扩散模型(Diffusion Models)
规定一个“把图像逐步加噪”的前向过程 q,再学习一个“把噪声逐步还原成图像”的逆向过程 pθ。
前向过程 q 是固定的,不训练。前向过程 pθ 是固定的,不训练。因此扩散模型真正学的是一个逆向链。
前向过程
前向扩散过程,也叫加噪过程:
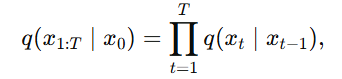
前向过程的条件联合分布 q(x1:T∣x0) 意思是:给定一张干净图像 x0,如果按照规定的加噪规则一步一步走,那么整条加噪路径出现的概率是多少。
![]()
意思是:给定 xt−1,下一步 xt 是在“缩小一点原信号”的同时,再加一层高斯噪声得到的。把这个高斯写成采样形式会更直观:
![]()
第一个动作是保留上一时刻的内容,但乘了一个小于 1 的系数,因此图像中的原始信号会逐步衰减。第二个动作是加入新的高斯噪声,强度由 βt 控制。
这里为什么写成乘积,是因为前向过程被假设成一个马尔可夫链:每一步只依赖前一步。也就是
![]()
因为一旦有马尔可夫结构,整条联合链就可以分解成相邻转移的乘积。
逆向过程
扩散模型(Diffusion Models)是一类隐变量模型,由参数 θ 表示,其形式为:
![]()
- x0 原始数据(比如图像、实体表示)
- x0:T 表示一整条序列:(x0,x1,x2,...,xT)。x1,…,xT 是输入图像 x0 的逐步加噪版本
- pθ(x0:T) 模型定义的联合概率分布,也就是模型认为 “从最初图像 x0 到所有中间噪声状态 x1,…,xT 同时出现”的概率密度。
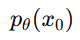 是我们最终关心的图像分布。因为生成任务最后只要生成一张图像 x0,不需要把整条中间轨迹都展示出来,所以要把中间变量 x1,…,xT全部边缘化掉,也就是积分掉。
是我们最终关心的图像分布。因为生成任务最后只要生成一张图像 x0,不需要把整条中间轨迹都展示出来,所以要把中间变量 x1,…,xT全部边缘化掉,也就是积分掉。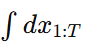 对所有中间变量积分消掉它们。
对所有中间变量积分消掉它们。
其中 x1,…,xT 是输入图像 x0 的逐步加噪版本(我们通过对所有中间变量 x1∼xT 积分,得到数据 x0 的概率分布。),注意:所有变量(包括噪声变量)与原图像的维度是相同的。这个计算![]() 的过程叫做 前向过程(diffusion process),它被建模为一个马尔可夫链,逐步加入高斯噪声。
的过程叫做 前向过程(diffusion process),它被建模为一个马尔可夫链,逐步加入高斯噪声。
就是把所有可能通向这个 x0 的路径的概率密度全部加总起来。因为这些变量是连续的,所以这里不是求和,而是积分。
扩散模型并不是“直接”生成 x0。它实际上描述的是一条完整的生成链。也就是说,模型更本质地定义了![]() ,然后你把中间那些潜变量都积分掉,最终得到对真实图像的分布
,然后你把中间那些潜变量都积分掉,最终得到对真实图像的分布![]() 。
。
理解马尔可夫性质
假设只有三个变量 x0,x1,x2,
①任何联合分布都成立的链式分解。
x0,x1,x2的联合分布按概率链式法则写成:
![]()
然后对 x1,x2 做边缘化(把联合分布里不关心的变量 x1,x2 积分掉,只留下 x0 的分布。)得到:
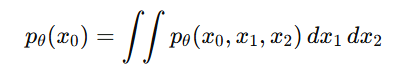
也就是:
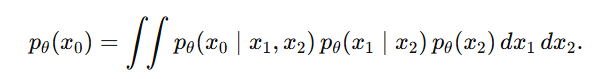
②额外加入马尔可夫结构之后的简化。
若进一步假设逆向过程满足马尔可夫性质 :
![]()
则有:
![]()
因此:
![]()
从而
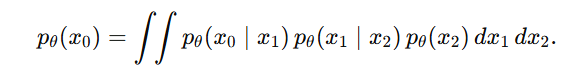
所以:
![]()
![]()
逆向过程满足马尔可夫性质有什么用?
如果逆向过程满足马尔可夫性质,那么联合分布就能写成
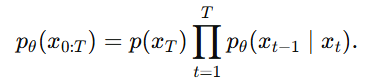
它把一个复杂的高维联合分布,拆成了一串局部条件分布。
没有马尔可夫性质时,逆向一步可能要写成:
![]()
意思是:要生成 xt−1,不仅要看当前的 xt,还要看后面所有更噪的状态。
这会让模型非常复杂,因为每一步都依赖整段未来轨迹。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)