当所有大模型都开始“吃“PDF,谁才能真正读懂它?
——OpenAI、Gemini、Claude、Mistral 的文档解析能力横评,以及为什么专业工具还没被取代
一、一场突然涌现的"文档解析大战"
2025 年开始,主流大模型厂商几乎同时发力文档解析:
-
OpenAI:Responses API 和 Chat Completions API 直接支持 PDF 文件输入,模型自动提取文本+图像
-
Google Gemini:原生视觉处理 PDF,支持最多 3600 页,可输出结构化 JSON
-
Anthropic Claude:支持直接上传 PDF,处理图文混合文档
-
Mistral:发布独立的 mistral-ocr-latest 模型,专攻 OCR,支持 PDF/PPTX/DOCX,声称准确率 95%+
听起来很美好——随便找个大模型 API,扔进去一个 PDF,就能提取内容了。
但这件事,真的没那么简单。
二、先搞懂一件事:PDF 本身是个坑
很多人不知道,PDF 的本质是一张设计图纸,不是文档。
它存储的是:每个字符的 坐标、字体、大小,而不是"这段是标题、这块是表格、这里是公式"。
所以:
-
视觉上整齐的表格 → 底层可能是一堆坐标对齐的碎字符
-
多栏文字 → 提取出来可能是乱序的
-
扫描版 PDF → 根本没有文本层,只是一张图
-
数学公式 → 以特殊字体存储,极易变成乱码
这就是为什么即便再强的 AI,在文档解析上也会翻车。
三、主流大模型的解析能力横评
OpenAI Responses API
怎么用:
from openai import OpenAI
import base64
client = OpenAI()
# 方式一:上传文件获取 file_id
with open("report.pdf", "rb") as f:
file = client.files.create(file=f, purpose="user_data")
response = client.responses.create(
model="gpt-4o",
input=[{
"role": "user",
"content": [
{"type": "input_file", "file_id": file.id},
{"type": "input_text", "text": "请提取文档中所有表格数据,输出为 JSON"}
]
}]
)
print(response.output_text)实际表现:
-
✅ 集成简单,适合快速做文档问答
-
⚠️ 表格提取不稳定,单元格内容会串行
-
❌ 存在静默截断——文档内容超过约 30-60KB 后,模型不报错,但实际上没读完(社区已多次反馈)
-
❌ 仅支持 PDF,不支持 DOCX/PPTX/XLSX
-
Google Gemini
怎么用:
-
import google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") # 上传 PDF uploaded_file = genai.upload_file("financial_report.pdf", mime_type="application/pdf") model = genai.GenerativeModel("gemini-1.5-pro") response = model.generate_content([ uploaded_file, "提取文档中的所有财务指标,输出为结构化 JSON" ]) print(response.text)实际表现:
-
✅ 支持最多 3600 页,是目前上限最高的
-
✅ 可以直接输出结构化 JSON(配合 response_mime_type)
-
⚠️ 处理中文复杂排版时容易丢失层级结构
-
⚠️ 公式识别依赖视觉能力,LaTeX 输出质量不稳定
-
❌ 每次调用都重新解析,没有缓存,成本随文档大小线性增长
Anthropic Claude
import anthropic
import base64
client = anthropic.Anthropic()
with open("contract.pdf", "rb") as f:
pdf_data = base64.standard_b64encode(f.read()).decode("utf-8")
response = client.messages.create(
model="claude-opus-4-5",
max_tokens=4096,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_data
}
},
{"type": "text", "text": "提取合同中的关键条款,列出甲乙双方义务"}
]
}]
)
print(response.content[0].text)实际表现:
-
✅ 理解长文档的语义能力强,适合合同/报告摘要
-
✅ 处理非结构化文档时效果相对稳定
-
⚠️ 精确的表格提取(要求字段一一对应)容易出错
-
❌ 同样存在大文档截断问题
-
❌ 无法直接输出 Markdown 结构化文档
Mistral OCR(最接近"专业解析"的大模型方案)
这个值得单独说。Mistral 没有把文档解析塞进通用对话 API,而是独立开了一个 OCR 端点:
import os
from mistralai import Mistral
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# 直接传 URL
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": "https://arxiv.org/pdf/2201.04234"
},
include_image_base64=True
)
# 输出结构化 Markdown
for page in ocr_response.pages:
print(f"--- 第 {page.index + 1} 页 ---")
print(page.markdown)实际表现:
-
✅ 输出是干净的 Markdown,不是"模型的理解",是真实的文档结构
-
✅ 支持 PDF、PPTX、DOCX,格式最全
-
✅ 表格、公式处理相对稳定,官方声称准确率 95%+
-
⚠️ 对中文复杂排版的支持还在完善中
-
❌ 付费 API,成本不低
四、大模型解析的本质局限
把上面四个对比完,你会发现一个规律:
越是通用的大模型,文档解析越像"理解文档"而不是"解析文档"。
这不是坏事——但它意味着: -
输出是模型的解释,不是文档的原始结构
-
同一个文档,两次调用可能得到不同的输出
-
文档中的"错误"(乱码、扫描噪声)可能被模型"脑补"填补,看起来对但实际上是幻觉
-
对于 RAG、知识库构建、批量文档入库这类场景,你需要的是确定性,不是智能猜测。
五、MinerU:做"解析"这件事,不做"理解"
MinerU 是上海 AI 实验室 OpenDataLab 团队开源的文档解析工具(GitHub 20K+ star),设计哲学和上面所有大模型都不同——它不回答问题,它只把文档变成干净的结构化数据。
-
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader from magic_pdf.data.dataset import PymuDocDataset from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze from magic_pdf.config.enums import SupportedPdfParseMethod 读取 PDF reader = FileBasedDataReader("") pdf_bytes = reader.read("research_paper.pdf") 解析 ds = PymuDocDataset(pdf_bytes) infer_result = ds.apply(doc_analyze, ocr=False) 输出 Markdown md_writer = FileBasedDataWriter("output/") pipe_result = infer_result.pipe_txt_mode(md_writer) pipe_result.dump_md(md_writer, "output.md", "images/") **命令行(最简单):** bash 单文件 mineru -p research_paper.pdf -o ./output 批量处理整个文件夹 mineru -p ./papers/ -o ./output_all 强制 OCR 模式(扫描版文档) mineru -p scanned_doc.pdf -o ./output -m ocr **输出效果:** output/ ├── research_paper.md # 干净的 Markdown 正文 ├── research_paper_content_list.json # 结构化 JSON(标题/段落/表格/图片) └── images/ # 提取的图片 ├── figure_1.png └── table_1.html # 复杂表格以 HTML 形式保存接入 RAG(LangChain 一行搞定)
python from langchain_mineru import MinerULoader loader = MinerULoader("company_report.pdf") documents = loader.load() documents 已经是干净的 Document 对象,直接喂给向量库 from langchain_community.vectorstores import Chroma vectorstore = Chroma.from_documents(documents, embedding)MinerU 解析的核心优势
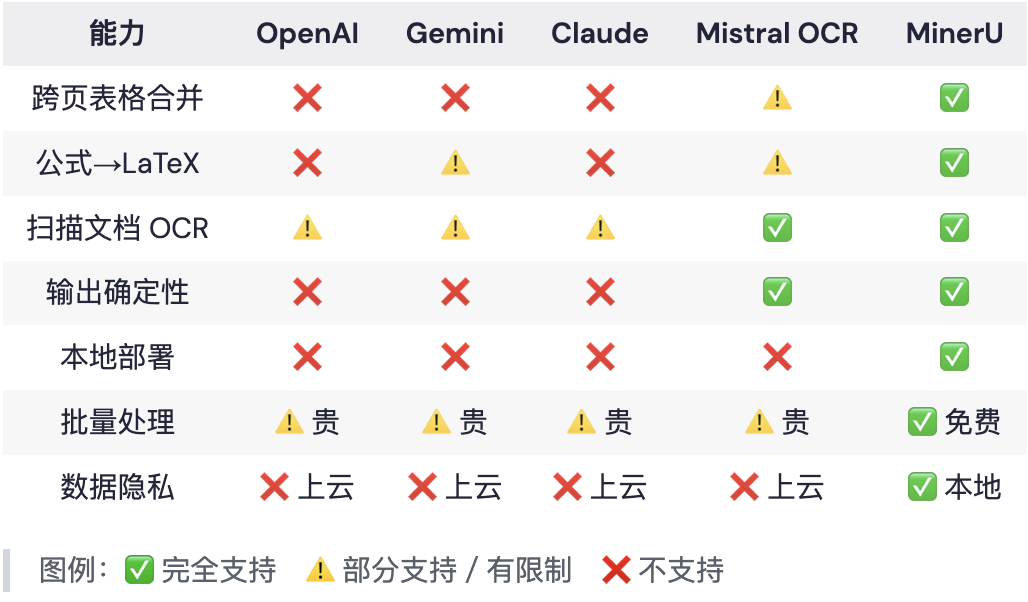
六、最佳实践:组合用,不要二选一
其实最好的文档 AI 管道,不是非此即彼的选择,而是:
原始 PDF
↓
MinerU 解析(结构化,确定性)
↓
干净的 Markdown / JSON
↓
GPT-4o / Gemini / Claude(语义理解,回答问题)
↓
用户得到高质量答案
用专业工具做解析,用大模型做理解。两者分工,各司其职。
这才是 2026 年以后做文档 AI 的正确姿势。
> MinerU 开源地址:github.com/opendatalab/MinerU
> Apache 2.0 协议,免费商用,支持本地部署,GitHub 60K+ star

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)