蓝桥杯备战Python
1.range(x,y)和data[1,5]这个两个操作都是左闭右开的操作
2.在python中list可以直接当作栈进行使用,以下是使用方式:
#定义一个栈
stack_list = []
#入栈
stack_list.append(x)
#出栈
stack_list.pop()
#栈顶元素
top_element=stack_list[-1]
3.字典存储
n = int(input("请输入行数: ")) # 先输入要输入的行数
my_dict = {}
for _ in range(n):
line = input() # 读取一行输入
if line: # 非空行处理
key, value = map(int, line.split())
my_dict[key] = value
print("生成的字典:", my_dict)4.差分数组与前缀和数组
nums = [0] + ...是为了让数组下标从1开始,方便和题目一致pres[i]表示前缀和:
pres[i]=A1+A2+⋯+Aipres[i]=A1+A2+⋯+Ai
所以区间和 [l, r] 可以快速写成:
pres[r]−pres[l−1]
cnt[i] 表示:原数组中第 i+1 个位置(下标i)被多少个查询区间覆盖
diff[i]差分数组就是表示变化量的,变化量的和就是
5.动态规划:例题:打家劫舍,动态规划五部曲
这里需要注意:
1.边界样例的检验,如nums数组长度为1时,return nums[0],为2时return max(nums[0],nums[1]).
2.注意总结dp[i]数组的含义,这里表示前i个数组的打劫最大值,dp[i]=max(nums[i]+dp[i-2],dp[i-1]).当选择i时,对应的打劫金额为:nums[i]+dp[i-2],当不选择i时,打劫金额为dp[i-1]。
3.要注意dp数组的长度选取,这里定义dp数组根据nums数组的长度来定,和nums长度一样
class Solution:
def rob(self, nums: List[int]) -> int:
lens=len(nums)
if lens==1:
return nums[0]
if lens==2:
return max(nums[0],nums[1])
dp=[0]*lens
dp[0]=nums[0]
dp[1]=max(nums[0],nums[1])
for i in range(2,lens):
dp[i]=max(nums[i]+dp[i-2],dp[i-1])
return dp[lens-1]
6:ord()函数返回字符的Unicode码点,小写字母 'a' 到 'z' 对应97-122:
7:首先理解优先队列(最小堆)
-
heapq是Python的标准堆模块 -
heapq.heappush(heap, item)将元素item推入堆heap中 -
堆会自动维护最小元素在堆顶
-
这里
pq是优先队列,存储形式为(距离, 节点)的元组 -
堆按照元组的第一个元素(距离)排序,距离最小的元素在堆顶
-
heapq.heappop(pq) # 取出pq(x,y)
# 这行代码可以分解为:
item = heapq.heappop(pq) # 1. 从堆中弹出最小元素
d = item[0] # 2. 获取元组的第一个元素(距离)
u = item[1] # 3. 获取元组的第二个元素(节点编号)
# 等价于一行:
d, u = heapq.heappop(pq) # 元组解包赋值8.异或和 = 把所有数字用 XOR 连起来算的结果
相同为0,不同为1,异或是位运算,符号是 ^,规则很简单:
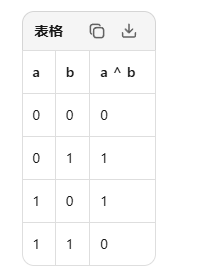


9.extend() 是 Python 列表(list)的方法,用于将一个可迭代对象中的所有元素,逐个追加到列表末尾。
10.邻接表
# 每个邻接表项存储 [邻居节点, 权值]
n = 4
graph = [[] for _ in range(n + 1)]
def add_edge(u, v, w):
graph[u].append([v, w]) # 存储为列表
graph[v].append([u, w])
add_edge(1, 2, 10)
add_edge(2, 3, 20)
add_edge(3, 4, 15)
# 遍历
for node in range(1, n + 1):
for edge in graph[node]:
neighbor, weight = edge[0], edge[1]
print(f"边 {node}-{neighbor}: 权值={weight}")11.用库函数来做全排列
product([0,1], repeat=2)相当于:
(0,0)
(0,1)
(1,0)
(1,1)from itertools import product
def generate_sequences(n):
# product([0,1], repeat=n) 生成所有长度为n的(0,1)元组
return [list(combo) for combo in product([0, 1], repeat=n)]
n = 3
for seq in generate_sequences(n):
print(seq)12.进制转换
def func_2(n):
if n == 0:
return [0]
result = []
while n > 0:
yushu = n % 2
n = n // 2
result.append(int(yushu))
result.reverse()
return result
def func_4(n):
if n == 0:
return [0]
result = []
while n > 0:
yushu = n % 4
n = n // 4
result.append(int(yushu))
result.reverse()
return result13排列组合
![]()
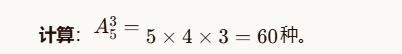

14.Python 列表不能通过不存在的索引直接赋值。
要记得列表初始化
A = [0] * (n+1) # 创建 n+1 个位置,A[0]~A[n]
for i in range(1, n+1):
A[i] = list(map(int, input().split()))15.strip()的用法
strip()方法移除字符串开头和结尾的空白字符- 包括:空格、制表符
\t、换行符\n、回车符\r等 - 不会移除字符串中间的空白字符
parts = line.rsplit(' ', 1) 使用了字符串的 从右向左分割 功能。让我详细解释:
16.rsplit() 方法详解
rsplit(separator, maxsplit) 方法:
left_parts = line.split(' ', 1)- 从字符串右侧开始分割
separator: 分隔符(这里是空格' ')maxsplit: 最大分割次数(这里是1)
17.并查集(路径压缩版本)

class UnionFind:
"""
并查集(Union-Find)数据结构
用于高效地管理元素的分组,支持合并集合和查询元素所属集合的操作
核心思想:用树形结构表示集合,根节点代表整个集合
"""
def __init__(self, n):
"""
初始化并查集,创建 n 个独立的集合
参数:
n: 元素的总数量,元素编号为 0 到 n-1
初始化内容:
- parent: 父节点数组,记录每个节点的直接父节点
- rank: 秩(树的高度)数组,用于按秩合并优化
"""
# parent[i] = i 表示节点 i 是根节点(自己指向自己)
self.parent = [i for i in range(n)]
# rank[i] 表示以节点 i 为根的树的高度(或深度)
# 初始时每个节点都是独立的树,高度为 0
self.rank = [0] * n
def find(self, x):
"""
查找元素 x 所属集合的根节点(代表元)
使用路径压缩优化:将查找路径上的所有节点直接连接到根节点
参数:
x: 要查找的元素
返回:
x 所在集合的根节点
时间复杂度: 近似 O(1)(阿克曼函数的反函数)
"""
# 如果 x 不是根节点(父节点不是自己)
if self.parent[x] != x:
# 递归查找根节点,同时进行路径压缩
# 将 x 的父节点直接设置为根节点,扁平化树结构
self.parent[x] = self.find(self.parent[x])
# 返回 x 的根节点(经过路径压缩后,self.parent[x] 就是根节点)
return self.parent[x]
def union(self, x, y):
"""
合并元素 x 和 y 所在的两个集合
参数:
x, y: 要合并的两个元素
实现细节:
- 先找到两个元素的根节点
- 如果根相同,说明已在同一集合,无需操作
- 否则,按秩合并:将较矮的树连接到较高的树下,保持树的平衡
时间复杂度: 近似 O(1)
"""
# 找到 x 的根节点
root_x = self.find(x)
# 找到 y 的根节点
root_y = self.find(y)
# 如果根节点相同,说明 x 和 y 已经在同一集合中
if root_x == root_y:
return # 无需合并,直接返回
# 按秩合并策略:将秩较小的树连接到秩较大的树下
# 这样可以保持树的平衡,避免树变得过深
if self.rank[root_x] < self.rank[root_y]:
# root_x 的树较矮,将其连接到 root_y 下
self.parent[root_x] = root_y
# root_y 的秩不变(因为矮树接在高树下,总高度不变)
elif self.rank[root_x] > self.rank[root_y]:
# root_y 的树较矮,将其连接到 root_x 下
self.parent[root_y] = root_x
else:
# 两棵树高度相同,选择将 root_y 连接到 root_x 下(可任意选择)
self.parent[root_y] = root_x
# root_x 的秩增加 1,因为树高增加了
self.rank[root_x] += 1
# ============ 使用示例 ============
if __name__ == "__main__":
# 创建一个包含 5 个元素的并查集
uf = UnionFind(5)
# 初始状态:每个元素各自为一个集合
# 集合: {0}, {1}, {2}, {3}, {4}
# 合并 0 和 1
uf.union(0, 1)
# 集合: {0,1}, {2}, {3}, {4}
# 合并 2 和 3
uf.union(2, 3)
# 集合: {0,1}, {2,3}, {4}
# 合并 1 和 2(这将合并 {0,1} 和 {2,3} 两个集合)
uf.union(1, 2)
# 集合: {0,1,2,3}, {4}
# 查询元素是否在同一集合
print(uf.find(0) == uf.find(3)) # True,0 和 3 在同一集合
print(uf.find(0) == uf.find(4)) # False,0 和 4 不在同一集合
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)