ResNet 和 Transformer 的原始论文阅读——Attention Is All You Need笔记
李沐的论文精读——Transformer论文逐段精读
第一遍 title + abs + conclusion
title
Attention Is All You Need 注意力是您所需要的全部
abs
主流序列转导模型基于包含编码器和解码器的复杂循环或卷积神经网络架构。性能最优的模型还会通过注意力机制连接编码器与解码器。我们提出了一种全新的简单网络架构——Transformer,该架构完全基于注意力机制,彻底摒弃了循环结构和卷积运算。在两项机器翻译任务的实验中,这些模型不仅在质量上表现更优,还具有更高的并行化能力且训练耗时显著降低。我们的模型在 WMT 2014英德翻译任务中取得28.4 BLEU分数,较现有最佳结果(包括集成模型)提升了超过2 BLEU。在 WMT 2014英法翻译任务中,经过8块GPU上3.5天的训练,我们的模型创下41.8的单模型最新BLEU分数,其训练成本仅为文献中最佳模型的零头。通过将Transformer成功应用于英语成分分析任务(无论训练数据规模大小),我们证明了该模型在其他任务中的良好泛化能力。
conclusion
在本研究中,我们提出了Transformer模型——首个完全基于注意力机制的序列转导模型,通过采用多头自注意力机制multi-headed self-attention 替代编码器-解码器encoder-decoder架构中最常用的循环层。在翻译任务中,Transformer模型的训练速度显著快于基于循环层或卷积层的架构。在 WMT2014英语-德语翻译任务和 WMT 2014英语-法语翻译任务中,我们均取得了新的技术突破。在前者任务中,我们的最优模型表现甚至超越了所有既往报道的集成模型。我们对基于注意力机制的模型未来发展充满期待,并计划将其应用于其他任务领域。我们将拓展Transformer模型的适用范围,使其能够处理文本以外的多种输入输出模态,同时研究局部受限注意力机制,以高效处理图像、音频和视频等大规模输入输出数据。降低生成过程的序列性特征,也是我们研究的重要目标之一。我们用于训练和评估模型的代码可在https://github.com/tensor2tensor上获取。
第二遍 重头读到尾,知道整个流程,每个点在干什么
引言 (Introduction)
1.1 主流模型架构
核心模型:循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)被确立为序列建模与转换任务(如语言建模、机器翻译)的前沿方法。
研究进展:后续研究通过改进循环语言模型和编码器-解码器架构,持续推动技术边界。
1.2 循环模型的计算特性
序列分解:循环模型沿输入/输出序列的符号位置分解计算,通过隐藏状态序列 建模,其中
依赖于前一状态
和当前
时刻输入。
并行化限制:固有的顺序计算特性导致训练样本内部无法并行化,在长序列场景下,存在长距离衰减问题,解码阶段,越靠后的内容,翻译效果越差。除非你把维度设置的很高,可以把每一个时间步的信息都存下来。但这样会造成内存开销很大,因内存限制进一步制约批量处理效率。
1.3 优化与挑战
效率提升:近期研究通过分解技巧和条件计算提升计算效率,但顺序计算的根本约束仍未解决。在此之前,已经成功的应用在encoder-decoder 架构中,但主要是用在如何把编码器的信息有效的传递给解码器,所以是和RNN一起使用的。
注意力机制的引入:注意力机制已成为序列模型的核心组件,可建模输入/输出序列中任意距离的依赖关系,但多数情况下需与循环网络结合使用。Transformer可以进行更多的并行化,训练时间更短但翻译效果更好。
背景
2.1 卷积模型的核心目标
减少顺序计算:扩展神经GPU、ByteNet和ConvS2S等模型以卷积神经网络(CNN)为基础构建模块,通过并行计算所有输入/输出位置的隐藏表征,旨在突破循环模型的顺序计算瓶颈。
2.2 卷积模型的计算特性
并行化优势:CNN通过滑动窗口机制实现并行处理,避免循环模型的逐位置依赖,提升计算效率。
长距离依赖挑战:
操作次数随距离增长:连接任意两个位置信号的操作次数随位置间距增大而增长:
ConvS2S模型:线性增长(O(),kk为卷积核大小);
ByteNet模型:对数增长(O(),kk为扩张卷积率)。
远距离依赖学习困难:操作次数的增长导致模型难以捕捉长序列中远距离位置间的依赖关系。
2.3 Transformer对卷积模型的改进
恒定操作次数:Transformer通过自注意力机制将任意位置间的依赖建模操作次数降至常数(O()),解决了卷积模型中操作次数随距离增长的问题。
有效分辨率补偿:尽管注意力加权平均可能降低分辨率,但通过多头注意力机制(将输入分解为多个子空间并行计算)抵消了这一影响。
关键文献对比
| 模型 | 核心组件 | 长距离依赖路径长度 | 计算复杂度 |
|---|---|---|---|
| ConvS2S | 卷积层(线性增长) | O(n) | O( |
| ByteNet[ | 扩张卷积(对数增长) | O( |
O( |
| Transformer | 自注意力(常数) | O(1) | O( |
总结
卷积模型通过并行计算提升了序列建模效率,但长距离依赖学习受限于操作次数随距离增长的特性。Transformer的自注意力机制以恒定操作次数突破了这一限制,为长序列依赖建模提供了更高效的解决方案。
但是卷积的好处是,输出可以有多个通道,每个通道可以认为是识别不同的模式,作者也想得到这种多通道输出的效果,所以提出了Multi-Head Attention多头注意力机制。(模拟卷积多通道输出效果)
Self-attention,有时称为intra-attention,是一种关联单个序列的不同位置以计算序列表示的关联机制。Transformer是第一个完全依靠self-attention,而不使用卷积或循环的的encoder-decoder 转换模型。
第三遍,逐段详读
模型体系结构:编码器-解码器框架
3.1 核心架构
主流范式:多数神经序列转导模型采用编码器-解码器结构,是机器翻译、文本生成等任务的基础框架。
编码器和解码器序列可以不一样长,且编码器可以一次看到整个序列,但是解码器是一步步输出的。
Transformer 遵循这种整体架构,对编码器和解码器使用堆叠的自注意力和逐点全连接层,分别如下图的左半部分和右半部分所示。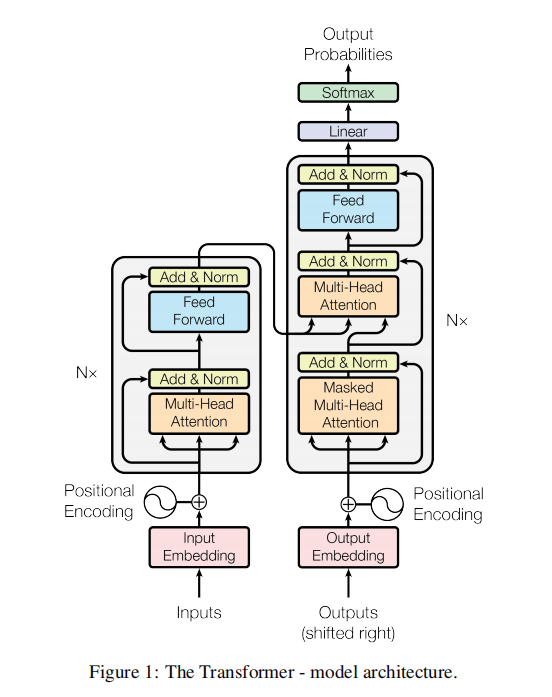
Outputs(shifted right):解码器在 时刻其实是没有输入的,其输入是编码器的输出,所以这里写的是output,shifted right就是逐个右移的意思。
Nx:模块堆叠重复N层
3.2 编码器
编码器由N=6个相同encoder层堆栈组成。每层有两个子层。
multi-head self-attention
FFNN层(前馈神经网络层,Feed Forward Neural Network),其实就是MLP,为了fancy一点,就把名字起的很长。
两个子层都使用残差连接(residual connection),然后进行层归一化(layer normalization)。
每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是当前子层的输出。
为了简单起见,模型中的所有子层以及嵌入层的向量维度都是 (如果输入输出维度不一样,残差连接就需要做投影,将其映射到统一维度)。(这和之前的CNN或MLP做法是不一样的,之前都会进行一些下采样)
这种各层统一维度使得模型比较简单,只有N和两个参数需要调。这个也影响到后面一系列网络,比如bert和GPT等等。
功能
输入映射:将离散符号序列(如单词或子词单元)() 转换为连续向量表示序列
。
核心目标:提取输入序列的上下文语义信息,为解码器提供全局语境支持。
为什么这里使用LN而不是BN?
一个横切一个竖切,方向不一样,BN计算变长序列时,变长序列后面会pad 0,这些pad部分是没有意义的,这样进行特征维度做归一化缺少实际意义。序列长度变化大时,计算出来的均值和方差不准确。
3.3 解码器
解码器同样由 N=6个相同的decoder层堆栈组成,每个层有三个子层。
Masked multi-head self-attention:在解码器里,Self-Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self-Attention 分数经过 Softmax 层之前,使用attention mask,屏蔽当前位置之后的那些位置。所以叫Masked multi-head self Attention。(对应masked位置使用一个很大的负数-inf,使得softmax之后其对应值为0)
Encoder-Decoder Attention :编码器输出最终向量,将会输入到每个解码器的Encoder-Decoder Attention层,用来帮解码器把注意力集中中输入序列的合适位置。
FFNN
与编码器类似,每个子层都使用残差连接,然后进行层归一化。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,如下图所示:
功能
序列生成:基于编码器输出 z,逐元素生成目标序列 ()。
自回归特性:生成第 i 个符号时,需将前 i−1 个已生成符号作为输入,确保序列生成的连贯性和依赖关系。
3.4 注意力机制:核心原理与实现
3.4.1 注意力函数的定义
核心功能:将查询(Query) 与一组键值对(Key-Value Pairs) 映射为输出向量,输出通过对值(Value) 的加权求和计算得出6页。
向量表示:查询(Q)、键(K)、值(V)及输出均为向量形式,其中键与值通常来自同一输入序列(如自注意力)或不同序列(如编码器-解码器注意力)。
3.4.2 标度化点积注意力(Scaled Dot-Product Attention)
计算步骤:
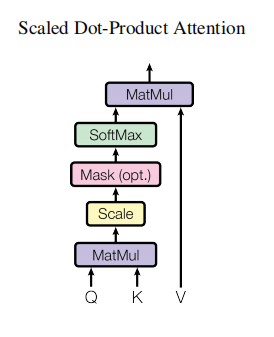
点积相似度:计算查询与所有键的点积
标度处理:将点积结果除以 (
为键向量维度),避免因高维向量导致的梯度消失问题;
权重归一化:通过Softmax函数将得分转换为权重;
加权求和:输出向量 。
3.4.3 多头注意力(Multi-Head Attention)
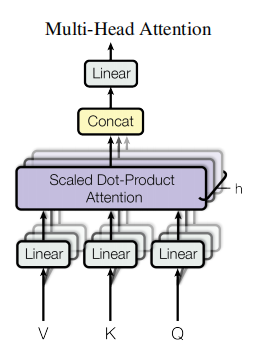
核心思想:通过多个并行的注意力头(Head)学习不同子空间的特征,增强模型对复杂依赖关系的建模能力。
实现步骤:
线性投影:将Q、K、V通过不同的线性层投影到低维空间(,
为头数);
并行计算:每个头独立执行标度化点积注意力,生成子空间输出;
拼接与投影:将所有头的输出拼接后,通过线性层映射为最终输出:
其中 为输出投影矩阵。
3.4.4 关键优势
并行化能力:注意力计算可通过矩阵运算高效并行,突破循环模型的顺序依赖限制;
长距离依赖建模:直接计算任意位置间的依赖关系,无需通过中间状态传递;
可解释性:注意力权重可直观反映输入序列中不同位置的重要性(如“making”对后续短语的依赖25页)。
3.4.5 与传统注意力的对比
| 注意力类型 | 计算方式 | 复杂度 | 优势场景 |
|---|---|---|---|
| 加法注意力(Additive) | 单隐藏层前馈网络计算兼容性 | O(d^2)O(d2) | 低维场景(d_kdk 较小时) |
| 点积注意力(Dot-Product) | 直接点积(无标度) | O(d)O(d) | 高维场景(需配合标度) |
| 标度化点积注意力 | 点积 + 1/\sqrt{d_k}1/dk | O(d)O(d) | 高维场景(避免梯度消失) |
3.4.6 与的关联注意力在Transformer中的应用
Transformer虽沿用编码器-解码器架构,但以自注意力机制彻底替代传统循环/卷积层,实现了更高效的并行计算与长距离依赖建模。其多头注意力机制通过三种方式应用:
-
多头自注意力(Multi-Head Self-Attention):用于编码器的首个子层,所有键(K)、值(V)和查询(Q)均源自编码器前一层的输出,使编码器每个位置能关注前一层的所有位置10页。
-
掩码自注意力(Masked Self-Attention):用于解码器的自注意力子层,通过掩码机制限制每个位置仅关注当前及之前的位置,防止信息左向流动,确保自回归生成特性,防止看到未来位置的信息。
-
编码器-解码器注意力(Encoder-Decoder Attention):解码器的第三个子层,查询来自前一解码器层,键和值则来自编码器输出。这使解码器每个位置能关注输入序列的所有位置,例如在英译中任务中生成“你好”‘hello world’时,解码器在输出‘你’的时候,模型会将注意力集中于源序列的“hello”,实现跨序列的语义关联。
3.5 基于位置的前馈神经网络(Position-wise Feed-Forward Networks)
编码器和解码器中的每个层都包含一个全连接的前馈网络,该前馈网络分别且相同地应用于每个位置。该前馈网络包括两个线性变换,并在两个线性变换中间有一个ReLU激活函数。
为线性层,
为激活层。
Position就是序列中每个,Position-wise 就是把MLP对每个作用一次,且作用的是同一个MLP。说白了就是单一层的MLP,只作用于最后一个维度d=512。
因为前面的注意力层以及抓取了输入序列的相关信息,并做了一次汇聚(拼接后W映射回d维)。所以attention层结果已经有了序列中我感兴趣的信息,所以后面在做MLP投影映射到想要的语义空间时,只需要对每个position单独做MLP就行。
从注意力抽取序列信息到MLP映射到需要的语义空间(非线性变换),就整个是transformer的处理信息的基础过程。
尽管两层都是线性变换,但它们在层与层之间使用不同的参数。另一种描述方式是两个内核大小为1的卷积。 输入和输出的维度都是 , 内层维度是
。(也就是第一层输入512维,输出2048维;第二层输入2048维,输出512维)
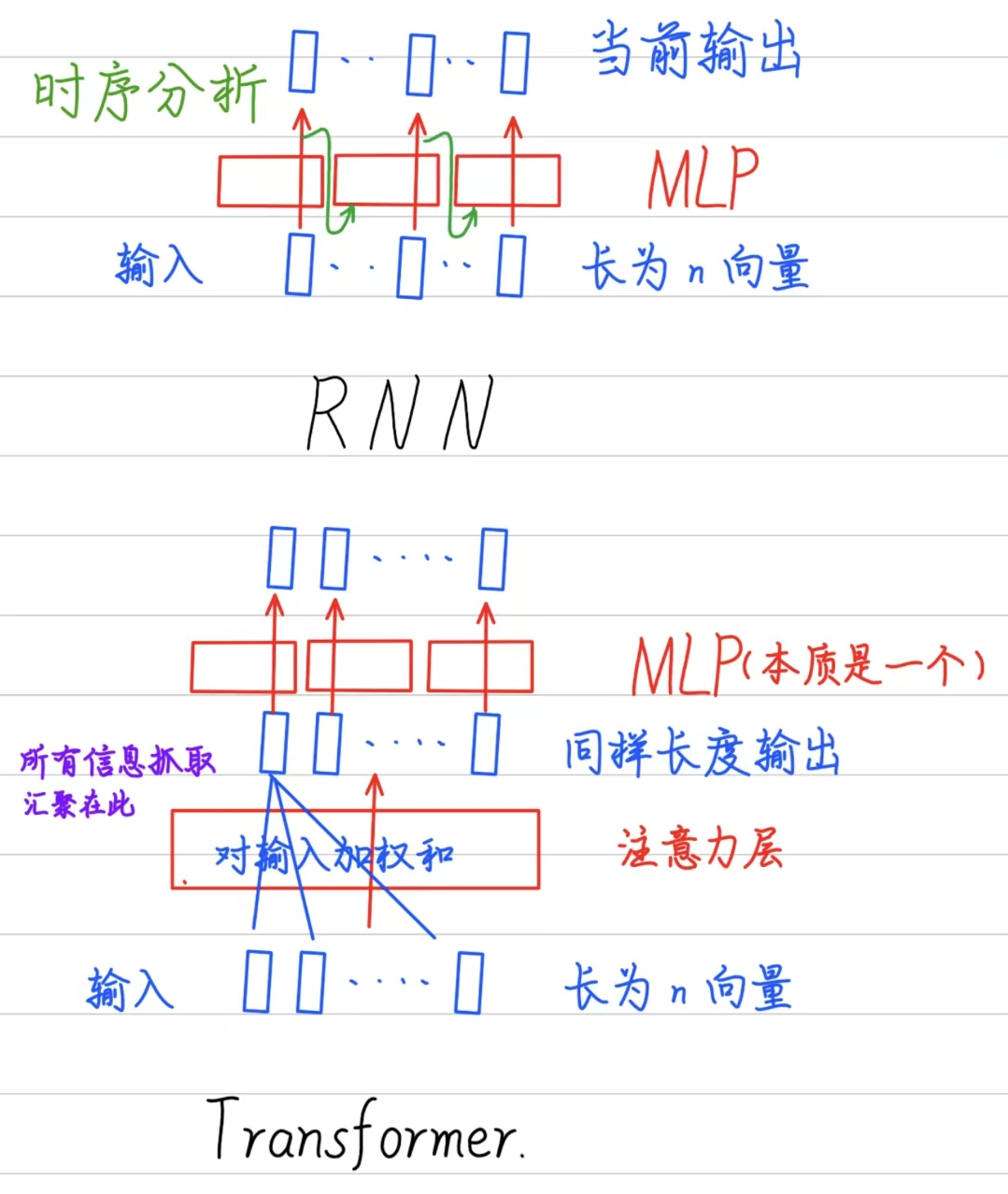
对比transformer和RNN,发现两者都是使用MLP来进行语义空间的转换,但区别是二者传递信息的方式不一样:
3.6 词嵌入和Softmax
我们使用学习到的embedding将输入和输出转换为维的向量。我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个的概率。在我们的模型中,输入输出两个嵌入层,和pre-softmax线性变换共享相同的权重矩阵(这样训练起来简单一些)。最后我们将这些权重乘以
(比如512)。
这是因为一般会把一个向量的L2Norm学到接近1,这样向量维度越大,这样学到的权重值就会很小。但是位置编码是不会这样学成L2Norm(L2范数)接近1的。所以把权重乘上
之后,token embedding和位置编码Positional Encoding才接近统一量级。(都在-1到1之间)
3.7 位置编码(Positional Encoding)
Attention计算时本身是不考虑位置信息的,这样序列顺序变化结果也是一样的。所以我们必须在序列中加入关于词符相对或者绝对位置的一些信息。
为此,我们将“位置编码”添加到mbedding中。二者维度相同(例如=512),可以相加。有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码。
在这项工作中,我们使用不同频率的正弦和余弦函数:
其中是位置,i 是维度。也就是说,位置编码的每个维度对应于一个正弦曲线。 这些波长形成一个从
到
的集合级数。我们选择这个函数是因为我们假设它会让模型很容易学习对相对位置的关注,因为对任意确定的偏移 k ,
可以表示为
的线性函数。最终编码向量每个元素值都是在-1到1之间。
此外,我们会将编码器和解码器堆栈中的embedding和位置编码的和再加一个dropout。对于基本模型,我们使用的dropout比例是
为什么使用自注意力机制
本节,我们比较self-attention与循环层和卷积层的各个方面,我们使用self-attention是考虑到解决三个问题。
每层计算的总复杂度,越少越好
顺序计算量,越少代表并行度越高。(顺序计算量就是下一步需要前面多少步计算完成)
网络中长距离依赖之间的路径长度
影响长距离依赖性能力的一个关键因素是前向和后向信号在网络中传播的路径长度。输入和输出序列中任意位置之间的这些路径越短,学习长距离依赖性就越容易。因此,我们还比较了由不同图层类型组成的网络中任意两个输入和输出位置之间的最大路径长度。
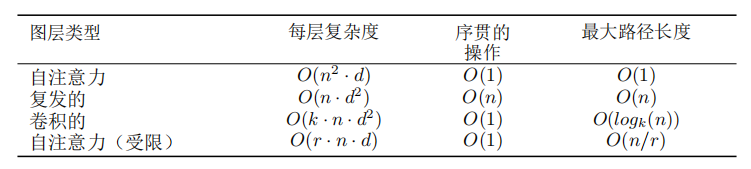
上图n是序列长度,d是维度。
Attention:
计算复杂度:矩阵Q*K,两个矩阵都是n行d列,所以相乘时复杂度是O(),其它还有一些计算量但影响不大;
顺序计算量:矩阵里面并行度是很高的,整个计算主要就是矩阵乘法,所以可以认为顺序计算量就是O(1);
最大路径长度:也就是从一个点关联到任何一个点的路径长度。attention是一次看到整个序列,所以只需要一次操作,复杂度为O(1);
k就是卷积核大小,一般是3、5之类的;而n和d现在的模型都是做到几百几千,所以可以认为前三种操作,计算复杂度差不多,但是并行度是attention和卷积更好;且attention在信息的融合上更好(最大路径长度=1)。
实际上attention对模型的假设更少,导致模型需要更多的数据和更大的模型才能训练到和RNN或CNN差不多的效果。所以现在基于transformer的模型都是很大,训练起来很贵。
2.6 示例代码
1. 缩放点积注意力 (Scaled Dot-Product Attention)
这是模型的心脏,通过计算 和
的点积并进行缩放,再经过 Softmax 得到权重,最后作用于
。
import torch
import torch.nn as nn
import numpy as np
def scaled_dot_product_attention(query, key, value, mask=None):
# d_k 是查询向量的维度 [cite: 462]
d_k = query.size(-1)
# 计算点积并缩放 [cite: 465]
scores = torch.matmul(query, key.transpose(-2, -1)) / np.sqrt(d_k)
# 如果有掩码(如在解码器中防止关注未来标记)[cite: 435, 493]
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# Softmax 归一化 [cite: 463]
attention_weights = torch.softmax(scores, dim=-1)
return torch.matmul(attention_weights, value), attention_weights2. 多头注意力 (Multi-Head Attention)
论文发现将维度 拆分为
个头并行处理,可以捕捉不同子空间的特征 。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, h=8): # 论文基准参数 [cite: 431, 482]
super().__init__()
self.h = h
self.d_k = d_model // h
# 定义线性投影矩阵 [cite: 473, 481]
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 1. 线性投影并拆分为多头
query = self.w_q(q).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
key = self.w_k(k).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
value = self.w_v(v).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
# 2. 应用缩放点积注意力 [cite: 474]
x, _ = scaled_dot_product_attention(query, key, value, mask)
# 3. 拼接头并过最后一个线性层 [cite: 477, 480]
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.fc(x)3. 逐位置前馈网络 (FFN)
每个编码器和解码器层都包含一个全连接的前馈网络,由两个线性变换和一个 ReLU 激活组成 。
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model=512, d_ff=2048): # 论文基准参数 [cite: 501]
super().__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
# FFN(x) = max(0, xW1 + b1)W2 + b2 [cite: 498]
return self.fc2(self.relu(self.fc1(x)))
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)