LangChain 聊天模型核心能力 [ 2 ]

聊天模型 - 调用工具
工具调用本质上是让大语言模型(LLM)具备与外部世界交互的能力。LLM 本身是一个封闭的知识系统,其能力受限于其训练数据(存在滞后性)和内在的文本生成逻辑。它无法进行实时计算、查询实时信息、操作 API、调用脚本等。
工具调用打破了这一层壁垒,具体体现在:
- 扩展能力边界:模型可以借助工具完成它自身无法完成的任务,如执行数学计算、搜索网络、查询数据库等。
- 保证信息实时性:通过调用搜索工具或数据库查询工具,LLM 可以获取最新的、训练数据中不存在的信息,避免回答过时或 “一本正经地胡说八道”。
- 处理复杂任务:将一个复杂的用户请求(如 “分析我上个月的消费趋势”)分解成多个步骤,并依次调用不同的工具(如 “从数据库获取数据” -> “用 Python 进行数据分析” -> “生成图表”)来协同完成。协调这件事这更体现在 Agent 智能体上。
- 连接现有系统:可以将企业内部已有的系统、API 和数据库封装成工具,让 LLM 成为一个用自然语言驱动的统一接口,极大地提升了自动化和集成能力。
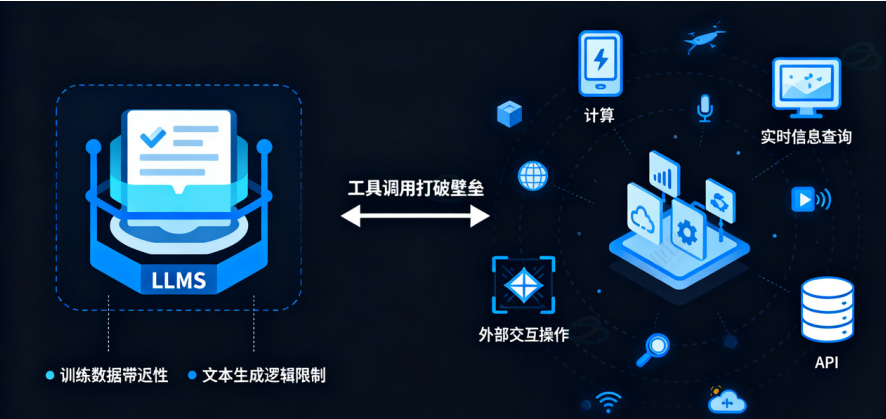
在 LangChain 中,聊天模型提供了额外的功能:工具调用。它能使 LLM 与外部服务、API 和数据库进行交互。工具调用还可用于从非结构化数据中提取结构化信息并执行各种其他任务。
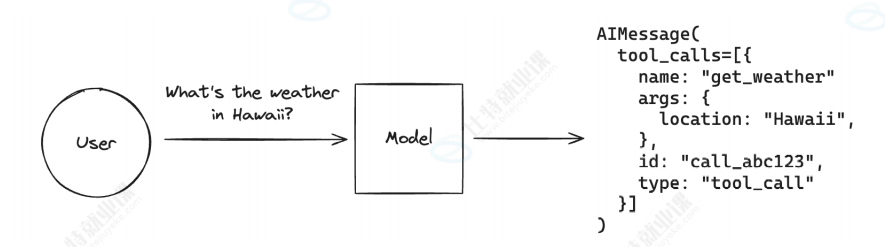
例如,当我们希望获取当前天气情况时,由于 LLM 无法获取实时信息,此时我们就可以借助工具,通过外部服务进行搜索完成查询:
再例如,当我们希望获取数据库表中的数据时,由于 LLM 无法直接获取表数据,此时我们就可以借助工具,通过与数据库交互完成查询:
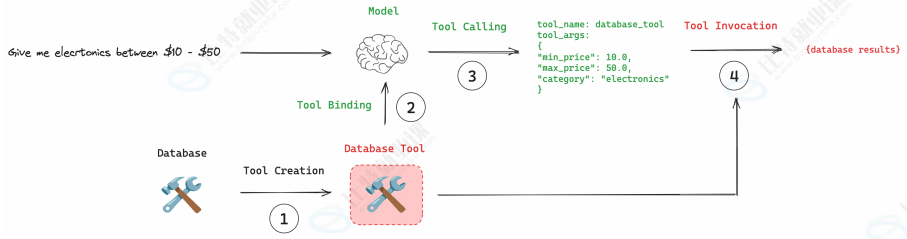
因此,在实际应用中,模型可以借助工具完成它自身无法完成的任务,如执行数学计算、搜索网络、查询数据库等。
创建工具
使用 @tool 装饰器创建工具
在 LangChain 中,实现了一个 @tool 装饰器来创建工具,@tool 装饰器是自定义工具的最简单方法。如下所示:
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two integers.
Args:
a: First integer
b: Second integer
"""
return a * b
print(multiply.invoke({"a": 2, "b": 3})) # 输出: 6
print(multiply.name) # 输出: multiply
print(multiply.description) # 输出: Multiply two ...省略...b: Second integer
print(multiply.args) # 输出: {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
可以看出,工具通过 @tool 加 Python 函数实现,其中:
- 该装饰器默认使用函数名称作为工具名称。
- 该装饰器将使用函数的文档字符串作为工具的描述。【注意哦,这个注释很重要】
因此,函数名、类型提示和文档字符串都是传递给工具 Schema 的一部分,不可缺失。定义好的描述是使模型良好运行的重要部分。
什么是 Schema?
答:想象以不同的方式,在 JSON 中表示有关一个人的信息:
示例 1:
{
"name": "张小红",
"birthday": "1732年2月22日",
"address": "陕西省西安市雁塔区"
}
示例 2:
{
"surname": "王",
"given_name": "刚",
"birthday": "1732-02-22",
"address": {
"district": "萧山区",
"city": "杭州市",
"province": "浙江省",
"country": "中国"
}
}
这两种表述同样有效,尽管示例 2 显然比示例 1 更正式。记录的设计在很大程度上取决于其在应用程序中的预期用途,因此这里没有正确或错误的答案。但是,当应用程序说 “给我一个人的 JSON 记录” 时,重要的是要确切地知道该如何组织记录。例如,我们需要知道需要哪些字段,以及如何表示这些值。这就是 JSON Schema 的用武之地。
你可能见过这种可视化配置方式【在我的 COZE 专栏中】,实际上是在构造 JSON Schema:
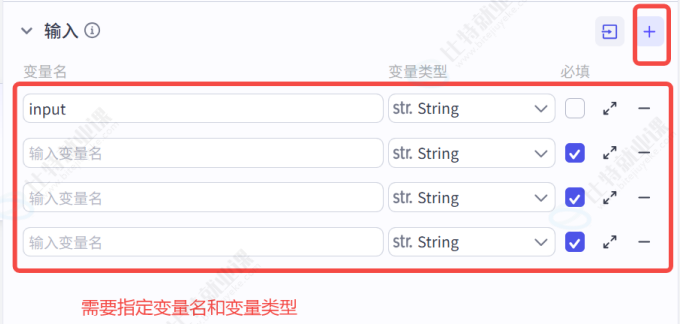
转换成编码方式,则为以下内容(此 JSON Schema 片段描述了上述第二个示例的结构):
{
"type": "object",
"properties": {
"surname": { "type": "string" },
"given_name": { "type": "string" },
"birthday": { "type": "string", "format": "date" },
"address": {
"type": "object",
"properties": {
"district": { "type": "string" },
"city": { "type": "string" },
"province": { "type": "string" },
"country": { "type": "string" }
}
}
}
}
若用此 JSON Schema “验证” 示例 1,那么示例 1 是不符合当前 JSON Schema 的,但是示例 2 可以 “验证” 通过。
注意,JSON Schema 是数据本身,而不是计算机程序,它只是一种 “描述其他数据结构” 的声明格式。简明扼要地描述数据的表面结构,并根据数据自动验证数据很容易。但是,由于 JSON Schema 不能包含任意代码,因此无法表达数据元素之间的关系存在某些约束。
因此,对于足够复杂的数据格式,任何 “验证工具” 都可能有两个验证阶段:一个在 schema(或结构)级别,一个在 语义级别。后一种检查可能需要使用更通用的编程语言来实现。
最后回答一下问题,Schema 就是描述其他数据结构的声明格式,用于自动验证数据而存在。
有了以上概念铺垫,对于工具 schema,它将从函数名、类型提示和文档字符串中获取相关属性,以此来声明一个工具,包括其名称、描述、输入参数、输出类型等等。这里需要说明的是,若是简单定义工具,如上述示例,工具 schema 需要解析 Google 风格的文档字符串 去获取【参数描述】。
什么是 Google 风格的文档字符串?Google 风格是 Python 文档字符串的一种写作规范。它并非 Python 语言官方强制要求,而是由 Google 为其内部 Python 项目制定的规范,后来因为其极高的可读性和简洁性而在整个 Python 社区中变得非常流行。
它使用 Args:、Returns: 等关键字,参数描述简洁明了,如下所示:
def fetch_data(url, retries=3):
"""从给定的URL获取数据。
Args:
url (str): 要从中获取数据的URL。
retries (int, optional): 失败时重试的次数。默认为3。
Returns:
dict: 从URL解析的JSON响应。
"""
# ... 函数实现 ...
除了这种方式,还有其他方式可以让工具 schema,获取相关工具声明需要的内容。下面再展示其他常用的工具定义模式:
模式 1:依赖 Pydantic 类
若使用 text-synthesis 定义工具时,没有任何文字字段,将会报错:
错误代码示例:
from langchain_core.tools import tool
@tool
def no_description_func(a: int, b: int) -> int:
return a + b
if __name__ == "__main__":
print(no_description_func.invoke(1, 2))
报错信息:
ValueError: Function must have a docstring if description not provided
这是因为这个原因,我们可以在 LangChain 中,可以使用 Pydantic 类来解决,这个类可以提供更详细的类型和类描述,通过 field description,LangChain 会自动生成 JSON Schema。注意,除非特殊情况,否则所有字段都有 required,即必填。
正确代码示例:
# 导入 Pydantic 库的 BaseModel,用于定义**数据验证模型**
# 作用:规定工具接收的参数类型、描述、校验规则
from pydantic import BaseModel, Field
# 导入 LangChain 提供的 @tool 装饰器
# 作用:把普通函数变成 LangChain 可调用的工具(Tool)
from langchain_core.tools import tool
# ------------------------------
# 步骤1:定义工具的参数结构(输入规范)
# ------------------------------
class MultiplySchema(BaseModel):
"""两个整数相乘""" # 模型文档字符串:给大模型看的功能描述
# Field:给参数加【描述 + 校验】,LLM 会根据这个描述理解参数
a: int = Field(description="第一个整数") # 参数a:int类型,描述文字
b: int = Field(description="第二个整数") # 参数b:int类型,描述文字
# ------------------------------
# 步骤2:用 @tool 装饰器把函数包装成 LangChain 工具
# ------------------------------
# args_schema=MultiplySchema:
# 告诉工具:我的输入参数必须遵循 MultiplySchema 的格式和类型
@tool(args_schema=MultiplySchema)
def multiply(a: int, b: int) -> int:
"""
两个整数相乘
:param a: 第一个整数
:param b: 第二个整数
:return: 两个整数的积
"""
# 函数核心逻辑:计算并返回 a*b
return a * b
# ------------------------------
# 步骤3:测试调用工具
# ------------------------------
if __name__ == "__main__":
# 工具调用方式:.invoke({参数字典})
# LangChain Tool 必须传入字典格式,会自动验证参数类型
print(multiply.invoke({"a": 3, "b": 4})) # 输出 12输出:
12
完整代码示例:
from pydantic import BaseModel, Field
from langchain_core.tools import tool
from typing import List, Optional
# 1. 定义复杂的输入参数模型
class UserInfo(BaseModel):
"""用户信息查询参数"""
user_id: int = Field(description="用户唯一标识ID", ge=1)
username: Optional[str] = Field(None, description="用户名,模糊查询")
tags: List[str] = Field(description="用户标签列表", min_items=1)
# 2. 使用Pydantic模型作为工具的参数Schema
@tool(args_schema=UserInfo)
def query_user_info(user_id: int, username: Optional[str] = None, tags: List[str] = None) -> dict:
"""
根据用户ID和可选条件查询用户信息
:param user_id: 用户唯一标识ID
:param username: 用户名,模糊查询
:param tags: 用户标签列表
:return: 用户信息字典
"""
# 模拟数据库查询结果
return {
"id": user_id,
"name": username or f"User_{user_id}",
"tags": tags,
"status": "active"
}
if __name__ == "__main__":
# 调用工具
result = query_user_info.invoke({
"user_id": 1001,
"username": "zhangsan",
"tags": ["vip", "developer"]
})
print(result)
输出:
{
'id': 1001,
'name': 'zhangsan',
'tags': ['vip', 'developer'],
'status': 'active'
}
注意代码中 @tool 的 args_schema 参数,它表示工具尚未在提供的描述、定义文档字符串等需要传递的参数。点选运行,不会报错,只将返回运行时的报错信息,因此,我们再次印证了函数名、类名描述和文档字符串的重要性。
模式 2:依赖 Annotated
在 LangChain 中,可以依赖 Annotated 和文档字符串传递给工具 Schema。如下所示:
# 导入 LangChain 核心的 @tool 装饰器
# 作用:把普通函数 → 包装成 LangChain 标准 Tool(工具)
from langchain_core.tools import tool
# 导入 Annotated:Python 3.9+ 类型注解扩展
# 作用:给参数附加元数据(描述、校验、示例等),LangChain 会读取它
from typing_extensions import Annotated
# ------------------------------
# 工具1:加法函数
# ------------------------------
# @tool:自动把函数转为 LangChain Tool
# 自动从:函数名、文档字符串、Annotated 生成工具描述
@tool
def add(
# Annotated[类型, ..., 描述]
# 结构:Annotated[真实类型, 元数据1, 元数据2, ..., 描述字符串]
# ... 是占位符(Ellipsis),表示“无额外校验/标记”
a: Annotated[int, ..., "First integer"], # 参数a:int,描述:First integer
b: Annotated[int, ..., "Second integer"] # 参数b:int,描述:Second integer
) -> int: # 返回值类型:int
"""Add two integers.""" # 工具功能描述(给大模型看的prompt)
return a + b # 实际逻辑
# ------------------------------
# 工具2:乘法函数(结构同上)
# ------------------------------
@tool
def multiply(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Multiply two integers."""
return a * b使用 StructuredTool 类提供的函数创建工具
class langchain_core.tools.structured.StructuredTool 类用来初始化工具,其中 from_function 类方法通过给定的函数来创建并返回一个工具。from_function 类方法定义如下:
classmethod from_function(
func: Callable | None = None,
coroutine: Callable[..., Awaitable[Any]] | None = None,
name: str | None = None,
description: str | None = None,
return_direct: bool = False,
args_schema: type[BaseModel] | dict[str, Any] | None = None,
infer_schema: bool = True,
*,
response_format: Literal['content', 'content_and_artifact'] = 'content',
parse_docstring: bool = False,
error_on_invalid_docstring: bool = False,
**kwargs: Any,
) -> StructuredTool
关键参数说明:
func:要设置的工具函数
coroutine:协程函数,要设置的异步工具函数
name:工具名称。默认为函数名称。
description:工具描述。默认为函数文档字符串。
args_schema:工具输入参数的 schema。默认为 None。
response_format:工具响应格式。默认为 "content"。
- 如果配置为
"content",则工具的输出为ToolMessage的content属性,对于HumanMessage、AIMessage已经见过,分别表示 用户消息 和 AI 消息响应,对于ToolMessage,它表示对应工具角色所发出的消息。 - 如果配置为
"content_and_artifact",则输出应是与ToolMessage的content属性与artifact属性相对应的二元组。(用法见下面的 示例 3)
该类方法全部参数及含义见这里。
示例 1:常规用法
对于用该类方法创建的工具,同样函数名、类型提示和文档字符串也都是传递给工具 Schema 的一部分,不可缺失。
from langchain_core.tools import StructuredTool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
calculator_tool = StructuredTool.from_function(func=multiply)
print(calculator_tool.invoke({"a": 2, "b": 3})) # 输出: 6
示例 2:加入配置,依赖 Pydantic 类
同样的,让工具函数不提供描述、文档字符串等需要传递给工具 Schema 的内容,如下所示:
def multiply(a: int, b: int) -> int:
return a * b
此时可以:
- 使用
args_schema参数,依赖 Pydantic 类定义并提供工具输入参数的schema属性。 - 使用
description参数,替代文档字符串中对于工具描述的schema属性。
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> int:
return a * b
calculator_tool = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="两数相乘",
args_schema=CalculatorInput,
)
print(calculator_tool.invoke({"a": 2, "b": 3})) # 输出: 6
print(calculator_tool.description) # 输出: 两数相乘
print(calculator_tool.args)
# 输出: {'a': {'description': 'first number', 'title': 'A', 'type': 'integer'}, 'b': {'description': 'second number', 'title': 'B', 'type': 'integer'}}
示例 3:加入 response_format 配置
如果希望我们的工具区分消息内容(content)和其他工件(artifact),让大模型读取 content,而一些用来构造 content 的原始数据保存下来,若后续有一些记录、分析的步骤,就可以派上用场了,这就是 artifact。artifact 通常需要使用字典 Dict 或列表 List 保存。
接下来举个例子再来理解下。例如我们定义了一个搜索天气的 tool,若使用搜索引擎询问 “今天的天气如何?” 时:
- content 可能是:“根据最新搜索结果,今天北京晴,气温在 25°C 到 32°C 之间。建议穿短袖衣物。”
- artifact 可能是某搜索引擎 API 返回的完整 JSON 响应,其中包含多个搜索结果条目、每个条目的标题、链接、摘要、排名等元数据。如下所示:
# Artifact 的示例结构
{
'results': [
{
'title': '北京天气预报 - 中国天气网',
'link': 'https://weather.com.cn/',
'snippet': '北京今天白天晴,最高气温32°C,夜间晴,最低气温25°C...'
},
{
'title': '北京实时天气 - weather.com/',
'link': 'https://www.weather.com/...',
'snippet': 'Beijing, China weather. Mostly sunny. High 32C...'
},
# ... 更多结果
],
'search_parameters': { ... },
'search_information': { ... }
}
则对于以上原生数据,无论我们今后做日志记录、分析,或自定义后续的处理都很方便。例如存在以下场景:
- 我们不仅仅想要一个总结性的答案,还想要具体的链接、来源或多个备选答案。
- 工具的
content输出不符合你的预期,我们想查看原始数据来理解问题出在哪里(是工具解析的问题,还是 API 本身返回的问题)。 - 需要记录每次工具调用的完整原始响应,以满足数据分析的要求。
- ……
从这里就可以对比出只返回 content 无法做到这些事情。
如何做到?
我们需要在定义工具时指定 response_format="content_and_artifact" 参数,并确保我们返回一个元组 (content, artifact),代码如下:
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
from typing import List, Tuple
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> Tuple[str, List[int]]:
nums = [a, b]
content = f"{nums}相乘的结果是{a * b}"
return content, nums
calculator_tool = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="两数相乘",
args_schema=CalculatorInput,
response_format="content_and_artifact"
)
上面的代码中,我们将需要相乘的数据当作原始数据,作为样例。(说明:@tool 也支持 response_format 参数)
如果我们直接使用工具参数调用工具,将只返回输出的 content 部分:
print(calculator_tool.invoke({"a": 2, "b": 3})) # 输出: [2, 3]相乘的结果是6
若想要看到工具返回的元组,我们需要模拟大模型调用工具的姿势,如下所示。这将返回一个 ToolMessage:
print(calculator_tool.invoke(
{
"name": "Calculator",
"args": {"a":2,"b": 3},
"id": "123", # 必须,与工具调用关联的标识符,将工具调用请求与工具调用结果相关联
"type": "tool_call", # 必须
}
))
结果如下:
# ToolMessage 的结构是
content='[2, 3]相乘的结果是6' name='Calculator' tool_call_id='123' artifact=[2, 3]
由于 LLM 大多理解文本,所以工具的主要输出 content 必须是结构良好、简洁的文本,以便模型能够处理和基于它进行推理、生成下一步的指令。
在链(Chain)中,工具调用之后的其他组件 / 函数,可能需要工具的原始结构化数据(即 artifact)来执行其操作,这些数据可能是庞大的、自定义的,这些数据不适合直接给模型。因此,artifact 其实是为了给链中后续的组件或函数使用的,不被大模型所直接使用!
绑定工具
为了实际将这些工具绑定到聊天模型,可以使用聊天模型的 .bind_tools() 方法。如下所示:
# 定义 ChatOpenAI 模型
model = ChatOpenAI(model="gpt-4o-mini")
# 绑定工具,返回一个 Runnable 实例
tools = [add, multiply]
model_with_tools = model.bind_tools(tools)
bind_tools() 方法定义
def bind_tools(
tools: Sequence[BaseTool] | type[CallableBaseTool],
*,
tool_choice: dict[str, Any] | Literal["auto", "none", "required", "any"] | bool = None,
strict: bool | None = None,
parallel_tool_calls: bool | None = None,
**kwargs: Any,
) -> Runnable[
PromptValue
| str
| dict[str, Any]
| Sequence[BaseMessage]
| list[str]
| tuple[str, str]
| str
| dict[str, Any],
BaseMessage
]
请求参数:
tools:绑定到此聊天模型的工具定义列表。支持的类型为:字典、pydantic.BaseModel 类、Python 函数和 @tool 装饰器创建的工具。
tool_choice(默认空):要调用哪个工具。可以设置为:
- 形式为
<tool_name>的str:调用<tool_name>工具。 auto:自动选择工具(包括无工具)none:不调用工具。any或required:默认 OpenAI 强制调用至少一个工具。False或None:无效果,默认行为。str(默认空):- 如果为
True,则保证模型输出与工具定义中提供的 JSON Schema 完全匹配。输入也将根据提供的 Schema 进行验证。 - 如果为
False,则不会验证输入,也不会验证模型输出。 - 如果为
None,则不会将strict参数传递给模型。
- 如果为
parallel_tool_calls:默认为 None,允许并行工具使用。设置为 False 以禁用并行工具。
kwargs(Any):任何附加参数都直接传递给 bind()。
返回值:
返回一个 Runnable 实例。该实例支持多种输入:
- 原始提示 PromptValue
- 字符串:"上海天气如何?"
- 消息串或消息列表:
[HumanMessage(content="...")] - 包含工具调用信息的 AIMessage
工具调用
通过 .bind_tools() 方法我们可知,它返回了一个 Runnable 实例,因此我们可以使用该 Runnable 实例,调用 .invoke() 方法,完成工具调用。示例如下:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from typing_extensions import Annotated
# 定义大型模型
model = ChatOpenAI(model="gpt-4o-mini")
@tool
def add(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Add two integers."""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Multiply two integers."""
return a * b
# 绑定工具
tools = [add, multiply]
model_with_tools = model.bind_tools(tools)
# 调用工具
result = model_with_tools.invoke("6乘6等于多少?")
print(result)
输出结果(AIMessage):
{
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_mbNXWYvAfOrEXEcdC6Gl",
"function": {
"arguments": "{\"a\":9,\"b\":6}",
"name": "multiply",
"type": "function"
},
"proposal_tokens": 86,
"response_metadata": {
"token_usage": {
"completion_tokens": 17,
"prompt_tokens": 103,
"total_tokens": 120,
"completion_tokens_details": {
"audio_tokens": 0,
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
},
"model_name": "gpt-4o-mini-2024-07-18",
"system_fingerprint": "fp_66aef6e559",
"id": "chatcmpl-6G0S4bmkWU626ykPLlAsDuEyu",
"finish_reason": "tool_calls",
"logprobs": null
},
"id": "run-1f43e942-d56b-6d6f-8fad-call_mbNXWYvAfOrEXEcdC6Gl",
"type": "tool_call"
}
]
},
"usage_metadata": {
"input_tokens": 86,
"output_tokens": 103,
"total_tokens": 189,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 0
}
}
}输出说明:
AIMessage:来自 AI 的消息。从聊天模型返回,作为对提示(输入)的响应。
content:消息的内容。additional_kwargs:与消息关联的其他有效负载数据。对于来自 AI 的消息,可能包括模型提供程序的工具调用。response_metadata:响应元数据。例如:响应头、logprobs、令牌计数、模型名称。
从输出结果来看,AI 给出的响应是进行工具的调用!
工具调用的一个关键原则是,模型根据输入的相关性决定何时使用工具。模型并不总是需要调用工具。例如,给定一个不相关的输入,模型不会调用该工具:
result = model_with_tools.invoke("hello world!")
print(result)
输出结果(AIMessage):
{
"content": "Hello! How can I assist you today?",
"additional_kwargs": {
"refusal": None
},
"response_metadata": {
"token_usage": {
"completion_tokens": 10,
"prompt_tokens": 82,
"total_tokens": 92,
"completion_tokens_details": {
"audio_tokens": 0,
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
},
"model_name": "gpt-4o-mini-2024-07-18",
"system_fingerprint": "fp_66aef6e559",
"id": "chatcmpl-fN27rMf1soA66ae59e tid=",
"finish_reason": "stop",
"logprobs": None
},
"id": "run-82f966f1-0842-407b-87ca-19f536935de4-0",
"usage_metadata": {
"input_tokens": 82,
"output_tokens": 10,
"total_tokens": 92,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 0
}
}
}强制模型调用工具
当然我们也可以让模型强制调用工具,那需要在绑定工具时,设置 tool_choice="any",表示强制调用至少一个工具。示例如下:
model_with_tools = model.bind_tools(tools, tool_choice="any")
result = model_with_tools.invoke("hello world!")
print(result)
输出结果(AIMessage):
{
"content": "",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_mWZRKz0bsZC2cvWbACt",
"function": {
"arguments": "{\"a\":1,\"b\":2}",
"name": "add",
"type": "function"
},
"refusal": None,
"response_metadata": {
"token_usage": {
"completion_tokens": 17,
"prompt_tokens": 89,
"total_tokens": 106,
"completion_tokens_details": {
"audio_tokens": 0,
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
},
"model_name": "gpt-4o-mini-2024-07-18",
"system_fingerprint": "fp_66aef6e559",
"id": "chatcmpl-6G0S4bmkWU626ykPLlAsDuEyu",
"finish_reason": "tool_calls",
"logprobs": None
},
"id": "run-1f43e942-d56b-6d6f-8fad-call_mWZRKz0bsZC2cvWbACt",
"type": "tool_call"
}
]
},
"usage_metadata": {
"input_tokens": 99,
"output_tokens": 17,
"total_tokens": 116,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 0
}
}
}工具属性
现在我们知道,输出结果是一个 AIMessage。但是,如果调用了工具,则 result 将具有一个 tool_calls 属性。此属性包括执行该工具所需的一切,包括工具名称和输入参数,示例如下:
model_with_tools = model.bind_tools(tools, tool_choice="any")
result = model_with_tools.invoke("6乘6等于多少?")
print(result.tool_calls)
输出结果:
[{'name': 'multiply', 'args': {'a': 9, 'b': 6}, 'id': 'call_mbNXWYvAfOrEXEcdC6Gl', 'type': 'tool_call'}]
将工具输出传给聊天模型
到这里可以发现,我们仅仅只是成功调用了工具,但是聊天模型并没有给我们返回我们真正需要的答案。此时就需要:
- 将工具输出传递给聊天模型,包括
HumanMessage、AIMessage(工具调用)、ToolMessage - 聊天模型根据以上消息输入,将最终结果
AIMessage返回。
为什么要发 ToolMessage 呢?
之前我们讲过,聊天模型通常不是接受单个字符串作为输入,而是接受 聊天消息 (XxxMessage) 列表,因此在这里我们需要将工具的返回,构造成 ToolMessage,再传输给聊天模型!!!
方便的是,如果我们使用 @tool 装饰器创建的工具,使用 tool.invoke(tool_calls),将自动返回一个 ToolMessage。完整示例如下:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from typing_extensions import Annotated
# 定义大型模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义工具
@tool
def add(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Add two integers."""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "First integer"],
b: Annotated[int, ..., "Second integer"]
) -> int:
"""Multiply two integers."""
return a * b
# 绑定工具
tools = [add, multiply]
model_with_tools = model.bind_tools(tools)
# 添加 AIMessage 到消息中去
messages = [
HumanMessage("9乘6等于多少?5加3等于多少?")
]
ai_msg = model_with_tools.invoke(messages)
messages.append(ai_msg)
# 根据工具名选择对应工具,区分大小写
for tool_call in ai_msg.tool_calls:
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
# 执行工具调用,返回 ToolMessage
tool_msg = selected_tool.invoke(tool_call)
# 将 ToolMessage 加入消息
messages.append(tool_msg)
print(messages)
result = model.invoke(messages)
print(result)
打印结果如下:
[HumanMessage(content='9乘6等于多少?5加3等于多少?', additional_kwargs={}, response_metadata={}),
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_tZHIrzQL0bGuXX6Zy', 'function': {'arguments': '{"a": 9, "b": 6}', 'name': 'multiply', 'type': 'function'}, 'refusal': None, 'response_metadata': {'token_usage': {'completion_tokens': 34, 'prompt_tokens': 93, 'total_tokens': 127, 'completion_tokens_details': {'audio_tokens': 0, 'reasoning_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_66aef6e559', 'id': 'chatcmpl-6G0S4bmkWU626ykPLlAsDuEyu', 'finish_reason': 'tool_calls', 'logprobs': None}, 'id': 'run-8e7a-9d74-023a-1f43e942d0f1', 'type': 'tool_call'}, {'id': 'call_tZHIrzQL0bGuXX6Zy2', 'function': {'arguments': '{"a": 5, "b": 3}', 'name': 'add', 'type': 'function'}, 'refusal': None, 'response_metadata': {}}, 'id': 'run-8e7a-9d74-023a-1f43e942d0f1', 'type': 'tool_call'}]}, response_metadata={}),
ToolMessage(content='54', name='multiply', tool_call_id='call_tZHIrzQL0bGuXX6Zy'),
ToolMessage(content='8', name='add', tool_call_id='call_tZHIrzQL0bGuXX6Zy2')]
content='9乘以6等于54,5加3等于8。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 159, 'total_tokens': 174, 'completion_tokens_details': {'audio_tokens': 0, 'reasoning_tokens': 0, 'accepted_prediction_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_66aef6e559', 'id': 'chatcmpl-fN27rMf1soA66ae59e tid=', 'finish_reason': 'stop', 'logprobs': None} id='run-82f966f1-0842-407b-87ca-19f536935de4-0' usage_metadata={'input_tokens': 159, 'output_tokens': 15, 'total_tokens': 174, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}}
从流程与代码中可以看到,实际上我们调用了两次聊天模型:
- 第一次:将【HumanMessage】发送给聊天模型进行处理,结果返回了【包含工具调用的 AIMessage】,但并没有返回我们要的结果。
- 第二次:将【HumanMessage + AIMessage + ToolMessage】消息发送给聊天模型进行处理,结果返回了【包含结果的 AIMessage】
LangChain 提供的工具
工具也不是全部需要我们自己手写,其实 LangChain 官方也已经给我们提供了很多现成的工具(Tool)和工具包(Toolkits)。LangChain 全部的工具(Tools)里,写的工具一般都是为了使用 langchain 提供了三方组件或工具而创造的,有搜索、数据库、网页浏览器等相关的工具。
LangChain 中的工具实际上是继承了 BaseTool 和 BaseToolkit,如下所示:
BaseTool:所有工具的基类BaseToolkit:工具包,用于管理一组相关工具
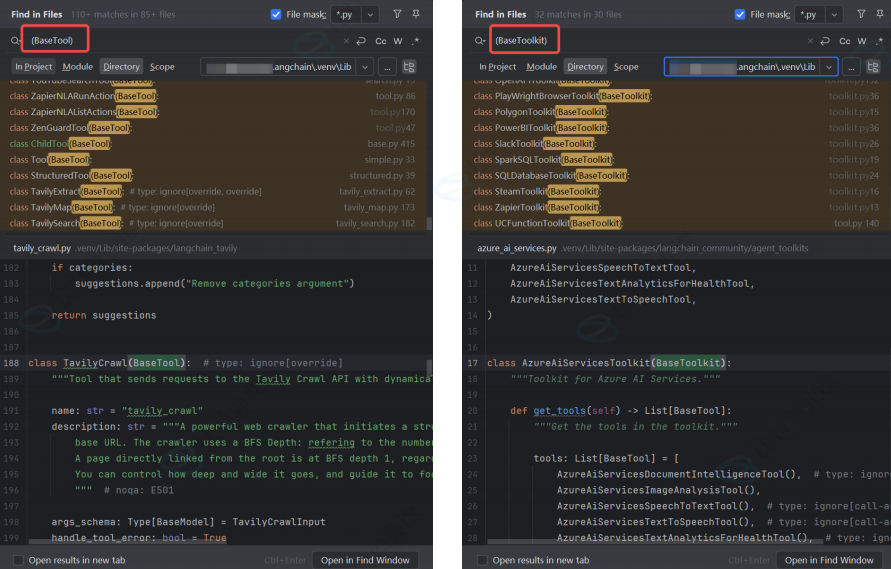
这里展示的全部是不同功能的工具,我们可以直接使用它们,找到相关的类名,去官网 API Reference查看,即可获取工具的详细用法与参数。
下面我们简单看一个搜索工具。
TavilySearch
TavilySearch 类可以支持我们进行搜索,Tavily 是一个专门为 AI 设计的搜索引擎,专为智能体检索与推理需求量身打造的工具。Tavily 不仅提供了高可信度的搜索结果,更具备基于传统搜索引擎的上下文推理生成能力。能够以结构化、可解析的形式返回 API 接口,便于将结果用于信息索引、后续的相关、理解任务。
执行流程:
访问 https://tavily.com/,需要注册,登录完成后,新建 API Key,如下图所示。【点击进入】
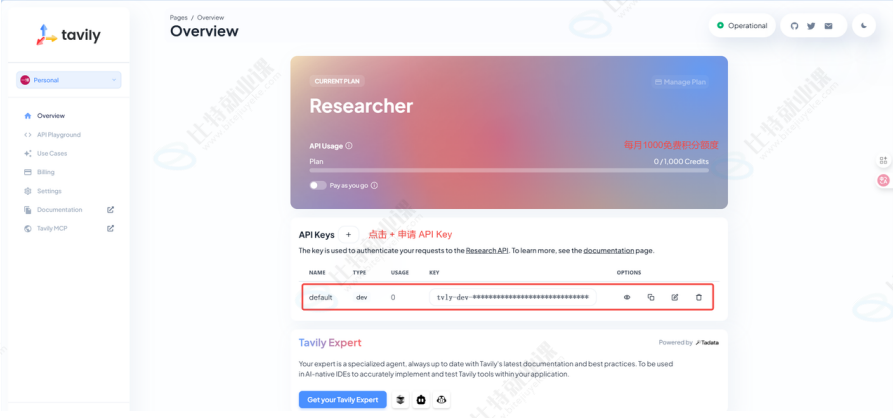
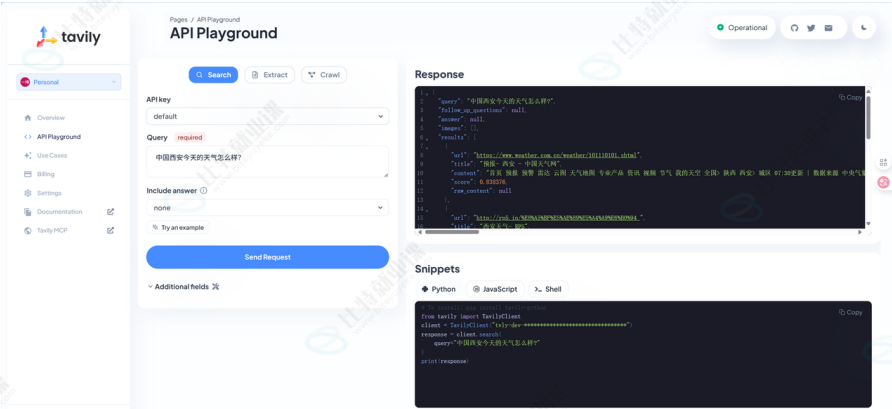
得到 API Key 后,可以使用刚申请的 API Keys,进行搜索测试。这会返回根据内容衍生出的多条搜索结果。
点击左侧 Use cases,可以了解相关功能,如聊天中可以支持搜索。
使用 Chat 模型:
下面我们在 LangChain 中接入搜索工具,步骤如下:
安装 langchain-tavily 包
pip install -U langchain-tavily
配置环境变量 TAVILY_API_KEY,值为我们申请的 API Key。
代码接入 TavilySearch 类,实现功能
from langchain_tavily import TavilySearch
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 定义大型模型
model = ChatOpenAI(model="gpt-4o-mini")
# 绑定工具
tool = TavilySearch(max_results=2)
model_with_tools = model.bind_tools([tool])
# 添加 AIMessage 到消息中去
messages = [
HumanMessage("上海天气如何?")
]
ai_msg = model_with_tools.invoke(messages)
messages.append(ai_msg)
# 执行工具调用,返回 ToolMessage
tool_msg = tool.invoke(ai_msg.tool_calls[0])
# 将 ToolMessage 加入消息
messages.append(tool_msg)
result = model_with_tools.invoke(messages)
print(result)
结果打印:
今天上海的天气情况如下:
- **最高气温**:31℃
- **最低气温**:22℃
- **天气**:晴转多云
- **风向**:东北风3-4级
- **湿度**:65%
- **紫外线**:中等
- **穿衣建议**:短袖、薄外套,注意防晒。
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)