模型训练套路+GPU训练
这里写目录标题
完整的模型训练套路
常规训练步骤
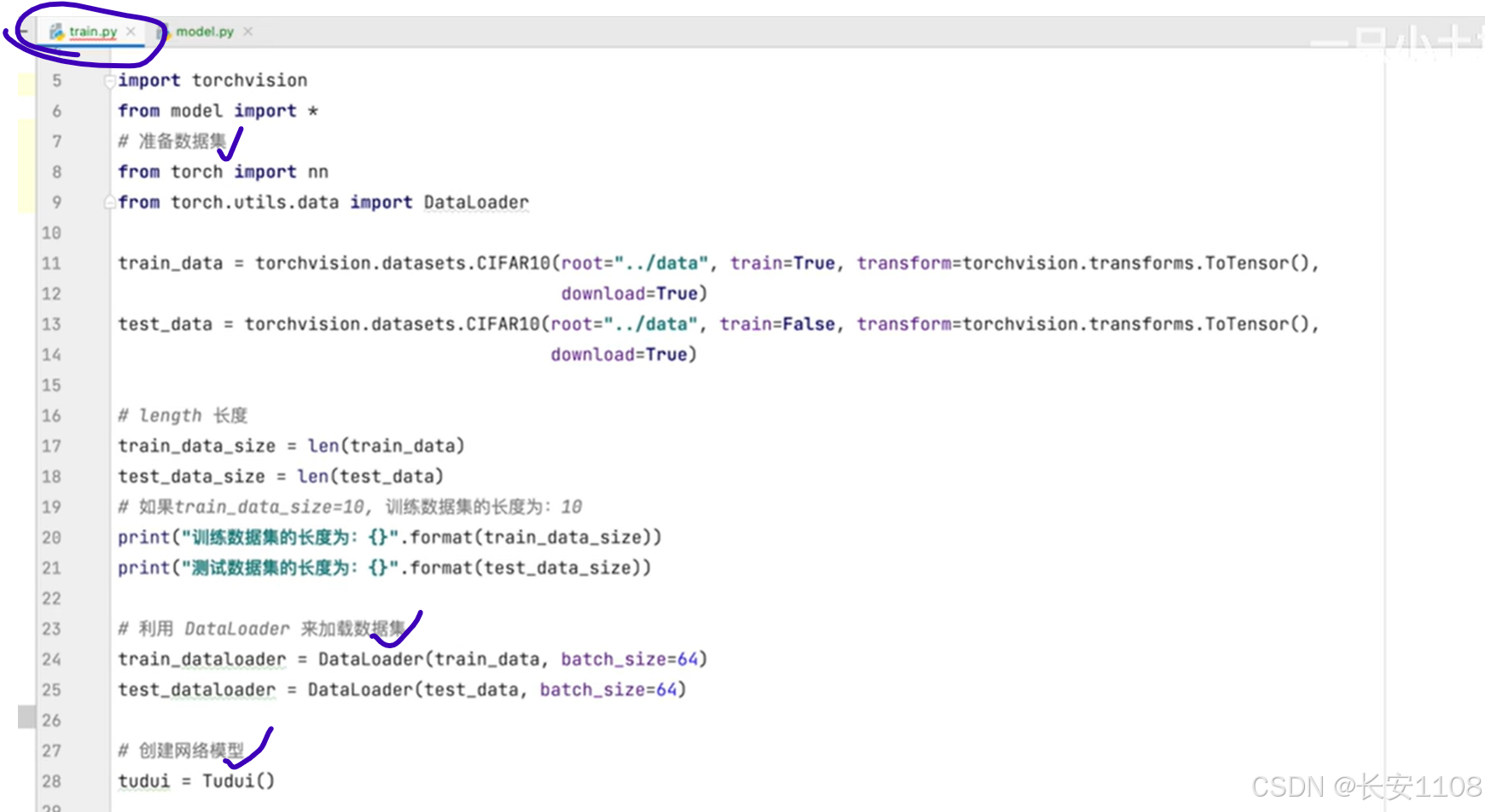
首先准备数据集,我们还是引入官网提供的CIFAR10,并且将数据转为Tensor类型,设置下载为True
之后,可以使用len方法获取数据集的长度,也就是获取到的数据集有几张图片
之后,使用Dataloader加载,抓取数据,每次抓取64张
然后,就是搭建网络模型,由于网络模型是一个类,所以,我们可以在别的python文件中,单独进行网络模型的搭建,也就是类的编写:
另起文件:Model.python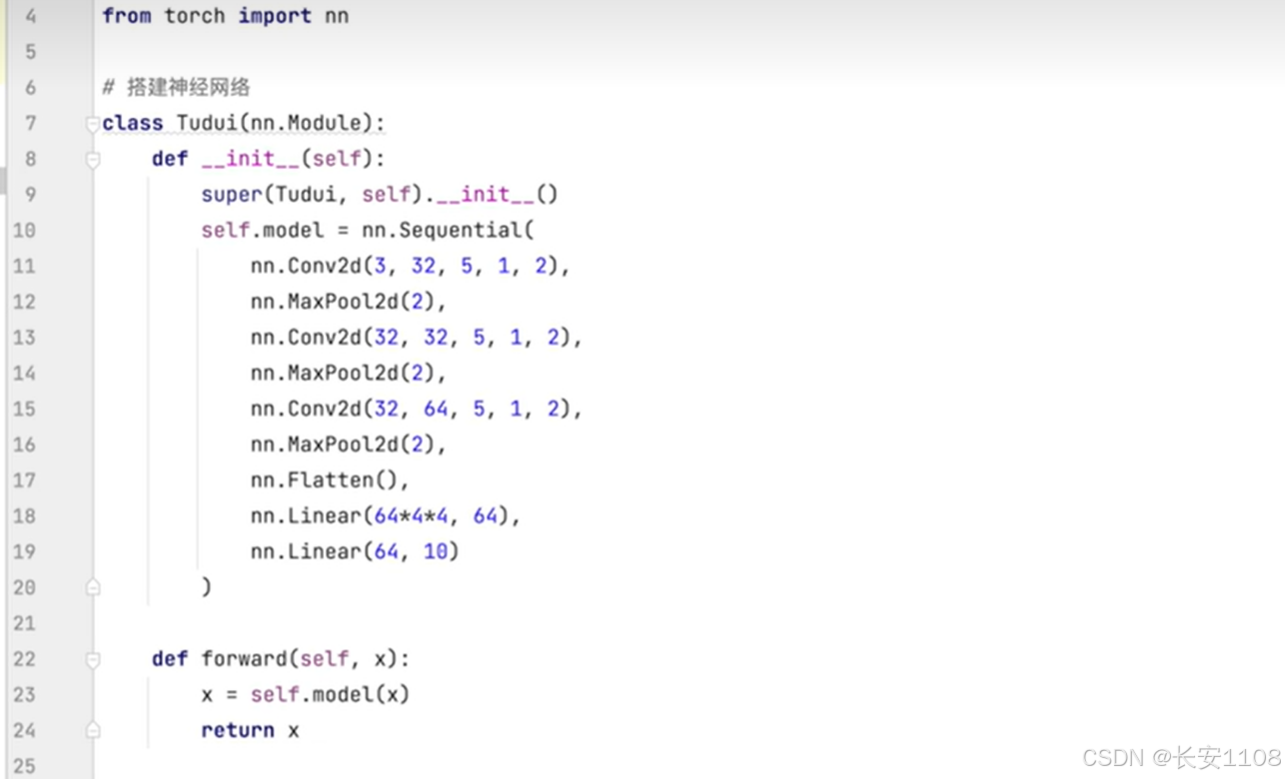
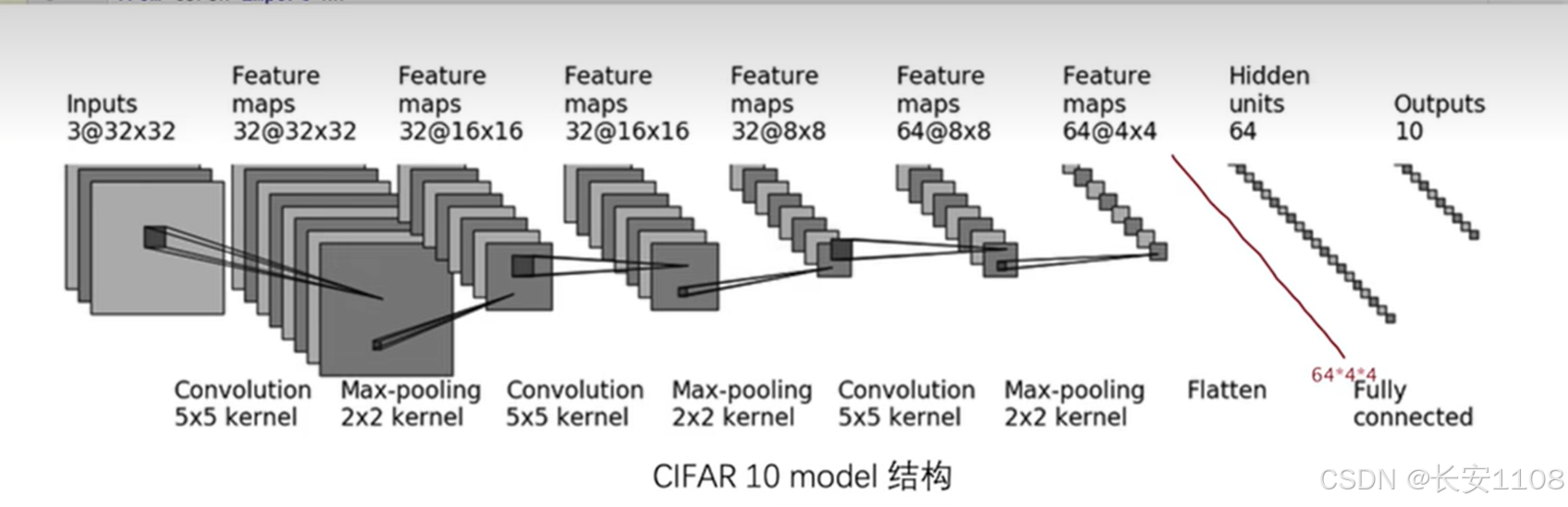
这里我们使用Sequential进行模型的搭建,而搭建的就是CIFARF10的模型
有了模型之后,我们可以在该独立文件中,对模型进行验证: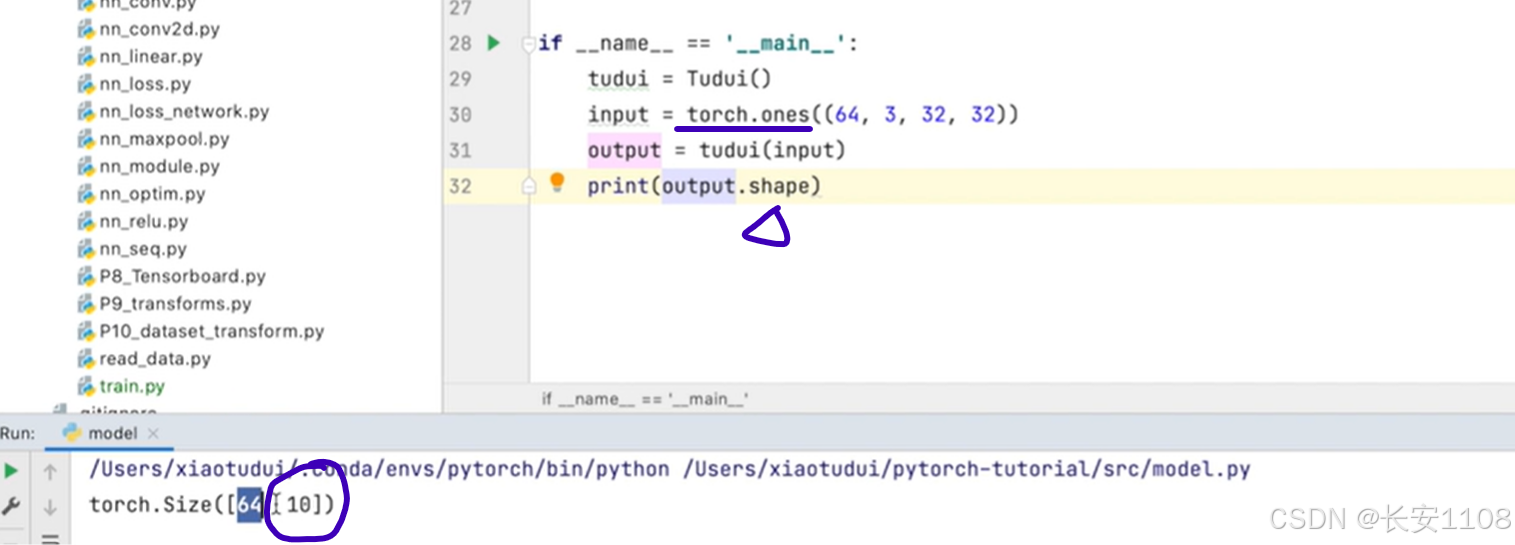
敲入“main”,会提示上图28行的代码,tab自动填补即可
在main函数中,首先创建模型对象
之后,使用torch.ones方法,传入demo数据的shape,我们传入一次抓取64张,信道类型是3,尺寸是32 * 32
输出经过模型处理过后的输出,打印其shape,可以看到最后的shape是[64, 10],64表示抓取数,一般是不变的,10表示最后的尺寸,发现符合我们的预期,验证完成(main函数可以保留至此,无需注释)
之后引入模型所在的文件:
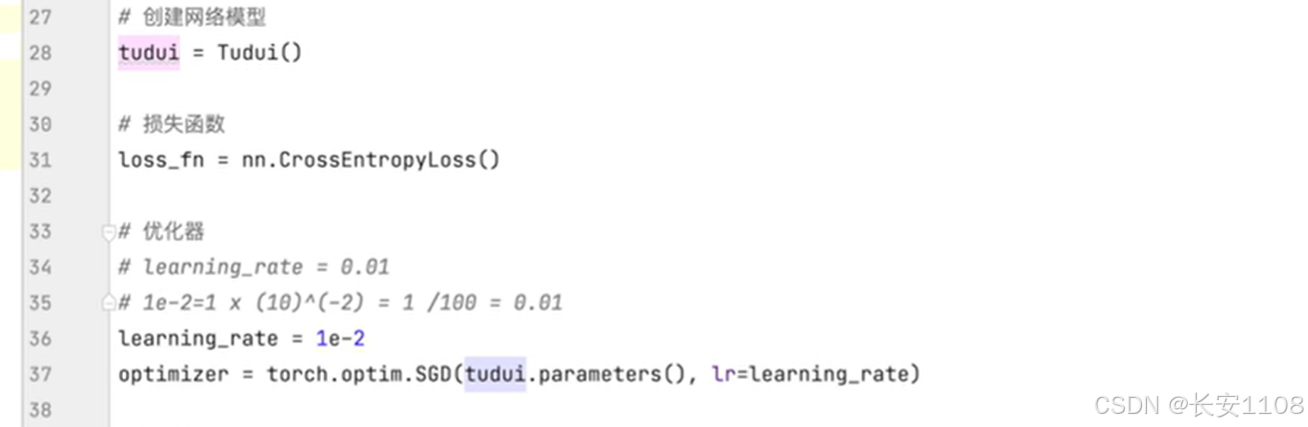
创建模型对象
之后,创建损失函数,不同的模型,或者说不同的模型的功能(比如分类、分割、检测)要选用不同的合适的损失函数
之后,创建优化器,这里选择随机梯度下降,并设置学习速率是1e-2,也就是0.01
之后就可以进行模型的训练了(调参):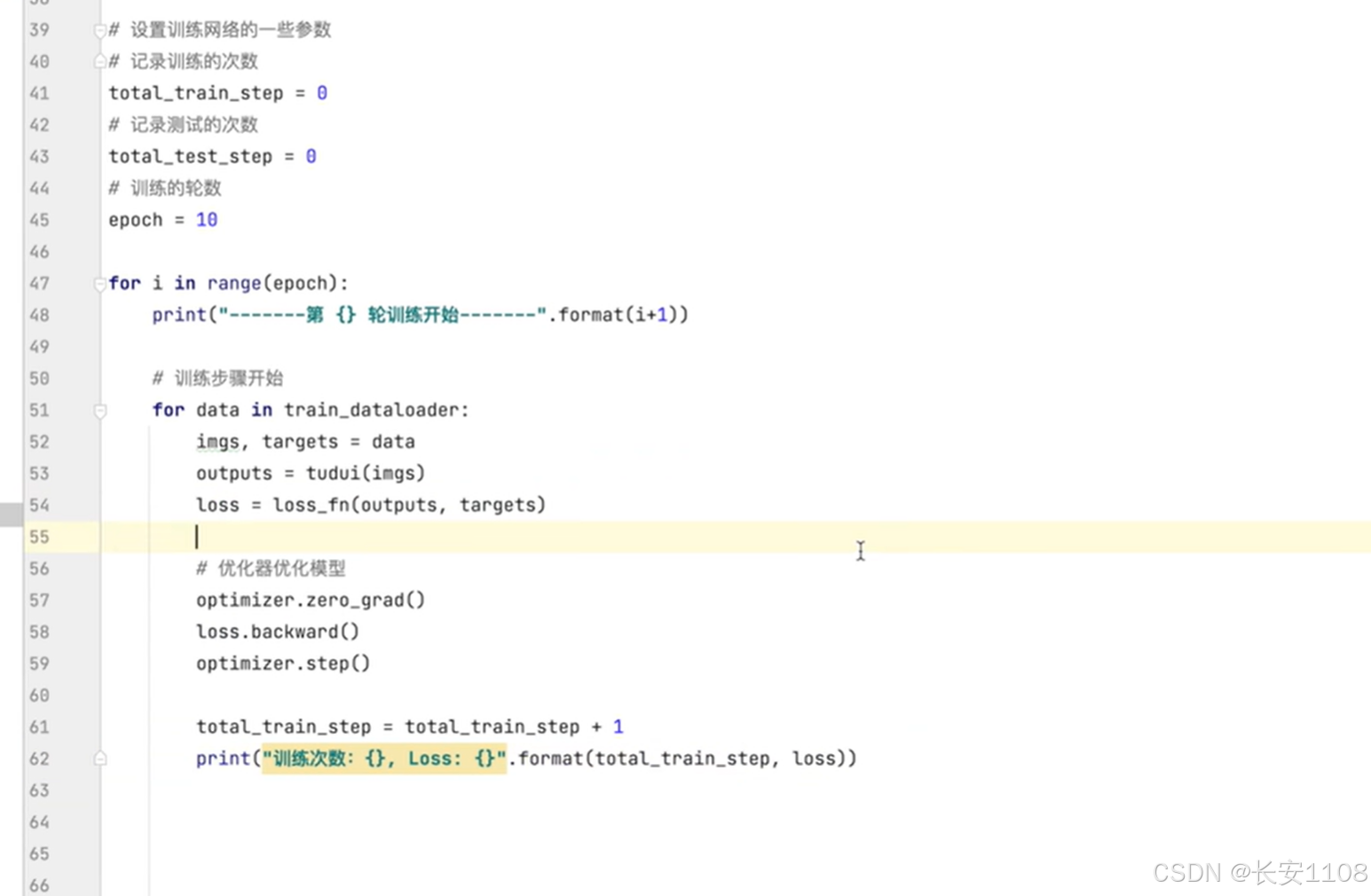
首先,设置轮数为10轮,也就是整个数据集会循环训练十遍
之后,每轮训练中,对数据集进行遍历,取出每次抓取的数据
拿到这些数据的imgs、targets
之后将imgs放入模型进行训练
之后通过损失函数,计算训练得到的输出与真实的target之间的差距:loss
.之后,要使用优化器进行优化:
在优化之前,先对梯度进行清零,然后使用loss的backward()函数推送梯度
之后使用优化器的step,利用梯度进行参数优化
这样,就完成了一次训练,我们可以使用计数器记录并打印
其中核心流程:
1、xxxloss函数计算出本组训练集的成本loss,因为loss默认是tensor类型,loss不仅包含损失值,还包含成本函数结构(这里以及之前的"传入模型"都是前向传播)
2、对grad属性进行清零,为第三步做准备
3、loss.backward(),会对成本函数进行对各个参数的求偏导,偏导数也称为梯度,并存储到各个参数的grad属性中(反向传播)
4、optimizer.step(),执行梯度下降,w = w - α * 梯度,更新参数
测试、可视化
测试: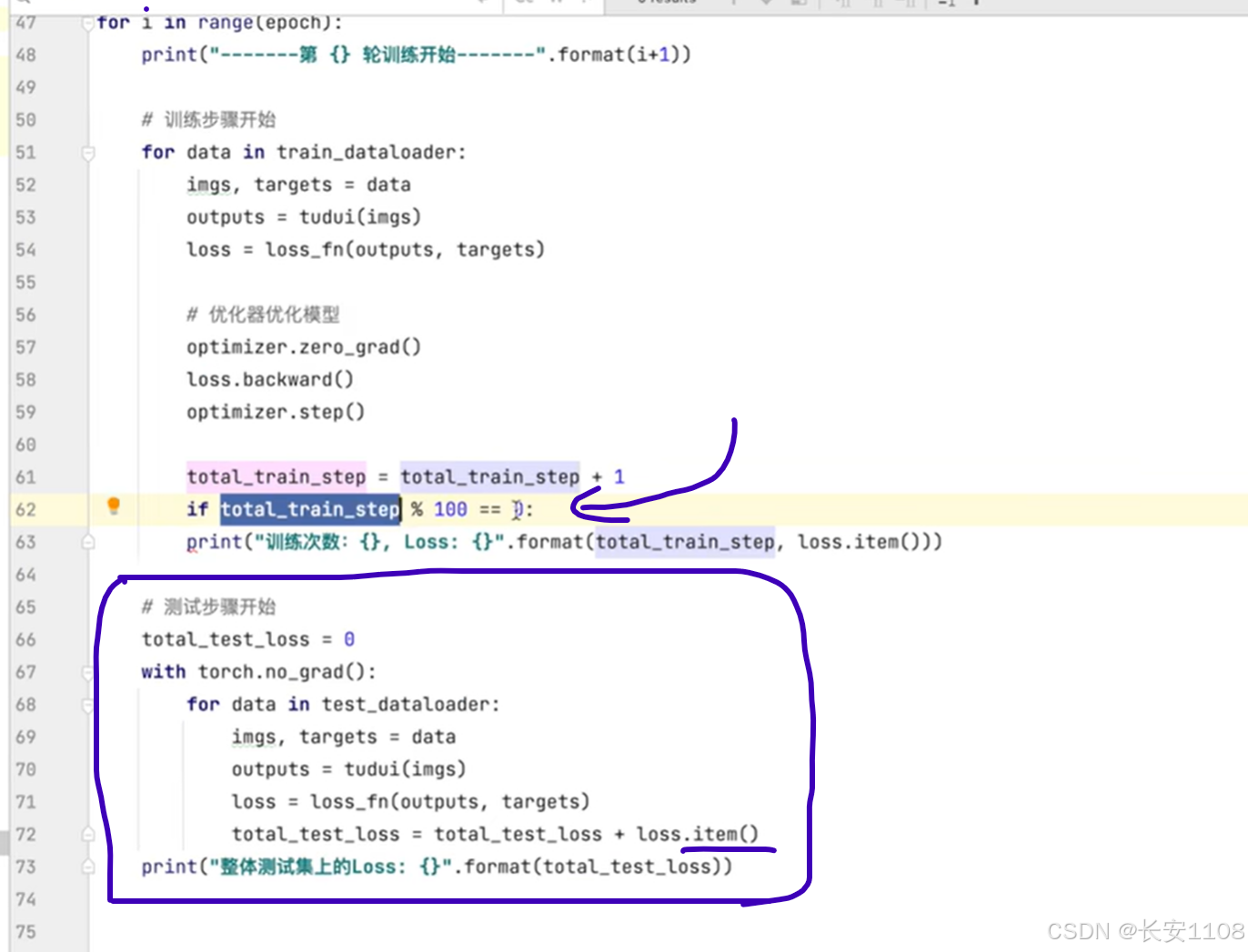
我们可以在一轮训练完的最后,使用测试集去进行测试,即,将测试集载入模型,看一看损失函数的总和是多少
可以看到,先进行一个with语句,该语句的作用是不进行梯度的设置,如果没有梯度,那么就不会进行调参的动作,也就不会改变当前轮训练完之后的模型,
就可以观察每轮过后,使用当前的模型处理的数据的损失函数的总和是不是在减少
而之所以在求loss的和时,使用loss.item(),是因为loss默认是tensor类型,使用.item()之后,就会变成纯数字,方便进行求和
同时,可以设置训练模式时,训练每100次,才进行一次损失函数损失值的打印,防止测试集的输出淹没在训练时的损失函数输出中
效果:
可视化:
我们可以使用Tensorboard将数据进行可视化,我们这里将训练时每次训练的损失函数的结果,以及测试时,每次得到的损失函数的总和,进行可视化: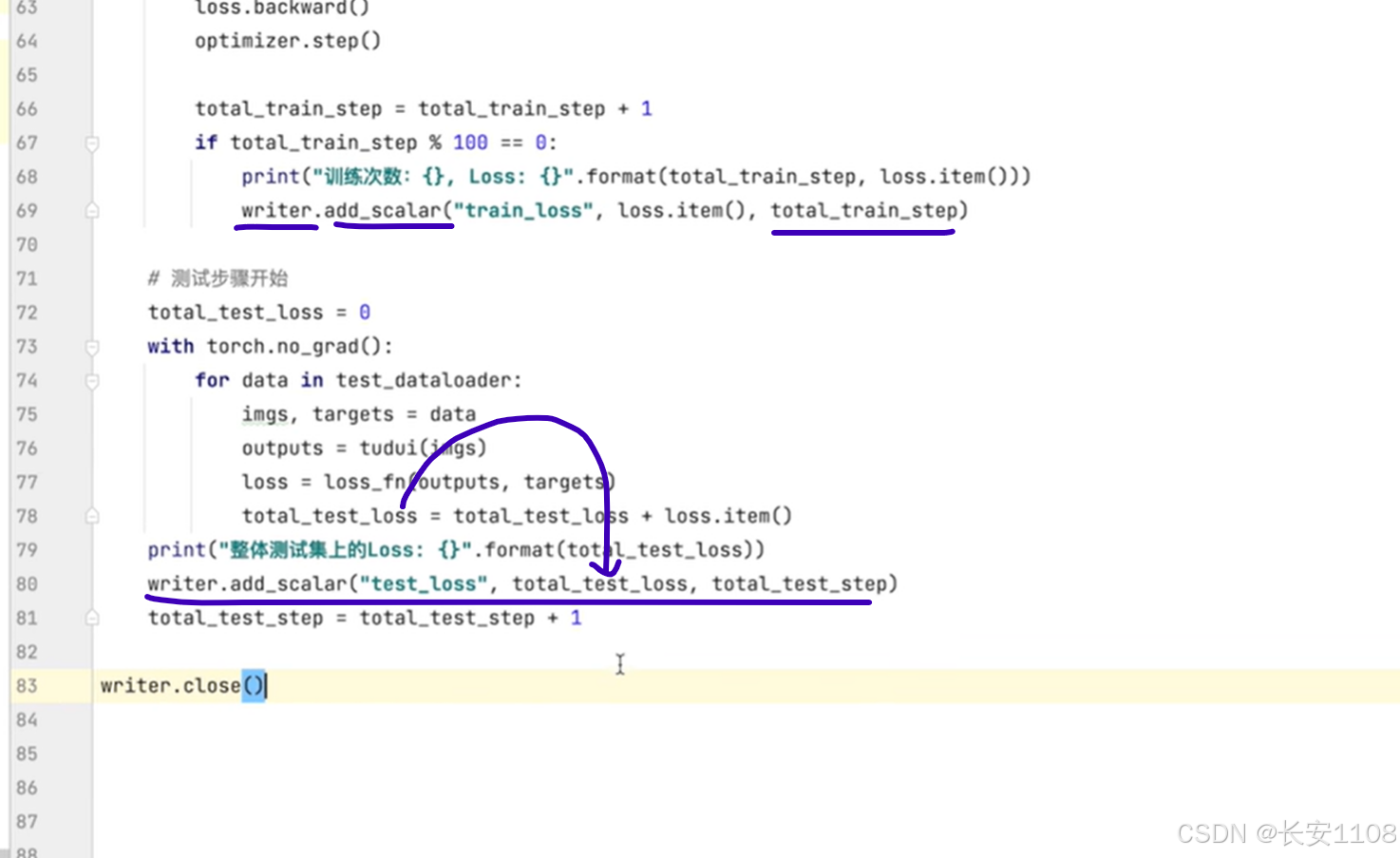
在使用writer之前,要用SummaryWriter创建对象:writer,且传参设置日志文件的输出位置
注意,对于第一个add_scalar,他的参数三,表示步数,不一定从1开始1、2、3…,这里就是从100、200、300…
(参数一是图表的标题,其输出位置是SummaryWriter设置的)
参数二就是纵坐标,参数三就是横坐标,可以灵活设置
再终端进行日志文件的激活:
效果: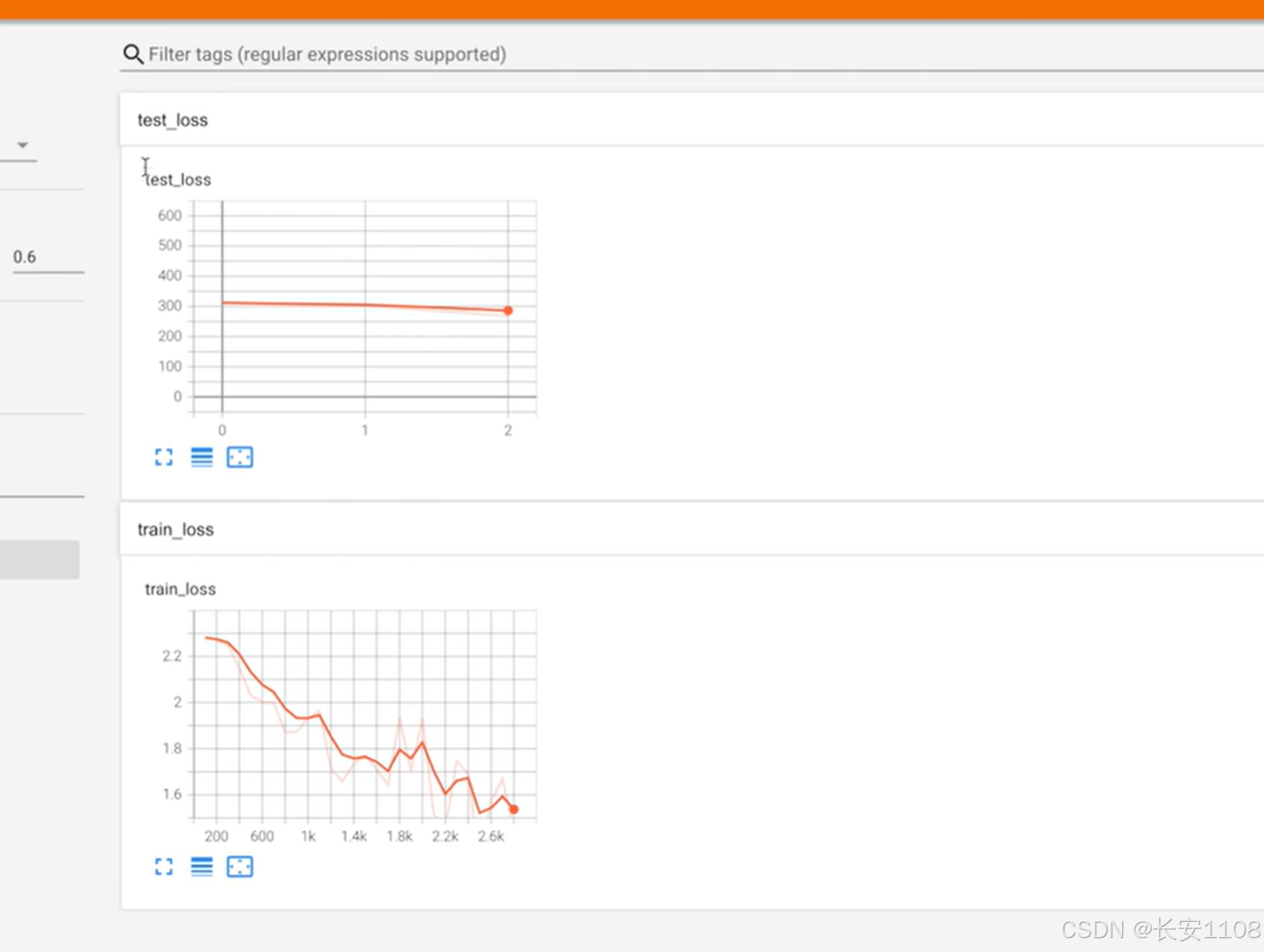
模型保存: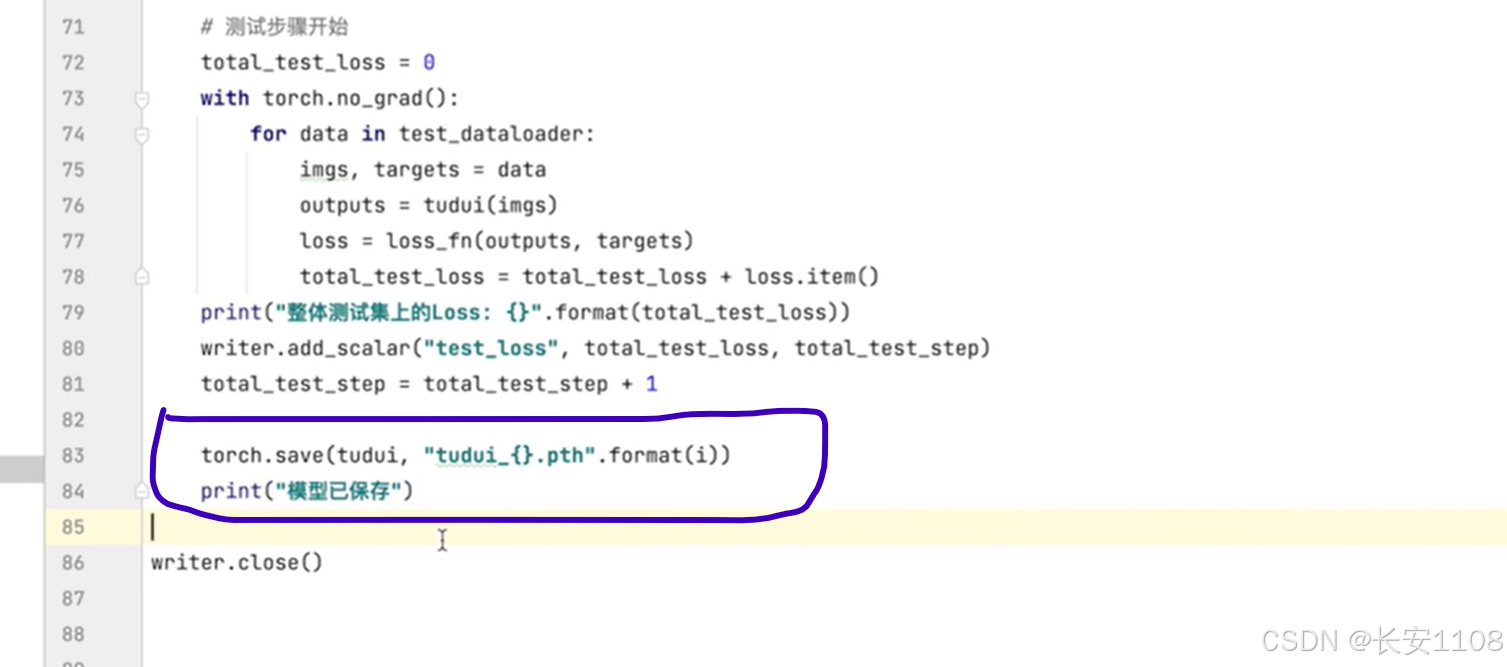
在一轮训练过后,可以使用save,对当前的模型进行一个保存,同时可以使用format区分是第几轮的模型
测试的优化
对于分类
补充:argmax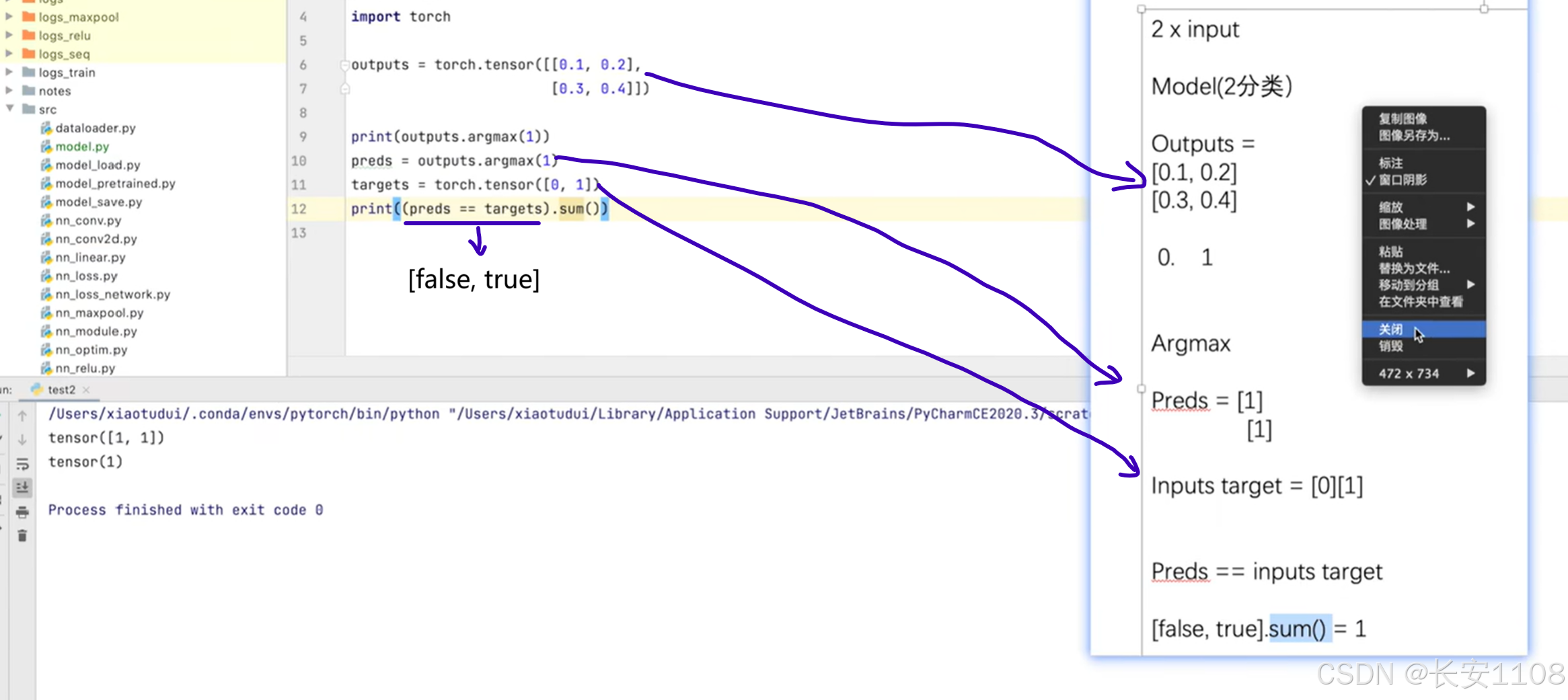
对于分类问题,我们最终模型处理出来的结果是多个n元组,n是分类的类别个数,比如,2分类问题,就是有多个2元组,其中[0.1, 0.2]是一个二元组,[0.3, 0.4]是一个二元组
当前处理的imgs包中的图片个数(或者说单次抓包数),就是二元组的个数,因为一张图片就会得到一个n元组,代表每个类别的概率
而target是一个正确类别的下标,所以,我们要使用argmax,他可以获取每个二元组中最大数的下标,将这64(batchsize)个下标组成一个新的多元组
(传入1是横向比较,传入0是纵向比较)
之后,我们拿到真实的target(也是64个下标组成的多元组)
然后直接将两个多元组进行"=="比较,对应位置相等的会返回True,不相等的返回Flase,之后将其加上括号,再使用sum,就会返回True的个数,就可以反应我们这个模型的正确率了

首先在测试开始前,创建一个记录分类正确的图片的个数的变量
之后修改测试代码: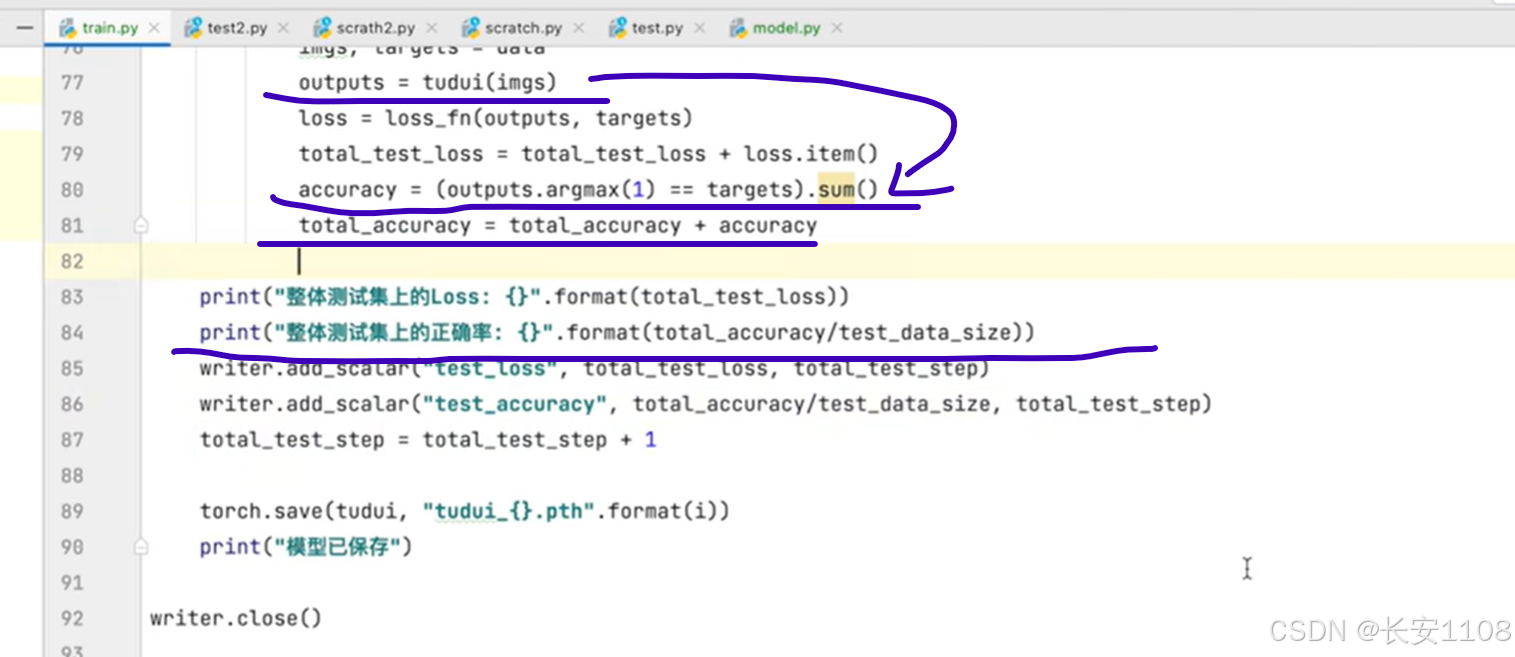
每次放入一个包之后,会得到预测的输出,然后就可以拿到每次整个包64张图片的正确数,然后将其加到total_accuracy中,最后for循环结束后,将其除以图片总数,就是本次该轮模型处理的正确率了
我们可以使用add_scalar,将其可视化,如上图85行
对于分割和目标检测
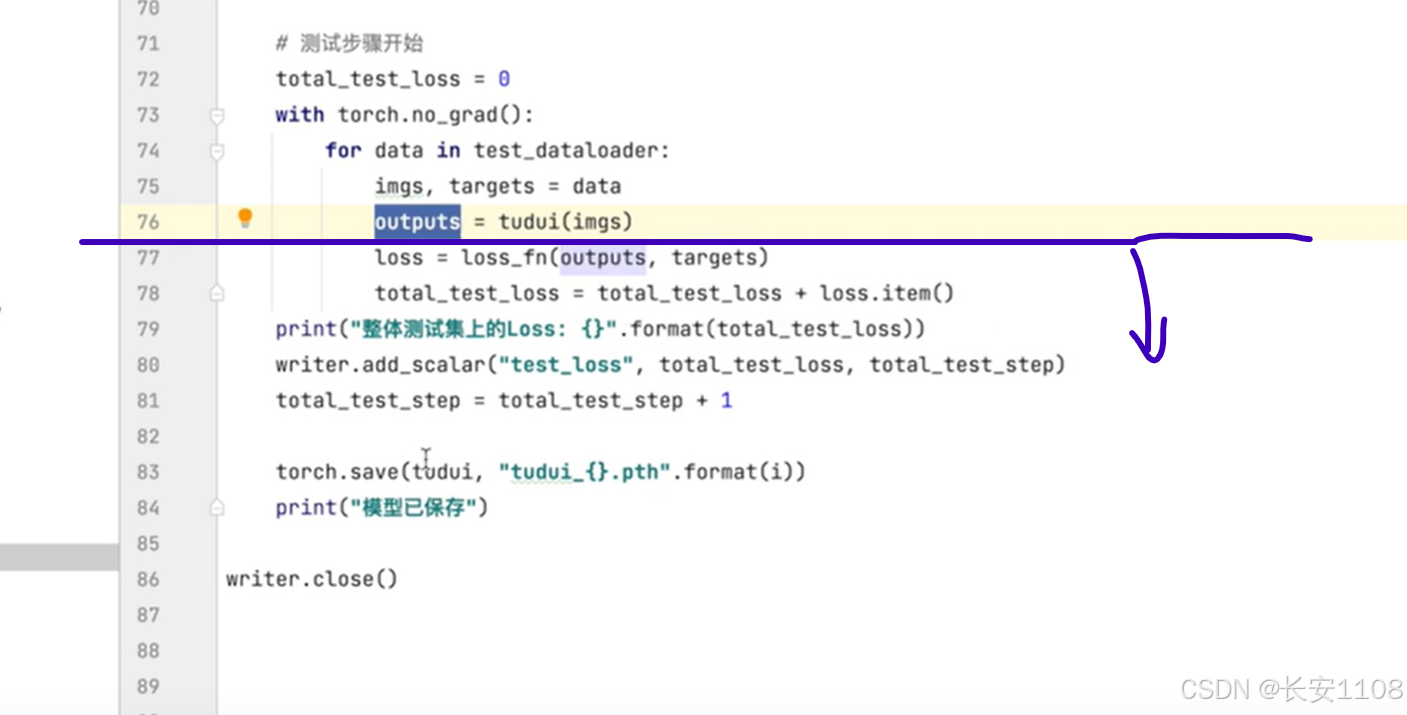
对于语义分割和目标检测,当使用测试集去测试一个模型的时候,我们在76行往下就不用去计算损失,我们可以直接使用UI库去展示出来最终模型选出来的图片,看看对不对
细节
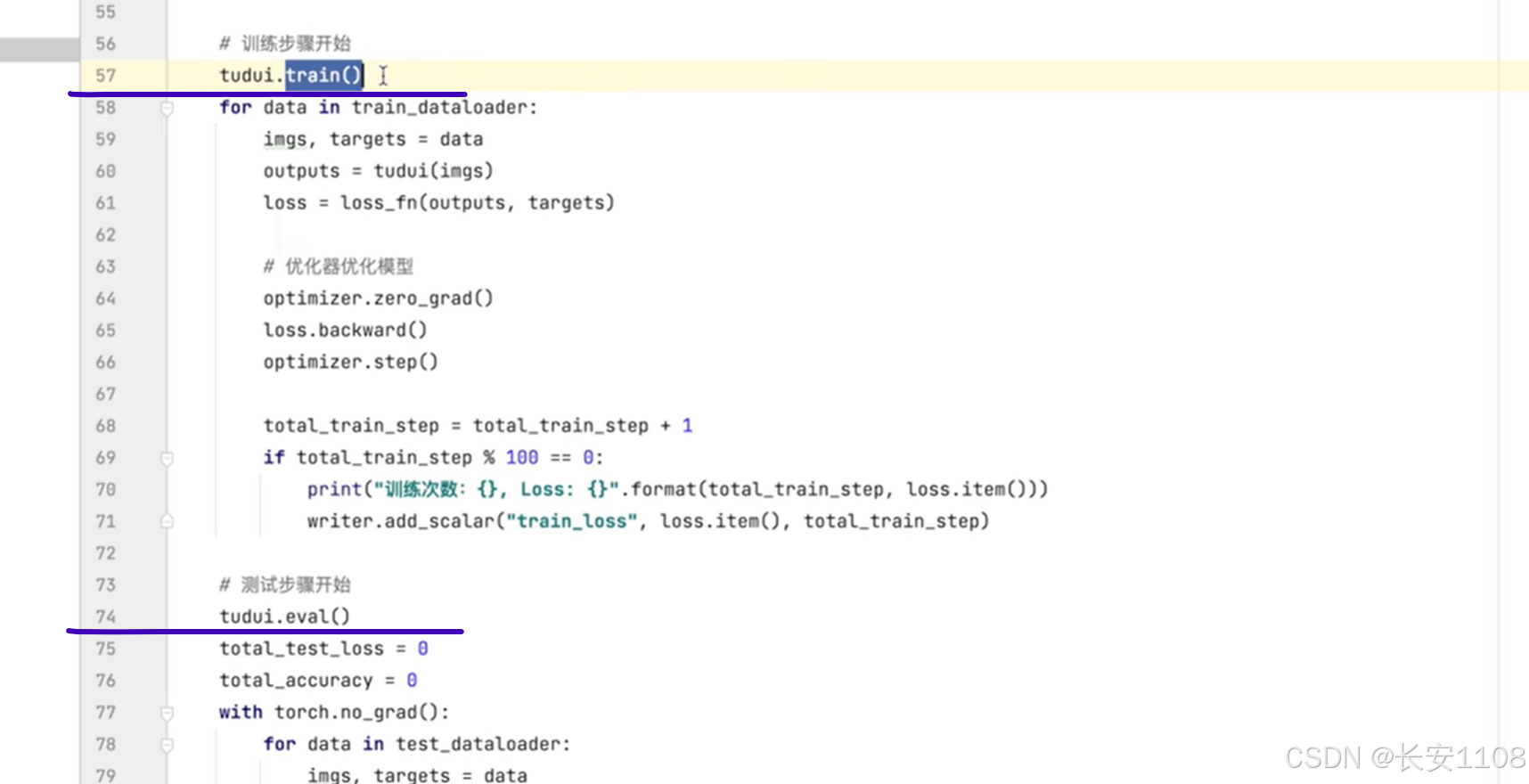
在训练开始前,我们可以使用模型对象去调用train方法,
同时,在测试(验证)开始前,我们可以使用模型对象去调用eval方法
这两个方法不是必须要调用的,而是当网络模型中有特定的层时,才要求去调用:

如上图所示,只有网络中有这些层,才要求去调用train和eval
GPU训练
方式一
我们要对模型、损失函数、以及数据,进行GPU的训练设置:
对模型、损失函数进行设置: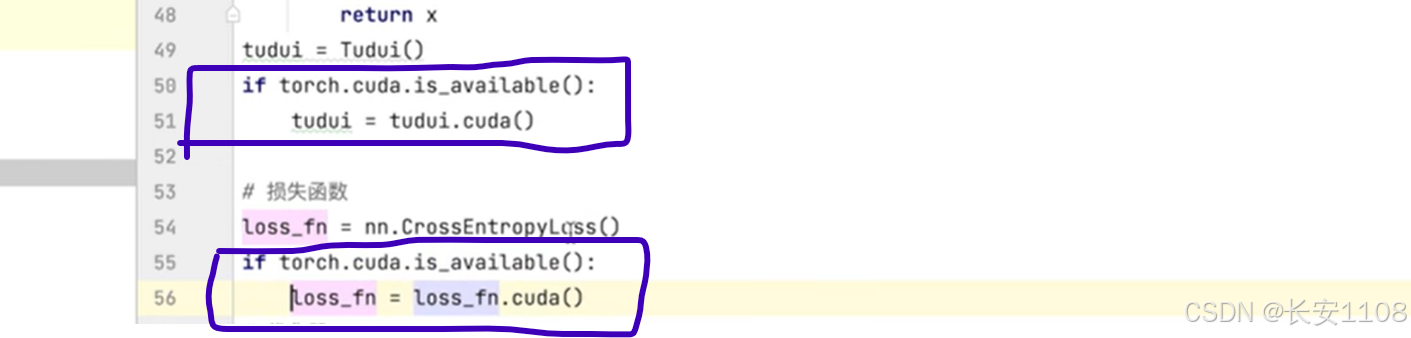
我们在前面的代码的基础上,进行GPU的训练设置
首先,检查如果主机上有GPU的话,用模型对象调用cuda()方法,再返回给模型对象,就完成了GPU的设置
之后,再设置损失函数,如上
对数据进行设置: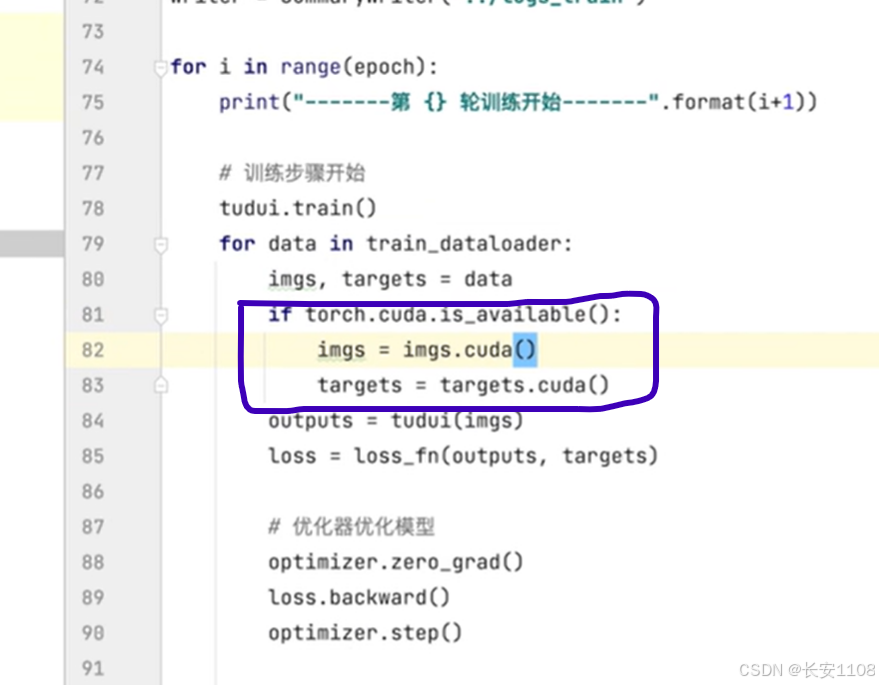
设置训练时每次训练抓取的数据以及标注,都设置为GPU训练,并且返回给自身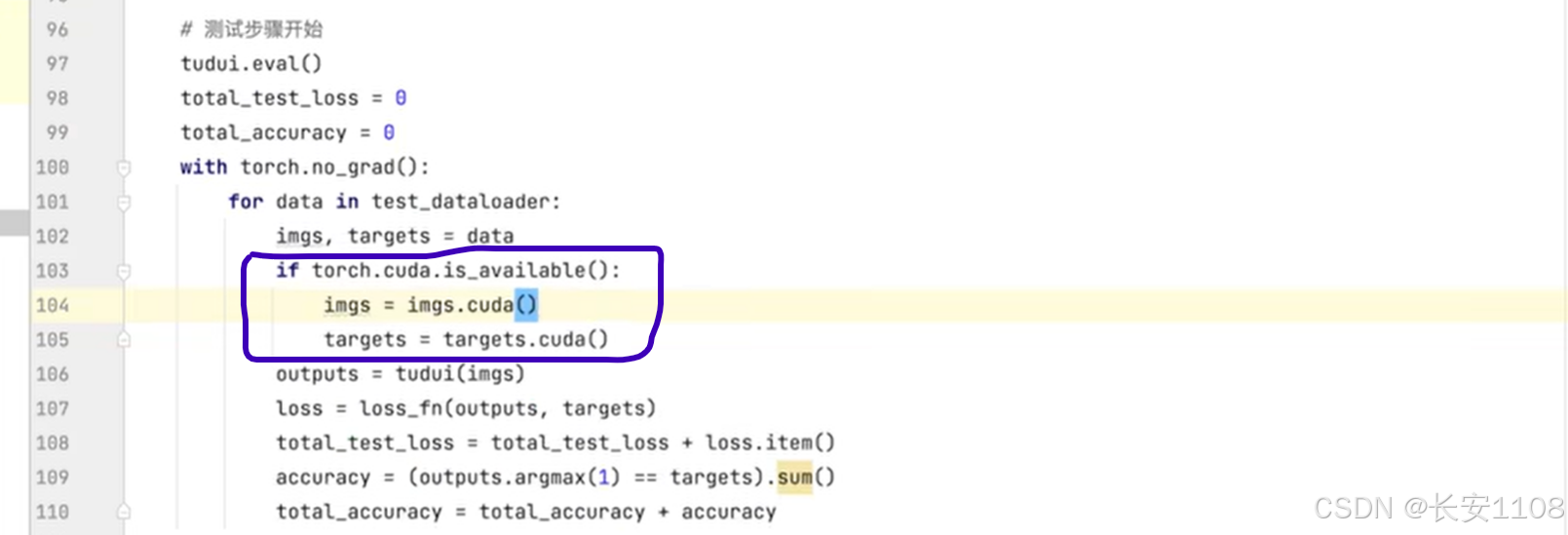
设置测试时每次测试抓取的数据以及标注,都设置为GPU训练,并且返回给自身
这样,就完成了GPU训练的设置,再次启动就是使用GPU进行训练了
效果:
对比训练速度:
不使用GPU: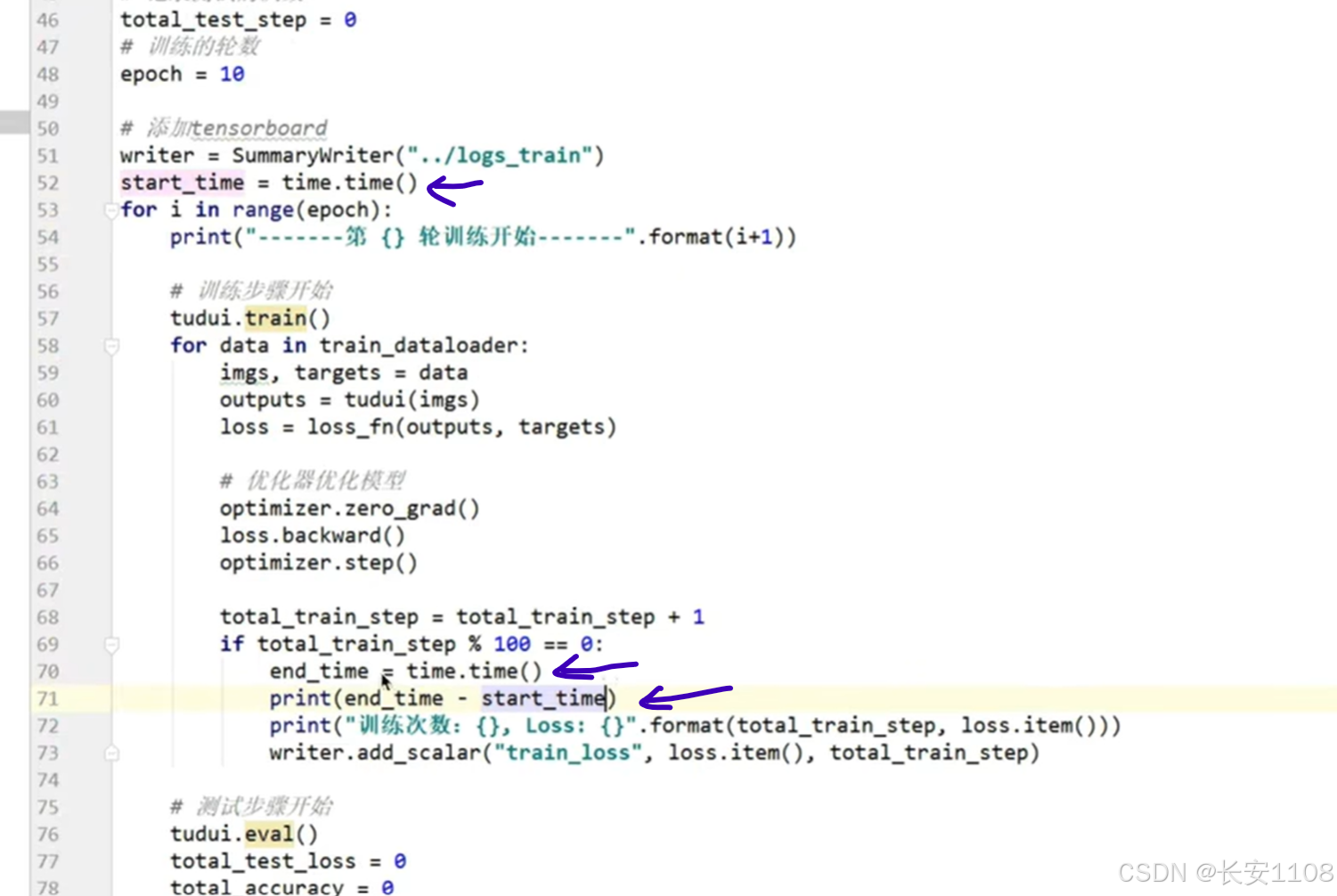
我们先导入time包,然后在开始训练之前,记录一下时间戳,在第一个100次训练完成时,再记录一下时间戳,打印完成100次训练需要的时间
同样的操作,我们在使用了GPU的代码中,打印第一个100次训练完成后所使用的时间
结果:不使用GPU:20s
使用GPU:2s
补充(在线GPU训练)
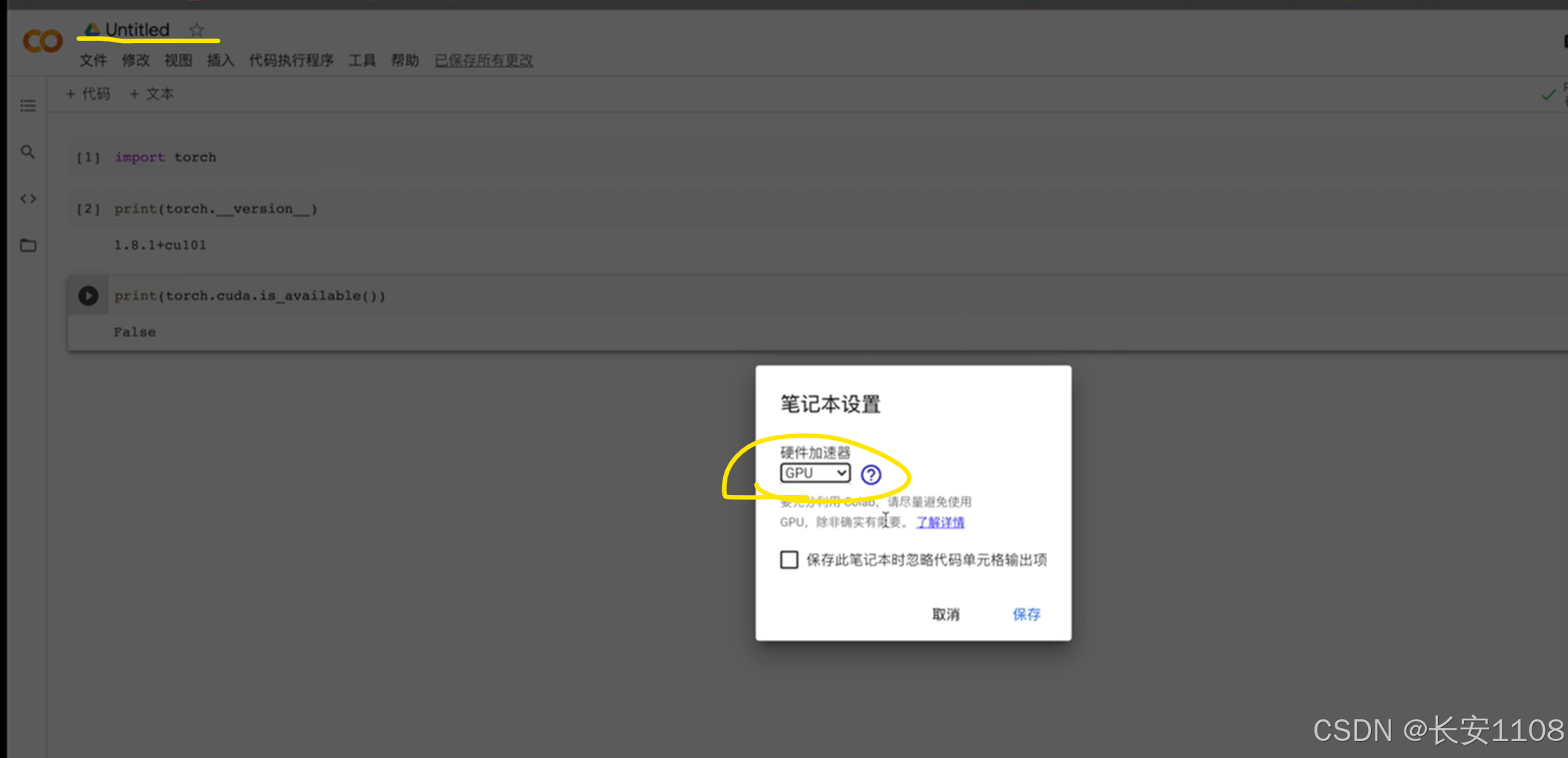
我们可以使用谷歌提供的一个在线版笔记本,实际上就是一个在线编译器,跟jupyter一个性质
我们可以设置其硬件加速为GPU
设置完成后,我们可以看到显示可以使用GPU:
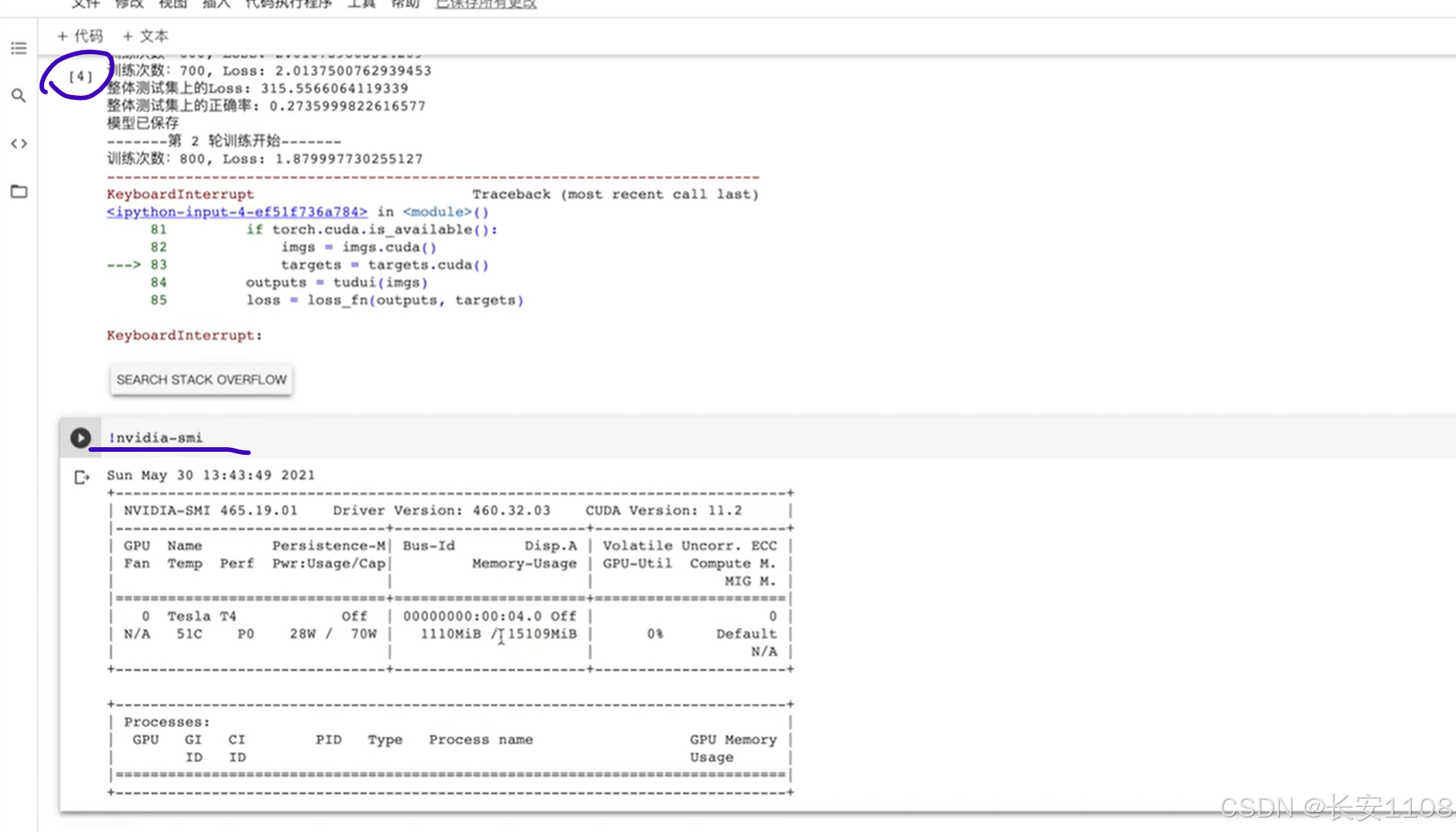
之后,将整个代码拷贝过来直接运行,可以看到已经在使用GPU进行训练了
而如果想查看GPU的型号、功率、显存等:
在在线版可以输入: !nvidia-smi
(前面加感叹号)
在本地终端可以不加感叹号,直接nvidia-smi,即可查看显卡配置
方式二
定义device,去设置GPU训练:
首先,定义device,如果设备有GPU,则是"cuda", 如果没有,则是"cpu"
之后,对模型、损失函数、训练和测试的数据、都进行to(device)方法:
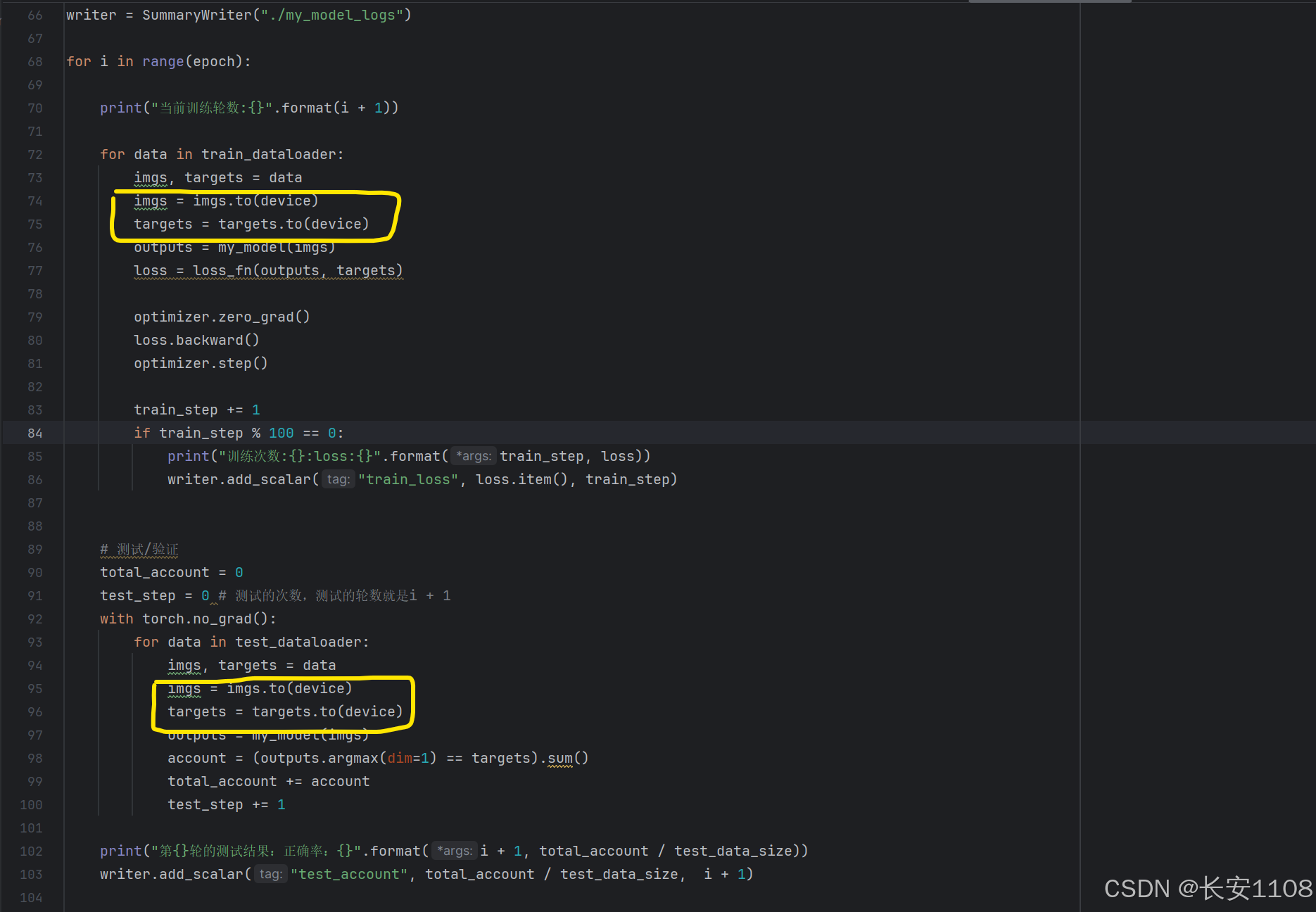
补充:对于device的定义,我们的"cuda",可以是"cuda:0"、“cuda:1”、“cuda:2”…(当只有一张显卡时,“cuda:0"就是"cuda”;有多张显卡时:“cuda:0”、“cuda:1”、"cuda:2"分别表示第一张显卡、第二张显卡、第三张显卡…,也就是可以指定使用哪个显卡)
模型验证/测试/应用
解释
模型的验证/应用,实际上,我们训练模型的目的就是去使用模型,比如,我们训练一个分类模型,那么最终,训练到一定程度之后,我们要使用这个模型去进行图片的分类,比如,输入一张飞机的图片,他可以预测出这是一个飞机
那这个应用的过程,就是模型的应用、模型的验证,或者说,模型的测试
完整的应用/验证套路
1、数据处理: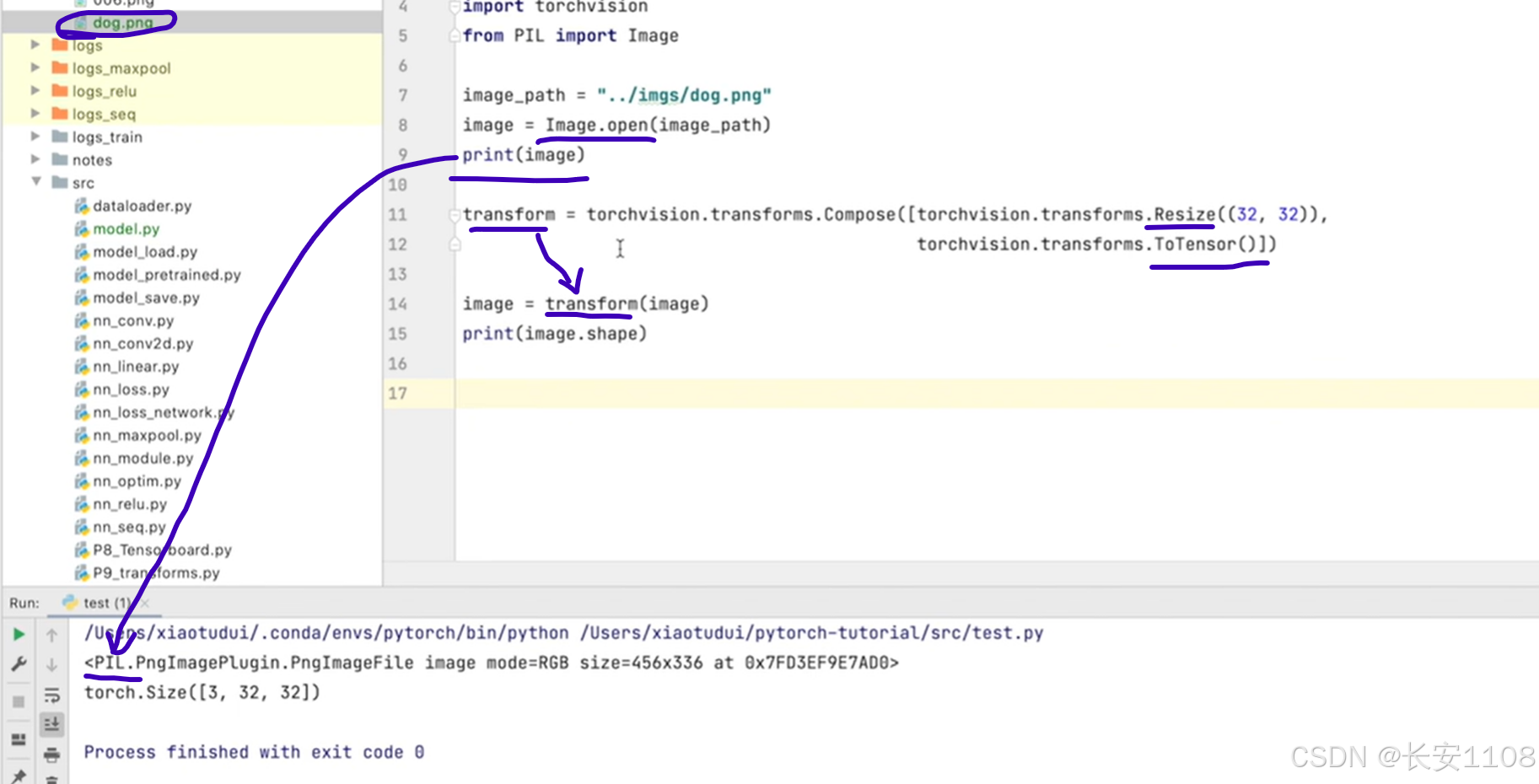
我们随意从网上找一张图片(或者可以使用官方提供的测试数据集)
其初始状态是PIL类型,而想要放入模型中,则需要将其信道类型、尺寸改成模型要求的信道数和输入尺寸、类型转为tensor类型,上述11行代码可以实现,这里注意:
之后,我们可以打印一下处理完之后的图片的shape
但是注意,这里的图片缺少抓包数,我们要使用reshape,将其抓包数改为1(因为我们目前只输入一张图片),如下:
2、加载模型: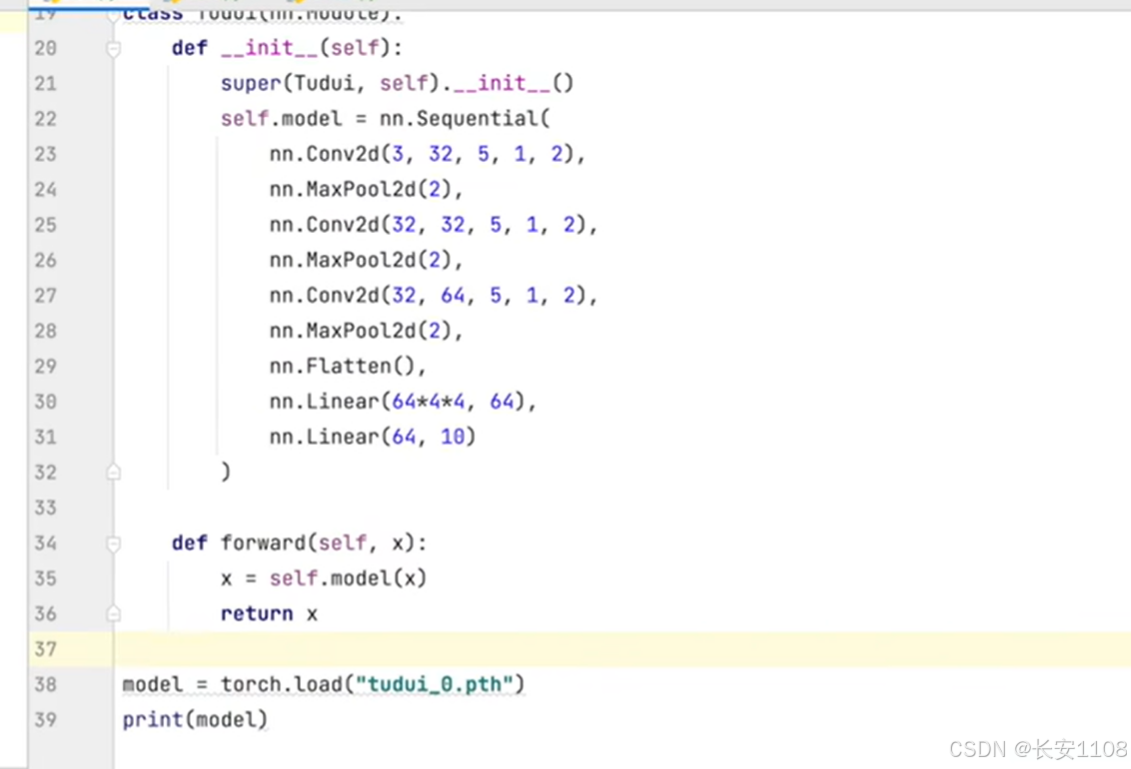
因为我们的模型文件是使用方式一进行保存的,所以,我们使用对应的加载方式进行加载
3、模型应用: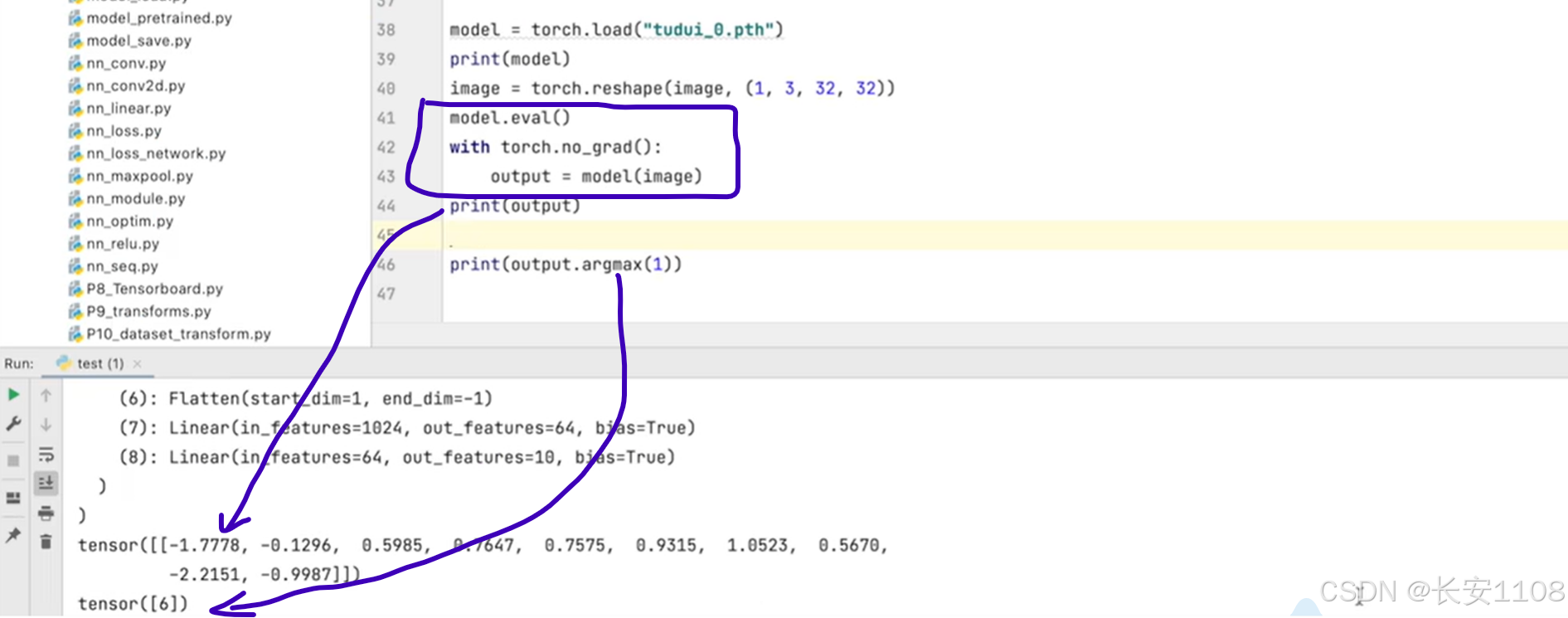
在应用模型前,我们可以加上
mode.eval() --------可以确保有特点层在模型中时,避免出现错误
with torch.no_grad(): ---------防止误修改模型权重,且可以减少资源开销
在with内,进行模型的处理
最后打印处理的结果,对于该例子,CIFAR10模型来说,第一个打印会打印十个类别对应的概率,第二个打印使用了argmax,那么会返回最大值的下标,以此来对应是预测出来的是哪个类别
至于下标对应类别的查看: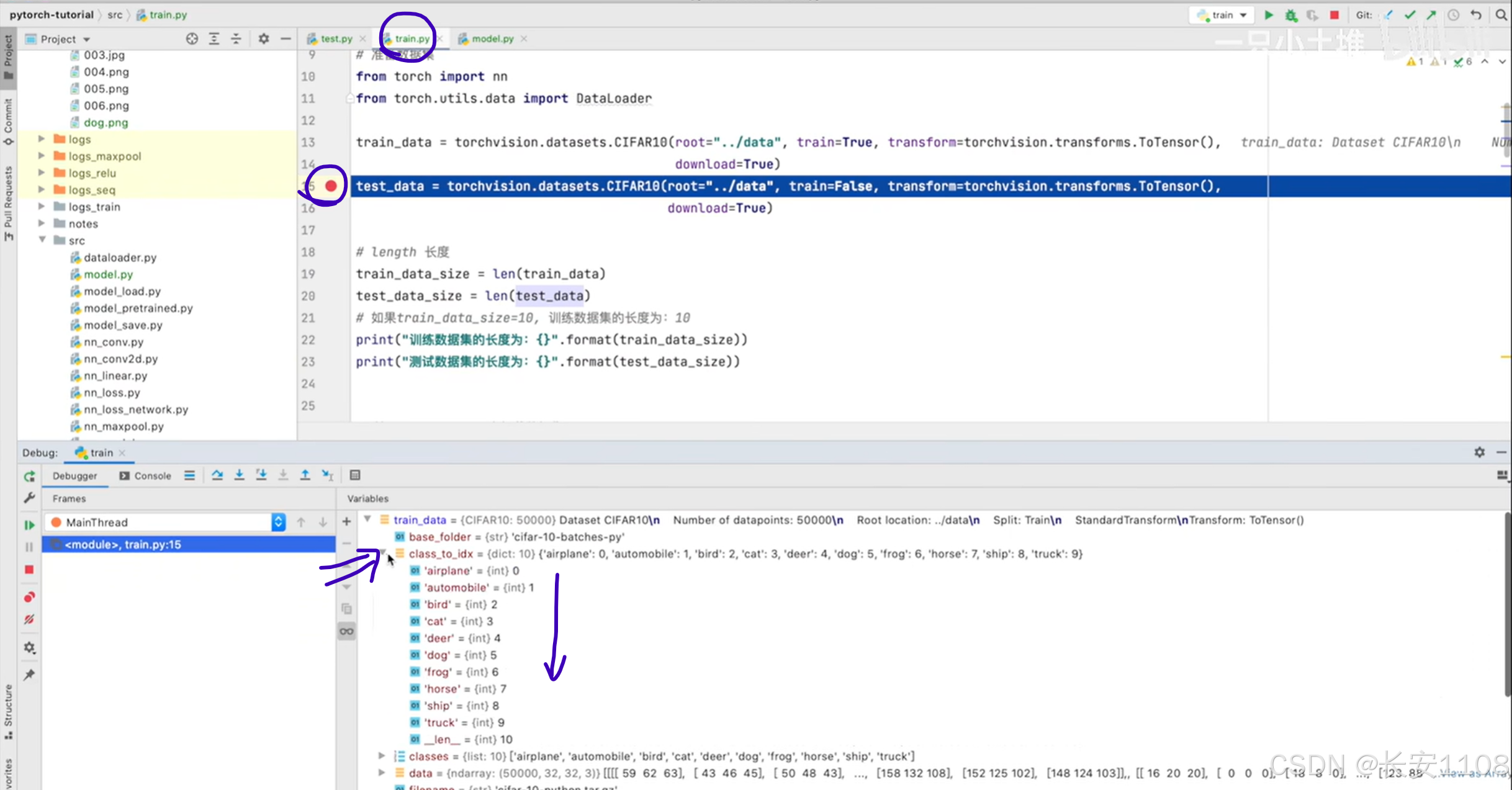
我们在一个训练代码中,任意位置打一个端点,即可查看class_to_idx,就可以看到下标对应的类别
上述代码加载的是cpu训练出来的模型文件,且只训练了一轮,接下来,我们加载使用GPU训练的训练了10轮的模型: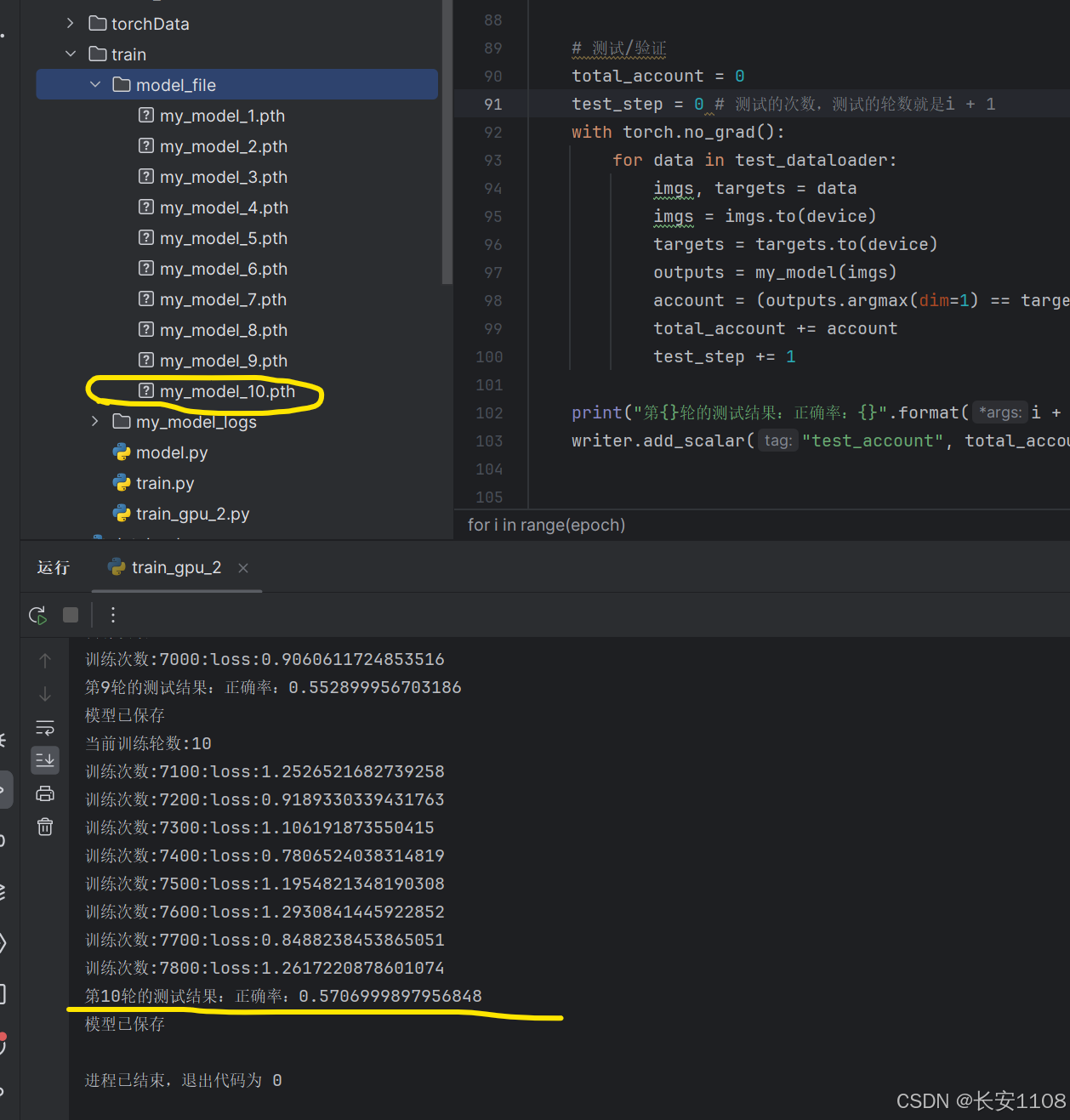
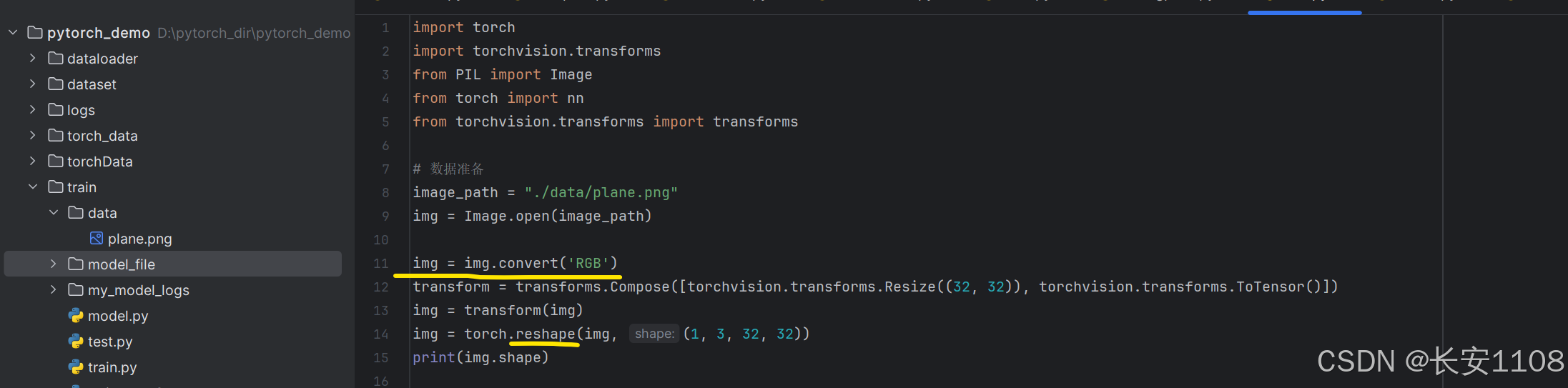
这里要用到设置RGB,因为当前图片文件是四通道,我们将其改为RGB三通道
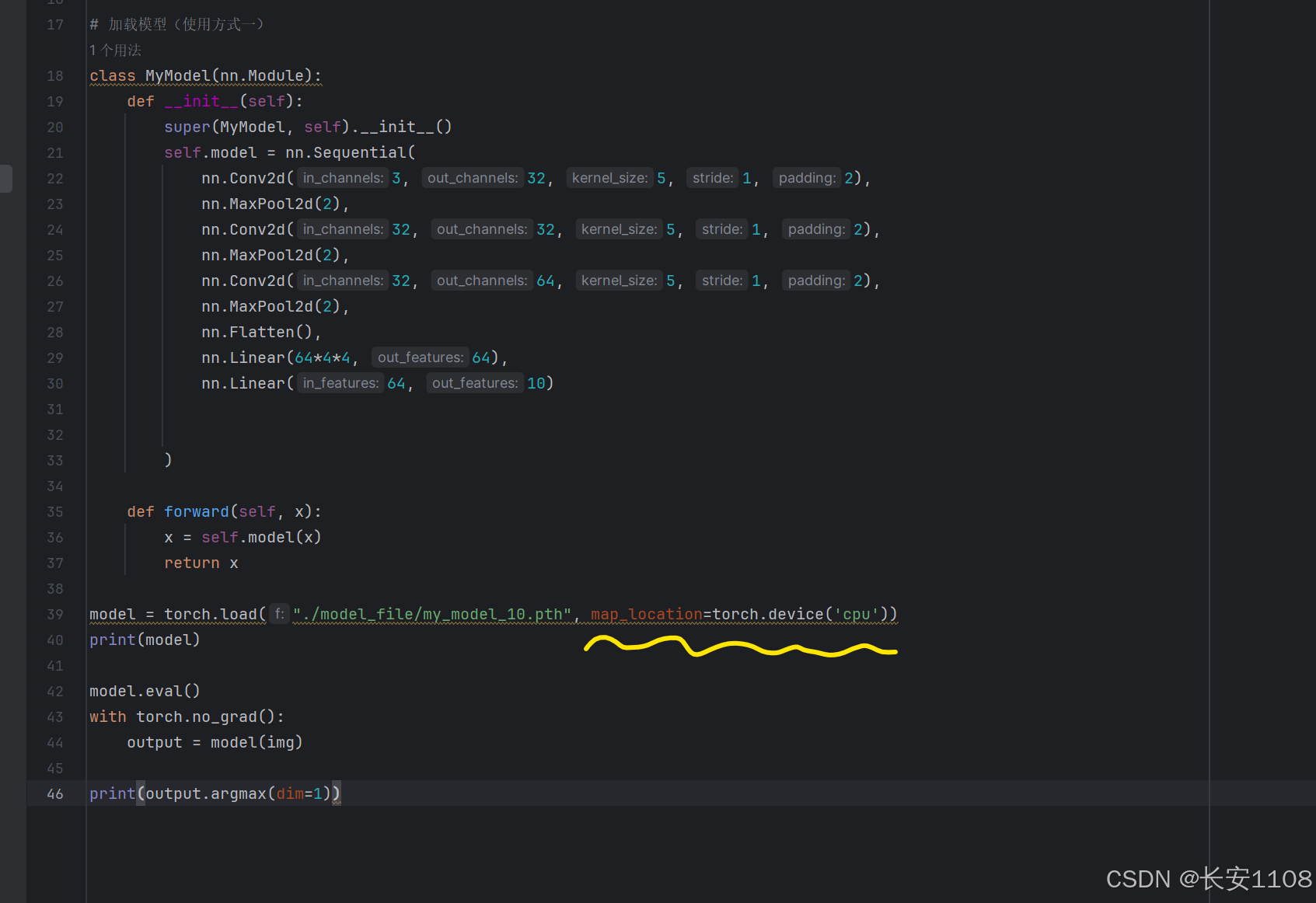
由于使用的是gpu模型,而模型运行时是运行在cpu上,所以,加载模型时,可以将其映射到cpu上进行加载
或者: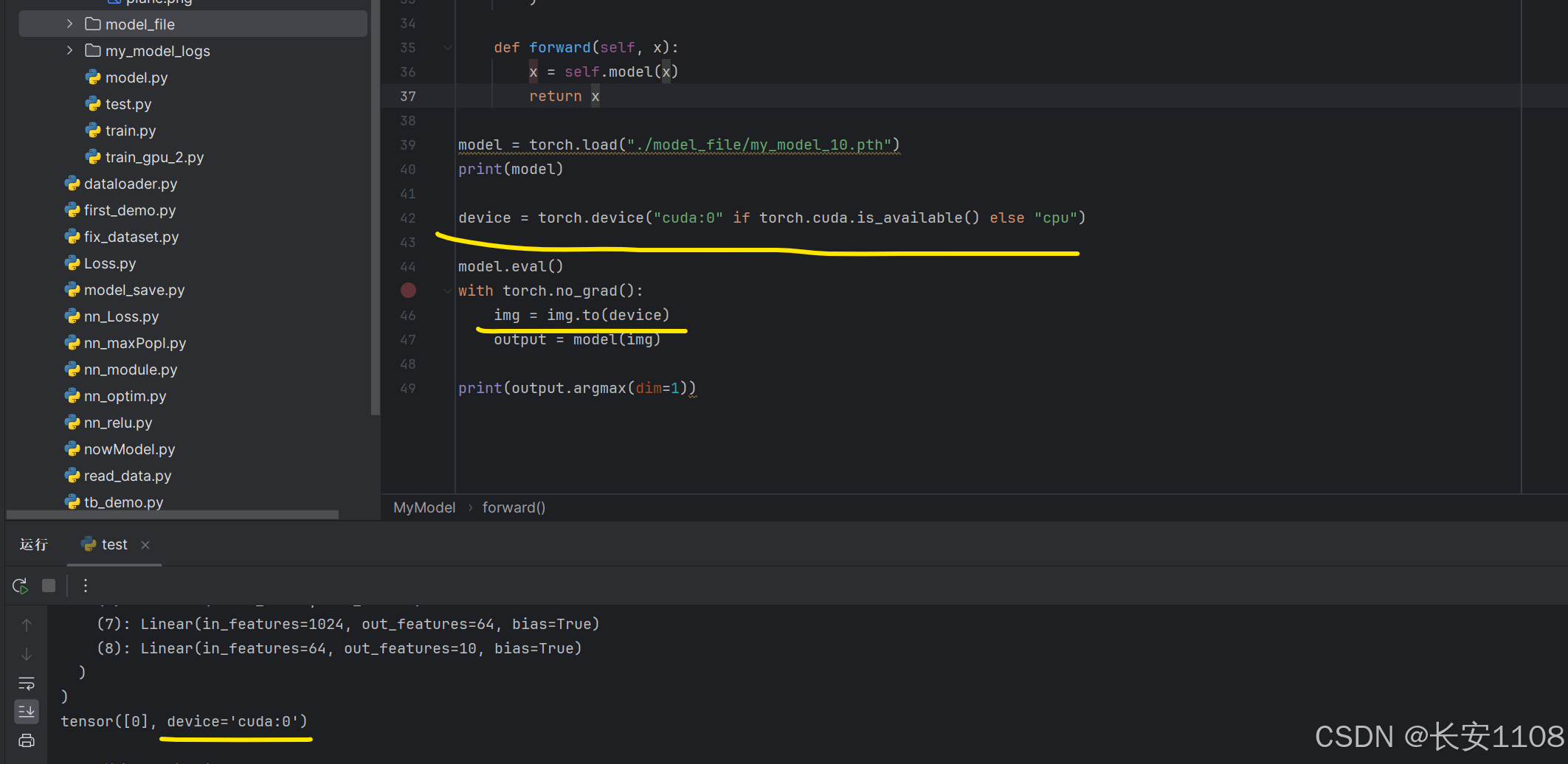
我们将输入的img改成GPU性质,这样无需对加载的模型进行更改,同样可以预测出类别,只不过最后会多一个device

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)