MySQL索引优化快速入门
这里需要知道什么是B+树
从数据结构角度简单分析:
二叉树和B树可以简单理解为通过二分法减少查询的次数,但是仍存在严重的性能问题
1,插入顺序不对时,会退化为链表,时间复杂度由O(logn)变成O(n)。
2. 大数据情况下,查询性能低
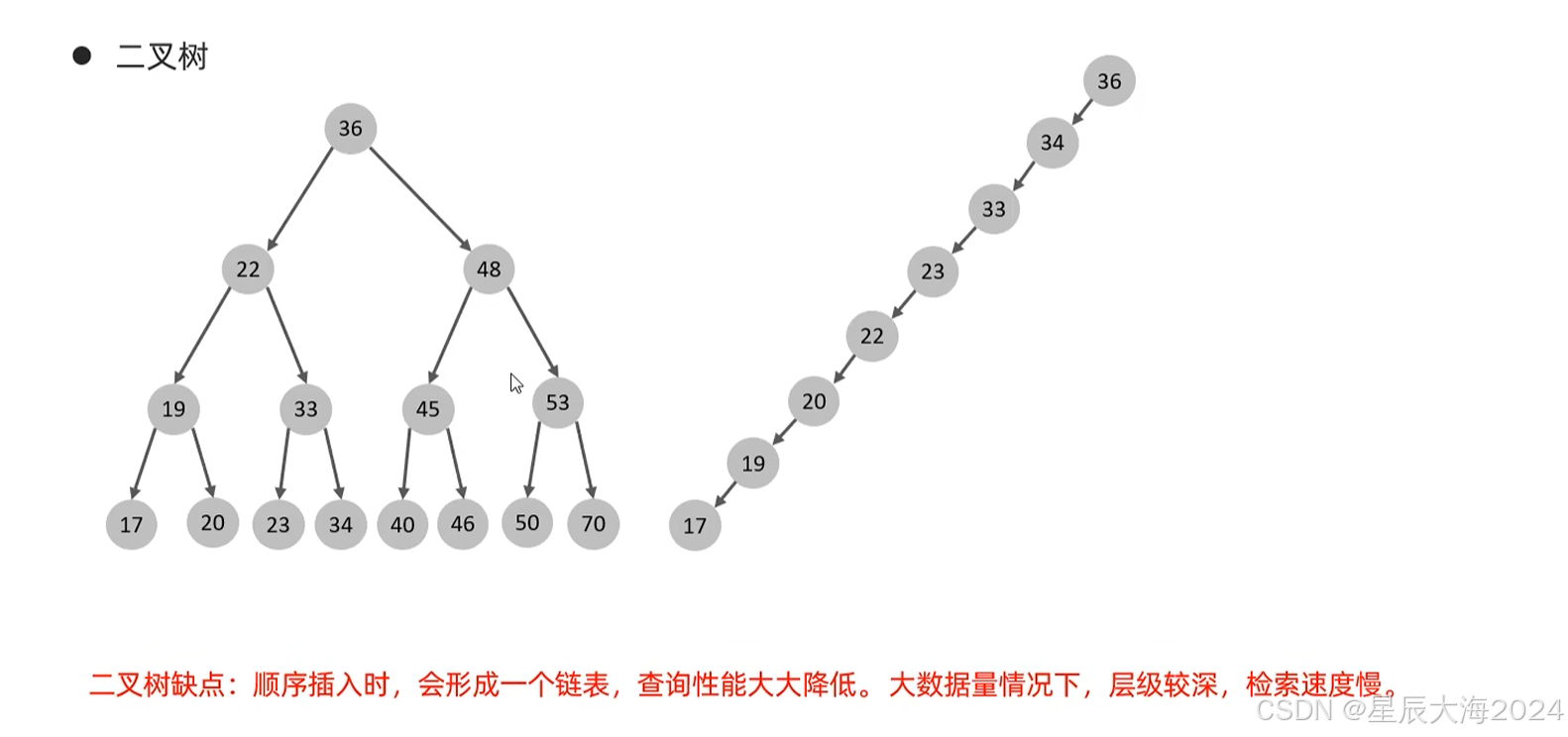
为了解决以上问题,选择B树
如何解决
自动平衡机制
B-tree与B+树在插入和删除时会执行自动平衡算法。删除导致节点键值对数不足时,会触发合并或重新分配操作(页合并和借键)。
度数为n的b+树,每个节点(每个页)最大容纳n-1的键值对,在子节点达到n-1对时,中间的键值对会复制一份到父节点,该子节点分裂为两个子节点。
阶数为5
[25] ← 父节点(提升的键)
/ \
[10, 20] [25,30, 40] ← 两个叶子
这些算法保证整棵树的平衡性,防止出现性能退化情况。平衡操作的时间复杂度同样维持在O(log n)级别。
。
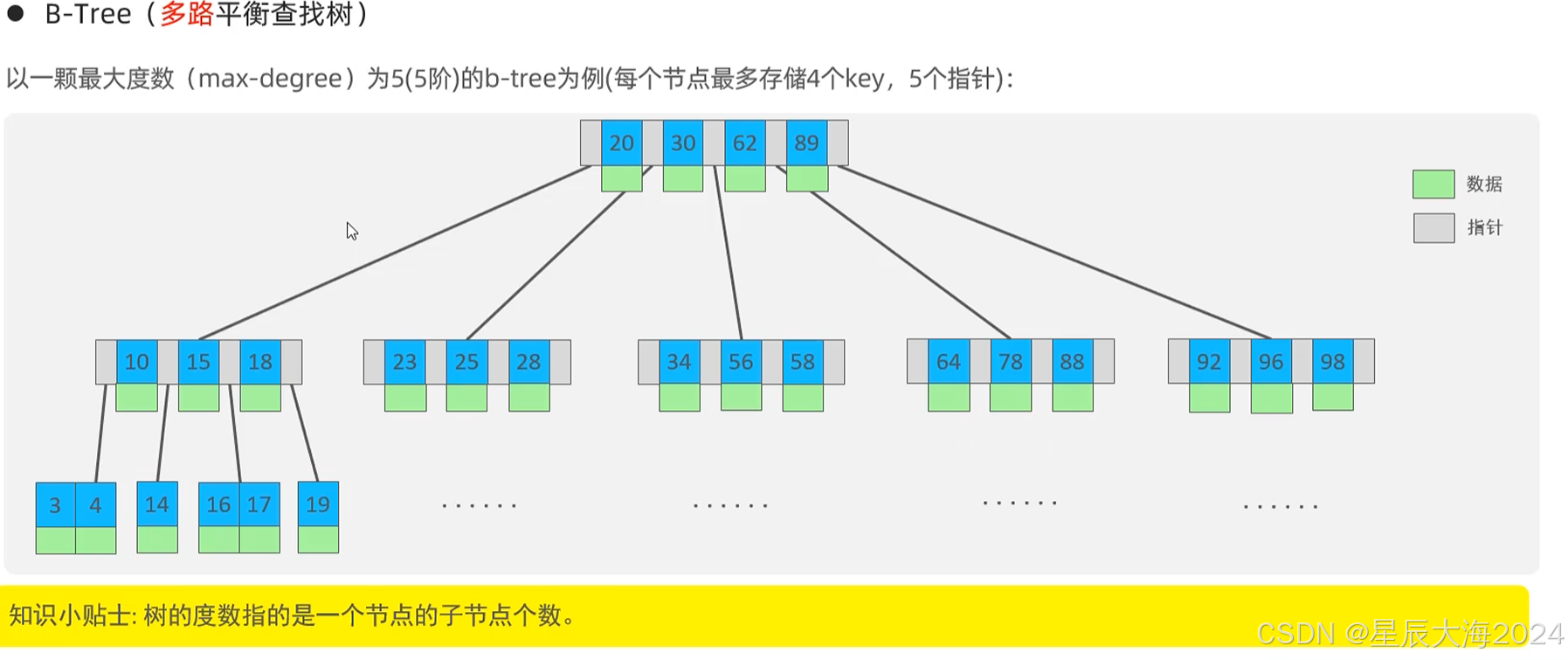
仍存在以下问题:
范围查询性能低
大数据情况,树的高度过高,查询次数过多
为了解决以上问题,MySQL InnoDB选择B+树
如何解决
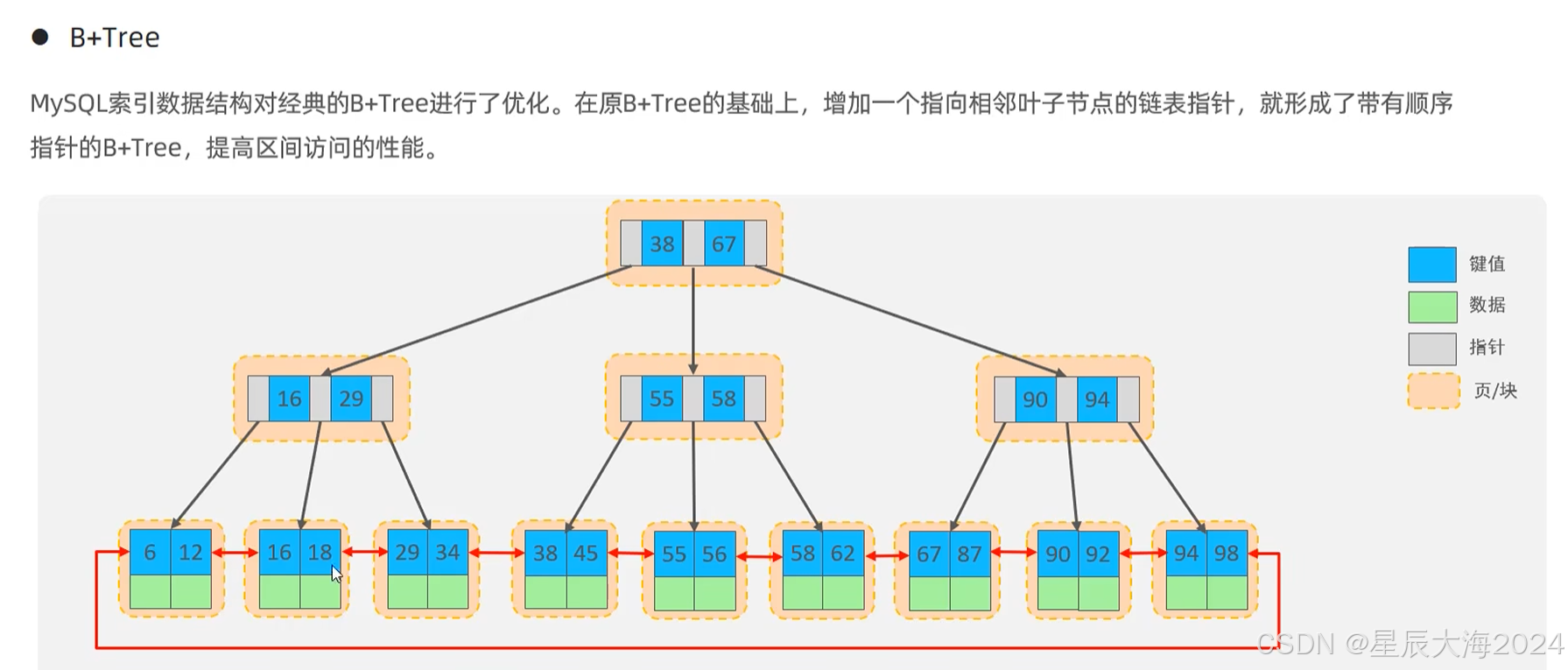
叶子节点双向链表连接
所有叶子节点通过双向链表连接,形成有序序列。这种结构保证范围查询的高效性,无论插入顺序如何,只需遍历链表即可获取有序数据。链表连接方式使得B+树在保持平衡的同时,支持高效的范围操作。
非叶节点仅做key的区分
B+树的非叶子节点不存储实际数据,因此单个节点(单个页)可以容纳更多键。该特性显著降低树的高度,例如在千万级数据量下,B+树可能仅需3-4层。这种特性确保大数据量下的查询性能稳定。
一、索引
索引结构
索引的核心定义
- 索引是MySQL在存储引擎层为字段构建的B+树数据结构,用于快速定位符合条件的数据行,减少磁盘IO。
2. 基础索引类型
|
索引类型 |
核心特点 |
适用场景 |
|
主键索引 |
唯一、非空,一张表仅1个,聚簇索引 |
主键查询(WHERE id=1) |
|
唯一索引 |
字段值唯一(允许NULL),一张表可多个 |
唯一字段查询(如手机号phone) |
|
普通索引 |
无唯一性约束,最常用 |
普通查询字段(如age、name) |
|
联合索引 |
多个字段组合的索引 |
多字段查询(如age+name) |
|
覆盖索引 |
索引包含查询所需所有字段 |
避免回表(如SELECT id,age FROM user WHERE age=20,(age,id)索引覆盖) |
3. 什么是回表
聚簇索引是实际存储表数据的结构
每个主键下存储该row的数据
非聚簇索引以字段为key,主键为value
在查询时,先查询出主键再到聚簇索引中查询出该主键下的row数据,这个过程叫做回表
回表
select * from tb_user where age=20;不回表
select id,age from tb_user where age=20;4. 索引底层:为什么用B+树?(基础理解)
- B+树是“平衡多路查找树”,所有数据存在叶子节点,且叶子节点按顺序链表连接;
- 对比其他结构优势:
- 比二叉树:层级少(百万数据仅3-4层),查询更快;
- 比哈希索引:支持范围查询(如age>20),哈希仅支持等值查询。
5. 什么是最左前缀法则
查询条件必须从联合索引的最左侧列开始,并且不能跳过任何字段,否则索引部分生效,最坏情况完全失效。
对于联合索引 (name, age, city):
- 索引生效:
SELECT * FROM tb_user WHERE name='Alice' AND age=25;- 索引部分失效:(
city无法利用索引)
SELECT * FROM tb_user WHERE name='Alice' AND city='Beijing'- 索引完全失效: 全表扫描(Full Table Scan) 性能最差
SELECT * FROM tb_user WHERE age=13
SELECT * FROM tb_user WHERE city="北京"6. 索引失效核心场景
- 索引列做运算/函数:age+1=20、YEAR(create_time)=2024;
select id,age from tb_user where age+1=20;- 存在隐式类型转换:WHERE phone=13800138000(phone是var类型);
select id,phone from tb_user where phone=12334567;- 联合索引不满足“最左前缀”:(age,name)索引,仅查name='张三';
select id,name from tb_user where name="张三";- LIKE后置模糊匹配:name LIKE '%张'(前缀匹配 张% 生效);
select id,name from tb_user where name like "%张";- OR条件含非索引列:age=20 OR address='北京'(address无索引)。
select id,age,address from tb_user where age=20 OR address='北京';7. 索引设计基础原则
首先:通过该命令查看当前数据库各语句的访问频次
SHOW GLOBAL STATUS LIKE 'Com_______';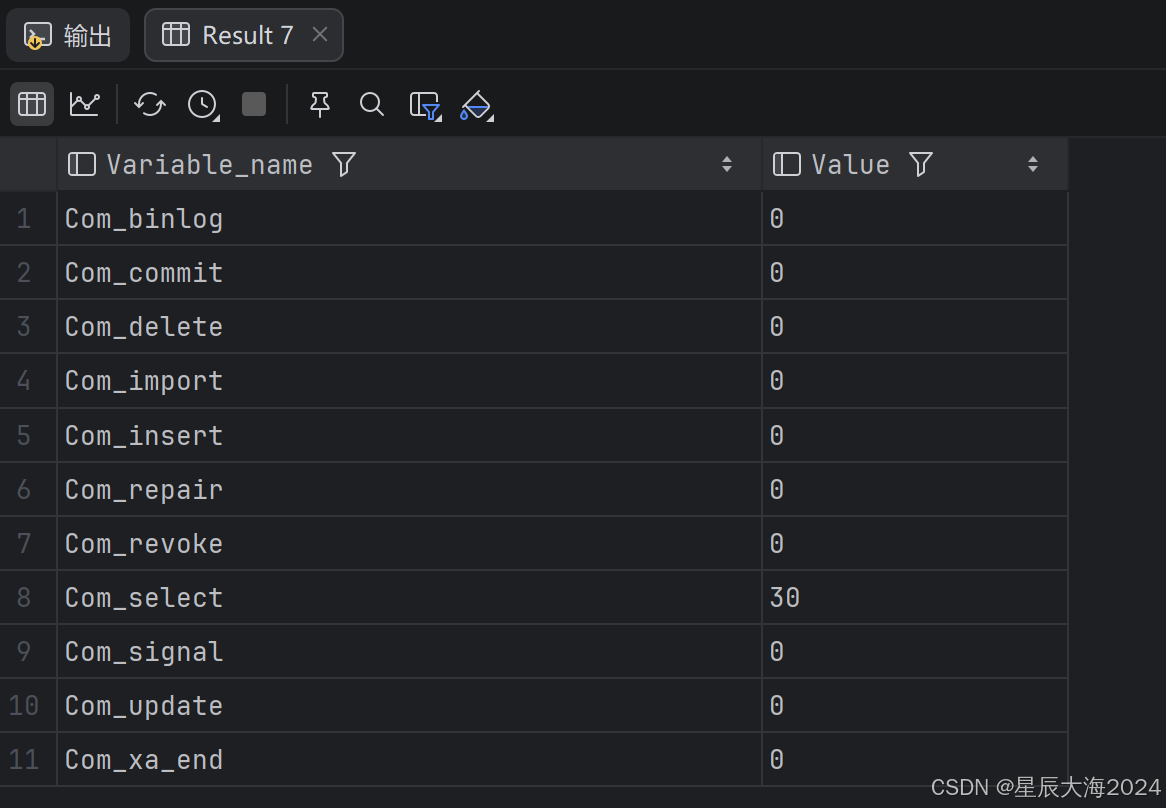
一般只为select语句进行优化(select语句要占比高),select/select+insert+update+delete
- 只为“高频查询字段”建索引(WHERE/ORDER BY/GROUP BY字段);

- 联合索引:高频字段放左、区分度高的字段放左(如phone> age);
- 避免冗余索引(如已有(age,name),无需再建age索引)。
索引下推(ICP)基础
语句:
select * from tb_user where age>20 and reward=200;范围查询让联合索引(age,reward)中的reward部分失效,从“B+ 树二分查找”退化成“叶子双向链表顺序扫描 + ICP 过滤”。 非叶子节点的快速定位能力只用到 age 定位起点,后面的 reward 完全靠过滤,不再参与树遍历。
核心定义
索引下推全称 Index Condition Pushdown(ICP),是索引优化机制:在使用联合索引查询时,将原本由 MySQL 服务器层执行的「索引字段过滤逻辑」,下推到存储引擎层完成,减少回表次数和数据传输量,提升查询效率。
核心作用
- 减少回表 IO:存储引擎层先过滤不符合条件的索引记录,仅将符合条件的记录主键返回给服务器层,再回表查询完整数据;
- 降低服务器层开销:避免服务器层处理大量无效的索引记录,减少 CPU 计算成本;
- 对联合索引的长尾条件过滤效果显著。
总结
- 适用场景:仅针对非主键的联合索引,且过滤条件是索引中包含的字段(如上面的
reward是联合索引的一部分); - 识别方式:
EXPLAIN的Extra字段显示Using index condition,表示触发了索引下推;
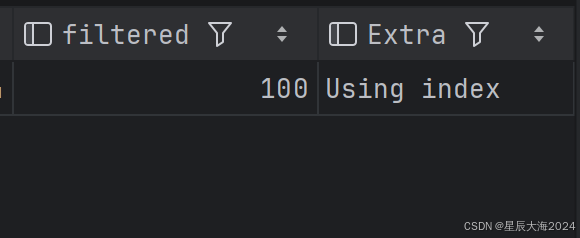
- 与覆盖索引的区别:覆盖索引是「完全不回表」(索引包含所有查询字段),索引下推是「减少回表行数」(仍需回表,只是回表数据更少)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)