SaiVLA-0:面向计算-觉察VLA的大脑-脑桥-小脑三元架构
26年3月来自Synthoid.ai的论文“SaiVLA-0: Cerebrum–Pons–Cerebellum Tripartite Architecture for Compute-Aware Vision-Language-Action”。
通过一个受神经科学启发的三元组重新审视视觉-语言-动作(VLA)过程。从生物学角度来看,大脑皮层提供稳定的高级多模态先验信息并保持冻结状态;脑桥适配器将这些皮层特征与实时本体感觉输入整合,并将意图编译成可执行的token;小脑(ParaCAT,平行分类动作Transformer)执行快速并行的类别解码以实现在线控制,并利用滞后/EMA/温度/熵来保证稳定性。固定比率调度和两阶段特征缓存使系统具有计算-觉察能力和可复现性。受主动注视视觉的启发,腕部感兴趣区域(ROI)通过标定投影与末端执行器几何绑定,从而提供运动稳定的高分辨率视图,该视图对细微的姿态变化敏感,并补充主视图的全局上下文。该设计采用模块化结构:升级大脑皮层只需重新训练脑桥;仅改变机器人的形态即可训练小脑;仅针对小脑的强化学习可以在不触及高层语义的情况下进一步优化控制。作为一篇概念与协议论文,本文概述一种在匹配条件(GPU/分辨率/批次)下的时间协议,以验证预期的效率提升。本文还报告LIBERO的初步证据,表明在官方N1.5头部训练条件下,特征分割缓存可减少训练时间(7.5小时→4.5小时)并提高平均成功率(86.5%→92.5%),并且SaiVLA0的平均成功率达到99.0%。
现代VLA模型通常将语义理解和高频控制混杂在同一个系统中,导致高延迟和不稳定性,尤其是在数据有限的情况下,对大型VLM架构进行端到端微调既不切实际,又存在过拟合的风险[1-4][5,6]。仅仅依赖最后一层表征也难以同时捕捉全局语义和局部几何及接触细节,而不一致的提示/校准也会阻碍可复现性。
本文通过一个受神经科学启发的三元组重新审视VLA,该三元组将理解与快速控制分离,同时保持计算使用明确且可控[7-9]。大脑提供稳定的、高级的多模态先验,并在下游学习过程中保持冻结状态。脑桥适配器通过将皮层表征与实时感知和本体感觉输入整合,将意图编译成可执行的token,从而模拟脑桥的功能。小脑模块(ParaCAT)随后执行快速并行分类解码,以在极低延迟下在线调整动作策略。这种感觉运动类比也启发两-阶段训练(阶段 A 缓存冻结的大脑特征;阶段 B 端到端地训练脑桥-小脑通路)。类似的双-系统理念已出现在工业人形机器人堆栈中,例如 Figure AI 的 Helix [10]。
具体而言,一个冻结的大型VLM(大脑 Cerebrum)以低频运行,并暴露多层隐状态。脑桥适配器(Pons Adapter)将这些状态投影到少量上下文token中。小脑(Cerebellum)—— 一个由 ViT、文本编码器和平行分类动作Transformer(ParaCAT)组成的组件——以高频率运行,融合以下信息:(i) 当前图像(主图像 1028×800 → 2562,包含两个 2562 的腕部 ROI),(ii) 指令,(iii) 机器人状态,以及 (iv) 大脑token,以生成每个维度的类别增量 {-1, 0, +1}。
采用固定比率调度(每 N = 5 个数据块运行一次大脑token),并结合微视界重用(K = 20 步/前向),以及滞后/EMA/温度/熵等机制来保证延迟下的稳定性。概览如图所示: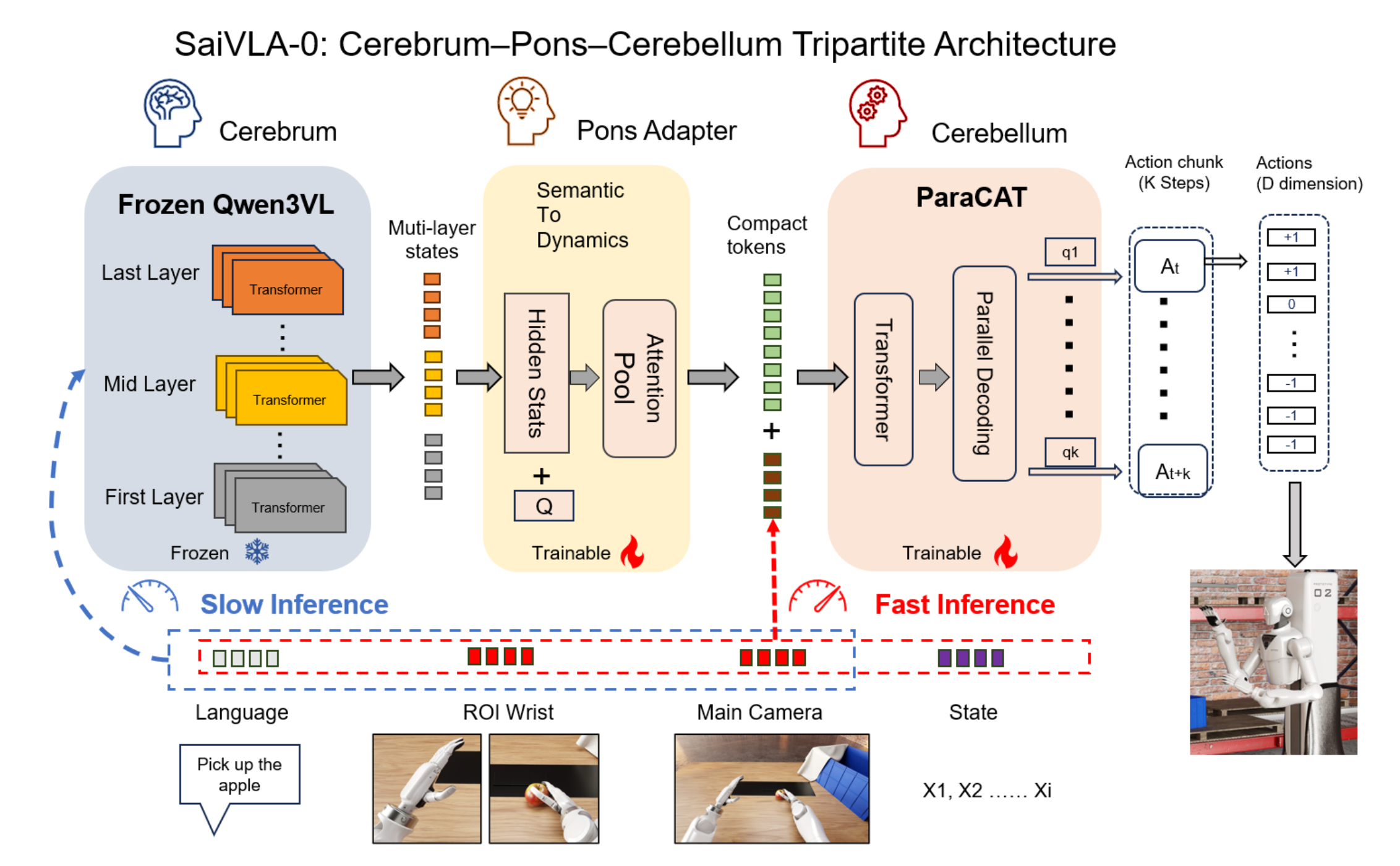
采用特征缓存和两-阶段训练流程:(A) 离线进行大脑推理,并缓存多层token和提示元数据;(B) 基于缓存的特征和当前帧训练小脑和脑桥适配器。 (可选)对适配器进行轻微调整。这可以加快迭代速度并提高可重复性[1, 11, 12]。
受神经科学启发的感兴趣区域(ROI)。人类视觉具有中心凹效应:中心凹持续指向与任务相关的目标,提供高分辨率细节,而周边视觉则提供全局上下文。ROI设计也体现这一点:腕部ROI通过标定的投影(类似于视网膜拓扑映射)与末端执行器几何绑定,从而提供运动稳定的高分辨率视图,捕捉精细的姿态和接触变化。这种视角与近期关于具身人工智能视觉基础模型的研究相辅相成,后者研究可跨任务和具身重用的“人工视觉皮层”表征[13]。感兴趣区域(ROI)token通过交叉注意与主视图token融合,类似于中央凹/周边通路的注意门控;当ROI置信度下降(例如,被遮挡)时,回退到主视图并采用更保守的解码策略(更高的温度/更强的滞后),类似于不确定性下的风险-觉察视觉运动行为。
这种划分是计算-觉察的:延迟按组件报告(大脑单次调用与小脑每次前向传递),公开吞吐量参数N和K,并且对计算归一化的成功率SR进行标准化。所谓“计算-觉察”,是指延迟、浮点运算次数(FLOPs)和成功率始终联合报告,包括SR以便进行公平比较。模块化设计使得在模拟中仅对小脑进行强化学习成为可能,而无需触及大脑或脑桥适配器。
总架构(三元)。冻结的VLM(大脑)以稀疏方式运行,并暴露多层隐状态。可训练的桥适配器(Pons adapter)将这些状态融合为固定长度的上下文token C。高频小脑融合图像 token V、文本 token W和状态 token s;其动作头引入K×D个可学习的动作查询 {q_k,j}。这些查询是模型参数(可学习的嵌入),而非外源输入。Transformer处理以下内部token 序列:
X = [C; V; W; s; {q_k,j}]。
小脑生成每个维度的分类logit R3(-1/0/+1),并使用滞后/E-MA/温度/熵约束来保证延迟下的稳定性。在双臂硬件中,D=16(两个7自由度机械臂加上两个夹爪的开/关自由度)[7, 9, 10]。
设计假设(可检验的预测)。
H1(三元延迟-稳定性):在数据有限的情况下,将低频冻结的大脑皮层与高频小脑分离,可以降低抖动和端到端延迟,且效果相当。
H2(多层上下文):使用早期/中期/晚期大脑皮层token可以改善接触敏感行为,优于仅使用最后一层上下文。
H3(分类控制):在相似的计算量下,使用具有滞后/EMA/温度/熵的每维度{-1, 0, +1}增量可以改善标定并减少振荡,优于连续头部。
H4(两-阶段缓存):在相似的精度下,离线大脑皮层缓存可以减少实际运行时间和种子方差,优于端到端调谐。
H5(调度):简单的固定大脑皮层调用节奏(每 N 个小脑块调用一次)可在相同预算下分摊计算成本并保持成功率。
H6(注视点 ROI):在计算量相当的情况下,几何绑定的手腕 ROI 加上主视图可改善接触敏感行为和稳定性指标(例如,抖动和加加速度)。
H7(计算-归一化报告):在固定的运行时间预算下,计算-归一化成功率 SR_cn 与延迟和有效操作率指标一起,可以比单独固定预算下原始成功率提供跨头和调度更有意义的比较。
大脑(冻结的VLM)。主干和提示。冻结一个大型VLM(在主要设置中为Qwen-VL-8B;在扩展研究中使用4B/32B),包括token化器和提示模板。用结构化/JSON提示(字段:目标、约束、对象、失败案例、环境),并在训练过程中随机化字段顺序以提高鲁棒性。
多层输出(冻结)。从冻结的VLM中暴露早期/中期/晚期隐状态{H^(l)_B},并保持所有主干/token化器/提示参数固定。投影/融合/池化由小脑侧的可训练脑桥适配器(大脑-到-小脑适配器)实现,因此大脑模块完全保持冻结状态。设计说明:早期/中期/晚期层分别捕获边缘/形状、对象/部件线索和语义/任务信息。
脑桥适配器。脑桥适配器(语义到动力学编译器;可训练,在线)。给定多层输出 {H(l)_B},脑桥适配器将其投影、融合并概括为 C,作为动作头的上下文token。具体来说,脑桥适配器 (i) 将结构化的大脑意图进行高维稀疏重编码,生成可执行的token;(ii) 将动作结构分解为几何、动力学先验和控制目标,以形成可组合的运动基元;(iii) 对齐反馈和意图,以简化小脑前向模型的更新,从而实现闭环稳定性。用逐层投影和融合(GLU 和跨层注意机制),然后使用可学习查询进行注意token池化。
脑桥适配器与小脑联合训练(在线适配器);仅大脑部分被冻结。在两阶段设置中,阶段 A 缓存冻结的大脑多层输出 {H(l)_B },阶段 B 基于缓存的大脑特征和当前帧,对脑桥适配器和动作头进行端到端训练。
输入:ViT 将当前 RGB 主视图(以 1028×800 捕获并调整大小为 256×256)和两个腕部 ROI(每个 256×256)编码为 V;(冻结或轻度调整的)文本编码器将指令映射到 W;低维机器人状态变为 s。通过可学习嵌入token模态(大脑/图像/文本/状态/动作),并采用相对位置编码来处理可变token长度。
小脑:ParaCAT(并行分类动作Transformer;K × D 查询)。仅编码器的Transformer处理X。ParaCAT执行并行softmax分类解码:对于每个时间维度查询(k, j),提取最终的隐值z_k,j,并通过一个共享的轻量级头部将其映射到分类logits。
选择三元网格{-1, 0, +1}使标签空间极其简单,这在经验上稳定优化过程,并使头部在数据有限和延迟预算紧张的情况下易于训练。它也与冻结VLM骨干的判别特性相匹配:小脑仅决定每个控制维度是负向移动、保持不变还是正向移动,而实际的度量尺度由固定的步长δ设定。从神经科学的角度来看,这些分类δ类似于离散的脉冲事件:经过时间整合以及通过EMA和滞后效应进行的群体式聚合后,它们在关节和肌肉层面产生平滑、连续的控制信号。用类加权交叉熵、标签平滑和可选的时间平滑进行训练。执行方面,滞后阈值和EMA可减少抖动。
执行策略(默认:无触发器的微时域重用)。给定一次前向传播得到的 (K × D) 个预测结果,按顺序执行步骤 k=1, 2, …, K,无需重新前向传播,然后对下一个数据块执行新的前向传播。这种执行和重用策略可以摊销推理成本,并在保持实现简单的同时获得更高的有效动作率;本文未使用基于不确定性/偏差的早期重规划。在实践中,ParaCAT 能够实现单次前向传播的多步决策,并且与扩散/流匹配头相比,推理速度显著提升 [2–4, 14, 26, 27]。
双频调度(固定比率)。采用简单的固定速率调度:每隔 N 个小脑块(默认 N=5)调用一次 Cerebrum。令 f_fwd 为小脑的前向传播速率,K 为块大小;有效动作速率为 f_eff ≈ K · f_fwd,而 Cerebrum 则在 N 个块上进行摊销。该策略简单有效;为简洁起见,省略伪代码。
特征缓存和两阶段训练。
阶段 A(冻结 Cerebrum 缓存)。离线运行冻结的 VLM,以提取多层输出 {H(l)_B} 以及提示元数据、标定和轨迹(包含版本哈希、形状、时间戳、校验和、依赖关系)并存储在 npz/mmap 中。
阶段 B(在线适配器 + 小脑训练)。在缓存的 {H(l)_B} 帧和当前帧上联合训练 Pons Adapter 和 ViT + Transformer 动作头;大脑保持冻结状态。
阶段 C(可选)。如有需要,可对小型桥接层进行轻微调整。从感觉运动的角度来看,这种划分对应于缓存皮层输出(阶段 A)和在线调整脑桥-小脑通路(阶段 B)[1, 11, 20, 21]。
ROI/多视图融合。通过标定的内部参数将末端执行器投影到图像坐标系中,并裁剪两个腕部 ROI(左/右)。与固定腕部摄像头不同,这些 ROI 在几何上与末端执行器绑定,相对于工具坐标系保持稳定,因此对除距离线索之外的微小姿态和接触变化更加敏感。通过交叉注意机制融合 ROI 和主视图token;在低投资回报率置信度/遮挡情况下,回归主视图,并采用更保守的解码策略(更高的温度和更强的滞后/EMA)。如图展示投影流程的示意图。其灵感来源于神经科学。人类视觉具有中心凹效应:中心凹持续指向与任务相关的目标(例如手或工具),并提供高精度细节信息,而周边视觉则提供粗略的全局上下文信息。ROI 功能类似于中心凹视图,它通过类似视网膜拓扑的投影动态地与末端执行器对齐,而主视图则作为周边上下文信息。交叉注意反映视觉通路中的注意门控;置信度感知的回退机制类似于不确定性下的风险-觉察视觉运动行为 [9, 28]。
如图所示ROI投影流水线:
复杂性和延迟。将大脑单次调用成本和小脑每步成本分开。设 f 为控制回路频率,N 为大脑重复间隔。定义单位时间的计算预算,并报告计算归一化成功率 SR_cn = SuccessRate/C。还报告冷态大脑延迟、每步小脑延迟(包括感兴趣区域)以及达到的闭环频率。
分摊计算,支持块重用。在执行和重用策略(不进行早期重新规划)下,一次小脑前向操作覆盖 K 个控制步骤。如果 f_fwd 表示前向传递速率,则有效动作率接近 f_eff ≈ K·f_fwd。
以下描述与三方设计相符的数据集、标注、提示、缓存和训练细节。默认设置已提供,并针对每个实验进行调整;在结果旁边报告具体的设置。
数据来源和划分:结合 (i) 公开的机器人演示(例如 LIBERO 子集 [29]),(ii) 一小部分真实的桌面操作任务(抓取放置、工具使用),以及 (iii) 用于长尾覆盖的可选仿真。这种设计符合大规模数据驱动机器人领域的最新趋势,其中多样化的多任务、多域数据集和数据重用框架(例如 BridgeData、DROID 和基于奖励草图的离线强化学习)已被证明可以提高泛化能力和数据效率 [30–32]。与近期依赖海量跨具身语料库的网络规模研究[19, 33, 34]不同,特意选择一个更为适中的数据集,以更好地适应计算资源有限的实验室。数据集按任务分层;训练集/验证集/测试集中的重复数据和近似重复数据均被去重。隐私敏感数据段被过滤。我们固定了随机种子,记录了环境版本,并确保了数据加载顺序的确定性。
硬件配置:一个双臂系统,包含两个7自由度机械臂;每个机械臂上安装一个灵巧的手形抓取器,具有一个开合自由度。演示数据通过VR远程操作采集;VR姿态流被映射到关节空间轨迹,速率和安全限制与数据一同记录。
动作标注(类别增量)。从带有时间戳的姿态/指令中计算每个维度的增量,并使用死区量化符号 {−1, 0, +1}:
∆p (mm) , ∆θ (deg) ⇒ y_t,j ∈ {−1, 0, +1}。
控制维度为 D=16(两个 7 自由度机械臂 + 两个机械爪开合自由度)。用步长网格 δ_p = 5 mm 和 δ_θ = 1°,零频带由小运动噪声标定。异常值(速度尖峰、滑移)通过基于鲁棒统计的每帧权重 w_t 进行降权;机械爪开合通道采用与角度网格匹配的对称阈值。为了实现微视界重用,标签与 (K × D) 网格对齐;可以在量化之前选择性地应用轻微的时间平滑以减少闪烁。
精确-控制任务。除了语义目标之外,还引入定量目标(例如,“将物体向左移动 10 厘米”),以鼓励可衡量的空间理解和精细控制。据此定义位置/方向误差指标和成功阈值,并报告误差分布以及成功率/抖动/加加速度。
针对“冻结大脑”的结构化提示。用三种提示模板(简洁、扩展、JSON)。除非另有说明,训练和推理均使用包含 goal、constraints、objects、failure_cases 和 environment 字段的 JSON 模板。在训练过程中,以 50% 的概率随机化字段顺序,并应用轻量级的文本规范化(小写、空格修剪)和指令增强(同义词替换),而不改变语义,以提高鲁棒性并减少模板偏移。
特征缓存(阶段 A,离线)。在脑干完全冻结后,离线运行模型以提取早期/中期/晚期隐藏状态 {H(l)_B}。持久化每个轨迹的存档(默认 npz/mmap 格式,float16 类型),其中包含:(i) 版本哈希、分词器 ID、提示 ID、标定 ID;(ii) 具有形状和数据类型的多层张量;(iii) 提示元数据和原始指令;(iv) 相机内参和 ROI 投影;(v) 轨迹时间戳和类别标签;(vi) 校验和以及依赖关系清单。提供一个缓存验证脚本(用于检查形状/数据类型/哈希/时间戳)和一个用于查看随机样本的小型查看器。
训练(阶段 B 和可选的阶段 C)。阶段 B 使用缓存的 {H(l)_B} 和当前帧联合训练脑桥适配器和小脑。批次大小根据任务难度进行平衡;用带标签平滑和熵正则化的类加权交叉熵。图像增强包括随机缩放裁剪、颜色抖动、高斯噪声和运动模糊;ROI 从校准图像投影,并在可用时裁剪为两个视图(左/右末端执行器),并根据置信度回退到主视图。文本编码器被冻结或通过小型适配器进行轻微调整。阶段 C(可选)在降低学习率的情况下轻微调整桥接层(例如,适配器投影);大脑皮层始终保持冻结状态。模块化划分自然地实现仅小脑的强化学习(RL)——在冻结大脑皮层和脑桥适配器的情况下微调 Para-CAT,以在不影响高层语义的情况下提高平滑度和精度。
执行策略和调度(固定比例)。采用执行-重用微时域:一次前向操作产生 K 个步骤,这些步骤按顺序执行,无需重新前向;不使用提前重新规划。除非另有说明,否则设置 K = 20。大脑每 N 个小脑块(默认 N=5)调用一次。令 f_fwd 为小脑的前向速率;有效动作速率为 f_eff ≈ K · f_fwd。此固定比例调度与“方法”部分一致,并摊销大脑的成本。
优化和正则化。除非另有说明,用 AdamW 优化器(学习率 1 × 10⁻⁴,权重衰减 0.05),余弦衰减(预热 2k 步),梯度裁剪(1.0),标签平滑 ε = 0.05,类别权重从逆频率裁剪到 [0.5, 2.0],熵正则化 λ_H ∈ [1e-3, 5e-3],时间 KL 正则化 λ_T ∈ [1e-3, 5e-3]。批次大小和训练步数根据实验而定(例如,LIBERO 初步设置使用 20k 步,批次大小为 80 × 8 个 GPU)。温度 τ 进行退火处理(例如,1.5 → 0.7);滞后阈值(θ_↑,θ_↓)默认为 (0.2, 0.2);EMA 系数 α=0.8。记录每个维度的混淆和抖动统计数据。
可复现性和日志记录。固定种子,在可行的情况下启用确定性操作,并记录以下内容:版本哈希值、数据分割清单、缓存校验和、超参数、VR 远程操作元数据(速率、安全限制)以及实际运行延迟。报告计算归一化成功率 SR_cn、冷启动大脑延迟、每步小脑延迟(包括 ROI)以及闭环频率 f_eff。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)