ForgeAdmin渐进式 Spec 开发:开源项目从需求到落地完整流程
我在开源项目实践渐进式 Spec 开发:从需求到落地完整流程

什么是渐进式 Spec 开发?
最近在我的开源项目 Forge Admin 中,我实践了一种新的开发方式 —— 渐进式 Spec 开发。这种方式强调 “No Spec No Code”,在写代码之前先写好规格说明,逐步确认,再编码实现。
这篇文章我就分享一下整个实践过程,以及我做分布式幂等防重组件的完整案例。
核心思想:No Spec No Code
“No Spec No Code” 不是说完全不允许迭代,而是说:
- 没有清晰规格不写代码 —— 避免做到一半发现理解错需求
- 规格逐步完善 —— 从小处开始,慢慢增量演进
- 每个阶段都有确认入口 —— 需求确认、Spec确认、代码审查
- Spec 和代码分离 —— 先把需求和设计说清楚,再动手编码
Forge Admin 中的渐进式开发流程
在 Forge Admin 项目中,我们定义了一套完整的命令工作流:完整文件内容,参考gitee仓库https://gitee.com/ForgeLab/forge-admin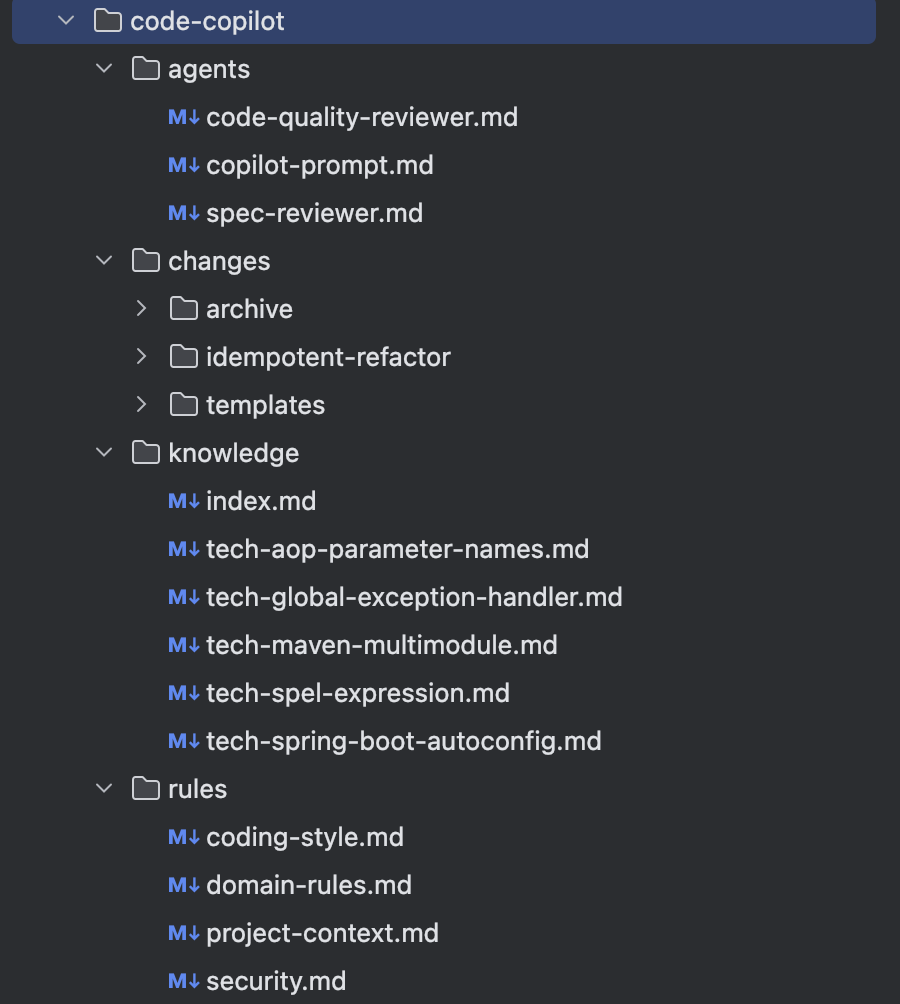
/spec:init <初始化项目上下文> # 分析工程结构、依赖、分层模式
/propose <需求描述> # 创建变更提案,生成渐进式Spec
/apply <变更名> # 按确认后的Spec执行编码
/fix <变更名> [描述] # Review后修正迭代
/review <变更名> # 两阶段代码审查(Spec合规 + 代码质量)
/test <变更名> # 生成单测并执行TDD流程
/archive <变更名> # 归档变更并沉淀知识到知识库
所有变更产物统一存放在 code-copilot/changes/[变更名]/ 目录下,包含:
spec.md—— 需求规格说明tasks.md—— 任务拆分test-spec.md—— 测试计划log.md—— 开发日志,记录决策、踩坑、知识发现
实战案例:分布式幂等防重组件
我们以刚刚完成的分布式幂等防重组件为例,走一遍完整流程。
本项目用的是opencode工具,需要在项目根目录创建AGENT.md文件,方便opencode执行自定义命令,当然这部分内容也可以让AI来生成
暂时无法在飞书文档外展示此内容
第一步:提出需求 /propose
首先,我提出了需求:参考美团GTIS方案,实现通用分布式幂等防重组件。
系统自动生成了 spec.md 框架,我填充了完整内容:
# 分布式幂等防重组件(美团GTIS方案实现)
## 1. 背景与目标
### 背景
当前系统缺乏统一的分布式幂等防重机制,存在以下问题:
1. 接口重复提交、网络重试、消息重复消费等场景容易导致数据重复插入
2. 各业务模块自行实现幂等逻辑,代码重复、实现不规范
3. 缺乏统一的监控、统计、降级能力,出现问题排查困难
### 目标
1. ✅ 低侵入:提供注解式使用方式,业务代码无需修改核心逻辑
2. ✅ 多场景支持:支持Web接口、RPC调用、消息消费等多种场景
3. ✅ 灵活配置:支持自定义幂等键生成策略、存储介质、过期时间
4. ✅ 高可用:支持集群部署、降级开关、容错机制
5. ✅ 可观测:提供幂等请求统计、命中日志、告警能力
## 3. 功能点
- [ ] 核心功能1:@Idempotent注解定义与AOP切面实现
- [ ] 核心功能2:幂等Token生成与校验服务
- [ ] 核心功能3:多种幂等键生成策略(SpEL表达式、自定义策略接口)
- [ ] 核心功能4:Redis幂等存储实现(支持原子操作、过期时间)
- [x] 扩展功能:降级配置、告警统计、日志记录
## 8. 风险与关注点
> ⚠️ 涉及资金/状态流转/权限变更必须标注
- ⚠️ 风险1:Redis故障时的降级策略,需要保证不影响主业务流程
- ⚠️ 风险2:幂等键冲突问题,需要保证生成的幂等键全局唯一
- ⚠️ 风险3:性能影响,需要保证幂等校验的耗时在10ms以内
## 9. 待澄清
- [x] 问题1:是否需要支持除Redis之外的存储介质?→ 仅支持Redis
- [x] 问题2:幂等默认过期时间设置为多长比较合适?→ 10分钟(可自定义)
- [x] 问题3:是否需要支持接口级别的幂等配置全局开关?→ 需要
## 10. 技术决策
1. **存储方案**:仅使用Redis作为幂等存储介质,利用Redis原子操作保证高性能
2. **默认配置**:幂等记录默认过期时间10分钟,可通过注解自定义
3. **开关控制**:支持全局配置开关,注解优先级高于全局配置
4. **幂等键生成**:默认使用"用户ID+接口路径+参数哈希",支持SpEL表达式自定义
5. **异常处理**:默认幂等校验失败抛出业务异常,可配置返回缓存
6. **高可用保障**:Redis异常时自动降级,不影响主业务流程
💡 这个阶段最关键的就是把所有待澄清问题都列出来,并且得到明确答案之后再进入下一阶段。很多开发做到一半卡壳,就是因为有些隐含问题没有提前确认。
第二步:确认 Spec 后开始编码 /apply
Spec 确认无误后,执行 /apply 开始编码,系统会自动拆分任务,按任务逐步实现:
| Task | 状态 | 实际改动文件 | 备注 |
|---|---|---|---|
| Task1: 创建幂等组件模块结构与基础依赖 | ✅ 完成 | pom.xml, AutoConfiguration.imports | - |
| Task2: 定义@Idempotent注解与配置类 | ✅ 完成 | Idempotent.java, IdempotentProperties.java | - |
| Task3: 实现幂等键生成器 | ✅ 完成 | SpelUtil.java, DefaultIdempotentKeyGenerator.java | - |
| Task4: 实现Redis幂等存储服务 | ✅ 完成 | IdempotentException.java, RedisIdempotentStorageService.java | - |
| Task5: 实现AOP切面与Web拦截器 | ✅ 完成 | IdempotentAutoConfiguration.java, IdempotentAspect.java | - |
| Task6: 实现全局开关与异常处理 | ✅ 完成 | IdempotentException.java(修改继承BusinessException) | - |
第三步:记录开发日志和踩坑
开发过程中,每完成一个任务,我都会在 log.md 中记录:
## 踩坑记录
| 问题 | 原因 | 解决方案 | 沉淀? |
|------|------|----------|--------|
| 注入了未使用的RedissonClient依赖 | 开发时误添加 | 移除未使用的依赖 | 是 |
| SpEL解析缺少异常处理 | 直接调用没捕获异常 | 添加try-catch,解析失败回退到参数哈希 | 是 |
| 切面缺少全局开关二次检查 | 仅靠自动配置条件注解 | 在切面中再次检查配置开关 | 是 |
| 参数名获取使用了单一实现 | StandardReflectionParameterNameDiscoverer在无-parameters编译参数时失效 | 改用DefaultParameterNameDiscoverer | 是 |
## 知识发现
- [x] **Spring Boot自动配置**: 通过META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports注册
- [x] **Maven多模块结构**: 新增starter需要在父pom的modules中添加声明
- [x] **SpEL表达式**: 使用Spring Expression Language动态解析幂等键
- [x] **AOP方法参数获取**: 使用DefaultParameterNameDiscoverer获取方法参数名
📝 好记性不如烂笔头,踩过的坑一定要记下来,下次就能避免了。同时这些知识也会沉淀到项目的知识库中,后续开发可以直接参考。
第四步:代码审查 /review
开发完成后,进行两阶段审查:
- 第一阶段:Spec 合规检查 —— 代码是否按照 Spec 实现?有没有偏离需求?
- 第二阶段:代码质量检查 —— 编码规范、命名、注释、异常处理是否到位?
代码审查发现了几个小问题:
- 移除未使用的RedissonClient依赖 ✓
- 改进参数名获取方式 ✓
- 添加SpEL解析异常处理 ✓
- 添加切面全局开关二次检查 ✓
修复之后重新审查,通过。
第五步:归档变更 /archive
所有工作完成后,执行 /archive 归档变更:
- 将变更移动到
archive/目录归档 - 将本次开发发现的知识沉淀到项目知识库
- 更新项目总结
最终代码成果
最终我们得到了一个完整的分布式幂等防重组件,项目结构清晰:
forge-starter-idempotent
├── src/main/java
│ └── com/mdframe/forge/starter/idempotent
│ ├── annotation/Idempotent.java # 幂等注解
│ ├── aop/IdempotentAspect.java # AOP切面
│ ├── config/IdempotentAutoConfiguration.java # 自动配置
│ ├── generator/DefaultIdempotentKeyGenerator.java # 键生成器
│ ├── service/RedisIdempotentStorageService.java # Redis存储
│ └── util/SpelUtil.java # SpEL工具
└── src/main/resources
└── META-INF/spring
└── org.springframework.boot.autoconfigure.AutoConfiguration.imports
使用方式非常简单
只需要三步:
1. 引入依赖
<dependency>
<groupId>com.mdframe.forge</groupId>
<artifactId>forge-starter-idempotent</artifactId>
<version>${revision}</version>
</dependency>
2. 配置
forge:
idempotent:
enabled: true # 开启幂等组件
default-expire: 600 # 默认过期时间(秒)
3. 添加注解
/**
* 使用订单号作为幂等键,精确匹配
*/
@Idempotent(key = "#order.orderNo", expire = 300)
public Result createOrder(Order order) {
// 业务逻辑
return Result.success();
}
就这么简单,零侵入,加个注解就搞定了。
渐进式 Spec 开发的优势

1. 减少沟通成本
需求 -> Spec -> 编码,每个环节都有明确的产出和确认,避免"我以为你懂了"的误解。
2. 风险提前暴露
在 Spec 阶段就能发现隐含问题和风险,等编码到一半才发现问题,改造成本高很多。
3. 知识沉淀
每个变更都有完整记录,后来的开发者可以通过 spec.md 和 log.md 理解当初为什么这么设计。
4. 适合 AI 辅助开发
AI 编码最大的问题就是需求理解偏差,Spec 相当于给AI一张明确的地图,AI按照地图走,不容易跑偏。
踩过的坑
坑1:参数名获取问题
一开始我用 StandardReflectionParameterNameDiscoverer,后来发现如果编译的时候没有开启 -parameters 参数,就获取不到参数名,导致 SpEL 表达式中的 #参数名 无法解析。
解决:改用 DefaultParameterNameDiscoverer,它会自动尝试多种方式获取参数名,更健壮。
坑2:SpEL 异常处理
一开始没有处理 SpEL 解析异常,如果用户写错了表达式,整个接口直接500。
解决:添加 try-catch,解析失败时回退到默认的参数哈希方案,保证接口可用。
坑3:全局开关动态生效
一开始只在自动配置上加了 @ConditionalOnProperty,如果运行时通过配置中心关闭,切面还是会执行。
解决:在切面切入点再次检查配置开关,保证开关即时生效。
项目地址
完整代码已经开源在 Forge Admin:
👉 https://gitee.com/ForgeLab/forge-admin
如果你也对渐进式 Spec 开发感兴趣,欢迎去看看项目里的 code-copilot/ 目录,里面有完整的流程定义和模板。
总结
渐进式 Spec 开发不是什么银弹,但在实践中确实能减少很多不必要的返工:
- 先想清楚,再动手 —— Spec 阶段把需求、设计、风险都想清楚
- 小步快跑,逐步确认 —— 每次只做一小段,确认后再继续
- 完整记录,沉淀知识 —— 每个变更都留下记录,方便后续维护
如果你也在使用 AI 辅助开发,不妨试试这种方式,相信会对你有帮助。
#Java #开源 #开发流程 #AI编程 #渐进式开发 #ForgeAdmin

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)