SSA-RFR算法优化随机森林回归预测MATLAB代码详解:Excel数据读取与注释清晰易懂...
SSA-RFR麻雀搜索算法优化随机森林回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,初学者容易上手。
一、系统概述
本系统基于MATLAB开发,融合麻雀搜索算法(SSA)与随机森林回归(RFR)模型,构建了一套数据驱动的预测分析框架。该系统通过SSA算法对RFR模型的关键超参数进行智能寻优,显著提升了传统随机森林回归模型的预测精度与稳定性,适用于工业数据预测、环境参数估算、金融指标预测等多领域的回归分析场景。
系统具备完整的数据处理流程,涵盖数据读取、数据集划分、归一化处理、参数优化、模型训练、预测分析及误差评估等功能模块,且代码结构清晰、注释详尽,支持初学者快速上手并根据实际需求进行二次开发。
二、核心功能模块解析
(一)数据处理模块
数据处理模块是整个预测系统的基础,负责将原始数据转化为符合模型输入要求的标准化数据,主要包含数据读取、数据集划分与数据归一化三个子功能。
- 数据读取:通过调用MATLAB内置函数读取Excel格式的数据源文件,支持指定数据所在工作表及数据范围,自动提取输入特征变量(前n-1列)与目标预测变量(最后1列),并统计样本总数,为后续数据处理提供基础数据支撑。
- 数据集划分:按照用户预设的测试集样本数量,将原始数据集划分为训练集与测试集。训练集用于模型参数优化与训练,测试集用于验证模型的泛化能力,划分过程中保持数据的原始顺序,避免因随机打乱导致的数据分布偏差。
- 数据归一化:采用
mapminmax函数对训练集输入数据与输出数据进行归一化处理,将数据压缩至[-1,1]区间(输入数据)或默认区间(输出数据),消除不同特征变量量纲差异对模型训练的影响;同时保存归一化参数,用于后续测试集数据的标准化处理与预测结果的反归一化,确保数据处理的一致性。
(二)误差评估模块(calc_error函数)
误差评估模块是衡量模型预测性能的核心,通过计算多项误差指标,全面量化预测值与实际值之间的偏差,为模型性能分析提供客观依据。
SSA-RFR麻雀搜索算法优化随机森林回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,初学者容易上手。
该模块支持输入真实值与预测值两类参数,自动处理列向量与行向量的格式转换,确保计算过程的兼容性。主要计算的误差指标包括:
- 平均绝对误差(MAE):通过计算绝对误差的平均值,反映预测值误差的实际大小,对异常值不敏感,适合评估数据分布较为均匀的场景。
- 均方误差(MSE):将预测值与实际值偏差的平方和除以样本总数,放大了较大误差的影响,能有效反映模型对极端偏差的控制能力。
- 均方误差根(RMSE):对MSE进行开方运算,使误差指标的量纲与原始数据一致,便于直观理解预测偏差的实际大小。
- 平均绝对百分比误差(MAPE):通过计算偏差绝对值与实际值比值的平均值,消除了量纲影响,可用于不同数据集或不同模型间的性能对比。
同时,模块还会输出每个样本的绝对误差与相对误差,并在命令行窗口打印各项误差指标的计算结果,方便用户快速查看模型性能。
(三)适应度计算模块(fitness函数)
适应度计算模块是SSA算法优化RFR模型的关键桥梁,负责将RFR模型的预测性能转化为SSA算法可识别的适应度值,为参数寻优提供评价标准。
其核心流程如下:
- 参数提取:从SSA算法生成的个体中提取RFR模型的两个关键超参数——决策树数量(ntrees)与每棵树使用的特征数量(nlayers)。
- 数据格式转换:将归一化后的训练集输入数据、输出数据及原始训练集输出数据进行转置处理,使其符合RFR模型训练函数的输入格式要求。
- 模型训练与预测:调用随机森林回归训练函数(regRF_train),基于提取的超参数构建RFR模型,并使用训练集数据进行模型训练;随后通过训练好的模型对训练集数据进行预测,得到预测结果。
- 适应度计算:将预测结果进行反归一化处理,恢复至原始数据的量纲;以反归一化后的预测值与原始训练集输出值的均方误差作为适应度值,适应度值越小,表明当前超参数组合下RFR模型的训练精度越高。
(四)麻雀搜索优化模块(main函数核心部分)
麻雀搜索优化模块是系统的核心创新点,通过模拟麻雀种群的觅食与反捕食行为,实现对RFR模型超参数的智能寻优,具体包含参数初始化、种群更新与边界控制三个关键环节。
- 参数初始化:用户可设置种群规模(popsize)、最大进化代数(maxgen)、安全值(ST)、发现者比例(PD)、危险麻雀比例(SD)等SSA算法参数,同时定义RFR模型超参数的取值范围(lb为下限,ub为上限);随机生成初始种群,每个个体对应一组RFR模型超参数,并计算每个个体的适应度值,确定初始种群中的最优个体与最差个体。
- 种群更新:
- 发现者位置更新:根据预警值(R2)与安全值(ST)的大小关系,采用不同策略更新发现者位置。当R2- 加入者位置更新:加入者分为两类,一类通过跟随最优发现者调整位置,另一类通过随机策略探索新的搜索区域,确保种群的多样性与搜索的全局性。
- 危险麻雀位置更新:对于意识到危险的麻雀,若其适应度值较差,则向最优个体靠近以提升性能;若其适应度值较优,则通过随机扰动策略探索新区域,避免种群陷入局部最优。 - 边界控制:在每次种群更新后,对超出超参数取值范围的个体进行边界截断处理,确保所有个体对应的超参数均在合理区间内;同时对超参数进行取整处理,因为决策树数量与特征数量需为正整数。
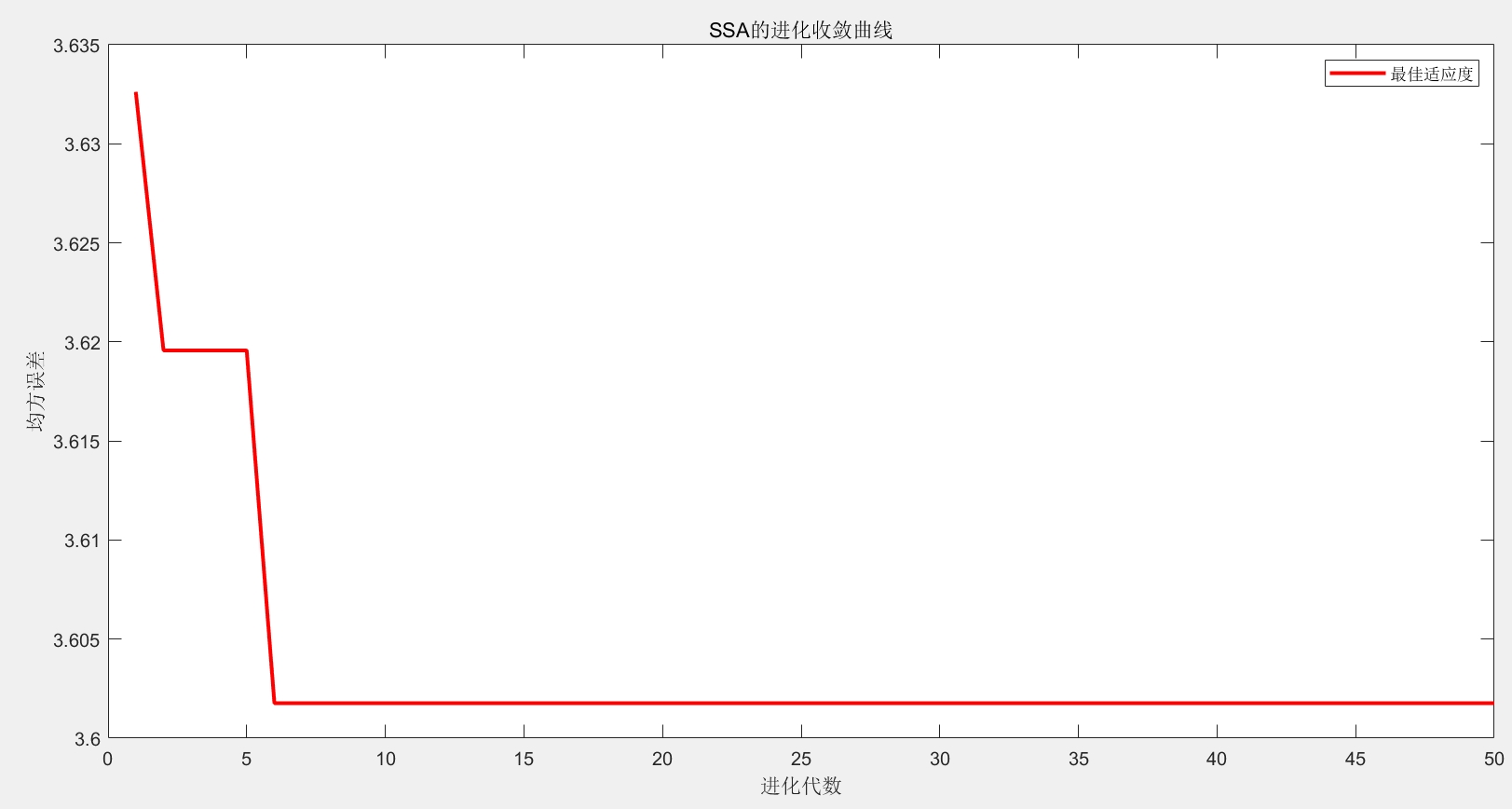
优化过程中,系统会实时记录每一代的全局最优适应度值,绘制进化收敛曲线,直观展示超参数寻优的过程与效果;优化结束后,输出最优超参数组合(Bestpos)与对应的最优适应度值(Bestscore)。
(五)随机森林回归模块(regRF_train与regRF_predict函数)
随机森林回归模块是实现预测功能的核心,包含模型训练(regRFtrain)与预测(regRFpredict)两个子模块,基于多棵决策树的集成学习思想,提升模型的预测精度与泛化能力。
- 模型训练子模块(regRFtrain):
- 参数配置:支持设置决策树数量(ntree)、每棵树使用的特征数量(mtry)、节点最小样本数(nodesize)、是否计算特征重要性(importance)等参数,用户可根据数据集规模与预测需求灵活调整。
- 数据校验:对输入的训练数据进行校验,包括检查数据维度一致性、是否存在缺失值(NaN)、目标变量唯一值数量等,确保数据符合模型训练要求;若目标变量唯一值数量≤5,会发出回归任务适用性警告。
- 模型训练:调用底层训练函数(mexRFtrain),基于Bootstrap抽样方法生成多组训练子集,为每棵决策树分配不同的特征子集,构建多棵决策树;同时计算每棵树的节点信息(如左右子节点索引、节点状态、节点均值等),并统计模型的均方误差(mse)与伪R²(rsq),评估模型训练效果。
- 结果返回:返回训练好的模型结构,包含决策树节点信息、模型超参数、训练误差、特征重要性(若开启)等数据,为后续预测任务提供支持。
- 模型预测子模块(regRFpredict):
- 输入校验:检查输入参数数量,确保包含预测数据(X)与训练好的模型(model)两类必要参数,若参数数量不符则抛出错误提示。
- 预测计算:调用底层预测函数(mexRFpredict),基于模型中存储的决策树节点信息,对输入的预测数据进行遍历分类,得到每棵决策树的预测结果,通过取平均值的方式融合多棵决策树的预测结果,得到最终预测值(Yhat)。
- 偏差校正:若模型训练过程中开启了偏差校正(corrbias),则基于模型中存储的校正系数(coef)对预测结果进行校正,进一步提升预测精度。
三、系统运行流程
- 环境初始化:运行main函数,首先清空MATLAB工作空间中的变量与命令行窗口,避免历史数据对当前运行结果的干扰。
- 数据预处理:读取Excel数据源文件,划分训练集与测试集,对训练集数据进行归一化处理,并使用训练集的归一化参数对测试集数据进行标准化处理。
- SSA参数寻优:初始化SSA算法参数与种群,通过多代进化更新种群,寻找使RFR模型适应度值最小的最优超参数组合,并绘制进化收敛曲线。
- RFR模型训练:将SSA算法寻得的最优超参数代入RFR模型,使用归一化后的训练集数据进行模型训练,构建优化后的RFR预测模型。
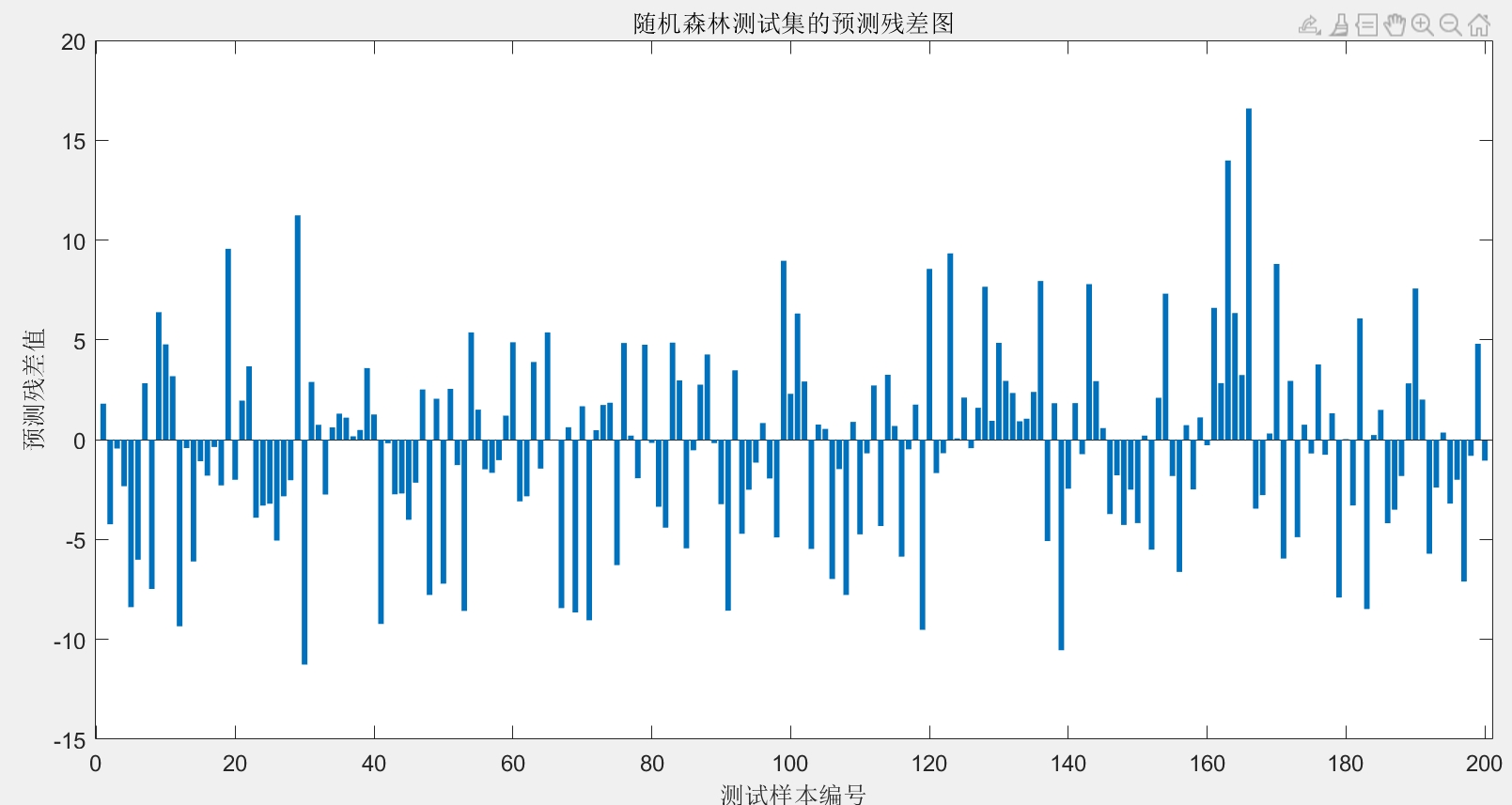
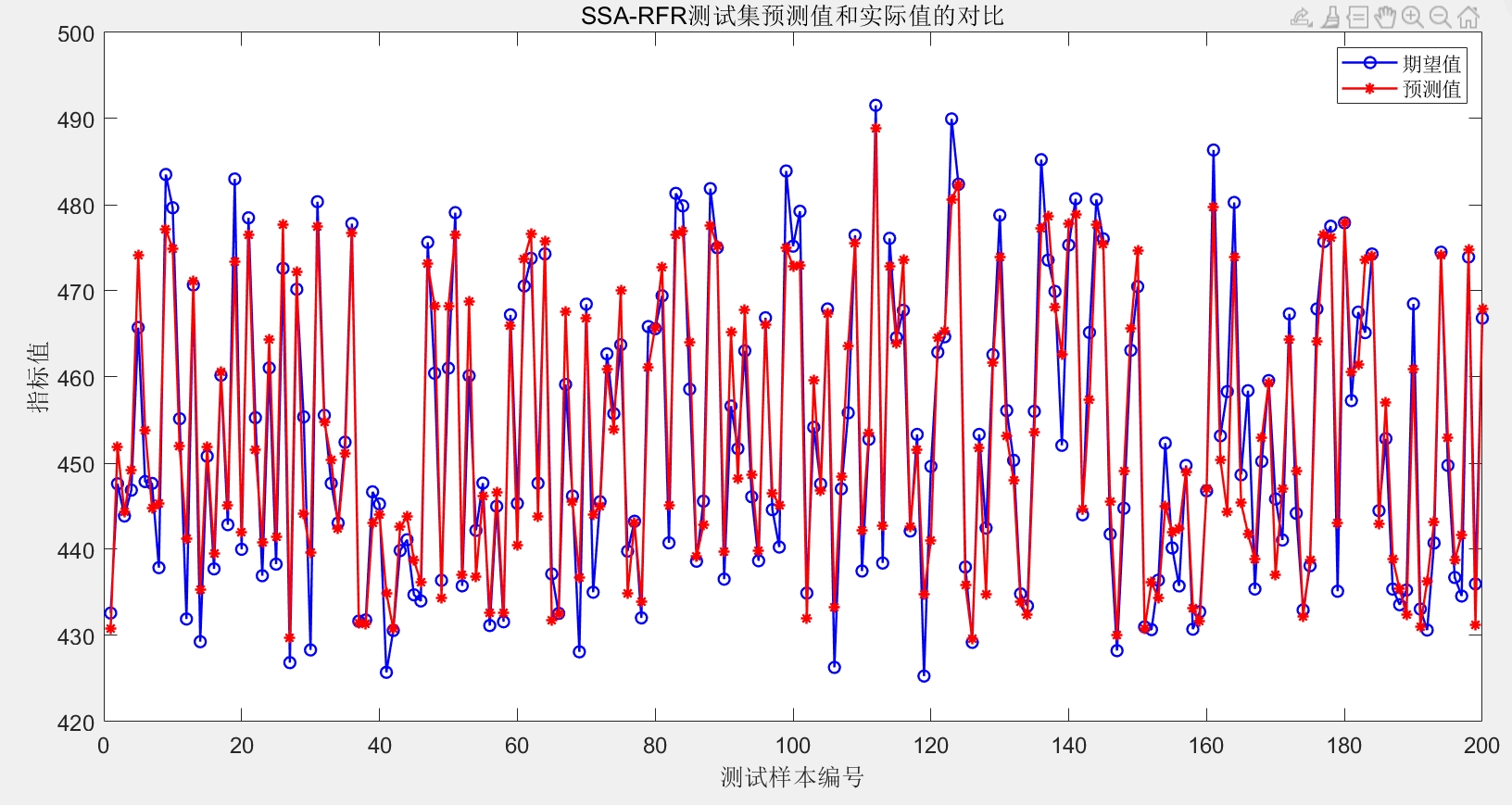
- 模型预测与评估:使用训练好的模型对标准化后的测试集数据进行预测,将预测结果反归一化处理;调用误差评估模块计算测试集预测结果的各项误差指标,同时绘制测试集实际值与预测值对比图、预测残差图,直观展示模型的预测性能。
- 结果输出:在命令行窗口打印SSA优化过程信息、最优超参数组合及各项误差指标,保存训练好的模型与处理后的数据,为后续分析或二次开发提供数据支持。
四、系统特点与优势
- 性能优越:通过SSA算法对RFR模型超参数进行智能优化,有效解决了传统RFR模型依赖人工经验设置超参数导致的性能不稳定问题,显著提升了模型的预测精度与泛化能力。
- 易用性强:代码结构模块化程度高,每个功能模块均有详细注释,主程序(main.m)可直接读取Excel数据,用户仅需修改数据源路径、测试集数量等少量参数即可运行,适合初学者快速上手。
- 功能完整:涵盖数据处理、参数优化、模型训练、预测分析、误差评估等全流程功能,支持输出多项误差指标与可视化图表,满足用户对模型性能的全面评估需求。
- 扩展性好:系统采用模块化设计,各功能模块相对独立,用户可根据实际需求替换数据源、调整算法参数(如SSA的种群规模、RFR的决策树数量),或集成其他优化算法(如粒子群优化、遗传算法)进一步提升模型性能。
五、适用场景与使用建议
(一)适用场景
- 工业过程参数预测:如化工生产中的产品纯度预测、机械加工中的加工精度预测等,可基于历史生产数据构建预测模型,实现生产过程的提前预警与优化控制。
- 环境监测数据估算:如空气质量指数(AQI)预测、水质指标估算等,利用环境监测站的历史数据与相关影响因素(如气象数据、污染源数据),实现对未来环境指标的预测。
- 金融经济指标分析:如股票价格预测、GDP增长率估算等,结合宏观经济数据、市场交易数据等,为投资决策或政策制定提供数据支撑。
(二)使用建议
- 数据准备:确保数据源为Excel格式,且数据无缺失值、异常值(或已进行预处理);建议输入特征变量与目标变量之间存在较强的相关性,以提升模型的预测效果。
- 参数调整:根据数据集规模调整SSA算法参数,若数据集较大,可适当增大种群规模(如30-50)与最大进化代数(如50-100),以提高参数寻优的准确性;若数据集较小,可减小参数值,降低计算复杂度。
- 结果分析:关注进化收敛曲线的收敛速度与稳定性,若曲线过早收敛,可能存在种群陷入局部最优的问题,可通过调整安全值(ST)、发现者比例(PD)等参数优化搜索过程;同时结合误差指标与可视化图表,综合评估模型的预测性能,若MAE、RMSE等指标较大,可考虑增加输入特征变量或扩大数据集规模。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)