基于 PyTorch 实现的非线性函数拟合任务(拟合 y=x^3 +2x^2 )
核心逻辑是:
构建深度全连接神经网络,用带噪声的训练数据训练模型,验证拟合效果,并测试模型在训练区间外的泛化能力。
环境配置→数据准备→模型定义→训练过程→结果可视化

一、模块导入:加载所需工具库
import random # 生成随机数(备用,代码中未实际使用)
import os # 系统操作(未实际使用,保留扩展空间)
from torch.utils.data import DataLoader, Dataset # PyTorch数据加载工具(批量处理/自定义数据集)
from torch.utils.data import TensorDataset # 张量数据集(备用,未实际使用)
import torch.nn as nn # PyTorch神经网络模块(定义层、损失函数)
import numpy as np # 数值计算(生成数据、数组操作)
import torch # 深度学习框架(张量、优化器、自动求导)
import matplotlib.pyplot as plt # 绘图(展示拟合效果)核心库:torch(模型训练)、numpy(数据生成)、matplotlib(可视化)、torch.utils.data(数据加载)。
二、全局参数与随机种子固定
scatter = True # 可视化模式:True=散点图,False=折线图
def seed_everything(seed):
"""固定所有随机种子,保证实验可复现(每次运行结果一致)"""
torch.manual_seed(seed) # PyTorch CPU随机种子
torch.cuda.manual_seed(seed) # PyTorch GPU随机种子
torch.cuda.manual_seed_all(seed) # 多GPU时的随机种子
torch.backends.cudnn.benchmark = False # 关闭cuDNN自动优化(避免随机性)
torch.backends.cudnn.deterministic = True # cuDNN确定性模式
random.seed(seed) # Python原生随机种子
np.random.seed(seed) # NumPy随机种子
os.environ['PYTHONHASHSEED'] = str(seed) # Python哈希种子
seed_everything(0) # 固定种子为0,确保每次运行结果相同关键作用:深度学习中随机种子会影响参数初始化、数据打乱等,固定种子能让实验结果可复现,方便调试。
2.1 随机种子
在深度学习中,随机种子(Seed) 是一个用于初始化随机数生成器的值。设置随机种子的目的是为了确保每次运行代码时生成的随机数序列是相同的,从而保证实验结果的可重复性。
为什么要使用随机种子?
可重复性:在科学实验和模型训练中,设置随机种子可以确保多次运行产生相同的随机数序列,方便验证和调试。
复现性:在机器学习中,如果模型的随机初始化在不同的训练运行中是随机的,那么结果可能会有所不同。通过设置种子,可以确保每次训练使用相同的初始权重,以便比较和分析模型性能。
随机种子在不同库中的使用
Python 中的 random 模块:random.seed(seed_value),用于生成伪随机数序列。
这是 Python 标准库中 random 模块的函数。random 模块提供了伪随机数生成器,通过设置种子,你可以控制生成的随机数序列。
在这里,random.seed(seed) 将 Python 内置的随机数生成器的种子设置为提供的 seed 值,以确保每次程序运行时都产生相同的随机数序列。这对于调试和可重复的实验是很有用的。
NumPy 中的 numpy.random:numpy.random.seed(seed_value),用于生成 NumPy 库中的随机数组。
机器学习库中的随机性控制:比如 PyTorch 中的 torch.manual_seed(seed) 用于控制随机数生成,在模型训练中确保重复性。
深度学习框架中的 GPU 随机性控制:对于使用 GPU 的深度学习框架(如 PyTorch、TensorFlow),通常也会有类似 torch.cuda.manual_seed(seed) 的函数,用于设置 GPU 相关的随机种子,以保证实验结果的一致性。
————————————————
版权声明:本文为CSDN博主「慕溪同学」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/J_oshua/article/details/135283556
三、定义神经网络模型
class Net(nn.Module):
""" 定义深度全连接神经网络,用于拟合非线性函数 y = x³ + 2x² """
def __init__(self):
super(Net, self).__init__() # 调用父类nn.Module的初始化方法(必须)
# nn.Sequential:按顺序堆叠网络层,简化前向传播代码
self.net = nn.Sequential(
nn.Linear(in_features=1, out_features=100),
# 输入层:1维(x)→ 隐藏层100维
nn.ReLU(), # 激活函数:引入非线性(否则多层线性层等价于单层)
nn.Linear(100, 100), # 隐藏层1:100维→100维
nn.ReLU(), # 激活函数
nn.Linear(100, 100), # 隐藏层2:100维→100维
nn.ReLU(), # 激活函数
nn.Linear(100, 1) # 输出层:100维→1维(预测y值)
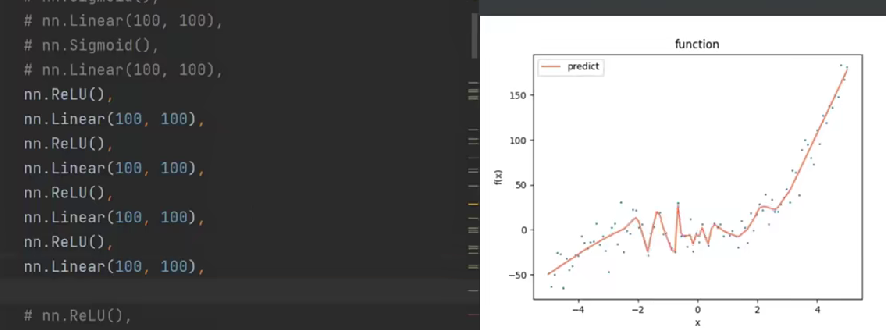
# 层数不一定越多越好,太多会曲曲折折的,过拟合
)
def forward(self, input):
"""前向传播:输入数据→经过网络层→输出预测值"""
return self.net(input) # 直接调用Sequential堆叠的网络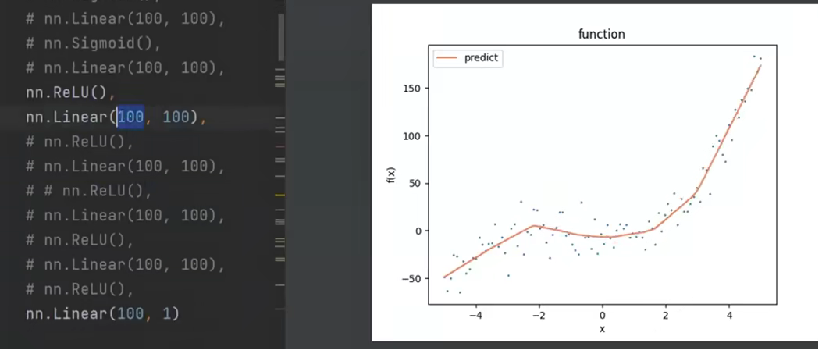
四、自定义数据集类
定义一个名为mydataset的类,继承自 PyTorch 的Dataset类
mydataset 是子类,Dataset(PyTorch 提供的类)是父类(也叫基类)。
4.1 继承
1. 子类可以 “继承” 父类的所有属性和方法(比如 Dataset 里的默认方法);
2. 但子类如果自定义了 __init__ 方法,会覆盖父类的 __init__ 方法 —— 如果不主动调用父类的 __init__,父类的初始化逻辑就不会执行,可能导致父类的属性 / 方法失效。
4.2 为什么要继承Dataset?
PyTorch 的DataLoader(批量加载数据的工具)只能处理继承自Dataset的类,
因为Dataset规定了两个必须实现的方法:
__getitem__(按索引取样本)和__len__(取数据集长度)。
4.3 super是什么?
super() 是 Python 内置的函数,核心作用是:
获取当前子类对应的父类对象,从而调用父类的方法(尤其是初始化方法 __init__)。
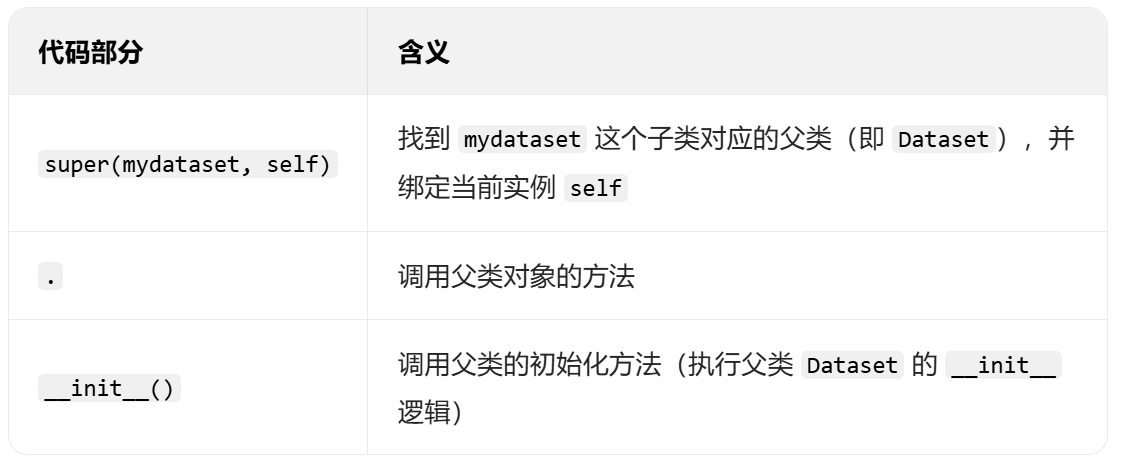
class mydataset(Dataset):
""" 自定义Dataset类,将numpy数组转为PyTorch可处理的数据集 """
""" mydataset 是子类,Dataset(PyTorch 提供的类)是父类(也叫基类)。"""
def __init__(self, x, y):
super(mydataset, self).__init__() # 调用父类初始化
# 将numpy数组转为PyTorch张量(float32类型,适配PyTorch计算)
self.x = torch.tensor(x, dtype=torch.float)
self.y = torch.tensor(y, dtype=torch.float)
#将传入的NumPy 数组x转换为PyTorch 张量(Tensor),并指定数据类型为torch.float
def __getitem__(self, item):
""" 按索引返回单个样本:(x, y) """
return self.x[item], self.y[item]
def __len__(self):
""" 返回数据集总长度(DataLoader需要) """
return len(self.x)核心作用:PyTorch 的DataLoader只能处理Dataset类的对象,该类将原始 numpy 数据封装成 “可按索引取值、可获取长度” 的数据集,适配批量加载逻辑
五、生成训练数据(必要 数据预处理 步骤)
data_num = 100 # 训练样本数量
train_s = -5 # 训练数据x的起始范围
train_e = 5 # 训练数据x的结束范围
# 1. 生成x:在[-5,5]范围内生成100个均匀分布的数
x = np.linspace(train_s, train_e, data_num)
# 2. 生成真实y值:y = x³ + 2x²
y = x**3 + 2*x**2
# 3. 给y添加高斯噪声(模拟真实场景的噪声数据)
mu = 0 # 噪声均值
sigma = 1 # 噪声标准差
y += np.random.normal(mu, sigma, y.shape) # 加噪声:N(0,1)
# 4. 调整数据维度(适配PyTorch输入格式)
# np.expand_dims(x, axis=1):将x从(100,)转为(100,1)(PyTorch要求输入为二维:[样本数, 特征数])
X = np.expand_dims(x, axis=1)
# y.reshape(data_num,-1):将y从(100,)转为(100,1)(和X维度匹配)
Y = y.reshape(data_num, -1)5.1 x = np.linspace ( train_s , train_e , data_num )
在指定的数值范围 [起始值, 终止值] 内,生成指定数量的均匀分布的数值,
返回一个 NumPy 一维数组。
5.2 np.random.normal()
是 NumPy 生成正态分布(高斯分布)随机数的函数,而 y += ... 是把生成的噪声叠加到原始 y 上,最终让 y 变成 “真实值 + 随机噪声” 的形式。
正态分布的特点:
噪声值围绕 mu(均值)分布,大部分值集中在 mu ± sigma(标准差)范围内;
标准差 sigma 越大,噪声波动越剧烈;越小,噪声越平缓。
np.linspace: 生成等间距的数,保证 x 覆盖 [-5,5] 区间;
加噪声: 让数据更贴近真实场景(无噪声的话模型会完美拟合,但泛化能力差);
维度调整: PyTorch 的线性层要求输入为[批次大小, 特征数],所以必须把一维的 x/y 转为二维。
如果不加噪声会怎么样

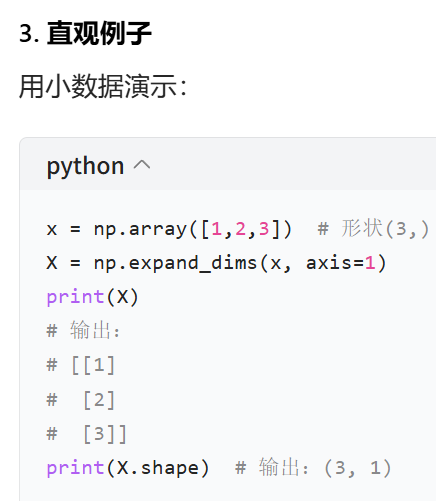
5.3 X = np.expand_dims ( x , axis=1 )
np.expand_dims():NumPy 的函数,作用是给数组 “增加一个维度”(不改变数据本身,只改变数组的形状);
x:原始数据(你的代码中是np.linspace生成的一维数组,形状为(100,),100 个元素);
axis=1:指定 “在第 1 个维度上增加维度”(NumPy 的维度下标从 0 开始)。

执行 X=np.expand_dims(x,axis=1) 后:
给x在第 1 维(对应列方向)增加一个维度;
新数组X的形状变成 (100, 1)(二维数组,100 行、1 列)。
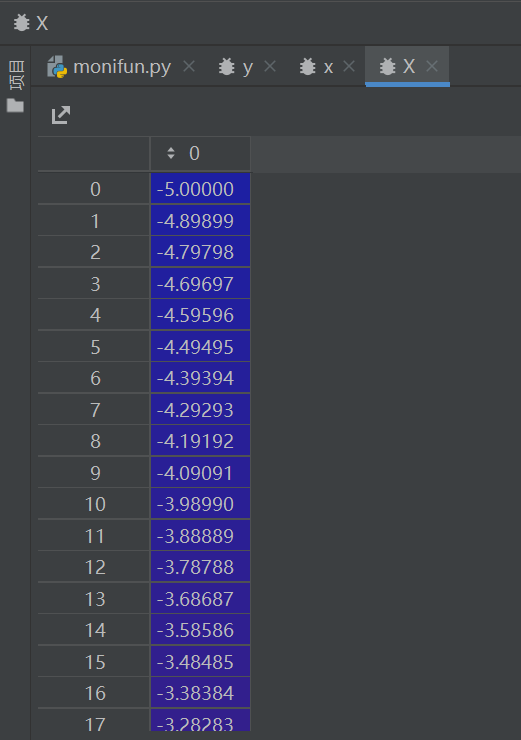
5.4 Y = y.reshape(data_num,-1)
执行 Y=y.reshape(data_num,-1) 后:
data_num=100 固定第一维为 100 行;
-1 让 NumPy 自动计算第二维:总元素数 100 = 100 行 × 1 列 → 第二维为 1;
新数组Y的形状变成 (100, 1)(二维数组,100 行、1 列)。
这两行代码的核心作用(为什么必须写)
PyTorch 的神经网络输入有严格的格式要求:
模型的输入必须是二维张量,形状为 [样本数量, 特征数量];
你的任务中,每个样本只有 1 个特征(x),所以特征数量 = 1。
如果不调整维度:
原始x/y是一维数组((100,)),直接传入模型会报「维度不匹配」错误;
调整后X/Y是二维数组((100, 1)),刚好符合 [100个样本, 1个特征] 的格式,能被模型正常接收。


简单说,这两行代码是为了把原始的一维数据 “包装” 成神经网络能识别的二维格式。
原始数组不是 1*100(这是二维),而是一维数组 (100,)
(可以理解为 “无行列之分的 100 个元素”),
这两行代码的核心就是把这个一维数组,转换成二维的 100*1 形状(100 行、1 列)。

当 data_num = 50 时,
执行 X=np.expand_dims(x,axis=0) 后,数据会变成 1 行 50 列 的二维数组(形状为 (1, 50))
执行X = np.expand_dims(x, axis=1) → 形状(50, 1)(50 行 1 列);
Y=y.reshape(data_num,-1) → 形状(50,1)(50 行 1 列)
只有当原始y的总元素数 = 100 时,reshape(50,-1)才会得到(50,2)(50×2=100),

np.expand_dims(x, axis=N)的核心规则是:axis的取值不能超过数组当前的维度数。
你的原始x是data_num=50对应的一维数组,形状为(50,) → 当前维度数 = 1(只有第 0 维);
axis的合法取值只能是0或1(一维数组的维度下标范围是[-1,1],超出则报错);
你指定axis=2,相当于要在 “第 3 个维度” 上增加维度,但原始数组只有 1 个维度,NumPy 会直接抛出AxisError:
六、构建数据加载器(批量训练)
# 1. 封装数据集:将X/Y传入自定义mydataset类
dataset = mydataset(X, Y)
# 2. 构建DataLoader:批量加载数据,打乱顺序
dataloader = DataLoader(dataset, batch_size=100, shuffle=True)batch_size=100:(每个批次)每次训练用 100 个样本(即全量训练,也叫 “批量梯度下降”);
shuffle=True:每个 epoch 打乱数据顺序(避免模型学习数据顺序而非规律)。
七、初始化模型、优化器、损失函数
7.1 net = Net( ) : 实例化神经网络模型
Net() 是你之前定义的神经网络类(包含多层全连接 + ReLU 激活),net = Net() 就是创建这个网络的 “实例”(可以理解为 “造了一个具体的神经网络出来”)。
实例化后,net 就具备了网络的所有结构(输入层、隐藏层、输出层),并自动初始化了网络的参数(比如线性层的权重w、偏置b);
此时net还未训练,参数都是随机初始化的,无法正确拟合函数。
# 1. 实例化神经网络模型
net = Net()
# 2. 定义优化器:Adam(自适应学习率优化器,比SGD更易收敛)
optim = torch.optim.Adam(net.parameters(), lr=0.001)
# 3. 定义损失函数:MSE(均方误差,回归任务常用)
Loss = nn.MSELoss()
7.2 optim=torch.optim.Adam(net.parameters(),lr=0.001)
定义 Adam 优化器
torch.optim.Adam() 是 PyTorch 提供的自适应学习率优化器,
作用是:根据模型预测的误差,自动调整网络参数(权重w、偏置b),让模型的预测越来越接近真实值。

7.3 Adam优化器
7.2.2 为什么选 Adam?
Adam 是 SGD(随机梯度下降)的改进版,会自适应调整每个参数的学习率(比如对更新慢的参数用大学习率,更新快的用小学习率),相比你注释掉的SGD,收敛更快、更稳定,适合非线性函数拟合这类场景。
7.2.1 学习率的作用:
lr太大:参数更新步长过大,模型可能 “跳过” 最优解,损失震荡不收敛;
lr太小:参数更新太慢,训练 1000 轮还没学到规律;
0.001 是 Adam 的常用默认值,适合你的函数拟合任务。
7.2.3 注释掉的SGD:
torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.09) 是基础的随机梯度下降,momentum=0.09是 “动量”(模拟物理惯性,让参数更新更顺滑),但需要手动调学习率,收敛效率比 Adam 低。

7.4 优化器 |SGD |Momentum |Adagrad |RMSProp |Adam
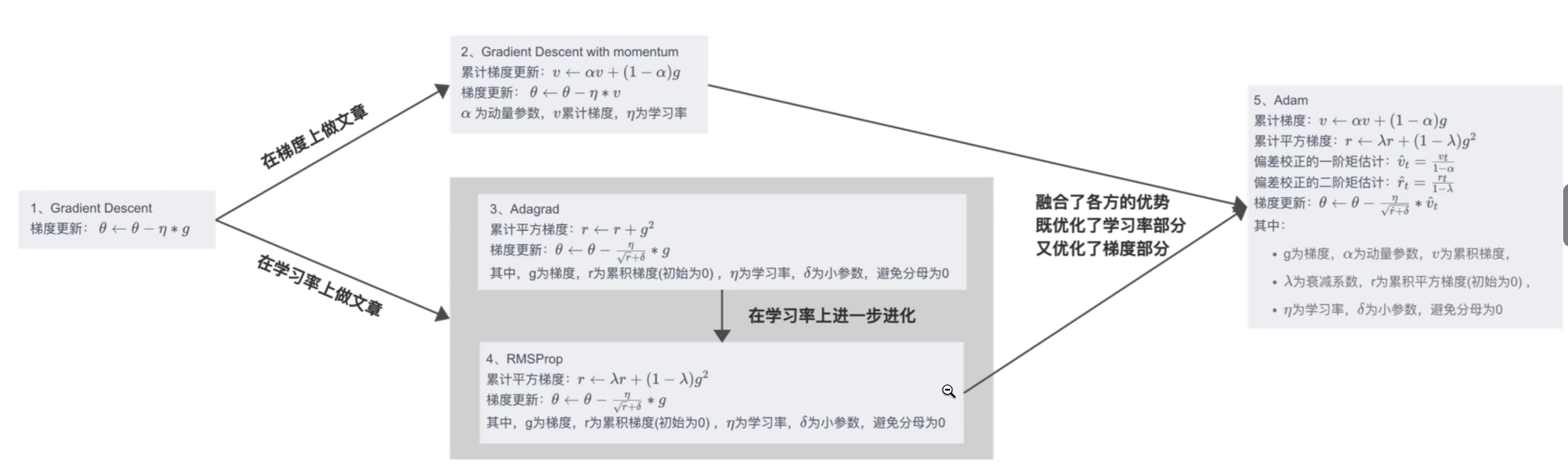
BV1jh4y1q7ua

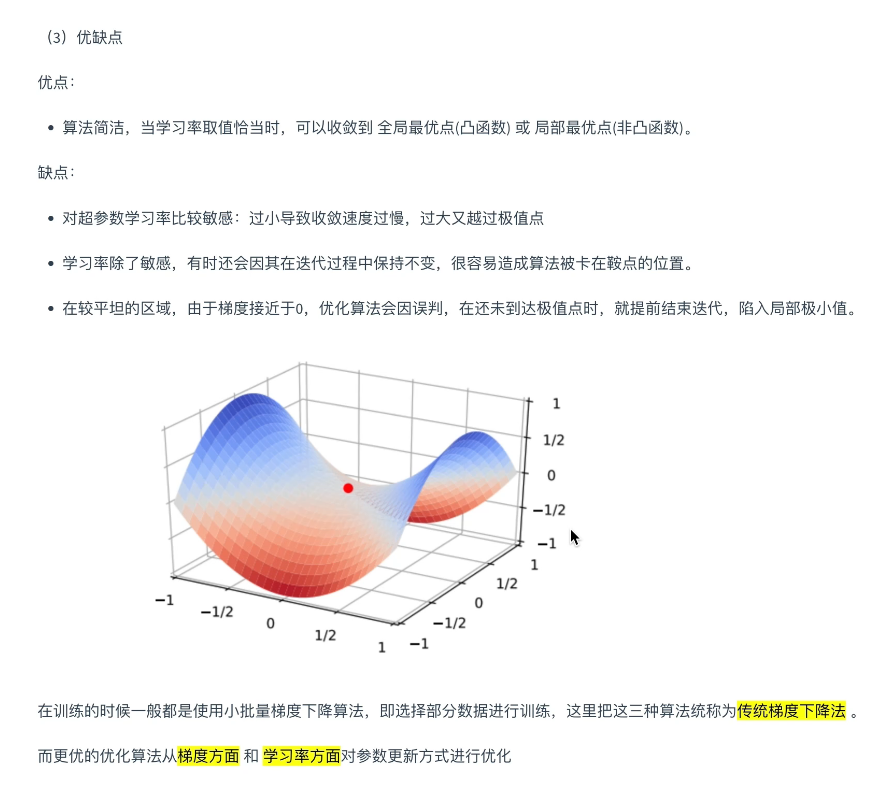
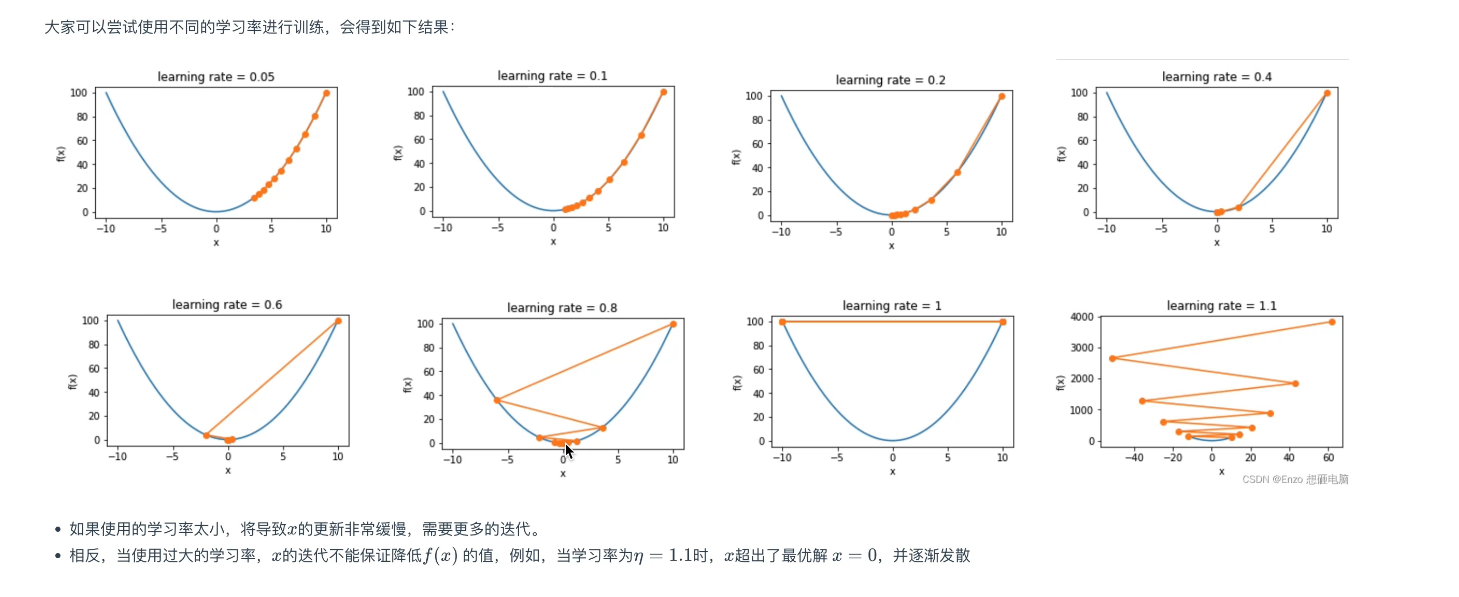

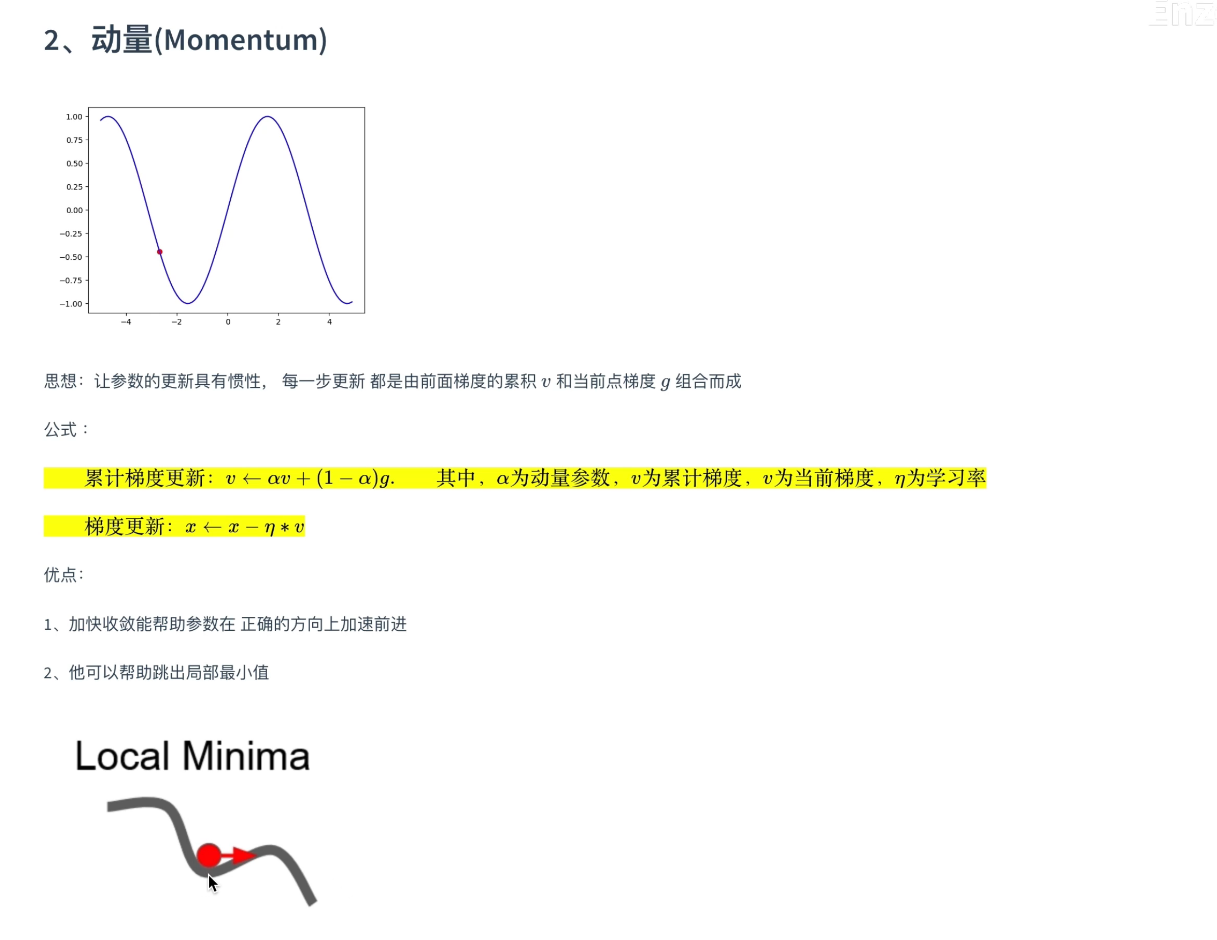



adam非常非常平滑的SGD,如果没时间狂调参数,用adam是一个很好的选择
SGD+动量 调好效果可能比adam好一点点
八、模型训练过程
# 训练1000个epoch(整个数据集遍历1000次)
for epoch in range(1000):
loss = None # 初始化损失变量
# 遍历DataLoader,获取批量数据
for batch_x, batch_y in dataloader:
# 前向传播:输入批量x,得到预测值y_predict
y_predict = net(batch_x)
""" 计算损失:预测值vs真实值
调用之前定义的nn.MSELoss(),计算预测值和真实值的均方误差;
loss是一个 PyTorch 张量(包含梯度信息),值越小说明预测越准 """
loss = Loss(y_predict, batch_y)
""" 梯度清零:避免上一轮梯度累积
PyTorch 的梯度会自动累积(比如第 2 批数据的梯度会叠加在第 1 批的梯度上);
必须在反向传播前清零,否则梯度混乱,参数更新错误 """
optim.zero_grad()
# 反向传播:计算参数的梯度
loss.backward()
# 按adam优化器公式,更新参数:根据梯度调整网络权重
optim.step()
# 每100个epoch打印日志+可视化拟合效果
if (epoch+1) % 100 == 0:
# 打印当前epoch和损失值
print("step: {0} , loss: {1}".format(epoch+1, loss.item()))
# 用训练好的模型预测整个训练集
predict = net(torch.tensor(X, dtype=torch.float))
# 可视化拟合效果
if scatter:
plt.scatter(x, y, 1) # 真实值:散点图(点大小1)
else:
plt.plot(x, y, color="coral", label="fact") # 真实值:折线图
# 预测值:折线图(coral色)
plt.plot(x, predict.detach().numpy(), color="coral", label="predict")
plt.title("function")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.legend() # 显示图例
plt.show() # 展示图片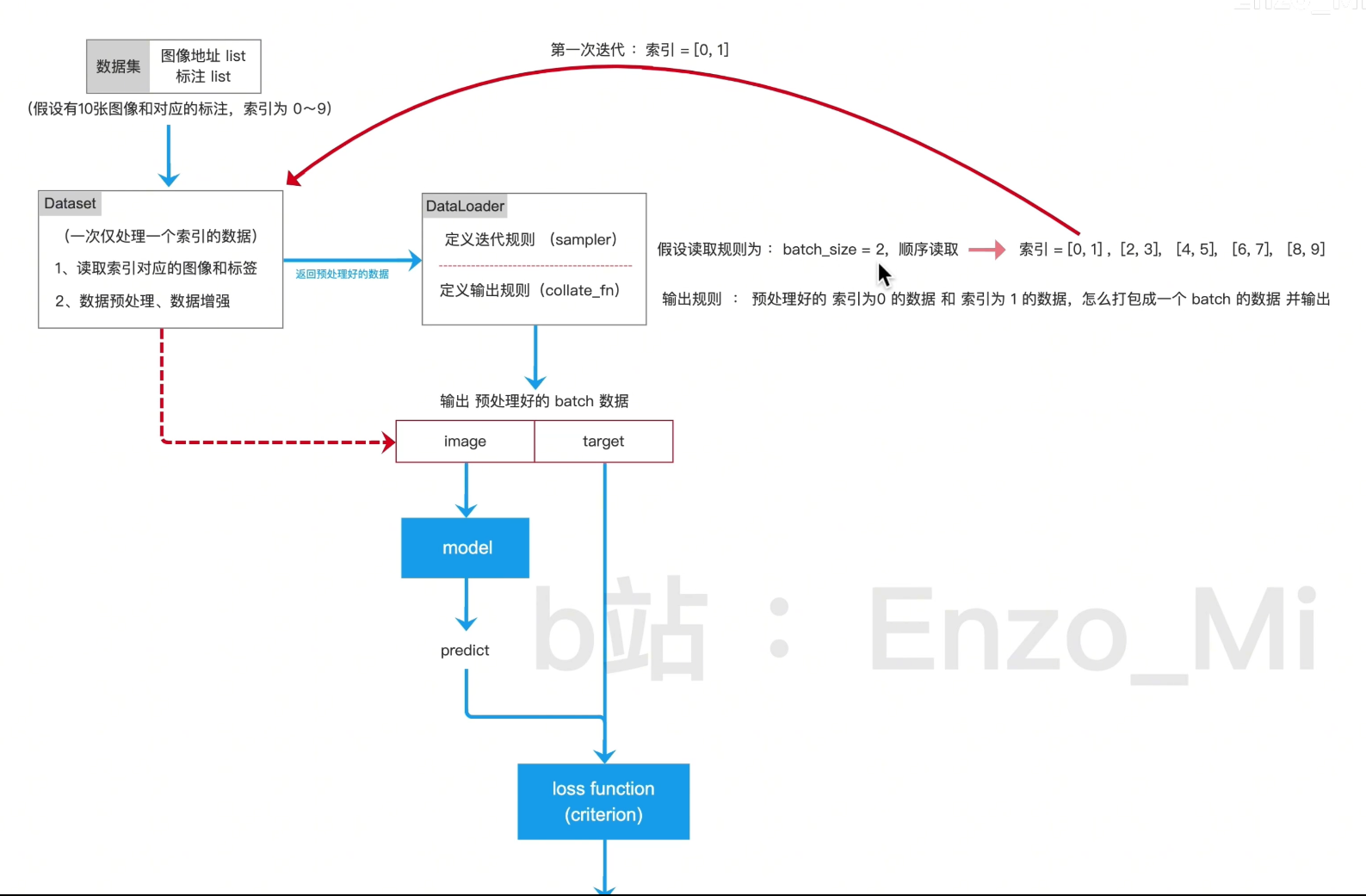
 核心流程(每个 epoch):
核心流程(每个 epoch):
1.批量读取数据 → 2. 前向传播算预测值 → 3. 计算损失 → 4. 梯度清零 → 5. 反向传播算梯度 → 6. 优化器更新参数;
可视化关键:
predict.detach().numpy():将 PyTorch 张量转为 numpy 数组(detach()避免梯度追踪,否则报错)。
九、模型泛化能力测试(训练区间外的预测)
# 1. 绘制训练集真实值
if scatter:
plt.scatter(x, y, 1)
else:
plt.plot(x, y, label="fact")
# 2. 生成测试集数据:x范围[5,10](训练集是[-5,5],测试泛化能力)
test_s = train_e # 测试集起始:5(训练集结束位置)
test_e = test_s + 5 # 测试集结束:10
test_x = np.linspace(test_s, test_e, data_num) # 生成100个测试x
test_y = test_x ** 3 + 2 * test_x ** 2 # 测试集真实y
# 3. 调整测试集数据维度
test_X = np.expand_dims(test_x, axis=1)
test_Y = test_y.reshape(data_num, -1)
"""4. 用训练好的模型预测测试集
把测试集传入训练好的模型,得到测试集的预测值pre; """
pre = net(torch.tensor(test_X, dtype=torch.float))
# 5. 合并训练集和测试集的x/y,用于整体可视化
x = np.concatenate((x, test_x), axis=0) # x: [-5,10]
y = np.concatenate((y, test_y), axis=0) # y: 对应x的真实值
""" 6. 合并训练集和测试集的预测值
detach()切断梯度追踪,.numpy()转为 NumPy 数组; """
pre_y = np.concatenate((predict.detach().numpy(), pre.detach().numpy()), axis=0)
# 7. 绘制整体预测结果
plt.plot(x, pre_y, color="coral", label="predict")
# 8. 绘制整体真实值
if scatter:
plt.scatter(x, y, 1, color="blue", label="fact")
else:
plt.plot(x, y, label="fact", color="blue")
# 9. 图表配置
plt.xlabel("x")
plt.legend()
plt.show()核心目的:测试模型在训练区间外(5~10)的预测能力,验证模型是否能泛化到未见过的数据(而非只记住训练集);
关键观察:如果模型在 5~10 区间的预测曲线和真实曲线接近,说明泛化能力好;如果偏差大,说明模型过拟合(只记住训练集,不会举一反三)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)