基于GA遗传优化的Transformer-LSTM网络模型的时间序列预测算法matlab性能仿真
目录
1.前言
基于GA遗传优化的Transformer-LSTM时间序列预测算法,是遗传算法(全局优化算法) 与Transformer-LSTM混合深度学习模型的结合体,核心解决传统Transformer-LSTM网络超参数人工调参效率低、预测精度差、模型泛化能力弱的问题,专门面向非线性、非平稳、长时序依赖的时间序列预测任务(如电池容量预测、负荷预测等)。
2.算法测试效果图预览
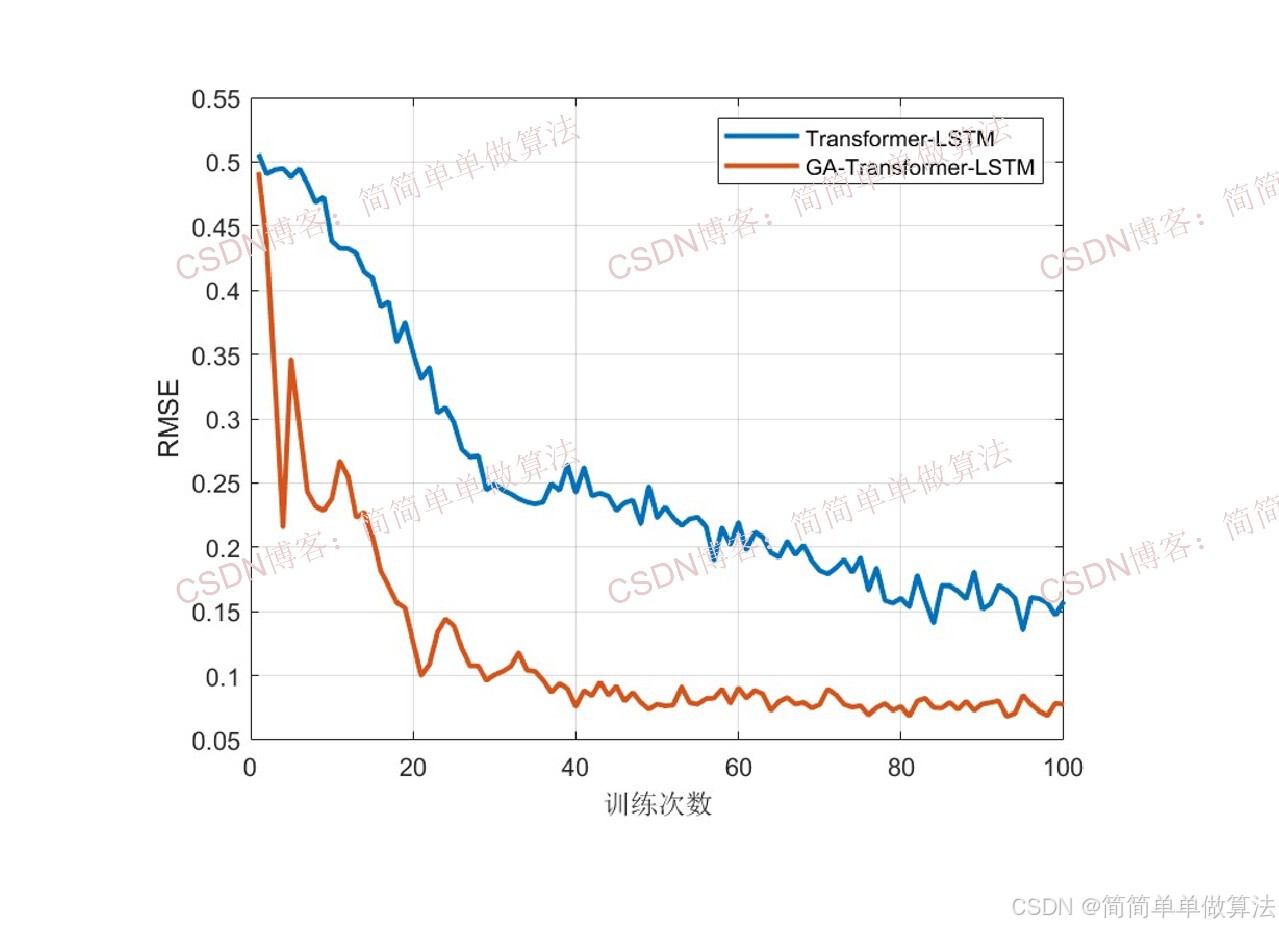
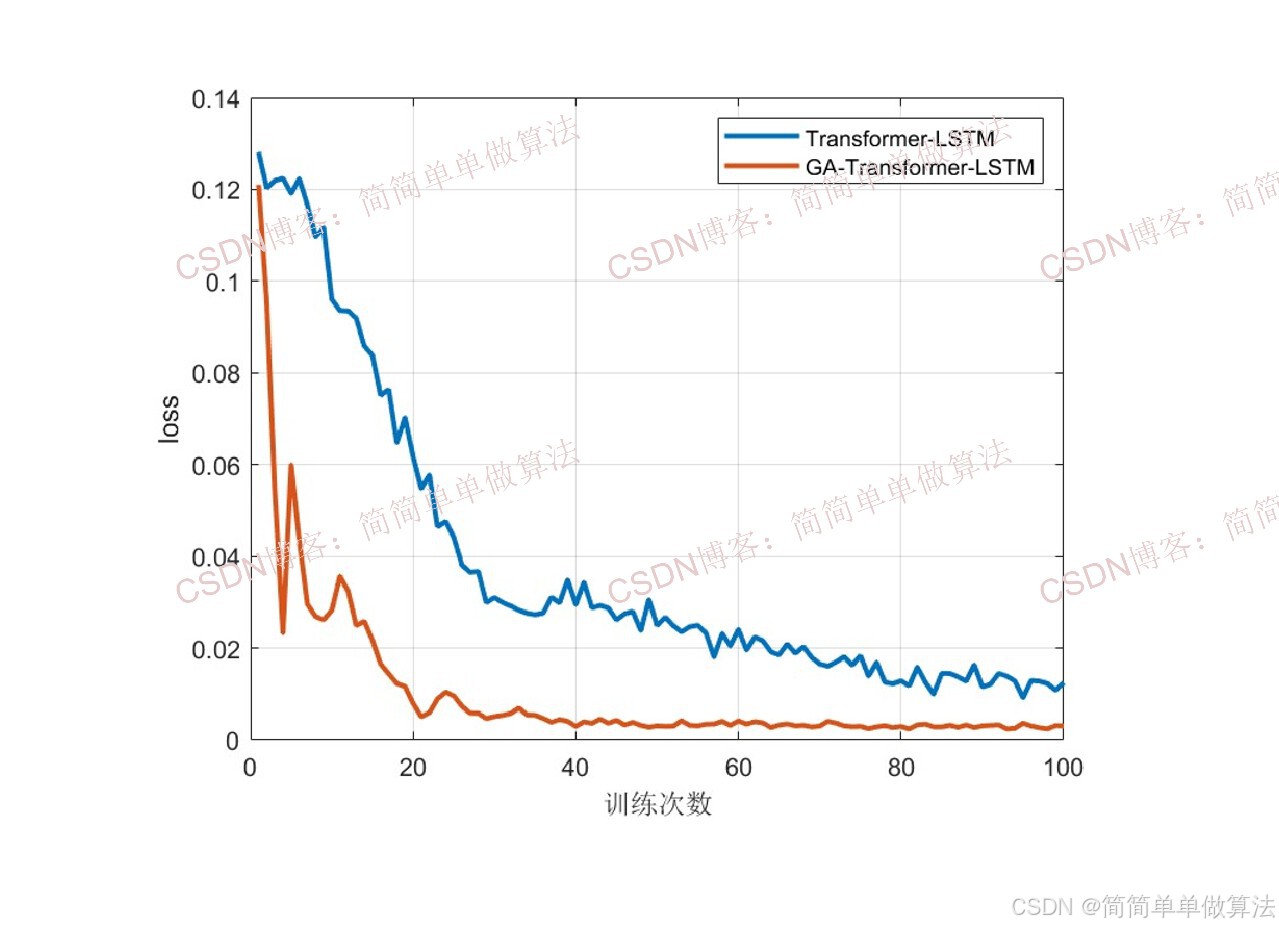
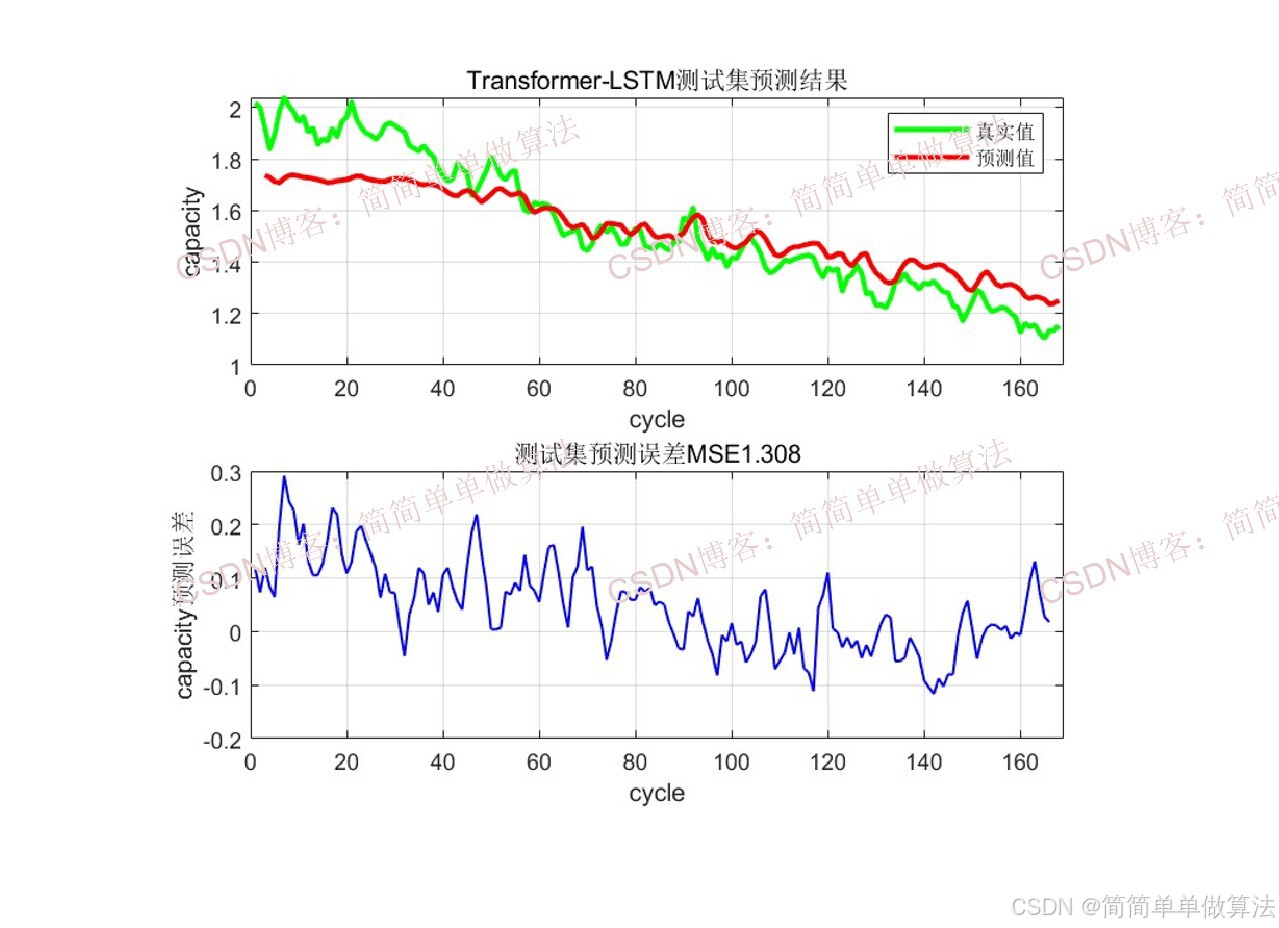
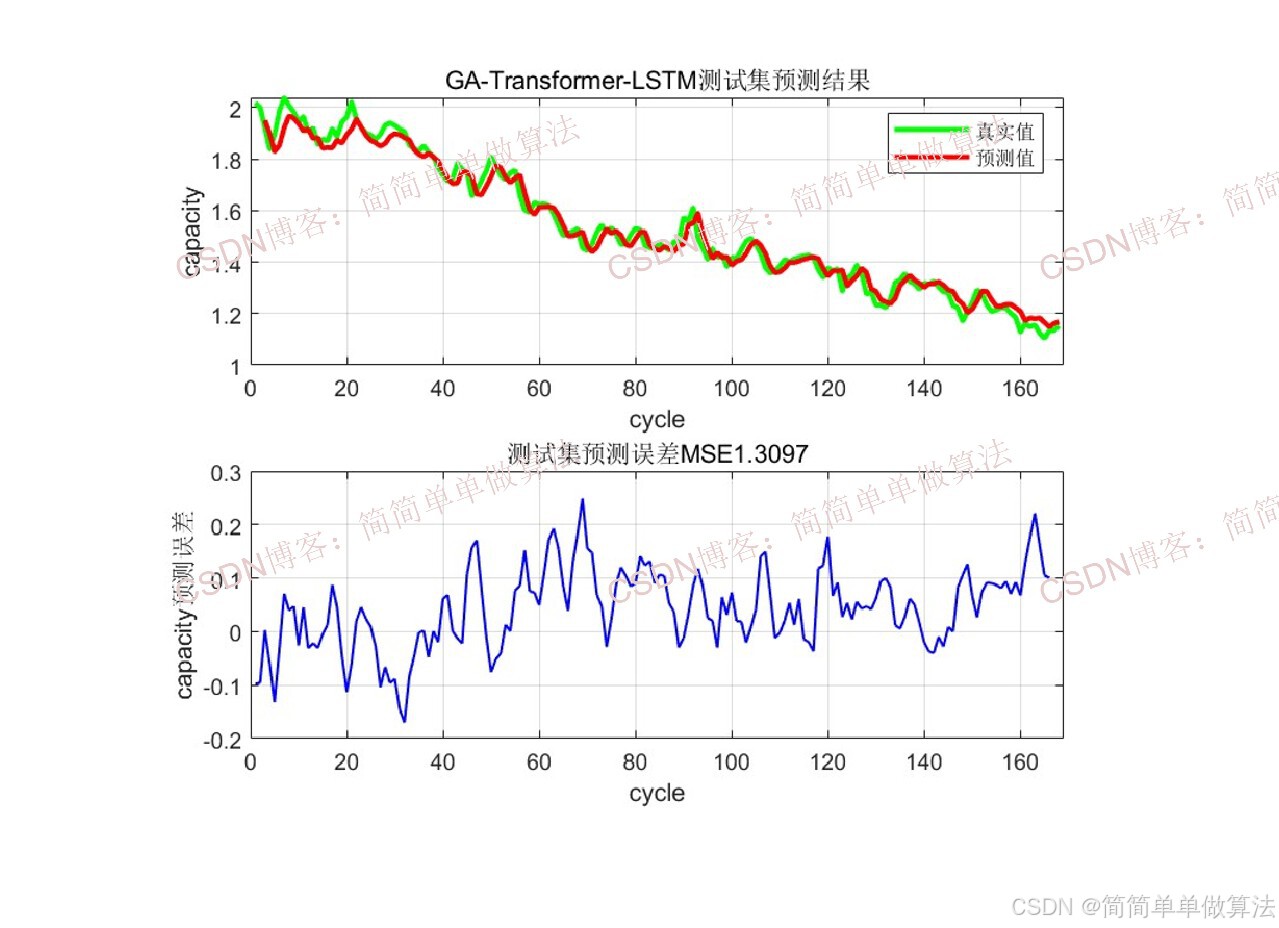
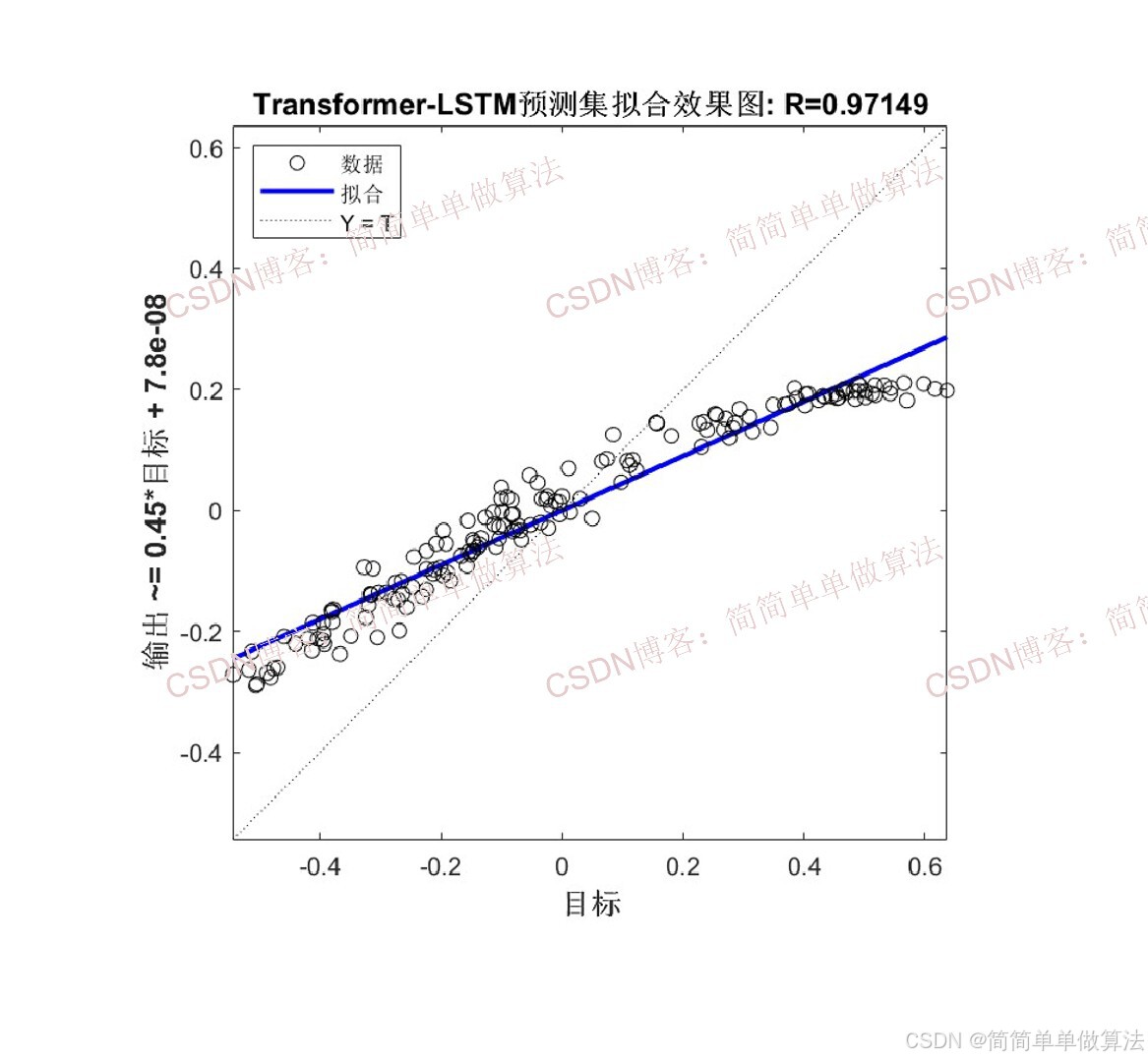
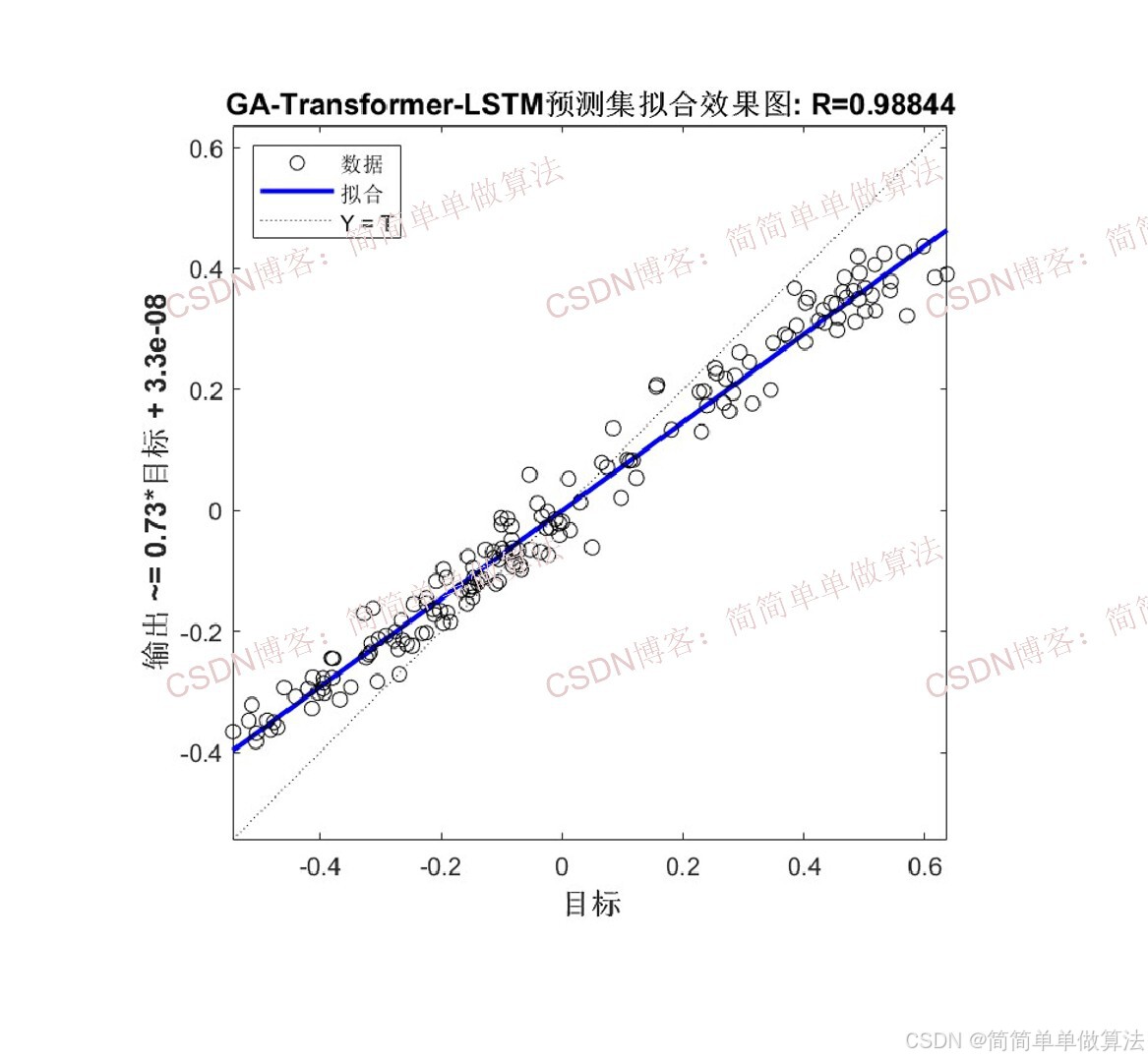
3.算法运行软件版本
matlab2024b
4.部分核心程序
%参数设置
options = trainingOptions('adam', ...
'MaxEpochs', 100, ...
'InitialLearnRate', RR, ...
'LearnRateSchedule', 'piecewise', ...
'LearnRateDropFactor', 0.1, ...
'LearnRateDropPeriod', 80, ... % 学习率
'Shuffle', 'every-epoch', ...
'Plots', 'none', ...
'Verbose', false);
%训练模型
[net,INFO]= trainNetwork(P_train2, T_train, lgraph, options);
%仿真预测
Dat_pre1 = predict(net, P_train2);
Dat_pre2 = predict(net, P_test2 );
%反归一化
Dat_pre1s = mapminmax('reverse', Dat_pre1', PS2);
Dat_pre2s = mapminmax('reverse', Dat_pre2', PS2);
T_train = T_train';
T_test = T_test' ;
%均方根误差
error1 = sqrt(sum((Dat_pre1s - T_train).^2) ./ LL1);
error2 = sqrt(sum((Dat_pre2s - T_test ).^2) ./ LL2);
%MSE
mse1 = sum((Dat_pre1s - T_train).^2)./LL1;
mse2 = sum((Dat_pre2s - T_test).^2)./LL2;
disp(['训练集MSE:', num2str(mse1)])
disp(['测试集MSE:', num2str(mse2)])
figure
plot(1:length(dat_train),dat_train,'g-','LineWidth',2);
hold on
plot(starts+1:starts+length(Dat_pre1s),Dat_pre1s,'r-','LineWidth',2)
legend('真实值','预测值')
xlabel('cycle')
ylabel('capacity')
xlim([0 length(dat_train)+1])
ylim([1.2 2.0])
grid on
figure
plot(1:length(dat_test),dat_test,'g-','LineWidth',2);
hold on
plot(starts+1:starts+length(Dat_pre2s),Dat_pre2s,'r-','LineWidth',2)
legend('真实值','预测值')
xlabel('cycle')
ylabel('capacity')
xlim([0 length(dat_test)+1])
ylim([1 2.2])
grid on
2515.算法理论概述
5.1 各模块核心原理
Transformer模块:基于自注意力机制,核心解决长距离时序依赖捕捉问题。通过多头自注意力机制计算序列中每个时间步与其他时间步的关联权重,忽略时序距离限制,提取全局时序特征;结合位置编码保留时间序列的先后顺序信息,弥补自注意力机制无位置感知的缺陷。

LSTM模块:长短期记忆网络,核心解决局部时序特征提取问题。通过门控结构(输入门、遗忘门、输出门)过滤无效时序信息、保留关键短期特征,与Transformer的全局特征形成互补,解决单一模型无法兼顾全局与局部特征的问题。

遗传算法(GA):基于达尔文生物进化理论的全局优化算法,核心作用是自动优化Transformer-LSTM的关键超参数。通过模拟自然选择、交叉、变异过程,在参数空间中搜索最优超参数组合,避免人工调参的主观性和局部最优陷阱。
5.2 遗传算法优化
GA算法通过选择、交叉、变异、重插入完成种群进化,逐代缩小超参数搜索范围:
适应度排序:基于预测误差对个体排序,误差越小适应度越高,采用排序适应度计算:
![]()
其中Objv为个体预测误差,适应度值与误差成反比。
选择操作:采用随机遍历抽样选择优良个体,保留高适应度个体进入下一代,选择概率与适应度成正比:

交叉操作:采用单点交叉,交叉概率Pe0=0.999,随机选择染色体交叉点交换基因片段,生成新个体:
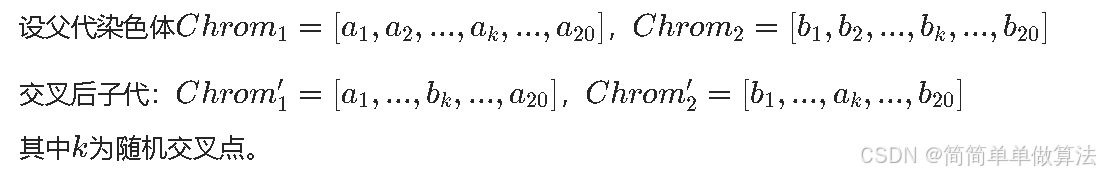
变异操作:采用基本位变异,变异概率pe1=0.001,随机翻转染色体二进制位,保持种群多样性:
![]()
二进制解码:将变异后的二进制染色体解码为实际超参数值:

目标函数计算:解码后的超参数构建Transformer-LSTM,计算预测均方误差作为目标值:
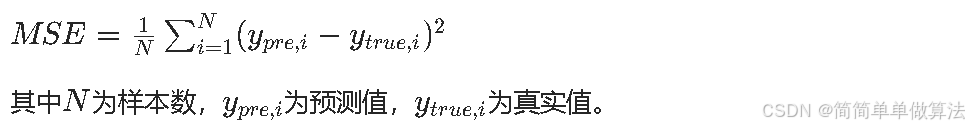
重插入操作:将子代个体与父代个体合并,保留最优个体,更新种群和适应度值:

5.3 最优Transformer-LSTM模型构建
遗传算法迭代结束后,筛选出适应度最小(误差最优)的超参数组合:LSTM 层数Osize、学习率RR,搭建混合网络模型。
该算法适用于所有存在长短期时序依赖的时间序列预测任务,包括:电池健康状态预测、电力负荷预测、交通流量预测、环境监测预测等,尤其适合对预测精度要求高、时序依赖复杂的工业和金融场景。
6.算法完整程序工程
OOOOO
OOO
O
关注GZH后输入回复:0034

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)