FIPO:通过未来KL影响策略优化激发深度推理
Qwen Pilot Team, 阿里巴巴集团 ∗
https://arxiv.org/pdf/2603.19835
摘要
我们提出了未来KL影响策略优化(Future-KL Influenced Policy Optimization, FIPO),这是一种旨在克服大语言模型推理瓶颈的强化学习算法。虽然GRPO风格的训练能够有效扩展,但它通常依赖于基于结果的奖励(ORM),该奖励将全局优势均匀地分配给轨迹中的每个token。我们认为,这种粗粒度的信用分配由于无法区分关键逻辑枢纽与平凡token,从而设定了性能上限。FIPO通过将折扣的未来KL散度引入策略更新来解决这一问题,创建了一种稠密的优势表述,根据token对后续轨迹行为的影响重新加权token。经验表明,FIPO使模型能够突破标准基线中观察到的长度停滞。在Qwen2.5-32B上评估时,FIPO将平均思维链长度从约4,000 token扩展到超过10,000 token,并将AIME 2024的Pass@1准确率从50.0%提升至峰值58.0%(收敛于约56.0%)。这优于DeepSeek-R1-Zero-Math-32B(47.0%)和o1-mini(56.0%)。我们的结果表明,建立稠密优势表述是将基于ORM的算法演进以解锁基础模型全部推理潜力的重要途径。我们开源了基于verl框架构建的训练系统。
1. 引言
测试时扩展策略(如OpenAI的o系列、Gemini系列和DeepSeek的R系列所采用的策略)标志着大语言模型执行推理方式的根本转变。通过在推理时分配更多的计算资源,这些方法支持更长的思维链和更审慎的推理,从而在数学竞赛和编程等苛刻任务上取得显著提升。大部分进展源于大规模可验证奖励强化学习(RLVR),它使用任务特定验证器的反馈微调模型的生成策略,从而激发并放大其推理能力。然而,由于具体算法和训练配方大多未公开,目前仍不清楚强化学习如何作为主要催化剂来解锁潜在的推理深度,从而有效地从最初没有这种倾向的基础模型中激发出长思维链行为。
与此同时,开源社区在更透明的环境中复现和扩展类似算法方面投入了大量精力。其中,DAPO提供了将GRPO风格训练应用于干净基础模型的 promising 大规模复现。然而,我们认为GRPO框架内对基于结果的奖励的固有依赖引入了显著的结构约束。因为奖励仅在轨迹末端进行二值可验证,标准公式将统一的优势分配给每个token。这导致了完全粗粒度的信用分配,算法对关键推理步骤和平凡token赋予相等的权重。具体而言,我们观察到此类基线生成的推理轨迹往往在中间长度处达到平台期。我们认为这一限制对标准GRPO设定了较低的性能上限:由于统一奖励无法突出驱动正确逻辑的特定token,模型无法收敛到解决困难任务所需的复杂、扩展的推理路径。虽然这一限制导致近期工作回归到PPO框架以实现细粒度优势估计,但我们认为无需价值模型的复杂性即可实现这种稠密性。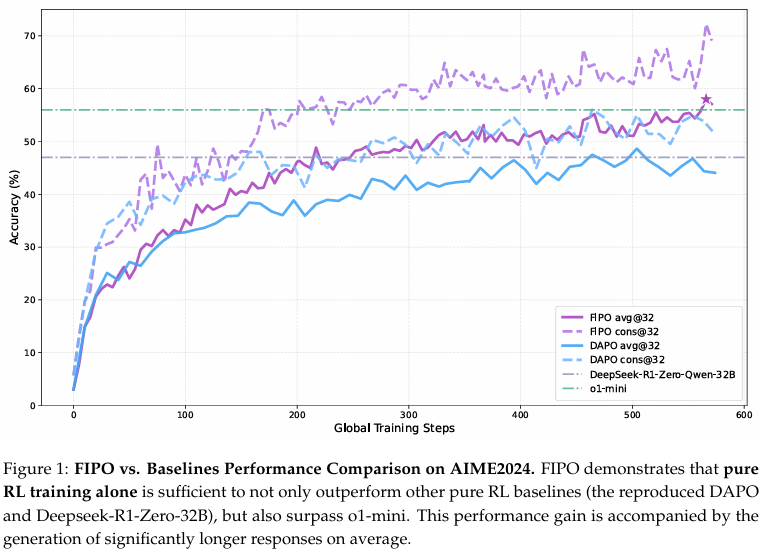
我们引入未来KL影响策略优化(FIPO)。FIPO通过引入未来KL散度修改策略更新,该散度根据后续轨迹的累积行为重新加权当前token的优势。为了保持训练稳定性,该目标与影响权重裁剪和过滤机制相结合。我们在Qwen2.5-32B-Base上评估该方法,该模型此前未接触过任何长思维链合成数据,并使用DAPO公开释放的训练数据集以确保严格控制的比较。如图1所示,FIPO突破了标准基线的性能上限;当DAPO在AIME 2024上达到50.0%(Pass@1)时,FIPO使模型能够逐步延长推理链,稳步从基线的4,000 token扩展到深度推理状态的超过10,000 token。这种持续扩展将准确率推至峰值58.0%,与近期基于PPO的同类方法相当。这些发现表明,建立稠密优势表述有效弥合了GRPO效率与PPO性能之间的差距,解锁了在统一奖励方案下原本无法利用的深度推理能力。
我们的实现基于verl框架和DAPO代码库。通过完全公开完整的训练代码和配置配方,我们旨在揭示对更广泛研究社区有益的大规模大语言模型强化学习的宝贵见解。
2. 相关工作
大语言模型的强化学习。 强化学习(RL)是大语言模型后训练管道的基石。虽然基础性工作主要利用基于人类反馈的强化学习(RLHF)使模型行为与人类偏好对齐,但最近的进展已转向通过RL增强推理能力。显著的例子包括开创性以推理为中心的OpenAI o系列,以及引入全面RLVR框架通过GRPO算法开发推理模型的DeepSeek-R1。这些突破进一步激发了后续行业领先工作,如Kimi、Qwen3和Gemini 2.5。
大规模开源RL配方。 与推理模型的专有进展并行,开源社区在 democratize 大规模RL训练方面取得了显著进展。这些工作旨在弥合高级算法概念与实际、稳定且可扩展的实现之间的差距,并持续改进训练管道。值得注意的是,GSPO、BAPO、SAPO和OR1主要在已发展出长思维链能力的模型上开发其RL算法。其他工作则致力于从更干净的基础模型(特别是Qwen2.5-32B-Base)开始激励复杂的推理能力。其中,Open-Reasoner-Zero、VC-PPO、VAPO和T-PPO基于PPO框架构建算法,而DAPO则是作为GRPO的修改版开发。
为确保严格评估,我们采用Qwen2.5-32B-Base作为主干,并使用DAPO作为主要基线。虽然Open-Reasoner-Zero回归PPO以避免vanilla GRPO中的稀疏优势信号,但我们通过直接改进GRPO框架来应对这一挑战。值得注意的是,由于Open-Reasoner-Zero在没有辅助价值模型的情况下运行,其性能最终不及DAPO。相比之下,VC-PPO、VAPO和T-PPO等方法严重依赖于通过已使用长思维链数据进行监督微调(SFT)的模型预训练的价值模型。我们认为这种方法通过价值模型引入了外部知识先验,在评估中造成了潜在的混淆因素。这使得难以区分性能提升是源于策略优化算法本身,还是仅仅从预训练的价值模型中继承而来。通过摒弃对价值模型的需求并从原始基础模型开始,FIPO实现了与这些基于预训练价值模型的方法相当甚至在某些情况下更优的性能。这表明,建立稠密优势表述是演进基于ORM的GRPO算法以解锁基础模型固有推理潜力的一个有前景的方向。
3. 预备知识
在本节中,我们回顾我们工作核心的策略优化框架:PPO及其无价值网络变体GRPO和DAPO。在本文中,令 TTT 表示轨迹的总长度,ttt 表示该轨迹内的当前步索引。在GRPO设置中,对于每个问题提示 qqq,我们采样 GGG 个轨迹,产生输出记为 ooo。
3.1 近端策略优化 (Proximal Policy Optimization)
近端策略优化(PPO)为策略优化引入了裁剪代理目标。通过裁剪机制将策略更新限制在旧策略的邻近区域,PPO稳定了训练并提高了样本效率。具体而言,PPO最大化:
JPPO(θ)=E(q,o)∼D,o∼πθold(⋅∣q)[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]J_{PPO}(\theta)= \mathbb{E}_{(q,o)\sim D, o\sim \pi_{\theta_{old}}(\cdot|q)}\left[\min(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_t)\right]JPPO(θ)=E(q,o)∼D,o∼πθold(⋅∣q)[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
这里,rt(θ)=πθ(ot∣q,o<t)πθold(ot∣q,o<t)r_t(\theta)= \frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{\theta_{old}}(o_t|q,o_{<t})}rt(θ)=πθold(ot∣q,o<t)πθ(ot∣q,o<t) 表示步 ttt 处的token级概率比,A^t\hat{A}_tA^t 是通过学习到的价值函数估计的优势,ϵ\epsilonϵ 是裁剪系数。至关重要的是,标准PPO实现使用广义优势估计(GAE)计算优势 A^t\hat{A}_tA^t。这产生了独特的、token特定的优势信号,使模型能够执行时间信用分配。这与仅从最终结果推导优势、有效地将统一信号广播给轨迹中所有token的简化公式形成对比。通过利用GAE,PPO在每个步骤提供稠密监督,使其能够区分生成过程中关键和影响力较小的动作。
3.2 组相对策略优化 (Group Relative Policy Optimization)
组相对策略优化(GRPO)通过基于组的采样估计优势,规避了价值网络的计算负担。对于给定的查询 qqq(和真实答案 aaa),从旧策略 πθold\pi_{\theta_{old}}πθold 采样一组输出 {oi}i=1G\{o_i\}_{i=1}^G{oi}i=1G。第 iii 个样本的序列级优势标准化为:
A^i=Ri−μσ,其中 Ri=I(Verify(oi,a)),(1)\hat{A}_i= \frac{R_i - \mu}{\sigma}, \quad \text{其中 } R_i= I(\text{Verify}(o_i, a)), \quad (1)A^i=σRi−μ,其中 Ri=I(Verify(oi,a)),(1)
其中 μ\muμ 和 σ\sigmaσ 分别表示采样组内奖励的经验均值和标准差。与PPO类似,GRPO采用裁剪目标,但直接在损失中添加逐token的KL惩罚项:
JGRPO(θ)=Eq∼D,{oi}i=1G∼πθold(⋅∣q)[1G∑i=1G1∣oi∣∑t=1∣oi∣(min(ρi,t(θ)A^i,clip(ρi,t(θ),1−ϵ,1+ϵ)A^i)−βDKL(πθ∥πref))](2)J_{GRPO}(\theta)= \mathbb{E}_{q\sim D, \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(\cdot|q)}\left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left( \min(\rho_{i,t}(\theta)\hat{A}_i, \text{clip}(\rho_{i,t}(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_i) - \beta D_{KL}(\pi_\theta\|\pi_{ref}) \right) \right] \quad (2)JGRPO(θ)=Eq∼D,{oi}i=1G∼πθold(⋅∣q)
G1i=1∑G∣oi∣1t=1∑∣oi∣(min(ρi,t(θ)A^i,clip(ρi,t(θ),1−ϵ,1+ϵ)A^i)−βDKL(πθ∥πref))
(2)
这里,ρi,t(θ)=πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t)\rho_{i,t}(\theta)= \frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,o_{i,<t})}ρi,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t) 表示概率比。根据设计,计算出的标量 A^i\hat{A}_iA^i 在整个序列上广播;具体来说,对于每个token ttt,优势被相同地设置为 A^i,t=A^i\hat{A}_{i,t}= \hat{A}_iA^i,t=A^i。与PPO不同(其中GAE为每个token提供独特信号),GRPO对轨迹中的每个步骤分配统一信用,无论其对最终结果的个体贡献如何。
3.3 解耦裁剪与动态采样策略优化 (Decoupled Clip and Dynamic Sampling Policy Optimization)
解耦裁剪与动态采样策略优化(DAPO)通过消除显式KL惩罚扩展了GRPO框架。相反,它在区间 (1−ϵlow,1+ϵhigh)(1-\epsilon_{low}, 1+\epsilon_{high})(1−ϵlow,1+ϵhigh) 内采用不对称裁剪来放大优势动作的更新,有效缓解了GRPO常见的熵崩溃问题。此外,DAPO实现了逐token的策略梯度损失,以在长思维链RL训练的背景下维持健康的优化动态。此外,DAPO强制执行动态采样机制,确保每组 {oi}i=1G\{o_i\}_{i=1}^G{oi}i=1G 内正负样本的混合。该机制确保在优化期间具有非平凡梯度的有效更新。我们采用DAPO作为本文的主要基线。
3.4 策略更新方向与细粒度token分析的发现
在我们之前的工作(Meng et al., 2025)中,对RL如何重写基础模型进行了系统分析。我们发现在超过98%的生成步骤中,输出分布是相同的。RL仅在高度稀疏的关键token处进行干预,以保持模型在正轨上。此外,Huang et al. (2025) 认为标准指标(如KL散度)无法定位这些稀疏变化。通过跟踪有符号的对数概率差,我们可以精确映射优化的“方向”,甚至仅通过放大这些关键token就能提升推理准确率,且无需额外训练。这些洞察得出明确结论:并非所有token对推理过程的贡献都相等。然而,虽然瞬时对数概率差指示了优化方向,但它仅作为原始的局部信号。激发更有效推理的关键在于发现如何利用这个原始 Δlogp\Delta \log pΔlogp 来构建一个更准确的token真实下游影响的度量,从而使我们能够在RL训练期间自动定位并强化这些关键枢纽。
4. FIPO
在本节中,我们介绍FutureKL诱导策略优化(FIPO)的核心框架。我们首先讨论概率偏移,这是我们目标的基本构建块。接下来,我们详细说明未来KL的公式。最后,我们说明我们的方法如何通过关注局部“未来上下文”来实现“软衰减窗口”策略。该机制自然地优先考虑近端信号而非远距离信号,将有效范围限制在最相关的后续token上。
4.1 概率偏移:Δlogp\Delta \log pΔlogp
我们的方法基于我们最近对大语言模型(LLM)在强化学习期间动态的研究。具体而言,我们之前关于RLVR更新的工作(Huang et al., 2025)证明,概率偏移的大小和方向 Δlogp\Delta \log pΔlogp 是推理改进的稳健指标。在此基础上,我们对分布偏移的细粒度分析(Meng et al., 2025)进一步揭示了生成过程通常由少数“稀疏但关键”的token驱动,这些token对后续思维链产生不成比例的影响。受这些洞察启发,我们将token级概率偏移确定为信用分配机制的原子单位。
形式上,我们将时间步 ttt 处的概率偏移定义为当前策略与旧策略在对数空间中的差异:
Δlogpt=logπθ(ot∣q,o<t)−logπθold(ot∣q,o<t).(3)\Delta \log p_t= \log \pi_\theta(o_t | q, o_{<t}) - \log \pi_{\theta_{old}}(o_t | q, o_{<t}). \quad (3)Δlogpt=logπθ(ot∣q,o<t)−logπθold(ot∣q,o<t).(3)
该术语作为微分信号捕捉瞬时策略漂移:
- 正偏移(Δlogpt>0\Delta \log p_t > 0Δlogpt>0):表示当前策略相对于旧策略增加了token oto_tot 的可能性。这通常表明训练目标正在强化这一特定推理步骤。
- 负偏移(Δlogpt<0\Delta \log p_t < 0Δlogpt<0):意味着策略正在抑制 oto_tot 的生成,表明更新后的模型相对于参考策略正在主动降权该特定token。
与将这种漂移主要视为需最小化的正则化成本的传统KL惩罚不同,我们将其解释为行为调整的方向性信号,从而将优化目标与生成动态显式耦合。然而,仅依赖这种瞬时偏移是不够的,因为它无法捕捉决策的长期后果。这一局限性激发了我们提出的Future-KL机制,该机制通过聚合其未来轨迹的分布偏移来重新加权当前token。
4.2 未来KL估计
虽然 Δlogpt\Delta \log p_tΔlogpt 捕捉了局部分布偏移,但推理本质上是一个序列过程,该token的真实重要性取决于其启动的轨迹。为了捕捉这种因果影响,我们将Future-KL定义为从当前步 ttt 到序列结束 TTT 的累积有符号概率偏移:
FutureKLt=∑k=tTΔlogpk.(4)\text{FutureKL}_t= \sum_{k=t}^T \Delta \log p_k. \quad (4)FutureKLt=k=t∑TΔlogpk.(4)
该求和在数学上等同于后续序列 ot:To_{t:T}ot:T 的联合概率分布的对数似然比。因此,它可以被解释为限制在未来范围内的KL散度的基于样本的估计,测量了轨迹剩余部分当前策略相对于参考策略的累积偏差。因此,我们称此指标为Future-KL。
在功能上,FutureKLt\text{FutureKL}_tFutureKLt 作为前瞻指标,量化了关于未来轨迹的策略分布的累积偏移。正值(FutureKLt>0\text{FutureKL}_t > 0FutureKLt>0)表示更新后的策略整体上强化了由token oto_tot 启动的整个后续轨迹,表明 oto_tot 充当后续推理链的稳定锚点。相反,负值(FutureKLt<0\text{FutureKL}_t < 0FutureKLt<0)意味着策略正在集体抑制跟随 oto_tot 的未来token,表明从该点开始的轨迹在优化过程中变得不那么受青睐。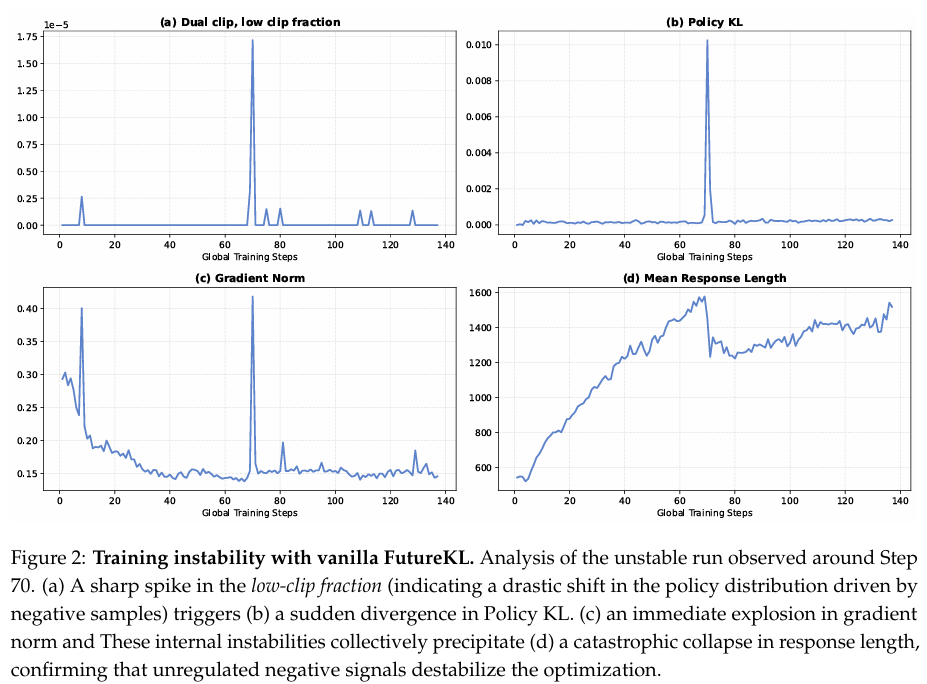
然而,在实践中,这种公式往往会加剧由分布偏移引起的方差。由于 FutureKLt\text{FutureKL}_tFutureKLt 充当优势函数的加权系数(如后续部分所述),未来logits的过度偏差(例如由于训练-推理不一致)会不成比例地放大尺度。这使得优化对噪声token过于敏感,而不是推理链的内在质量。经验上,我们观察到在缺乏安全机制的情况下,训练运行容易出现严重的不稳定性。如图2所示,这种崩溃伴随着“低裁剪分数(low-clip fraction)”指标的急剧飙升,该指标跟踪触发Dual-Clip阈值的样本频率(负样本上的硬裁剪比率)。负样本上的这种高重要性比率标志着关键错位:模型为实际上有害的动作分配了高概率。在我们的实验中,这一飙升(约在第70步)与梯度范数和策略KL1的激增相一致,表明策略分布发生了实质性转变,同时响应长度立即下降。这种同步表明,如果没有调节,来自 FutureKLt\text{FutureKL}_tFutureKLt 的累积负信号可能达到使优化过程不稳定的极值。
受这些观察的启发,我们通过显式掩蔽超过Dual-Clip阈值的token来改进FutureKL计算。由于这些token代表其梯度已被裁剪(通过裁剪策略目标)的“有害”动作,允许其过高的重要性比率传播到递归求和中会引入严重方差。通过将这些特定异常值的未来累积归零,我们消除了不稳定的主要来源。改进的目标定义为:
FutureKLt=∑k=tTMk⋅Δlogpk,Mk=I(πθ(ok∣o<k)πold(ok∣o<k)≤c).(5)\text{FutureKL}_t= \sum_{k=t}^T M_k \cdot \Delta \log p_k, \quad M_k= I\left( \frac{\pi_\theta(o_k|o_{<k})}{\pi_{old}(o_k|o_{<k})} \leq c \right). \quad (5)FutureKLt=k=t∑TMk⋅Δlogpk,Mk=I(πold(ok∣o<k)πθ(ok∣o<k)≤c).(5)
这里,MkM_kMk 充当二元过滤器,仅当重要性比率保持在Dual-Clip阈值 ccc(通常 c≥10c \geq 10c≥10)内时才评估为1,否则为0。这确保触发硬约束的token被有效排除在FutureKL计算之外,防止梯度爆炸而不改变轨迹的有效信号。
4.2.1 软衰减窗口
除了稳定性约束外,我们还解决了长视界生成的固有不确定性。当前动作 oto_tot 与未来token oko_kok 之间的因果依赖性随着时间视界 k−tk-tk−t 的增加而自然减弱。直接后继者直接取决于当前选择,而远距离token受累积随机性的影响,变得难以预测。为了对这种递减的影响进行建模,我们引入折扣因子 γ∈(0,1]\gamma \in (0, 1]γ∈(0,1]。将这种衰减纳入掩蔽目标得出我们实验中使用的最终公式:
FutureKLt=∑k=tTMk⋅γk−t⋅Δlogpk.(6)\text{FutureKL}_t= \sum_{k=t}^T M_k \cdot \gamma^{k-t} \cdot \Delta \log p_k. \quad (6)FutureKLt=k=t∑TMk⋅γk−t⋅Δlogpk.(6)
我们将衰减率参数化为 γ=2−1τ\gamma= 2^{-\frac{1}{\tau}}γ=2−τ1,其中 τ\tauτ 是控制未来监督有效范围(或“半衰期”)的超参数。该公式确保信用分配集中在直接推理链上,为遥远、高度不确定的token分配较低权重。在功能上,τ\tauτ 定义了此软衰减窗口的光圈。与硬截断在固定步长之外突然丢弃信息不同,这种指数公式创建了一个连续的滑动窗口,其中 τ\tauτ 表示未来信号影响衰减一半的距离。该机制允许模型优先考虑窗口 τ\tauτ 内的局部一致性,同时平滑过滤远距离未来的噪声,而不会引入边界伪影。
4.2.2 带裁剪的FutureKL重新加权优势
最后,我们将软衰减窗口和掩蔽机制整合到策略优化目标中。我们提出使用未来影响权重 ftf_tft 调制标准优势估计 A^t\hat{A}_tA^t。修改后的优势 A~t\tilde{A}_tA~t 定义为:
ft=clip(exp(FutureKLt),1−ϵflow,1+ϵfhigh),A~t=A^t⋅ft.(7)f_t= \text{clip}(\exp(\text{FutureKL}_t), 1-\epsilon_{f_{low}}, 1+\epsilon_{f_{high}}), \quad \tilde{A}_t= \hat{A}_t \cdot f_t. \quad (7)ft=clip(exp(FutureKLt),1−ϵflow,1+ϵfhigh),A~t=A^t⋅ft.(7)
该公式引入两个关键操作:
- 指数映射:我们将累积标量信号从对数空间转换到乘法域。数学上,未裁剪的项表示似然比的衰减加权乘积,其充当反映策略对生成未来有效偏好的重要性权重。
- 影响权重裁剪:我们将乘法系数 ftf_tft 约束在区间 [1−ϵflow,1+ϵfhigh][1-\epsilon_{f_{low}}, 1+\epsilon_{f_{high}}][1−ϵflow,1+ϵfhigh] 内。该操作严格用于限制优势调制的幅度,防止指数项向梯度估计中引入过度方差。通过限制权重,我们确保未来轨迹在受控范围内调制更新信号,避免由极端累积对数概率偏移引起的数值不稳定性。
在功能上,这种调制根据生成未来的强化或抑制来缩放策略更新的幅度。当更新后的策略强化后续轨迹时(即 FutureKLt>0\text{FutureKL}_t > 0FutureKLt>0),权重项 ft>1f_t > 1ft>1 放大梯度信号。因此,正优势被提升以鼓励当前token作为稳定锚点,而负优势则受到更严厉的惩罚以严格纠正启动该路径的错误。相反,当策略抑制未来轨迹时(即 FutureKLt<0\text{FutureKL}_t < 0FutureKLt<0),项 ft<1f_t < 1ft<1 衰减更新。这种衰减有效降低了偶然处于成功序列中的局部有害token的奖励信号,并软化陷入失败序列中的好token的惩罚。在实践中,为确保训练稳定性并防止过度惩罚,对于表现出过高重要性比率的负优势(A^t<0\hat{A}_t < 0A^t<0)相关token,我们将 ftf_tft 重置为1。
4.3 目标损失
采用DAPO的逐token公式,我们最大化以下FIPO目标:
JFIPO(θ)=E(q,a)∼D,{oi}∼πθold[1∑i=1G∣oi∣∑i=1G∑t=1∣oi∣min(ri,tfi,tA^i,t,clip(ri,t,1−ϵ,1+ϵ)fi,tA^i,t)].(8)J_{FIPO}(\theta)= \mathbb{E}_{(q,a)\sim D, \{o_i\}\sim \pi_{\theta_{old}}}\left[ \frac{1}{\sum_{i=1}^G |o_i|} \sum_{i=1}^G \sum_{t=1}^{|o_i|} \min(r_{i,t} f_{i,t} \hat{A}_{i,t}, \text{clip}(r_{i,t}, 1-\epsilon, 1+\epsilon) f_{i,t} \hat{A}_{i,t}) \right]. \quad (8)JFIPO(θ)=E(q,a)∼D,{oi}∼πθold
∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(ri,tfi,tA^i,t,clip(ri,t,1−ϵ,1+ϵ)fi,tA^i,t)
.(8)
这里,GGG 表示每个查询采样的输出数量,ri,t=πθ(ai,t∣si,t)πθold(ai,t∣si,t)r_{i,t}= \frac{\pi_\theta(a_{i,t}|s_{i,t})}{\pi_{\theta_{old}}(a_{i,t}|s_{i,t})}ri,t=πθold(ai,t∣si,t)πθ(ai,t∣si,t) 表示当前策略与旧策略之间的重要性比率。术语 A^i,t\hat{A}_{i,t}A^i,t 指组相对优势,而 fi,tf_{i,t}fi,t 充当先前引入的Future-KL重要性权重。
5. 实验
5.1 实验设置
在本工作中,我们采用DAPO的训练设置,特别专注于数学推理任务以确保严格控制的比较。我们使用VeRL框架进行训练和基线复现。我们保持与DAPO一致的优化设置,并在公开释放的DAPO-17K数据集上进行训练。每个训练批次包含512个提示,每个提示采样16个响应,总共产生8,192个训练样本。在标准DAPO配置中,更新以512个样本(32个提示)的mini-batch大小执行,导致每次训练迭代进行16次梯度更新。然而,我们的经验表明,更大的mini-batch大小能提高训练稳定性。因此,我们采用1,024个样本(64个提示)的mini-batch大小,导致每次迭代进行8次梯度更新。关于此增加的mini-batch大小影响的更详细讨论见附录E。对于Future-KL计算,我们将衰减率的有效范围 τ\tauτ 设置为32。特定于32B模型的训练,Future-KL权重被裁剪在 [1,1.2][1, 1.2][1,1.2] 内;这有效放大了与成功推理轨迹相关token的奖励,同时对导致错误结果的token施加更严格的惩罚。FIPO和DAPO共享20,480 token的最大响应长度,对超过16,384 token的轨迹应用超长惩罚。基线和FIPO的详细超参数配置见附录A。
对于评估,我们采用AIME 2024作为主要验证基准,并辅以AIME 2025,以确保与DAPO基线的严格和全面比较。为保持结果稳定性并考虑思维链生成的方差,我们遵循DAPO协议重复评估32次,并报告Pass@1(32个样本的平均值)。推理超参数一致设置为温度1.0和top-p 0.7。
5.2 主要结果
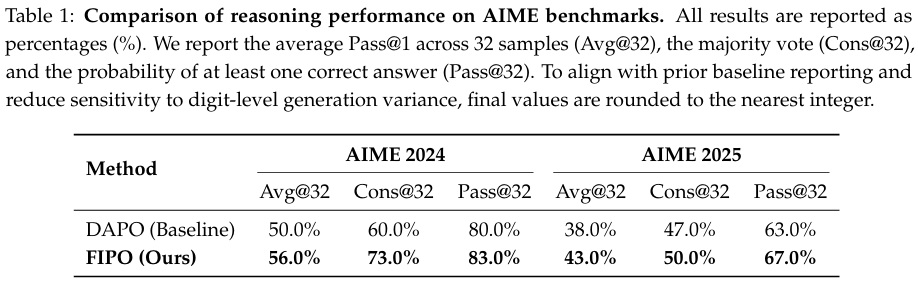
表1展示了AIME 2024和AIME 2025基准上的定量评估。FIPO在两个数据集上相对于DAPO基线在Pass@1(Avg@32)上实现了约6.0%的系统性提升。我们将此指标视为推理可靠性的最稳健指示器。虽然我们也观察到一致性的提升,但覆盖率(Pass@32)的提升更为温和,特别是在AIME 2025上。我们将其归因于仅通过强化学习扩展大模型绝对问题解决范围的固有挑战。在没有外部知识增强或工具集成的情况下,RL主要受限于优化模型如何导航其现有内部知识。因此,虽然FIPO显著增强了模型在其潜在能力内可靠解决问题的能力(推高Avg@32),但转移可解决问题边界(Pass@32)仍然是非平凡的。
6. 分析
除了汇总指标外,我们观察到几个我们认为支撑这些性能提升的独特现象。通过剖析训练动态和推理行为,我们确定了FIPO有效性的三个关键驱动因素:推理链中基于长度的扩展的出现、响应长度加权平均优势公式捕获的独特正向学习信号,以及与标准基线相比显著改善的优化过程稳定性。
6.1 长度与性能的扩展
FIPO训练中的一个核心观察是,性能提升与响应长度的持续扩展深度耦合。随着训练的进行,我们观察到token计数显著激增,并与模型准确率同步扩展。如图3所示,DAPO的响应长度在初始增加后逐渐进入停滞阶段,在平均约4,000 token处达到平台期。相比之下,FIPO表现出卓越的扩展韧性。该扩展过程通过不同的演化阶段展开(由图3中的彩色区域可视化),标志着从初始快速探索到持续深度推理时期的过渡。值得注意的是,尽管维持了超长惩罚以约束冗余,FIPO成功引导模型激发出广泛的思维链(CoT)推理。附录D提供的定性分析揭示,这种长度扩展是由自我反思行为的逐渐出现驱动的;模型越来越多地利用扩展的序列长度重新评估其中间步骤,并探索多种方法来验证其结论。有趣的是,这种系统自我验证的自发出现与高级推理模型(如OpenAI o系列和DeepSeek-R1)中观察到的推理时扩展行为相一致。这表明FIPO有效触发了推理时推理,优先考虑分析深度以解锁更高性能。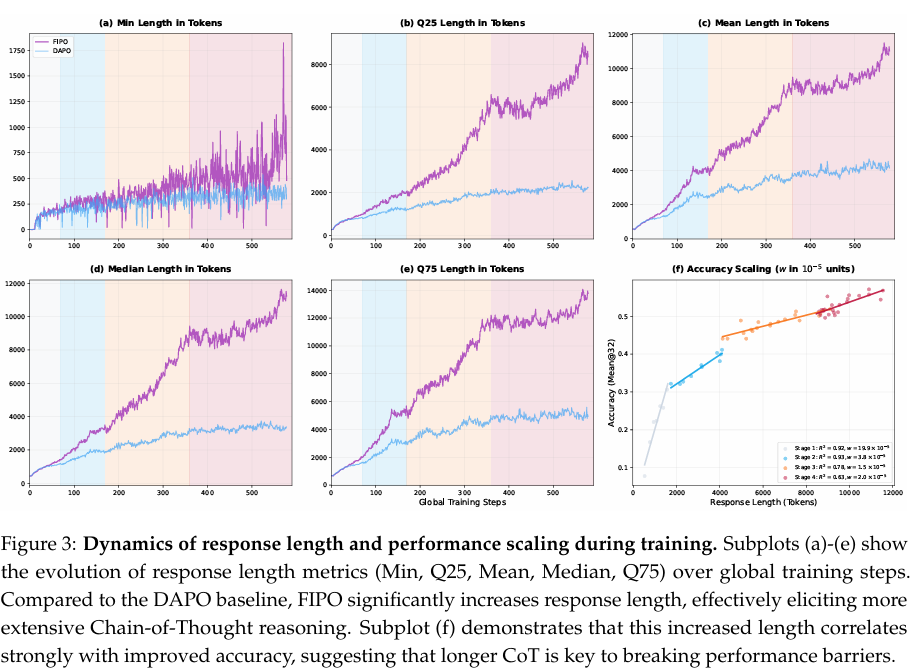
对训练动态的进一步检查揭示,这种长度激增并非由孤立异常值驱动,而是代表了全面的分布迁移。如图3(a)–(e)所示,在FIPO训练下,从最小值和Q25到中位数和Q75的所有长度相关百分位数都表现出同步且稳定的向上偏移。具体而言,在这些训练阶段中,中位数token计数从最初的200稳步攀升至超过10,000。整个分布的这种迁移证明FIPO促进了模型底层问题解决策略的根本转变:模型从直接响应模式过渡到系统性的自我验证推理过程。至关重要的是,我们发现这种向更长推理链的集体转变正是解锁我们实验中观察到的性能突破的原因。如图3(f)所示,在所有识别阶段中,模型准确率与响应长度之间存在强烈的正相关。虽然阶段之间的相关斜率(表示为 www)略有不同,但轨迹始终保持正值。当DAPO基线的性能因其长度停滞而达到瓶颈时,FIPO持续解锁额外“思考空间”的能力使模型能够导航日益复杂的逻辑依赖关系。这证实FIPO成功将增加的序列长度转化为真实的推理深度,使模型能够在高难度推理任务上超越标准基线的性能上限。
6.2 优势动态与持续推理增长
我们通过比较奖励和优势的演化进一步调查训练动态。如图4(a)所示,基线(DAPO)始终保持高于FIPO的平均训练奖励。然而,我们认为这种差异是奖励公式的数值假象,而非卓越性能的指示器。由于奖励函数包含超长惩罚,FIPO构建精心推理链不可避免地导致更高惩罚,从而抑制其平均原始奖励。相反,基线的更高奖励是由其生成较短响应的倾向驱动的。虽然该策略通过最小化惩罚最大化即时奖励,但它表明在受限搜索空间内收敛到局部最优。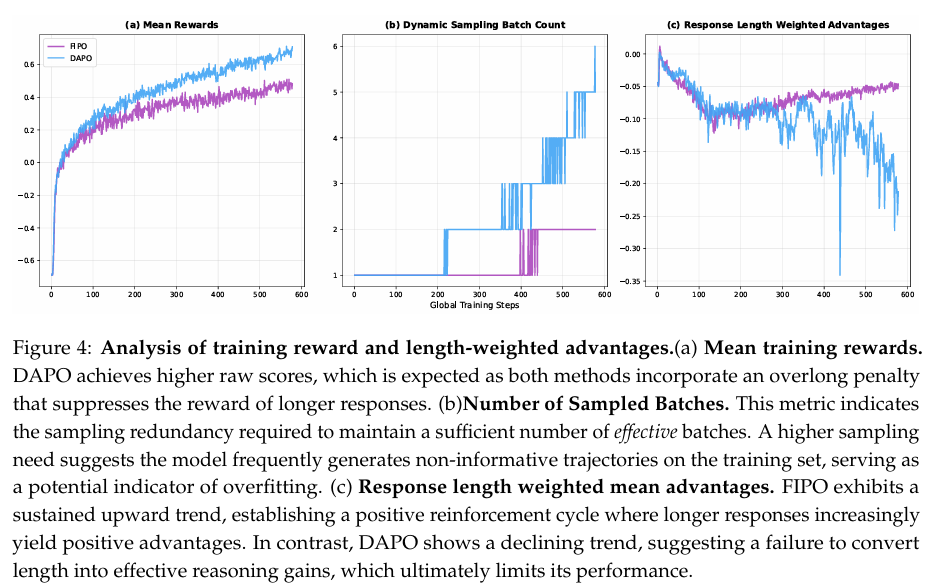
该假设得到图4(b)中DAPO采样批次数量快速上升的进一步证实。这一趋势表明模型正在过拟合训练集,越来越多地生成非判别性样本(即完全正确或完全错误的批次),这些样本产生可忽略的梯度信息。因此,算法被迫更积极地采样以收集足够的有效数据进行优化。相比之下,FIPO主动遍历更广阔的搜索空间,优先考虑挑战性推理任务所需的结构深度,而不仅仅是避免惩罚。
当从原始奖励转向优势提供的动态激励时,这种差异变得更加明显。如图4©所示,DAPO在整个训练期间表现出响应长度加权平均相对优势的下降趋势。这意味着正样本的长度日益被负样本的长度所主导,导致扩展推导的激励减弱;由于增加长度不再产生更多正相对优势,模型最终在推理增长上遇到平台期。形成鲜明对比的是,FIPO表现出一致的上升趋势。这表明正样本正在变得比其负对应物实质上更有意义。这种动态培育了持续增长轨迹:随着更长、有效推理链的生成产生越来越正的优势,并在奖励稳步上升的促进下,它保留了模型追求更广泛、更严格推理路径的动量。
6.3 平滑策略漂移、探索与梯度更新
为进一步表征训练过程,我们检查策略行为和优化稳定性的演化。如图5(a)所示,FIPO在策略KL散度上表现出稳定且结构化的增加。这代表了渐进的策略偏移,模型持续远离其先前策略状态,以导航至更专业的推理状态。该趋势与我们的rollout观察在定性上一致:自我反思片段的长度是增量增加而非突然增加,反映了推理过程的逐渐扩展。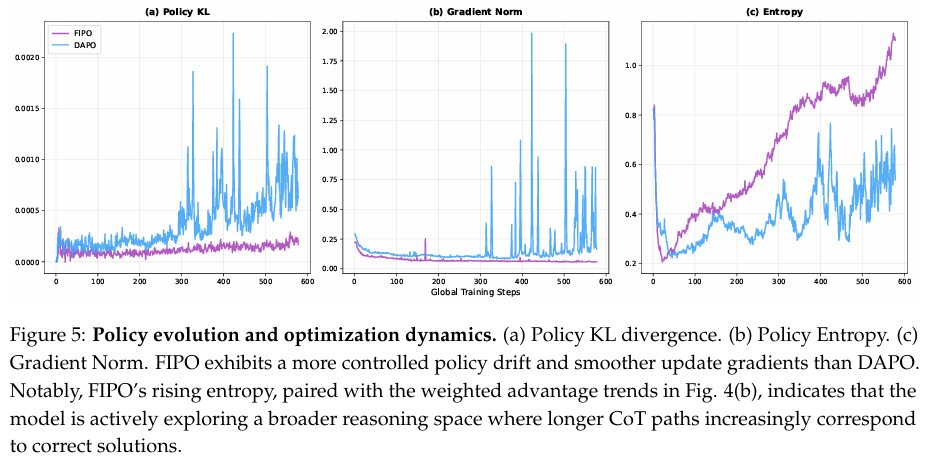
优化特征在梯度尺度上也显著不同。如图5(b)所示,FIPO的梯度范数在整个训练期间保持低位且一致,表征了建立在细粒度更新基础上的演化。相比之下,基线(DAPO)表现出高度波动的波动,其梯度范数频繁出现剧烈峰值。这些波动更新表明DAPO的搜索过程面临突然偏移和潜在不稳定的风险。
这种稳定性对比进一步反映在策略熵中(图5c)。虽然FIPO保持平滑且持续的熵上升,表明对推理空间的持续稳定探索,但DAPO的熵在训练进展期间以噪声振荡为特征。总之,这些指标将FIPO描绘为一个实现显著且有目的的策略演化以进行复杂推理的模型,同时确保优化过程在数值上表现良好。
7. 结论
在本文中,我们介绍了未来KL影响策略优化(FIPO),这是一种旨在解决标准GRPO固有粗粒度信用分配问题的强化学习方法。通过将折扣的未来KL散度纳入策略更新,FIPO将稀疏的基于结果的奖励转化为稠密的逐token监督。我们的经验分析识别并解决了现有基线中的关键“长度-性能平台期”现象,证明标准统一奖励无法维持长链推理。在Qwen2.5-32B-Base上验证,FIPO有效突破了这一上限:它将AIME 2024的性能从基线的50.0%提升至峰值58.0%(收敛于56.0%),并将平均思维链长度从4,000 token扩展至超过10,000 token。至关重要的是,这些发现挑战了“复杂价值模型是细粒度信用分配所必需的”这一普遍假设,证明稠密监督可以在更高效的GRPO框架内有效实现。为促进未来研究,我们开源了完整的训练代码和配方,为社区提供可扩展且可访问的途径以推进大规模推理模型。
8. 局限性与未来工作
尽管有效,FIPO仍有某些局限性:
成本与效率。 主要约束是与扩展推理序列相关的计算成本增加。随着FIPO成功解锁超过10,000 token的CoT长度,训练和推理开销显著增长,对资源受限的部署构成挑战。我们认为高级推理的发展应是一个顺序过程:首先激发长、高质量的推理能力,随后优化其效率。虽然本文专注于第一阶段(突破长度停滞以实现卓越性能),但将这些长推理路径转化为更简洁高效形式的任务是关键的下一步。我们将留待未来探索。
任务泛化。 另一个局限性是我们的评估主要在数学推理基准上进行。然而,我们认为数学是深度推理的严格且具有代表性的代理;其对客观、可验证的真实答案和高密度逻辑一致性的要求使其成为我们算法最具挑战性的测试平台。在证明FIPO能在这一挑战性领域克服长度停滞之后,我们将其他开放域或结构化程度较低领域中这些激发行为的探索和验证留待未来工作。
训练数据范围。 为确保与基线的严格和公平比较,我们将训练严格限制在DAPO使用的数据集上。因此,我们尚未探索FIPO在更大规模或更高质量数据集上的可扩展性。虽然这种受控设置有助于隔离我们方法的算法贡献,但FIPO在更广泛或更多样化数据分布上的潜力仍是未知领域。此外,虽然FIPO在数学基准上实现了优于o1-mini的性能,但这种优势本质上是领域特定的。鉴于我们的训练严格限制在数学数据集上,我们不预期这些收益能泛化到非数学领域(如编程或符号逻辑),其中o1-mini受益于大规模多阶段强化学习。因此,我们将探索FIPO在更广泛数据机制中的泛化及其基本扩展特性留待未来工作。
有限模型范围。 我们研究的核心目标是调查从没有长思维链合成数据先验的干净基础模型开始的RL驱动推理。这种对实验纯度的严格要求显著限制了合适主干模型的选择。大多数当代针对推理优化的开源模型已经过广泛的监督微调(SFT)或从长形式推理轨迹中蒸馏。我们认为,直接从原始基础模型激发推理的底层训练动态与进一步优化已内化蒸馏推理模式的模型存在根本不同。因此,我们的模型选择仅限于少数高质量原始基础模型(如Qwen2.5系列),以确保我们的发现专门表征固有推理潜力的出现,而非预蒸馏CoT行为的精炼。在未来工作中,我们计划调查该算法应用于此类预蒸馏长思维链模型时的效能和机制行为,探索稠密优势表述是否能进一步精炼或与现有蒸馏推理能力产生协同。
与蒸馏的性能差距。 虽然基于RL的自我演化显著增强了推理,但它本质上是一个“基于发现”的过程,效率低于直接蒸馏。更大的教师模型提供密集得多的监督信号和优越的启发式(logits),这些是小模型仅通过稀疏奖励难以自我推导的,导致自训练和蒸馏变体之间存在持续的性能差距。
9. 贡献
核心贡献者:Chiyu Ma, Shuo Yang
贡献者:Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang
监督:Bolin Ding, Soroush Vosoughi, Guoyin Wang, Jingren Zhou
机构:1 达特茅斯学院 2 北京大学 3 多伦多大学 4 南加州大学 5 Qwen Pilot Team 6 阿里巴巴
附录目录
- A. 参数设置
- B. Qwen2.5-7B-Math 上的结果
- C. 消融研究
- D. 案例研究
- E. 失败试验与复现讨论
- F. 训练成本的更多细节
A. 参数设置
我们详细列出了用于微调 Qwen2.5-32B-Base 和 Qwen2.5-7B-Math 的具体超参数配置。我们的工作始于 DAPO 公开的训练脚本。为确保完全可复现,我们将连同实验所使用的训练脚本一起发布完整的代码库。
A.1 Qwen2.5-32B-Base
我们使用 512512512 的全局批次大小进行训练,每个提示的采样组大小为 G=16G=16G=16。模型使用 1×10−61 \times 10^{-6}1×10−6 的学习率和 0.10.10.1 的权重衰减进行优化。对于 FIPO 的特定参数,我们将 Future-KL 衰减率设置为 32.032.032.0,并采用 10.010.010.0 的安全阈值来过滤极端影响权重。策略更新受到 [0.2,0.28][0.2, 0.28][0.2,0.28] 非对称裁剪比例的限制。为支持广泛的推理链,最大响应长度设置为 20,48020,48020,480 个 token。我们方法与 DAPO 的详细超参数对比见表 2。
表 2:Qwen2.5-32B-Base 实验的超参数设置。 我们将提出的 FIPO 与 DAPO 基线进行配置对比。为确保公平比较,大多数基础设施与优化设置保持一致。
| 超参数 | DAPO (基线) | FIPO (本文) |
|---|---|---|
| 共享优化设置 | ||
| 基础模型 | Qwen2.5-32B-Base | Qwen2.5-32B-Base |
| 全局批次大小 | 512512512 | 512512512 |
| 组大小 (GGG) | 161616 | 161616 |
| 学习率 | 1×10−61 \times 10^{-6}1×10−6 | 1×10−61 \times 10^{-6}1×10−6 |
| 学习率调度器 | 常数,含 10 步预热 | 常数,含 10 步预热 |
| 权重衰减 | 0.10.10.1 | 0.10.10.1 |
| 梯度裁剪 | 1.01.01.0 | 1.01.01.0 |
| 最大提示长度 | 2,0482,0482,048 | 2,0482,0482,048 |
| 最大响应长度 | 20,48020,48020,480 | 20,48020,48020,480 |
| 超长缓冲 | 409640964096 | 409640964096 |
| 采样温度 / Top-p | 1.0/1.01.0 / 1.01.0/1.0 | 1.0/1.01.0 / 1.01.0/1.0 |
| 双重裁剪比例 | 10.010.010.0 | 10.010.010.0 |
| 策略裁剪比例 | [0.2,0.28][0.2, 0.28][0.2,0.28] (非对称) | [0.2,0.28][0.2, 0.28][0.2,0.28] (非对称) |
| KL 惩罚系数 | 0.00.00.0 | 0.00.00.0 |
| 方法特定设置 | ||
| 小批次大小 | 323232 | 646464 |
| 损失函数 | DAPO | Future-KL |
| Future-KL 衰减率 | - | 32.032.032.0 |
| Future-KL 裁剪比例 | - | [1.0,1.2][1.0, 1.2][1.0,1.2] |
| 安全阈值 | - | 10.010.010.0 |
A.2 Qwen2.5-7B-Math
在扩展至 32B32B32B 参数规模之前,我们首先在 Qwen2.5-7B-Math 上初步验证了该方法的有效性,作为试点研究。在这一初步阶段,我们观察到训练性能初期存在波动,且独立运行间的推理性能提升复现性不一致。为解决这些稳定性问题,我们将组大小增加到 G=32G=32G=32 以提供更稳定的优化信号,并强制执行更严格的优势裁剪阈值 3.03.03.0,以过滤掉导致不稳定的更新。这些调整成功稳定了训练轨迹,在保持相同性能水平的同时使结果更加可靠。模型使用 1×10−61 \times 10^{-6}1×10−6 的学习率和 0.10.10.1 的权重衰减进行优化,Future-KL 衰减率设置为 32.032.032.0。在这些试点实验稳定后,我们将已验证的框架扩展至 32B32B32B 模型。7B7B7B 超参数设置的摘要见表 3,7B7B7B MATH 实验的详细结果见 B 节。
表 3:Qwen2.5-7B-Math 实验的超参数设置。 我们将提出的 FIPO 与 DAPO 基线进行配置对比。为确保公平比较,大多数基础设施与优化设置保持一致。
| 超参数 | DAPO (基线) | FIPO (本文) |
|---|---|---|
| 共享优化设置 | ||
| 基础模型 | Qwen2.5-7B-MATH | Qwen2.5-7B-MATH |
| 全局批次大小 | 512512512 | 512512512 |
| 学习率 | 1×10−61 \times 10^{-6}1×10−6 | 1×10−61 \times 10^{-6}1×10−6 |
| 学习率调度器 | 常数,含 10 步预热 | 常数,含 10 步预热 |
| 权重衰减 | 0.10.10.1 | 0.10.10.1 |
| 梯度裁剪 | 1.01.01.0 | 1.01.01.0 |
| 最大提示长度 | 2,0482,0482,048 | 2,0482,0482,048 |
| 采样温度 / Top-p | 1.0/1.01.0 / 1.01.0/1.0 | 1.0/1.01.0 / 1.01.0/1.0 |
| 双重裁剪比例 | 10.010.010.0 | 10.010.010.0 |
| 策略裁剪比例 | [0.2,0.28][0.2, 0.28][0.2,0.28] (非对称) | [0.2,0.28][0.2, 0.28][0.2,0.28] (非对称) |
| KL 惩罚系数 | 0.00.00.0 | 0.00.00.0 |
| 方法特定设置 | ||
| 小批次大小 | 323232 | 646464 |
| 损失函数 | DAPO | Future-KL |
| Future-KL 衰减率 | - | 32.032.032.0 |
| Future-KL 裁剪比例 | - | [0.8,1.2][0.8, 1.2][0.8,1.2] |
| 安全阈值 | - | 3.03.03.0 |
| 组大小 (GGG) | 161616 | 323232 |
| 最大响应长度 | 819281928192 | 102401024010240 |
| 超长缓冲 | 409640964096 | 204820482048 |
B. Qwen2.5-7B-Math 上的结果
本节记录了在 Qwen-2.5 7B MATH 模型上的实验结果。由于 32B32B32B 模型的计算成本极高,我们的大部分早期探索和消融实验均使用该变体进行。如第 3.2 节所述,7B7B7B 模型在不同训练配置下表现出明显的性能敏感性。为解决此问题,我们进行了针对性的超参数调整以稳定训练动态,并确保观察到的趋势具有可靠性。请注意,遵循 DAPO verl 脚本的指示,我们将上下文窗口从 409640964096 扩展至 327683276832768。
B.1 性能表现
表 4 展示了不同基于 RL 的方法在 AIME 2024 和 AIME 2025 基准上的 Pass@1 性能对比分析。我们提出的 FIPO(7B) 在 AIME 2024 上取得了 40.0%40.0\%40.0% 的显著性能,大幅优于 GRPO(7B) 基线 (22.0%22.0\%22.0%) 和 DAPO(7B) 方法 (36.0%36.0\%36.0%)。然而,我们观察到在 AIME 2025 基准上存在普遍的性能压缩现象。尽管 FIPO 仍以 19.0%19.0\%19.0% 保持领先,但三种方法之间的性能差距相较于 AIME 2024 的结果显著缩小。这一现象主要归因于 AIME 2025 问题极高的内在难度及其“新题”特性,在没有外部引导的情况下,这些问题似乎已逼近 7B7B7B 参数模型的推理天花板。在此规模下,尤其是在缺乏对更高级思维链结构进行预训练的情况下,AIME 2025 所需推理链复杂度的增加使得区分不同优化算法的边际收益变得困难,因为大多数模型都遇到了类似的结构瓶颈。
表 4:Qwen 2.5-7B-MATH 在 AIME2024 和 AIME2025 上 Pass@1 性能对比。 所有结果均以百分比 (%\%%) 报告。我们报告 32 个样本的平均峰值 Pass@1 (Avg@32)。为降低对数字级生成方差的敏感性,最终值四舍五入至最接近的整数。
| 方法 | AIME 2024 (Pass@1) | AIME 2025 (Pass@1) |
|---|---|---|
| GRPO (Guo et al., 2025) | 22.0%22.0\%22.0% | 18.0%18.0\%18.0% |
| DAPO | 36.0%36.0\%36.0% | 18.0%18.0\%18.0% |
| FIPO (本文) | 40.0%40.0\%40.0% | 19.0%19.0\%19.0% |
B.2 结果分析
如图 6 所示,两种算法均保持了稳定的长度加权平均优势,且平均响应长度在 120012001200 个 token 左右波动。值得注意的是,这与 32B32B32B 模型的训练形成鲜明对比,在后者中 FIPO 通常会触发响应长度的持续增长。我们假设这种长度停滞并非优化失败,而是反映了 7B7B7B 模型固有的容量限制和训练先验。具体而言,Qwen-2.5 7B MATH 基座是在受限的 4K4K4K 上下文窗口下预训练的 (Yang et al., 2024),这可能在无外部引导的情况下对其推理深度施加了物理上限。此外,该模型对基于代码的推理具有强烈的初始偏好 (Shao et al., 2025),这种偏好倾向于逻辑密集、确定性的路径而非冗长的探索,再加上潜在的 AIME24 数据泄露 (Wu et al., 2025b),提供了“高置信度捷径”,使模型能够快速得出简洁的解决方案,而不是探索更长、迭代的路径。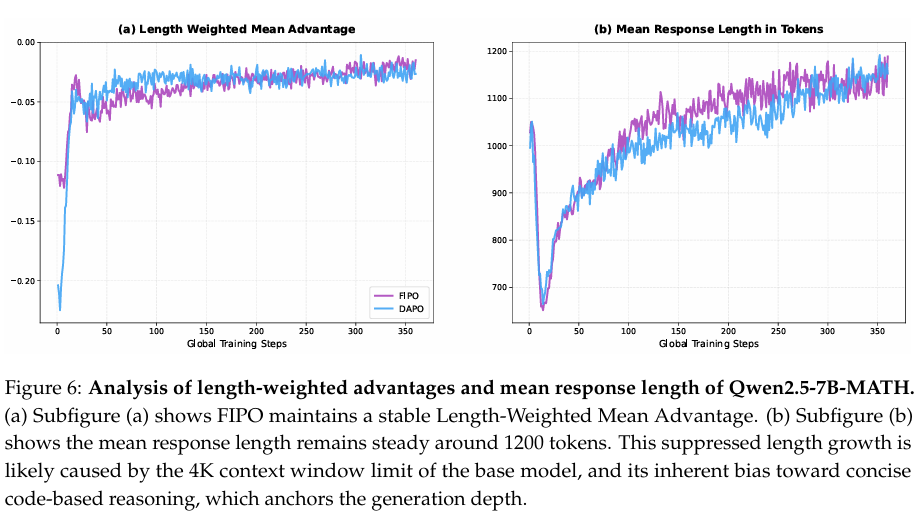
图 7© 所示的熵动态进一步证实了这种“高效但受限”的推理现象。虽然较大规模的模型通常依赖持续的熵增长来探索复杂的推理空间,但 7B7B7B MATH 模型在 FIPO 下通过收敛到显著更低熵的策略来实现最优性能。这种差异表明了缩放行为的根本区别:32B32B32B 模型从广泛探索中受益,而 7B7B7B 模型似乎优先考虑精炼特定的、高置信度的推理流形。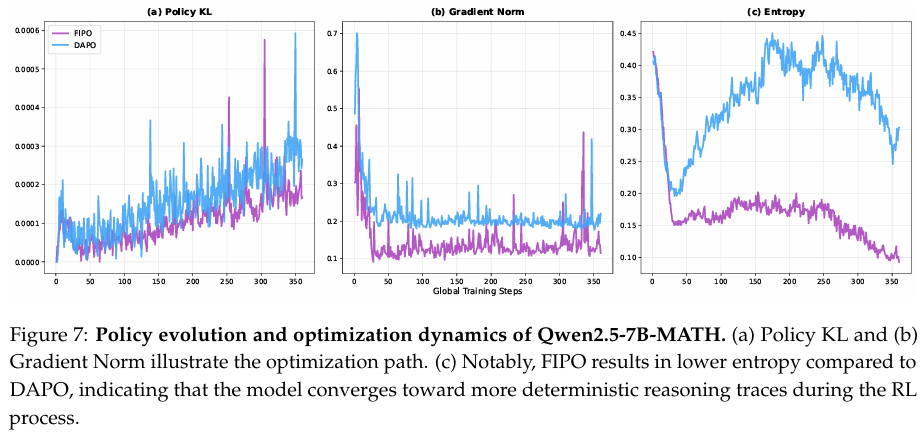
关于低熵状态对该规模性能至关重要的假设,得到了我们对 Future-KL 影响权重裁剪消融研究的进一步支持。如附录 C 所述,7B7B7B 和 32B32B32B 模型对 Future-KL 裁剪范围表现出不同的敏感性。虽然 32B32B32B 模型在影响权重裁剪于 [1.0,1.2][1.0, 1.2][1.0,1.2] 时保持了优越的性能,但将此相同范围应用于 7B7B7B 模型会导致熵持续增加(类似于 32B32B32B 模型的行为),却导致性能显著下降。相反,我们发现 7B7B7B 模型在应用 [0.8,1.2][0.8, 1.2][0.8,1.2] 裁剪范围的不同机制下表现最优。这一观察表明,7B7B7B 模型可能缺乏足够的内在自我探索能力来从高熵状态中获益。在此机制下,维持较高熵似乎会引入更多有害噪声而非有益发现。因此,在此规模下,当模型收敛到特定的低熵推理轨迹时,最有可能获得卓越性能。这一现象从根本上符合熵最小化 (Agarwal et al., 2025)、熵调节 (Wu et al., 2025a)、自我引导 (Zuo et al., 2025) 和自我确定性优化 (Zhao et al., 2025) 的原则,这些原则通常在类似规模的模型中被证明是有效的。
C. 消融研究
本节全面分析了为验证我们方法而进行的消融研究。我们首先考察在 FIPO 训练 32B32B32B 模型期间,高值裁剪和最大响应长度扩展对最终平均响应长度的影响。接下来,我们展示 7B7B7B 模型规模上关于权重过滤的结果,这补充了我们在 32B32B32B 实验中观察到的与稳定性相关的发现。此外,我们研究了各种自适应裁剪配置的含义及其对性能的影响,特别强调这些选择如何驱动策略熵的差异化行为。最后,我们评估优化过程对不同衰减率选项的敏感性及其对收敛动态的潜在影响。
C.1 Clip-High、最大长度与响应长度
我们观察到的最有趣的现象之一是,在早期阶段调高 PPO 目标的 ϵhigh\epsilon_{high}ϵhigh 裁剪比例时,响应长度出现了意外的激增。在本研究中,我们将 ϵhigh\epsilon_{high}ϵhigh 设置为 1.41.41.4,在优势为正时为策略更新提供更大的信任区域。对于最大长度试验,我们将限制扩展至 25K25K25K 个 token(默认值为 20K20K20K),同时将超长缓冲保持在一致的 20%20\%20% 比例。所有其他变量保持一致以确保公平比较。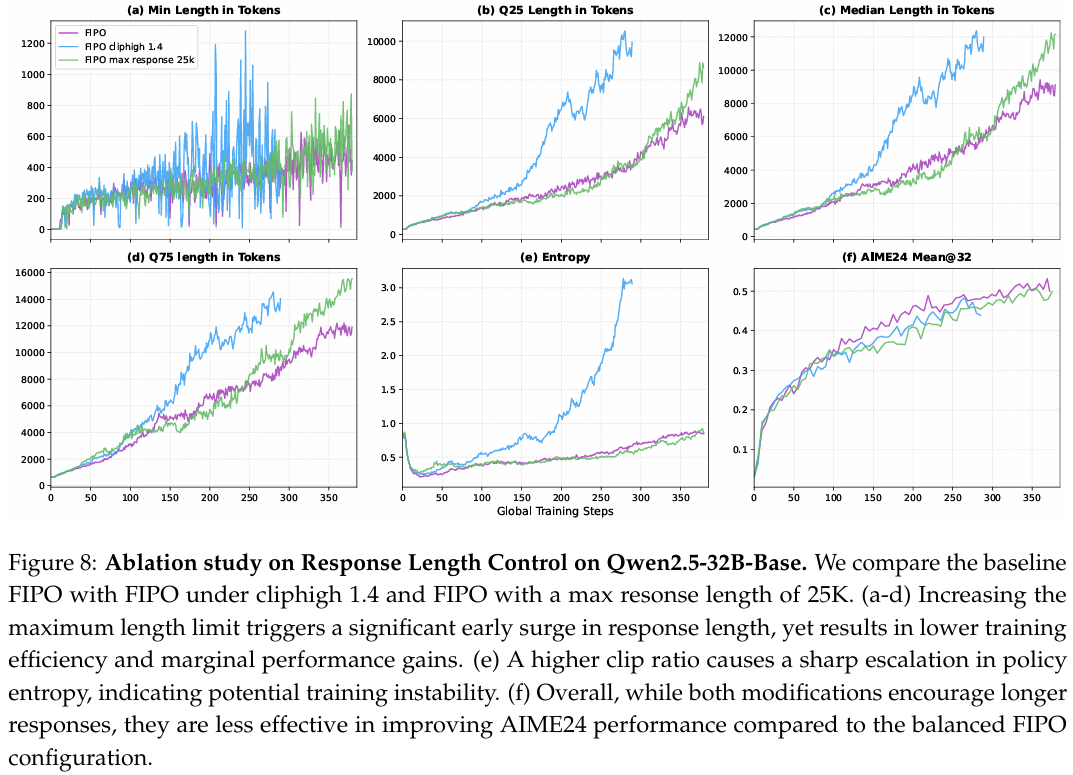
如图 8(a-d) 所示,较高的 ϵhigh\epsilon_{high}ϵhigh 允许策略在接收到正优势时更激进地偏离旧分布,激励模型几乎立即“过度探索”更长的推理路径。然而,这种激增是以训练稳定性为代价的;如图 8(e) 所示,在较高的 ϵhigh\epsilon_{high}ϵhigh 下策略熵爆炸,表明当裁剪约束过于宽松时优化景观变得不稳定。
当增加最大响应长度限制时,观察到一种惊人相似的失败模式。虽然这也触发了 token 数量的快速增长,但它揭示了推理效率的明显收益递减。两种情况都受到表面推理行为的困扰,例如重复内容、与任务无关的 LaTeX 格式以及过早的自我反思。我们认为,当模型尚未建立坚实的单步推理基础时,引入自我反思可能会适得其反。在这种情况下,模型缺乏评估自身状态所需的可验证内部逻辑,导致内部一致性冲突,即模型在相互矛盾的步骤之间振荡而无法朝着正确解推进。这些观察表明,诸如自我反思之类的高阶推理模式的出现,在训练过程中并不一定是“越早越好”。相反,它应该是一个渐进成熟的过程,其中复杂策略建立在稳定的基本逻辑基础之上。因此,AIME24 的性能提升(图 8f)与平衡的 FIPO 基线相比是微乎其微的。这些结果强调了受控的响应长度增长的重要性,确保扩展的计算被分配给真正的逻辑深度,而非冗余的自我纠正循环。
图 8 说明: Qwen2.5-32B-Base 上响应长度控制的消融研究。我们将基线 FIPO 与 ϵhigh=1.4\epsilon_{high}=1.4ϵhigh=1.4 的 FIPO 以及最大响应长度为 25K25K25K 的 FIPO 进行比较。(a-d) 增加最大长度限制触发了响应长度的显著早期激增,但导致训练效率降低和边际性能提升。(e) 较高的裁剪比例导致策略熵急剧升级,表明潜在的训练不稳定性。(f) 总体而言,虽然两种修改都鼓励更长的响应,但在提升 AIME24 性能方面不如平衡的 FIPO 配置有效。
C.2 极值过滤
如 4.2 小节所述,由于 Future-KL 的计算高度依赖于每次更新之间的 logit 值,其缺点之一是对重要性比率波动的敏感性。如果重要性比率的变化变得显著,Future-KL 权重也会同时变得高度不稳定。Future-KL 项未能提供稳定的策略更新指导信号,而是引入了过多的噪声。在这种情况下,结合未来 KL 信息可能导致更不稳定的更新,且模型的性能倾向于回退到接近标准基线的次优水平,而未显示出预期的改进。这在重要性比率频繁波动的 7B7B7B 模型中尤为明显。
表 5 展示了 7B7B7B 模型上的消融结果。我们观察到,在不过滤极端重要性采样 (IS) 比率的情况下,AIME2024 的性能增益次优,不如应用过滤的配置。尽管未过滤版本在某一实例中在 AIME2025 上取得了略高的分数,但 AIME2024 的整体可靠性与峰值性能 (40.0%40.0\%40.0%) 以及我们在 32B32B32B 训练中的观察结果,均证实了过滤机制对于更可靠训练的必要性。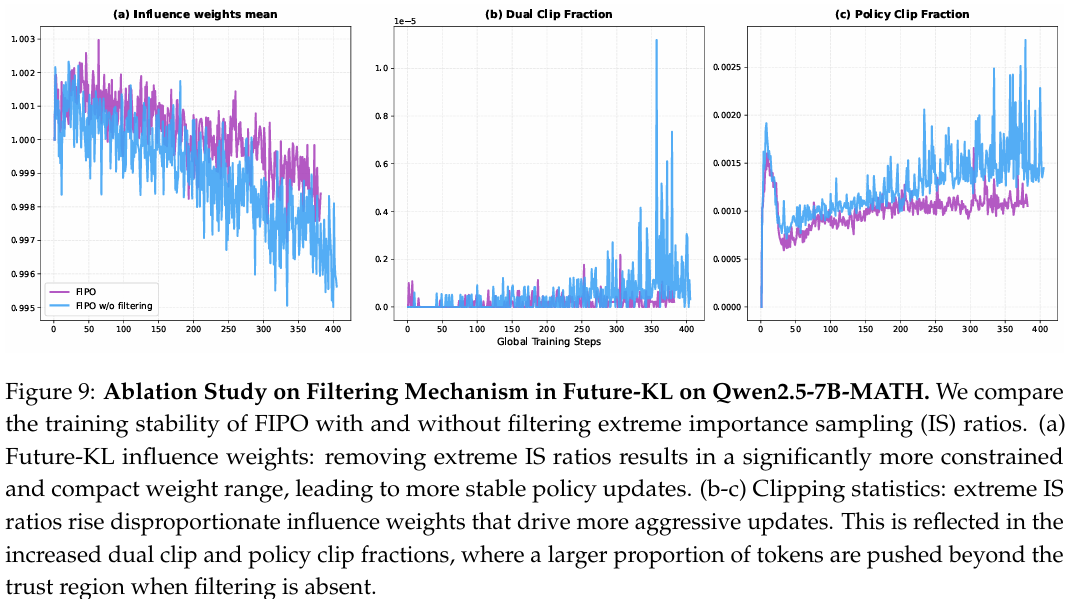
此外,如图 9(a) 所示,移除极端 IS 比率会导致权重范围显著更受约束和紧凑,从而为优势估计器提供更稳定的信号。相反,缺乏过滤会导致不成比例的巨大影响权重。这导致更频繁的策略激进更新,如图 9(b) 和 © 中的裁剪分数所示。当缺乏过滤时,更大比例的 token 被推至指定的信任区域之外,导致双重裁剪和策略裁剪分数升高。这表明模型频繁尝试进行超出 PPO 目标约束的更新,从而解释了当 IS 比率波动较高时性能增益次优的原因。
表 5:Qwen2.5-7B-MATH 上极值过滤与影响权重裁剪的消融实验 Pass@1 性能对比。
| 方法 | AIME 2024 (Pass@1) | AIME 2025 (Pass@1) |
|---|---|---|
| FIPO (ϵflow=1.0,ϵfhigh=1.2\epsilon_{f_{low}}=1.0, \epsilon_{f_{high}}=1.2ϵflow=1.0,ϵfhigh=1.2) | 36.0%36.0\%36.0% | 19.0%19.0\%19.0% |
| FIPO (无过滤, ϵflow=0.8,ϵfhigh=1.2\epsilon_{f_{low}}=0.8, \epsilon_{f_{high}}=1.2ϵflow=0.8,ϵfhigh=1.2) | 38.0%38.0\%38.0% | 21.0%21.0\%21.0% |
| FIPO (ϵflow=0.8,ϵfhigh=1.2\epsilon_{f_{low}}=0.8, \epsilon_{f_{high}}=1.2ϵflow=0.8,ϵfhigh=1.2) | 40.0%40.0\%40.0% | 19.0%19.0\%19.0% |
图 9 说明: Qwen2.5-7B-MATH 上 Future-KL 过滤机制的消融研究。我们比较了过滤与不过滤极端重要性采样 (IS) 比率时 FIPO 的训练稳定性。(a) Future-KL 影响权重:移除极端 IS 比率会导致权重范围显著更受约束和紧凑,从而带来更稳定的策略更新。(b-c) 裁剪统计:极端 IS 比率会推高不成比例的影响权重,从而驱动更激进的更新。这反映在双重裁剪和策略裁剪分数的增加上,表明在缺乏过滤时,更大比例的 token 被推至信任区域之外。
C.3 影响权重裁剪
表 5 展示了影响权重裁剪的消融结果。我们主要修改了相对于 111 的裁剪范围。范围在 [1.0,1.2][1.0, 1.2][1.0,1.2] 的影响权重本质上对负样本提供更多惩罚,对正样本提供更多奖励。[0.8,1.2][0.8, 1.2][0.8,1.2] 的范围继承了这些特性,同时提供了更平衡的影响;当正样本中的 token 与后续负向行为关联时,它进一步降低奖励;当负样本中的 token 与后续正向行为关联时,它降低惩罚。这有助于提供更受控的探索,从而实现了表 5 所示的性能提升。
具体而言,[0.8,1.2][0.8, 1.2][0.8,1.2] 配置在 AIME 2024 上达到 40.0%40.0\%40.0%,超过了 [1.0,1.2][1.0, 1.2][1.0,1.2] 设置的 36.0%36.0\%36.0%。虽然后者鼓励更激进的探索(如图 10(a) 所示策略熵的持续增长),但我们的结果表明 7B7B7B 模型对这种过度的探索压力很敏感。这与我们关于缩放行为的广泛观察相一致:与从广泛探索中受益的较大模型不同,7B7B7B 模型似乎优先考虑精炼特定的高置信度推理流形。在此背景下,[1.0,1.2][1.0, 1.2][1.0,1.2] 范围引起的较高熵引入了更多有害噪声而非有益发现。相比之下,[0.8,1.2][0.8, 1.2][0.8,1.2] 的平衡影响促进了向更低熵状态的收敛,优化了自我确定性而非随机搜索。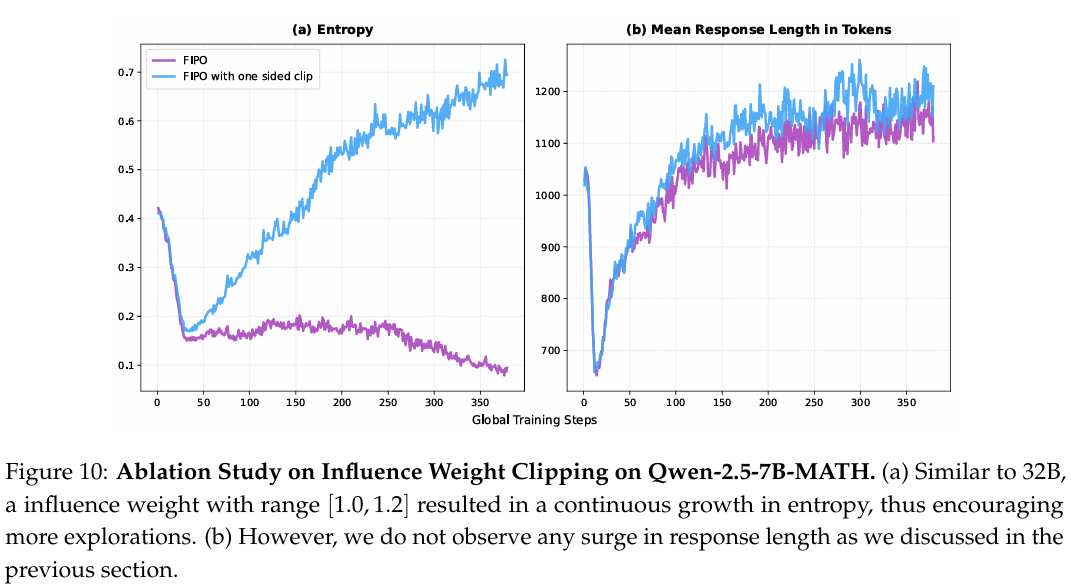
图 10 说明: Qwen-2.5-7B-MATH 上影响权重裁剪的消融研究。(a) 与 32B32B32B 类似,范围在 [1.0,1.2][1.0, 1.2][1.0,1.2] 的影响权重导致熵持续增长,从而鼓励更多探索。(b) 然而,我们并未观察到如前文所述的响应长度激增。
C.4 衰减率的有效视界
作为补充分析,我们进一步对衰减率的有效视界进行了消融研究,具体测试了 τ∈{8,32,128,256}\tau \in \{8, 32, 128, 256\}τ∈{8,32,128,256} 的值。这些值定义了影响权重衰减的半衰期,决定了未来 KL 信息保持显著的 token 距离。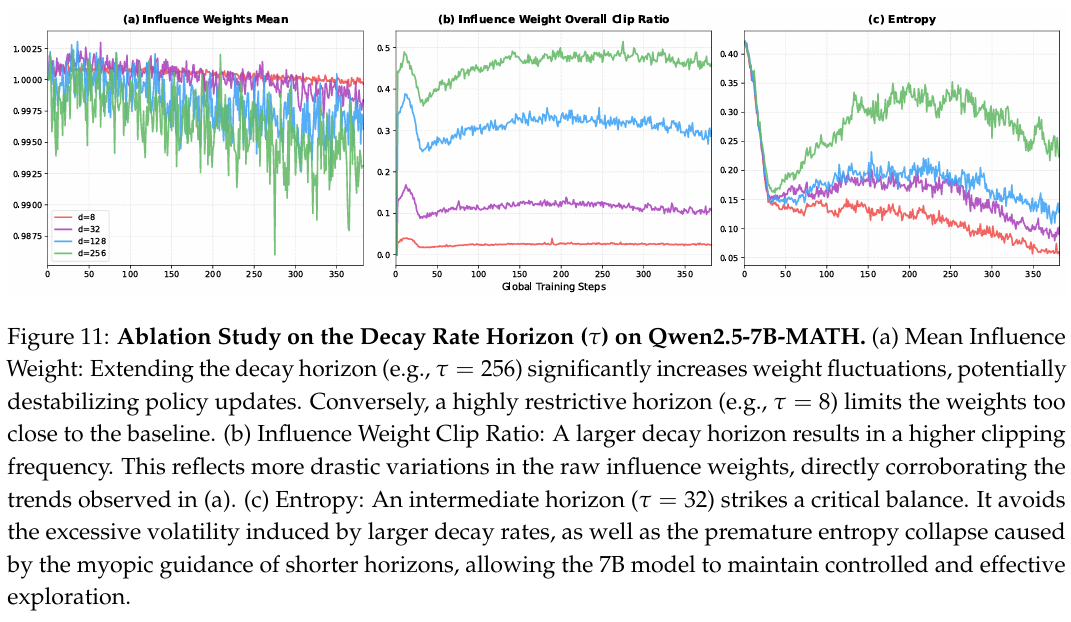
表 6 展示了这些配置下的性能,图 11 说明了相应的训练动态。如图 11(a) 所示,平均影响权重的波动幅度随着衰减视界 τ\tauτ 的延长而增加。对于最大视界 (τ=256\tau=256τ=256),权重均值表现出偏离 1.01.01.0 的最大偏差,这可能会引入策略更新的不稳定性。相反,对于非常小的视界 (τ=8\tau=8τ=8),影响权重高度接近 1.01.01.0,实质上导致模型保持接近基线,相对未充分利用未来 KL 信息。
图 11© 中的熵动态进一步证实了我们之前关于 7B7B7B 模型探索能力的观察。虽然所有配置都遵循先下降、后上升、最终下降的特征趋势,但较大衰减率的整体熵水平明显更高。τ=256\tau=256τ=256 设置在大部分训练期间保持最高熵,表明由长期未来信号驱动的激进探索。正如我们在限制性 [1.0,1.2][1.0, 1.2][1.0,1.2] 影响权重范围中观察到的那样,这种持续的高熵状态引入了 7B7B7B 模型难以应对的过度波动。相反,τ=8\tau=8τ=8 设置中观察到的熵快速下降代表了完全不同的失败模式:由于其影响权重仅微小波动,模型接收到高度短视的指导。缺乏足够的长期前瞻性,策略过早崩溃进入次优的低熵状态。中间视界 τ=32\tau=32τ=32 取得了关键平衡。类似于 [0.8,1.2][0.8, 1.2][0.8,1.2] 裁剪范围的稳定效果,τ=32\tau=32τ=32 提供了足够的局部未来信号以安全地引导更新,而不会导致过早停滞,允许策略最终收敛到特定的高质量推理流形。不同超参数之间的这种一致性巩固了我们的假设:在 7B7B7B 等较小规模下,通过受控的适度探索优化自我确定性,比强制进行广泛的高熵搜索更为有效。
表 6:Qwen2.5-7B-MATH 上衰减率有效视界的消融实验 Pass@1 性能对比。
| 方法 | AIME 2024 (Pass@1) | AIME 2025 (Pass@1) |
|---|---|---|
| FIPO (τ=8\tau=8τ=8) | 40.0%40.0\%40.0% | 17.0%17.0\%17.0% |
| FIPO (τ=32\tau=32τ=32) | 40.0%40.0\%40.0% | 19.0%19.0\%19.0% |
| FIPO (τ=128\tau=128τ=128) | 39.0%39.0\%39.0% | 21.0%21.0\%21.0% |
| FIPO (τ=256\tau=256τ=256) | 42.0%42.0\%42.0% | 16.0%16.0\%16.0% |
图 11 说明: Qwen2.5-7B-MATH 上衰减率视界 (τ\tauτ) 的消融研究。(a) 平均影响权重:延长衰减视界(例如 τ=256\tau=256τ=256)会显著增加权重波动,可能 destabilize 策略更新。相反,高度限制的视界(例如 τ=8\tau=8τ=8)将权重限制得过于接近基线。(b) 影响权重总体裁剪比例:较大的衰减视界导致更高的裁剪频率。这反映了原始影响权重更剧烈的变化,直接证实了 (a) 中观察到的趋势。© 熵:中间视界 (τ=32\tau=32τ=32) 取得了关键平衡。它避免了较大衰减率引起的过度波动,以及较短视界短视指导导致的过早熵崩溃,允许 7B7B7B 模型保持受控且有效的探索。
D. 案例研究
本节通过检查 AIME 2024 竞赛中的具体输出,对模型的推理演化进行定性分析。我们从分组样本中随机选择响应。从 DAPO 的长度停滞到 FIPO 的持续扩展的过渡,不仅仅是 token 数量的定量变化,更是模型如何利用其“思考”预算的定性转变。
阶段 1:表面规划(初始阶段)。 如图 13 所示,模型在初始阶段表现出“表面规划”行为。它生成类似模板的解决方案步骤大纲,但未能执行实际的数学推导。这导致响应简短且缺乏逻辑实质,通常会导致立即的幻觉结论。
阶段 2:线性执行(DAPO 收敛与 FIPO 早期)。 在其整个训练持续时间内,DAPO 始终处于此阶段(图 14),演变为能够准确遵循标准思维链 (CoT) 以达到真实答案的“线性执行器”。然而,其推理本质上局限于“单次通过”逻辑,一旦找到第一个结果生成即终止。这解释了图 3 中 DAPO 观察到的长度停滞。
阶段 3:涌现的自我反思(FIPO 中期)。 随着 FIPO 训练进展到中期(图 15),出现了明显的行为转变。模型开始利用扩展的 token 预算(响应长度增长)进行自发的自我反思。在得出初始结果后,模型主动启动验证阶段,探索替代方法,例如从代数运算切换到几何解释,以交叉验证其发现。
阶段 4:系统性深度推理(FIPO 后期)。 在训练的后期阶段(图 16),模型成熟为一种优先考虑分析深度的“计算密集型”策略。推理轨迹超越了简单的反思,进入系统性审计。模型执行多轮符号重推导和细粒度算术验证(例如,逐步手动展开大平方和平方根)。这种自我验证的自发出现与先进推理模型中观察到的推理时扩展行为相一致,模型将长度视为确保更好性能的重要资源。
E. 失败试验与复现讨论
如前所述,我们出于相对稳定性考虑,在 32B32B32B 模型训练及后续实验中使用了 646464 的小批次大小,而非 323232。为更好地理解此参数选择,我们在此详细说明在使用 323232 小批次大小时遇到的具体训练结果和问题。如图 12(a) 所示,虽然 323232 的小批次大小偶尔能产生强劲的性能,但它存在严重的复现性问题。最突出的失败模式是长度增长的严重减速,模型难以有效扩展到更长的推理轨迹。值得注意的是,简单地移除超长惩罚无法解决此瓶颈,这表明问题源于更深层的优化动态,而非直接的奖励惩罚。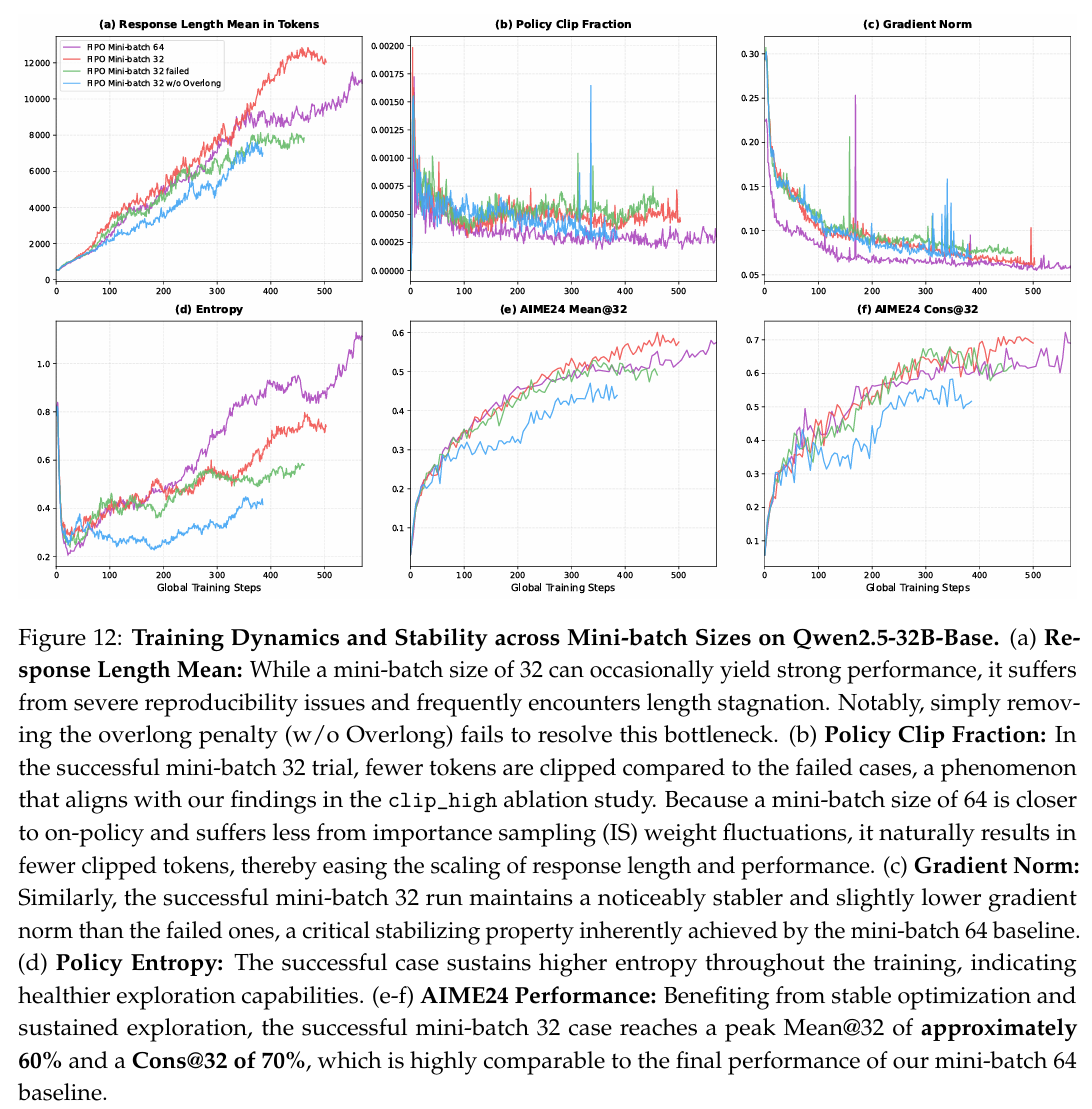
我们通过我们在 clip_high 消融研究中识别出的底层原理进一步解释这些发现(见 C.1 小节)。虽然该消融研究侧重于裁剪阈值而非小批次大小,但它揭示了一个核心优化动态:当更多 token 有效参与策略更新而不受裁剪边界限制时,模型获得扩展响应长度的显著动量。检查策略裁剪分数(图 12(b)),我们观察到成功的 323232 小批次试验比失败案例裁剪的 token 相对更少。我们推断,当重要性采样 (IS) 权重波动减少时,相对更大比例的 token 保持未裁剪状态并被完全纳入训练信号。这种有效纳入对于克服上述长度增长减速极为有益。因为 646464 的小批次大小在更广泛的样本集上计算梯度,它本质上更接近 on-policy 策略,受 IS 方差的影响更小。因此,它自然地避免了过度的 token 裁剪,提供了平滑扩展推理长度和性能所需的持续优化动量。
优化稳定性的差异在梯度范数和策略熵中也显而易见。如图 12© 所示,成功的 323232 小批次运行比失败运行保持了明显更稳定且略低的梯度范数。此外,它在整个训练过程中维持了更高的熵(图 12(d)),表明更健康、更有效的探索能力,而没有异常发散。至关重要的是,这些稳定特性(受控的梯度更新和持续、积极的探索)是由 646464 小批次基线内在实现的,无需依赖较小批次大小的随机成功。最终,受益于稳定的优化和一致的探索,成功的 323232 小批次案例达到约 60%60\%60% 的峰值 Mean@32 和 70%70\%70% 的 Cons@32(图 12(e-f))。这些指标与我们 646464 小批次基线的一致性能高度相当。因此,我们采用 646464 小批次大小并非由更高的理论性能上限驱动,而是由其可靠地将策略导航至高质量推理流形而不陷入优化陷阱的能力所驱动。
将此现象与现有的自适应裁剪技术 (Xi et al., 2025; Gao et al., 2025) 区分开来至关重要。虽然自适应裁剪主要动态调整阈值以维持信任区域稳定性并防止策略崩溃,但我们的发现强调了一种根本不同的机制:有效裁剪分数充当了长度扩展的结构阀门。通过使用 646464 的小批次大小自然稳定 IS 权重,我们允许更大比例的有效 token 安全地通过固定边界。此外,正是在这些稳定的优化条件下,我们提出的 Future KL 机制才能充分发挥其作为推理训练主要驱动力的预期效果。根据设计,Future KL 结合前瞻性信号来引导当前 token 更新,从而自然鼓励扩展推理轨迹的探索。然而,该机制本质上依赖于跨长序列的连续且完整的梯度流。稳定的 IS 权重提供了这一确切基础:通过防止过度的 token 截断,它确保 Future KL 的长期探索信号成功且平滑地反向传播,而不会被人造中断。在这种不受阻碍的优化动量支持下,Future KL 明确推动策略扩展至更深、更高质量的推理流形,有效防止模型崩溃回过早的短形式响应。
图 12 说明: Qwen2.5-32B-Base 上不同小批次大小的训练动态与稳定性。(a) 平均响应长度:虽然小批次 323232 偶尔能产生强劲性能,但存在严重的复现性问题并频繁遭遇长度停滞。值得注意的是,简单地移除超长惩罚 (w/o Overlong) 无法解决此瓶颈。(b) 策略裁剪比例:在成功的 323232 小批次试验中,被裁剪的 token 少于失败案例,这一现象与我们在 clip_high 消融研究中的发现相一致。因为小批次 646464 更接近 on-policy 且受重要性采样 (IS) 权重波动的影响更小,它自然导致更少的 token 被裁剪,从而缓解响应长度和性能的扩展。© 梯度范数:同样,成功的 323232 小批次运行比失败案例保持明显更稳定且略低的梯度范数,这是小批次 646464 基线内在实现的关键稳定特性。(d) 策略熵:成功案例在整个训练期间维持更高的熵,表明更健康的探索能力。(e-f) AIME24 性能:受益于稳定的优化和持续的探索,成功的 323232 小批次案例达到约 60%60\%60% 的峰值 Mean@32 和 70%70\%70% 的 Cons@32,与我们 646464 小批次基线的最终性能高度可比。
F. 训练成本的更多细节
Future KL 的朴素实现需要计算稠密的 (L,L)(L, L)(L,L) 时间衰减矩阵(其中 LLL 是响应长度),导致 O(L2)O(L^2)O(L2) 的内存占用,在长轨迹推理训练期间极易引发显存不足 (OOM) 错误。为缓解此问题,我们实现了如代码清单 1 所示的基于分块的内存高效算法。通过将响应序列划分为固定分块大小 (KKK) 的块,我们增量计算距离掩码和衰减权重。分块贡献通过形状为 (B,K)×(K,L)(B, K) \times (K, L)(B,K)×(K,L) 的并行矩阵乘法计算。该算法保留了 Future KL 公式的精确解析结果,同时将峰值内存复杂度严格限制在 O(B⋅L+L⋅K)O(B \cdot L + L \cdot K)O(B⋅L+L⋅K)。虽然时间复杂度仍为 O(B⋅L2)O(B \cdot L^2)O(B⋅L2),但张量化分块操作在现代 GPU 上高度优化,有效消除了扩展推理长度的内存瓶颈。
虽然标准 GRPO 使用严格逐元素操作计算策略目标,时间复杂度为 O(B⋅L)O(B \cdot L)O(B⋅L),但集成我们的 Future KL 机制自然引入了 O(B⋅L2)O(B \cdot L^2)O(B⋅L2) 的时间聚合过程。因此,这在 Actor 更新阶段施加了一定程度的计算开销。然而,我们的分块矩阵乘法实现有效地向量化了这些操作,重度利用了现代 GPU 高度优化的稠密 MatMul 能力。经验表明,GRPO 训练迭代期间的挂钟时间延迟相对微小且完全可接受。最重要的是,我们认为训练速度的这种适度权衡是合理的:它提供了扩展复杂推理所需的稠密、长视界信用分配,这是标准 O(B⋅L)O(B \cdot L)O(B⋅L) GRPO 本质上难以克服的根本瓶颈。自然地,虽然我们的分块实现有效解决了内存限制,但更复杂的计算优化仍然是可能的。
代码清单 1:计算内存高效分块 Future KL 的 Python 代码
import torch
def compute_future_kl_chunked(D, M, K, tau):
# 计算衰减因子
gamma = 2**(-1/tau)
# 掩蔽无效 token 和过滤的异常值
D = D * M
# 初始化 Future KL 累加器
F = torch.zeros_like(D)
L = D.shape[1]
# 查询位置的列向量 (L x 1)
i = torch.arange(L, device=D.device).unsqueeze(1)
for j_start in range(0, L, K):
j_end = min(j_start + K, L)
# 当前分块位置的行向量 (1 x K_cur)
j = torch.arange(j_start, j_end, device=D.device).unsqueeze(0)
# 广播距离矩阵 (L x K_cur)
Delta = j - i
# 衰减权重分块
W = (gamma**torch.clamp(Delta, min=0)) * (Delta >= 0).float()
# 提取当前分块的 KL 值
V = D[:, j_start:j_end]
# 并行矩阵乘法更新
F += torch.matmul(V, W.T)
return F

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)