多模态大模型系统综述全解(非常详细),大模型技术进阶从入门到精通,收藏这一篇就够了!
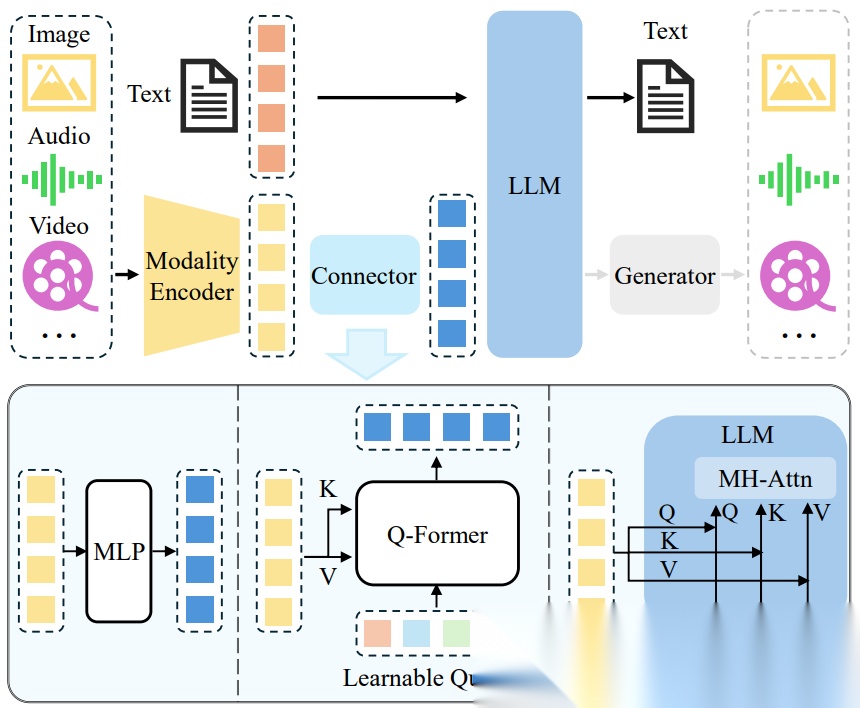
由多模态大模型的范式引出多模态大语言模型,并对多模态大语言模型的模型结构进行了详细的介绍,如下图所示:
本篇将继续介绍多模态大语言模型的训练及其对应的数据工作。大模型的训练范式主要有预训练、指令微调和对齐训练等。不同的训练范式需要使用不同的训练数据,一般需要进行针对性的数据构建。
预训练
预训练(pre-training)是对不同模态数据的对齐,并从大量的训练数据中学习到世界知识。训练数据主要是模态数据及其描述数据caption对,caption是图像/语音/视频等其他模态数据的自然语言描述。
多模态大模型中包含多个预训练模块,如LLM、文本编码器和模态编码器等。一般为了降低预训练难度,在训练多模态大模型时会保持预训练模块参数不变,只训练可学习的模态接口connector;当然也可以将所有模块一起训练。
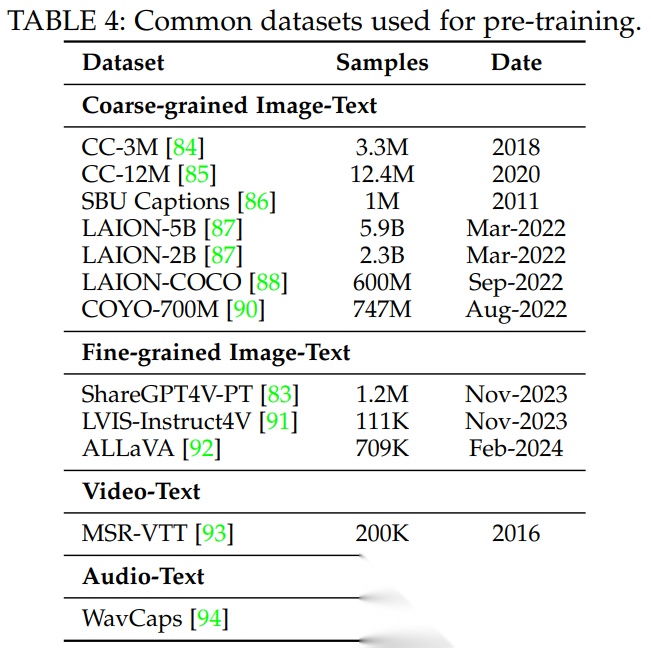
预训练数据根据模态的不同,主要有以下数据集:
指令微调
指令微调(instruction-tuning)是为了让模型更好地理解人类的指令,并且解决人类提出的任务,其中的instruction指的是对任务的描述。指令微调后的模型zero-shot的性能更强,能够根据新的指令解决从未见过的任务。
指令微调数据一般为以下形式:

对于不同的任务,指令微调的输入(上图中的Input)数据类型可能不一样,如在VQA任务中,输入数据为图片-文本对;而在image caption中,输入只是图片。
指令微调数据的采集方式主要有三种,分别是Data Adaptation, Self-Instruction, Data Mixture.
Data Adaptation
数据适应,顾名思义为利用已有的高质量数据集构建适应指令微调任务的数据集,也即构建指令样式(instruction-formatted)的数据集。获取指令的方式有两种,一种是人工编写候选的指令集,训练的时候从中拿一个;还有一种是人工编写少量的种子指令集,然后利用GPT基于这些种子指令集生成更多的指令。
Self-Instruction
该方式有点像few-shot。Self-Instruction需要首先人工标注一些样例,然后利用LLMs生成指令遵循的数据。与Data Adaptation不同的是,Self-Instruction能够生成单轮或多轮的对话数据,更符合现实场景。
举个例子,对于一张图片,标注bbox,并且描述bbox中的图片内容(caption),然后设计prompt利用GPT-4根据这个样例生成新数据。同样,也可以设计QA样例和reasoning样例,利用LLM分别生成QA数据和reasoning数据。

Data Mixture
顾名思义,文本的数据和其他多模态的数据混合使用,文本的数据可以是language-only user-assistant conversation data。训练时,既可以在混合的数据中随机采样成batch(mixed instruction tuning),也可以在文本数据后接上多模态的数据(sequential instruction tuning).
对齐训练
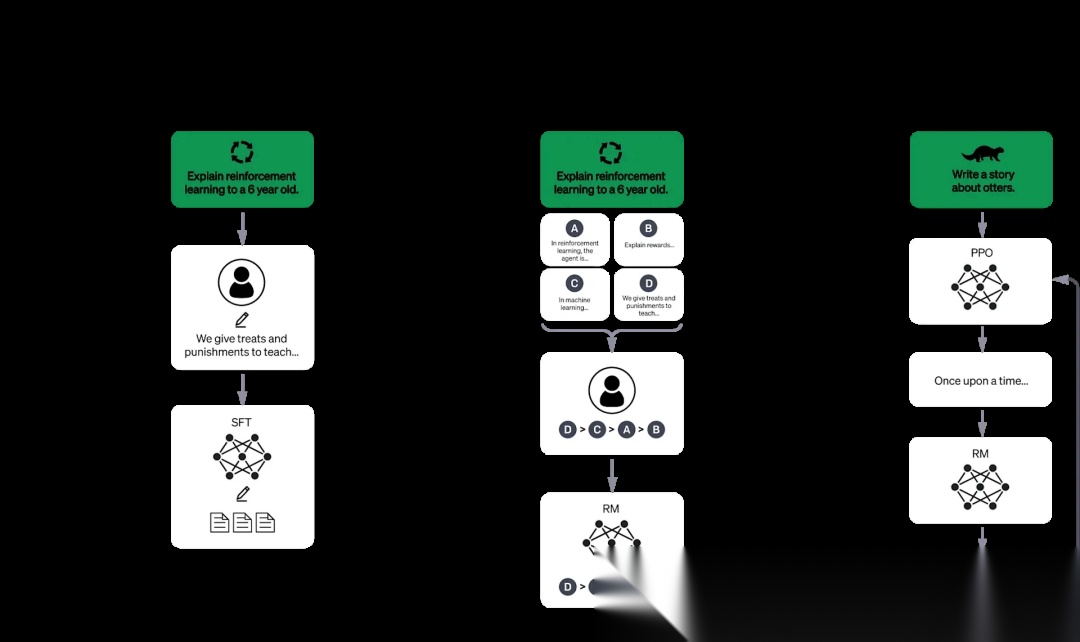
对齐训练主要是为了让模型与人类的偏好进行对齐,主要是进行强化学习训练,如RLHF和DPO。
RLHF
RLHF(基于人类反馈的强化学习)的训练过程通常包含监督微调、奖励模型训练、强化学习优化三个核心步骤。人类对监督微调得到的模型输出结果进行排序,并利用排序结果训练奖励模型,训练好的奖励模型可对任意生成文本给出评分,为后续强化学习提供量化的奖励信号。强化学习优化阶段将监督微调得到的模型作为初始策略网络,奖励模型对策略网络生成的多个候选回答进行打分,然后使用策略梯度PPO算法最大化期望奖励,从而更新模型策略。经过此步骤,得到RLHF优化后的最终模型,其输出质量与人类偏好高度对齐。
DPO
DPO无须训练奖励模型,直接利用人类偏好数据,将其转化为优化目标,通过最大化模型生成偏好输出的概率来调整模型参数。DPO依赖静态离线数据集,适应新反馈的能力受限。
{
"messages": [
{
"role": "system",
"content": "This is a system"
},
{
"role": "user",
"content": "What your name?"
},
{
"role": "assistant",
"content": "My name is xxx."
},
{
"role": "user",
"content": "How to learn Python?"
},
{
"role": "assistant",
"chosen": "It's so easy. First, you need to learn Python syntax...",
"rejected": "Check python doc yourself"
}
]
}
计算输入为的条件下,模型输出和的条件概率(此时的条件概率数值为字符串或生成过程中所有token的条件概率连乘),再代入偏好损失函数计算偏好损失,通过梯度更新优化模型参数,使得模型输出越来越偏向.
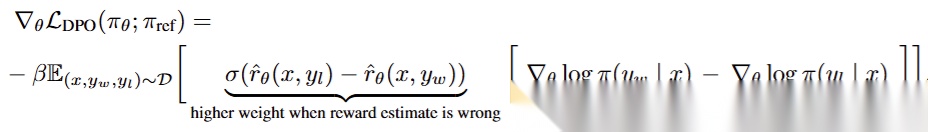
和分别代表人类更倾向(chosen)和不倾向(rejected)的表达。
模型每一次预测,都是根据当前输入的x预测下一个token,它是会预测出字典中所有token的概率,当然也包括yw和yl中当前位置的token,该概率就是该token的条件概率。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)