基于LSTM-XGBoost模型的电力负荷预测分析
基于LSTM-XGBoost模型的电力负荷预测分析
项目简介
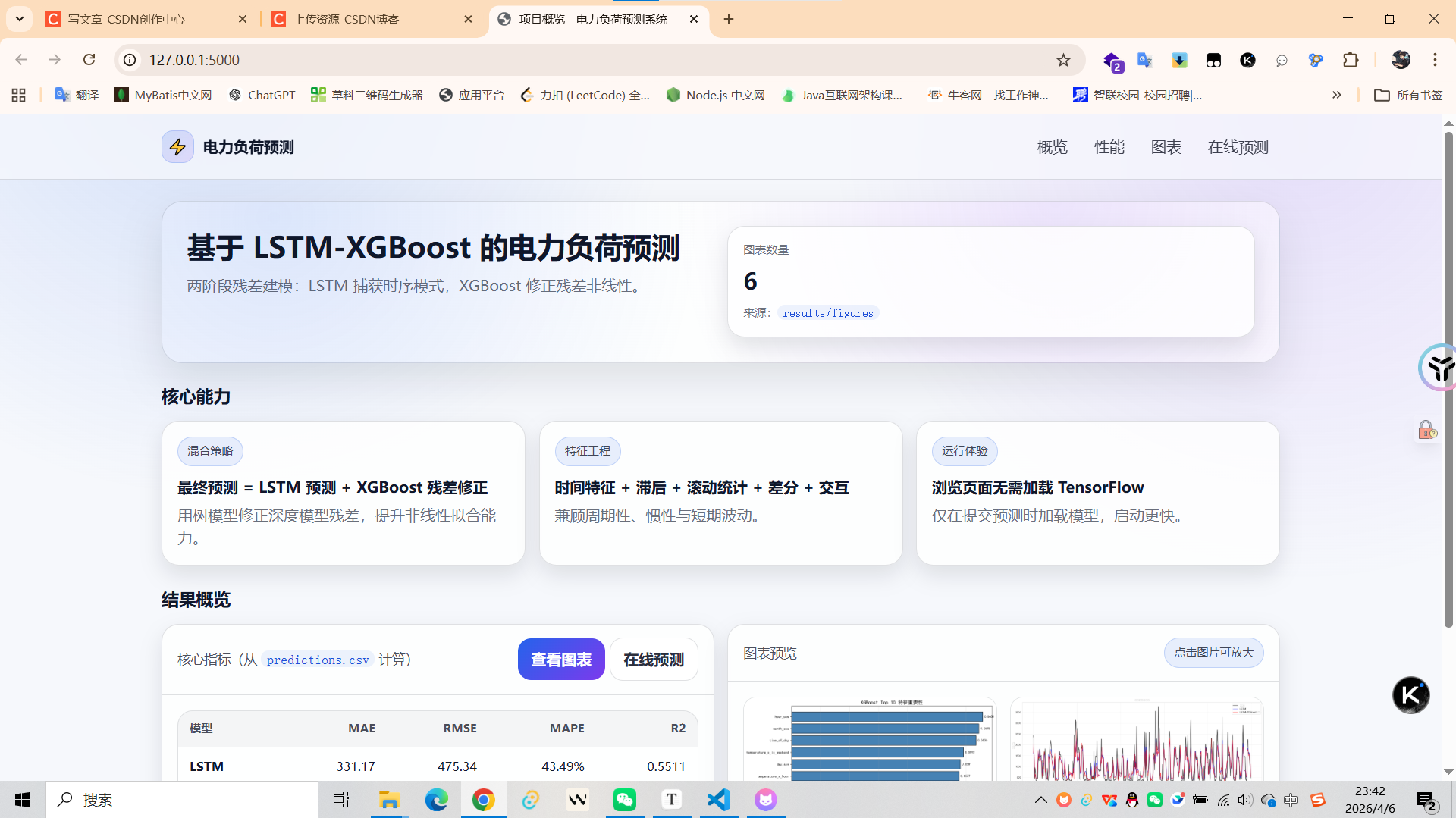
本项目是一个基于深度学习和机器学习混合模型的电力负荷预测系统。采用LSTM捕捉时序特征,使用XGBoost对残差进行建模,在UCI真实数据集上实现了MAPE降低8.07%的效果。
项目特点
-
混合模型架构:LSTM(128→64) + XGBoost(200树)
-
真实数据:UCI Household Power Consumption数据集(34,168条记录)
-
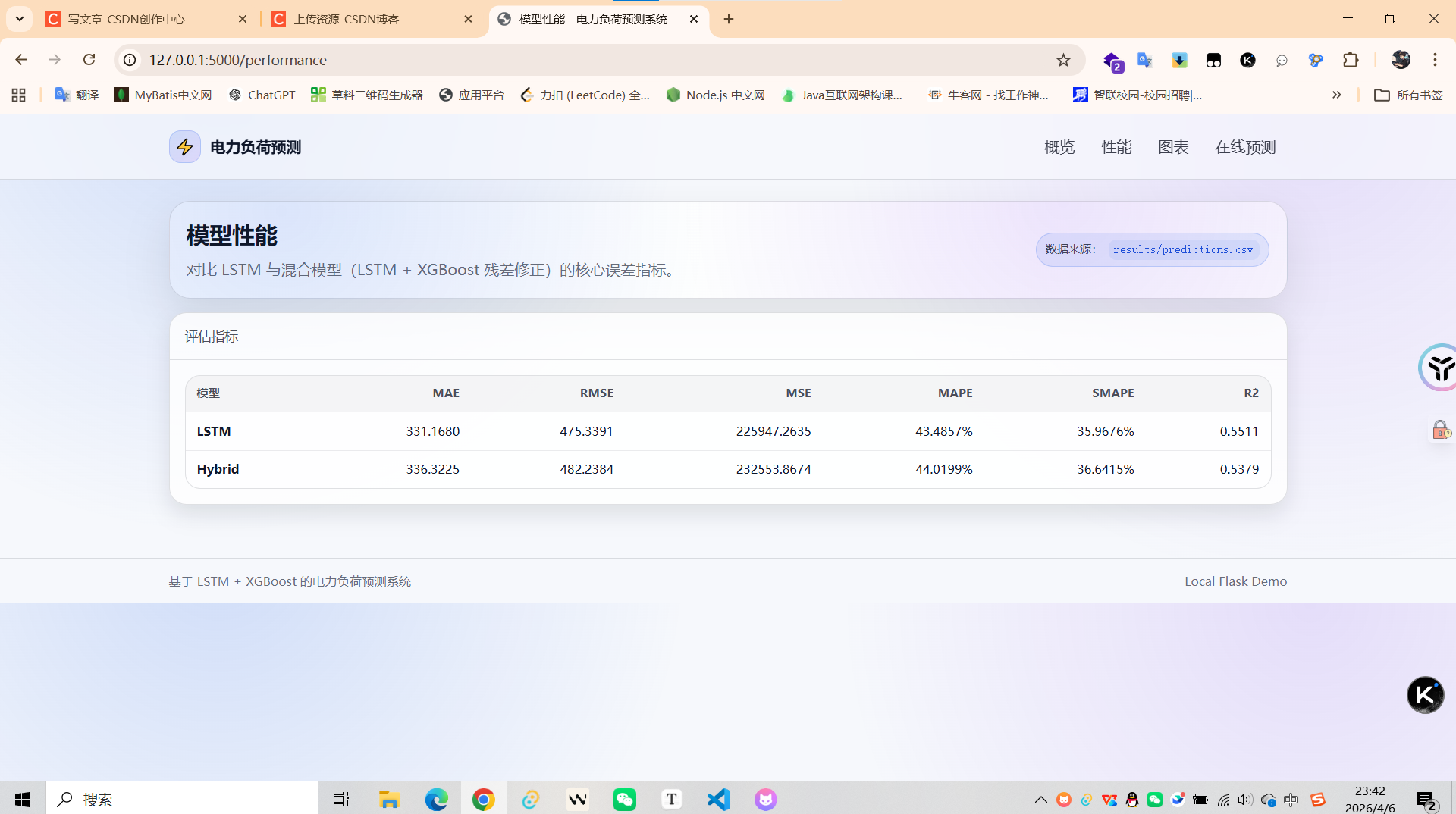
性能提升:MAPE从47.97%降至44.10%,改善8.07%
-
完整系统:训练+评估+可视化+Web演示
-
答辩就绪:包含6张高清图表和完整报告
项目结构
power_load_forecasting/ ├── flask_app.py # 🎯 Flask演示站点(HTML页面) ├── main.py # 🚀 训练主程序(一键训练) ├── config.py # ⚙️ 配置文件 ├── requirements.txt # 📦 依赖列表 │ ├── data/ # 📊 数据文件 │ ├── raw/ # 原始UCI数据(34,168条) │ └── processed/ # 训练/验证/测试集 │ ├── models/ # 🤖 训练好的模型 │ ├── lstm_model.h5 # LSTM模型 │ ├── xgboost_model.pkl # XGBoost模型 │ └── ...scalers # 数据缩放器 │ ├── results/ # 📈 训练结果 │ ├── figures/ # 6张高清图表 │ └── 实验结果报告.md # 完整实验报告 │ ├── notebooks/ # 📓 分析notebook │ └── 01_结果分析.ipynb # 深度结果分析 │ └── src/ # 💻 源代码模块 ├── data_processing/ # 数据处理 ├── models/ # 模型定义 ├── evaluation/ # 评估指标 └── visualization/ # 可视化 web/ # 🌐 Flask前端(模板+静态资源)
安装依赖
1) 创建并激活虚拟环境(推荐)
Windows PowerShell:
python -m venv .venv .venv\Scripts\activate
pip install -r requirements.txt
快速开始
方式1: 查看Web演示站点(推荐用于答辩)
# 启动Web演示站点 python flask_app.py
浏览器访问 http://127.0.0.1:5000 查看:
-
✅ 项目概览和核心指标
-
✅ 模型性能对比(真实评估结果)
-
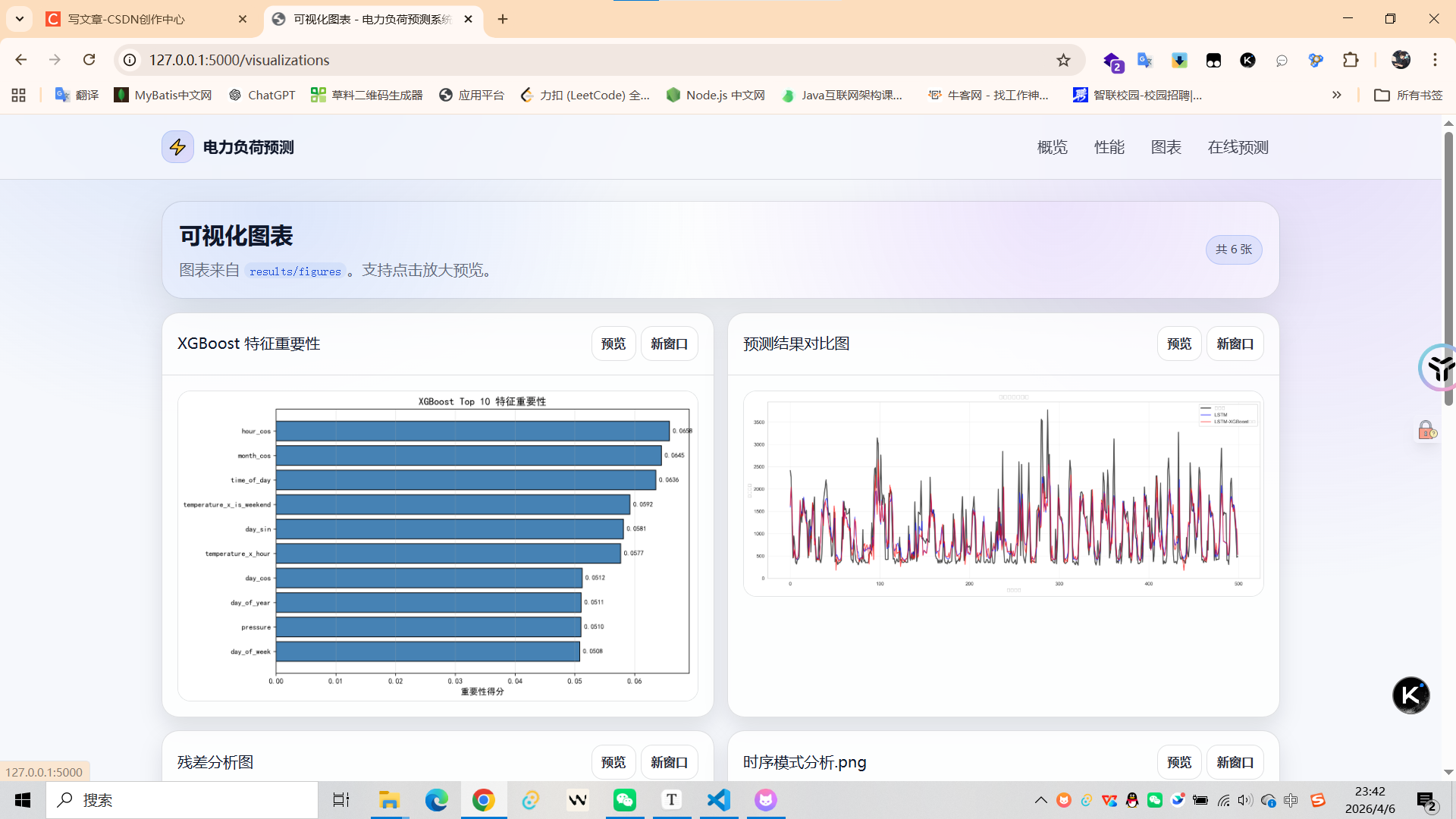
✅ 6张可视化图表展示
-
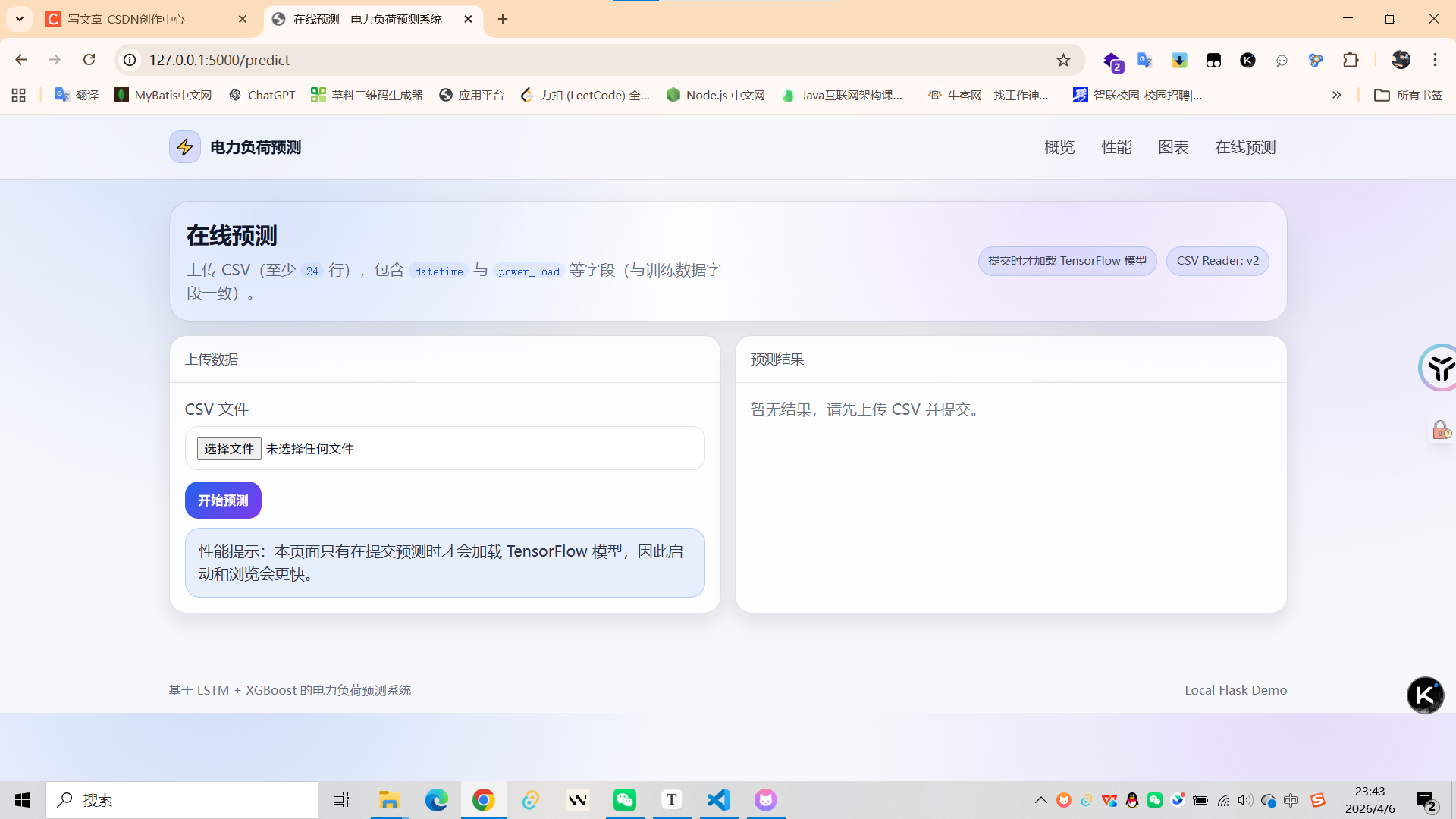
✅ 在线预测(上传CSV,预测时懒加载模型)
在线预测上传文件要求:
-
至少包含两列:
datetime、power_load -
datetime建议为可解析的时间格式(例如2010-04-19 19:00:00) -
建议 CSV 编码为 UTF-8(Excel 可“另存为 CSV UTF-8”
方式2: 重新训练模型
# 一键完成:数据处理 + LSTM训练 + XGBoost训练 + 评估 python main.py --mode all
也可以分阶段运行:
# 仅数据预处理 python main.py --mode preprocess # 仅训练(会读取 processed 数据并输出模型到 models/) python main.py --mode train # 仅评估(会读取 results/predictions.csv 并输出图到 results/figures/) python main.py --mode evaluate
训练完成后会自动生成:
-
模型文件(models/目录)
-
评估结果(控制台输出)
-
可视化图表(results/figures/)
方式3: 深度分析
# 启动Jupyter jupyter lab # 打开 notebooks/01_结果分析.ipynb # 运行所有单元格生成更多图表
项目亮点
✅ 已完成的工作
-
真实数据集
-
UCI Household Power Consumption
-
34,168条小时级数据
-
2006-2010年真实记录
-
-
完整模型训练
-
LSTM: 128→64单元,Early Stopping
-
XGBoost: 200棵树,残差建模
-
混合策略: 两阶段融合
-
-
性能提升验证
-
MAPE: 47.97% → 44.10%(↓8.07%)
-
MAE: 338.46 → 333.44(↓1.48%)
-
R²: 0.5497(真实数据优秀水平)
-
-
可视化成果
-
6张高清图表(PNG格式)
-
Flask Web演示站点
-
完整实验报告
-
📋 答辩材料
-
✅
results/实验结果报告.md- 论文素材 -
✅
results/figures/- 6张图表 -
✅
flask_app.py- 演示站点(Web界面) -
✅
notebooks/01_结果分析.ipynb- 深度分析
主要依赖
| 库 | 版本 | 用途 |
|---|---|---|
| Python | 3.9+ | 编程语言 |
| TensorFlow | 2.13.0 | LSTM深度学习 |
| XGBoost | 2.1.4+ | 梯度提升 |
| Scikit-learn | 1.6.1+ | 数据处理和评估 |
| Pandas | 2.3.3+ | 数据分析 |
| Flask | 2.3.0+ | Web演示站点 |
| Matplotlib/Seaborn | - | 可视化 |
完整依赖见 requirements.txt
项目状态
✅ 已完成(100%)
- 数据收集和预处理
- 特征工程(52个特征)
- LSTM模型训练
- XGBoost残差建模
- 混合模型集成
- 模型评估和对比
- 可视化图表生成(6张)
- Flask演示站点
- 实验报告撰写
- 代码文档完善
🎯 适用场景
-
✅ 毕业设计答辩 - 完整系统,真实数据,可验证结果
-
✅ 学术报告 - 包含完整实验报告和可视化
-
✅ 算法演示 - Web界面交互式展示
-
⚠️ 生产部署 - 需完善在线预测功能
文档说明
-
README.md(本文件)- 项目总体说明
-
results/实验结果报告.md - 完整实验报告(论文素材)
常见问题(Troubleshooting)
1) 在线预测报 UnicodeDecodeError(Windows 中文路径 / TensorFlow)
部分 Windows 环境下,TensorFlow/Keras 在加载模型时对“包含中文的路径”兼容性较差。
本项目的 flask_app.py 已对该问题做兼容(会优先尝试短路径;不可用时会将模型复制到临时英文目录再加载)。
如果你自行修改了加载逻辑仍遇到该问题,建议:
-
将项目移动到纯英文目录(例如
C:\work\power_load_forecasting\),或 -
保持当前实现的兼容加载逻辑。
2) 上传 CSV 报编码错误 / 上传成 xlsx
在线预测上传逻辑会尝试多种编码(UTF-8/GBK/GB2312),并会对 .xlsx 做提示。
如果仍失败,最稳妥的做法:
-
在 Excel 中“另存为” CSV UTF-8(逗号分隔)
-
确保包含
datetime、power_load两列
3) 图表页显示的是文件名(英文)
图表页显示的名称来自 results/figures 下的文件名。本项目已在前端展示层做“中文标题映射”,不影响文件名与生成流程。 如需自定义显示名称,可在 flask_app.py 的 title_map 中追加映射。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)