每天15分钟 15 天带你学会 AI 智能体开发(一):LangChain 入门
我看过很多 LangChain 教程,大多数上来就是"什么是 Agent"“什么是 RAG”,看完脑子里全是词,手上什么都没有。这篇换个方式——先跑起来,再慢慢理解。
为什么要学这个?
说个真实场景:同事最近在搭一个内部文档问答工具,想让员工直接问问题,系统自动去公司 Wiki 里找答案返回。他第一反应是直接调 OpenAI API,写了两天,光是"怎么把对话历史塞进去"“怎么限制输出格式”"怎么接搜索"就搞得焦头烂额。
后来换成 LangChain,核心逻辑三天搞完。
这就是 LangChain 存在的理由。它不是让模型变更聪明,而是帮你把模型和你的业务逻辑接起来,省掉大量重复的胶水代码。如果你写过 Web,可以这样理解它:
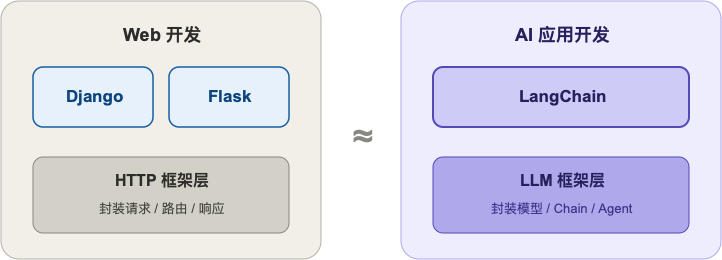
就像 Django / Flask 不会让 HTTP 协议变快,但它们让你写 Web 应用快很多——LangChain 是这个意思。
装好就出发
两行搞定:
pip install langchain langchain-openai
然后把 API Key 设进环境变量。先用最粗暴的方式:
import os
os.environ["OPENAI_API_KEY"] = "sk-..."
正经项目里别这么干,key 会被 git 提交进去。推荐新建一个 .env 文件放 key,用 python-dotenv 加载,.gitignore 里加上 .env,一劳永逸。
先跑起来再说
最简单的一句话
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
response = llm.invoke("用一句话解释什么是LangChain")
print(response.content)
LangChain 是一个帮助开发者将大型语言模型与外部数据和工具集成,快速构建 AI 应用的开发框架。
跑通了吧?就这么多。ChatOpenAI() 默认用 gpt-3.5-turbo,invoke() 就是"喂进去,拿出来"。返回的不是字符串,是一个 AIMessage 对象,文字内容在 .content 里。
加上 PromptTemplate——更正经的写法
上面那种写法,prompt 是硬编码的字符串,换个话题就得改代码。实际项目里你会想要这样:
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
prompt = PromptTemplate.from_template("请用简单语言解释:{topic}")
llm = ChatOpenAI()
chain = prompt | llm
result = chain.invoke({"topic": "LangChain"})
print(result.content)
LangChain 就像一套乐高积木,让你把大语言模型和各种工具拼接起来,
快速搭建 AI 应用,而不用从零写所有逻辑。
注意这里出现了一个奇怪的符号——|。这个竖线不是"或",它是 LangChain 的管道操作符,意思是"把左边的输出传给右边"。prompt | llm 就是:先用 prompt 渲染出字符串,再把字符串喂给模型。
翻译助手:五行真正有用的代码
prompt = PromptTemplate.from_template("把下面内容翻译成英文:{text}")
chain = prompt | llm
print(chain.invoke({"text": "我喜欢编程"}).content)
I love programming.
这三段代码其实已经展示了 LangChain 最核心的用法。接下来拆解一下你刚写的东西。
理解你刚写的代码
数据怎么流动的
你可能注意到,输入是个 dict,输出是个 AIMessage,中间发生了什么?
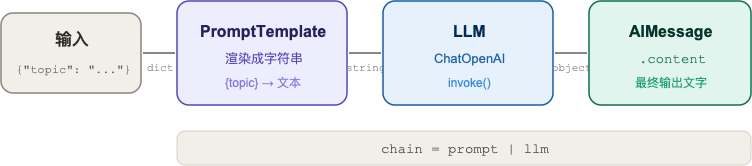
整条链走下来就这四步。PromptTemplate 把 dict 里的变量填进模板,变成一个字符串;字符串进 ChatOpenAI,出来一个 AIMessage;你用 .content 取里面的文字。
这个"数据从左到右流过各个组件"的机制,就是 LCEL(LangChain Expression Language)。| 就是它的管道符,跟 Unix 命令行里 cat file.txt | grep keyword 是一个思路。
三个组件,一张图说清楚
LangChain 的组件其实不多,刚上手只需要认识三个:
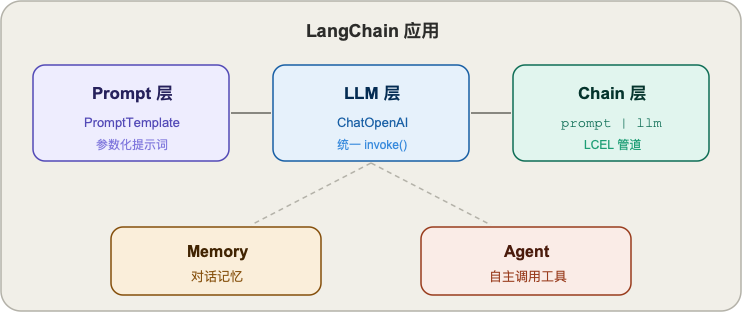
- Prompt 层:管"怎么问"。
PromptTemplate就是一个带变量的字符串模板,复用、参数化,比手拼字符串优雅得多。 - LLM 层:管"谁来回答"。今天是 OpenAI,明天换 Claude,后天换本地模型,对上层代码完全透明,接口都是
invoke()。 - Chain 层:管"怎么串起来"。用
|把 Prompt 和 LLM 接在一起,就是最基础的一条 Chain。
复杂一点的链可以无限叠加:
chain = prompt | llm # 基础:问答
chain = prompt | llm | parser # 加解析:结构化输出
chain = retriever | prompt | llm # 加检索:RAG 问答
能做什么
就我见过的用法,按难度从低到高:
| 场景 | 大概怎么做 |
|---|---|
| 简单问答 bot | prompt + llm,五分钟搞完 |
| 有记忆的对话 | 加上 Memory 组件 |
| 文档问答(RAG) | 加 retriever,先检索再回答 |
| 能调工具的 Agent | 给模型配工具,让它自己决定用哪个 |
从上往下,每一层都是在前一层基础上加一个东西,不是从零重写。这是 LangChain 模块化设计的好处。
下一步去哪
入门之后最值得看的三个方向,这里只点一下,后续章节展开讲:
Memory:你现在写的代码,每次 invoke() 都是独立的,模型不记得上轮说过什么。Memory 组件解决这个问题,让对话"活"起来。
Agent:想让模型帮你查天气、算数字、调 API?这就需要 Agent——给模型配上"工具箱",让它自己决定用哪个工具、用几次。这是从"聊天机器人"进化成"能干活的助手"的关键一步。
RAG:模型不知道你公司内部的事,也不知道上周发生了什么。RAG 的思路是:先用搜索把相关内容捞出来,再连同问题一起交给模型。这样它就能回答"我们 Q3 的 OKR 是什么"这类问题,而不是瞎编。
下一篇:给你的对话 bot 加上记忆——Memory 组件完整上手指南
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)