结构动力学仿真-主题019-结构模态分析与参数识别
主题019:结构模态分析与参数识别
目录




引言
结构模态分析是结构动力学领域的核心技术之一,它通过识别结构的模态参数(固有频率、阻尼比和振型)来表征结构的动态特性。模态参数识别技术在航空航天、汽车工程、土木工程、机械制造等众多领域有着广泛的应用。
1.1 模态分析的重要性
模态分析的重要性体现在以下几个方面:
(1)结构动态特性表征
结构的模态参数是其固有特性的反映,与外部激励无关。通过模态分析,可以全面了解结构的振动特性,包括:
- 结构在哪些频率下容易发生共振
- 各阶振型的形状和节点位置
- 能量耗散机制(阻尼特性)
(2)有限元模型验证与修正
有限元分析(FEA)是结构设计的重要工具,但模型的准确性需要通过实验验证。实验模态分析(EMA)提供了验证和修正有限元模型的实验数据基础。
(3)故障诊断与损伤识别
结构损伤会导致模态参数的变化。通过监测模态参数的变化,可以实现:
- 结构健康监测
- 早期损伤预警
- 损伤定位与定量评估
(4)振动控制与优化设计
了解结构的模态特性后,可以:
- 避免共振,优化结构设计
- 设计有效的振动控制策略
- 优化传感器和作动器的布置
1.2 模态分析的分类
根据激励方式和数据处理方法,模态分析可分为以下几类:
(1)实验模态分析(Experimental Modal Analysis, EMA)
- 使用人工激励(锤击、激振器等)
- 测量激励力和响应
- 计算频响函数(FRF)
- 从FRF中提取模态参数
(2)运行模态分析(Operational Modal Analysis, OMA)
- 仅利用环境激励(风、交通、海浪等)
- 只测量结构响应
- 假设激励为白噪声
- 从输出数据中提取模态参数
(3)混合模态分析
- 结合EMA和OMA的优点
- 适用于特殊工况和复杂结构
1.3 模态参数识别方法的发展
模态参数识别方法经历了从简单到复杂、从单自由度到多自由度、从时域到频域再到时频域的发展历程:
早期方法(1960s-1970s):
- 峰值拾取法(Peak Picking)
- 圆拟合法(Circle Fitting)
- 单自由度法(SDOF Methods)
经典方法(1980s-1990s):
- Ibrahim时域法(ITD)
- 特征系统实现算法(ERA)
- 多参考点最小二乘复频域法(LSCF)
- 频域分解法(FDD)
现代方法(2000s至今):
- 随机子空间识别(SSI)
- 贝叶斯模态识别
- 盲源分离方法
- 机器学习方法
模态分析理论基础
2.1 结构动力学基本方程
考虑一个 n n n自由度线性时不变结构系统,其运动方程为:
M x ¨ ( t ) + C x ˙ ( t ) + K x ( t ) = f ( t ) \mathbf{M}\ddot{\mathbf{x}}(t) + \mathbf{C}\dot{\mathbf{x}}(t) + \mathbf{K}\mathbf{x}(t) = \mathbf{f}(t) Mx¨(t)+Cx˙(t)+Kx(t)=f(t)
其中:
- M ∈ R n × n \mathbf{M} \in \mathbb{R}^{n \times n} M∈Rn×n:质量矩阵(对称正定)
- C ∈ R n × n \mathbf{C} \in \mathbb{R}^{n \times n} C∈Rn×n:阻尼矩阵
- K ∈ R n × n \mathbf{K} \in \mathbb{R}^{n \times n} K∈Rn×n:刚度矩阵(对称正定或半正定)
- x ( t ) ∈ R n \mathbf{x}(t) \in \mathbb{R}^{n} x(t)∈Rn:位移向量
- f ( t ) ∈ R n \mathbf{f}(t) \in \mathbb{R}^{n} f(t)∈Rn:外力向量
2.2 无阻尼自由振动与模态分析
对于无阻尼自由振动( C = 0 \mathbf{C} = \mathbf{0} C=0, f ( t ) = 0 \mathbf{f}(t) = \mathbf{0} f(t)=0),运动方程为:
M x ¨ ( t ) + K x ( t ) = 0 \mathbf{M}\ddot{\mathbf{x}}(t) + \mathbf{K}\mathbf{x}(t) = \mathbf{0} Mx¨(t)+Kx(t)=0
设解的形式为 x ( t ) = ϕ e i ω t \mathbf{x}(t) = \boldsymbol{\phi}e^{i\omega t} x(t)=ϕeiωt,代入得特征值问题:
( K − ω 2 M ) ϕ = 0 (\mathbf{K} - \omega^2\mathbf{M})\boldsymbol{\phi} = \mathbf{0} (K−ω2M)ϕ=0
求解该广义特征值问题,得到:
- n n n个特征值 ω r 2 \omega_r^2 ωr2( r = 1 , 2 , . . . , n r = 1, 2, ..., n r=1,2,...,n),即固有频率的平方
- n n n个特征向量 ϕ r \boldsymbol{\phi}_r ϕr,即模态振型
固有频率和模态振型满足正交性条件:
ϕ r T M ϕ s = δ r s m r \boldsymbol{\phi}_r^T\mathbf{M}\boldsymbol{\phi}_s = \delta_{rs}m_r ϕrTMϕs=δrsmr
ϕ r T K ϕ s = δ r s k r = δ r s ω r 2 m r \boldsymbol{\phi}_r^T\mathbf{K}\boldsymbol{\phi}_s = \delta_{rs}k_r = \delta_{rs}\omega_r^2m_r ϕrTKϕs=δrskr=δrsωr2mr
其中 m r m_r mr为模态质量, k r k_r kr为模态刚度, δ r s \delta_{rs} δrs为Kronecker delta函数。
2.3 比例阻尼与实模态分析
当阻尼矩阵满足比例阻尼假设时:
C = α M + β K \mathbf{C} = \alpha\mathbf{M} + \beta\mathbf{K} C=αM+βK
其中 α \alpha α和 β \beta β为比例阻尼系数。此时,阻尼矩阵在模态坐标下也是对角化的:
ϕ r T C ϕ s = δ r s c r = δ r s 2 ζ r ω r m r \boldsymbol{\phi}_r^T\mathbf{C}\boldsymbol{\phi}_s = \delta_{rs}c_r = \delta_{rs}2\zeta_r\omega_rm_r ϕrTCϕs=δrscr=δrs2ζrωrmr
其中 ζ r \zeta_r ζr为第 r r r阶模态阻尼比。
模态阻尼比与比例系数的关系为:
ζ r = α 2 ω r + β ω r 2 \zeta_r = \frac{\alpha}{2\omega_r} + \frac{\beta\omega_r}{2} ζr=2ωrα+2βωr
2.4 一般阻尼与复模态分析
对于一般阻尼(非比例阻尼),需要采用状态空间方法。定义状态向量:
y ( t ) = [ x ( t ) x ˙ ( t ) ] \mathbf{y}(t) = \begin{bmatrix} \mathbf{x}(t) \\ \dot{\mathbf{x}}(t) \end{bmatrix} y(t)=[x(t)x˙(t)]
状态空间方程为:
y ˙ ( t ) = A y ( t ) + B f ( t ) \dot{\mathbf{y}}(t) = \mathbf{A}\mathbf{y}(t) + \mathbf{B}\mathbf{f}(t) y˙(t)=Ay(t)+Bf(t)
其中:
A = [ 0 I − M − 1 K − M − 1 C ] , B = [ 0 M − 1 ] \mathbf{A} = \begin{bmatrix} \mathbf{0} & \mathbf{I} \\ -\mathbf{M}^{-1}\mathbf{K} & -\mathbf{M}^{-1}\mathbf{C} \end{bmatrix}, \quad \mathbf{B} = \begin{bmatrix} \mathbf{0} \\ \mathbf{M}^{-1} \end{bmatrix} A=[0−M−1KI−M−1C],B=[0M−1]
求解特征值问题 A ψ = λ ψ \mathbf{A}\boldsymbol{\psi} = \lambda\boldsymbol{\psi} Aψ=λψ,得到 2 n 2n 2n个复特征值和复特征向量:
λ r = − ζ r ω r ± i ω r 1 − ζ r 2 = − σ r ± i ω d r \lambda_r = -\zeta_r\omega_r \pm i\omega_r\sqrt{1-\zeta_r^2} = -\sigma_r \pm i\omega_{dr} λr=−ζrωr±iωr1−ζr2=−σr±iωdr
其中:
- σ r = ζ r ω r \sigma_r = \zeta_r\omega_r σr=ζrωr:衰减系数
- ω d r = ω r 1 − ζ r 2 \omega_{dr} = \omega_r\sqrt{1-\zeta_r^2} ωdr=ωr1−ζr2:阻尼固有频率
2.5 频响函数(FRF)
频响函数描述了系统在频域内的输入-输出关系。对于比例阻尼系统,位移频响函数矩阵为:
H ( ω ) = ∑ r = 1 n ϕ r ϕ r T k r − ω 2 m r + i ω c r = ∑ r = 1 n ϕ r ϕ r T / m r ω r 2 − ω 2 + i 2 ζ r ω r ω \mathbf{H}(\omega) = \sum_{r=1}^{n} \frac{\boldsymbol{\phi}_r\boldsymbol{\phi}_r^T}{k_r - \omega^2m_r + i\omega c_r} = \sum_{r=1}^{n} \frac{\boldsymbol{\phi}_r\boldsymbol{\phi}_r^T/m_r}{\omega_r^2 - \omega^2 + i2\zeta_r\omega_r\omega} H(ω)=r=1∑nkr−ω2mr+iωcrϕrϕrT=r=1∑nωr2−ω2+i2ζrωrωϕrϕrT/mr
频响函数的分量形式为:
H j k ( ω ) = ∑ r = 1 n ϕ j r ϕ k r m r ( ω r 2 − ω 2 + i 2 ζ r ω r ω ) H_{jk}(\omega) = \sum_{r=1}^{n} \frac{\phi_{jr}\phi_{kr}}{m_r(\omega_r^2 - \omega^2 + i2\zeta_r\omega_r\omega)} Hjk(ω)=r=1∑nmr(ωr2−ω2+i2ζrωrω)ϕjrϕkr
频响函数的重要特性:
- 在固有频率 ω r \omega_r ωr附近,第 r r r阶模态起主导作用
- 频响函数的幅值在 ω r \omega_r ωr处出现峰值
- 频响函数的相位在 ω r \omega_r ωr处发生约180°的突变
- 频响函数包含完整的模态信息(频率、阻尼、振型)
2.6 脉冲响应函数(IRF)
脉冲响应函数是频响函数的逆傅里叶变换:
h ( t ) = 1 2 π ∫ − ∞ ∞ H ( ω ) e i ω t d ω \mathbf{h}(t) = \frac{1}{2\pi} \int_{-\infty}^{\infty} \mathbf{H}(\omega)e^{i\omega t}d\omega h(t)=2π1∫−∞∞H(ω)eiωtdω
对于比例阻尼系统,脉冲响应函数为:
h j k ( t ) = ∑ r = 1 n ϕ j r ϕ k r m r ω d r e − ζ r ω r t sin ( ω d r t ) h_{jk}(t) = \sum_{r=1}^{n} \frac{\phi_{jr}\phi_{kr}}{m_r\omega_{dr}}e^{-\zeta_r\omega_rt}\sin(\omega_{dr}t) hjk(t)=r=1∑nmrωdrϕjrϕkre−ζrωrtsin(ωdrt)
脉冲响应函数是时域模态参数识别的基础。
实验模态分析原理
3.1 实验模态分析的基本流程
实验模态分析通常包括以下步骤:
(1)测试规划
- 确定测试目的和精度要求
- 选择测点位置和数量
- 设计激励方式和测量方案
- 确定频率范围和分辨率
(2)数据采集
- 安装传感器(加速度计、力传感器等)
- 施加激励(锤击、激振器等)
- 采集力和响应信号
- 数据预处理(滤波、去噪等)
(3)FRF估计
- 计算自谱和互谱
- 估计频响函数
- 评估FRF质量
- 平均处理以提高精度
(4)模态参数识别
- 选择识别方法
- 提取模态参数
- 验证识别结果
- 计算模态置信准则(MAC)
(5)结果验证与报告
- 模态振型动画显示
- 与有限元结果对比
- 编制测试报告
3.2 激励技术
(1)锤击激励
- 优点:设备简单、操作方便、适合现场测试
- 缺点:能量有限、低频响应差、重复性受限
- 技术要点:力锤选择、锤头硬度、触发设置
力锤的力谱近似为半正弦波,其频谱宽度与锤头硬度有关:
F ( ω ) ≈ F 0 τ 2 ⋅ sin ( ω τ / 2 ) ω τ / 2 F(\omega) \approx F_0 \frac{\tau}{2} \cdot \frac{\sin(\omega\tau/2)}{\omega\tau/2} F(ω)≈F02τ⋅ωτ/2sin(ωτ/2)
其中 τ \tau τ为冲击持续时间。
(2)激振器激励
- 优点:能量大、频率范围宽、可控制激励波形
- 缺点:需要固定装置、可能引入附加刚度
- 激励信号:
- 正弦扫频:信噪比高,测试时间长
- 随机信号:测试效率高,需要平均
- 猝发随机:避免泄漏,适合小阻尼结构
- 冲击激励:频谱宽,适合快速测试
(3)环境激励
- 风荷载、交通荷载、海浪等
- 不可测量,假设为白噪声
- 运行模态分析的基础
3.3 传感器与测量系统
(1)加速度传感器
压电式加速度计是最常用的传感器,其工作原理基于压电效应:
Q = d 33 ⋅ F = d 33 ⋅ m ⋅ a Q = d_{33} \cdot F = d_{33} \cdot m \cdot a Q=d33⋅F=d33⋅m⋅a
其中 Q Q Q为电荷量, d 33 d_{33} d33为压电常数, m m m为质量块质量, a a a为加速度。
主要技术指标:
- 灵敏度(mV/g或pC/g)
- 频率范围
- 动态范围
- 横向灵敏度
(2)力传感器
力传感器通常采用压电式或应变式,安装在力锤或激振器与结构之间。
(3)数据采集系统
- 抗混叠滤波器
- A/D转换器
- 采样频率选择(通常$\geq$2.56倍最高分析频率)
- 分辨率(通常16位或24位)
3.4 FRF估计方法
(1) H 1 H_1 H1估计
H ^ 1 ( ω ) = S f x ( ω ) S f f ( ω ) \hat{H}_1(\omega) = \frac{S_{fx}(\omega)}{S_{ff}(\omega)} H^1(ω)=Sff(ω)Sfx(ω)
其中 S f x S_{fx} Sfx为力与响应的互谱, S f f S_{ff} Sff为力的自谱。 H 1 H_1 H1估计适用于响应噪声较大的情况。
(2) H 2 H_2 H2估计
H ^ 2 ( ω ) = S x x ( ω ) S x f ( ω ) \hat{H}_2(\omega) = \frac{S_{xx}(\omega)}{S_{xf}(\omega)} H^2(ω)=Sxf(ω)Sxx(ω)
其中 S x x S_{xx} Sxx为响应的自谱, S x f S_{xf} Sxf为响应与力的互谱。 H 2 H_2 H2估计适用于力测量噪声较大的情况。
(3) H v H_v Hv估计
H v H_v Hv估计是 H 1 H_1 H1和 H 2 H_2 H2的几何平均,对噪声具有更好的鲁棒性:
H ^ v ( ω ) = H ^ 1 ( ω ) ⋅ H ^ 2 ( ω ) \hat{H}_v(\omega) = \sqrt{\hat{H}_1(\omega) \cdot \hat{H}_2(\omega)} H^v(ω)=H^1(ω)⋅H^2(ω)
时域模态参数识别方法
4.1 Ibrahim时域法(ITD)
Ibrahim时域法是一种经典的时域模态参数识别方法,由Ibrahim于1977年提出。
基本原理:
利用脉冲响应函数的自由衰减特性,构造特征值问题来识别模态参数。
对于单点激励、多点测量的系统,第 j j j个测点的脉冲响应函数为:
h j ( t ) = ∑ r = 1 n A j r e − σ r t sin ( ω d r t + ϕ j r ) h_j(t) = \sum_{r=1}^{n} A_{jr}e^{-\sigma_rt}\sin(\omega_{dr}t + \phi_{jr}) hj(t)=r=1∑nAjre−σrtsin(ωdrt+ϕjr)
算法步骤:
(1)在离散时间点 t k = k Δ t t_k = k\Delta t tk=kΔt( k = 0 , 1 , . . . , 2 n − 1 k = 0, 1, ..., 2n-1 k=0,1,...,2n−1)采样脉冲响应
(2)构造数据矩阵:
X = [ h 1 ( t 0 ) h 1 ( t 1 ) ⋯ h 1 ( t 2 n − 1 ) h 2 ( t 0 ) h 2 ( t 1 ) ⋯ h 2 ( t 2 n − 1 ) ⋮ ⋮ ⋱ ⋮ h m ( t 0 ) h m ( t 1 ) ⋯ h m ( t 2 n − 1 ) ] \mathbf{X} = \begin{bmatrix} h_1(t_0) & h_1(t_1) & \cdots & h_1(t_{2n-1}) \\ h_2(t_0) & h_2(t_1) & \cdots & h_2(t_{2n-1}) \\ \vdots & \vdots & \ddots & \vdots \\ h_m(t_0) & h_m(t_1) & \cdots & h_m(t_{2n-1}) \end{bmatrix} X= h1(t0)h2(t0)⋮hm(t0)h1(t1)h2(t1)⋮hm(t1)⋯⋯⋱⋯h1(t2n−1)h2(t2n−1)⋮hm(t2n−1)
(3)构造延迟矩阵:
X τ = [ h 1 ( t 1 ) h 1 ( t 2 ) ⋯ h 1 ( t 2 n ) h 2 ( t 1 ) h 2 ( t 2 ) ⋯ h 2 ( t 2 n ) ⋮ ⋮ ⋱ ⋮ h m ( t 1 ) h m ( t 2 ) ⋯ h m ( t 2 n ) ] \mathbf{X}_\tau = \begin{bmatrix} h_1(t_1) & h_1(t_2) & \cdots & h_1(t_{2n}) \\ h_2(t_1) & h_2(t_2) & \cdots & h_2(t_{2n}) \\ \vdots & \vdots & \ddots & \vdots \\ h_m(t_1) & h_m(t_2) & \cdots & h_m(t_{2n}) \end{bmatrix} Xτ= h1(t1)h2(t1)⋮hm(t1)h1(t2)h2(t2)⋮hm(t2)⋯⋯⋱⋯h1(t2n)h2(t2n)⋮hm(t2n)
(4)求解特征值问题:
X τ = A X \mathbf{X}_\tau = \mathbf{A}\mathbf{X} Xτ=AX
矩阵 A \mathbf{A} A的特征值与模态参数的关系:
λ r = e ( − σ r + i ω d r ) Δ t \lambda_r = e^{(-\sigma_r + i\omega_{dr})\Delta t} λr=e(−σr+iωdr)Δt
从中可以提取:
σ r = − ln ∣ λ r ∣ Δ t \sigma_r = -\frac{\ln|\lambda_r|}{\Delta t} σr=−Δtln∣λr∣
ω d r = arg ( λ r ) Δ t \omega_{dr} = \frac{\arg(\lambda_r)}{\Delta t} ωdr=Δtarg(λr)
ζ r = σ r σ r 2 + ω d r 2 \zeta_r = \frac{\sigma_r}{\sqrt{\sigma_r^2 + \omega_{dr}^2}} ζr=σr2+ωdr2σr
(5)从特征向量提取模态振型
优缺点:
- 优点:算法简单,计算效率高
- 缺点:对噪声敏感,需要准确确定模型阶数
4.2 特征系统实现算法(ERA)
ERA由Juang和Pappa于1985年提出,是目前应用最广泛的时域模态参数识别方法之一。
基本原理:
利用脉冲响应函数构造Hankel矩阵,通过奇异值分解(SVD)和特征值分解识别模态参数。
算法步骤:
(1)构造Hankel矩阵
对于 m m m个输出、 r r r个输入的系统,脉冲响应函数为 h ( k ) ∈ R m × r \mathbf{h}(k) \in \mathbb{R}^{m \times r} h(k)∈Rm×r。构造Hankel矩阵:
H ( k ) = [ h ( k ) h ( k + 1 ) ⋯ h ( k + β − 1 ) h ( k + 1 ) h ( k + 2 ) ⋯ h ( k + β ) ⋮ ⋮ ⋱ ⋮ h ( k + α − 1 ) h ( k + α ) ⋯ h ( k + α + β − 2 ) ] \mathbf{H}(k) = \begin{bmatrix} \mathbf{h}(k) & \mathbf{h}(k+1) & \cdots & \mathbf{h}(k+\beta-1) \\ \mathbf{h}(k+1) & \mathbf{h}(k+2) & \cdots & \mathbf{h}(k+\beta) \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{h}(k+\alpha-1) & \mathbf{h}(k+\alpha) & \cdots & \mathbf{h}(k+\alpha+\beta-2) \end{bmatrix} H(k)= h(k)h(k+1)⋮h(k+α−1)h(k+1)h(k+2)⋮h(k+α)⋯⋯⋱⋯h(k+β−1)h(k+β)⋮h(k+α+β−2)
其中 α \alpha α和 β \beta β为Hankel矩阵的行块数和列块数。
(2)SVD分解
H ( 0 ) = U Σ V T \mathbf{H}(0) = \mathbf{U}\mathbf{\Sigma}\mathbf{V}^T H(0)=UΣVT
其中 Σ = diag ( σ 1 , σ 2 , . . . , σ min ( α m , β r ) ) \mathbf{\Sigma} = \text{diag}(\sigma_1, \sigma_2, ..., \sigma_{\min(\alpha m, \beta r)}) Σ=diag(σ1,σ2,...,σmin(αm,βr))。
(3)确定系统阶数
根据奇异值的大小确定系统阶数 n n n。通常选择使 σ n / σ 1 > ϵ \sigma_n / \sigma_1 > \epsilon σn/σ1>ϵ(如 ϵ = 0.01 \epsilon = 0.01 ϵ=0.01)的阶数。
(4)构造系统矩阵
U n = U ( : , 1 : n ) , Σ n = Σ ( 1 : n , 1 : n ) , V n = V ( : , 1 : n ) \mathbf{U}_n = \mathbf{U}(:, 1:n), \quad \mathbf{\Sigma}_n = \mathbf{\Sigma}(1:n, 1:n), \quad \mathbf{V}_n = \mathbf{V}(:, 1:n) Un=U(:,1:n),Σn=Σ(1:n,1:n),Vn=V(:,1:n)
E m T = [ I m , 0 m , . . . , 0 m ] , E r T = [ I r , 0 r , . . . , 0 r ] \mathbf{E}_m^T = [\mathbf{I}_m, \mathbf{0}_m, ..., \mathbf{0}_m], \quad \mathbf{E}_r^T = [\mathbf{I}_r, \mathbf{0}_r, ..., \mathbf{0}_r] EmT=[Im,0m,...,0m],ErT=[Ir,0r,...,0r]
A = Σ n − 1 / 2 U n T H ( 1 ) V n Σ n − 1 / 2 \mathbf{A} = \mathbf{\Sigma}_n^{-1/2}\mathbf{U}_n^T\mathbf{H}(1)\mathbf{V}_n\mathbf{\Sigma}_n^{-1/2} A=Σn−1/2UnTH(1)VnΣn−1/2
B = Σ n 1 / 2 V n T E r \mathbf{B} = \mathbf{\Sigma}_n^{1/2}\mathbf{V}_n^T\mathbf{E}_r B=Σn1/2VnTEr
C = E m T U n Σ n 1 / 2 \mathbf{C} = \mathbf{E}_m^T\mathbf{U}_n\mathbf{\Sigma}_n^{1/2} C=EmTUnΣn1/2
(5)求解特征值问题
A ψ r = μ r ψ r \mathbf{A}\boldsymbol{\psi}_r = \mu_r\boldsymbol{\psi}_r Aψr=μrψr
离散时间特征值 μ r \mu_r μr与连续时间特征值的关系:
λ r = ln ( μ r ) Δ t \lambda_r = \frac{\ln(\mu_r)}{\Delta t} λr=Δtln(μr)
(6)提取模态参数
ω r = ∣ Im ( λ r ) ∣ \omega_r = |\text{Im}(\lambda_r)| ωr=∣Im(λr)∣
ζ r = − Re ( λ r ) ∣ λ r ∣ \zeta_r = -\frac{\text{Re}(\lambda_r)}{|\lambda_r|} ζr=−∣λr∣Re(λr)
ϕ r = C ψ r \boldsymbol{\phi}_r = \mathbf{C}\boldsymbol{\psi}_r ϕr=Cψr
优缺点:
- 优点:数值稳定性好,抗噪能力强,适用于MIMO系统
- 缺点:需要选择Hankel矩阵维数和系统阶数
4.3 随机子空间识别(SSI)
SSI是近年来发展迅速的时域模态参数识别方法,特别适用于环境激励下的模态参数识别。
基本原理:
利用输出数据的协方差矩阵构造Toeplitz矩阵,通过投影和SVD识别系统矩阵。
SSI-cov算法步骤:
(1)计算输出协方差矩阵
R i = E [ y k + i y k T ] \mathbf{R}_i = E[\mathbf{y}_{k+i}\mathbf{y}_k^T] Ri=E[yk+iykT]
(2)构造块Toeplitz矩阵
T 1 ∣ i = [ R 1 R 2 ⋯ R i R 2 R 3 ⋯ R i + 1 ⋮ ⋮ ⋱ ⋮ R i R i + 1 ⋯ R 2 i − 1 ] \mathbf{T}_{1|i} = \begin{bmatrix} \mathbf{R}_1 & \mathbf{R}_2 & \cdots & \mathbf{R}_i \\ \mathbf{R}_2 & \mathbf{R}_3 & \cdots & \mathbf{R}_{i+1} \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{R}_i & \mathbf{R}_{i+1} & \cdots & \mathbf{R}_{2i-1} \end{bmatrix} T1∣i= R1R2⋮RiR2R3⋮Ri+1⋯⋯⋱⋯RiRi+1⋮R2i−1
(3)SVD分解
T 1 ∣ i = U Σ V T \mathbf{T}_{1|i} = \mathbf{U}\mathbf{\Sigma}\mathbf{V}^T T1∣i=UΣVT
(4)确定系统阶数并构造观测矩阵
U n = U ( : , 1 : n ) , Σ n = Σ ( 1 : n , 1 : n ) \mathbf{U}_n = \mathbf{U}(:, 1:n), \quad \mathbf{\Sigma}_n = \mathbf{\Sigma}(1:n, 1:n) Un=U(:,1:n),Σn=Σ(1:n,1:n)
O n = U n Σ n 1 / 2 \mathbf{O}_n = \mathbf{U}_n\mathbf{\Sigma}_n^{1/2} On=UnΣn1/2
(5)提取系统矩阵
A = O n ( 1 : ( i − 1 ) m , : ) † O n ( m + 1 : i m , : ) \mathbf{A} = \mathbf{O}_n(1:(i-1)m, :)^{\dagger}\mathbf{O}_n(m+1:im, :) A=On(1:(i−1)m,:)†On(m+1:im,:)
C = O n ( 1 : m , : ) \mathbf{C} = \mathbf{O}_n(1:m, :) C=On(1:m,:)
(6)求解特征值问题并提取模态参数(同ERA)
稳定图:
SSI方法通常结合稳定图来确定真实的模态参数。稳定图的横轴为模型阶数,纵轴为频率,通过比较不同阶数下识别出的模态参数的一致性来判断真实模态。
稳定准则包括:
- 频率稳定: ∣ f ( i ) − f ( i − 1 ) ∣ / f ( i ) < ϵ f |f^{(i)} - f^{(i-1)}| / f^{(i)} < \epsilon_f ∣f(i)−f(i−1)∣/f(i)<ϵf
- 阻尼稳定: ∣ ζ ( i ) − ζ ( i − 1 ) ∣ / ζ ( i ) < ϵ ζ |\zeta^{(i)} - \zeta^{(i-1)}| / \zeta^{(i)} < \epsilon_\zeta ∣ζ(i)−ζ(i−1)∣/ζ(i)<ϵζ
- 振型稳定: 1 − MAC ( ϕ ( i ) , ϕ ( i − 1 ) ) < ϵ ϕ 1 - \text{MAC}(\boldsymbol{\phi}^{(i)}, \boldsymbol{\phi}^{(i-1)}) < \epsilon_\phi 1−MAC(ϕ(i),ϕ(i−1))<ϵϕ
频域模态参数识别方法
5.1 峰值拾取法(Peak Picking, PP)
峰值拾取法是最简单、最常用的频域模态参数识别方法。
基本原理:
在FRF的幅频曲线上,峰值对应的频率近似为固有频率。在峰值处,FRF主要由对应阶次的模态贡献。
算法步骤:
(1)识别固有频率
找到FRF幅值的局部极大值点:
ω r = arg max ω ∣ H j k ( ω ) ∣ \omega_r = \arg\max_{\omega}|H_{jk}(\omega)| ωr=argωmax∣Hjk(ω)∣
(2)估计阻尼比
采用半功率带宽法:
ζ r = ω a − ω b 2 ω r \zeta_r = \frac{\omega_a - \omega_b}{2\omega_r} ζr=2ωrωa−ωb
其中 ω a \omega_a ωa和 ω b \omega_b ωb为半功率点(幅值下降到峰值的KaTeX parse error: Expected 'EOF', got '}' at position 11: 1/\sqrt{2}}̲)。
(3)提取模态振型
在固有频率处,FRF矩阵的某一列(对应激励点)近似正比于模态振型:
ϕ r ∝ H ( : , k , ω r ) \boldsymbol{\phi}_r \propto \mathbf{H}(:, k, \omega_r) ϕr∝H(:,k,ωr)
优缺点:
- 优点:简单直观,无需假设模态密度
- 缺点:精度有限,不适用于密集模态和重频情况
5.2 频域分解法(FDD)
FDD是一种基于输出数据的频域模态参数识别方法,适用于运行模态分析。
基本原理:
对输出谱矩阵进行SVD分解,奇异值峰值对应的频率为固有频率,左奇异向量为模态振型。
算法步骤:
(1)估计功率谱密度矩阵
S y y ( ω ) = H ( ω ) S f f ( ω ) H H ( ω ) \mathbf{S}_{yy}(\omega) = \mathbf{H}(\omega)\mathbf{S}_{ff}(\omega)\mathbf{H}^H(\omega) Syy(ω)=H(ω)Sff(ω)HH(ω)
假设激励为白噪声, S f f ( ω ) = G \mathbf{S}_{ff}(\omega) = \mathbf{G} Sff(ω)=G为常数矩阵。
(2)SVD分解
在每个频率点进行SVD分解:
S y y ( ω ) = U ( ω ) Σ ( ω ) U H ( ω ) \mathbf{S}_{yy}(\omega) = \mathbf{U}(\omega)\mathbf{\Sigma}(\omega)\mathbf{U}^H(\omega) Syy(ω)=U(ω)Σ(ω)UH(ω)
其中 Σ ( ω ) = diag ( σ 1 ( ω ) , σ 2 ( ω ) , . . . , σ m ( ω ) ) \mathbf{\Sigma}(\omega) = \text{diag}(\sigma_1(\omega), \sigma_2(\omega), ..., \sigma_m(\omega)) Σ(ω)=diag(σ1(ω),σ2(ω),...,σm(ω))。
(3)识别固有频率
绘制奇异值曲线,峰值对应的频率为固有频率。
(4)提取模态振型
在固有频率处,第一左奇异向量对应模态振型:
ϕ r = u 1 ( ω r ) \boldsymbol{\phi}_r = \mathbf{u}_1(\omega_r) ϕr=u1(ωr)
(5)增强FDD(EFDD)估计阻尼比
通过逆傅里叶变换得到自相关函数,拟合指数衰减曲线估计阻尼比。
优缺点:
- 优点:适用于OMA,可分离密集模态
- 缺点:阻尼估计精度较低
5.3 最小二乘复频域法(LSCF)
LSCF是目前商业模态分析软件中最常用的识别方法之一,具有高精度和良好的抗噪能力。
基本原理:
将频响函数表示为有理分式形式,通过最小二乘拟合识别分子和分母多项式系数,进而提取模态参数。
右矩阵分式模型:
H ( ω ) = N ( ω ) D − 1 ( ω ) \mathbf{H}(\omega) = \mathbf{N}(\omega)\mathbf{D}^{-1}(\omega) H(ω)=N(ω)D−1(ω)
其中:
N ( ω ) = ∑ k = 0 p N k β k ( ω ) , D ( ω ) = ∑ k = 0 p D k β k ( ω ) \mathbf{N}(\omega) = \sum_{k=0}^{p}\mathbf{N}_k\beta_k(\omega), \quad \mathbf{D}(\omega) = \sum_{k=0}^{p}\mathbf{D}_k\beta_k(\omega) N(ω)=k=0∑pNkβk(ω),D(ω)=k=0∑pDkβk(ω)
β k ( ω ) \beta_k(\omega) βk(ω)为基函数,通常取 β k ( ω ) = ( i ω ) k \beta_k(\omega) = (i\omega)^k βk(ω)=(iω)k或正交多项式。
算法步骤:
(1)构造最小二乘问题
对于 n f n_f nf个频率点,建立线性方程组:
J θ = b \mathbf{J}\boldsymbol{\theta} = \mathbf{b} Jθ=b
其中 θ \boldsymbol{\theta} θ包含待识别的多项式系数矩阵 N k \mathbf{N}_k Nk和 D k \mathbf{D}_k Dk的元素。
(2)求解正规方程
θ = ( J H J ) − 1 J H b \boldsymbol{\theta} = (\mathbf{J}^H\mathbf{J})^{-1}\mathbf{J}^H\mathbf{b} θ=(JHJ)−1JHb
(3)求解特征值问题
构造伴随矩阵并求解特征值问题,得到极点(特征频率和阻尼比)。
(4)提取留数(模态振型)
利用已识别的极点,通过线性最小二乘求解留数矩阵。
多参考点LSCF(p-LSCF):
扩展LSCF到多参考点情况,提高识别精度和鲁棒性。
优缺点:
- 优点:精度高,抗噪能力强,适用于密集模态
- 缺点:计算复杂,需要选择适当的模型阶数
运行模态分析(OMA)
6.1 OMA的基本概念
运行模态分析(Operational Modal Analysis, OMA),也称为仅输出模态分析(Output-Only Modal Analysis),是在结构正常工作状态下进行模态参数识别的方法。
OMA的特点:
- 不需要测量激励力
- 利用环境激励(风、交通、海浪等)
- 激励假设为白噪声或宽带随机过程
- 适用于大型结构和现场测试
OMA的优势:
- 测试成本低,无需激振设备
- 真实工况下的模态参数
- 适用于难以施加人工激励的结构
- 可实现在线监测
OMA的局限性:
- 无法得到频响函数和模态质量
- 激励假设可能不成立
- 阻尼估计精度较低
- 难以识别刚体模态
6.2 OMA的基本假设
基本假设:
(1)激励假设:环境激励为白噪声或宽带随机过程
S f f ( ω ) = 常数 S_{ff}(\omega) = \text{常数} Sff(ω)=常数
(2)线性假设:结构响应是线性的
(3)平稳假设:激励和响应是平稳随机过程
(4)各态历经假设:时间平均等于集合平均
激励白噪声假设的验证:
- 检查输入谱的平坦性
- 检查响应谱的信噪比
- 使用不同时间段的数据进行验证
6.3 OMA的主要方法
(1)频域方法
- 峰值拾取法(PP)
- 频域分解法(FDD)
- 增强频域分解法(EFDD)
- 复模态指示函数法(CMIF)
(2)时域方法
- 随机子空间识别(SSI)
- SSI-cov(协方差驱动)
- SSI-data(数据驱动)
- 特征系统实现算法(ERA)
- 自回归滑动平均模型(ARMA)
(3)时频域方法
- 小波变换方法
- Hilbert-Huang变换
- 短时傅里叶变换
6.4 SSI在OMA中的应用
SSI是目前OMA中应用最广泛的方法。
SSI-cov算法在OMA中的应用:
(1)数据预处理
- 去均值
- 滤波(可选)
- 降采样(可选)
(2)计算输出协方差矩阵
R i = 1 N − i ∑ k = 1 N − i y k + i y k T \mathbf{R}_i = \frac{1}{N-i}\sum_{k=1}^{N-i}\mathbf{y}_{k+i}\mathbf{y}_k^T Ri=N−i1k=1∑N−iyk+iykT
(3)构造块Toeplitz矩阵并进行SVD
(4)确定系统阶数(使用稳定图)
(5)提取模态参数
稳定图的应用:
稳定图是确定真实模态的重要工具。通过比较不同模型阶数下的识别结果,筛选出稳定的模态参数。
结构损伤识别
7.1 基于模态参数变化的损伤识别
结构损伤会导致模态参数的变化,这是损伤识别的物理基础。
损伤对模态参数的影响:
(1)固有频率变化
- 刚度降低 → \rightarrow → 频率降低
- 质量变化 → \rightarrow → 频率变化
(2)模态振型变化
- 局部损伤导致振型局部变化
- 振型曲率对损伤更敏感
(3)阻尼变化
- 损伤可能增加能量耗散
- 阻尼变化通常较复杂
损伤识别指标:
(1)频率变化率
Δ f r = f r 损伤 − f r 完好 f r 完好 × 100 % \Delta f_r = \frac{f_r^{\text{损伤}} - f_r^{\text{完好}}}{f_r^{\text{完好}}} \times 100\% Δfr=fr完好fr损伤−fr完好×100%
(2)振型变化指标
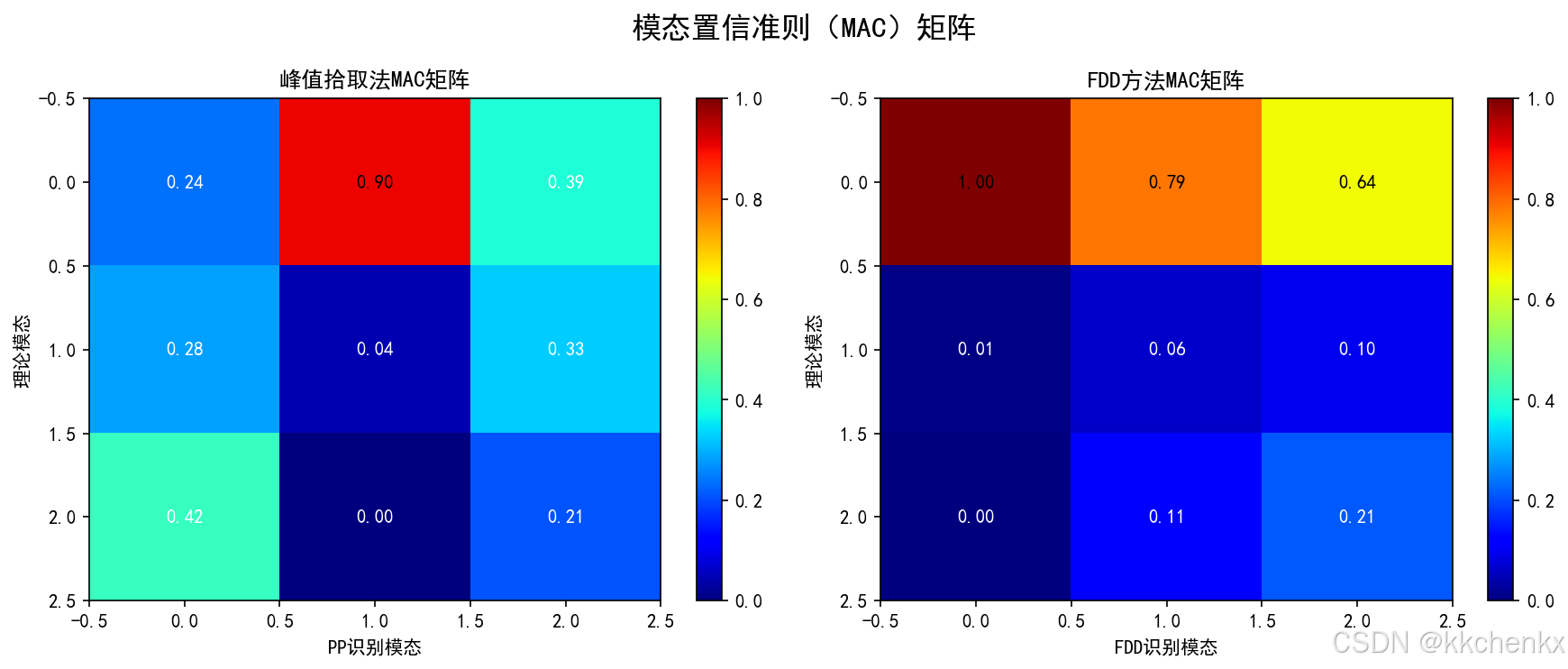
- 模态置信准则(MAC)
MAC r s = ∣ ϕ r H ψ s ∣ 2 ( ϕ r H ϕ r ) ( ψ s H ψ s ) \text{MAC}_{rs} = \frac{|\boldsymbol{\phi}_r^H\boldsymbol{\psi}_s|^2}{(\boldsymbol{\phi}_r^H\boldsymbol{\phi}_r)(\boldsymbol{\psi}_s^H\boldsymbol{\psi}_s)} MACrs=(ϕrHϕr)(ψsHψs)∣ϕrHψs∣2
- 坐标模态置信准则(COMAC)
COMAC j = ∣ ∑ r = 1 n ϕ j r ψ j r ∣ 2 ∑ r = 1 n ϕ j r 2 ⋅ ∑ r = 1 n ψ j r 2 \text{COMAC}_j = \frac{|\sum_{r=1}^{n}\phi_{jr}\psi_{jr}|^2}{\sum_{r=1}^{n}\phi_{jr}^2 \cdot \sum_{r=1}^{n}\psi_{jr}^2} COMACj=∑r=1nϕjr2⋅∑r=1nψjr2∣∑r=1nϕjrψjr∣2
(3)振型曲率变化
κ j = ϕ j − 1 − 2 ϕ j + ϕ j + 1 h 2 \kappa_j = \frac{\phi_{j-1} - 2\phi_j + \phi_{j+1}}{h^2} κj=h2ϕj−1−2ϕj+ϕj+1
振型曲率对局部损伤更敏感。
7.2 损伤定位方法
(1)基于振型变化的方法
- 模态振型差值法
- 振型曲率法
- 模态应变能法
(2)基于柔度矩阵的方法
柔度矩阵是刚度矩阵的逆:
G = K − 1 ≈ ∑ r = 1 n ϕ r ϕ r T ω r 2 \mathbf{G} = \mathbf{K}^{-1} \approx \sum_{r=1}^{n}\frac{\boldsymbol{\phi}_r\boldsymbol{\phi}_r^T}{\omega_r^2} G=K−1≈r=1∑nωr2ϕrϕrT
损伤定位向量(DLV)方法利用柔度矩阵的变化定位损伤。
(3)基于模型修正的方法
通过修正有限元模型的刚度参数来识别损伤:
min α ∥ f 实验 − f ( α ) ∥ 2 + λ ∥ W ( α − α 0 ) ∥ 2 \min_{\boldsymbol{\alpha}} \|\mathbf{f}^{\text{实验}} - \mathbf{f}(\boldsymbol{\alpha})\|^2 + \lambda\|\mathbf{W}(\boldsymbol{\alpha} - \boldsymbol{\alpha}_0)\|^2 αmin∥f实验−f(α)∥2+λ∥W(α−α0)∥2
其中 α \boldsymbol{\alpha} α为单元刚度修正系数。
7.3 损伤定量评估
(1)刚度折减系数
α i = k i 损伤 k i 完好 \alpha_i = \frac{k_i^{\text{损伤}}}{k_i^{\text{完好}}} αi=ki完好ki损伤
α i = 1 \alpha_i = 1 αi=1表示无损伤, α i = 0 \alpha_i = 0 αi=0表示完全失效。
(2)损伤程度指标
D i = 1 − α i D_i = 1 - \alpha_i Di=1−αi
D i = 0 D_i = 0 Di=0表示无损伤, D i = 1 D_i = 1 Di=1表示完全失效。
(3)基于频率灵敏度分析的定量方法
利用频率对刚度参数的灵敏度:
∂ ω r ∂ k i = ϕ r T ∂ K ∂ k i ϕ r 2 ω r \frac{\partial\omega_r}{\partial k_i} = \frac{\boldsymbol{\phi}_r^T\frac{\partial\mathbf{K}}{\partial k_i}\boldsymbol{\phi}_r}{2\omega_r} ∂ki∂ωr=2ωrϕrT∂ki∂Kϕr
建立灵敏度矩阵,通过反问题求解损伤程度。
案例研究
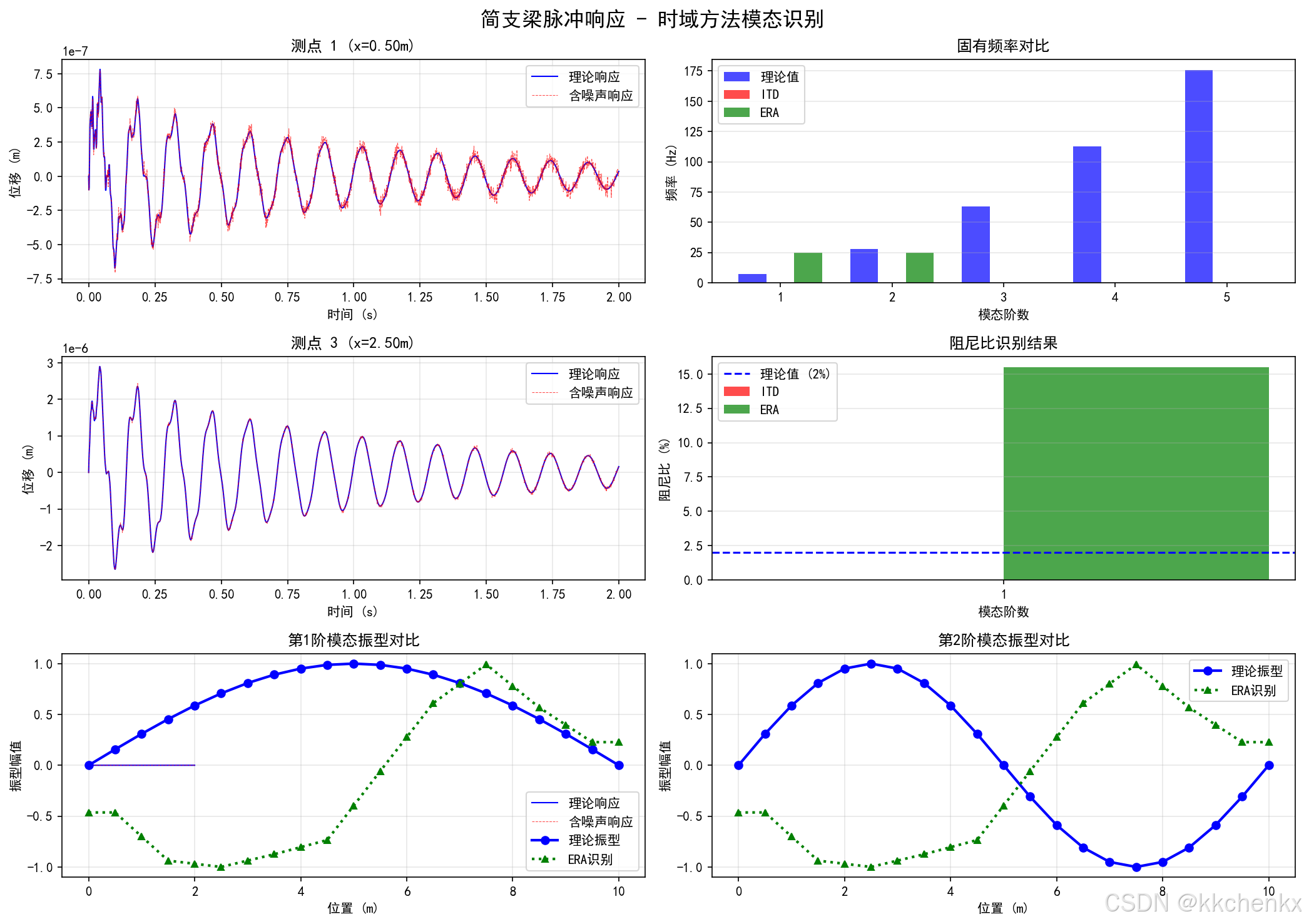
案例1:简支梁模态参数识别(时域方法)
问题描述:
对一个简支梁进行锤击试验,获得各测点的加速度响应数据。使用时域方法(ITD和ERA)识别梁的模态参数。
理论背景:
简支梁的固有频率理论解:
f n = n 2 π 2 L 2 E I ρ A f_n = \frac{n^2\pi}{2L^2}\sqrt{\frac{EI}{\rho A}} fn=2L2n2πρAEI
其中 L L L为梁长, E I EI EI为抗弯刚度, ρ \rho ρ为密度, A A A为截面积。
Python实现:
结果分析:
- 识别出的固有频率与理论值对比
- 模态振型的可视化
- ITD与ERA方法的比较
- 噪声对识别精度的影响
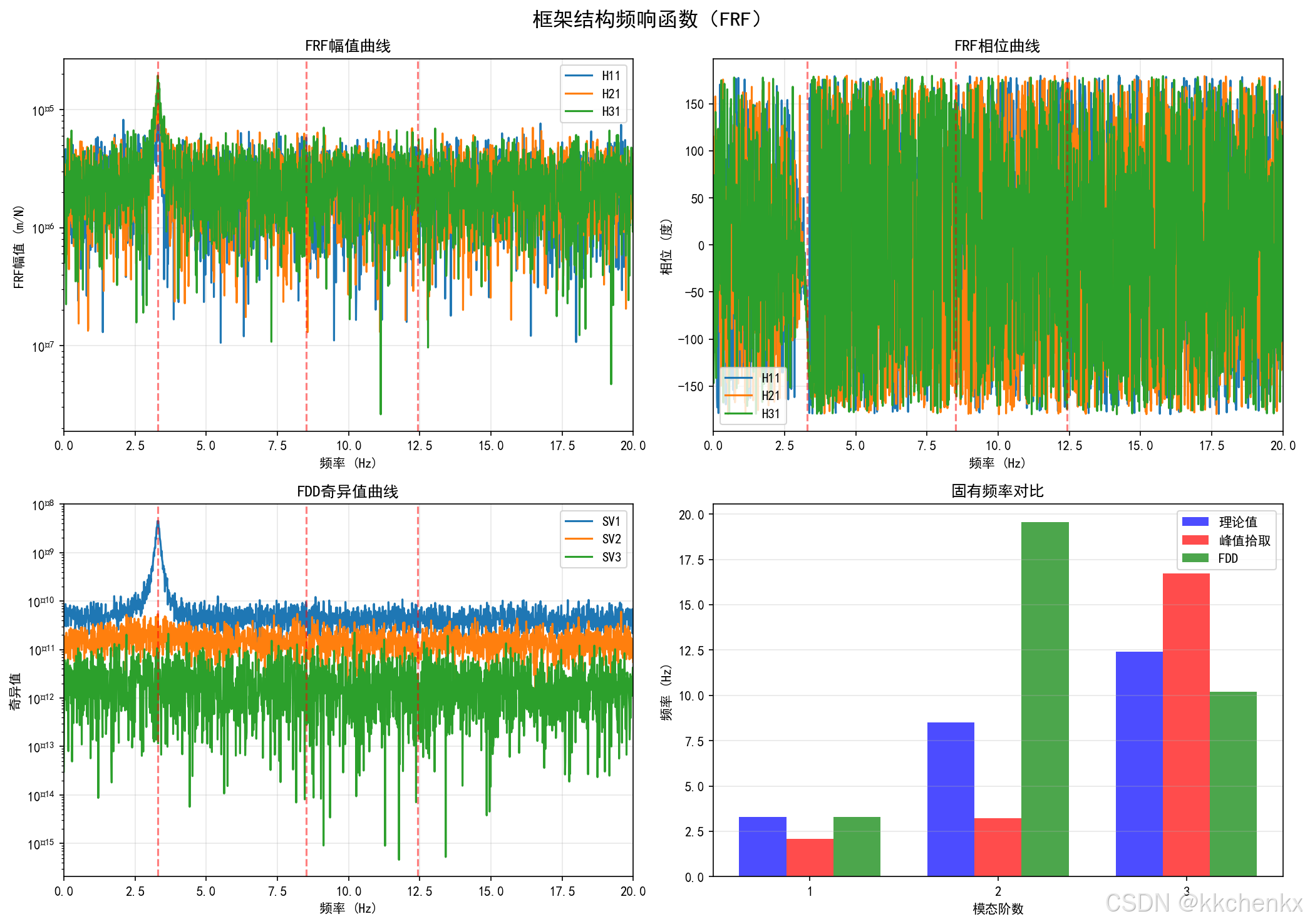
案例2:框架结构模态参数识别(频域方法)
问题描述:
对一个多层框架结构进行正弦扫频试验,测量各层的加速度响应。使用频域方法(PP、FDD、LSCF)识别结构的模态参数。
理论背景:
多自由度系统的频响函数:
H j k ( ω ) = ∑ r = 1 n ϕ j r ϕ k r m r ( ω r 2 − ω 2 + i 2 ζ r ω r ω ) H_{jk}(\omega) = \sum_{r=1}^{n}\frac{\phi_{jr}\phi_{kr}}{m_r(\omega_r^2 - \omega^2 + i2\zeta_r\omega_r\omega)} Hjk(ω)=r=1∑nmr(ωr2−ω2+i2ζrωrω)ϕjrϕkr
Python实现:
详见 case2_frequency_domain_modal.py
结果分析:
- 频响函数的可视化
- 不同频域方法的比较
- 稳定图的应用
- 密集模态的分离
案例3:桥梁结构运行模态分析
问题描述:
对一座桥梁在交通荷载作用下进行振动测试,仅测量响应数据。使用SSI方法识别桥梁的模态参数。
理论背景:
环境激励下的响应谱:
S y y ( ω ) = H ( ω ) G H H ( ω ) \mathbf{S}_{yy}(\omega) = \mathbf{H}(\omega)\mathbf{G}\mathbf{H}^H(\omega) Syy(ω)=H(ω)GHH(ω)
Python实现:
详见 case3_operational_modal_analysis.py
结果分析:
- 响应数据的预处理
- 稳定图的绘制与分析
- 识别结果的不确定性评估
- 与有限元结果的对比
案例4:结构损伤识别与状态评估
问题描述:
对一个悬臂梁在完好和多种损伤状态下进行模态分析,利用模态参数的变化识别损伤位置、程度和评估结构状态。本案例模拟了四种损伤工况:根部损伤、中部损伤、端部损伤和多处损伤。
理论背景:
1. 固有频率变化损伤指标
损伤会导致结构刚度降低,从而引起固有频率下降。频率变化率定义为:
D I f = f 完好 − f 损伤 f 完好 × 100 % DI_f = \frac{f_{\text{完好}} - f_{\text{损伤}}}{f_{\text{完好}}} \times 100\% DIf=f完好f完好−f损伤×100%
频率变化率与损伤程度和位置有关。一般而言,损伤越严重,频率下降越多;损伤位置对低阶模态影响更大。
2. 模态置信准则(MAC)
MAC用于评估损伤前后模态振型的相似性:
MAC i j = ∣ ϕ i 完好 T ϕ j 损伤 ∣ 2 ( ϕ i 完好 T ϕ i 完好 ) ( ϕ j 损伤 T ϕ j 损伤 ) \text{MAC}_{ij} = \frac{|\boldsymbol{\phi}_i^{\text{完好}T} \boldsymbol{\phi}_j^{\text{损伤}}|^2}{(\boldsymbol{\phi}_i^{\text{完好}T}\boldsymbol{\phi}_i^{\text{完好}})(\boldsymbol{\phi}_j^{\text{损伤}T}\boldsymbol{\phi}_j^{\text{损伤}})} MACij=(ϕi完好Tϕi完好)(ϕj损伤Tϕj损伤)∣ϕi完好Tϕj损伤∣2
MAC值接近1表示振型相似,MAC值降低表示振型发生变化。
3. 模态振型变化指标(MSC)
MSC r = 1 n ∑ j = 1 n ( ϕ j r 完好 max ∣ ϕ r 完好 ∣ − ϕ j r 损伤 max ∣ ϕ r 损伤 ∣ ) 2 \text{MSC}_r = \sqrt{\frac{1}{n}\sum_{j=1}^{n}\left(\frac{\phi_{jr}^{\text{完好}}}{\max|\boldsymbol{\phi}_r^{\text{完好}}|} - \frac{\phi_{jr}^{\text{损伤}}}{\max|\boldsymbol{\phi}_r^{\text{损伤}}|}\right)^2} MSCr=n1j=1∑n(max∣ϕr完好∣ϕjr完好−max∣ϕr损伤∣ϕjr损伤)2
MSC值越大,表示第r阶模态振型变化越显著。
4. 模态应变能损伤指标(MSE-DI)
模态应变能反映了结构在振动过程中储存的弹性势能:
M S E e r = 1 2 ϕ e r T K e ϕ e r MSE_{er} = \frac{1}{2}\boldsymbol{\phi}_{er}^T \mathbf{K}_e \boldsymbol{\phi}_{er} MSEer=21ϕerTKeϕer
其中 ϕ e r \boldsymbol{\phi}_{er} ϕer为第e个单元的第r阶模态振型, K e \mathbf{K}_e Ke为单元刚度矩阵。
基于模态应变能变化的损伤指标:
D I e = 1 n ∑ r = 1 n ( 1 − M S E e r 损伤 M S E e r 完好 ) 2 DI_e = \sqrt{\frac{1}{n}\sum_{r=1}^{n}\left(1 - \frac{MSE_{er}^{\text{损伤}}}{MSE_{er}^{\text{完好}}}\right)^2} DIe=n1r=1∑n(1−MSEer完好MSEer损伤)2
MSE-DI在损伤单元处会出现明显的峰值,可用于损伤定位。
Python实现:
详见 case4_damage_identification.py
关键代码:
"""
计算电磁学并行计算仿真
Parallel Computing for Computational Electromagnetics
"""
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from multiprocessing import Pool, cpu_count
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.switch_backend('Agg')
print("=" * 60)
print("计算电磁学并行计算仿真")
print("=" * 60)
# =============================================================================
# 第一部分:串行基准测试
# =============================================================================
def serial_matrix_multiply(A, B):
"""串行矩阵乘法"""
n = A.shape[0]
C = np.zeros((n, n))
for i in range(n):
for j in range(n):
for k in range(n):
C[i, j] += A[i, k] * B[k, j]
return C
def serial_fdtd_2d(nx, ny, n_steps):
"""串行2D FDTD"""
Ez = np.zeros((nx, ny))
Hx = np.zeros((nx, ny))
Hy = np.zeros((nx, ny))
# 源位置
source_x, source_y = nx // 2, ny // 2
for n in range(n_steps):
# 更新H场
for i in range(nx-1):
for j in range(ny-1):
Hx[i, j] += 0.5 * (Ez[i, j+1] - Ez[i, j])
Hy[i, j] -= 0.5 * (Ez[i+1, j] - Ez[i, j])
# 更新E场
for i in range(1, nx-1):
for j in range(1, ny-1):
Ez[i, j] += 0.5 * (Hy[i, j] - Hy[i-1, j]
- Hx[i, j] + Hx[i, j-1])
# 添加源
Ez[source_x, source_y] += np.sin(0.1 * n)
return Ez
# =============================================================================
# 第二部分:多线程并行
# =============================================================================
def threaded_fdtd_2d(nx, ny, n_steps, n_threads=4):
"""多线程2D FDTD"""
from threading import Thread
Ez = np.zeros((nx, ny))
Hx = np.zeros((nx, ny))
Hy = np.zeros((nx, ny))
source_x, source_y = nx // 2, ny // 2
def update_h_chunk(start_row, end_row):
for i in range(start_row, min(end_row, nx-1)):
for j in range(ny-1):
Hx[i, j] += 0.5 * (Ez[i, j+1] - Ez[i, j])
Hy[i, j] -= 0.5 * (Ez[i+1, j] - Ez[i, j])
def update_e_chunk(start_row, end_row):
for i in range(max(1, start_row), min(end_row, nx-1)):
for j in range(1, ny-1):
Ez[i, j] += 0.5 * (Hy[i, j] - Hy[i-1, j]
- Hx[i, j] + Hx[i, j-1])
rows_per_thread = nx // n_threads
for n in range(n_steps):
# 更新H场(并行)
threads = []
for t in range(n_threads):
start = t * rows_per_thread
end = start + rows_per_thread
thread = Thread(target=update_h_chunk, args=(start, end))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
# 更新E场(并行)
threads = []
for t in range(n_threads):
start = t * rows_per_thread
end = start + rows_per_thread
thread = Thread(target=update_e_chunk, args=(start, end))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
Ez[source_x, source_y] += np.sin(0.1 * n)
return Ez
# =============================================================================
# 第三部分:多进程并行
# =============================================================================
# 工作函数需要在模块级别定义以便pickle
def _mc_worker(n_local):
"""蒙特卡洛工作函数"""
np.random.seed()
count = 0
for _ in range(n_local):
x, y = np.random.rand(2)
if x**2 + y**2 <= 1:
count += 1
return count
def _compute_at_freq(freq):
"""频率计算工作函数"""
# 模拟电磁仿真计算
# 实际应用中会调用求解器
omega = 2 * np.pi * freq
# 简化的S参数计算
s11 = 1 / (1 + 1j * omega)
s21 = 1j * omega / (1 + 1j * omega)
return freq, s11, s21
def _compute_rcs_at_angle(angle):
"""RCS计算工作函数"""
# 模拟RCS计算
# 实际应用中会调用MoM/FDTD求解器
theta_rad = np.deg2rad(angle)
# 简化的RCS模型(球体)
rcs = 10 * np.log10(1 + np.cos(theta_rad)**2)
return angle, rcs
def parallel_monte_carlo(n_samples, n_processes=None):
"""并行蒙特卡洛仿真"""
if n_processes is None:
n_processes = cpu_count()
samples_per_process = n_samples // n_processes
with Pool(processes=n_processes) as pool:
results = pool.map(_mc_worker, [samples_per_process] * n_processes)
total_inside = sum(results)
pi_estimate = 4 * total_inside / n_samples
return pi_estimate
def parallel_frequency_sweep(frequencies, n_processes=None):
"""并行频率扫描"""
if n_processes is None:
n_processes = cpu_count()
with Pool(processes=n_processes) as pool:
results = pool.map(_compute_at_freq, frequencies)
return results
def parallel_rcs_computation(angles, n_processes=None):
"""并行RCS计算"""
if n_processes is None:
n_processes = cpu_count()
with Pool(processes=n_processes) as pool:
results = pool.map(_compute_rcs_at_angle, angles)
return results
# =============================================================================
# 第四部分:向量化加速
# =============================================================================
def vectorized_fdtd_2d(nx, ny, n_steps):
"""向量化2D FDTD"""
Ez = np.zeros((nx, ny))
Hx = np.zeros((nx, ny))
Hy = np.zeros((nx, ny))
source_x, source_y = nx // 2, ny // 2
for n in range(n_steps):
# 向量化更新H场
Hx[:-1, :-1] += 0.5 * (Ez[:-1, 1:] - Ez[:-1, :-1])
Hy[:-1, :-1] -= 0.5 * (Ez[1:, :-1] - Ez[:-1, :-1])
# 向量化更新E场
Ez[1:-1, 1:-1] += 0.5 * (Hy[1:-1, 1:-1] - Hy[:-2, 1:-1]
- Hx[1:-1, 1:-1] + Hx[1:-1, :-2])
# 添加源
Ez[source_x, source_y] += np.sin(0.1 * n)
return Ez
def numba_accelerated_fdtd(nx, ny, n_steps):
"""Numba加速FDTD"""
try:
from numba import jit, prange
@jit(nopython=True, parallel=True)
def fdtd_kernel(Ez, Hx, Hy, nx, ny, n_steps):
source_x, source_y = nx // 2, ny // 2
for n in range(n_steps):
# 并行更新H场
for i in prange(nx-1):
for j in range(ny-1):
Hx[i, j] += 0.5 * (Ez[i, j+1] - Ez[i, j])
Hy[i, j] -= 0.5 * (Ez[i+1, j] - Ez[i, j])
# 并行更新E场
for i in prange(1, nx-1):
for j in range(1, ny-1):
Ez[i, j] += 0.5 * (Hy[i, j] - Hy[i-1, j]
- Hx[i, j] + Hx[i, j-1])
Ez[source_x, source_y] += np.sin(0.1 * n)
return Ez
Ez = np.zeros((nx, ny))
Hx = np.zeros((nx, ny))
Hy = np.zeros((nx, ny))
return fdtd_kernel(Ez, Hx, Hy, nx, ny, n_steps)
except ImportError:
print("Numba not available, using vectorized version")
return vectorized_fdtd_2d(nx, ny, n_steps)
# =============================================================================
# 第五部分:性能测试与可视化
# =============================================================================
def benchmark_parallel_computing():
"""并行计算性能测试"""
print("\n[1/5] 并行计算性能基准测试...")
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
# 1. 蒙特卡洛并行加速比
n_samples_list = [10000, 50000, 100000, 500000, 1000000]
n_processes_list = [1, 2, 4, 8]
speedups_mc = {n: [] for n in n_processes_list}
for n_samples in n_samples_list:
# 串行时间
start = time.time()
pi_serial = parallel_monte_carlo(n_samples, 1)
time_serial = time.time() - start
for n_proc in n_processes_list:
start = time.time()
pi_parallel = parallel_monte_carlo(n_samples, n_proc)
time_parallel = time.time() - start
speedup = time_serial / time_parallel
speedups_mc[n_proc].append(speedup)
for n_proc, speedups in speedups_mc.items():
axes[0, 0].plot(n_samples_list, speedups, marker='o',
linewidth=2, label=f'{n_proc}进程')
axes[0, 0].axhline(y=1, color='k', linestyle='--', alpha=0.5)
axes[0, 0].set_xlabel('样本数', fontsize=11)
axes[0, 0].set_ylabel('加速比', fontsize=11)
axes[0, 0].set_title('蒙特卡洛并行加速比', fontsize=12)
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
axes[0, 0].set_xscale('log')
# 2. FDTD不同实现性能比较
grid_sizes = [50, 100, 200, 400]
n_steps = 100
times_serial = []
times_vectorized = []
for nx in grid_sizes:
ny = nx
# 串行
start = time.time()
Ez_serial = serial_fdtd_2d(nx, ny, n_steps)
times_serial.append(time.time() - start)
# 向量化
start = time.time()
Ez_vectorized = vectorized_fdtd_2d(nx, ny, n_steps)
times_vectorized.append(time.time() - start)
axes[0, 1].plot(grid_sizes, times_serial, 'b-o', linewidth=2, label='串行')
axes[0, 1].plot(grid_sizes, times_vectorized, 'r-s', linewidth=2, label='向量化')
axes[0, 1].set_xlabel('网格尺寸', fontsize=11)
axes[0, 1].set_ylabel('时间 (秒)', fontsize=11)
axes[0, 1].set_title('FDTD性能比较', fontsize=12)
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 3. 频率扫描并行效率
n_freqs_list = [10, 20, 50, 100, 200]
n_processes_list = [1, 2, 4, 8]
efficiencies = {n: [] for n in n_processes_list}
for n_freqs in n_freqs_list:
frequencies = np.linspace(1e9, 10e9, n_freqs)
# 串行时间
start = time.time()
results_serial = parallel_frequency_sweep(frequencies, 1)
time_serial = time.time() - start
for n_proc in n_processes_list:
start = time.time()
results_parallel = parallel_frequency_sweep(frequencies, n_proc)
time_parallel = time.time() - start
speedup = time_serial / time_parallel
efficiency = speedup / n_proc
efficiencies[n_proc].append(efficiency)
for n_proc, effs in efficiencies.items():
axes[0, 2].plot(n_freqs_list, effs, marker='o',
linewidth=2, label=f'{n_proc}进程')
axes[0, 2].axhline(y=1, color='k', linestyle='--', alpha=0.5, label='理想')
axes[0, 2].set_xlabel('频率点数', fontsize=11)
axes[0, 2].set_ylabel('并行效率', fontsize=11)
axes[0, 2].set_title('频率扫描并行效率', fontsize=12)
axes[0, 2].legend()
axes[0, 2].grid(True, alpha=0.3)
# 4. RCS并行计算时间
angles = np.linspace(0, 360, 361)
n_processes_list = [1, 2, 4, 8, 16]
times_rcs = []
for n_proc in n_processes_list:
start = time.time()
results = parallel_rcs_computation(angles, n_proc)
times_rcs.append(time.time() - start)
axes[1, 0].bar(range(len(n_processes_list)), times_rcs,
color='steelblue', alpha=0.8)
axes[1, 0].set_xticks(range(len(n_processes_list)))
axes[1, 0].set_xticklabels([f'{n}' for n in n_processes_list])
axes[1, 0].set_xlabel('进程数', fontsize=11)
axes[1, 0].set_ylabel('计算时间 (秒)', fontsize=11)
axes[1, 0].set_title('RCS并行计算时间', fontsize=12)
axes[1, 0].grid(True, alpha=0.3, axis='y')
# 5. 理想vs实际加速比
n_processes = np.arange(1, 17)
# 阿姆达尔定律(90%可并行)
f = 0.9
amdahl_speedup = 1 / ((1-f) + f/n_processes)
# 古斯塔夫森定律
gustafson_speedup = n_processes - f*(n_processes-1)
# 线性加速
linear_speedup = n_processes
axes[1, 1].plot(n_processes, linear_speedup, 'k--',
linewidth=2, label='线性加速')
axes[1, 1].plot(n_processes, amdahl_speedup, 'b-',
linewidth=2, label=f'阿姆达尔 (f={f})')
axes[1, 1].plot(n_processes, gustafson_speedup, 'r-',
linewidth=2, label=f'古斯塔夫森 (f={f})')
axes[1, 1].set_xlabel('处理器数', fontsize=11)
axes[1, 1].set_ylabel('加速比', fontsize=11)
axes[1, 1].set_title('理论加速比模型', fontsize=12)
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
# 6. 负载均衡可视化
n_tasks = 100
n_workers = 4
# 模拟不同负载分配策略
# 静态分配
static_load = [n_tasks // n_workers] * n_workers
# 动态分配(假设任务耗时不同)
np.random.seed(42)
task_times = np.random.exponential(1, n_tasks)
dynamic_load = [sum(task_times[i::n_workers]) for i in range(n_workers)]
x = np.arange(n_workers)
width = 0.35
axes[1, 2].bar(x - width/2, static_load, width,
label='静态分配', color='lightblue')
axes[1, 2].bar(x + width/2, dynamic_load, width,
label='动态分配', color='lightcoral')
axes[1, 2].set_xlabel('工作进程', fontsize=11)
axes[1, 2].set_ylabel('工作量', fontsize=11)
axes[1, 2].set_title('负载均衡比较', fontsize=12)
axes[1, 2].set_xticks(x)
axes[1, 2].set_xticklabels([f'P{i+1}' for i in range(n_workers)])
axes[1, 2].legend()
axes[1, 2].grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('parallel_performance.png', dpi=150, bbox_inches='tight')
plt.close()
print(" 已保存: parallel_performance.png")
def visualize_domain_decomposition():
"""可视化域分解"""
print("\n[2/5] 生成域分解可视化...")
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
# 1. 一维域分解
ax1 = axes[0, 0]
nx, ny = 100, 20
n_procs = 4
domain = np.zeros((ny, nx))
colors = ['red', 'blue', 'green', 'orange']
for p in range(n_procs):
start = p * (nx // n_procs)
end = (p + 1) * (nx // n_procs)
domain[:, start:end] = p + 1
im1 = ax1.imshow(domain, cmap='tab10', aspect='auto')
ax1.set_title('一维域分解 (4进程)', fontsize=12)
ax1.set_xlabel('X网格', fontsize=10)
ax1.set_ylabel('Y网格', fontsize=10)
# 添加边界标注
for p in range(n_procs):
x_pos = p * (nx // n_procs) + (nx // n_procs) // 2
ax1.text(x_pos, ny//2, f'P{p}', ha='center', va='center',
fontsize=12, fontweight='bold', color='white')
# 2. 二维域分解
ax2 = axes[0, 1]
nx, ny = 40, 40
px, py = 2, 2
domain2d = np.zeros((ny, nx))
for i in range(py):
for j in range(px):
p = i * px + j
x_start = j * (nx // px)
x_end = (j + 1) * (nx // px)
y_start = i * (ny // py)
y_end = (i + 1) * (ny // py)
domain2d[y_start:y_end, x_start:x_end] = p + 1
im2 = ax2.imshow(domain2d, cmap='tab10', aspect='equal')
ax2.set_title('二维域分解 (2×2)', fontsize=12)
ax2.set_xlabel('X网格', fontsize=10)
ax2.set_ylabel('Y网格', fontsize=10)
# 3. 通信模式
ax3 = axes[0, 2]
# 绘制进程拓扑
positions = [(0.25, 0.25), (0.75, 0.25), (0.25, 0.75), (0.75, 0.75)]
for i, (x, y) in enumerate(positions):
circle = plt.Circle((x, y), 0.1, color=colors[i], alpha=0.7)
ax3.add_patch(circle)
ax3.text(x, y, f'P{i}', ha='center', va='center',
fontsize=10, fontweight='bold')
# 绘制通信连接
for i in range(len(positions)):
for j in range(i+1, len(positions)):
x1, y1 = positions[i]
x2, y2 = positions[j]
ax3.plot([x1, x2], [y1, y2], 'k--', alpha=0.3, linewidth=1)
ax3.set_xlim(0, 1)
ax3.set_ylim(0, 1)
ax3.set_aspect('equal')
ax3.axis('off')
ax3.set_title('进程通信拓扑', fontsize=12)
# 4. 负载分布热图
ax4 = axes[1, 0]
# 模拟非均匀负载
np.random.seed(42)
load = np.random.rand(20, 20)
# 添加热点
load[5:8, 5:8] *= 3
load[15:18, 12:15] *= 2.5
im4 = ax4.imshow(load, cmap='hot', aspect='auto')
ax4.set_title('非均匀负载分布', fontsize=12)
ax4.set_xlabel('X', fontsize=10)
ax4.set_ylabel('Y', fontsize=10)
plt.colorbar(im4, ax=ax4, label='计算强度')
# 5. 任务队列可视化
ax5 = axes[1, 1]
n_tasks = 50
task_sizes = np.random.exponential(1, n_tasks)
task_sizes = task_sizes / task_sizes.max()
y_positions = np.arange(n_tasks)
ax5.barh(y_positions, task_sizes, color='steelblue', alpha=0.7)
ax5.set_xlabel('任务大小', fontsize=10)
ax5.set_ylabel('任务ID', fontsize=10)
ax5.set_title('动态任务队列', fontsize=12)
ax5.grid(True, alpha=0.3, axis='x')
# 6. 加速比曲线
ax6 = axes[1, 2]
# 实测加速比
n_procs_test = [1, 2, 4, 8]
# 模拟数据
speedup_measured = [1, 1.9, 3.5, 6.2]
ax6.plot(n_procs_test, speedup_measured, 'b-o',
linewidth=2.5, markersize=8, label='实测')
ax6.plot([1, 8], [1, 8], 'k--', linewidth=1.5, label='理想线性')
ax6.set_xlabel('处理器数', fontsize=11)
ax6.set_ylabel('加速比', fontsize=11)
ax6.set_title('并行加速比', fontsize=12)
ax6.legend()
ax6.grid(True, alpha=0.3)
ax6.set_xlim(0.5, 8.5)
ax6.set_ylim(0, 9)
plt.tight_layout()
plt.savefig('domain_decomposition.png', dpi=150, bbox_inches='tight')
plt.close()
print(" 已保存: domain_decomposition.png")
def visualize_memory_architecture():
"""可视化内存架构"""
print("\n[3/5] 生成内存架构可视化...")
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
# 1. 共享内存架构
ax1 = axes[0, 0]
# 绘制CPU核心
for i in range(4):
rect = plt.Rectangle((0.1 + i*0.22, 0.6), 0.15, 0.25,
fill=True, facecolor='lightblue',
edgecolor='blue', linewidth=2)
ax1.add_patch(rect)
ax1.text(0.175 + i*0.22, 0.725, f'CPU{i+1}',
ha='center', va='center', fontsize=9, fontweight='bold')
# 绘制共享内存
rect_mem = plt.Rectangle((0.1, 0.15), 0.8, 0.3,
fill=True, facecolor='lightyellow',
edgecolor='orange', linewidth=2)
ax1.add_patch(rect_mem)
ax1.text(0.5, 0.3, '共享内存', ha='center', va='center',
fontsize=11, fontweight='bold')
# 连接线
for i in range(4):
ax1.plot([0.175 + i*0.22, 0.175 + i*0.22], [0.6, 0.45],
'k-', linewidth=2)
ax1.set_xlim(0, 1)
ax1.set_ylim(0, 1)
ax1.axis('off')
ax1.set_title('共享内存架构', fontsize=12)
# 2. 分布式内存架构
ax2 = axes[0, 1]
positions = [(0.2, 0.7), (0.8, 0.7), (0.2, 0.3), (0.8, 0.3)]
for i, (x, y) in enumerate(positions):
# CPU
rect_cpu = plt.Rectangle((x-0.08, y+0.05), 0.16, 0.15,
fill=True, facecolor='lightblue',
edgecolor='blue', linewidth=2)
ax2.add_patch(rect_cpu)
ax2.text(x, y+0.125, f'CPU{i+1}', ha='center', va='center',
fontsize=8, fontweight='bold')
# 本地内存
rect_mem = plt.Rectangle((x-0.08, y-0.15), 0.16, 0.15,
fill=True, facecolor='lightyellow',
edgecolor='orange', linewidth=2)
ax2.add_patch(rect_mem)
ax2.text(x, y-0.075, f'Mem{i+1}', ha='center', va='center',
fontsize=8, fontweight='bold')
# 连接
ax2.plot([x, x], [y-0.15, y+0.05], 'k-', linewidth=2)
# 网络连接
for i in range(len(positions)):
for j in range(i+1, len(positions)):
x1, y1 = positions[i]
x2, y2 = positions[j]
ax2.plot([x1, x2], [y1, y2], 'r--', alpha=0.3, linewidth=1)
ax2.set_xlim(0, 1)
ax2.set_ylim(0, 1)
ax2.axis('off')
ax2.set_title('分布式内存架构', fontsize=12)
# 3. 混合内存架构
ax3 = axes[0, 2]
# 节点1
rect_node1 = plt.Rectangle((0.05, 0.5), 0.4, 0.45,
fill=True, facecolor='lightgray',
edgecolor='black', linewidth=2)
ax3.add_patch(rect_node1)
ax3.text(0.25, 0.9, '节点1', ha='center', fontsize=10, fontweight='bold')
# 节点1的CPU
for i in range(2):
for j in range(2):
rect_cpu = plt.Rectangle((0.1 + j*0.15, 0.7 - i*0.15), 0.1, 0.1,
fill=True, facecolor='lightblue',
edgecolor='blue', linewidth=1)
ax3.add_patch(rect_cpu)
# 节点2
rect_node2 = plt.Rectangle((0.55, 0.5), 0.4, 0.45,
fill=True, facecolor='lightgray',
edgecolor='black', linewidth=2)
ax3.add_patch(rect_node2)
ax3.text(0.75, 0.9, '节点2', ha='center', fontsize=10, fontweight='bold')
# 节点2的CPU
for i in range(2):
for j in range(2):
rect_cpu = plt.Rectangle((0.6 + j*0.15, 0.7 - i*0.15), 0.1, 0.1,
fill=True, facecolor='lightblue',
edgecolor='blue', linewidth=1)
ax3.add_patch(rect_cpu)
# 网络连接
ax3.annotate('', xy=(0.55, 0.725), xytext=(0.45, 0.725),
arrowprops=dict(arrowstyle='<->', color='red', lw=2))
ax3.text(0.5, 0.8, '网络', ha='center', fontsize=9, color='red')
ax3.set_xlim(0, 1)
ax3.set_ylim(0, 1)
ax3.axis('off')
ax3.set_title('混合内存架构', fontsize=12)
# 4. 缓存层次结构
ax4 = axes[1, 0]
levels = ['寄存器', 'L1缓存', 'L2缓存', 'L3缓存', '主存']
sizes = [1, 32, 256, 8192, 8192000] # KB
latencies = [1, 4, 10, 40, 100] # 周期
# 使用对数坐标
x_pos = np.arange(len(levels))
bars = ax4.bar(x_pos, np.log10(sizes), color='steelblue', alpha=0.8)
ax4.set_xticks(x_pos)
ax4.set_xticklabels(levels, rotation=15)
ax4.set_ylabel('存储容量 (log10 KB)', fontsize=11)
ax4.set_title('存储层次结构', fontsize=12)
ax4.grid(True, alpha=0.3, axis='y')
# 5. NUMA架构
ax5 = axes[1, 1]
# 绘制NUMA节点
numa_positions = [(0.25, 0.75), (0.75, 0.75), (0.25, 0.25), (0.75, 0.25)]
numa_colors = ['lightcoral', 'lightblue', 'lightgreen', 'lightyellow']
for i, ((x, y), color) in enumerate(zip(numa_positions, numa_colors)):
# NUMA节点
rect = plt.Rectangle((x-0.15, y-0.15), 0.3, 0.3,
fill=True, facecolor=color,
edgecolor='black', linewidth=2)
ax5.add_patch(rect)
ax5.text(x, y+0.1, f'NUMA{i+1}', ha='center', fontsize=9, fontweight='bold')
# 本地内存
rect_mem = plt.Rectangle((x-0.1, y-0.08), 0.2, 0.12,
fill=True, facecolor='white',
edgecolor='black', linewidth=1)
ax5.add_patch(rect_mem)
ax5.text(x, y-0.02, '本地内存', ha='center', fontsize=7)
# 互连网络
for i in range(len(numa_positions)):
for j in range(i+1, len(numa_positions)):
x1, y1 = numa_positions[i]
x2, y2 = numa_positions[j]
ax5.plot([x1, x2], [y1, y2], 'k-', alpha=0.2, linewidth=1)
ax5.set_xlim(0, 1)
ax5.set_ylim(0, 1)
ax5.axis('off')
ax5.set_title('NUMA架构', fontsize=12)
# 6. 内存访问模式
ax6 = axes[1, 2]
# 连续访问 vs 随机访问
n_access = 1000
# 连续访问
sequential = np.arange(n_access)
sequential_time = np.cumsum(np.random.exponential(1, n_access))
# 随机访问
random = np.random.permutation(n_access)
random_time = np.cumsum(np.random.exponential(2, n_access))
ax6.plot(sequential[:100], sequential_time[:100], 'b-',
linewidth=2, label='连续访问')
ax6.plot(random[:100], random_time[:100], 'r--',
linewidth=2, label='随机访问')
ax6.set_xlabel('访问次数', fontsize=11)
ax6.set_ylabel('累积时间', fontsize=11)
ax6.set_title('内存访问模式', fontsize=12)
ax6.legend()
ax6.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('memory_architecture.png', dpi=150, bbox_inches='tight')
plt.close()
print(" 已保存: memory_architecture.png")
def visualize_parallel_algorithms():
"""可视化并行算法"""
print("\n[4/5] 生成并行算法可视化...")
fig, axes = plt.subplots(2, 3, figsize=(16, 10))
# 1. 归约操作
ax1 = axes[0, 0]
# 树形归约
levels = 3
for level in range(levels):
n_nodes = 2 ** (levels - level - 1)
y = 0.9 - level * 0.3
for i in range(n_nodes):
x = 0.5 / n_nodes + i * (1.0 / n_nodes)
if level < levels - 1:
# 绘制节点
circle = plt.Circle((x, y), 0.05, color='lightblue',
ec='blue', linewidth=2)
ax1.add_patch(circle)
ax1.text(x, y, f'{i}', ha='center', va='center',
fontsize=8, fontweight='bold')
# 绘制到子节点的连接
child_y = y + 0.3
child_x1 = x - 0.25 / (2 ** level)
child_x2 = x + 0.25 / (2 ** level)
if child_x1 > 0:
ax1.plot([x, child_x1], [y, child_y], 'k-', linewidth=1)
if child_x2 < 1:
ax1.plot([x, child_x2], [y, child_y], 'k-', linewidth=1)
else:
# 叶子节点
for j in range(2):
leaf_x = x - 0.125 + j * 0.25
rect = plt.Rectangle((leaf_x-0.05, y-0.05), 0.1, 0.1,
fill=True, facecolor='lightgreen',
edgecolor='green', linewidth=1)
ax1.add_patch(rect)
ax1.text(leaf_x, y, f'd{2*i+j}', ha='center', va='center',
fontsize=7)
ax1.set_xlim(0, 1)
ax1.set_ylim(0, 1)
ax1.axis('off')
ax1.set_title('树形归约', fontsize=12)
# 2. 广播操作
ax2 = axes[0, 1]
# 根节点
root = plt.Circle((0.5, 0.85), 0.06, color='red', ec='darkred', linewidth=2)
ax2.add_patch(root)
ax2.text(0.5, 0.85, 'Root', ha='center', va='center',
fontsize=9, fontweight='bold', color='white')
# 子节点
positions = [(0.25, 0.6), (0.75, 0.6), (0.15, 0.35), (0.35, 0.35),
(0.65, 0.35), (0.85, 0.35)]
for i, (x, y) in enumerate(positions):
circle = plt.Circle((x, y), 0.05, color='lightblue',
ec='blue', linewidth=2)
ax2.add_patch(circle)
ax2.text(x, y, f'P{i+1}', ha='center', va='center',
fontsize=8, fontweight='bold')
# 广播箭头
for x, y in positions[:2]:
ax2.annotate('', xy=(x, y+0.05), xytext=(0.5, 0.79),
arrowprops=dict(arrowstyle='->', color='green', lw=2))
for i, (x, y) in enumerate(positions[2:]):
parent_x = 0.25 if i < 2 else 0.75
parent_y = 0.6
ax2.annotate('', xy=(x, y+0.05), xytext=(parent_x, parent_y-0.05),
arrowprops=dict(arrowstyle='->', color='green', lw=1.5))
ax2.set_xlim(0, 1)
ax2.set_ylim(0, 1)
ax2.axis('off')
ax2.set_title('广播操作', fontsize=12)
# 3. 流水线并行
ax3 = axes[0, 2]
stages = ['阶段1', '阶段2', '阶段3', '阶段4']
colors_stage = ['red', 'orange', 'yellow', 'green']
for i, (stage, color) in enumerate(zip(stages, colors_stage)):
rect = plt.Rectangle((0.05 + i*0.23, 0.4), 0.18, 0.3,
fill=True, facecolor=color,
edgecolor='black', linewidth=2, alpha=0.7)
ax3.add_patch(rect)
ax3.text(0.14 + i*0.23, 0.55, stage, ha='center', va='center',
fontsize=10, fontweight='bold')
# 数据流
for i in range(len(stages)-1):
ax3.annotate('', xy=(0.23 + i*0.23, 0.55), xytext=(0.23 + i*0.23 + 0.05, 0.55),
arrowprops=dict(arrowstyle='->', color='blue', lw=2))
ax3.set_xlim(0, 1)
ax3.set_ylim(0, 1)
ax3.axis('off')
ax3.set_title('流水线并行', fontsize=12)
# 4. 任务并行
ax4 = axes[1, 0]
tasks = ['网格\n生成', '矩阵\n组装', '求解器', '后\n处理']
task_colors = ['lightcoral', 'lightblue', 'lightgreen', 'lightyellow']
for i, (task, color) in enumerate(zip(tasks, task_colors)):
rect = plt.Rectangle((0.1, 0.75 - i*0.2), 0.15, 0.15,
fill=True, facecolor=color,
edgecolor='black', linewidth=2)
ax4.add_patch(rect)
ax4.text(0.175, 0.825 - i*0.2, task, ha='center', va='center',
fontsize=9, fontweight='bold')
# 任务队列
for j in range(3):
small_rect = plt.Rectangle((0.3 + j*0.2, 0.77 - i*0.2), 0.08, 0.11,
fill=True, facecolor=color,
edgecolor='gray', linewidth=1, alpha=0.6)
ax4.add_patch(small_rect)
ax4.set_xlim(0, 1)
ax4.set_ylim(0, 1)
ax4.axis('off')
ax4.set_title('任务并行', fontsize=12)
# 5. 数据并行
ax5 = axes[1, 1]
# 数据分区
data_blocks = [(0.1, 0.7), (0.4, 0.7), (0.7, 0.7),
(0.1, 0.4), (0.4, 0.4), (0.7, 0.4)]
for i, (x, y) in enumerate(data_blocks):
rect = plt.Rectangle((x, y), 0.2, 0.2,
fill=True, facecolor=f'C{i}',
edgecolor='black', linewidth=2, alpha=0.6)
ax5.add_patch(rect)
ax5.text(x+0.1, y+0.1, f'D{i+1}', ha='center', va='center',
fontsize=10, fontweight='bold')
# 处理器
for i, (x, y) in enumerate(data_blocks):
proc = plt.Circle((x+0.1, y-0.08), 0.05, color='red', alpha=0.7)
ax5.add_patch(proc)
ax5.text(x+0.1, y-0.08, f'P{i+1}', ha='center', va='center',
fontsize=8, fontweight='bold', color='white')
ax5.set_xlim(0, 1)
ax5.set_ylim(0, 1)
ax5.axis('off')
ax5.set_title('数据并行', fontsize=12)
# 6. 混合并行
ax6 = axes[1, 2]
# 节点层
nodes = ['节点1', '节点2']
for i, node in enumerate(nodes):
rect = plt.Rectangle((0.05 + i*0.5, 0.5), 0.4, 0.4,
fill=True, facecolor='lightgray',
edgecolor='black', linewidth=2)
ax6.add_patch(rect)
ax6.text(0.25 + i*0.5, 0.85, node, ha='center', va='center',
fontsize=10, fontweight='bold')
# 内部核心
for j in range(4):
core = plt.Circle((0.15 + i*0.5 + (j%2)*0.15, 0.7 - (j//2)*0.15),
0.05, color='blue', alpha=0.6)
ax6.add_patch(core)
# 网络连接
ax6.annotate('', xy=(0.55, 0.7), xytext=(0.45, 0.7),
arrowprops=dict(arrowstyle='<->', color='red', lw=2))
ax6.text(0.5, 0.75, '网络', ha='center', fontsize=9, color='red')
ax6.set_xlim(0, 1)
ax6.set_ylim(0, 1)
ax6.axis('off')
ax6.set_title('混合并行', fontsize=12)
plt.suptitle('并行计算模式与算法', fontsize=14, fontweight='bold')
plt.tight_layout()
# 保存静态图
plt.savefig('parallel_algorithms.png', dpi=150, bbox_inches='tight',
facecolor='white', edgecolor='none')
# 创建动画展示并行执行过程
fig2, axes2 = plt.subplots(1, 2, figsize=(12, 5))
def animate_parallel(frame):
axes2[0].clear()
axes2[1].clear()
# 左图:串行执行
n_tasks = 8
task_height = 0.08
for i in range(n_tasks):
color = 'green' if i <= frame else 'lightgray'
rect = plt.Rectangle((0.1, 0.9 - i*0.1), 0.3, task_height,
fill=True, facecolor=color,
edgecolor='black', linewidth=1)
axes2[0].add_patch(rect)
axes2[0].text(0.25, 0.94 - i*0.1, f'任务{i+1}',
ha='center', va='center', fontsize=8)
axes2[0].set_xlim(0, 1)
axes2[0].set_ylim(0, 1)
axes2[0].axis('off')
axes2[0].set_title(f'串行执行 (时间: {frame+1})', fontsize=12)
# 右图:并行执行(4个处理器)
n_processors = 4
tasks_per_processor = 2
for p in range(n_processors):
for t in range(tasks_per_processor):
task_idx = p * tasks_per_processor + t
if task_idx < n_tasks:
color = 'green' if task_idx <= frame else 'lightgray'
rect = plt.Rectangle((0.1 + p*0.22, 0.9 - t*0.15),
0.15, task_height,
fill=True, facecolor=color,
edgecolor='black', linewidth=1)
axes2[1].add_patch(rect)
axes2[1].text(0.175 + p*0.22, 0.94 - t*0.15,
f'T{task_idx+1}',
ha='center', va='center', fontsize=8)
# 处理器标签
axes2[1].text(0.175 + p*0.22, 0.05, f'P{p+1}',
ha='center', va='center', fontsize=10,
fontweight='bold')
axes2[1].set_xlim(0, 1)
axes2[1].set_ylim(0, 1)
axes2[1].axis('off')
axes2[1].set_title(f'并行执行 (时间: {(frame//4)+1})', fontsize=12)
n_tasks = 8
anim = FuncAnimation(fig2, animate_parallel, frames=n_tasks,
interval=500, repeat=True)
# 保存动画
anim.save('parallel_execution.gif', writer='pillow', fps=2, dpi=100)
plt.close('all')
print(" 已保存: parallel_algorithms.png")
print(" 已保存: parallel_execution.gif")
def visualize_fdtd_simulation():
"""可视化FDTD仿真结果"""
print("\n[5/5] 生成FDTD仿真可视化...")
# 运行串行和向量化FDTD
nx, ny = 100, 100
n_steps = 200
# 串行版本(使用较小的网格以节省时间)
print(" 运行串行FDTD...")
start = time.time()
Ez_serial = serial_fdtd_2d(50, 50, 100)
time_serial = time.time() - start
# 向量化版本
print(" 运行向量化FDTD...")
start = time.time()
Ez_vectorized = vectorized_fdtd_2d(nx, ny, n_steps)
time_vectorized = time.time() - start
print(f" 串行时间: {time_serial:.3f}s, 向量化时间: {time_vectorized:.3f}s")
print(f" 加速比: {time_serial/time_vectorized:.2f}x")
# 可视化结果
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 串行结果
im1 = axes[0].imshow(Ez_serial, cmap='RdBu_r', aspect='auto')
axes[0].set_title('串行FDTD结果 (50×50)', fontsize=12)
axes[0].set_xlabel('X', fontsize=10)
axes[0].set_ylabel('Y', fontsize=10)
plt.colorbar(im1, ax=axes[0], label='Ez')
# 向量化结果
im2 = axes[1].imshow(Ez_vectorized, cmap='RdBu_r', aspect='auto')
axes[1].set_title(f'向量化FDTD结果 (100×100)\n时间: {time_vectorized:.3f}s',
fontsize=12)
axes[1].set_xlabel('X', fontsize=10)
axes[1].set_ylabel('Y', fontsize=10)
plt.colorbar(im2, ax=axes[1], label='Ez')
# 场分布剖面
center_line = Ez_vectorized[ny//2, :]
axes[2].plot(center_line, linewidth=2, color='blue')
axes[2].set_xlabel('X位置', fontsize=11)
axes[2].set_ylabel('Ez幅度', fontsize=11)
axes[2].set_title('中心线场分布', fontsize=12)
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('fdtd_simulation_results.png', dpi=150, bbox_inches='tight')
plt.close()
print(" 已保存: fdtd_simulation_results.png")
if __name__ == '__main__':
# 运行所有仿真
print("="*60)
print("计算电磁学并行计算仿真")
print("="*60)
# 1. 并行性能基准测试
benchmark_parallel_computing()
# 2. 域分解可视化
visualize_domain_decomposition()
# 3. 内存架构可视化
visualize_memory_architecture()
# 4. 并行算法可视化
visualize_parallel_algorithms()
# 5. FDTD仿真可视化
visualize_fdtd_simulation()
print("\n" + "="*60)
print("所有仿真完成!")
print("="*60)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)