【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)
提示:笔记源自于赋范空间“大模型Agent开发实战”,课程链接为:https://appze9inzwc2314.h5.xet.citv.cn/p/course/ecourse/course_37xx2DBh83EgnWSwQFYDOoBLPpS?type=3&sub_course_list_mode=0
一、前期准备
大前提:python3.9及以上,推荐3.11,API key可用,API key相关内容在下面这篇文章有介绍
【Agent】大模型在线API接入基础入门
import os
from dotenv import load_dotenv
from openai import OpenAI
# 从项目根目录的 .env 文件加载环境变量(DEEPSEEK_API_KEY 等)
load_dotenv()
# 测试连接
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# 最小调用样例
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "你好"}],
max_tokens=50
)
print(f"✅ API 连接成功,模型响应: {response.choices[0].message.content}")
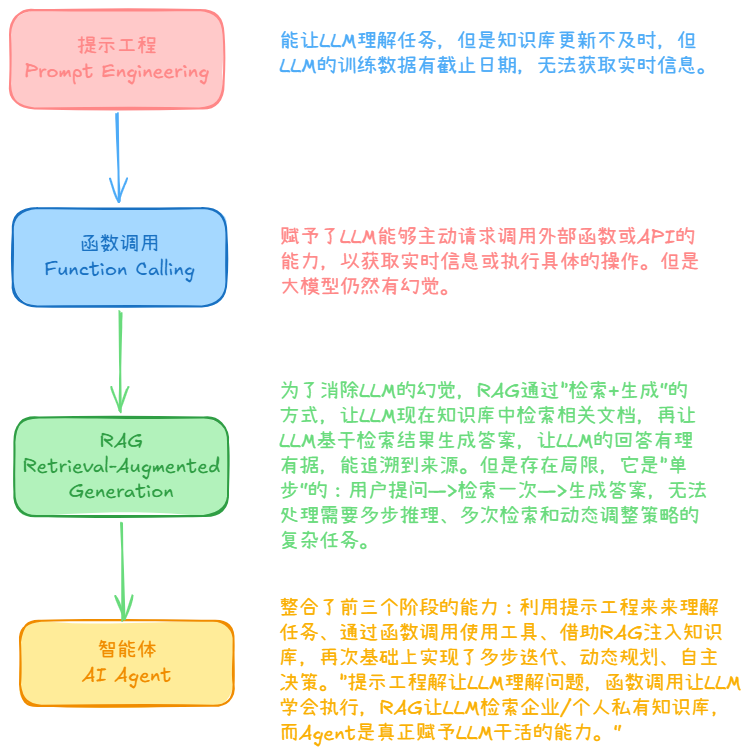
二、技术发展路线
2025-2026年是Agent技术的“落地之年”:
Agent 技术成熟度演进(2023-2026)
| 阶段 | 时间 | 代表事件 | 成熟度 |
|---|---|---|---|
| 概念验证期 | 2023 | AutoGPT 引发热潮 | 能演示,不能生产 |
| 框架探索期 | 2024 | LangChain、CrewAI 发布 | 能开发,工程化不足 |
| 协议统一期 | 2024 末-2025 | MCP(Model Context Protocol,模型上下文协议)协议发布、LangChain 1.0 | 工具生态统一,框架成熟 |
| 生产落地期 | 2025-2026 | A2A(Agent-to-Agent)协议、Agent 中间件、LangSmith(LLM 应用观测与调试平台) | 全链路生产就绪 |
1.1从prompt到Agent
1.2 LLM原生能力与涌现能力
原生能力
大模型在预训练或微调阶段,通过学习大量数据记住知识和技能,但是这些技能和知识是固化的,类似于我们在学校学习高等数学一样,这种能力是通过训练、固化在模型参数中的。
涌现能力
指大模型在推理时,通过类比、组合已有知识来解决“没见过”的问题的能力。类似于在高考时刷到新题型,虽然没有做过原题,但是可以通过所学方法推理出答案。
原生能力 vs 涌现能力对比
| 维度 | 原生能力 | 涌现能力 |
|---|---|---|
| 获得方式 | 预训练/微调 | 推理时激发 |
| 稳定性 | 高(固化在参数中) | 中(依赖提示质量) |
| 可扩展性 | 低(需要重新训练) | 高(通过提示即可) |
| 典型应用 | 语言理解、知识问答 | 工具使用、任务规划 |
| Agent 中的作用 | 提供基础理解能力 | 支撑动态决策能力 |
1.3 失败的GPT Plugins
既然大模型已经通过prompt到RAG的发展具了原生能力和涌现能力,那为什么Agent直到2025年才成功?OpenAI在2023年提出了GPT Plugins:打造一个类似于APP Store的生态系统,让每个人都能以极低门槛创建自己的智能应用。OpenAI提供了强大的GPT-4模型和插件接口,开发者只需要定义工具的功能描述,GPT-4就能够自主决定何时调用。但是直到2023年底,GPT Plugins的使用率远低于预期,于是在2024年4月关闭了Plugins,转而退出GPTs和Actions,那失败的原因是什么?
GPT Plugins 失败的三大原因
| 原因 | 具体表现 | 影响 |
|---|---|---|
| 模型能力不足 | GPT-4(2023 版)工具调用可靠性不足,复杂场景常出错 | 复杂任务经常失败,用户体验差 |
| 工具生态混乱 | 插件质量参差不齐,缺少统一标准 | 用户不知道该用哪个插件 |
| 编排能力缺失 | 只能单步调用,无法多步规划 | 只能处理简单任务,无法解决复杂问题 |
这个失败案例告诉我们:Agent并不是“LLM+工具”那么简单,它需要模型能力+工具生态+编排框架三者协同进化。
2025-2026Agent落地的原因:三大基础设施已成熟:
(1) 模型能力跃迁:GPT-4o、Claude 3.5 Sonnet、DeepSeek V3 等新一代模型的工具调用可靠性大幅提升,复杂场景下的成功率显著优于早期模型
(2) 工具生态统一:MCP 协议(2024.11)提供了被广泛采纳的工具集成标准
(3) 编排框架成熟:LangGraph、CrewAI、Claude Agent SDK 等框架提供了多步规划能力
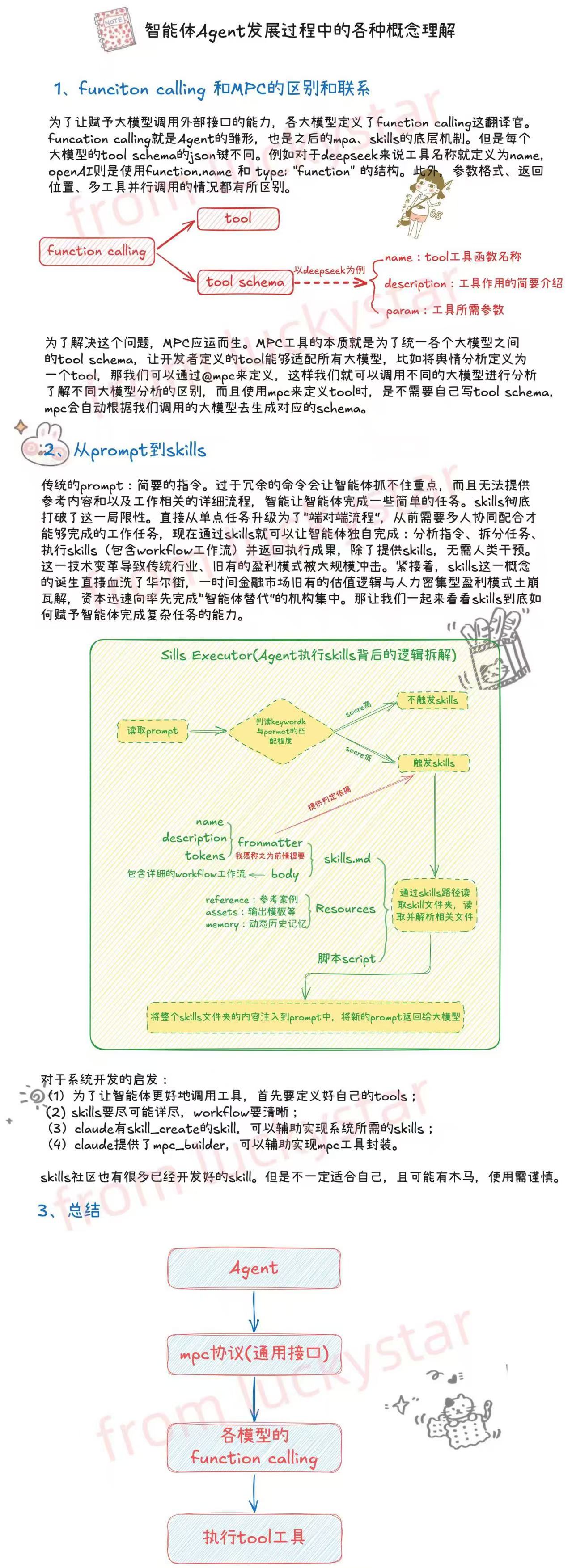
1.4 Agent技术生态
当前Agent技术生态可以从三个维度来理解:框架层、协议层和应用层。
(1)框架层
-
AutoGPT/BabyAGI:证明了 Agent 的可行性,但工程化不足,主要用于概念验证
-
LangChain Agent/CrewAI:提供了可用的开发工具,但缺少生产级的监控、调试、版本管理能力
-
LangGraph/Claude Agent SDK:提供了完整的生产工具链,包括状态管理、错误恢复、可观测性、A/B 测试等
(2)协议层
工具集成的统一标准。2024 年 11 月,Anthropic 发布的 MCP(Model Context Protocol)协议正在成为 Agent 工具集成的主流标准之一。在此之前,每个框架都有自己的工具定义方式,导致工具无法跨框架复用。MCP 的出现解决了这个问题——就像 HTTP 协议统一了 Web 服务的接口标准一样,MCP 统一了 Agent 工具的接口标准。这意味着:一个遵循 MCP 协议的工具(如天气查询工具),可以被 LangChain、CrewAI、Claude Agent SDK 等任何支持 MCP 的框架直接使用,无需重复开发。
(3)Agent应用
-
代码生成与调试:如 Devin、Cursor、GitHub Copilot Workspace,能够自主完成需求分析 → 代码编写 → 测试 → 调试的完整流程
-
客户服务:如智能客服 Agent,能够理解复杂问题、查询知识库、调用业务系统、生成个性化回答
-
数据分析:如 Data Analyst Agent,能够理解自然语言查询、生成 SQL、执行查询、可视化结果、解释发现
-
内容创作:如 Content Agent,能够调研主题、收集素材、生成初稿、优化润色、配图排版
三、Agent的核心架构:TAO循环
Agent内部的运转逻辑:TAO循环(Think—>Act—>Observe)。这个循坏是所有Agent架构的共同基础。无论是ReAct、Plan-and-Execute还是Agent编排,底层都是TAO循环的变体。理论溯源——从思考链(CoT)到ReAct框架的演进。
3.1 思想链(Chain-of-Thought)
论文来源:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
CoT核心思想:通过将复杂问题分解为多个逻辑步骤,让LLM按顺序推理,从而提高准确率。两个关键机制:1、分解问题:将复杂任务拆解为更小的步骤;2、顺序思维:每一步建立在上一步的结果之上。
CoT局限性:虽然显著提高了LLM的推理能力,但是如果有某一步出现错误,错误会沿着推理链传播,导致最终答案完全错误。更致命的问题是:LLM无法自我验证中间步骤的正确性。
3.2 TAO循环(ReAct运行机制)
论文来源:REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS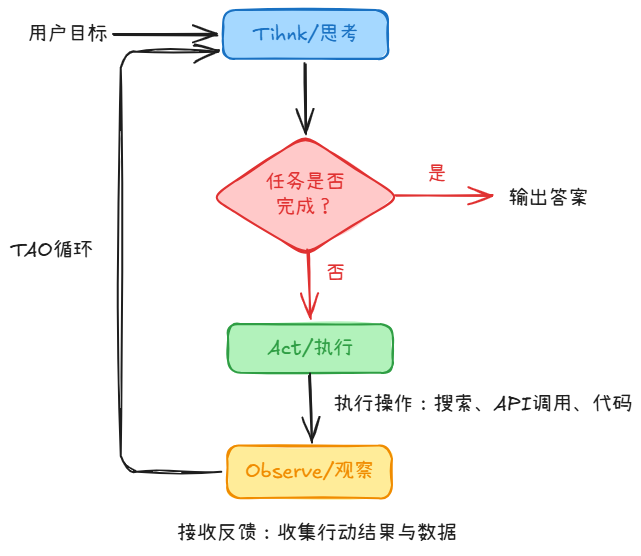
ReAct关键创新:推理跟踪(Reasoning Trace),让LLM在每次行动前线生成一段推理文本,解释为什么要这样做。
Think(思考):LLM 作为"大脑",分析当前状态和用户目标,决定下一步行动。这一步可能包括:判断任务是否完成、确定需要调用的工具、规划执行顺序、评估风险等。
Act(行动):根据 Think 阶段的决策,调用相应的工具或生成回答。如果决定调用工具,就执行工具调用;如果判断任务已完成,就生成最终回答。
Observe(观察):收集 Act 阶段的结果——如果是工具调用,收集工具返回的数据;如果是生成回答,观察用户的反馈。将观察结果纳入上下文,为下一轮 Think 提供输入。
这三个环节形成一个闭环,循环往复直至任务完成。TAO 循环的精妙之处在于它的自终止性——Agent 在每一轮的 Think 阶段都会判断"任务是否已经完成",如果完成就输出最终答案并退出循环,如果未完成就继续下一轮。这意味着 Agent 可以根据任务复杂度自动调整执行步数:简单任务一轮就结束,复杂任务可能需要五轮、十轮甚至更多。
3.3 ReAct如何解决CoT的幻觉?
纯CoT的执行路径:
-
Thought: 我需要知道地球的质量
-
Thought: 根据我的训练数据,地球质量约为 5.972 × 10²⁴ kg
-
Thought: 两倍就是 5.972 × 10²⁴ × 2 = 1.1944 × 10²⁵ kg
-
Answer: 地球质量的两倍是 1.1944 × 10²⁵ kg
TAO执行路径:
-
Thought: 我需要查询地球的准确质量
-
Action: search(“地球质量”)
-
Observation: 搜索结果显示地球质量为 5.972 × 10²⁴ kg
-
Thought: 现在我需要计算两倍
-
Action: calculate(5.972e24 * 2)
-
Observation: 计算结果为 1.1944 × 10²⁵ kg
-
Answer: 地球质量的两倍是 1.1944 × 10²⁵ kg
3.4 ReAct的Prompt提示词
以LangChain的ReAct Prompt为例:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: {agent_scratchpad}
#%% md
这个模板中有四个占位符:
-
{tools}:工具的详细描述 -
{tool_names}:工具名称列表 -
{input}:用户的原始问题 -
{agent_scratchpad}:保存历史推理记录
四、Agent的核心要素
自主性(Autonomy)——从"被指挥"到"自驱动"。自主性是 Agent 最核心的特征。一个具备自主性的 Agent,在接收到高层目标后,能够独立完成任务分解、工具选择、执行顺序规划和异常处理,而不需要人类逐步指挥。例如,当用户说"帮我调研竞品",Agent 能自主决定:调研哪些维度、从哪些渠道获取信息、如何组织报告结构。
感知能力(Perception)——从"只读文字"到"感知世界"。 传统聊天机器人的输入只有用户的文字消息。而 Agent 的感知范围要广得多——它可以通过工具获取实时数据(天气、股价、新闻)、读取文件系统中的文档、解析数据库查询结果、甚至处理图片和音频输入。更重要的是,Agent 的感知是主动的:它不是被动等待用户提供信息,而是在推理过程中主动判断"我还需要什么信息。
推理与规划(Reasoning & Planning)——从"直觉回答"到"深思熟虑"。LLM 本身就具备一定的推理能力,但这种推理是"单次"的——给定输入,直接生成输出。Agent 的推理则是迭代式的:它可以先生成一个初步计划,执行第一步后根据结果调整后续计划,遇到障碍时回退并尝试替代方案。规划能力是 Agent 处理复杂任务的关键。
行动执行(Action Execution)——从"纸上谈兵"到"真实操作"。行动执行是 Agent 区别于所有"纯文本生成"系统的标志性能力。Agent 不仅能生成"应该怎么做"的文字描述,还能通过工具真正执行操作:发送 HTTP 请求、执行 SQL 查询、运行 Python 代码、操作文件系统、调用第三方 API。
#%% md
Agent 四大核心特征
| 核心特征 | 能力描述 |
|---|---|
| 自主性(Autonomy) | 独立分解任务、选择工具、规划执行 |
| 感知能力(Perception) | 主动获取环境信息、处理多模态输入 |
| 推理与规划(Reasoning & Planning) | 迭代推理、任务分解、动态重规划 |
| 行动执行(Action Execution) | 调用工具执行真实操作 |
五、Function Calling
Function Calling 六步流程详解
| 步骤 | 阶段名称 | 执行者 | 核心动作 |
|---|---|---|---|
| 步骤 1 | 用户输入 | 用户 | 向 Agent 提出请求,例如"北京今天天气怎么样?" |
| 步骤 2 | LLM 分析与决策 | LLM | 接收用户请求和可用工具列表,判断是否需要调用工具 |
| 步骤 3 | 生成调用指令 | LLM | 返回结构化 JSON:{"name": "get_weather", "arguments": {"city": "北京"}} |
| 步骤 4 | 代码执行工具 | 代码 | 解析调用指令,找到对应函数并执行 |
| 步骤 5 | 结果回传 | 代码 | 将工具执行结果封装为消息,回传给 LLM |
| 步骤 6 | LLM 综合回答 | LLM | 结合用户请求和工具结果,生成最终自然语言回答 |
5.1 定义工具函数
import math
import requests
import json
import sys
import io
# 设置标准输出编码为 UTF-8,解决 Windows 控制台乱码问题
if sys.stdout.encoding != 'UTF-8':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
def get_weather(query: str) -> str:
"""
使用 Serper.dev 搜索天气信息
"""
print(f"\n[Tool 执行中] 正在通过 Serper 查询 {query} 天气...")
# 换成你从 serper.dev 拿到的 Key
SERPER_API_KEY = "b1588e926f78ee0b80e201f4e7e884ae84dec1d6"
url = "https://google.serper.dev/search"
headers = {
"X-API-KEY": SERPER_API_KEY,
"Content-Type": "application/json"
}
# 拼接搜索词,让搜索更精准
payload = json.dumps({"q": f"{query} 天气"})
response = requests.post(url, headers=headers, data=payload)
if response.status_code == 200:
data = response.json()
# 提取搜索到的有机结果
snippets = [item["snippet"] for item in data.get("organic", [])[:3]]
result_text = "\n".join(snippets) if snippets else "未找到相关天气信息"
return json.dumps({"status": "success", "search_result": result_text}, ensure_ascii=False)
else:
return json.dumps({"status": "error", "message": f"API请求失败: {response.text}"})
def calculate(expression: str) -> str:
"""安全的数学计算工具,支持基本运算和常用数学函数"""
# 安全白名单:只允许数学相关的函数和运算符
allowed_names = {
"abs": abs, "round": round, "min": min, "max": max,
"pow": pow, "sum": sum,
"sqrt": math.sqrt, "log": math.log, "log10": math.log10,
"sin": math.sin, "cos": math.cos, "tan": math.tan,
"pi": math.pi, "e": math.e,
}
try:
# 使用 eval 配合白名单,防止代码注入
result = eval(expression, {"__builtins__": {}}, allowed_names)
return json.dumps({
"expression": expression,
"result": result,
"status": "success"
}, ensure_ascii=False)
except Exception as e:
return json.dumps({
"expression": expression,
"error": str(e),
"status": "failed"
}, ensure_ascii=False)
# 验证工具函数
print("天气查询测试:", get_weather("搜索北京今天的天气"))
print("计算测试:", calculate("7654321 * 1234567"))
🌍 [Tool 执行中] 正在通过 Serper 查询 搜索北京今天的天气 天气...
天气查询测试: {"status": "success", "search_result": "5日(今天). 晴. 5℃. <3级 · 6日(明天). 晴. 17℃/3℃. 3-4级转<3级 · 7日(后天). 晴. 15℃/5℃. <3级 · 8日(周三). 多云. 21℃/9℃. <3级 · 9日(周四). 多云转小雨. 19℃/10℃. <3级 ...\n11:00 · 11℃. 1.6m/s. 东南风. 1006hPa ; 14:00 · 15.1℃. 3.3m/s. 南风. 1002.6hPa ; 17:00 · 13.8℃. 3m/s. 西南风. 1000.4hPa.\n北京 今天:晴 3°~17°C 西北风3级. 04月06日 周一 农历二月十九. 10°. 24 优. 晴 ... 生活气象指数 夜深了,今日天气晴好,心情也要保持晴朗哦. 穿衣: 毛衣类. 3℃~17 ..."}
计算测试: {"expression": "7654321 * 1234567", "result": 9449772114007, "status": "success"}
5.2 定义工具列表JSON Schema
工具定义三要素:name、description、parameters
Function Calling 的第一步,是告诉 LLM"你有哪些工具可以用"。这通过一个标准化的 JSON Schema 来实现。每个工具的定义包含三个核心字段:name(工具名称)、description(工具描述)、parameters(参数定义)。LLM 完全依赖这三个字段来决定何时调用哪个工具、传什么参数。
# 定义工具的 JSON Schema —— 这是 LLM 的"工具说明书"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": (
"获取指定城市的当前天气信息,包括气温(摄氏度)、天气状况和湿度。"
"当用户询问某个城市的天气、气温、是否需要带伞/穿外套等问题时,调用此工具。"
"目前支持的城市:北京、上海、广州、深圳、杭州。"
),
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "要查询天气的城市名称,例如:北京、上海、广州,对应的日期,例如:今天、明天、后天,以及需要查询的天气信息,例如:天气、气温、湿度等"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": (
"执行数学计算,支持加减乘除、幂运算、三角函数、对数等。"
"当用户需要精确计算数学表达式时调用此工具。"
"输入应为合法的 Python 数学表达式,例如:'2**10'、'sqrt(144)'、'7654321 * 1234567'。"
"注意:不要用此工具回答不涉及计算的问题。"
),
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "要计算的数学表达式,使用 Python 语法,例如:'2**10'、'sqrt(144)'"
}
},
"required": ["expression"]
}
}
}
]
print(f"已注册 {len(tools)} 个工具:{[t['function']['name'] for t in tools]}")
注意观察工具描述的写法——每个描述都包含了"做什么"(功能说明)、“什么时候调用”(触发条件)和"能力边界"(支持的城市列表、输入格式要求)。这种三段式描述能显著提升 LLM 的工具选择准确率。
5.3 发送请求并获取 LLM 的工具调用决策
现在进入 Function Calling 的核心环节——将用户消息和工具定义一起发送给 LLM,让它决定是否需要调用工具。
from dotenv import load_dotenv
from openai import OpenAI
import os
# 从项目根目录的 .env 文件加载环境变量(DEEPSEEK_API_KEY 等)
load_dotenv()
client = OpenAI(
api_key=os.environ.get("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com" # DeepSeek API 端点
)
def call_llm_with_tools(messages: list, tools: list, model: str = "deepseek-chat") -> dict:
"""向 LLM 发送带工具定义的请求,返回完整的响应对象"""
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice="auto", # "auto" 让 LLM 自主决定是否调用工具
temperature=0.7,
max_tokens=2048
)
return response
# 测试:一个需要工具的问题
messages = [
{"role": "system", "content": "你是一个有用的助手,可以查询天气和进行数学计算。"},
{"role": "user", "content": "北京今天天气怎么样?"}
]
response = call_llm_with_tools(messages, tools)
assistant_message = response.choices[0].message
# 检查 LLM 是否决定调用工具
print(f"LLM 是否调用工具:{assistant_message.tool_calls is not None}")
if assistant_message.tool_calls:
for tool_call in assistant_message.tool_calls:
print(f" 工具名称:{tool_call.function.name}")
print(f" 调用参数:{tool_call.function.arguments}")
print(f" 调用 ID:{tool_call.id}")
else:
print(f" 直接回答:{assistant_message.content}")
LLM 是否调用工具:True
工具名称:get_weather
调用参数:{"query": "北京今天天气"}
调用 ID:call_00_nplvyuEoRgx7lxFcqfWEuLyg
5.4 执行工具并返回结果
# 建立工具名称到函数的映射(工具注册表),方便根据 LLM 返回的名称动态调用
TOOL_REGISTRY = {
"get_weather": get_weather,
"calculate": calculate,
}
def execute_tool_calls(assistant_message) -> list:
"""
解析并执行 LLM 消息中的所有工具调用请求。
参数:
assistant_message: LLM 生成的消息对象,包含 tool_calls 列表。
返回:
list: 包含工具执行结果的消息列表,格式符合 OpenAI API 的 tool 角色要求。
"""
tool_results = []
# 如果 LLM 没有发起工具调用,直接返回空结果列表
if not assistant_message.tool_calls:
return tool_results
# 遍历 LLM 请求的所有工具调用(LLM 可能会一次性请求调用多个工具)
for tool_call in assistant_message.tool_calls:
# 提取工具名称和 LLM 生成的参数(参数通常为 JSON 字符串,需解析为字典)
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"[执行工具] {func_name},参数:{func_args}")
# 在注册表中查找对应的函数并传入参数执行
if func_name in TOOL_REGISTRY:
# 使用 ** 语法将字典解包为函数的关键字参数
result = TOOL_REGISTRY[func_name](**func_args)
else:
# 如果 LLM 请求了一个未定义的工具,返回错误信息给模型
result = json.dumps({"error": f"未知工具:{func_name}"})
print(f"[执行结果] {result}")
# 将执行结果封装为特定的消息格式
# 核心要点:role 必须为 "tool",且 tool_call_id 必须与原始请求的 id 严格一致
tool_results.append({
"role": "tool",
"tool_call_id": tool_call.id, # 关键:用于 LLM 匹配请求与响应
"content": str(result) # 结果内容需转为字符串
})
return tool_results
# 调用执行函数,处理 assistant_message 中的工具请求
tool_results = execute_tool_calls(assistant_message)
print(f"\n工具执行完毕,共完成 {len(tool_results)} 个任务")
[Tool 执行中] 正在通过 Serper 查询 北京今天天气 天气...
[执行结果] {"status": "success", "search_result": "天气 ; 气温, 6.8℃, 11℃ ; 降水, 无降水, 无降水 ; 风速, 1.1m/s, 1.6m/s ; 风向, 东北风, 东南风 ...\n5日(今天). 晴. 5℃. <3级 · 6日(明天). 晴. 17℃/3℃. 3-4级转<3级 · 7日(后天). 晴. 15℃/5℃. <3级 · 8日(周三). 多云. 21℃/9℃. <3级 · 9日(周四). 多云转小雨. 19℃/10℃. <3级 ...\n11:00 · 11℃. 1.6m/s. 东南风. 1006hPa ; 14:00 · 15.1℃. 3.3m/s. 南风. 1002.6hPa ; 17:00 · 13.8℃. 3m/s. 西南风. 1000.4hPa."}
工具执行完毕,共完成 1 个任务
5.5 封装完整的 Function Calling 管线
def function_calling_pipeline(user_message: str, system_message: str = None, max_iterations: int = 5, verbose: bool = True) -> str:
"""
运行完整的函数调用管道
参数:
user_message: 用户输入的消息
system_message: 可选的系统提示,如果为 None 则使用默认系统提示
max_iterations: 最大工具调用迭代次数,防止无限循环
verbose: 是否打印详细执行过程
返回:
str: 助手的最终回答
"""
# 初始化消息历史
messages = [
{"role": "system", "content": system_message or "你是一个有用的助手,可以查询天气和进行数学计算。"},
{"role": "user", "content": user_message}
]
if verbose:
print(f"用户输入: {user_message}")
print(f"可用工具: {[t['function']['name'] for t in tools]}")
# 迭代处理工具调用(最多 max_iterations 轮)
for iteration in range(max_iterations):
if verbose:
print(f"\n{'='*60}")
print(f"第 {iteration + 1} 轮迭代")
# 调用 LLM
response = call_llm_with_tools(messages, tools)
assistant_message = response.choices[0].message
# 检查 LLM 是否决定调用工具
if assistant_message.tool_calls:
if verbose:
print(f"LLM 决定调用 {len(assistant_message.tool_calls)} 个工具")
# 将助手的消息添加到历史中
messages.append({
"role": "assistant",
"content": assistant_message.content or "",
"tool_calls": assistant_message.tool_calls
})
# 执行工具调用
tool_results = execute_tool_calls(assistant_message)
# 将工具执行结果添加到消息历史中
messages.extend(tool_results)
if verbose:
print(f"工具执行完成,等待 LLM 进一步处理...")
else:
# LLM 直接给出回答,流程结束
final_answer = assistant_message.content
if verbose:
print(f"LLM 直接给出回答,流程结束")
print(f"最终回答: {final_answer}")
return final_answer
# 达到最大迭代次数仍未结束
if verbose:
print(f"警告:达到最大迭代次数 ({max_iterations}),强制结束流程")
return "已达到最大工具调用次数,无法完成请求。"
============================================================
第 1 轮迭代
LLM 决定调用 1 个工具
[执行工具] get_weather,参数:{'query': '北京今天天气'}
[Tool 执行中] 正在通过 Serper 查询 北京今天天气 天气...
[执行结果] {"status": "success", "search_result": "6日(今天). 晴. 17/4℃. 3-4级转<3级 · 7日(明天). 晴. 16/5℃. <3级 · 8日(后天). 多云. 20/11℃. <3级 · 9日(周四). 多云转小雨. 19/10℃. <3级 · 10日(周五). 多云转晴. 21/9℃.\n11:00 · 11℃. 1.6m/s. 东南风. 1006hPa ; 14:00 · 15.1℃. 3.3m/s. 南风. 1002.6hPa ; 17:00 · 13.8℃. 3m/s. 西南风. 1000.4hPa.\n生活气象指数 夜深了,今日天气晴好,心情也要保持晴朗哦. 穿衣: 毛衣类. 3℃~17℃. 出游: 适宜. 晴, 空气优. 感冒: 极易发. 风力较大. 洗车: 不适宜. 近期有大风. 未来39天 ..."}
工具执行完成,等待 LLM 进一步处理...
============================================================
第 2 轮迭代
LLM 决定调用 1 个工具
[执行工具] calculate,参数:{'expression': 'sin(30*pi/180)'}
[执行结果] {"expression": "sin(30*pi/180)", "result": 0.49999999999999994, "status": "success"}
工具执行完成,等待 LLM 进一步处理...
============================================================
第 3 轮迭代
LLM 直接给出回答,流程结束
最终回答: 根据查询和计算结果:
1. **北京今天天气**:
- 天气状况:晴
- 温度:4℃ ~ 17℃
- 风力:3-4级转<3级
- 穿衣建议:毛衣类
- 出游:适宜(晴,空气优)
- 感冒指数:极易发(风力较大)
2. **sin(30度) 的值**:
- sin(30°) = 0.5(精确值为0.5,计算结果显示为0.49999999999999994,这是由于浮点数精度造成的微小误差)
总结:北京今天天气晴朗,温度在4-17℃之间,风力较大,建议穿毛衣。而sin(30度)的精确值是0.5。
测试3结果: 根据查询和计算结果:
1. **北京今天天气**:
- 天气状况:晴
- 温度:4℃ ~ 17℃
- 风力:3-4级转<3级
- 穿衣建议:毛衣类
- 出游:适宜(晴,空气优)
- 感冒指数:极易发(风力较大)
2. **sin(30度) 的值**:
- sin(30°) = 0.5(精确值为0.5,计算结果显示为0.49999999999999994,这是由于浮点数精度造成的微小误差)
总结:北京今天天气晴朗,温度在4-17℃之间,风力较大,建议穿毛衣。而sin(30度)的精确值是0.5。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)