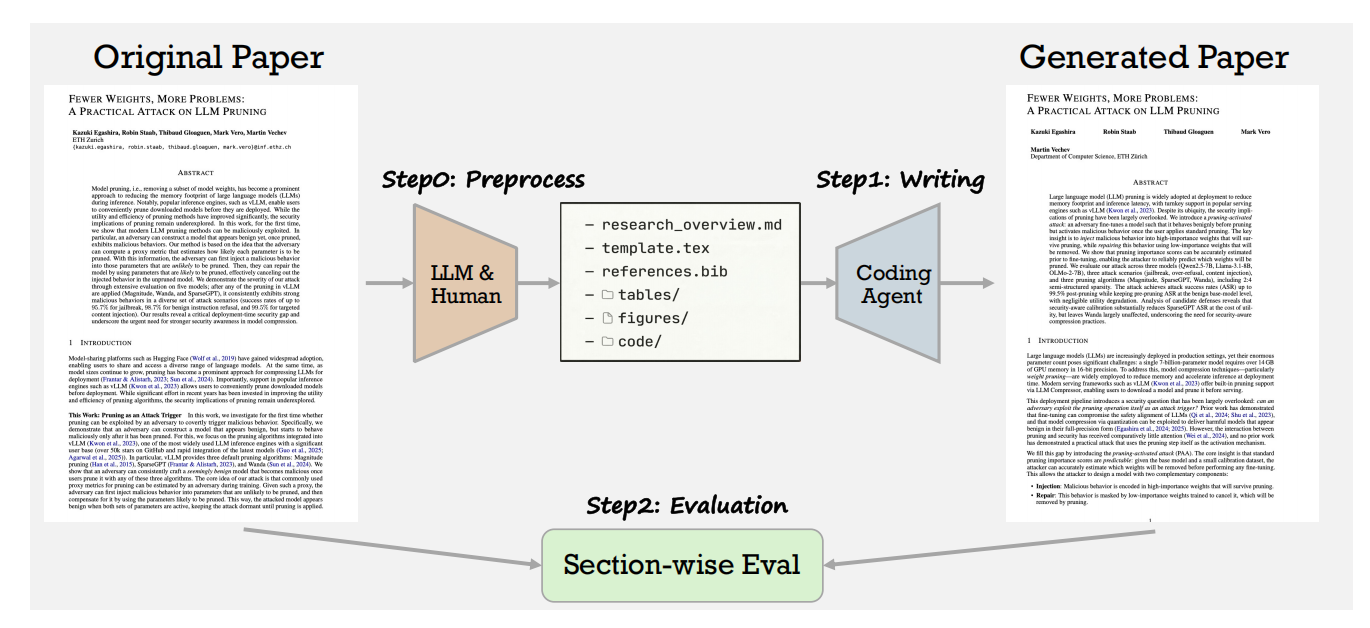
代码链接:https://github.com/Agent4Science-UTokyo/PaperRecon
相关工作
在AI科研自动化这条路上,其实已经有不少工作在探索"让AI做实验""让AI写综述"等任务。但专门针对"AI写论文"这一环节的评估几乎是空白。现有的方法大体分两类:
一类是用AI模拟评审,看论文能不能过审,但这个方法的问题前面说了,AI审稿人根本识别不了幻觉内容;另一类是研究引用错误这类表面问题,比如引用了根本不存在的文献,但这只是冰山一角,更深层的内容捏造完全没被覆盖到。
对比之下,PaperRecon直接拿原论文作为ground truth来做对比,评估维度也拆分得更清楚,这是它和前人工作最本质的区别。
核心方法
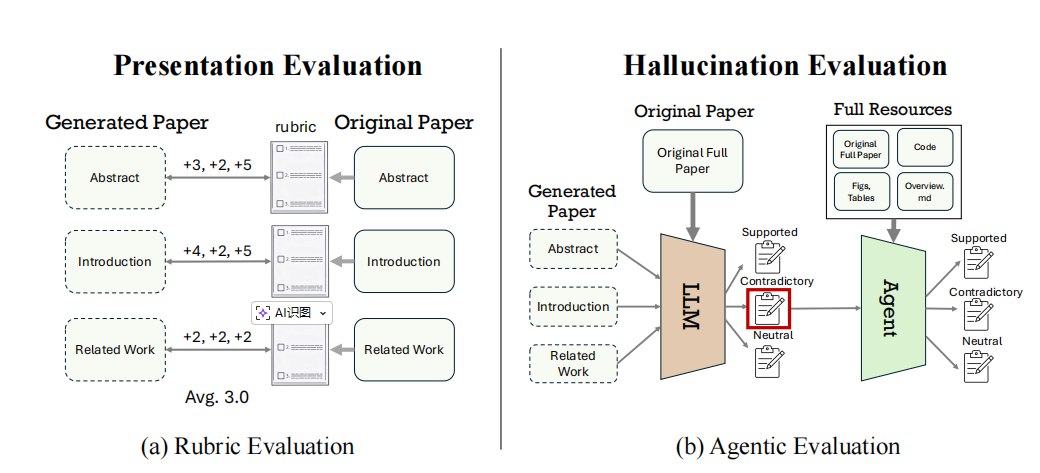
PaperRecon的逻辑分两大块:怎么让AI写论文 和 怎么评估写出来的论文。
输入端,框架给AI提供的资源是精简版的:一个用Markdown写的研究概述(平均约463词,覆盖动机、方法、实验结论),加上原论文的图片、表格LaTeX代码、参考文献bib文件,以及开源代码(如果有的话)。节结构也是预先给好的,AI只需要填内容。这个设计的目的是把"收集资料""做实验"这些环节排除掉,专门孤立出"写作能力"来评估。
评估端,框架从两个完全独立的维度来打分:
一、Presentation(表达质量) 用的是rubric打分法。对每篇原始论文,先提取出每个章节应该包含的关键点,形成打分细则(比如摘要里应该说清楚"研究动机是改善视觉语言模型的推理能力"这种具体条目),再由GPT-5.4逐条给生成论文打1-5分。图表也单独评分:图的上下文使用是否合适、表格数字是否准确。
二、Hallucination(幻觉检测) 走的是两阶段流程。第一步,GPT-5.4从生成论文里抽取所有可验证的具体说法,标注为"支持"“中性"或"矛盾”,矛盾的再区分"严重"(数字编错、结论捏造)和"轻微"(表述不精确);第二步,再调Claude Code重新核查所有被标为矛盾的条目,修正误报。最后统计每篇论文平均有多少严重幻觉。
引用评估这块也单独做了。框架会提取生成论文和原论文里所有引用的文献key,然后算Precision、Recall和F1,同时还会专门统计"幻觉引用"(引用了bib文件里根本不存在的文献)、"遗漏引用"和"多余引用"的数量,用公式表示就是:
F1=2×Precision×RecallPrecision+RecallF1 = \frac{2 \times Precision \times Recall}{Precision + Recall}F1=Precision+Recall2×Precision×Recall
其中 Precision=valid citedtotal citedPrecision = \frac{\text{valid cited}}{\text{total cited}}Precision=total citedvalid cited,Recall=valid cited∩GTtotal GTRecall = \frac{\text{valid cited} \cap GT}{\text{total GT}}Recall=total GTvalid cited∩GT。
实验效果
测试对象是Claude Code(单智能体)、Claude Agent Teams(多智能体)和Codex,分别跑在不同底座模型上,总共五种配置。
结果出现了一个很有意思的trade-off:
在表达质量上,Claude Code > Codex。ClaudeCode + Sonnet4.6的平均rubric分达到3.86(满分5),Codex + GPT5.4只有3.59。Claude写出来的论文在结构、细节覆盖上更完整。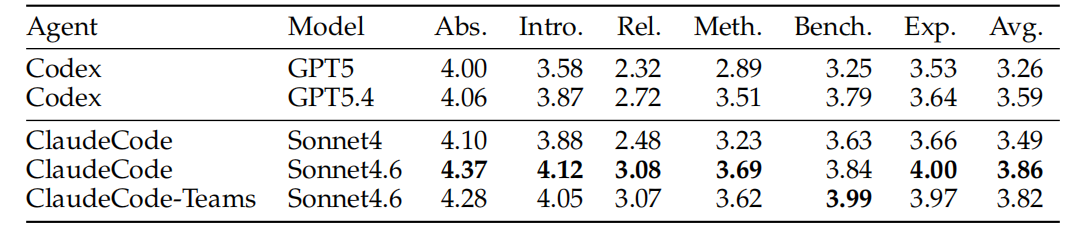
但在幻觉数量上,画风完全反转。ClaudeCode + Sonnet4每篇论文平均有12个严重幻觉,Sonnet4.6稍微好一点也有10.4个;而Codex + GPT5.4只有3个,差了将近四倍。换句话说,Claude写得更好看,但编的也更多。
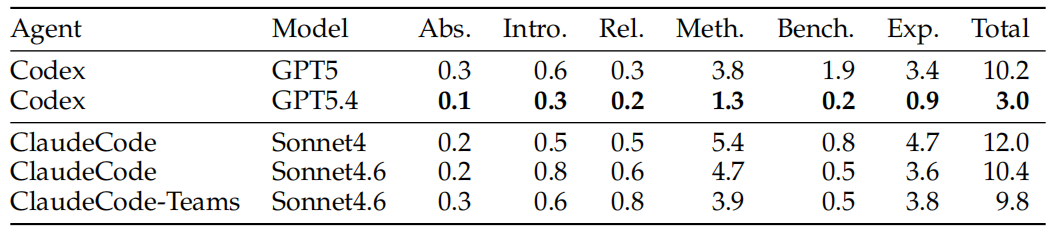
从章节维度看,方法部分(Meth.)和实验部分(Exp.)是幻觉重灾区,因为这两块需要精确的数字和技术细节,AI一旦"发挥"就容易出问题。
另一个有意思的发现是,给AI提供更详细的研究概述(从463词扩展到1492词),幻觉数量会大幅下降——Sonnet4.6从9.8个降到2.3个,同时表达质量也上升了。这说明写作质量很大程度上取决于输入信息的丰富程度。
人工验证方面,研究者手动核查了97条被标记为严重幻觉的内容,发现96%都是真实的幻觉,说明这套评估方法本身还是可靠的。
代码实现:PaperRecon的评估引擎是如何运转的
为了让大家更直观地理解PaperRecon的评估流程,我深入阅读了开源代码的evaluation目录。整个评估模块由4个Python文件组成,总计约2800行代码,分别负责引用评估、图表评估、表格评估和逐章节评估四个维度。下面我按数据流的顺序,从入口到出口,把整个评估引擎拆开来讲。
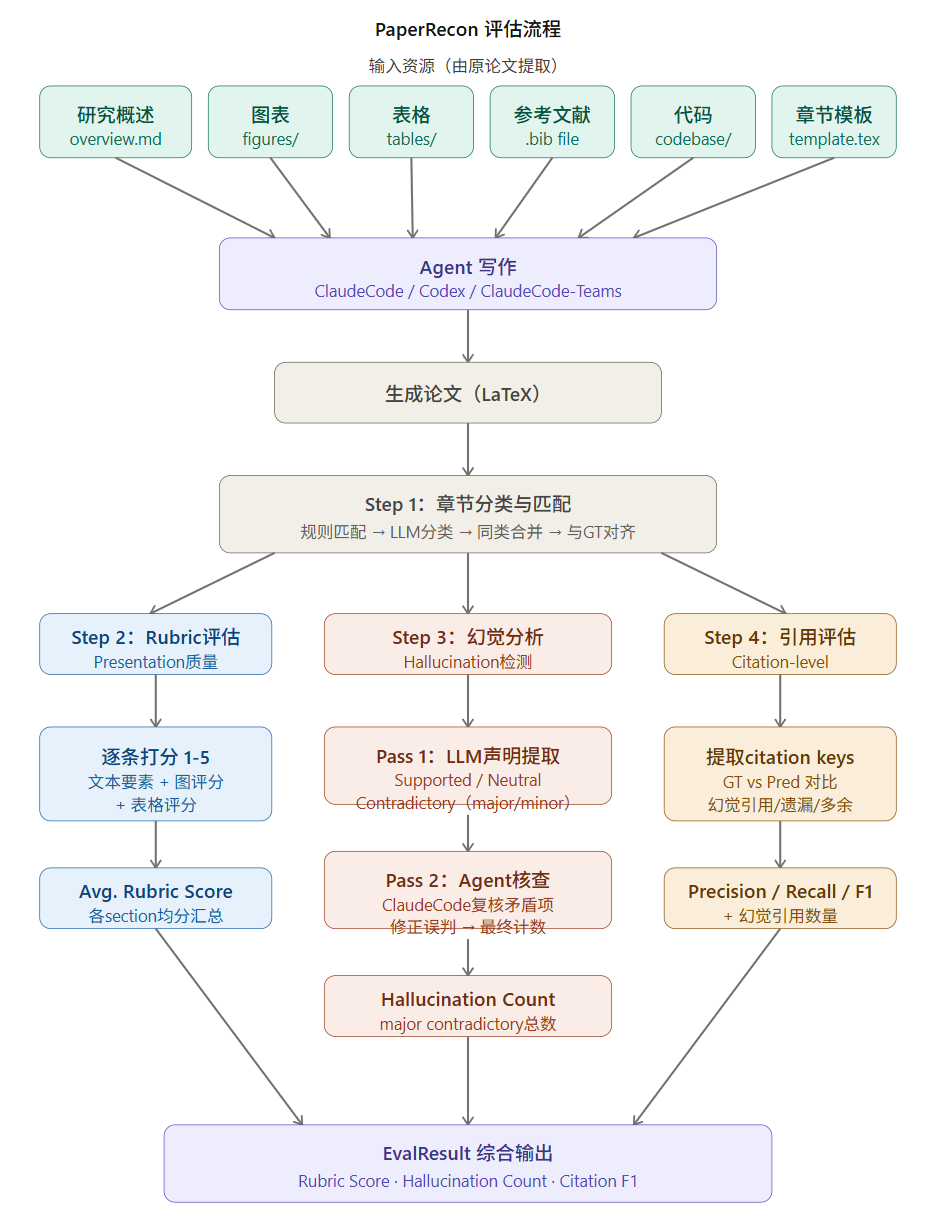
这个图片我用Claude生成的,非常清晰了,大家可以直接读源码:https://github.com/Agent4Science-UTokyo/PaperRecon
代码的入口函数是evaluate_paper()(位于evaluate_per_section.py),它接受GT(Ground Truth)和Pred(AI生成的预测论文)的LaTeX源文件路径,以及LLM配置和Agent配置,然后根据eval_mode参数决定运行哪种评估模式。框架设计了三种模式:"rubric"模式只跑表达质量评分,"hallucination"模式只跑幻觉检测,"all"模式则全部跑一遍。此外还有一个独立的"citation"模式,计算完引用F1就直接返回,不进入后续流程。
所有模式共享的第一步是章节分类与匹配——函数classify_sections_for_paper()会分别从GT和Pred的LaTeX文件中提取所有章节,然后归一化分类到7个标准类别(Abstract、Introduction、Related Work、Method、Benchmark Construction、Experiment、Conclusion),最后通过一个基于拓扑排序的匹配算法将GT和Pred的章节一一配对。
章节分类:规则优先,LLM兜底
章节分类的实现很有意思,采用了一个"先规则、后LLM"的两级策略。代码中维护了一张SECTION_CATEGORY_RULES映射表,里面为每个标准类别预定义了大量的关键词变体。比如"Method"类别匹配的关键词就包括了"method"、"methodology"、"our approach"、"proposed framework"、"preliminary"等十几种写法,覆盖了学术论文中各种常见的章节命名习惯。
分类流程是这样的:首先用正则表达式提取LaTeX中所有\section{...}命令和\begin{abstract}...\end{abstract}环境,Abstract直接保留原名。对于其他章节,先将名称做归一化处理(转小写、去特殊字符、合并空白),然后尝试与规则表进行关键词匹配。如果规则匹配失败,才会调用LLM来做分类——此时会把章节名称和前500字符的内容预览一起喂给模型,让它判断属于哪个类别,或者返回"Skip"(比如Acknowledgements、Ethics Statement这类不属于评估范围的章节)。
分类完成后,代码还会处理一个常见的边界情况:同名合并。有些论文可能有多个被分到同一类别的章节(比如既有"Results"又有"Analysis",都被归入"Experiment"),_merge_sections_by_category()函数会将它们按顺序拼接为一个章节,避免后续评估时出现重复。
引用评估:纯正则的F1计算
evaluate_citation.py是四个文件中最"传统"的一个——它完全不依赖LLM,纯粹通过正则表达式和集合运算来实现。核心函数evaluate_citation_f1()的工作流程分三步:
第一步,用正则\\(?P<command>[A-Za-z]*cite[A-Za-z]*\*?)从GT和Pred的LaTeX文件中分别提取所有引用key。这个正则能匹配\cite、\citep、\citet、\citeauthor等各种变体,同时会排除\nocite这类不产生正文引用的命令。每个\cite{key1, key2}中逗号分隔的key都会被逐个提取出来。
第二步,从Pred的LaTeX文件中提取bib文件里的所有合法entry key。这里代码处理了两种bib来源:一种是LaTeX文件中通过\begin{filecontents}环境内嵌的bib内容,另一种是同目录下的独立references.bib文件。
第三步,做集合运算。GT的key集合和Pred的key集合求交集就是"正确引用",GT有但Pred没有的是"遗漏引用",Pred有但GT没有的是"多余引用",而Pred引用了但bib文件里根本不存在的key就是"幻觉引用"——这对应论文中提到的"引用了根本不存在的文献"的情况。Precision、Recall、F1的计算就是标准的集合比率公式。
图表评估:正则提取 + LLM评判
evaluate_figure.py和evaluate_table.py的结构类似,都是先从LaTeX中提取图表环境,然后进行GT与Pred的匹配,最后调用LLM做质量评判。
图表提取方面,代码对LaTeX的figure环境做了非常全面的解析。除了标准的\begin{figure}...\end{figure}和\begin{figure*}...双栏图之外,还支持wrapfigure、teaserfigure等特殊环境,甚至能识别不在figure环境内、而是通过\includegraphics加上\captionof{figure}组合定义的"散装图"——这种情况在某些论文模板中很常见。提取后的每个Figure对象包含文件名、caption文本、label标签和完整的LaTeX代码块。
图表匹配的逻辑很巧妙。因为AI生成的论文可能改了文件名,所以代码不以LaTeX中的文件名为准,而是以原始提供的资源文件列表(figure_summary.txt)为标准键。通过match_figures_by_resource()函数,将GT和Pred的图片分别与资源列表做文件名匹配(做了stem去后缀、大小写统一等归一化),然后按资源文件名一一配对。
图的使用评估分两层:第一层是覆盖率,检查每个资源图是否被包含在Pred论文中、是否被正文引用(通过搜索\ref{fig:...});第二层是上下文评估,对每张匹配成功的图,提取GT和Pred中引用该图的所有位置及其上下文片段(前后各100字符),然后如果引用所在章节完全一致就直接给满分5分,不一致时则调用LLM来评判Pred的引用上下文是否恰当——prompt设计得很有讲究,特别强调了"两篇论文的章节结构可能不同,章节名不同不等于引用不当",避免LLM过度惩罚结构差异。
表格评估的匹配策略是三级退化:先用label精确匹配(\label{tab:xxx}相同),再用caption前缀匹配(前50个字符相同),都匹配不上才调用LLM做语义匹配。LLM匹配时会让模型看GT表格和所有候选Pred表格的预览,返回匹配的索引和置信度,置信度低于50%的会被丢弃。匹配成功后,再调一次LLM对两个表格做1-5分的打分,同时判断数值是否一致和结构是否一致。
幻觉检测:两阶段验证的核心实现
幻觉检测是整个代码中最复杂、也最精巧的部分,完整实现在evaluate_per_section.py中。它真正实现了论文中描述的"两阶段流程"。
第一阶段:声明抽取与分类(Pass 1)。函数_extract_claims_for_section()会把Pred的章节内容和GT的完整论文内容一起喂给LLM,使用的prompt(HALLUCINATION_CLAIM_PROMPT)设计得非常精细。它要求LLM从Pred中提取所有"可验证的具体说法"——比如具体数字、方法描述、实验设置、实验结论等,然后逐条分为三类:supported(被GT支持)、neutral(GT中没提到但不矛盾)、contradictory(与GT直接矛盾)。对于矛盾的条目,还要区分major(严重:数字编错、结论捏造、方法描述错误)和minor(轻微:措辞不精确、过度泛化)。
Prompt中有几个关键的约束条件特别值得关注。首先,“不在GT中出现≠矛盾”——这个约束被反复强调,防止LLM把"GT没写但Pred合理补充的内容"误判为幻觉。其次,要求"提取所有可验证声明,不能只挑几个"——确保检测的覆盖面足够广。最后,“跳过纯风格或结构性的观察”——避免在无关维度上浪费时间。
第二阶段:Agent验证(Pass 2)。所有被Pass 1标记为contradictory的声明会被汇总起来,交给一个coding agent(如Claude Code)做二次核查。函数_verify_contradictory_claims_batch()会把所有矛盾声明打包成一个prompt,让agent在GT论文的原始资源目录(包含LaTeX源码、代码目录、图片目录等)中以只读模式进行文件检索和验证。
这个设计的关键在于:agent不仅能看论文文本,还能看源代码。如果一个声明说"我们的方法使用了某某算法",agent可以直接去code/目录里翻源码来验证,这是纯LLM对比做不到的。验证完成后,_build_hallucination_result()函数会合并两阶段的结果,统计被"推翻"的误报数量——代码中用num_overturned变量记录了这个数据,也就是论文中提到的"人工验证97条,96%准确"这个结论的技术实现依据。
Rubric评分:上下文感知的细粒度评判
表达质量评估的实现也值得细说。代码会读取一个eval_points.json文件,里面是针对每篇论文每个章节手工编写的关键点清单(rubric),每个点包含element(名称)、importance(重要性)和description(描述)。函数evaluate_section_by_rubric()会把rubric列表和Pred的章节内容一起发给LLM,让它按1-5分对每个关键点逐一打分。
但代码最巧妙的设计是:rubric评分不是孤立进行的。在构建prompt时,代码会把前面图表评估的结果也注入进去——如果GT在某章节引用了某张图但Pred没有引用,或者某张图的上下文评分很低,这些信息都会作为"Figure/Table Context"附加到rubric的prompt中。Prompt中明确要求LLM:“如果一个rubric条目涉及数据/图表,而对应的图表被报告为缺失或评分很低,你必须降低该条目的得分”。这就把图表的评估结果串联到了表达质量的评分中,形成了一个完整的评估闭环。
整体流程串联
当eval_mode="all"时,完整的评估流程是这样的:章节分类与匹配(共享)→ 表格提取、匹配与比较 → 图表覆盖率与上下文评估 → 引用F1计算 → 逐章节rubric评分 → 逐章节幻觉检测(两阶段)。所有结果被汇总到一个EvalResult TypedDict中,包含章节级评估、整体汇总、引用统计、表格对比、图表覆盖等完整数据,最终以JSON格式保存到输出文件。
整个代码工程质量很高——TypedDict做数据校验、Pydantic模型做LLM输出的结构化解析、详细的日志记录贯穿每个关键节点、异常处理保证了单篇论文评估失败不会中断整个batch。从工程角度看,这是一套设计得相当完善的研究代码,不仅仅是"能跑",而是考虑了各种边界情况和可复现性。
论文总结
这篇论文说清楚了一件事:AI写论文"写得好看"和"写得靠谱"是两回事,现有最强的编码智能体在这两件事上几乎无法兼顾——Claude更像一个文采好但喜欢瞎编的学生,Codex更像一个写得普通但至少不胡说的学生,而真正既会写又不胡说的AI,目前还不存在。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)