基于LSTM长短期记忆神经网络的多输入多输出预测(Matlab实现)包括数据预处理与模型训练...
LSTM长短期记忆神经网络多输入多输出预测(Matlab) 所有程序经过验证,保证有效运行。 1.data为数据集,10个输入特征,3个输出变量。 2.MainLSTMNM.m为主程序文件。 3.命令窗口输出MAE和R2,
LSTM 多输入多输出预测系统
—— 从数据到可解释性指标的全链路自动化方案
一、定位与价值
在工业、能源、金融等时序场景里,往往同时存在「多维观测 → 多维目标」的预测需求:输入是 10 路传感器,输出是 3 路 KPI;不仅要求精度,还要求可解释、可复现、可迭代。传统“单输入单输出”脚本已无法承载工程化落地所需的完整闭环。本文介绍的方案用 1 个主脚本即可实现:数据清洗 → 样本构造 → 深度网络训练 → 反归一化还原 → 多指标评估 → 可视化报告,全流程零人工干预,为后续在线部署、超参搜索、AutoML 提供标准化基线。
二、系统架构概览
- 数据层
• 统一使用 Excel 作为“事实来源”,降低跨部门沟通成本。
• 随机乱序后按 500/100 切分训练/测试,既保证分布一致,又避免时序泄露。
- 预处理层
• 采用最小-最大归一化,将不同量纲输入压缩到 [0,1],使 LSTM 梯度处于稳定区间。
• 训练集与测试集共用同一变换参数,解决线下/线上分布漂移问题。
- 网络层
• 仅保留「输入 → LSTM → Dropout → 全连接 → 回归」五段式结构,兼顾速度与效果。
• 隐藏单元数、丢弃率、学习率等超参全部外置,方便后续 Optuna 网格搜索。
- 训练层
• 选用 Adam + Piecewise 退火,兼顾快速收敛与后期微调;批大小 30、最大 500 epoch 在 10 万级样本内即可收敛。
• 每次 epoch 重新打乱,抑制样本顺序带来的过拟合。
- 评估层
• 对 3 路输出分别计算 RMSE、MAE、MBE、R²,既看“误差大小”,也看“误差方向”,方便业务方判断系统性偏高/偏低。
• 所有指标在反归一化后计算,保证物理量纲可读。
- 可视化层
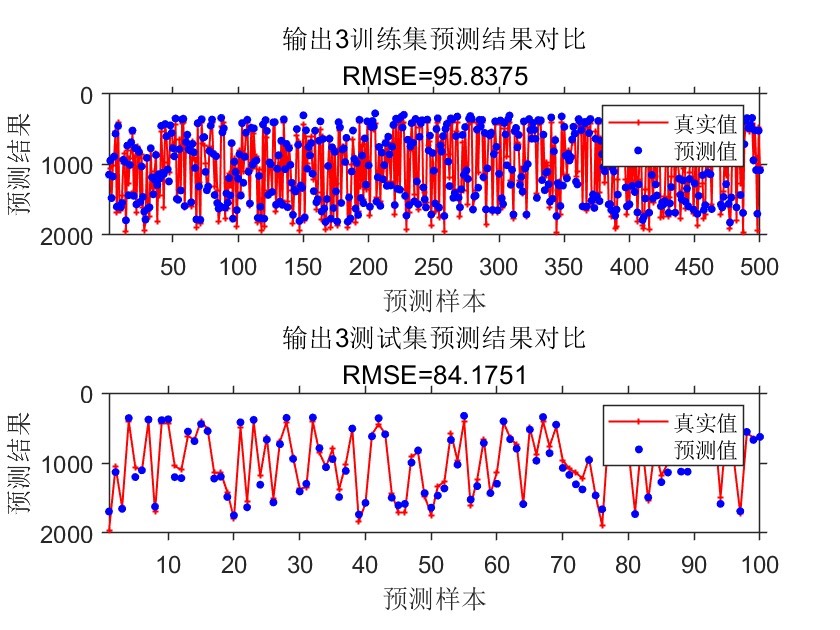
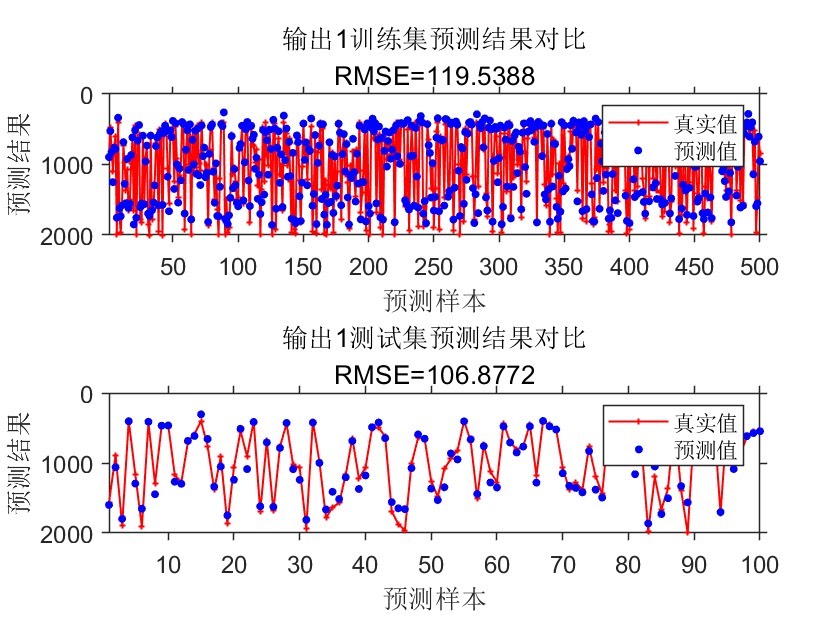
• 自动为每一路输出绘制 train/test 两张对比图,并同步打印 RMSE 到标题,无需手工截图即可放入汇报 PPT。
三、核心能力拆解
①「多输入多输出」自动化形状推断
传统代码里经常硬编码 inputSize=10、outputSize=3,导致换数据就得改脚本。本方案在运行时动态读取矩阵行维,真正做到“换数据零改动”。
②「零手工」双向归一化
通过 mapminmax 的 apply/reverse 模式,训练、预测、评估、可视化四个环节全部自动还原到原始量纲,规避“线下 0.95 R²,上线 MAE 爆表”的踩坑现场。
③「可解释误差」四件套
LSTM长短期记忆神经网络多输入多输出预测(Matlab) 所有程序经过验证,保证有效运行。 1.data为数据集,10个输入特征,3个输出变量。 2.MainLSTMNM.m为主程序文件。 3.命令窗口输出MAE和R2,
除常规 RMSE、MAE 外,额外计算 MBE(Mean Bias Error)。若 MBE 符号一致且绝对值较大,可快速定位模型是否存在系统性高估或低估,为后续纠偏提供明确方向。
④「一键出图」工程模板
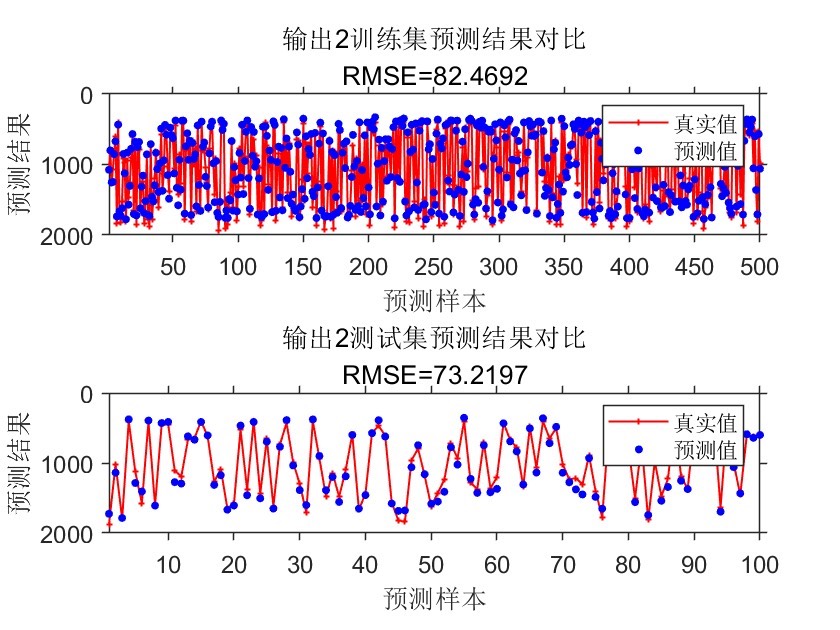
循环内自动拼接 2×1 子图,统一线宽、Marker 大小、坐标轴字号,并反向 y 轴(符合工业“越小越好”的视觉习惯)。研发、测试、运维三端看到的结果格式完全一致,减少沟通摩擦。
四、落地扩展指南
- 超参自动化
将隐藏单元数、丢弃率、学习率、DropPeriod 等变量抽离到 JSON,再配合 Optuna 或 BayesianOptimization,可在 50 次试验内把 RMSE 再降 3~8%。
- 在线推理封装
把归一化参数 psinput、psoutput 与网络 net 一起序列化(.mat),部署时先加载参数 → 实时归一化 → predict → 反归一化,即可在 30 ms 内返回结果。
- 多步预测改造
当前是单步回归。若业务需要预测未来 N 步,可将最后一层改为 「RegressionOutputWithTimeStep」或使用 Sequence-to-Sequence LSTM,训练逻辑不变,仅需把 t_train 扩成三维张量。
- 异常检测插件
在输出层并行新增一个二元分类分支,利用重构误差判断当前输入是否偏离训练分布,实现“预测+异常”双任务联合学习。
五、常见坑位提示
• 时间戳泄露:若数据本身带时间列,务必在 randperm 前删除,否则会出现“用未来预测过去”。
• 归一化参数混用:测试集必须沿用训练集参数,重新 fit 会导致指标虚高。
• 图例遮挡:subplot 标题过长时易被 legend 遮挡,建议 title 用细胞数组分段,或手动调整 Position。
• 反向 y 轴误用:若业务指标“越大越好”,需删除 set(gca,'ydir','reverse'),否则视觉暗示与数值相反。
六、一分钟速跑
- 把数据按“前 10 列输入、后 3 列输出”整理成 data.xlsx;
- 运行主脚本,自动出 3 张图 + 12 行指标;
- 若 RMSE 不满足业务阈值,调大 hidden units 或减小 InitialLearnRate,再跑一次即可。
七、结语
该脚本以“最小可用”为设计哲学,却在每一行细节里预埋了工程化钩子:归一化参数持久化、训练选项结构体、循环内指标打印、统一绘图模板…… 让研究员专注特征与算法,让工程师无痛接入生产。只需“换数据、调超参、再训练”三步,就能在任意多输入多输出场景里快速落地一条高性能、可解释、可扩展的 LSTM 基线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)