[数智金融] [3] 关于经济数据分析模块的大致思路
一些思考
TomySwift认为,任何模块的构思过程都应该是有规律的。对于TomySwift来说,主要的构思方式就是:明确现在面临什么样的问题,对于这些问题,应该有什么样的解决方案。每一种方案有什么不确定的地方是有待之后着手探索的,应该用什么样的测试标准筛选这些方案。而在着手探索阶段,TomySwift亦有对应的构思方法,在这就不赘述了。
面临的问题
由于我们整个项目的基础是通用大模型,如deepseek、豆包、Gemini和gpt等,这些模型是由多方面的大量数据训练而成的,虽然泛化能力比较强,但是在单一的任务,比如我们的金融投资策略生成任务中,其对各类金融数据的理解与利用能力明显不足。主要体现于模型受相关机构发表的文章的引导比较严重,提供的建议和相关文章、评论与博客中的建议高度重合,对数据本身的理解不够深入以及忽视每只股票的差异性导致的提出的建议同质化非常严重的问题。
解决方案
TomySwift想用相关数据训练一个或几个数据分析小模型或者微调已有的模型,单独为通用大模型投资策略生成模块提供几个用于参考的量化指标。tomyswift打算先从以下几个方面对小模型进行粗粒度的建模。
1.训练数据:根据实际情况考虑,TomySwift打算利用聚宽平台提供的相关日频数据自己建立训练、验证和测试集(如果效果好且条件允许的话考虑开源)。其中,每一条数据的基本格式如下:
输入特征:
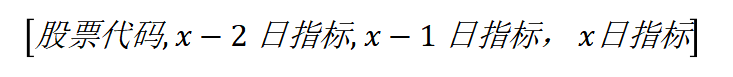
真实标签
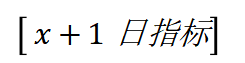
其中,输入特征中的指标既包含每支股票特有的日频指标,也包含其他市场行为数据和宏观经济数据,既有数字数据,也有文本数据,是多模态数据集。而标签只包含每只股票特有的日频指标。这里,具体选哪些指标需要根据实际训练效果得出。
2.模型输出:向训练好的模型输入用户要求生成策略的日期对应的前3日的相关指标,输出还未到来的第4日的相关指标及分数。
3.模型架构选择
这里,TomySwift暂时无法确定哪种模型是最好的,遂决定先提出大致合适的模型,然后通过实验进行选择。
以下是gpt和豆包分别提出的模型建议


、
当然,tomyswift当然不会满足于以上的模型,因为量化领域的好模型都是自己根据实际的数据研究出来的呢,如果一味的参考别人的模型,那岂不是所有人炒股都能赚钱了。
所以,tomyswift决定对以上模型进行架构上的创新,tomyswift一直想将恺明老师的某个思想融入自己的模型进行联合训练呢,这里由于一些原因,等tomyswift做出来之后在告诉你融入的思想是什么呢。
不确定的地方
1.到底哪些指标对策略的生成真正能够起到引导作用,而哪些指标实际上是噪声。
2.是训练一个能够综合所有指标影响的模型,还是对不同的指标训练不同的模型。这两种方法的不同之处在于前者是将综合所有指标影响的任务交给了自己训练的这个模型,而后者自己训练的模型只负责得到各个指标的预测值,综合的任务就交给大模型来处理。(下图就是对不同的指标训练不同的模型,最后向策略生成模块提供的就是各个模型的不同方面的预测分数及结论。)
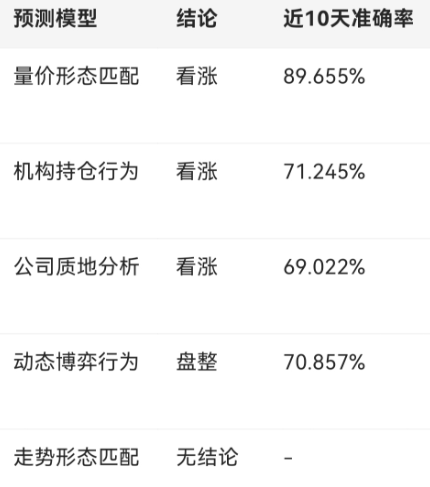
3.模型的输入数据一定是3天的指标吗,多一些或少一些效果会变好吗。模型的输出一定是1天的指标吗,模型能否预测1天以上的指标。
4.最佳的模型架构是什么呢,各个模型的具体优势和缺陷是什么呢。这里需要根据实验验证。周sir曾经说过,只有适合具体任务的模型才是最好的。
测试标准
这里具体的测试标准有2个,第一个就是只测试经济数据分析模型本身,看哪个模型在测试集上表现的更好,自身具有更准确的预测能力。
第二个标准就是和策略生成模块一起测试,看策略生成模块在哪个经济数据分析模型预测的指标的引导下输出的策略效果更好,整体性更强。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)