LangChain 聊天模型核心能力 [ 3 ]

聊天模型 -- 结构化输出
在 LangChain 中,聊天模型提供了额外的功能:结构化输出。一种使聊天模型以结构化格式(例如 JSON)进行响应的技术。例如,可能希望将模型输出存储在数据库中,并确保输出符合数据库模式。这种需求激发了结构化输出的概念,其中可以指示模型使用特定的输出结构进行响应。
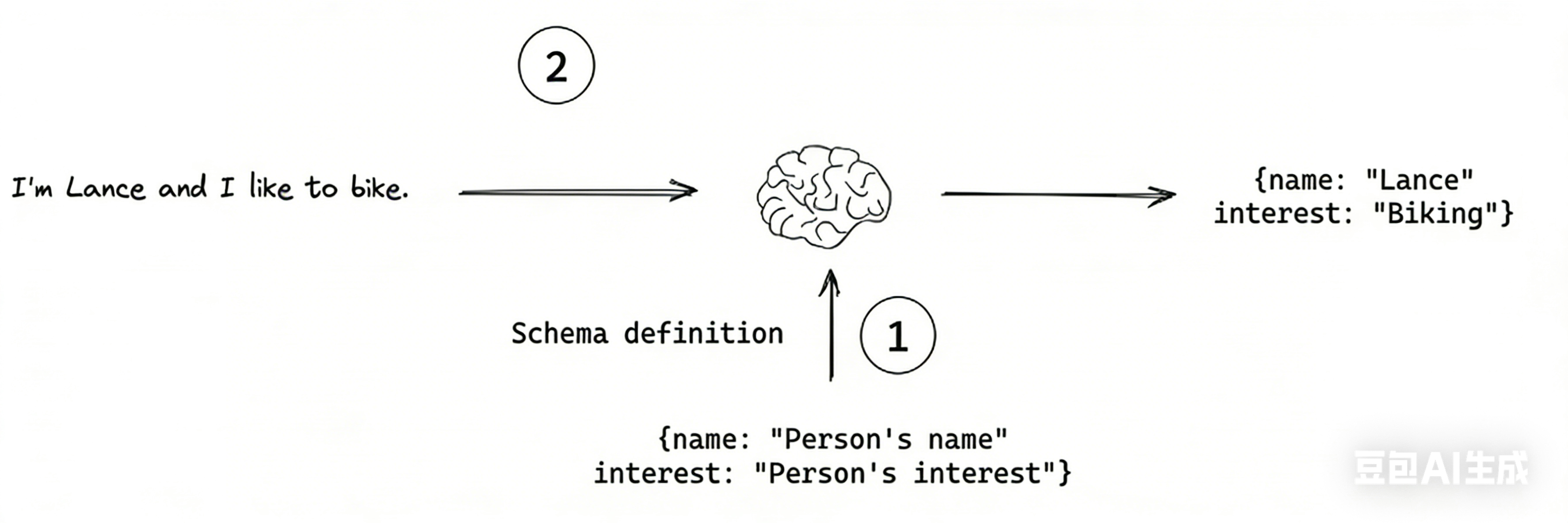
这样做的核心原因是:从 “字符串” 到 “对象” 的范式转换。想象一下,在没有这个功能之前,我们调用聊天模型得到的是一个 AIMessage,其内容是一个字符串。例如下述伪代码:
# 代码块
model = ChatOpenAI()
response = model.invoke("告诉我关于苹果公司的最新消息。")
print(response.content)
# 输出: "苹果公司于昨日发布了新款iPhone...其股价上涨了2%..."
这个字符串对人类很友好,但对程序不友好。如果我们想从这段文本中提取出 “公司名” 和 “股价变化” 并用在后续逻辑中,则需要编写复杂且容易出错的解析代码(例如,使用正则表达式)。
聊天模型的 with_structured_output 方法则允许我们预先定义一个期望的数据结构,并要求大模型必须按照这个结构返回信息。
with_structured_output()
要想使用结构化输出能力,LangChain 提供了一种方法 .with_structured_output(),该方法需要先定义输出结构,然后执行通过 .with_structured_output() 得到的 Runnable 实例。步骤如下(伪代码):
# 1. 定义输出结构
schema = {"foo": "bar"}
# 2. 绑定schema,其实是生成支持结构化返回的 Runnable 实例
model_with_structure = model.with_structured_output(schema)
# 3. 执行
structured_output = model_with_structure.invoke(user_input)
这是获得结构化输出的最简单、最可靠的方法。此方法将输出结构作为参数输入,返回一个类似model的 Runnable。不同之处在于执行 Runnable 后的输出结果,输出的不是字符串或消息,而是输出与给定输出结构相对应的对象。
该输出结构可以指定为 TypedDict 类、JSON Schema 或 Pydantic 类。如果使用 TypedDict 或 JSON Schema,则 Runnable 将返回一个字典,如果使用 Pydantic 类,则将返回一个 Pydantic 对象。以下是该方法的详细定义:
with_structured_output() 方法定义:
with_structured_output(
schema: dict[str, Any] | type[_BM] | type | None = None, # 输出结构:JSON Schema / Pydantic / TypedDict / None
*, # 强制关键字参数分隔,后续必须用 key=value 传参
method: Literal['function_calling', 'json_mode', 'json_schema'] = 'json_schema', # 结构化实现方式
include_raw: bool = False, # 是否返回原始 AIMessage(默认只返回解析结果)
strict: bool | None = None, # 是否严格校验 schema(True=强匹配,None=不设)
**kwargs: Any, # 额外参数,透传给 bind()
) -> Runnable[PromptValue | str | Sequence[BaseMessage | list[str] | tuple[str, str] | str | dict[str, Any]], dict | _BM]
# 返回:Runnable,输入支持提示串/消息,输出为 dict 或 Pydantic 对象请求参数:
schema:表示输出结构。可以传入为:JSON Schema、TypedDict、Pydantic、OpenAI 函数 / 工具
method:表示 LLM 的生成方法:
json_schema(默认):表示使用 OpenAI 的结构化输出 API。function_calling:使用 OpenAI 的工具调用(以前称为函数调用)json_mode:使用 OpenAI 的JSON mode。请注意,如果使用json_mode,则必须在模型调用中包含将输出格式化为所需schema的说明。
include_raw:
- 如果为
False(默认),则仅返回解析的结构化输出。如果在模型输出解析过程中发生错误,则会引发错误。 - 如果为
True,则将返回原始模型响应(BaseMessage)和解析的模型响应。如果在输出解析过程中发生错误,它也会被捕获并返回。最终输出始终是带有键"raw"、"parsed"和"parsing_error"的字典。
strict:
- 如果为
True,保证模型输出与schema完全匹配。输入schema也将根据支持的schema进行验证。 - 如果为
False,输入schema将不会被验证,模型输出也不会被验证。 - 如果为
None(默认),则不会将strict参数传递给模型。
tools:要绑定到聊天模型的工具列表。要求:method 为 'json_schema'、strict=True、include_raw=True。则生成的 AIMessage 将在 'raw' 中包含工具调用
kwargs(Any):任何附加参数都直接传递给bind()。
返回值:
返回一个 Runnable 实例。将来执行时:
如果 include_raw=False
- 且
schema是 Pydantic 类,则 Runnable 会输出 Pydantic 对象。 - 否则 Runnable 输出一个字典。
如果 include_raw=True,则 Runnable 输出一个带有键的字典:
'raw':BaseMessage'parsed':如果出现解析错误,则为 None,否则类型取决于如上所述的schema。'parsing_error':Optional[BaseException]
返回 Pydantic 对象
我们可以设置执行 Runnable 后的输出结果指定为 Pydantic 类,这将返回一个 Pydantic 对象。当收到模型的响应后,LangChain 会提取代表 Pydantic 参数的 JSON 对象,并用 Pydantic 模型对其进行解析和验证,将这个验证后的 JSON 转换为一个可用的 Pydantic 对象实例返回。如下所示:
from langchain_openai import ChatOpenAI
from typing import Optional
from pydantic import BaseModel, Field
# 初始化大语言模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义结构化输出格式:Pydantic 模型
class Joke(BaseModel):
"""用于返回一个笑话的结构化数据"""
# 笑话的开头/铺垫
setup: str = Field(description="笑话的开头")
# 笑话的包袱/点睛之笔
punchline: str = Field(description="笑话的妙语")
# 可选评分,1-10分
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
# 绑定结构化输出规则
structured_model = model.with_structured_output(Joke)
# 调用模型获取结果
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
# 打印结构化结果
print(result)打印结果:
setup='为什么歌手总是喜欢在洗手间里唱歌?'
punchline='因为那里有很好的回音和灵感!'
rating=7
还支持嵌套输出:
from langchain_openai import ChatOpenAI
from typing import Optional, List
from pydantic import BaseModel, Field
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出结构: Pydantic 类
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
class Data(BaseModel):
"""获取关于笑话的数据。"""
jokes: List[Joke]
structured_model = model.with_structured_output(Data)
result = structured_model.invoke("分别讲一个关于唱歌和跳舞的笑话")
print(result)打印结果:
代码块
jokes=[
Joke(setup='为什么唱歌的人总是很快乐?', punchline='因为他们总是"音"乐满满!', rating=8),
Joke(setup='一个跳舞的牛走进俱乐部,为什么大家都不理它?', punchline='因为它总是"踏"错节拍!', rating=7)
]返回 TypedDict
先了解一下 TypedDict,它用于为字典对象提供精确的、结构化的类型提示。它允许我们指定一个字典中应该有哪些键,以及每个键对应的值的类型。最清晰、最常用的定义方式,就是类似于定义一个类(Python 3.8+),如下所示:
from typing import TypedDict
class User(TypedDict):
name: str
age: int
email: str
is_active: bool = True # 默认值这有什么用呢?对于它非常重要的一个能力就是捕捉键名拼写错误与类型错误,如:
user1: User = {
"name": "Bob",
"age": 25,
"email": "bob@example.com"
}
# 类型检查器会捕获这些错误
bad_user: User = {
"name": "Dave",
"age": "forty", # 错误: 应该是 int
"emal": "dave@example.com" # 错误: 拼写错误
}因此,我们也可以设置执行 Runnable 后的输出结果指定为 TypedDict 类,这将返回一个字典,且输出后,会根据设定进行验证。以下是该方法的使用姿势:
# 导入LangChain与OpenAI的大模型对接类
from langchain_openai import ChatOpenAI
# 导入类型注解工具:TypedDict用于定义结构化输出字典, Annotated用于添加字段描述
from typing_extensions import Annotated, TypedDict
# 补充导入可选类型(原代码缺失,否则会报错)
from typing import Optional
# 初始化大模型实例,指定使用gpt-4o-mini模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义结构化输出格式:使用TypedDict定义固定结构的字典类型
class Joke(TypedDict):
"""笑话的结构化数据格式"""
# 笑话开头:字符串类型,必填,字段说明
setup: Annotated[str, ..., "这个笑话的开头"]
# 笑话妙语/结尾:字符串类型,必填,字段说明
punchline: Annotated[str, ..., "这个笑话的妙语"]
# 笑话评分:整数类型,可选(可传None),字段说明
rating: Annotated[Optional[int], None, "从1到10分,给这个笑话评分"]
# 为模型绑定结构化输出能力,强制输出符合Joke格式的结果
structured_model = model.with_structured_output(Joke)
# 调用模型,传入提示词,获取结构化的笑话数据
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
# 打印最终输出的结构化结果
print(result)打印结果:
{
'setup': '为什么歌手总是带一把伞?',
'punchline': '因为他们怕下雨时会错过音调!',
'rating': 7
}
让我们加入 include_raw=True,再来看看效果:
# 给模型开启结构化输出,并设置返回原始响应信息(include_raw=True)
structured_model = model.with_structured_output(Joke, include_raw=True)
# 调用模型,传入提示词,获取带原始数据的结构化笑话结果
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
# 打印完整返回结果(包含 raw 原始信息 + parsed 解析后的数据)
print(result)打印结果:
{
'raw': AIMessage(content='{"setup":"你知道为什么歌手总是喜欢在吃饭的时候唱歌吗?","punchline":"因为他们想要增加自己的"调味"!","rating":7}', additional_kwargs={'parsed': None, 'refusal': None, 'response_metadata': {'token_usage': {'completion_tokens': 40, 'prompt_tokens': 173, 'total_tokens': 213, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-C6WnVyn0C2VIwCQfrfIm3GdNA', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='run-00306p87-97-490cf-65e5b32358b4-0', usage_metadata={'input_tokens': 173, 'output_tokens': 40, 'total_tokens': 213, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
'parsed': {'setup': '你知道为什么歌手总是喜欢在吃饭的时候唱歌吗?', 'punchline': '因为他们想要增加自己的"调味"!', 'rating': 7},
'parsing_error': None
}返回 JSON
还可以让聊天模型直接返回 JSON,只不过为了声明 JSON,我们需要定义 JSON Schema,如下所示:
# 导入LangChain对接OpenAI大模型的核心类
from langchain_openai import ChatOpenAI
# 初始化大模型实例,指定使用 gpt-4o-mini 模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义 JSON Schema 结构化输出格式(手动定义数据结构)
json_schema = {
# 结构名称
"title": "joke",
# 结构描述
"description": "给用户讲一个笑话。",
# 指定输出类型为对象(字典)
"type": "object",
# 定义对象包含的字段
"properties": {
# 字段1:笑话开头
"setup": {
"type": "string", # 数据类型:字符串
"description": "这个笑话的开头", # 字段说明
},
# 字段2:笑话妙语/结尾
"punchline": {
"type": "string", # 数据类型:字符串
"description": "这个笑话的妙语", # 字段说明
},
# 字段3:笑话评分(可选)
"rating": {
"type": "integer", # 数据类型:整数
"description": "从1到10分,给这个笑话评分", # 字段说明
"default": None # 默认值:空
},
},
# 指定必填字段(setup 和 punchline 必须返回)
"required": ["setup", "punchline"],
}
# 为模型绑定 JSON Schema 结构化输出规则
structured_model = model.with_structured_output(json_schema)
# 调用模型,传入提示词,获取符合 Schema 格式的结果
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
# 打印输出的结构化数据
print(result)打印结果:
{
'setup': '为什么唱歌的人总是很开心?',
'punchline': '因为他们总是有很多音符可供选择!',
'rating': 7
}
选择输出格式
创建具有联合类型属性的父模式,以使用 Pydantic 为例(其他同理),代码如下:
# 导入LangChain对接OpenAI大模型的类
from langchain_openai import ChatOpenAI
# 导入Pydantic的基础模型类和字段描述类,用于定义结构化输出
from pydantic import BaseModel, Field
# 导入可选类型和联合类型,用于字段约束
from typing import Optional, Union
# 初始化大模型实例,指定使用gpt-4o-mini模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义笑话结构化模型,继承Pydantic的BaseModel
class Joke(BaseModel):
"""给用户讲一个笑话。"""
# 笑话开头:字符串类型,必填,附带字段描述
setup: str = Field(description="这个笑话的开头")
# 笑话妙语:字符串类型,必填,附带字段描述
punchline: str = Field(description="这个笑话的妙语")
# 笑话评分:整数类型,可选,默认值为None,附带字段描述
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
# 定义普通对话响应结构化模型
class ConversationalResponse(BaseModel):
"""以对话的方式回应。待人友善,乐于助人。"""
# 对话响应内容:字符串类型,必填,附带字段描述
response: str = Field(description="对用户查询的会话响应")
# 定义最终输出模型,支持两种输出类型二选一
class FinalResponse(BaseModel):
# 联合类型:输出结果要么是Joke笑话,要么是ConversationalResponse普通对话
final_output: Union[Joke, ConversationalResponse]
# 为模型绑定最终的结构化输出规则
structured_model = model.with_structured_output(FinalResponse)
# 第一次调用:请求讲唱歌的笑话,模型会自动返回Joke类型的结果
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print(result)
# 第二次调用:普通问候,模型会自动返回ConversationalResponse类型的结果
result = structured_model.invoke("你好")
print(result)打印结果:
final_output=Joke(setup='为什么歌手总是带着梯子?', punchline='因为他们想要达到更高的音调!', rating=7)
final_output=ConversationalResponse(response='你好!有什么我可以帮助你的吗?')
实用场景
场景 1:作为信息提取器
# 导入LangChain对接OpenAI大模型的核心类
from langchain_openai import ChatOpenAI
# 导入可选类型,用于定义非必填字段
from typing import Optional
# 导入Pydantic基础模型和字段描述,用于定义结构化输出格式
from pydantic import BaseModel, Field
# 导入系统消息和用户消息类,用于构建模型对话上下文
from langchain_core.messages import HumanMessage, SystemMessage
# 初始化大模型实例,指定使用 gpt-4o-mini 模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义人物信息结构化提取模型,继承 Pydantic BaseModel
class Person(BaseModel):
"""一个人的信息。"""
# 核心注意事项:
# 1. 所有字段均为 Optional 可选类型,允许模型在未知时返回 None
# 2. 每个字段附带清晰描述,能显著提升大模型信息提取的准确性
# 姓名:字符串可选,默认None,描述为人物姓名
name: Optional[str] = Field(default=None, description="这个人的名字")
# 头发颜色:字符串可选,默认None,描述为人物头发颜色
hair_color: Optional[str] = Field(default=None, description="如果知道这个人头发的颜色")
# 肤色:字符串可选,默认None,描述为人物肤色
skin_color: Optional[str] = Field(default=None, description="如果知道这个人的肤色")
# 身高(米):字符串可选,默认None,描述为以米为单位的身高
height_in_meters: Optional[str] = Field(default=None, description="以米为单位的高度")
# 为模型绑定 Person 结构化输出规则,强制输出该格式
structured_model = model.with_structured_output(schema=Person)
# 构建对话消息列表:包含系统提示 + 用户输入文本
messages = [
# 系统提示:定义模型角色为信息提取专家,未知字段返回 null
SystemMessage(content="你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性,请返回null!"),
# 用户输入:需要提取信息的原始文本
HumanMessage(content="史密斯,身高6英尺,金发。")
]
# 调用模型,传入消息上下文,执行信息提取
result = structured_model.invoke(messages)
# 打印提取后的结构化人物信息
print(result)打印结果:
name='史密斯' hair_color='金发' skin_color=None height_in_meters='1.83'
场景 2:使用 "少样本提示" 来增强信息提取能力
由于「少样本提示」能力还未讲解,这部分代码示例在「少样本提示」部分看,可直接跳过去看。
场景 3:与工具结合使用
注意:使用聊天模型原生的工具搭配结构化输出并不好用!!!这里只是了解下其能力。更好的用法见 LangGraph Agent 能力。
方式 1:使用 with_structured_output() 的 tools 参数
# 导入LangChain对接OpenAI大模型的类
from langchain_openai import ChatOpenAI
# 导入Pydantic基础模型和字段,用于定义结构化输出格式
from pydantic import BaseModel, Field
# 导入工具装饰器,用于定义自定义工具函数
from langchain_core.tools import tool
# 导入用户消息类,用于构建模型输入
from langchain_core.messages import HumanMessage
# 初始化大模型实例,指定使用gpt-4o-mini模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义结构化输出对象:搜索结果模型
class SearchResult(BaseModel):
"""Search for ch result.
结构化搜索结果。"""
# 搜索查询词:字符串类型,必填
query: str = Field(description="搜索查询")
# 搜索结果摘要:字符串类型,必填
findings: str = Field(description="调查结果摘要")
# 定义工具函数:使用@tool装饰器注册为模型可调用工具
@tool
def web_search(query: str) -> str:
"""在网上搜索信息。
Args:
query: 搜索查询
"""
# 模拟网络搜索,返回固定的天气信息
return "西安今天多云转小雨,气温18-23度,东南风2级,空气质量良好"
# 为模型配置:结构化输出 + 绑定工具 + 严格模式 + 返回原始响应
structured_search_model = model.with_structured_output(
SearchResult, # 指定输出结构为SearchResult
tools=[web_search], # 绑定可调用的工具列表
strict=True, # 开启严格模式,强制符合格式
include_raw=True, # 返回原始响应信息
)
# 调用模型,传入用户查询,执行结构化搜索
result = structured_search_model.invoke("搜索当前最新的西安的天气")
# 打印完整的返回结果(包含raw、parsed、parsing_error)
print(result)输出结果:
{
'raw': AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_8cJnQUQp78Pugdput7oei', 'function': {'arguments': '{"query":"西安天气"}', 'name': 'web_search'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 178, 'total_tokens': 196, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-C6WnVyn0C2VIwCQfrfIm3GdNA', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-00306p87-97-490cf-65e5b32358b4-0', usage_metadata={'input_tokens': 178, 'output_tokens': 18, 'total_tokens': 196, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
'parsed': None,
'parsing_error': None
}可以看到,它并不能直接帮我们输出想要的SearchResult搜索结果,而只是返回了AIMessage(工具调用信息)实际上,with_structured_output 方法只是让模型知道有哪些工具可以调用,但是并不会自动执行工具。要获得工具执行的结果并将其结构化输出,我们需要手动处理工具调用,然后将工具返回的结果再次传递给模型。见方式 2。
方式 2:拆解能力,单独依次执行
需要同时使用结构化输出和工具时,需要注意顺序,不要弄反:
- 首先绑定工具
- 其次添加结构化输出
代码演示:
# 导入LangChain对接OpenAI大模型的核心类
from langchain_openai import ChatOpenAI
# 导入Pydantic基础模型和字段,用于定义结构化输出格式
from pydantic import BaseModel, Field
# 导入工具装饰器,用于注册自定义工具函数
from langchain_core.tools import tool
# 导入用户消息类,用于构建模型输入内容
from langchain_core.messages import HumanMessage
# 初始化大模型实例,指定使用 gpt-4o-mini 模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义结构化输出对象:搜索结果模型
class SearchResult(BaseModel):
"""Search for ch result.
结构化搜索结果。"""
# 搜索查询词:字符串类型,必填
query: str = Field(description="搜索查询")
# 搜索结果摘要:字符串类型,必填
findings: str = Field(description="调查结果摘要")
# 定义网络搜索工具,使用 @tool 装饰器注册为模型可调用工具
@tool
def web_search(query: str) -> str:
"""在网上搜索信息。
Args:
query: 搜索查询
"""
# 模拟网络搜索,返回固定的西安天气信息
return "西安今天多云转小雨,气温18-23度,东南风2级,空气质量良好"
# 链式调用:先绑定工具,再绑定结构化输出,一次性完成配置
model_with_tools = (
model.bind_tools([web_search]).with_structured_output(SearchResult)
)
# 构建用户消息,传入查询内容
messages = [HumanMessage(content="搜索当前最新的西安的天气")]
# 调用绑定工具和结构化输出的模型,执行查询
result = model_with_tools.invoke(messages)
# 打印最终结构化输出结果
print(result)打印结果:
query='西安天气' findings='西安当前多云转小雨,气温在18℃到23℃之间,有轻微的风,空气湿度适中,无降水。'
从打印结果可以发现,它也没有去调用工具。而是聊天模型直接给出了结果。让我们改造下:
# 导入 LangChain 对接 OpenAI 大模型的类
from langchain_openai import ChatOpenAI
# 导入 Pydantic 用于定义结构化输出格式
from pydantic import BaseModel, Field
# 导入工具装饰器,用于注册模型可调用工具
from langchain_core.tools import tool
# 导入用户消息类,构建模型输入上下文
from langchain_core.messages import HumanMessage
# 初始化大模型实例,指定使用 gpt-4o-mini
model = ChatOpenAI(model="gpt-4o-mini")
# 定义结构化输出结果模型
class SearchResult(BaseModel):
"""Search for ch result.
结构化搜索结果。"""
# 搜索关键词
query: str = Field(description="搜索查询")
# 搜索结果摘要
findings: str = Field(description="调查结果摘要")
# 定义网络搜索工具函数
@tool
def web_search(query: str) -> str:
"""在网上搜索信息。
Args:
query: 搜索查询
"""
# 模拟真实搜索,返回固定天气信息
return "西安今天多云转小雨,气温18-23度,东南风2级,空气质量良好"
# 手动流程:先让模型判断是否需要调用工具
messages = [HumanMessage(content="搜索当前最新的西安的天气")]
# 绑定工具并调用模型,获取 AI 响应(包含工具调用指令)
ai_msg = model.bind_tools([web_search]).invoke(messages)
# 遍历工具调用指令,执行工具并把结果加入消息列表
for tool_call in ai_msg.tool_calls:
tool_msg = web_search.invoke(tool_call)
messages.append(tool_msg)
# 绑定结构化输出格式
structured_search_model = model.with_structured_output(SearchResult)
# 传入包含工具结果的完整消息,让模型生成最终结构化答案
result = structured_search_model.invoke(messages)
# 打印最终结构化结果
print(result)打印结果:
query='西安天气' findings='西安今天多云转小雨,气温18-23度,东南风2级,空气质量良好。'
这次的结果符合我们的预期。但依旧很麻烦,因为其实我们实际上调用了两次模型:
- 第一次调用模型时,模型返回了工具调用,然后我们执行工具,将工具结果加入消息列表。
- 第二次调用时,我们使用结构化输出
SearchResult的模型,来处理整个消息列表(包括工具调用的结果),然后输出结构化结果。
有没有办法用一次就可以做到这件事?就能获取到结构化输出的结果呢?将来在学习 LangChain 部分的Agent(实际上,调用两次模型)就可以。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)