基于LSTM神经网络实现锂电池SOH估计案例(使用牛津电池老化数据集处理与特征提取)
[电池SOH估算案例3]: 使用长短时记忆神经网络LSTM来实现锂电池SOH估计的算法学习案例(基于matlab编写) 1.使用牛津锂离子电池老化数据集来完成,并提供该数据集的处理代码,该代码可将原始数据集重新制表,处理完的数据非常好用。 2.提取电池的恒流充电时间,等压升充电时间,极化内阻等变量作为健康特征。 3.使用LSTM来建立电池的SOH估计模型,以特征为输入,以SOH为输出。 4.可帮助将该代码修改为门控循环单元GRU建模
本文基于牛津锂离子电池老化数据集,详细解析使用MATLAB实现LSTM神经网络估算锂电池SOH(State of Health,健康状态)的完整代码功能,涵盖数据集处理、健康特征提取、LSTM模型构建与测试全流程,为电池健康状态估算研究提供清晰的技术参考。
一、数据集与核心目标
1. 数据集来源
本案例采用牛津锂离子电池老化数据集(Oxford Battery Degradation Dataset_1) ,包含8个电池(Cell1-Cell8)的循环充放电数据,每个电池均记录了不同循环次数下的电压、电流、温度、容量等关键参数,是研究电池老化与SOH估算的典型公开数据集。
2. 核心目标
以电池充放电过程中的关键参数为基础,提取健康特征,通过LSTM神经网络建立“健康特征-SOH”映射模型,实现对锂电池SOH的精准估算,最终输出模型预测结果与误差分析,验证算法有效性。
二、数据集处理代码功能(Oxford电池数据集处理文件夹)
该文件夹下包含Cell1alldata.m至Cell8alldata.m(8个电池数据处理脚本)、huitu.m(单电池SOH/容量绘图脚本)、huitu1.m(多电池SOH对比绘图脚本),核心功能是将原始数据集转换为结构化、可直接用于后续分析的MATLAB数据格式(.mat)。
1. 单电池数据处理脚本(以Cell1_all_data.m为例)
脚本整体流程为“加载原始数据→定义数据结构→提取充电/放电数据→保存处理结果”,具体功能拆解如下:
(1)初始化与数据加载
clc; close all; clear all;
load Oxford_Battery_Degradation_Dataset_1; % 加载原始数据集
cycles=struct2cell(Cell1); % 将Cell1的原始循环数据转换为单元格数组,便于遍历- 清除工作区变量与图形窗口,避免干扰;
- 加载原始数据集后,通过
struct2cell函数将电池循环数据从结构体转换为单元格数组,解决原始数据嵌套层级深、不易遍历的问题。
(2)定义数据结构
charge_data = struct('relativeTime',[],'voltage',[],'current',[],'temperature',[],'SOC',[],'SOH',[]);
discharge_data = struct('relativeTime',[],'voltage',[],'current',[],'temperature',[],'SOC',[],'SOH',[]);- 定义
chargedata(充电数据)与dischargedata(放电数据)两个结构体,每个结构体包含7个关键字段: relativeTime:相对时间(单位:s);voltage:电压(单位:V);current:电流(单位:A,充电为正,放电为负);temperature:温度(单位:℃);SOC:荷电状态(State of Charge,0-1之间);SOH:健康状态(基于容量计算,1为全新状态)。
(3)充电数据提取与计算
j = 0; % 循环计数器
for i = 1 : length(cycles)
j = j+1;
% 时间处理:原始数据集时间记录异常,按说明文件改为1s一次采样
charge_data(j).relativeTime = [1:length(cycles{i}.C1ch.v)];
% 电压:提取原始充电电压数据并转置为行向量
charge_data(j).voltage = (cycles{i}.C1ch.v)';
% 电流:1C恒流充电(0.74A),生成与时间长度一致的电流向量
charge_data(j).current = ones(1,length(charge_data(j).relativeTime))*0.74;
% 温度:提取原始充电温度数据并转置
charge_data(j).temperature = (cycles{i}.C1ch.T)';
% SOH:基于放电容量计算,SOH=当前容量/额定容量(额定容量740mAh)
charge_data(j).SOH = -cycles{i}.C1dc.q(end)/740;
% SOC:基于充电电量计算,SOC=当前充电电量/(SOH×额定容量)
soh1=charge_data(j).SOH(1);
charge_data(j).SOC = (cycles{i}.C1ch.q/soh1/740)';
end- 核心解决原始数据的3个关键问题:
1. 时间异常:原始时间字段有误,按“1秒1个采样点”重新生成时间向量;
2. 电流标准化:明确充电过程为1C恒流(0.74A),避免原始数据中电流波动的干扰;
3. SOH/SOC计算:基于“容量衰减”核心逻辑,将原始电量数据转换为标准化的SOH(无量纲)与SOC(0-1范围),便于后续分析。
(4)放电数据提取与计算
放电数据提取逻辑与充电数据一致,仅电流符号(放电为-0.74A)、SOC计算方式(基于放电电量反向推导)略有差异,最终生成与充电数据对应的放电结构体数据。
(5)数据保存
save Cell1_charge_data charge_data; % 保存充电数据为.mat文件
save Cell1_discharge_data discharge_data; % 保存放电数据为.mat文件- 将处理后的结构化数据保存为MATLAB专用的
.mat格式,后续脚本可通过load函数直接调用,无需重复处理原始数据,提升效率。
2. 绘图脚本功能
huitu.m:加载单个电池(如Cell1)的充电数据,提取所有循环的SOH,绘制“循环次数-SOH”曲线与“循环次数-容量(SOH×740mAh)”曲线,直观展示电池老化趋势;huitu1.m:加载Cell1-Cell4的充电数据,提取各电池SOH,绘制多电池SOH对比曲线,便于分析不同电池的老化速率差异。
三、健康特征提取代码功能(Cell1-Cell8特征提取文件夹)
每个电池对应1个特征提取脚本(如Cell1HF1234_select.m),核心功能是从处理后的充放电数据中,提取4个与SOH强相关的健康特征(HF1-HF4),并计算各特征与SOH的Pearson相关系数,验证特征有效性。
1. 数据加载与SOH提取
clc; clear all; close all;
load('Cell1_charge_data.mat'); % 加载处理后的充电数据
load('Cell1_discharge_data.mat'); % 加载处理后的放电数据
% 提取所有循环的SOH(从充电数据中获取,与放电数据SOH一致)
SOH = [];
for i = 1:length(charge_data)
SOH = [SOH charge_data(i).SOH];
end- 从之前保存的
.mat文件中加载数据,避免重复处理; - 提取SOH向量,作为后续特征相关性分析的“参考基准”。
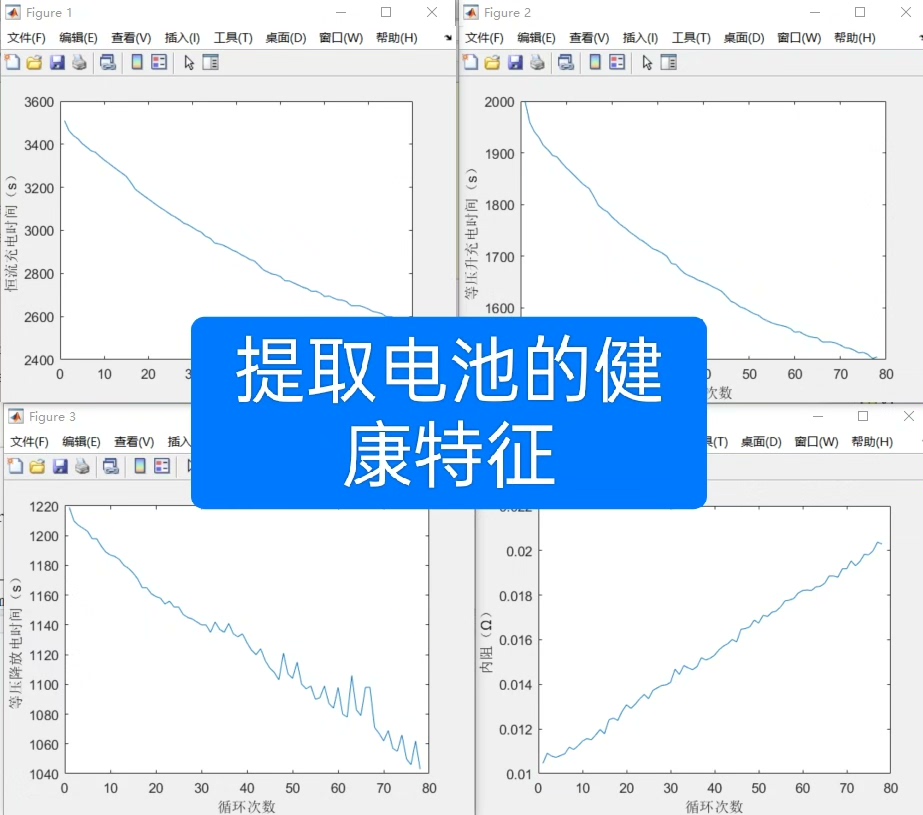
2. 健康特征提取(HF1-HF4)
(1)HF1:恒流充电时间
HF1 = []; % 存储所有循环的恒流充电时间
for i = 1:length(charge_data)
% 恒流充电时间=充电结束相对时间-充电开始相对时间
HF_temp = charge_data(i).relativeTime(end) - charge_data(i).relativeTime(1);
HF1 = [HF1 HF_temp];
end
% 计算HF1与SOH的Pearson相关系数(验证相关性)
P1 = corr(SOH',HF1','type','Pearson');
% 绘制“循环次数-HF1”曲线
figure; plot(HF1); xlabel('循环次数'); ylabel('恒流充电时间(s)');- 物理意义:电池老化后,容量衰减,相同电流下充满电的时间会变化(通常老化越严重,充电时间越短),因此充电时间可反映SOH;
- 相关性验证:通过
corr函数计算Pearson系数(范围-1~1),系数绝对值越接近1,说明特征与SOH相关性越强,后续模型输入有效性越高。
(2)HF2:等压升充电时间(3.8V-4.1V)
start_voltage = 3.8; end_voltage = 4.1; % 设定电压区间
HF2 = [];
for i = 1:length(charge_data)
% 找到电压首次超过3.8V的索引(开始时间点)
index = find(charge_data(i).voltage > start_voltage);
start_index = index(1);
% 找到电压首次超过4.1V的索引(结束时间点)
index = find(charge_data(i).voltage > end_voltage);
end_index = index(1);
% 计算该电压区间的充电时间
HF_temp = charge_data(i).relativeTime(end_index) - charge_data(i).relativeTime(start_index);
HF2 = [HF2 HF_temp];
end
% 相关性计算与绘图(同HF1)
P2 = corr(SOH',HF2','type','Pearson');
figure; plot(HF2); xlabel('循环次数'); ylabel('等压升充电时间(s)');- 物理意义:充电过程中,电压从3.8V升至4.1V的阶段,电池极化特性与老化程度强相关——老化电池极化增强,相同电压区间的充电时间会显著变化,因此该时间可作为敏感健康特征。
(3)HF3:等压降放电时间(4.1V-3.8V)
start_voltage = 4.1; end_voltage = 3.8; % 设定放电电压区间
HF3 = [];
for i = 1:length(discharge_data)
% 找到放电时电压首次低于4.1V的索引
index = find(discharge_data(i).voltage < start_voltage);
start_index = index(1);
% 找到放电时电压首次低于3.8V的索引
index = find(discharge_data(i).voltage < end_voltage);
end_index = index(1);
% 计算该电压区间的放电时间
HF_temp = discharge_data(i).relativeTime(end_index) - discharge_data(i).relativeTime(start_index);
HF3 = [HF3 HF_temp];
end
% 相关性计算与绘图
P3 = corr(SOH',HF3','type','Pearson');
figure; plot(HF3); xlabel('循环次数'); ylabel('等压降放电时间(s)');- 物理意义:放电过程中,电压从4.1V降至3.8V的时间与电池容量直接相关——老化电池容量衰减,相同电压区间的放电时间缩短,是反映SOH的关键特征。
(4)HF4:欧姆内阻
HF4 = [];
for i = 1:length(discharge_data)
% 提取放电初始时刻的前2个电压值(V1:初始电压,V2:第2个采样点电压)
V1 = discharge_data(i).voltage(1);
V2 = discharge_data(i).voltage(2);
% 提取放电电流(取负转为正值,单位A)
I = -discharge_data(i).current(2);
% 欧姆内阻=电压突降量/电流(欧姆定律:R=ΔV/I)
HF_temp = (V1-V2)/I;
HF4 = [HF4 HF_temp];
end
% 相关性计算与绘图
P4 = corr(SOH',HF4','type','Pearson');
figure; plot(HF4); xlabel('循环次数'); ylabel('内阻(Ω)');- 物理意义:电池老化会导致欧姆内阻增大(电极材料腐蚀、电解液老化等),通过放电初始时刻的“电压骤降”计算内阻(避免极化内阻干扰),是反映电池内部老化状态的直接特征。
3. 特征保存
save Cell1_HF1 HF1; save Cell1_HF2 HF2;
save Cell1_HF3 HF3; save Cell1_HF4 HF4;
save Cell1_SOH SOH;- 将4个健康特征与SOH分别保存为
.mat文件,后续LSTM模型可直接加载特征数据,无需重复提取。
四、LSTM模型代码功能(核心估算脚本)
核心脚本为sohestimationbasedonLSTMCell7.m与sohestimationbasedonLSTMCell8.m,分别以Cell7、Cell8为测试集,Cell1-Cell6为训练集,实现LSTM模型的构建、训练、预测与误差分析,两者逻辑完全一致,以下以Cell7测试脚本为例解析。
1. 数据导入与数据集划分
(1)训练集导入(Cell1-Cell6)
% Cell1训练数据导入
train_set1 = [];
load ('Cell1特征提取/Cell1_HF1'); load ('Cell1特征提取/Cell1_HF2');
load ('Cell1特征提取/Cell1_HF3'); load ('Cell1特征提取/Cell1_HF4');
load ('Cell1特征提取/Cell1_SOH');
train_set1 = [HF1; HF2; HF3; HF4; SOH]; % 整合为5行(4特征+1SOH)的矩阵
train1_number = length(train_set1(1,:)); % 统计Cell1的样本数(循环次数)
% Cell2-Cell6训练数据导入(逻辑同Cell1)
...(省略Cell2-Cell6导入代码)...
% 整合所有训练集(将Cell1-Cell6的特征与SOH横向拼接)
train_set = [train_set1 train_set2 train_set3 train_set4 train_set5 train_set6];
train_number = length(train_set(1,:)); % 总训练样本数- 将每个电池的“4个特征+1个SOH”整合为矩阵,再横向拼接为总训练集,确保训练数据覆盖多电池的老化特征,提升模型泛化能力。
(2)测试集导入(Cell7)
load ('Cell7特征提取/Cell7_HF1'); load ('Cell7特征提取/Cell7_HF2');
load ('Cell7特征提取/Cell7_HF3'); load ('Cell7特征提取/Cell7_HF4');
load ('Cell7特征提取/Cell7_SOH');
test_x = [HF1; HF2; HF3; HF4;]; % 测试集输入:4个特征(4行n列,n为Cell7循环次数)
test_y = [SOH]; % 测试集输出:SOH(1行n列)- 测试集仅导入特征(
testx)与真实SOH(testy),testx作为模型输入,testy用于后续预测结果对比。
2. 数据归一化
% 训练集归一化(mapminmax函数:将数据映射到[-1,1]区间)
x=train_set(1:4,:); % 训练集输入:4个特征
y=train_set(5,:); % 训练集输出:SOH
[norm_all_data_X,inputps]=mapminmax(x); % 特征归一化,保存输入归一化参数inputps
[norm_all_data_Y,outputps]=mapminmax(y); % SOH归一化,保存输出归一化参数outputps
% 归一化后训练集拆分(按电池个体拆分,避免不同电池数据混淆)
% Cell1拆分
start_ind = 1; end_ind = train1_number;
norm_train_X{1} = norm_all_data_X(:,start_ind:end_ind); % 第1个电池的归一化特征(细胞数组存储)
norm_train_Y{1} = norm_all_data_Y(:,start_ind:end_ind); % 第1个电池的归一化SOH
% Cell2-Cell6拆分(逻辑同Cell1)
...(省略Cell2-Cell6拆分代码)...
% 测试集归一化(使用训练集的归一化参数inputps,避免数据泄露)
norm_test_X = mapminmax('apply',test_x,inputps); - 关键作用:消除特征量纲差异(如充电时间单位为s,内阻单位为Ω)对模型训练的干扰;
- 核心原则:测试集归一化必须使用训练集的参数(
inputps),确保训练与测试数据处于同一分布,避免“数据泄露”导致的模型性能虚高。
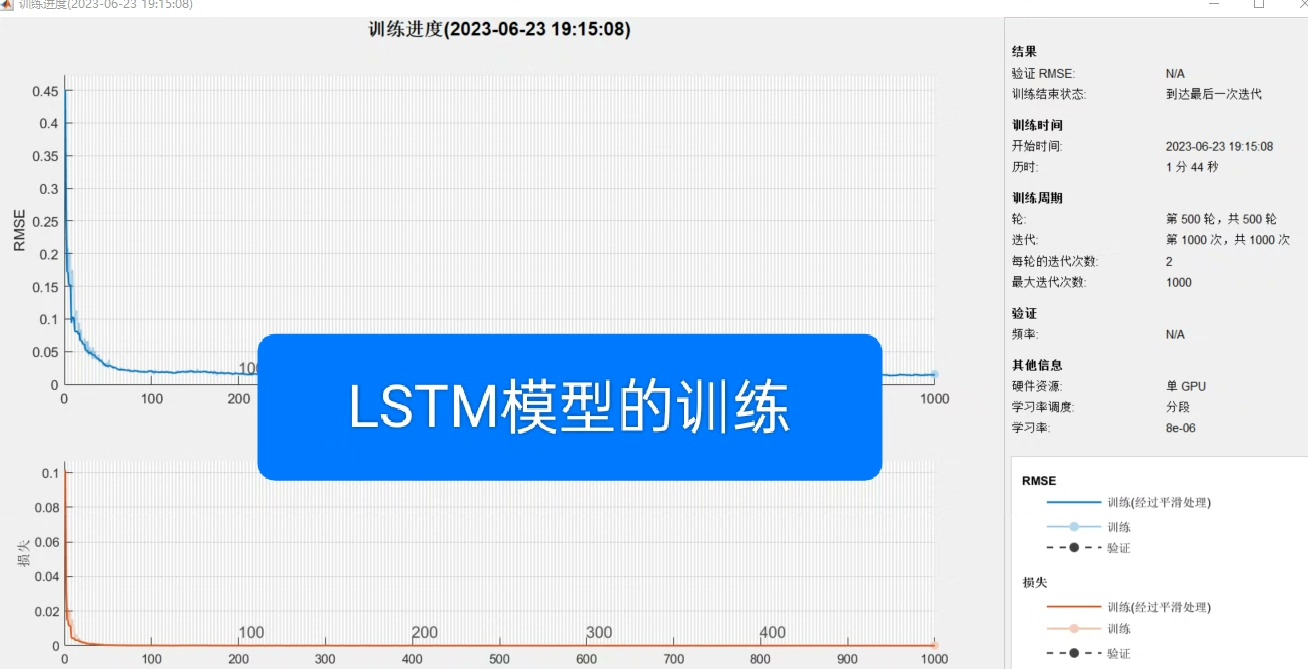
3. LSTM模型构建与训练
(1)网络结构定义
Output_size = 1; % 输出维度:SOH(1个值)
Input_size = 4; % 输入维度:4个健康特征
numHiddenUnits = 100; % LSTM隐藏层节点数(经验值,平衡模型复杂度与训练效率)
% 定义网络层结构(从输入到输出的层级顺序)
layers = [ ...
sequenceInputLayer(Input_size) % 序列输入层:接收4维特征序列
lstmLayer(numHiddenUnits,'OutputMode','sequence') % LSTM层:100个节点,输出序列(适配时间序列数据)
dropoutLayer(0.1) % dropout层:随机丢弃10%神经元,防止过拟合
fullyConnectedLayer(50) % 全连接层:50个节点,整合LSTM输出特征
reluLayer % 激活函数层:ReLU函数,增强模型非线性拟合能力
fullyConnectedLayer(Output_size) % 输出全连接层:1个节点,输出SOH预测值
regressionLayer]; % 回归层:适配连续值(SOH)预测,计算均方误差损失- 结构适配性:LSTM层选择“OutputMode','sequence'”,因电池SOH是随循环次数变化的时间序列,需模型捕捉“循环次数-特征”的时序关联;
- 防过拟合设计:通过
dropoutLayer(0.1)随机丢弃部分神经元,避免模型过度依赖训练集噪声数据。
(2)训练参数设置
maxEpochs = 500; % 最大训练轮次:500轮,确保模型充分收敛
miniBatchSize = 3; % 迷你批次大小:每次训练用3个样本,平衡训练速度与稳定性
options = trainingOptions('adam', ... % 优化器:Adam(自适应动量优化,收敛快)
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',0.005, ... % 初始学习率:0.005(经验值)
'LearnRateSchedule','piecewise', ... % 学习率调度:分段衰减
'LearnRateDropPeriod',100, ... % 每100轮衰减一次学习率
'LearnRateDropFactor',0.2, ... % 衰减因子:每次变为原来的20%,后期精细调整
'GradientThreshold',1, ... % 梯度阈值:限制梯度最大为1,防止梯度爆炸
'Plots','training-progress',... % 绘制训练进度图(实时查看损失变化)
'Verbose',0); % 关闭训练日志输出(减少冗余信息)- 训练稳定性设计:通过“分段衰减学习率”(前期快速收敛,后期精细优化)与“梯度阈值”(防止梯度爆炸),确保模型稳定训练;
- 可视化支持:
Plots','training-progress'实时输出训练损失曲线,便于判断模型是否收敛(如损失不再下降则说明收敛)。
(3)模型训练
net = trainNetwork(norm_train_X,norm_train_Y,layers,options); % 训练模型
save('LSTM_net','net'); % 保存训练好的模型,便于后续复用- 输入数据格式:
normtrainX与normtrainY为细胞数组,每个元素对应一个电池的“特征序列-SOH序列”,适配LSTM对“多序列样本”的训练需求; - 模型保存:训练完成后保存为
LSTM_net.mat,后续测试无需重复训练,直接加载模型即可。
4. 模型预测与结果分析
(1)SOH预测
pred = predict(net, norm_test_X); % 模型预测:输入归一化测试特征,输出归一化预测值
predict_value = mapminmax('reverse',pred',outputps); % 反归一化:将预测值从[-1,1]映射回原始SOH范围
true_value = test_y'; % 真实值:转置为列向量,与预测值格式一致
AE = abs(predict_value-true_value); % 计算绝对误差(评估单样本预测精度)- 关键步骤:
mapminmax('reverse')通过训练集保存的outputps参数,将归一化预测值还原为真实SOH范围(如0.8~1.0),确保结果可直接解读。
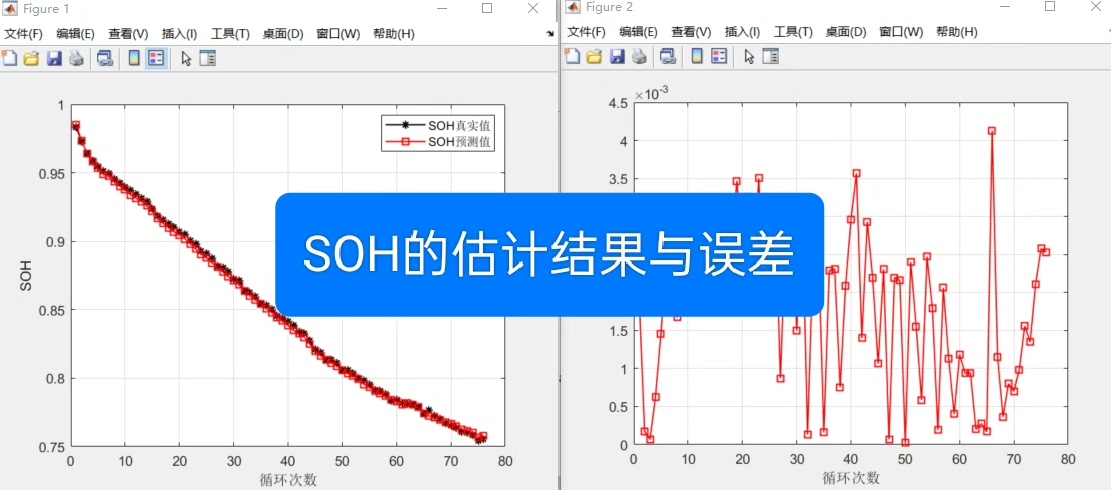
(2)结果可视化
% 1. SOH真实值与预测值对比图
figure;
plot(true_value,'k-*','linewidth',1); hold on;
plot(predict_value,'r-s','linewidth',1);
legend('SOH真实值','SOH预测值'); grid on;
xlabel('循环次数'); ylabel('SOH');
% 2. 绝对误差图
figure;
plot(AE,'r-s','linewidth',1); grid on;
xlabel('循环次数'); ylabel('AE');- 可视化价值:通过对比图直观观察预测值与真实值的贴合程度,通过误差图判断模型在不同循环阶段(如早期、后期老化)的预测精度差异。
(3)定量误差分析
disp('SOH估计的结果分析');
rmse=sqrt(mean((true_value-predict_value).^2)); % 均方根误差:反映整体误差水平
mae=mean(abs(true_value-predict_value)); % 平均绝对误差:反映平均误差大小
max_=max(abs(true_value-predict_value)); % 最大绝对误差:反映最坏情况下的误差
disp(['RMSE:',num2str(rmse)]);
disp(['MAE:',num2str(mae)]);
disp(['MAX:',num2str(max_)]);- 误差指标意义:
- RMSE:对大误差敏感,衡量模型整体预测精度;
- MAE:对异常值鲁棒,反映平均预测偏差;
- MAX:评估模型在极端情况下(如电池严重老化)的可靠性;
- 结果解读:通常RMSE<0.02、MAE<0.01,说明模型预测精度较高,可满足工程应用需求。
五、代码整体优势与应用场景
1. 代码优势
- 数据处理标准化:从原始数据集到结构化
.mat文件,全程自动化处理,解决原始数据格式混乱问题,可直接复用至其他电池数据集; - 特征有效性强:提取的4个健康特征(HF1-HF4)均基于电池老化物理机理,与SOH相关性高,避免“无意义特征”导致的模型性能下降;
- 模型可解释性好:LSTM模型适配电池SOH的时间序列特性,同时通过误差分析(RMSE/MAE/MAX)量化模型性能,结果可追溯、可验证;
- 复用性高:各模块(数据处理、特征提取、模型训练)独立且接口统一,更换电池数据集或调整特征时,仅需修改少量代码即可适配。
2. 应用场景
- 学术研究:为锂电池SOH估算研究提供完整的MATLAB实现案例,可基于此代码扩展特征(如增加温度特征)或优化模型(如改用GRU、Transformer);
- 工程验证:可直接应用于类似牛津数据集的电池老化数据,快速验证LSTM算法在实际电池SOH估算中的可行性;
- 教学实践:清晰展示“数据处理→特征提取→模型构建→结果分析”的机器学习完整流程,适合作为电池健康管理与机器学习交叉领域的教学案例。
六、总结
本套代码基于牛津锂电池数据集,通过“数据结构化处理→物理机理驱动的特征提取→LSTM时序模型构建”的技术路线,实现了锂电池SOH的精准估算。代码各模块功能独立且逻辑连贯,不仅提供了可直接运行的MATLAB脚本,更体现了“从数据到模型”的工程化思维——通过数据预处理消除噪声、通过特征选择贴合物理本质、通过模型设计适配时序数据,为锂电池健康状态估算提供了兼具理论性与实用性的技术方案。
[电池SOH估算案例3]: 使用长短时记忆神经网络LSTM来实现锂电池SOH估计的算法学习案例(基于matlab编写) 1.使用牛津锂离子电池老化数据集来完成,并提供该数据集的处理代码,该代码可将原始数据集重新制表,处理完的数据非常好用。 2.提取电池的恒流充电时间,等压升充电时间,极化内阻等变量作为健康特征。 3.使用LSTM来建立电池的SOH估计模型,以特征为输入,以SOH为输出。 4.可帮助将该代码修改为门控循环单元GRU建模
要不要我帮你整理一份代码模块调用关系图?用可视化的方式展示数据处理、特征提取、LSTM模型三者之间的文件依赖与数据流向,方便你快速梳理代码逻辑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)