【kaggel学习笔记】Stacked Regressions : Top 4% on LeaderBoard-堆叠回归:排行榜Top 4%
本文用于对kaggel项目:House Prices - Advanced Regression Techniques 的学习。
一.参考资料
Stacked Regressions : Top 4% on LeaderBoard
【kaggel学习笔记】Comprehensive data exploration with Python 使用python进行全面数据探索-CSDN博客
【kaggel学习笔记】Regularized Linear Models-正则化线性模型-CSDN博客
【kaggel学习笔记】A study on Regression applied to the Ames dataset-基于Ames房价数据集的回归模型研究-CSDN博客
二.数据处理部分
原文:
由于这个数据集使用起来十分方便,几天前我决定重新回到这场比赛,把目前学到的知识付诸实践,尤其是模型堆叠(stacking)相关的内容。为此,我实现了两个堆叠类(一种最简方案,以及一种稍复杂的方案)。
这些类是为通用场景编写的,你可以轻松将它们适配或扩展到自己的回归问题中。整体思路我尽量写得简洁易懂。
这份笔记中的特征工程相对精简(至少和其他一些优秀代码相比),主要包括:
- 按数据顺序依次填充缺失值
- 将一些看似是数值、实际为分类的变量做类别转换
- 对一些包含有序信息的分类变量做标签编码
- 对有偏分布的特征做 Box-Cox 变换(而非对数变换):这一处理让我的公榜分数和交叉验证结果都有了小幅提升
- 对分类特征做独热编码(哑变量)
之后我选用了多种基模型(大部分是 scikit-learn 原生模型,加上 DMLC 的 XGBoost 与微软的 LightGBM 的 sklearn 接口),在数据上做交叉验证,再进行堆叠与集成。关键在于让(线性)模型对异常值更稳健,这一点同时提升了公榜成绩和交叉验证效果。
出乎我意料的是,这套方案在榜单上表现相当不错(最后一次测试是 2017 年 7 月 2 日,得分 0.11420,前 4%)。
希望看完这份笔记后,那些和我当初一样觉得堆叠概念难以理解的人,能够真正弄明白 stacking 到底是什么。
1. 库导入 + 读数据 2. 合并 train + test(安全做法,不泄露) 3. 数据清洗 + 缺失值处理(业务逻辑) 4. 特征工程(轻量但有效) 5. 偏斜特征 Box-Cox 变换 6. 独热编码 7. 分离回 train / test 8. 定义一堆基础模型(base models) 9. 定义 Stacking 类(核心!) 10. 交叉验证训练所有模型 11. Stacking 融合 12. 预测测试集 13. 生成提交文件
1.库导入 + 读数据
# 导入一些必要的库
import numpy as np # 线性代数运算
import pandas as pd # 数据处理、CSV文件读写(例如 pd.read_csv)
%matplotlib inline
import matplotlib.pyplot as plt # Matlab风格的绘图
import seaborn as sns # 更美观的绘图库
color = sns.color_palette() # 获取配色方案
sns.set_style('darkgrid') # 设置绘图背景为暗网格
# 忽略警告设置
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn # 忽略来自sklearn和seaborn的烦人的警告
from scipy import stats # 科学计算库
from scipy.stats import norm, skew # 用于一些统计计算(正态分布、偏度)
# 限制浮点数输出为3位小数
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x))
from subprocess import check_output
# 查看 ../input 文件夹下有哪些文件(Kaggle环境专用)
print(check_output(["ls", "../input"]).decode("utf8"))sample_submission.csv test.csv train.csv
#Now let's import and put the train and test datasets in pandas dataframe
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')##display the first five rows of the train dataset.
train.head(5) 5 rows × 81 columns
5 rows × 81 columns
##display the first five rows of the test dataset.
test.head(5)
5 rows × 80 columns
# 查看样本和特征的数量
print("删除 Id 列之前,训练集大小为:{} ".format(train.shape))
print("删除 Id 列之前,测试集大小为:{} ".format(test.shape))
# 保存 Id 列(后面提交结果时需要用到)
train_ID = train['Id']
test_ID = test['Id']
# 删除 Id 列,因为它对预测没有帮助
train.drop("Id", axis = 1, inplace = True)
test.drop("Id", axis = 1, inplace = True)
# 再次查看删除 Id 后的数据大小
print("\n删除 Id 列之后,训练集大小为:{} ".format(train.shape))
print("删除 Id 列之后,测试集大小为:{} ".format(test.shape))The train data size before dropping Id feature is : (1460, 81) The test data size before dropping Id feature is : (1459, 80) The train data size after dropping Id feature is : (1460, 80) The test data size after dropping Id feature is : (1459, 79)
2.EDA+数据预处理
2.1异常值
# 创建绘图对象
fig, ax = plt.subplots()
# 绘制 GrLivArea 与 SalePrice 的散点图
ax.scatter(x = train['GrLivArea'], y = train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()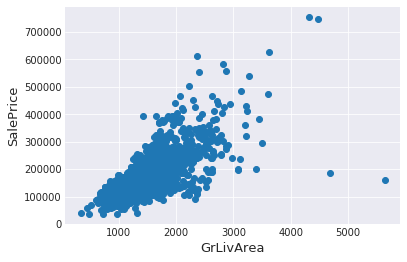
#Deleting outliers
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<300000)].index)
#Check the graphic again
fig, ax = plt.subplots()
ax.scatter(train['GrLivArea'], train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()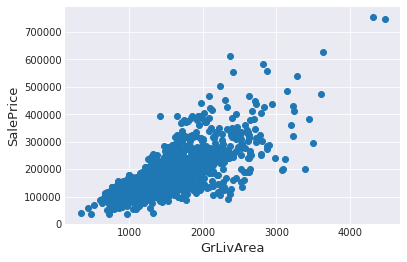
原文:
删除异常值并非总是安全的。我们之所以决定删除这两个样本,是因为它们过于极端,影响非常糟糕(面积极大,售价却极低)。
训练数据中很可能还存在其他异常值。但如果测试数据中也存在异常值,那么把所有异常值都删掉可能会对模型产生严重负面影响。因此,我们不会删除全部异常值,而是会设法让部分模型对异常值具备鲁棒性。你可以参考本笔记的建模部分了解具体实现。
2.2因变量分析
sns.distplot(train['SalePrice'] , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
#Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
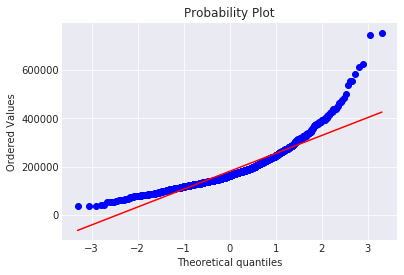
#Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()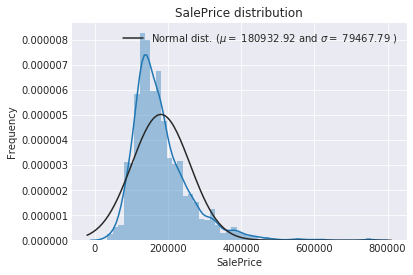
2.3因变量log1p变换
#我们使用numpy函数log1p,对该列的所有元素执行log(1+x)变换
train["SalePrice"] = np.log1p(train["SalePrice"])
#检查变换后的新分布
sns.distplot(train['SalePrice'] , fit=norm);
#获取函数使用的拟合参数
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
#绘制分布图像
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
#同时绘制QQ图
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()mu = 12.02 and sigma = 0.40
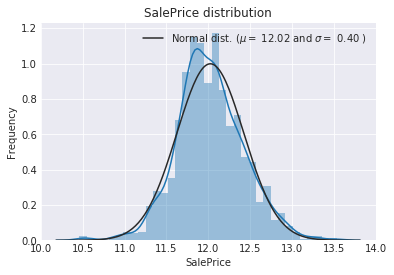
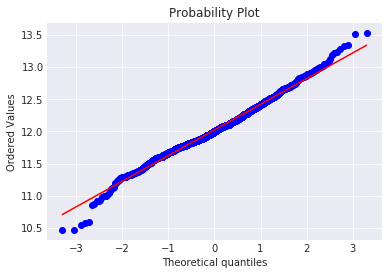
2.4合并数据集
# 计算训练集的样本数量(行数)
ntrain = train.shape[0]
# 计算测试集的样本数量(行数)
ntest = test.shape[0]
# 把训练集的目标值(房价)提取出来,保存到y_train中
y_train = train.SalePrice.values
# 把训练集和测试集上下拼接在一起,生成一个总数据集,并重置索引
all_data = pd.concat((train, test)).reset_index(drop=True)
# 把拼接后数据里的 SalePrice 列删掉(因为测试集没有房价,需要统一格式)
all_data.drop(['SalePrice'], axis=1, inplace=True)
# 输出拼接后所有数据的大小(行数和列数)
print("all_data size is : {}".format(all_data.shape))all_data size is : (2917, 79)
2.5缺失率分析
# 计算每列缺失值占的百分比
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
# 去掉缺失率为0的列,按缺失率从高到低排序,取前30个
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)[:30]
# 把缺失比例存成DataFrame,方便查看
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
# 展示缺失最多的前20个特征
missing_data.head(20)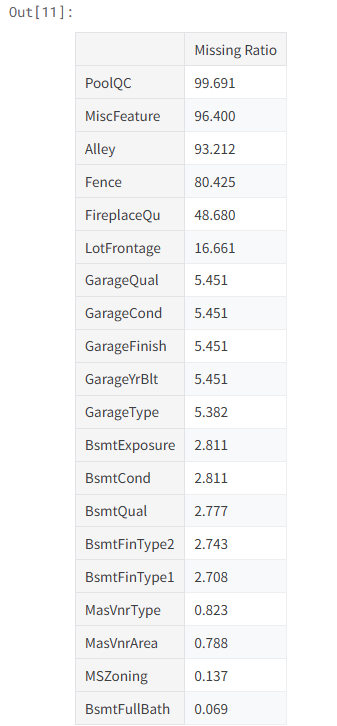
# 创建画布,设置图片大小
f, ax = plt.subplots(figsize=(15, 12))
# X轴文字旋转90度,防止重叠
plt.xticks(rotation='90')
# 绘制柱状图:X轴是特征名称,Y轴是缺失值百分比
sns.barplot(x=all_data_na.index, y=all_data_na)
# X轴标签:特征
plt.xlabel('Features', fontsize=15)
# Y轴标签:缺失值百分比
plt.ylabel('Percent of missing values', fontsize=15)
# 图表标题
plt.title('Percent missing data by feature', fontsize=15)Text(0.5,1,'Percent missing data by feature')
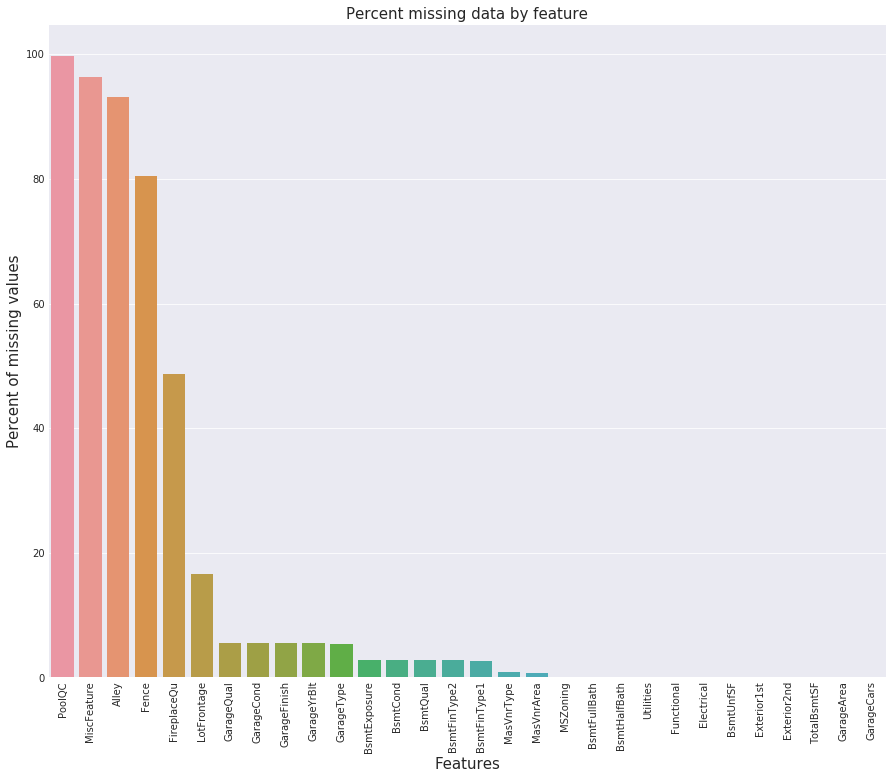
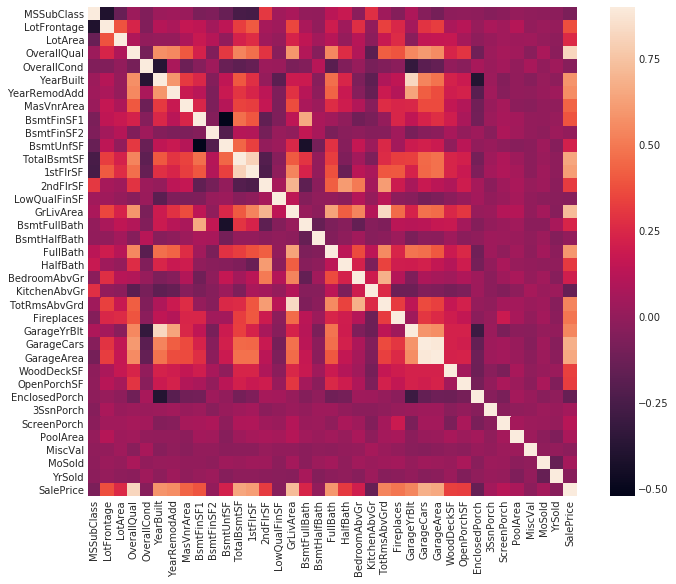
2.6数据相关性分析
# 绘制相关性热力图,观察各特征与 SalePrice 的相关程度
corrmat = train.corr()
plt.subplots(figsize=(12,9))
sns.heatmap(corrmat, vmax=0.9, square=True)<matplotlib.axes._subplots.AxesSubplot at 0x7efd7b454898>
2.7填充缺失值
# 填充缺失值
# 我们按照顺序逐个处理有缺失值的特征
# PoolQC:数据说明中写 NA 代表“没有游泳池”
# 考虑到超过99%的缺失率,且大多数房子确实没有泳池,这样填充合理
all_data["PoolQC"] = all_data["PoolQC"].fillna("None")
# MiscFeature:NA 代表“没有额外设施”
all_data["MiscFeature"] = all_data["MiscFeature"].fillna("None")
# Alley:NA 代表“没有小巷通道”
all_data["Alley"] = all_data["Alley"].fillna("None")
# Fence:NA 代表“没有围栏”
all_data["Fence"] = all_data["Fence"].fillna("None")
# FireplaceQu:NA 代表“没有壁炉”
all_data["FireplaceQu"] = all_data["FireplaceQu"].fillna("None")
# LotFrontage:
# 同一个街区的房屋,临街面积通常很相似
# 因此用同一 Neighborhood 的中位数来填充
all_data["LotFrontage"] = all_data.groupby("Neighborhood")["LotFrontage"].transform(
lambda x: x.fillna(x.median()))
# GarageType, GarageFinish, GarageQual, GarageCond:
# 缺失代表没有车库,填充为 None
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col] = all_data[col].fillna('None')
# GarageYrBlt, GarageArea, GarageCars:
# 没有车库 → 这些数值都是 0
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
# BsmtFinSF1, BsmtFinSF2, BsmtUnfSF, TotalBsmtSF, BsmtFullBath, BsmtHalfBath:
# 没有地下室 → 面积、数量都填 0
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col] = all_data[col].fillna(0)
# BsmtQual, BsmtCond, BsmtExposure, BsmtFinType1, BsmtFinType2:
# 没有地下室 → 填 None
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col] = all_data[col].fillna('None')
# MasVnrArea 和 MasVnrType:
# 缺失代表没有砖石饰面 → 类型填 None,面积填 0
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)
# MSZoning:
# 最多的类别是 RL,用众数填充
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
# Utilities:
# 几乎所有值都是 AllPub,只有一个不同,且缺失2个
# 对建模没用,直接删除
all_data = all_data.drop(['Utilities'], axis=1)
# Functional:
# 数据说明写 NA 代表 typical(正常)
all_data["Functional"] = all_data["Functional"].fillna("Typ")
# Electrical:
# 只有1个缺失,用众数 SBrkr 填充
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
# KitchenQual:
# 只有1个缺失,用众数 TA 填充
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
# Exterior1st 和 Exterior2nd:
# 各缺1个,用众数填充
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
# SaleType:
# 用众数 WD 填充
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
# MSSubClass:
# 缺失代表没有建筑类别 → 填 None
all_data['MSSubClass'] = all_data['MSSubClass'].fillna("None")#Check remaining missing values if any
# 检查是否还有剩余的缺失值
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
missing_data.head()| Missing Ratio |
|---|
3.特征工程
3.1将一些看似是数值、实际是分类的变量进行类型转换
# 将一些看似是数值、实际是分类的变量进行类型转换
# Transforming some numerical variables that are really categorical
# MSSubClass:房屋建筑类型,实际是分类特征,转成字符串类型
all_data['MSSubClass'] = all_data['MSSubClass'].apply(str)
# 将 OverallCond(整体状况)转换为分类变量
# Changing OverallCond into a categorical variable
all_data['OverallCond'] = all_data['OverallCond'].astype(str)
# 将销售年份、销售月份转换成分类特征
# Year and month sold are transformed into categorical features.
all_data['YrSold'] = all_data['YrSold'].astype(str)
all_data['MoSold'] = all_data['MoSold'].astype(str)3.2对一些具有有序类别信息的分类变量进行标签编码
# 对一些具有有序类别信息的分类变量进行标签编码
# Label Encoding some categorical variables that may contain information in their ordering set
from sklearn.preprocessing import LabelEncoder
# 需要进行标签编码的特征列表(这些特征有高低/好坏之分)
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
# 遍历这些列,对分类特征进行标签编码
for c in cols:
# 初始化标签编码器
lbl = LabelEncoder()
# 编码器学习当前列的所有类别
lbl.fit(list(all_data[c].values))
# 将编码后的值替换回原数据
all_data[c] = lbl.transform(list(all_data[c].values))
# 输出处理后数据的形状
print('Shape all_data: {}'.format(all_data.shape))Shape all_data: (2917, 78)
Q1. 什么是 “有序分类特征”?
比如:
- ExterQual(外墙质量):Po < Fa < TA < Gd < Ex
- KitchenQual(厨房质量):差 < 中 < 好 < 极好
- BsmtQual(地下室质量):无 < 差 < 中 < 好
- FireplaceQu(壁炉质量)
- GarageQual(车库质量)
- Fence(围栏质量)
- PoolQC(泳池质量)
- HeatingQC(暖气质量)
它们不是平等的类别,而是有等级、有顺序、有好坏。
Q2. 为什么不能用独热编码?
独热编码会破坏顺序关系!
比如:
- Ex(极好)
- Gd(好)
- TA(一般)
独热会变成:
Ex [1,0,0]
Gd [0,1,0]
TA [0,0,1]
模型完全不知道 Ex > Gd > TA,它会认为它们是平等、无差别的。
Q3. 为什么 LabelEncoder 是对的?
LabelEncoder 会把它们变成:
Ex → 4
Gd → 3
TA → 2
Fa → 1
Po → 0
模型能直接看懂大小关系:
数字越大 → 质量越好 → 房价越高
3.3新增重要特征:房屋总面积
# Adding total sqfootage feature
# 增加【房屋总面积】特征(总地下室面积 + 1楼面积 + 2楼面积)
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']4.其他处理+收尾
4.1偏度特征分析
# =====================
# 偏度特征分析
# Skewed features
# =====================
# 筛选出所有数值型特征(排除object类型,即分类特征)
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
# 计算所有数值特征的偏度(skew),并按从大到小排序
# 先dropna去掉缺失值,再计算偏度
skewed_feats = all_data[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
# 输出提示文字
print("\nSkew in numerical features: \n")
# 把偏度结果存到DataFrame里
skewness = pd.DataFrame({'Skew' :skewed_feats})
# 查看偏度最大的前10个特征
skewness.head(10)Skew in numerical features:
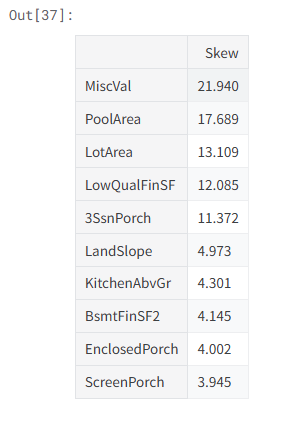
4.2Box-Cox 变换
对(高度)偏斜特征进行 Box-Cox 变换
我们使用 scipy 中的 boxcox1p 函数,它计算的是 1+x 的 Box-Cox 变换。
注意:当 λ=0 时,该变换等价于我们之前对目标变量使用的 log1p 变换。
更多关于 Box-Cox 变换以及该 scipy 函数的详细说明,可以参见相关页面。
# 筛选出偏度绝对值大于 0.75 的特征
skewness = skewness[abs(skewness) > 0.75]
# 打印提示:有多少个偏斜特征需要进行 Box-Cox 变换
print("There are {} skewed numerical features to Box Cox transform".format(skewness.shape[0]))
# 导入 Box-Cox 变换函数
from scipy.special import boxcox1p
# 获取需要变换的特征名称
skewed_features = skewness.index
# 设置 Box-Cox 的 lambda 参数
lam = 0.15
# 对每个偏斜特征循环执行 Box-Cox 变换
for feat in skewed_features:
#all_data[feat] += 1
all_data[feat] = boxcox1p(all_data[feat], lam)
# 注释掉的代码:也可以使用 log1p 进行对数变换
#all_data[skewed_features] = np.log1p(all_data[skewed_features])There are 59 skewed numerical features to Box Cox transform
4.3独热编码
all_data = pd.get_dummies(all_data)
print(all_data.shape)(2917, 220)
4.4划分数据集
train = all_data[:ntrain]
test = all_data[ntrain:]三.建模部分
1.定义RMSE和k折交叉验证
# 导入库
# Import libraries
# 线性回归模型
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
# 集成学习模型
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
# 核岭回归
from sklearn.kernel_ridge import KernelRidge
# 构建流水线
from sklearn.pipeline import make_pipeline
# 鲁棒标准化(对异常值不敏感)
from sklearn.preprocessing import RobustScaler
# 自定义模型基类
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
# 交叉验证工具
from sklearn.model_selection import KFold, cross_val_score, train_test_split
# 模型评估指标
from sklearn.metrics import mean_squared_error
# 梯度提升库
import xgboost as xgb
import lightgbm as lgb
# 定义交叉验证策略
# Define a cross validation strategy
# 我们使用 Sklearn 的 cross_val_score 函数。
# 但是这个函数没有 shuffle 参数,
# 所以我们添加一行代码,在交叉验证之前打乱数据集。
# 交叉验证折数
n_folds = 5
# 定义交叉验证函数(计算 RMSLE)
#Validation function
def rmsle_cv(model):
# 设置5折交叉验证,打乱数据,随机种子固定
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
# 计算负均方误差,取反并开根号,得到 RMSE
rmse = np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv=kf))
# 返回每一折的 RMSE 误差
return rmse2.基础模型
2.1LASSO Regression
这个模型可能对异常值非常敏感。 因此我们需要让模型对异常值更加鲁棒(稳健)。为此,我们在流水线中使用 sklearn 的 Robustscaler() 方法。
# 构建 Lasso 模型流水线:先做鲁棒标准化,再训练 Lasso
lasso = make_pipeline(RobustScaler(), Lasso(alpha=0.0005, random_state=42))2.2Elastic Net Regression
同样对异常值进行鲁棒处理
# 构建弹性网络回归模型:
# 先做鲁棒标准化,再传入 ElasticNet 进行训练
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))make_pipeline(...):把预处理和模型串成一条流水线RobustScaler():对异常值不敏感的标准化ElasticNet(...):弹性网络回归(结合 Lasso + Ridge)alpha=0.0005:正则化强度l1_ratio=0.9:L1 正则占比,接近 Lassorandom_state=3:固定随机种子,结果可复现
2.3Kernel Ridge Regression
# 核岭回归模型 (Kernel Ridge Regression)
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)- KernelRidge:核岭回归,结合核方法与岭回归,能拟合非线性关系
- alpha=0.6:正则化参数,控制模型复杂度,防止过拟合
- kernel='polynomial':使用多项式核函数
- degree=2:多项式次数为 2(二次多项式)
- coef0=2.5:核函数的偏移项,提升多项式拟合效果
2.4Gradient Boosting Regression
使用 huber 损失函数,使得模型对异常值具有鲁棒性
# 梯度提升回归模型定义
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state=5)- n_estimators=3000树的数量,用 3000 棵树一起预测
- learning_rate=0.05学习率,越小学得越精细、越稳定
- max_depth=4每棵树最大深度 4,防止过深、过拟合
- max_features='sqrt'每次分裂只用平方根数量的特征,增加随机性
- min_samples_leaf=15叶子节点至少 15 个样本,让模型更平滑
- min_samples_split=10节点至少 10 个样本才分裂,控制树复杂度
- loss='huber':用 Huber 损失,对异常值不敏感
- random_state=5固定随机种子,保证结果可复现
2.5XGBoost
# 定义 XGBoost 回归模型
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state=7, nthread=-1)1. 基础参数
- learning_rate=0.05学习率,越小学得越细,越不容易过拟合
- max_depth=3树的最大深度 3,很浅,防止过拟合
- n_estimators=2200一共用 2200 棵树 集成预测
2. 控制随机性(防过拟合)
- subsample=0.5213每次训练只用 52% 左右的样本
- colsample_bytree=0.4603每次训练只用 46% 左右的特征
3. 正则化(核心)
- reg_alpha=0.4640L1 正则(类似 Lasso)
- reg_lambda=0.8571L2 正则(类似 Ridge)
- gamma=0.0468分裂门槛,越大越保守
4. 其他
- min_child_weight=1.7817叶子节点最小权重,控制树复杂度
- silent=1不打印训练日志
- random_state=7固定随机种子
- nthread=-1使用所有 CPU 核心加速
2.6LightGBM
# 定义 LightGBM 回归模型
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)1. 任务与基础
- objective='regression'任务 = 回归(预测房价,连续值)
- num_leaves=5每棵树最多 5 个叶子(树非常小,防过拟合)
- learning_rate=0.05学习率小,训练更稳定
- n_estimators=720使用 720 棵树
2. 速度与内存优化
- max_bin=55把特征值分箱成 55 段,训练更快、更稳
3. 随机抽样(防过拟合)
- bagging_fraction=0.8每次用 80% 样本训练
- bagging_freq=5每 5 轮做一次样本抽样
- feature_fraction=0.2319每次只用 23% 特征,增加随机性
4. 随机种子(保证结果可复现)
- feature_fraction_seed=9
- bagging_seed=9
5. 正则化(让模型更平稳)
- min_data_in_leaf=6叶子至少 6 个样本
- min_sum_hessian_in_leaf=11叶子最小二阶导数和,控制复杂度,防过拟合
3.基础模型分数
score = rmsle_cv(lasso)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))Lasso score: 0.1115 (0.0074)
score = rmsle_cv(ENet)
print("ElasticNet score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))ElasticNet score: 0.1116 (0.0074)
score = rmsle_cv(KRR)
print("Kernel Ridge score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))Kernel Ridge score: 0.1153 (0.0075)
score = rmsle_cv(GBoost)
print("Gradient Boosting score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))Gradient Boosting score: 0.1177 (0.0080)
score = rmsle_cv(model_xgb)
print("Xgboost score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))Xgboost score: 0.1161 (0.0079)
score = rmsle_cv(model_lgb)
print("LGBM score: {:.4f} ({:.4f})\n" .format(score.mean(), score.std()))LGBM score: 0.1157 (0.0067)
4.模型堆叠
最简单的堆叠方法:平均基础模型我们从这种平均基础模型的简单方法入手。我们构建一个新类来对我们的模型扩展 scikit-learn 功能,同时利用封装和代码复用(继承)
4.1平均基础模型类
# 定义一个平均模型的类,继承 sklearn 基类,使其可以使用 fit/predict
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
# 初始化方法,传入要融合的多个模型
def __init__(self, models):
self.models = models # 保存传入的模型列表
# 训练函数:克隆每个模型,然后分别训练
def fit(self, X, y):
# 为每个模型创建一个独立副本,避免修改原始模型
self.models_ = [clone(x) for x in self.models]
# 遍历所有复制后的模型,分别训练
for model in self.models_:
model.fit(X, y)
return self # 返回自身,符合 sklearn 规范
# 预测函数:对所有模型的预测结果取平均
def predict(self, X):
# 把每个模型的预测结果按列拼在一起
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
# 对每一行(每个样本)求平均值,作为最终预测结果
return np.mean(predictions, axis=1)4.2平均基础模型分数
我们在这里只对四个模型进行平均:弹性网络、梯度提升、核岭回归和套索回归。当然我们也可以轻松地加入更多模型来进行组合。
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))Averaged base models score: 0.1091 (0.0075)
4.3更简单的堆叠:Meta-model
在这种方法中,我们在平均后的基础模型上添加一个元模型,并使用这些基础模型的折外预测结果来训练我们的元模型。
在训练部分,该过程可以描述如下:
将整个训练集划分为两个不相交的集合(这里是训练集和留出集)
在第一部分(训练集)上训练多个基础模型
在第二部分(留出集)上测试这些基础模型
将步骤 3 中的预测结果(称为折外预测)作为输入,将正确的响应(目标变量)作为输出,来训练一个更高级的学习器,称为元模型。
前三个步骤是迭代执行的。例如,如果我们采用 5 折堆叠,我们首先将训练数据划分为 5 折。然后我们将进行 5 次迭代。在每次迭代中,我们在 4 折数据上训练每个基础模型,并在剩余的一折(留出折)上进行预测。
因此,我们可以确保,在 5 次迭代之后,使用全部数据得到折外预测结果,然后我们将这些结果作为新特征,在步骤 4 中训练我们的元模型。
在预测部分,我们对所有基础模型在测试数据上的预测结果取平均,并将它们用作元特征,最终通过元模型完成最终预测。
4.4堆叠平均模型类
# 堆叠平均模型类
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
# 初始化:传入基础模型、元模型、折数
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
# 我们再次在原始模型的副本上拟合数据
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
# 训练复制的基础模型,然后创建训练复制元模型所需的折外预测值
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
# 现在使用折外预测值作为新特征来训练复制的元模型
self.meta_model_.fit(out_of_fold_predictions, y)
return self
# 在测试数据上对所有基础模型进行预测,并将平均预测值作为元特征
# 最终预测由元模型完成
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)4.5堆叠平均模型分数
# 定义堆叠平均模型:基础模型为 ENet、GBoost、KRR,元模型为 Lasso
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR),
meta_model = lasso)
# 交叉验证评估堆叠模型
score = rmsle_cv(stacked_averaged_models)
# 输出分数:均值(标准差)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))Stacking Averaged models score: 0.1085 (0.0074)
5.最终训练与预测
5.1集成堆叠回归器、XGBoost 和 LightGBM
我们将 XGBoost 和 LightGBM 添加到之前定义的堆叠回归器中。
我们首先定义一个均方根对数误差评估函数
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))# 最终训练与预测
# 堆叠回归器:
stacked_averaged_models.fit(train.values, y_train)
stacked_train_pred = stacked_averaged_models.predict(train.values)
stacked_pred = np.expm1(stacked_averaged_models.predict(test.values))
print(rmsle(y_train, stacked_train_pred))
# 1. test.values:把测试集特征数据转成numpy数组(适配模型输入格式)
# 2. stacked_averaged_models.predict(...):用训练好的堆叠模型对测试集做预测
# 3. np.expm1(...):对预测结果**指数还原**
# → 因为训练前对房价标签做了 log(1+x) 处理,必须用 expm1 恢复真实房价
# 4. 最终结果 stacked_pred:测试集的**真实房价预测值**0.0781571937916
# XGBoost:
model_xgb.fit(train, y_train)
xgb_train_pred = model_xgb.predict(train)
xgb_pred = np.expm1(model_xgb.predict(test))
print(rmsle(y_train, xgb_train_pred))0.0785165142425
#LightGBM:
model_lgb.fit(train, y_train)
lgb_train_pred = model_lgb.predict(train)
lgb_pred = np.expm1(model_lgb.predict(test.values))
print(rmsle(y_train, lgb_train_pred))0.0716757468834
# 注释:对全部训练数据进行【加权平均融合】时的 RMSLE 误差计算
'''RMSE on the entire Train data when averaging'''
# 打印输出提示文字
print('RMSLE score on train data:')
# 注释:
# 对三个模型的训练集预测结果进行【加权融合】
# stacked_train_pred 权重 0.70 → 占比70%(堆叠模型,权重最高)
# xgb_train_pred 权重 0.15 → 占比15%
# lgb_train_pred 权重 0.15 → 占比15%
# 融合后与真实标签 y_train 计算 RMSLE 误差
print(rmsle(y_train,stacked_train_pred*0.70 +
xgb_train_pred*0.15 + lgb_train_pred*0.15 ))RMSLE score on train data: 0.0752190464543
5.2预测及提交
# 集成预测:
# 将三个模型的测试集预测结果 按照权重加权求和,得到最终的融合预测值
ensemble = stacked_pred*0.70 + xgb_pred*0.15 + lgb_pred*0.15
# 生成提交文件
# 创建一个空的DataFrame用于保存提交结果
sub = pd.DataFrame()
# 把测试集的ID列存入提交文件
sub['Id'] = test_ID
# 把集成学习的最终预测结果(房价)存入SalePrice列
sub['SalePrice'] = ensemble
# 将结果保存为csv文件,不保存行索引,用于比赛提交
sub.to_csv('submission.csv',index=False)四.一些思考总结
1.数据处理流程总结
【整个机器学习 Pipeline】
├─ 1. 库导入 + 读取数据(train + test)
│
├─ 2. EDA 探索性数据分析(只分析、不修改数据、不碰测试集y)
│ ├─ 异常值分析(画图、观察、不删除)
│ ├─ 目标变量分布分析(SalePrice)
│ ├─ 缺失值统计分析(计算缺失率)
│ ├─ 特征相关性分析(热力图)
│ └─ 数值特征偏度分析(计算skew)
│
├─ 3. 数据预处理(第一步:合并 train + test)
│ │
│ ├─ 【第一步:合并训练集 + 测试集】
│ │
│ ├─ 【子模块1:数据清洗】
│ │ ├─ 删除异常值
│ │ └─ 填充所有缺失值(None / 0 / 众数 / 中位数)
│ │
│ ├─ 【子模块2:特征工程】
│ │ ├─ 类型转换(数值转分类特征)
│ │ ├─ 有序特征标签编码(LabelEncoder)
│ │ ├─ 构造新特征(TotalSF 总面积)
│ │ ├─ 偏度特征 Box-Cox 变换
│ │ ├─ 无序特征独热编码
│ │ └─ 目标变量 log1p 变换(SalePrice)
│ │
│ └─ 【最后一步:拆分回 train / test】
│
└─ 4. 模型训练 & 预测(只用训练集!)
├─ 模型构建(Lasso / XGBoost / 堆叠)
├─ 模型训练
├─ 测试集预测
└─ 提交结果|
大类 |
包含的具体步骤(对应项目实操) |
核心定义 |
|---|---|---|
|
EDA(探索性数据分析) |
1. 异常值分析(仅观察、统计,不执行删除/修正动作);2. 目标变量(因变量)分布分析(如SalePrice分布观察);3. 缺失率分析(统计各特征缺失比例);4. 数据相关性分析(如特征间热力图分析);5. 数值特征偏度分析(计算各数值特征skew,判断分布偏斜程度) |
独立前置阶段,仅对原始数据进行观察、统计、诊断,不修改任何数据,只找问题、定处理方案,不做“治疗”操作 |
|
数据清洗(Data Cleaning) |
1. 异常值处理(执行删除/修正异常值的动作);2. 填充缺失值(按规则填充所有缺失值,如None、0、众数、中位数、按街区分组填充等) |
数据预处理的基础子步骤,核心任务是“把脏数据弄干净”,解决数据中的缺失、异常等基础问题,为后续处理铺路 |
|
数据预处理(Data Preprocessing) |
1. 合并训练集与测试集;2. 数据清洗(填充缺失值、处理异常值);3. 目标变量log1p变换;4. 类型转换(如数值型分类特征转字符串);5. 标签编码(有序分类特征);6. Box-Cox变换(偏斜特征分布修正);7. 独热编码(无序分类特征);8. 划分训练集与测试集 |
核心执行阶段,动手修改原始数据,将未处理的原始数据转换为模型可接受、可学习的格式,包含数据清洗、特征工程所有操作,是连接原始数据与建模的核心环节 |
|
特征工程(Feature Engineering) |
1. 类型转换(将数值形式的分类特征转为字符串,修正特征类型);2. 标签编码(对有序分类特征进行编码,保留顺序信息);3. 新增特征(如构造TotalSF房屋总面积特征);4. Box-Cox变换(修正数值特征的偏斜分布,优化特征质量);5. 独热编码(对无序分类特征进行编码,避免顺序误导);6. 目标变量log1p变换(修正目标变量分布,提升模型拟合效果) |
数据预处理的高级子步骤,核心任务是优化现有特征、构造新特征,提升特征与目标变量的关联性,让模型能更好地学习数据规律,是提升模型性能的关键 |
2.堆叠模型stacking的原理
2.1.核心原理
让一堆模型先预测,把它们的预测结果当成新特征,再训练一个最终模型来做决定。
2.2.标准 Stacking 流程(5 折为例)
把训练集分成 5 份:A B C D E
第一轮用 A B C D 训练基础模型 → 在 E 上预测得到 E 的预测值
第二轮用 A B C E 训练 → 在 D 上预测得到 D 的预测值
第三、四、五轮同理
最后会得到:全部训练集的 “模型预测值”这些预测值 = 新特征
最后一步
用这些新特征去训练一个元模型(比如 Lasso)元模型学会怎么组合这些预测才最准。
2.3代码里的 Stacking 到底在干嘛?
# 基础模型:3个
base_models = (ENet, GBoost, KRR)
# 元模型:1个(总指挥)
meta_model = lasso
训练时:
- 用 5 折交叉训练 3 个基础模型
- 得到每条训练样本的 3 个预测值
- 把这 3 个预测当成新特征
- 用 Lasso 学习怎么加权最准
预测时:
- 3 个模型分别预测测试集
- 把它们的预测送给 Lasso
- Lasso 输出最终房价
2.4为什么要这么做?
- 每个模型擅长的地方不一样
- 有的擅长线性
- 有的擅长非线性
- Stacking 让它们互补→ 结果比任何单个模型都准
3.最后集成的权重怎么来的?
3.1经验值,凭感觉
3.2GridSearchCV 可以自动找权重
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LinearRegression
# 把三个模型的预测结果拼在一起
train_meta = np.column_stack([stacked_train_pred, xgb_train_pred, lgb_train_pred])
# 用线性回归找最优权重
grid = LinearRegression(fit_intercept=False)
grid.fit(train_meta, y_train)
# 输出自动找到的权重!
print(grid.coef_)运行后可能的输出:[0.68, 0.16, 0.16]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)