回归预测任务:基于 COVID-19 相关特征预测阳性数量
整个代码是一个端到端的回归预测任务,目标是基于 COVID-19 相关特征预测阳性数量,
流程可概括为:
1.数据处理:读取 CSV→划分训练 / 验证 / 测试集→特征选择→标准化;
2.模型构建:简单全连接网络(输入→64 维→1 维);
3.训练优化:SGD + 动量优化,带 L2 正则的 MSE 损失,监控验证损失保存最优模型;
4.预测输出:用最优模型预测测试集,生成 CSV 结果。
一、模块导入:加载所需工具库
import matplotlib.pyplot as plt # 绘制训练/验证损失曲线
import torch # 深度学习框架(张量运算、模型构建、自动求导)
import numpy as np # 数值计算(数组处理、矩阵运算)
import csv # 读取/写入CSV文件(处理数据集和预测结果)
import pandas as pd # 数据处理(备选:更便捷的CSV读取,代码中未实际使用)
from torch.utils.data import DataLoader, Dataset # PyTorch数据加载工具(批量处理数据)
import torch.nn as nn # PyTorch神经网络模块(定义线性层、激活函数等)
from torch import optim # PyTorch优化器模块(定义SGD等优化器)
import time # 计算每轮训练耗时
from sklearn.feature_selection import SelectKBest, chi2 # 特征选择(用卡方检验选最优特征)
import os # 系统操作(解决Matplotlib多线程冲突)
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" # 防止Matplotlib因KMP库冲突报错所有导入的库都是为后续 “数据处理→模型训练→结果输出” 服务,其中torch和sklearn是核心(分别负责模型和特征选择)。
二、特征选择函数:筛选最优特征(减少冗余,提升模型效率)
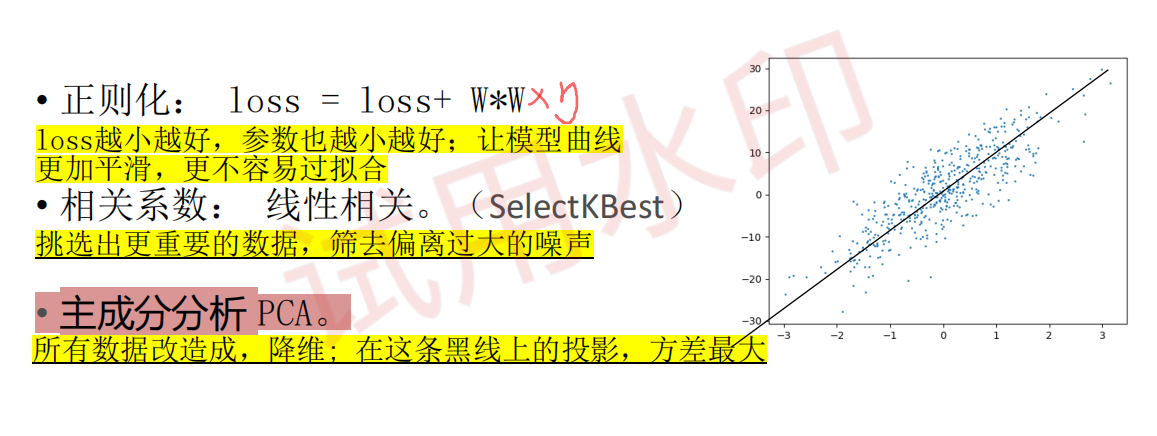
使用相关系数


功能:从所有特征中筛选出k个与标签相关性最强的特征(用卡方检验)
参数:
feature_data:输入特征数据(二维数组,每行一个样本,每列一个特征)
label_data:标签数据(一维数组,每个样本的目标值)
k:要选择的最优特征数量(默认4)
column:特征列名列表(用于打印选中的特征名称,可选)
返回:
X_new:筛选后的k维特征数据
indices[0:k]:选中特征在原始特征中的下标
此处省略 feature_data, label_data 的生成代码。
如果是 CSV 文件,可通过 read_csv() 函数获得特征和标签。
这个函数的目的是, 找到所有的特征种, 比较有用的k个特征, 并打印这些列的名字。
def get_feature_importance(feature_data, label_data, k=4, column=None):
model = SelectKBest(chi2, k=k) # 定义特征选择器:用卡方检验(chi2)选k个最优特征
# 卡方检验适用于“分类特征+分类标签”,此处默认数据集符合该场景
feature_data = np.array(feature_data, dtype=np.float64)
#np.array() 是 NumPy 库中创建数组(ndarray) 的核心函数
# 确保特征数据为float64类型(避免计算错误)
X_new = model.fit_transform(feature_data, label_data)
# 拟合数据并筛选特征:输出k维特征
print('x_new', X_new)
# 打印筛选后的特征数据(调试用,查看特征维度是否正确)
scores = model.scores_ # 获取每个特征的“重要性得分”(得分越高,与标签相关性越强)
indices = np.argsort(scores)[::-1]
# 对得分排序:argsort返回下标,[::-1]反转成“从高到低”
if column: # 如果传入了列名,打印选中的k个特征名称(方便理解哪些特征有用)
# indices[0:k]是前k个最优特征的下标,column[i+1]对应原始CSV的列名(跳过第一列id)
k_best_features = [column[i+1] for i in indices[0:k].tolist()]
print('k best features are: ', k_best_features)
return X_new, indices[0:k] # 返回筛选后的特征数据和对应下标(后续数据加载用下标取特征)2.1 model = SelectKBest(chi2, k=k)
chi2是卡方检验(Chi-Squared Test)的缩写,是sklearn中实现卡方检验的工具,
在SelectKBest里的作用是衡量 “特征与标签的相关性”,从而筛选出对标签影响最大的 k 个特征。
一、chi2(卡方检验)是什么?
卡方检验是一种统计检验方法,核心是判断 “两个变量(这里是 “特征” 和 “标签”)是否独立”:
如果特征和标签不独立(卡方值大):说明这个特征和标签相关性强,对预测标签更有用;
如果特征和标签独立(卡方值小):说明这个特征和标签没关系,是冗余特征。
二、在SelectKBest中chi2的作用
SelectKBest(chi2, k=k)的逻辑是:
对每个特征,用chi2计算它与标签的卡方统计量(得分越高,相关性越强);
按卡方得分从高到低排序,选出前 k 个得分最高的特征。
三、chi2的适用场景
卡方检验有两个前提:
特征是离散型数据(比如 “性别(男 / 女)”“年龄段(18-25/26-35)”);
标签是分类类型(比如 “是否阳性(0/1)”)。
如果你的数据集是 “连续特征 + 回归标签”(比如预测数值型的阳性数量),用chi2可能不太合适,更推荐用f_regression(基于 F 检验的回归特征选择)。
简单说,chi2在这里就是个 “打分工具”—— 给每个特征打个 “和标签的相关度分数”,方便SelectKBest选最优特征。
2.2、np.array() 的核心作用



![]()

2.3、model.fit_transform(feature_data, label_data)
特征选择环节的核心代码,它整合了 “训练特征选择器” 和 “筛选特征” 两个关键动作,最终输出筛选后的最优特征集。
一、核心作用
这行代码的本质是:
先用特征和标签 “训练” 卡方检验的特征选择器,再用训练好的选择器对原始特征数据做 “筛选”,最终得到仅包含 k 个最优特征的新数据集。
对应到你的场景:
输入:原始特征 feature_data(比如 93 维)、标签 label_data;
输出:X_new(仅包含 k 个与标签相关性最强的特征,比如 6 维)。
二、拆解 fit_transform() 的执行逻辑
fit_transform() 是 sklearn 中所有数据预处理 / 特征选择类的通用方法,
它等价于先调用 fit() 再调用 transform(),但更高效(避免重复计算)。
第一步:fit(feature_data, label_data)(训练特征选择器)
作用:
让 SelectKBest(chi2, k=k) 这个 “特征选择器” 学习数据的规律 ——计算每个特征与标签的卡方得分,并按得分排序,确定 “哪些特征是前 k 优的”。
具体操作:
1.对每个特征,用卡方检验(chi2)计算它和标签的 “相关性得分”;
2.把所有特征的得分从高到低排序;
3.记录前 k 个得分最高的特征的下标(比如第 5、18、23、45、67、89 列)。
这一步只 “学习规律”,不改变原始数据。
第二步:transform(feature_data)(筛选特征)
作用:
根据 fit() 阶段确定的 “前 k 优特征下标”,从原始特征数据中只保留这些特征列,删掉其他冗余列。
具体操作:
1.读取 fit() 阶段记录的前 k 个特征下标;
2.从 feature_data 中提取这些下标对应的列;
3.返回提取后的新数组(维度从 [样本数, 93] 变成 [样本数, k])。
当你执行 model.fit_transform(feature_data, label_data) 时,model 内部会完成:
对每一个原始特征,单独和标签做卡方检验,计算出一个卡方得分;
把所有特征的得分按 “原始特征的列顺序” 存入 model.scores_。
三、fit_transform() 的优势
合并 fit() 和 transform() 两步,减少一次数据遍历,效率更高;
保证 “筛选特征时用的规则” 和 “训练时的规则” 完全一致(避免手动调用时的不一致问题)。
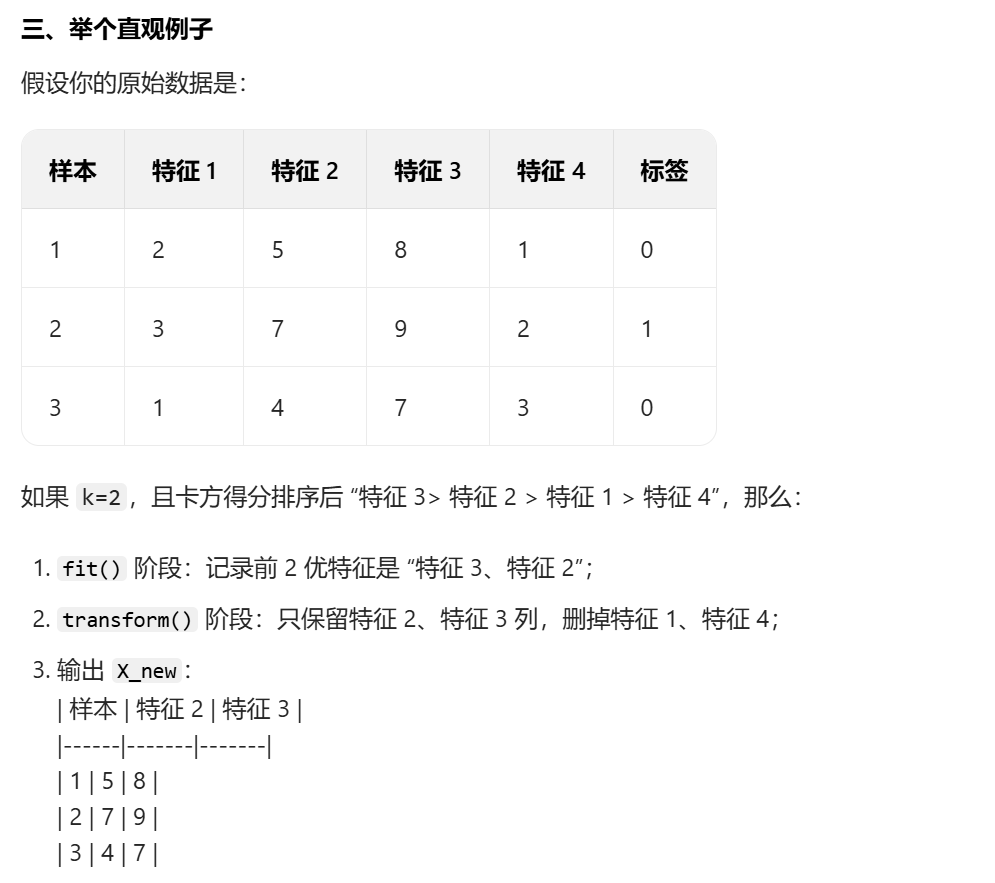
2.4 k_best_features = [column[i+1] for i in indices[0:k].tolist()]
根据特征得分排序后的下标,从特征名列表中提取出 “得分最高的前 k 个特征的名称”,最终得到一个包含 k 个最优特征名的列表

核心部分 1:indices[0:k].tolist()
indices[0:k]:从降序排序的特征下标数组中,截取前 k 个下标(这 k 个下标对应得分最高的 k 个特征);
.tolist():把 NumPy 数组(indices是 np 数组)转成 Python 原生列表,避免后续遍历时报类型错误。
2. 核心部分 2:i+1(最关键的偏移逻辑)
这里的+1是下标补偿,原因是:
你的原始数据中,CSV 文件的第一列通常是id(无用列),所以在计算特征得分时,是从第二列(下标 1)开始的特征列;
而indices中的下标是 “特征列的相对下标”(比如i=0对应第一个特征列),但column列表包含了id列(下标 0),所以需要i+1才能匹配到正确的特征名。
3. 核心部分 3:column[i+1]
从特征名列表column中,根据偏移后的下标提取对应的特征名。
三、自定义数据集类:加载和预处理数据(适配 PyTorch)
核心作用:统一数据处理流程—— 将原始 CSV 数据转为 PyTorch 能处理的张量,同时完成 “划分数据集、特征选择、标准化”,为后续训练做准备。
3.1 feature = np.array( ori_data [ 1 : ] ) [ : , 1 : -1 ]
ori_data[1:]:取原始数据的第 2 行到最后一行(跳过表头);
np.array(ori_data[1:]):将列表转成 NumPy 数组,方便做列切片;
[ : , 1 : - 1 ] :
第一个 ' : ' 表示 “取所有行”;
' 1 : -1 ' 表示 “取第 1 列到倒数第 2 列”(跳过第 0 列的id,跳过最后 1 列的label);
最终feature就是训练 / 验证集的特征数据(仅包含特征列,无 id 和标签);
[ : , - 1 ] :
' - 1 ' 表示 “取最后 1 列”;
最终label_data就是训练 / 验证集的标签数据(对应每个样本的目标值)。
class CovidDataset(Dataset):
"""
功能:自定义Dataset类,实现“读取CSV数据→预处理→返回样本”的流程,适配PyTorch的DataLoader
继承自PyTorch的Dataset类,
必须实现__init__初始化、__getitem__取值、__len__求长度 三个方法
"""
def __init__(self, file_path, mode="train", all_feature=False, feature_dim=6):
"""
初始化:读取CSV文件,划分训练/验证/测试集,预处理特征(标准化+特征选择)
参数:
file_path:CSV文件路径(训练集或测试集)
mode:数据模式(train/val/test,决定是否划分数据和是否有标签)
all_feature:是否使用所有特征(True=用全部93个特征,False=用筛选后的特征)
feature_dim:筛选的特征数量(仅all_feature=False时有效)
"""
# 1. 读取CSV文件
with open(file_path, "r") as f:
ori_data = list(csv.reader(f))
# 读取所有行,ori_data[0]是列名,ori_data[1:]是数据
column = ori_data[0]
# 列名列表(如["id", "feature1", "feature2", ..., "label"])
# 读取数据部分:跳过第一列(id),转为float类型(避免字符串运算)
csv_data = np.array(ori_data[1:])[:, 1:].astype(float)
# 2. 准备特征和标签(仅训练/验证集需要标签,测试集无标签)
if mode in ["train", "val"]:
# 训练/验证集:特征是除id和label外的列,标签是最后一列
feature = np.array(ori_data[1:])[:, 1:-1]
# 特征:跳过id(第0列)和label(最后一列)
label_data = np.array(ori_data[1:])[:, -1]
# 标签:最后一列(如“tested_positive”)
else: # 测试集:无标签,特征是除id外的所有列
feature = np.array(ori_data[1:])[:, 1:] # 跳过id列
label_data = None # 测试集无标签,设为None
# 3. 特征选择(决定用哪些特征)
if all_feature: # 用所有特征(共93个,对应csv_data的前93列,最后一列是标签)
col = np.array([i for i in range(0, 93)]) # 特征下标:0~92(共93个)
else: # 用筛选后的特征:调用get_feature_importance选feature_dim个最优特征
_, col = get_feature_importance(feature, label_data, feature_dim, column)
# 4. 划分训练/验证/测试集(按“逢5取1”的规则划分训练和验证集)
col = col.tolist() # 特征下标转为列表(方便后续切片)
if mode == "train": # 训练集:取所有下标不被5整除的样本(80%数据)
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
data = torch.tensor(csv_data[indices, :-1]) # 训练集特征:跳过最后一列(标签)
self.y = torch.tensor(csv_data[indices, -1]) # 训练集标签:最后一列
elif mode == "val": # 验证集:取所有下标被5整除的样本(20%数据)
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
data = torch.tensor(csv_data[indices, :-1]) # 验证集特征
self.y = torch.tensor(csv_data[indices, -1]) # 验证集标签
else: # 测试集:无标签,取所有样本,数据是除id外的所有列
indices = [i for i in range(len(csv_data))]
data = torch.tensor(csv_data[indices]) # 测试集特征(无标签)
# 5. 特征标准化(重要!避免不同量级特征影响模型训练)
# 标准化公式:(x - 均值) / 标准差,按特征列计算(dim=0),保持维度(keepdim=True)
self.data = (data - data.mean(dim=0, keepdim=True)) / data.std(dim=0, keepdim=True)
self.mode = mode # 记录数据模式(用于__getitem__判断是否返回标签)
def __getitem__(self, idx):
"""
功能:按索引idx返回单个样本(适配DataLoader批量读取)
返回:
训练/验证集:(特征张量, 标签张量) 有x,y
测试集:仅特征张量(无标签) 只有x,没有y,需要预测y的部分
"""
if self.mode != "test":
return self.data[idx].float(), self.y[idx].float() # 转为float32(PyTorch默认精度)
else:
return self.data[idx].float()
def __len__(self):
"""功能:返回数据集的样本总数(DataLoader需要知道总长度来计算批次)"""
return len(self.data)四、模型定义:构建简单的全连接神经网络
模型结构:输入特征(inDim) → 全连接层(64维) → ReLU → 全连接层(1维)
核心作用:学习特征到标签的映射关系—— 通过两层线性层和非线性激活,拟合 COVID-19 阳性数量的预测函数。
class MyModel(nn.Module):
"""
功能:定义一个简单的全连接神经网络(回归模型,预测COVID-19阳性数量)
继承自PyTorch的nn.Module,必须实现__init__(定义层)和forward(前向传播)
"""
def __init__(self, inDim):
"""
初始化:定义神经网络的层结构
参数:inDim:输入特征维度(即筛选后的特征数量,如6)
"""
super(MyModel, self).__init__() # 调用父类nn.Module的初始化方法(必须)
self.fc1 = nn.Linear(inDim, 64) # 第一层全连接层:inDim维输入→64维输出
self.relu1 = nn.ReLU() # ReLU激活函数:引入非线性,提升模型表达能力
self.fc2 = nn.Linear(64, 1) # 第二层全连接层:64维输入→1维输出(回归任务,预测单个值)
def forward(self, x): # 模型前向传播过程(输入x→输出预测值)
x = self.fc1(x) # 输入x经过第一层全连接层
x = self.relu1(x) # 经过ReLU激活函数(非线性变换)
x = self.fc2(x) # 经过第二层全连接层(得到1维预测值)
# 处理输出维度:如果输出是(batch_size, 1),压缩为(batch_size)(避免后续计算维度不匹配)
if len(x.size()) > 1:
return x.squeeze(1) # 挤压第1维(如(16,1)→(16))
return x五、训练与验证函数:执行模型训练和性能评估
核心流程:
训练(前向→损失→反向→更新)→ 验证(前向→损失,无更新)→ 保存最优模型→ 绘图
关键作用:
让模型在训练中学习规律,在验证中监控过拟合,最终得到泛化能力强的最优模型。
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
"""
功能:执行模型训练、验证,记录损失,保存最优模型,绘制损失曲线
参数:
model:待训练的模型
train_loader:训练集数据加载器(批量提供训练数据)
val_loader:验证集数据加载器(批量提供验证数据)
device:训练设备(cuda或cpu)
epochs:训练轮次(整个数据集遍历的次数)
optimizer:优化器(如SGD,用于更新模型参数)
loss:损失函数(如带正则的MSE,用于计算预测误差)
save_path:最优模型的保存路径
"""
model = model.to(device) # 将模型移动到指定设备(cuda加速或cpu)
plt_train_loss = [] # 记录每轮训练的平均损失(用于绘图)
plt_val_loss = [] # 记录每轮验证的平均损失(用于绘图)
min_val_loss = 9999999999999 # 初始化最小验证损失(用于保存最优模型)
for epoch in range(epochs): #冲锋的号角 ; 开始了训练过程;遍历每一轮训练
train_loss = 0.0 # 累计当前轮训练的总损失
val_loss = 0.0 # 累计当前轮验证的总损失
start_time = time.time() # 记录当前轮开始时间(计算耗时)
# -------------------------- 训练阶段 --------------------------
model.train()
# 模型设为训练模式:启用Dropout、BatchNorm等训练特有的层(本模型无,但规范需加)
for batch_x, batch_y in train_loader: # 遍历训练集的每个批次
# 将数据移动到指定设备(cuda/cpu)
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 前向传播:输入x→得到预测值pred
train_bat_loss = loss(pred, target, model) # 计算当前批次的损失(带正则)
train_bat_loss.backward() # 反向传播:计算参数的梯度
optimizer.step() # 优化器更新模型参数(根据梯度调整权重)之前调用sgd函数实现
optimizer.zero_grad() # 梯度清零:避免下一批次梯度累加
train_loss += train_bat_loss.cpu().item()
# 累计损失(转为CPU数值,避免显存占用)
# 计算当前轮训练的平均损失(总损失 / 批次数),存入列表
plt_train_loss.append(train_loss / train_loader.__len__())
# -------------------------- 验证阶段 --------------------------
model.eval() # 模型设为验证模式:关闭Dropout、BatchNorm等训练特有的层
with torch.no_grad():
# 禁用梯度计算(验证不更新参数,节省显存和时间)验证集不能更新梯度,故不能积攒梯度,要归0
for batch_x, batch_y in val_loader: # 遍历验证集的每个批次
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x) # 前向传播:得到验证集预测值
val_bat_loss = loss(pred, target, model) # 计算当前批次的验证损失
val_loss += val_bat_loss.cpu().item() # 累计验证损失
# 计算当前轮验证的平均损失,存入列表
plt_val_loss.append(val_loss / val_loader.__len__())
# -------------------------- 保存最优模型 --------------------------
if val_loss < min_val_loss: # 如果当前验证损失是历史最小,保存模型
torch.save(model, save_path) # 保存整个模型(参数+结构)
min_val_loss = val_loss # 更新最小验证损失
# -------------------------- 打印训练信息 --------------------------
# 输出:轮次/总轮次、耗时、训练损失、验证损失
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f | Valloss: %.6f" %
(epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1]))
# -------------------------- 绘制损失曲线 --------------------------
plt.plot(plt_train_loss) # 绘制训练损失曲线
plt.plot(plt_val_loss) # 绘制验证损失曲线
plt.title("loss") # 图表标题
plt.legend(["train", "val"]) # 图例:区分训练和验证损失
plt.show() # 显示图表六、测试与预测函数:用最优模型生成测试结果
核心作用:将训练好的模型应用于新数据(测试集),生成可提交的预测结果。
def evaluate(sava_path, test_loader, device, rel_path):
"""
功能:用训练好的最优模型预测测试集,生成CSV格式的预测结果
参数:
sava_path:最优模型的保存路径
test_loader:测试集数据加载器
device:预测设备(cuda或cpu)
rel_path:预测结果的保存路径(CSV文件)
"""
# 加载保存的最优模型,并移动到指定设备
model = torch.load(sava_path).to(device)
rel = [] # 存储所有测试样本的预测结果
model.eval() # 模型设为验证模式(无训练操作)
with torch.no_grad():
# 禁用梯度计算(节省资源);测试中不更新参数,不能累计梯度
for x in test_loader: # 遍历测试集的每个样本(batch_size=1,逐个预测)
pred = model(x.to(device)) # 前向传播:输入测试样本→得到预测值
rel.append(pred.cpu().item()) # 将预测值转为CPU数值,存入列表
print(rel) # 打印预测结果(调试用,查看预测值范围)
# 写入预测结果到CSV文件(符合竞赛提交格式:第一列id,第二列tested_positive)
with open(rel_path, "w", newline='') as f:
csvWriter = csv.writer(f) # 创建CSV写入器
csvWriter.writerow(["id", "tested_positive"]) # 写入表头
for i, value in enumerate(rel): # 遍历预测结果,按id顺序写入
csvWriter.writerow([str(i), str(value)]) # id从0开始,预测值为value
print("文件已经保存到" + rel_path) # 提示文件保存路径七、主程序:参数配置与流程执行(串联所有模块)
所有导入的库都是为后续 “数据处理→模型训练→结果输出” 服务,其中torch和sklearn是核心(分别负责模型和特征选择)。
# 1. 配置特征相关参数:是否用所有特征,特征维度
all_feature = False # False=用筛选后的特征,True=用全部93个特征
if all_feature:
feature_dim = 93 # 全特征时,输入维度93
else:
feature_dim = 6 # 筛选特征时,输入维度6(选6个最优特征)
# 2. 配置文件路径:训练集、测试集路径
train_file = "covid.train.csv" # 训练集文件(代码中未提供,需确保路径正确)
test_file = "covid.test.csv" # 测试集文件(用户上传的文件)
# 3. 创建数据集实例:训练集、验证集、测试集
train_dataset = CovidDataset(train_file, "train", all_feature=all_feature, feature_dim=feature_dim)
val_dataset = CovidDataset(train_file, "val", all_feature=all_feature, feature_dim=feature_dim)
test_dataset = CovidDataset(test_file, "test", all_feature=all_feature, feature_dim=feature_dim)
# 4. 创建数据加载器:批量读取数据(shuffle=True打乱训练集,避免过拟合)
batch_size = 16 # 批次大小:每批处理16个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 训练集加载器(打乱)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True) # 验证集加载器(打乱,不影响)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False) # 测试集加载器(不打乱,保证id顺序)
# 5. 配置训练设备:优先用cuda(GPU加速),否则用cpu
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device) # 打印当前使用的设备(调试用)
# 6. 配置训练参数:学习率、轮次、动量、模型保存路径、结果保存路径
config = {
"lr": 0.001, # 学习率:控制参数更新步长
"epochs": 20, # 训练轮次:遍历数据集20次
"momentum": 0.9, # 动量系数:加速收敛,抑制震荡
"save_path": "model_save/best_model.pth", # 最优模型保存路径(需确保文件夹存在)
"rel_path": "pred.csv" # 预测结果保存路径
}
# 7. 定义带正则化的MSE损失函数(防止过拟合)
def mseLoss_with_reg(pred, target, model):
loss = nn.MSELoss(reduction='mean') # 基础MSE损失(均方误差,回归任务常用)
regularization_loss = 0 # 初始化正则化损失(L2正则)
for param in model.parameters(): # 遍历模型所有参数(fc1和fc2的权重、偏置)
# L2正则:计算所有参数的平方和(权重衰减,避免参数过大导致过拟合)
regularization_loss += torch.sum(param ** 2)
# 总损失 = 基础MSE损失 + 正则化损失(0.00075是正则化强度,超参数可调整)
return loss(pred, target) + 0.00075 * regularization_loss
# 8. 初始化模型、损失函数、优化器
model = MyModel(inDim=feature_dim).to(device) # 创建模型,输入维度=特征维度,移动到指定设备
loss = mseLoss_with_reg # 损失函数:带L2正则的MSE
# 优化器:SGD(随机梯度下降),带动量(momentum=0.9)
optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])
# 9. 执行训练和验证
train_val(model, train_loader, val_loader, device, config["epochs"], optimizer, loss, config["save_path"])
# 10. 执行测试和预测,生成结果文件
evaluate(config["save_path"], test_loader, device, config["rel_path"])
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)