大语言模型LLM
一、大模型
1. 从GPT到大模型
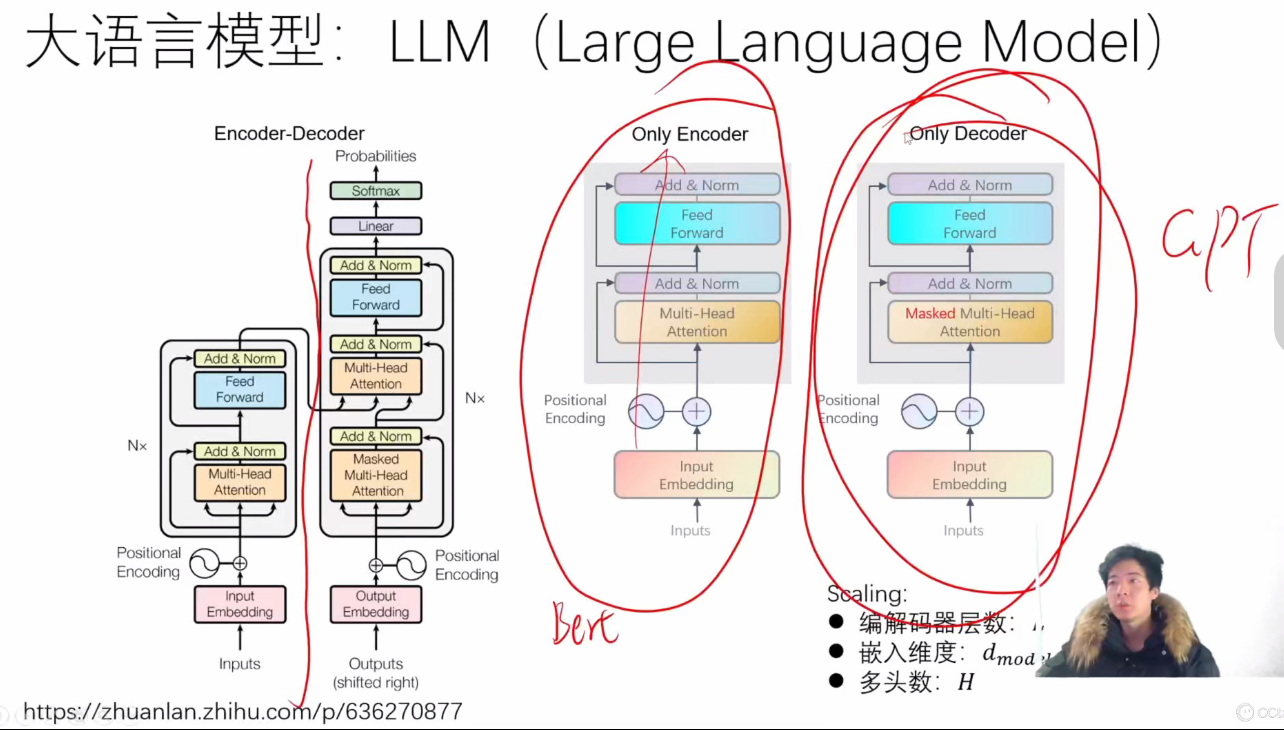
- 基础架构:所有大模型都源于Transformer架构,其并行处理长序列的能力使模型参数规模可以无限扩展
- 架构变体:
- Encoder-Decoder:完整Transformer结构
- Only Encoder:如BERT系列,用于特征提取和分类任务
- Only Decoder:如GPT系列,仅包含解码器的自回归生成模型
2. 大模型结构演进(模型改变)
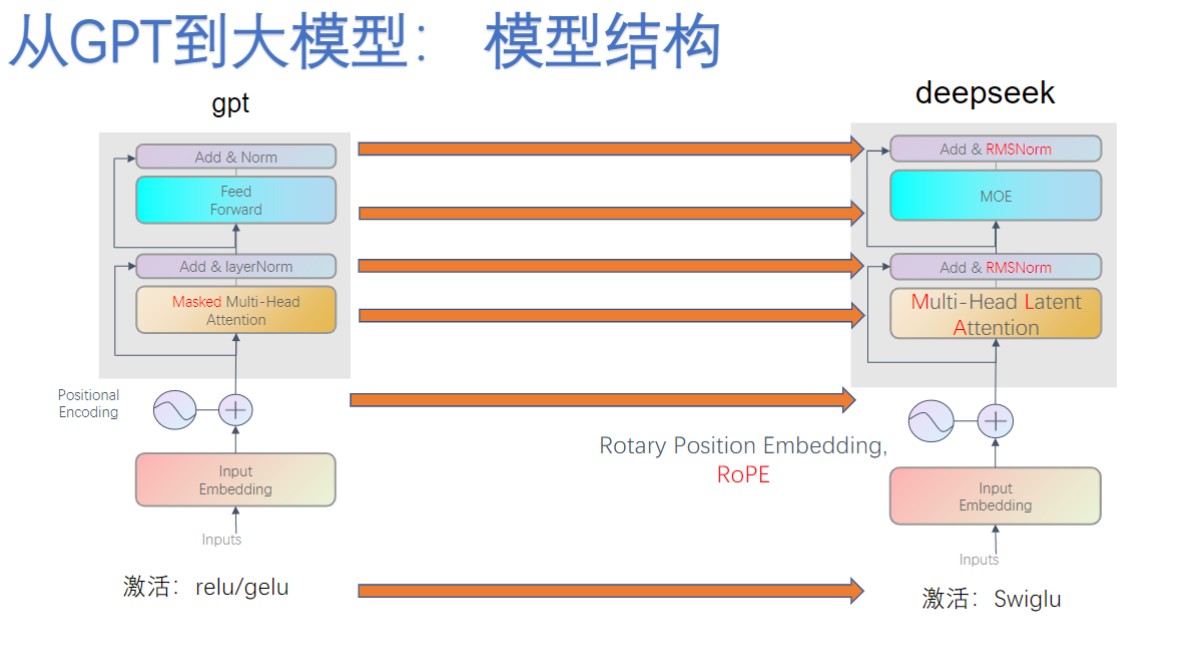
- 六大技术革新:
- 激活函数:从ReLU/GELU升级为更先进的激活方式
- 位置编码:改用Rotary Position Embedding (RoPE)
- 注意力机制:发展为Multi-Head Latent Attention
- 前馈网络:引入混合专家模型(MoE)结构
- 归一化层:LayerNorm变为RMSNorm
- 参数规模:嵌入维度(
dmodd_{mod}dmod
)和多头数(H)显著扩大
- 实现细节:
- 每层包含Masked Multi-Head Attention(防止信息泄露)
- 残差连接后接归一化(Add & Norm)
- 位置编码与词嵌入相加后输入模型
- 代码实现可见Block类中的att+ffn结构
1)模型的训练
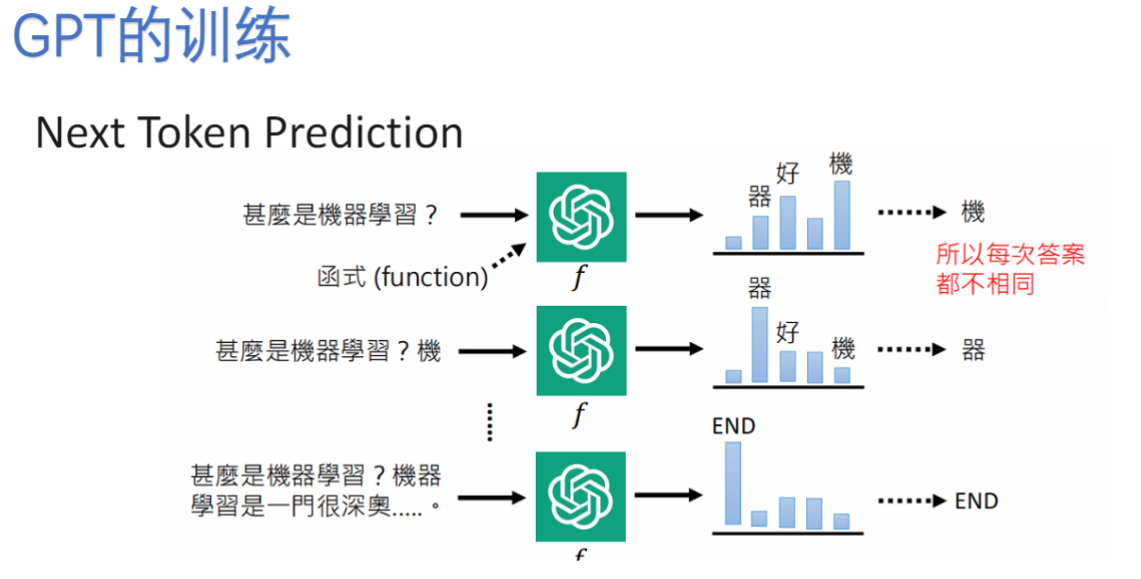

- 预训练
- 机制:Next Token Prediction (NTP)自回归预测
- 过程:输入前文预测下一个token,将预测结果作为下一轮输入
- 特点:使用海量互联网文本数据,早期GPT生成质量较差但参数扩大后能力显著提升
- 有监督微调
- 别名:SFT (Supervised Fine-Tuning) / Instruction Tuning
- 核心任务:将原始网络数据改造为结构化问答格式
- 关键点:
- 需要人工标注和重构数据格式
- 最耗费人力资源的环节
- 示例改造:将"《无间道》的主演有哪些?刘德华、梁朝伟"改为标准问答对
- 强化学习
- 全称:RLHF (Reinforcement Learning from Human Feedback)
- 机制:
- 人类对模型输出进行好坏评分
- 强化优质回答,抑制低质回答
- 示例:正面评价"屯了一大堆..."被强化,负面评价"对商品不满意..."被拒绝
- 意义:被认为是通向强人工智能的重要路径
3. 模型实现细节
- 核心组件:
- token_embedding_table:词嵌入矩阵
- position_embedding_table:位置编码矩阵
- blocks:多层Transformer块堆叠
- lm_head:输出词表概率分布
- 参数优化:
- 使用tie_weight减少参数(共享嵌入和输出层权重)
- 初始化采用均值为0,标准差为0.02的正态分布
- 前向传播:
- 输入token索引idx
- 叠加词嵌入和位置嵌入
- 通过多层Transformer块处理
- 最终输出下一个token的概率分布
4. 模型结构
1)混合专家模型

- 混合专家模型的结构与来源
- 结构改变点: 将Transformer中的FeedForward部分替换为混合专家结构
- 代码位置: 位于Transformer Block内部,具体是Block类中的self.ffn成员变量
- 原始结构:
- 组成: 两个全连接层,维度变化为
dmodel→4dmodel→dmodeld_{model}\rightarrow4d_{model}\rightarrow d_{model}dmodel→4dmodel→dmodel
- 示例参数:
- 2048维模型参数量:2048×2048×4×2≈3300万
- 4096维模型参数量:4096×4096×4×2≈1.3亿
- 组成: 两个全连接层,维度变化为
- 混合专家模型参数量与计算量问题
- 改造原因:
- 参数量爆炸: 大模型隐藏层维度(2048/4096)导致全连接层参数量过大
- 计算瓶颈: 矩阵乘法计算量随维度平方增长
- 解决思路:
- 通过路由机制选择性地激活部分专家网络
- 保持总参数量不变的情况下减少实际计算量
- 改造原因:
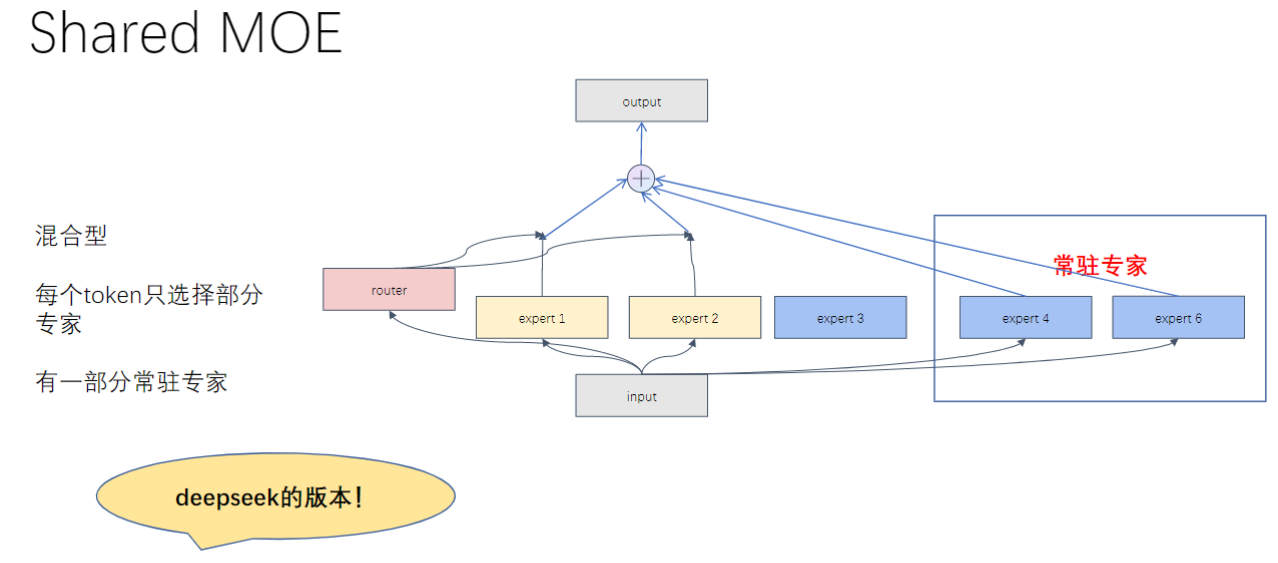
- DeepSeekMoE模型示意图解读
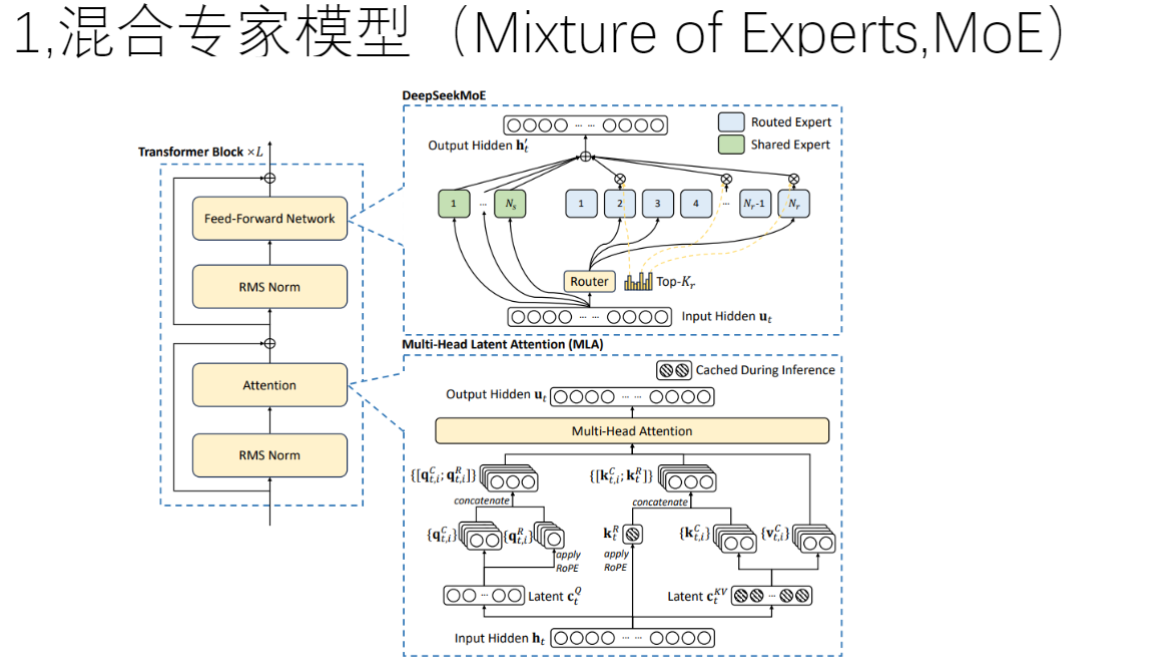
- 核心组件:
- 共享专家(Shared Expert): 所有输入都必须经过的固定处理路径
- 路由专家(Routed Expert): 通过门控机制动态选择的部分专家
- 路由门(Router): 决定输入向量分配给各专家的权重
- 工作流程:
- 输入向量h同时进入路由门和共享专家
- 路由门输出Top-K专家选择结果
- 选中的专家与共享专家结果加权求和
- 输出维度保持与输入一致
- 核心组件:
- 混合专家模型与医院科室的类比
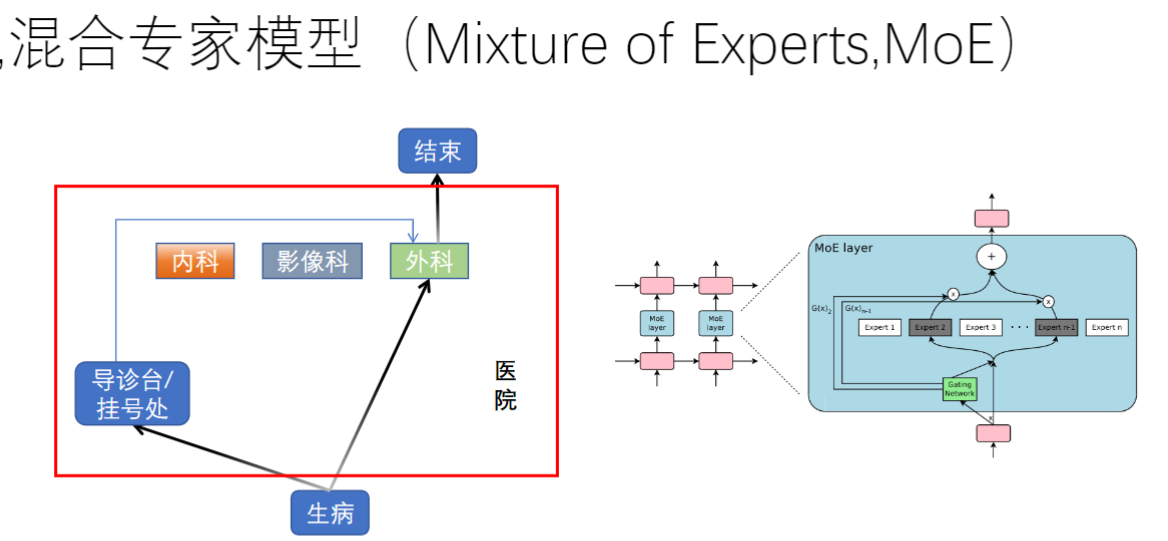
- 类比关系:输入数据先去共享专家,共享专家告诉数据去访问某几个路由专家,选中的专家与共享专家结果加权求和,最后相加输出。
- 工作特点:
- 必选路径: 类似所有病人都需要取药
- 可选路径: 类似根据症状选择专科
- 全加型MoE的实现原理
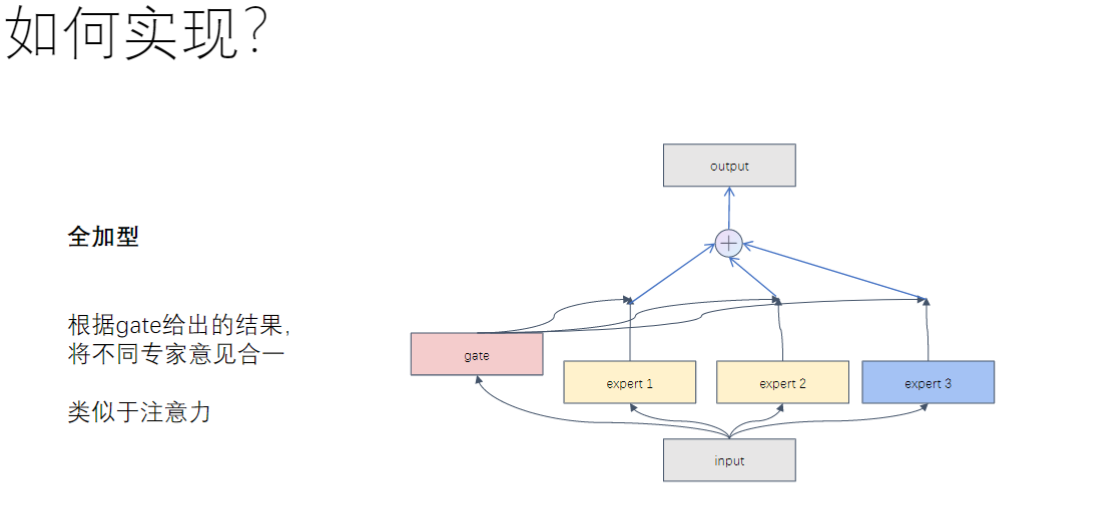
- 与注意力机制的关系:
- 相似性: 都是基于权重的特征融合
- 区别: 注意力关注token间关系,MoE关注特征空间划分
- 与注意力机制的关系:
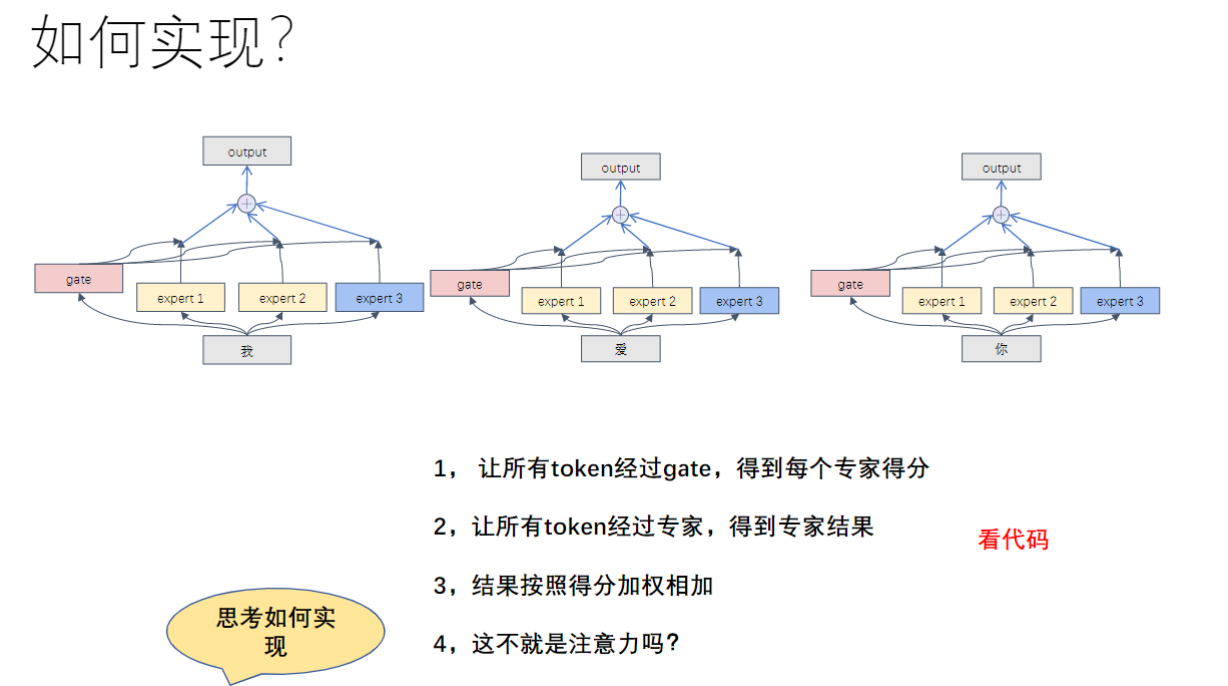
- 实现步骤:
- 所有token经过gate获得各专家得分
- 所有token经过所有专家得到中间结果
- 按得分加权求和最终输出
2)稀疏MOE
- 稀疏MOE的基本概念
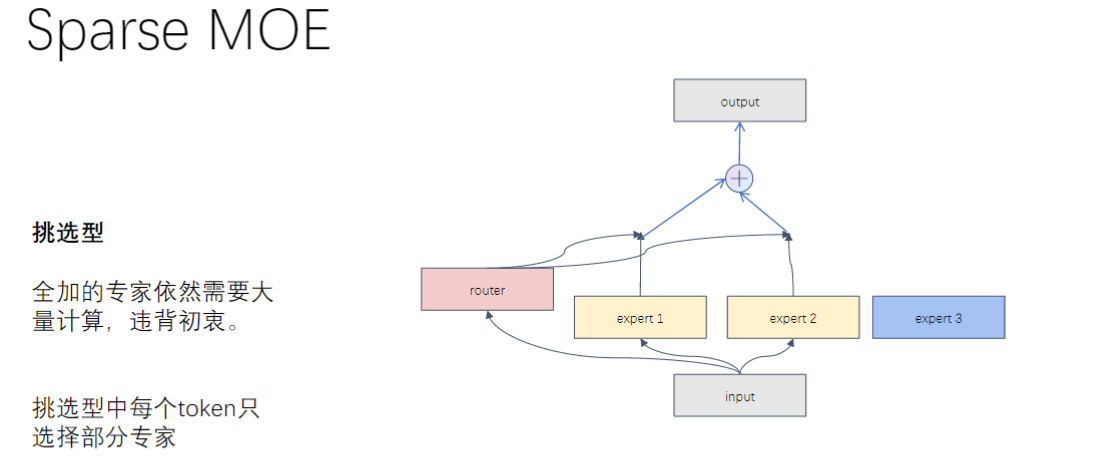
- 核心特点:每个token只选择部分专家进行计算,而非全连接所有专家
- 设计初衷:减少计算量,避免全连接专家带来的计算负担
- 专家偏好:在训练过程中,不同专家会形成处理特定类型token的偏好(如处理特定偏旁部首或发音的字符)
- 稀疏MOE的实现思路
- 路由机制:
- 通过gate生成专家得分
- 使用softmax归一化得分
- 选择top_k得分最高的专家
- 计算过程:
- 让token经过选定的专家
- 将专家输出按得分加权求和
- 注意力机制相似性:该过程与注意力机制有相似之处
- 路由机制:
- 稀疏MOE的实现难点
- 动态选择问题:
- 每个token选择的专家组合不同
- 无法批量处理所有token的专家计算
- 计算复杂度:
- 需要为每个token单独计算其选择的专家
- 当token数量大时(如10万),循环计算效率极低
- 代码复杂度:动态选择导致代码实现难度呈爆炸式增长
- 动态选择问题:
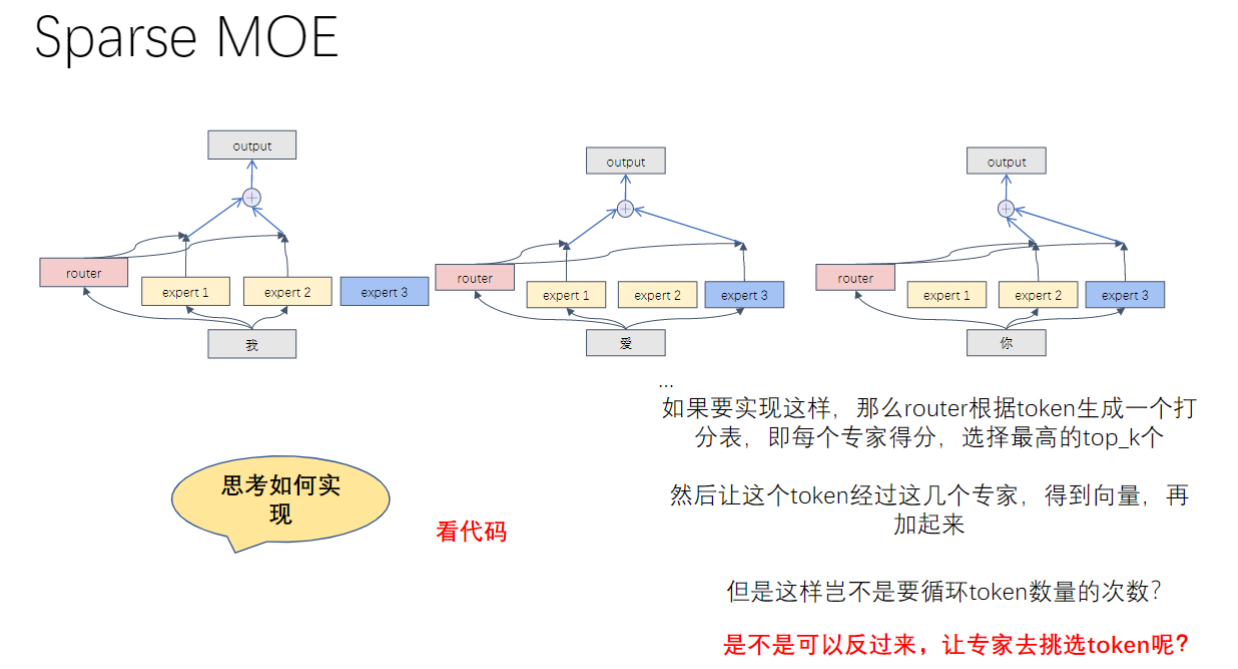
- 稀疏MOE的优化思路
- 计算方向反转:
- 传统思路:token选择专家
- 优化思路:专家选择token
- 优势:
- 专家数量固定(如1000个),远少于token数量
- 可批量处理每个专家对应的所有token
- 实现步骤:
- 为每个专家生成mask标识哪些token选择了它
- 批量处理每个专家对应的token
- 将结果按权重累加到最终输出
- 计算方向反转:
- MOE的负载均衡
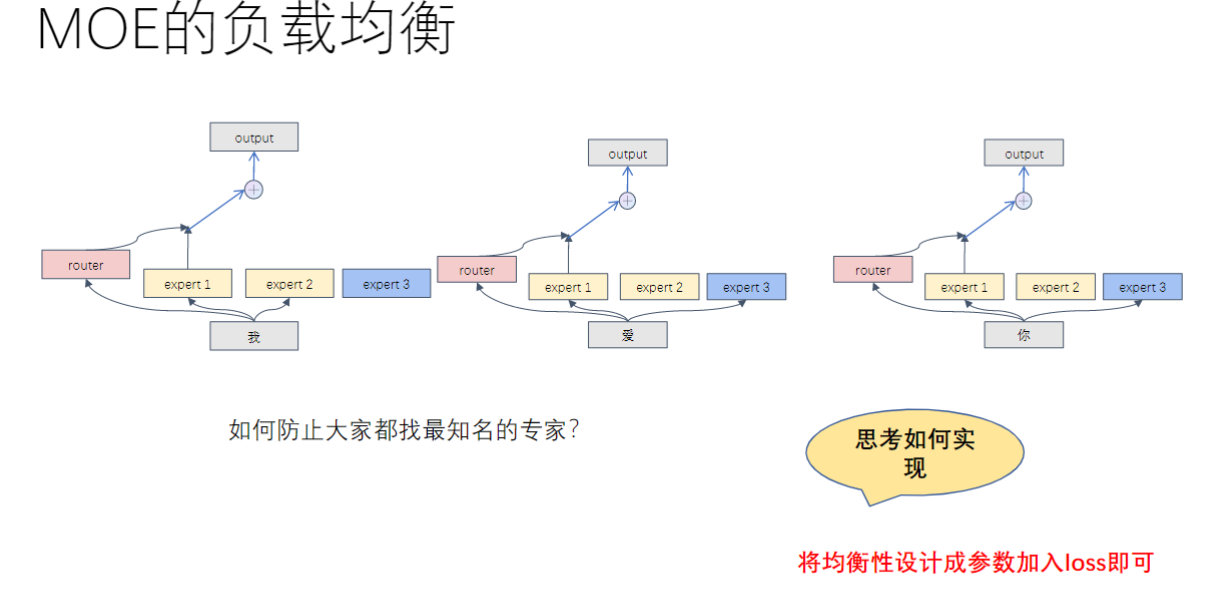
- 问题背景:防止所有token都选择同一"热门"专家
- 解决方案:
- 将专家使用均衡性设计为可训练参数
- 在loss函数中加入均衡性惩罚项
- 效果:确保所有专家都能得到合理利用
3)MOE的作用

- 核心优势:
- 减少激活参数:和传统的全连接FeedForward相比,从100B降至21B
- 降低计算量:减少约80%的浮点运算
- 设计理念:
- 现代AI设备中存储便宜但计算昂贵
- 稀疏激活(sparse activation)优化计算效率
- 实际限制:
- 不减少总参数量(可能增加)
- 多机通信仍是瓶颈
5. 旋转位置编码
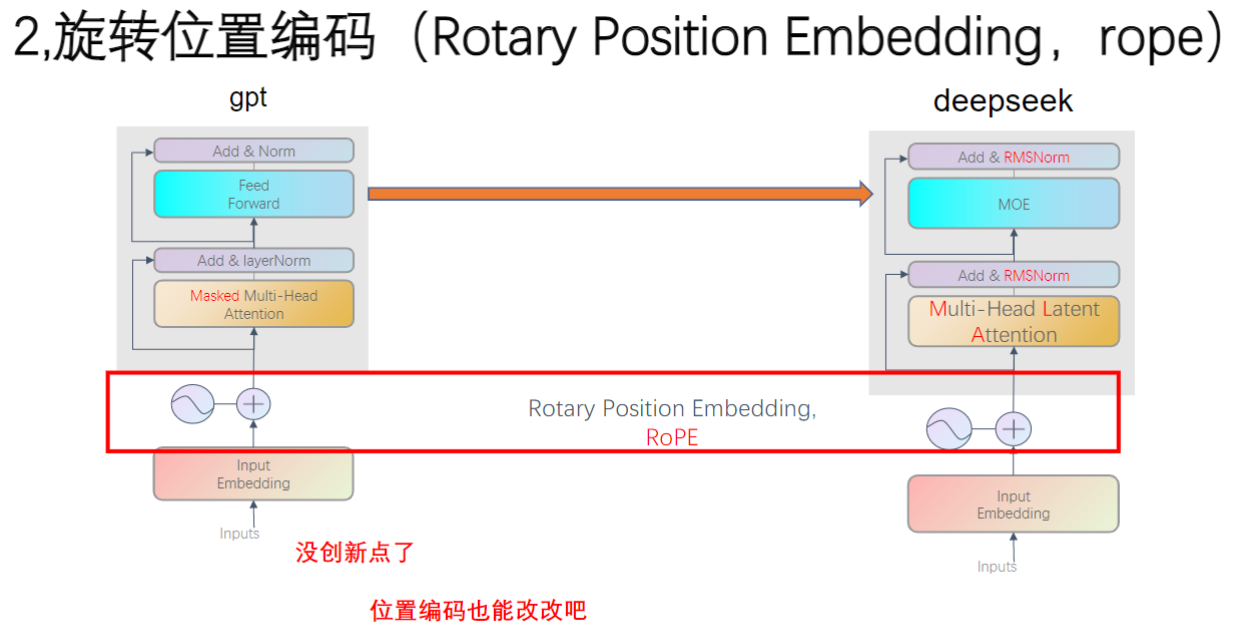
1)原始位置编码回顾
- 实现方式:将位置序号(1,2,3...)通过变换转化为向量形式,直接加到token的向量表示上
- 局限性:简单相加的方式难以有效捕捉长距离的相对位置关系
2)旋转位置编码的原理
- 核心思想:通过正交矩阵对query和key向量进行旋转操作
- 应用对象:专门作用于注意力机制中的Q和K向量
- 维度处理:对token向量的每个维度(如768维/2048维)都进行独立旋转
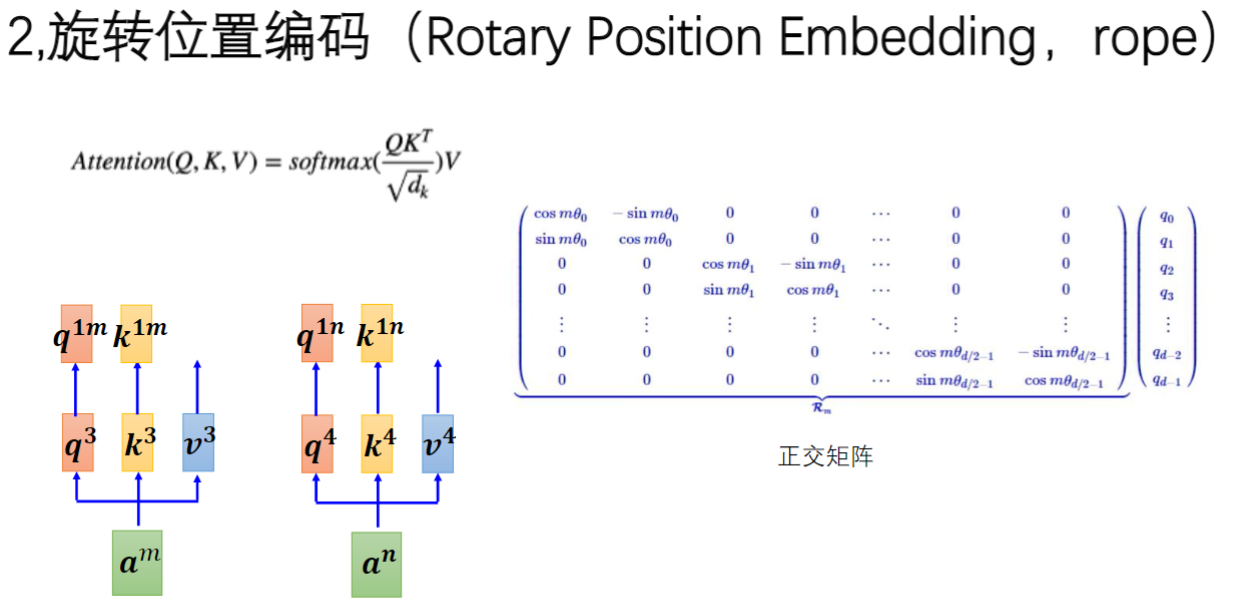
3)旋转位置编码的矩阵乘法与角度旋转
- 数学实现:使用包含cos和sin函数的正交矩阵R(m)进行乘法运算
- 位置关联:旋转角度m与token的位置序号直接相关(如第5个token对应
R(5)R(5)R(5)
- 运算特性:每个token的向量表示会随位置不同而旋转不同角度
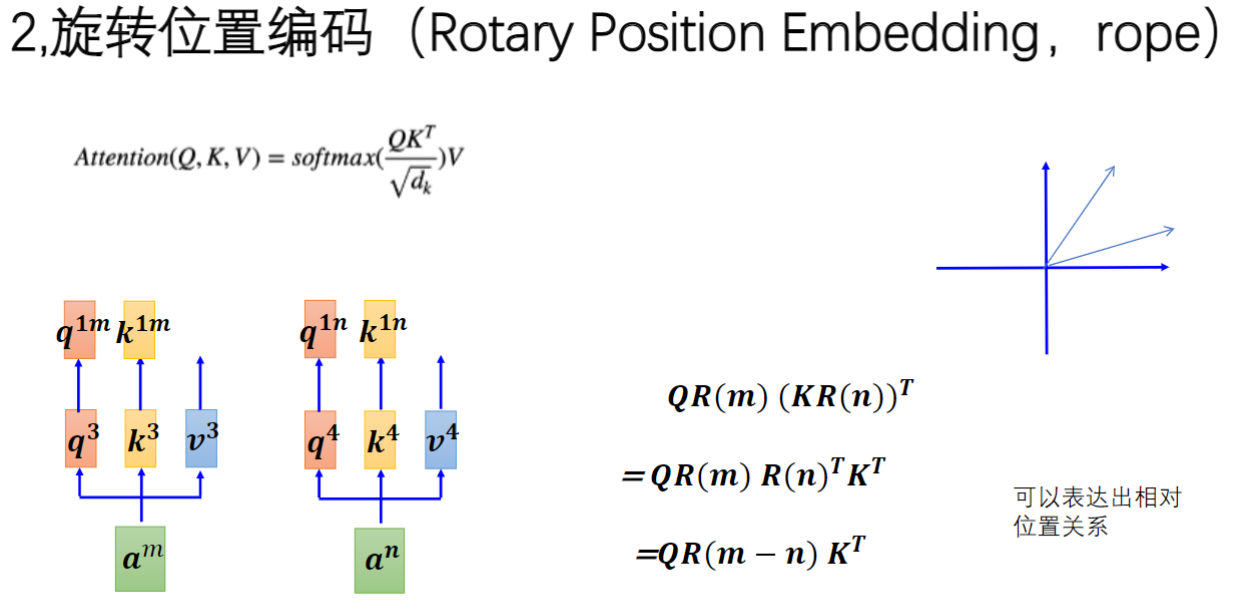
4)旋转位置编码的相对位置关系表达
- 关键公式:
QR(m)(KR(n))T=QR(m−n)KTQR(m)(KR(n))^T = QR(m-n)K^TQR(m)(KR(n))T=QR(m−n)KT
- 正交性质:利用正交矩阵
R(n)T=R(n)−1R(n)^T = R(n)^{-1}R(n)T=R(n)−1
的特性实现位置差转换 - 优势体现:能精确表达任意两个token之间的相对位置关系(如第1个和第1000个token的位置差)
- 敏感度提升:相比原始编码对长距离位置关系更敏感,每个维度都参与位置关系计算
5)旋转位置编码的性能与理论补充
- 实践验证:性能优势是采用该方法的直接原因,理论解释多为后续补充
- 实现细节:一个token的向量会产生768个不同旋转角度
- 效果保证:多维度的旋转差异共同保证了位置关系的精确表达
6. 多头潜在注意力
1)多头注意力机制变为MLA的原因
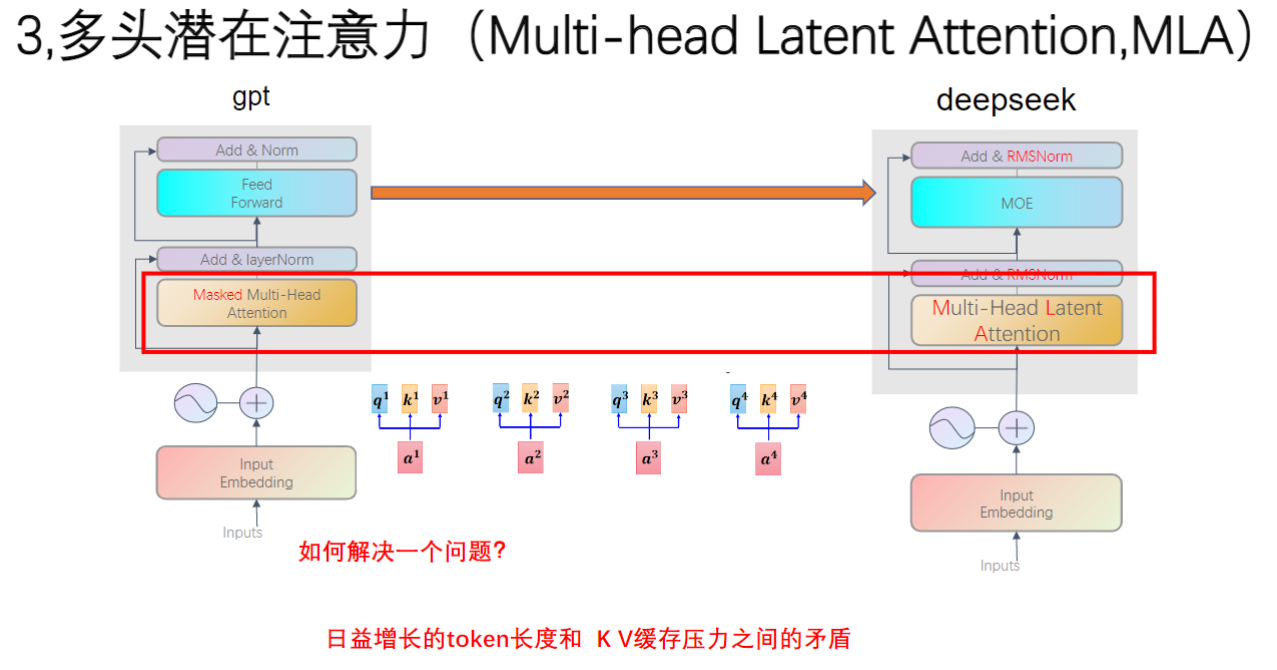
- 问题背景:处理超长序列(百万级token)时传统MHA效率低下
- 主要矛盾:token长度增长与KV缓存存储需求的矛盾
- 改进目标:将Multi-Head Attention改进为Multi-head Latent Attention
2)KV缓存的介绍
- 生成特点:推理阶段采用自回归方式逐token生成
- 计算模式:每个新token需要与之前所有token计算注意力
- 典型场景:如生成"start→我→爱→你"时需进行4次渐进式计算
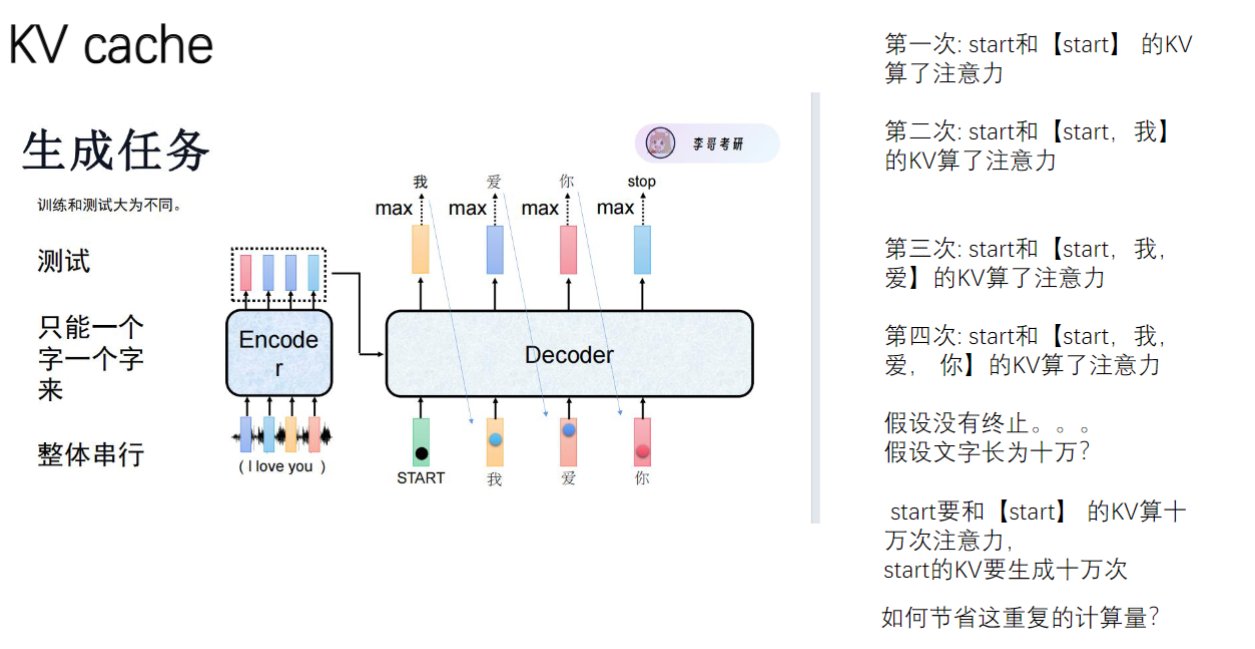
3)KV缓存重复计算的问题
- 计算冗余:首token("start")需要与后续每个扩展序列重复计算
- 数量级问题:10万token长度时单个token需计算10万次注意力
- 资源消耗:每次计算都涉及768维向量的矩阵运算,计算代价高昂
5)KV缓存的存储方式
- 存储内容:保留历史token的Key和Value向量
- 查询机制:每次只计算新token的Query向量
- 实现方式:将K和V的线性变换结果缓存复用

6)KV缓存的存储位置及问题
- 存储位置:必须保存在GPU显存中以保证快速访问
- 显存压力:长序列会导致显存被完全占满
- 核心矛盾:缓存效率与显存容量之间的平衡问题
7. KV cache的优化
1)计算优化:Multi-query与Group-query
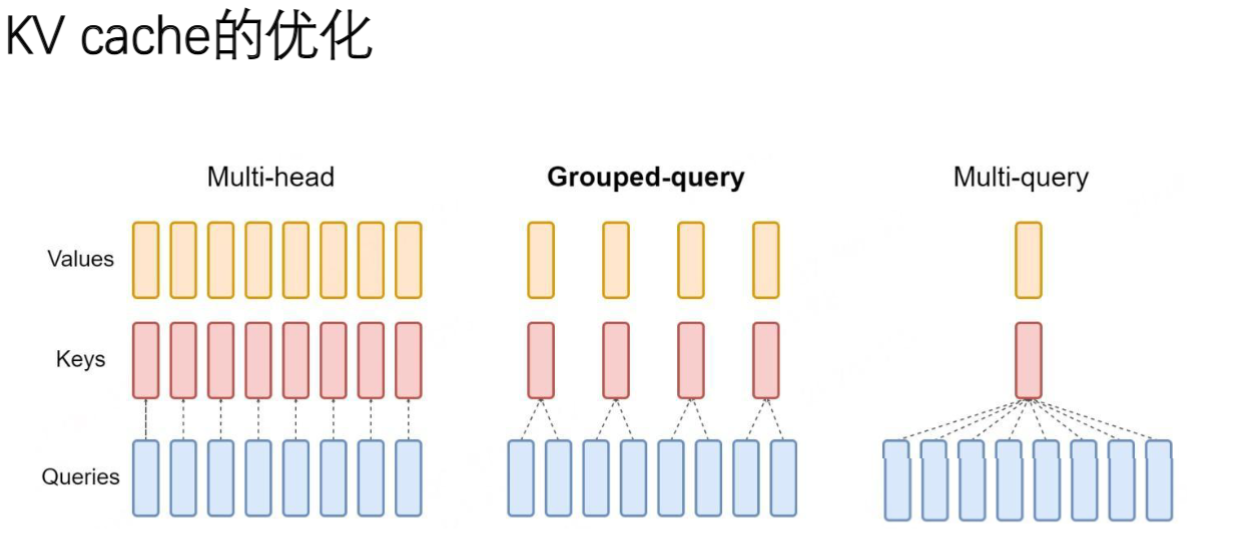
- Multi-head Attention原始机制:每个token都会生成独立的
Q,K,VQ,K,VQ,K,V
矩阵,计算时需要每个Q与所有K计算注意力权重,再与所有V相乘得到结果 - Multi-query Attention(MQA)创新:所有token共享同一组K和V,仅保留不同的Q。例如10万个token原本需要生成10万组KV,优化后只需1组,计算量大幅降低
- Group-query折中方案:采用分组共享机制(如10个token共用1组KV),在计算效率和模型性能间取得平衡。相比MQA能保留更多语义信息
- 关键记忆点:MQA是极端优化方案(1组KV),Group-query是实用方案(n组KV),考试需准确说出术语名称
2)硬件限制:显卡通信带宽问题
- 单卡限制:显存容量不足时,单纯增加显卡数量不可行
- 通信瓶颈:卡间通信带宽 << 卡内通信带宽。数据在模型各层间传递时(如第1层在卡A,第2层在卡B),跨卡传输延迟极高
- 临界问题:当显卡数量超过4张时,可能出现数据无法同步导致训练失败
- 本质矛盾:大模型训练的主要瓶颈从参数调优转变为通信协调,这是底层硬件限制带来的新挑战

3)大模型训练的通信挑战
- 编程困境:无法通过Python等高级语言解决卡间通信问题,需要底层硬件调度方案
- 实践经验:超过4卡配置时,需要专门设计模型并行方案,包括:
- 计算任务分配(哪些层在哪些卡)
- 数据传输同步机制
- 容错处理方案
8. LOW-RANK ADAPTATION(LORA)
1)低秩适配器概念引入
- 核心思想:通过低秩矩阵分解来近似表示高维参数更新量
ΔW\Delta WΔW
- 术语解析:"低秩"指矩阵的有效维度远小于其实际尺寸
2)例题1:矩阵存储与参数更新问题
- 题目解析
- 存储需求:
10000×1000010000 \times 1000010000×10000
矩阵需要1亿存储空间 - 参数更新量:更新全连接层
Linear(10000,10000)\operatorname{Linear}(10000,10000)Linear(10000,10000)
需要计算1亿个参数 - 关键矛盾:直接存储/计算
ΔW\Delta WΔW
成本过高
- 存储需求:
3)低秩适配器原理(本就是用两个低秩矩阵表示一个高秩矩阵)

- 数学原理:将
ΔW\Delta WΔW
分解为两个低秩矩阵乘积:(10000,x)@(x,10000)(10000, x) @ (x, 10000)(10000,x)@(x,10000)
- 极端案例:当
x=1x=1x=1
时,只需计算10000×1+1×10000=2000010000 \times 1 + 1 \times 10000 = 2000010000×1+1×10000=20000
个参数 - 效果对比:参数量从1亿降至2万,实现5000倍的存储/计算节省
4)低秩适配器参数计算与节省效果
- 秩的选择:实际应用中x通常取8/10/256等值,仍远小于原始维度
- 近似本质:用两个秩为x的矩阵近似表示秩为10000的矩阵,属于有损压缩
5)低秩适配器现实应用与参数x取值
- 典型场景:用于修改大模型的Feed-forward层
- 模块化特点:LORA模块(
ΔW\Delta WΔW
)与原始模型参数分离存储 - 实际效果:10GB的原始模型可能只需添加几MB的LORA模块即可实现功能调整
9. MLA
1)MHA与MQA的介绍
- MHA特点:
- 需要存储所有token的KV值,显存压力大
- 计算公式:
attention=softmax(QKTd)Vattention = softmax(\frac{QK^T}{\sqrt{d}})Vattention=softmax(dQKT)V
- MQA改进:
- 只存储一个token的KV值,所有head共享
- 显存消耗降低为原来的1/N(N为token数量)
- 存储原理:
- 传统方法:直接存储KV矩阵
- MLA方法:存储低维矩阵
CKV=XWDKVC^{KV}=XW^{DKV}CKV=XWDKV
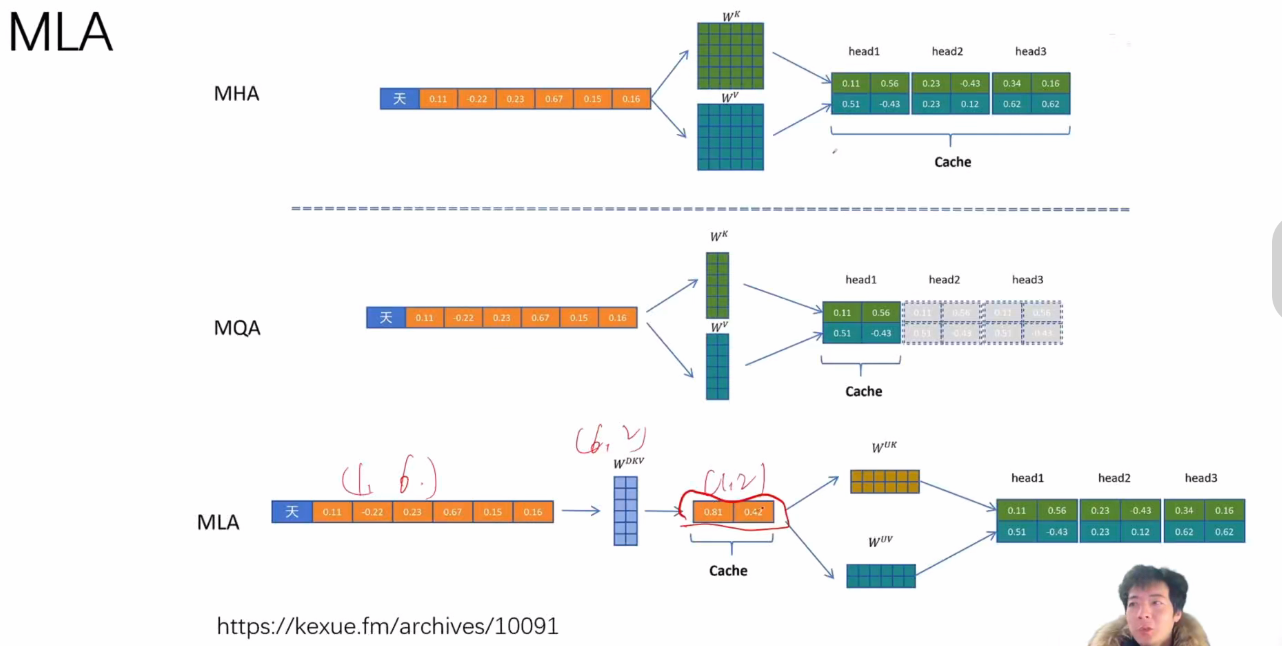
2)MLA的原理:低维矩阵的构建与应用
- 维度转换:
- 原始向量:768维
- 通过一个特殊矩阵
WDKVW^{DKV}WDKV
转换为6×2的低维矩阵
- 计算过程:
-
K=CKVWUKK = C^{KV}W^{UK}K=CKVWUK
-
V=CKVWUVV = C^{KV}W^{UV}V=CKVWUV
-
- 优势:
- 只存储(1,2)的矩阵
CKVC^{KV}CKV
而非完整KV,显著减少存储需求 - 计算时动态生成K和V
- 只存储(1,2)的矩阵
3)当前token与之前token的Q、K、V计算
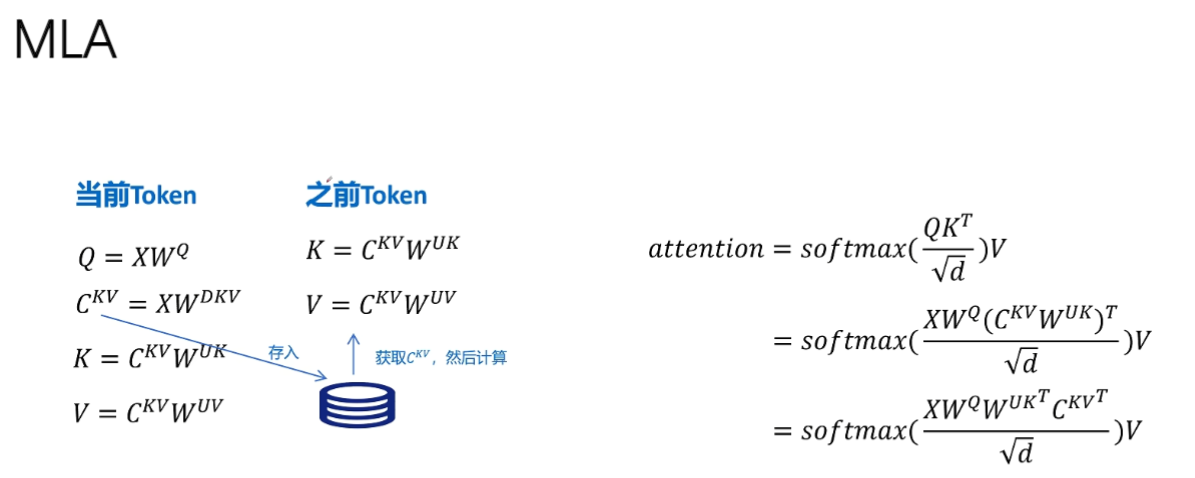
4)MLA减少计算量的原理
- 传统计算:
- 需要完整计算并存储KV
- 每次attention都要重新计算
- MLA优化:
- 存储低维
CKVC^{KV}CKV
- 通过矩阵乘法动态生成K/V
- 存储低维
- 关键改进:
- 避免直接计算和存储高维KV矩阵
- 利用
WUKW^{UK}WUK
和WUVW^{UV}WUV
进行维度转换
5)矩阵吸收:MLA减少计算量的关键
- 矩阵吸收机制:通过缓存
CKVC^{KV}CKV
直接获取中间计算结果,避免重复计算K和V矩阵。具体流程:- 计算
Q=XWQQ = XW^QQ=XWQ
- 从缓存获取
CKVC^{KV}CKV
后计算K=CKVWUKK = C^{KV}W^{UK}K=CKVWUK
- 使用相同
CKVC^{KV}CKV
计算V=CKVWUVV = C^{KV}W^{UV}V=CKVWUV
- 计算
- 运算简化原理:将传统注意力公式
softmax(QKTd)Vsoftmax(\frac{QK^T}{\sqrt{d}})Vsoftmax(dQKT)V
转化为softmax(XWQWUKTCKVTd)Vsoftmax(\frac{XW^QW^{UK^T}C^{KV^T}}{\sqrt{d}})Vsoftmax(dXWQWUKTCKVT)V
,减少KV矩阵的重复计算。
四、Deepseek中的MLA
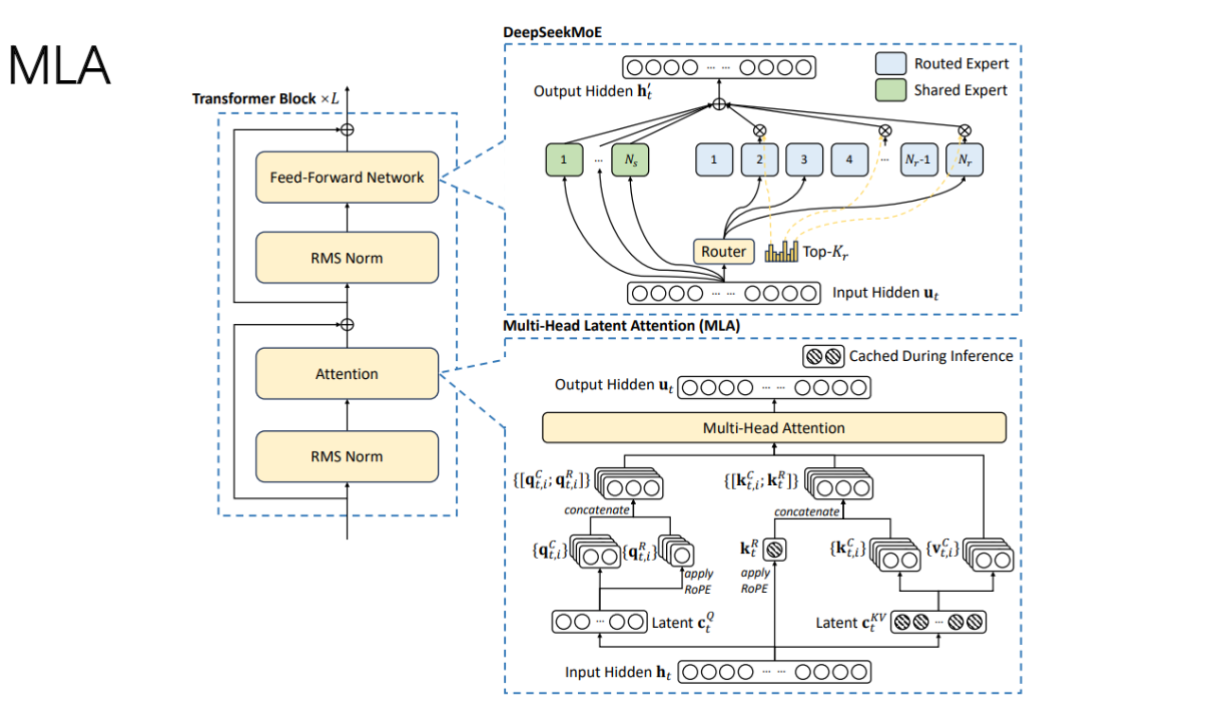
- 核心问题:传统RoPE(旋转位置编码)计算
QR(m)R(n)TKTQR(m)R(n)^TK^TQR(m)R(n)TKT
会破坏矩阵吸收的简化效果 - 解决方案:
- 将Q和K拆分为两部分处理:
- 90%直接使用缓存(不加RoPE)
- 10%进行完整RoPE计算
- 最终拼接形成新的
QnewQ_{new}Qnew
和KnewK_{new}Knew
- 将Q和K拆分为两部分处理:
- 实现细节:
- 输入隐藏层
hth_tht
经过RMS Norm标准化 - 并行处理:
- 常规注意力路径
- 带缓存处理的MLA路径
- 两路结果拼接后输出
- 输入隐藏层
- 设计优势:在保持位置感知能力的同时,显著减少计算量约90%
五、激活函数
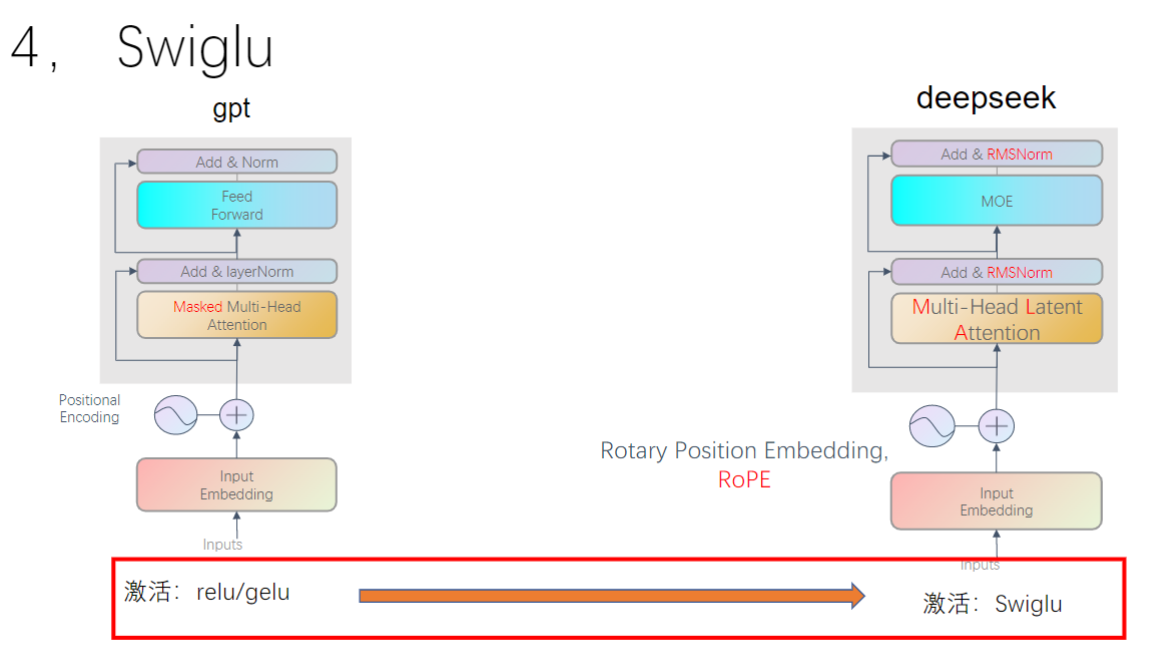
1. 激活函数概述

- 发展历程:从ReLU到Swish/SiLU再到GLU系列,最后发展为SwiGLU
- 核心思想:通过门控机制控制信息流通量,类似三极管的电压控制原理
2. Sigmoid激活函数
- 公式:
σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1
- 特性:
- 输出范围(0,1),适合概率输出
- 存在梯度消失问题
- 图像特征:S型曲线,平滑过渡
3. Swish/SiLU激活函数
- 公式:
Swishβ(x)=x1+e−βx\operatorname{Swish}_\beta(x) = \frac{x}{1 + e^{-\beta x}}Swishβ(x)=1+e−βxx
- 特殊形式:
- 当
β=1\beta=1β=1
时等同于xσ(x)x\sigma(x)xσ(x)
-
Swish1(x)=x1+e−x\operatorname{Swish}_1(x) = \frac{x}{1 + e^{-x}}Swish1(x)=1+e−xx
- 当
- 优势:相比ReLU具有平滑过渡特性
4. GLU激活函数
- 公式:
GLU(x,W,V)=σ(xW)⊗(xV)GLU(x,W,V) = \sigma(xW) \otimes (xV)GLU(x,W,V)=σ(xW)⊗(xV)
- 创新点:
- 首次引入可学习参数W和V
- 通过sigmoid实现门控功能
- 工作原理:类似三极管,控制信息通过量
5. SwiGLU激活函数
- 公式:
SwiGLU(x)=(xW1+e−xW)⊗(xV)SwiGLU(x) = (\frac{xW}{1 + e^{-xW}}) \otimes (xV)SwiGLU(x)=(1+e−xWxW)⊗(xV)
- 改进:
- 用Swish替代原始sigmoid门控
- 保持GLU的参数化特性
- 实际应用:现代大模型常用激活方案
六、归一化方法
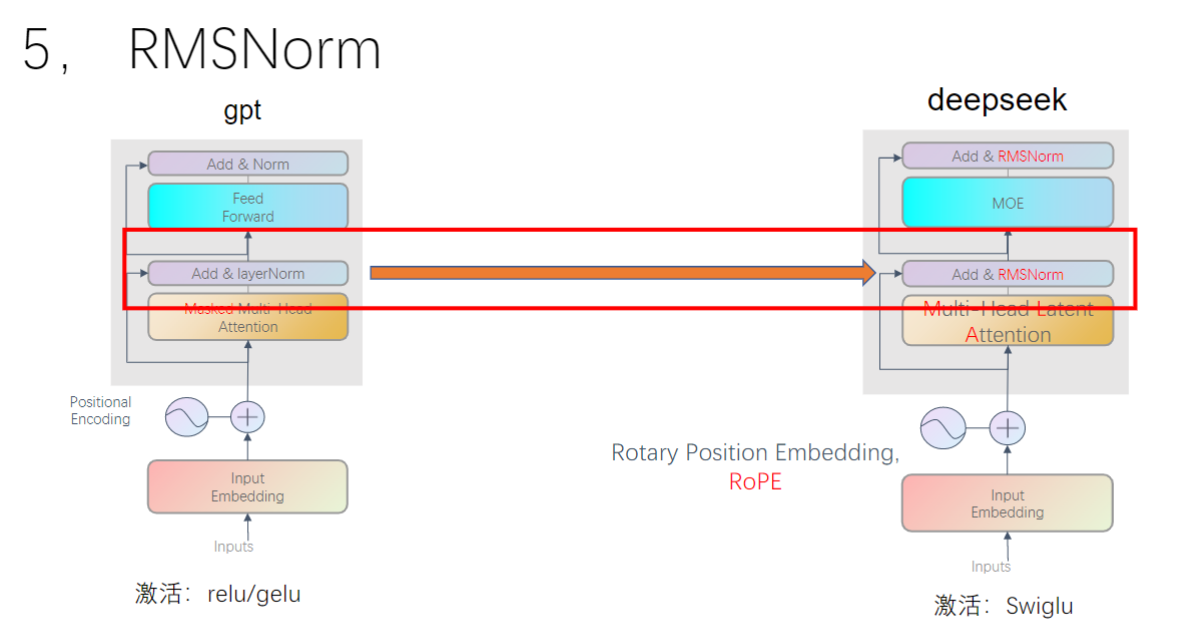

1. Batch Norm
- 公式:
y=γ⋅x−μσ2+ϵ+βy = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \betay=γ⋅σ2+ϵx−μ+β
- 特点:
- 在批次维度上计算统计量
- 适合图像等单样本数据
2. Layer Norm
- 公式:与Batch Norm相同但计算维度不同
- 优势:
- 对单个样本的所有token进行归一化
- 特别适合Transformer架构
3. RMS Norm
- 简化公式:
y=γ⋅x1n∑i=1nxi2+ϵy = \gamma \cdot \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^n x_i^2 + \epsilon}}y=γ⋅n1∑i=1nxi2+ϵx
- 创新点:
- 不再减去均值
- 仅进行缩放操作
- 稳定性:通过
ϵ\epsilonϵ
防止除零错误
七、大模型的训练(训练改变)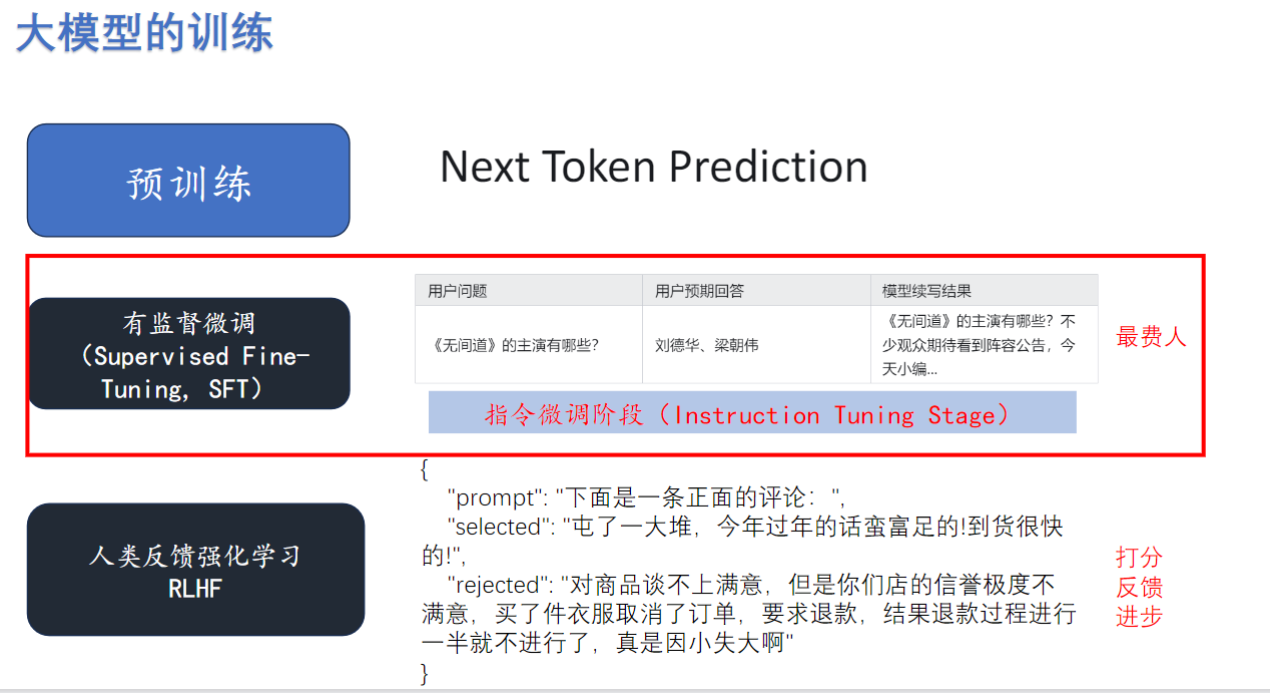
1. 预训练(未变)
- 核心方法: 采用Next Token Prediction(NTP)方式,通过大规模无标注数据进行自监督学习
- 训练特点: 仅预测下一个token,模型参数通过海量数据训练得到基础语言理解能力
- 资源消耗: 最耗费计算资源的阶段,需要大量GPU集群和训练时间
2. 有监督微调(新增)
1)数据集的改造
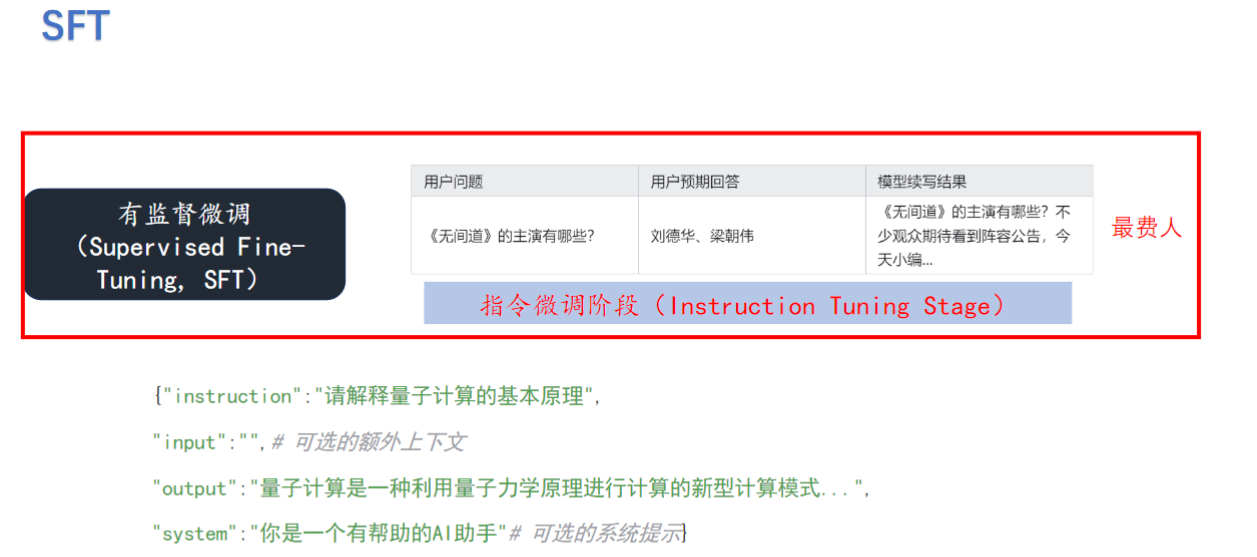
- 结构特点: 包含instruction-input-output三元组,如{"instruction":"解释量子计算","output":"量子计算是利用量子力学..."}
- 改造需求: 需要人工将原始数据改造成结构化格式,没有现成的天然数据集
- 训练方法: 仍采用NTP方式,与预训练相同但使用标注数据
2)应用案例

- 例题:简单问答任务示例
- 改造过程: 将"法国首都是哪里?巴黎"改造成{"instruction":"法国首都是哪里?","output":"巴黎"}
- 关键区别: 需要显式标注instruction和output的对应关系
- 实际应用: 电商客服对话改造为[{"role":"system","content":"客服助手"},{"role":"user","content":"订单状态"},{"role":"assistant","content":"已发货"}]格式
3. 指令微调阶段

- 核心工作: 人工构造高质量的指令-输出对,是最耗费人力的阶段
- 数据示例: 包括简单问答、翻译任务、数学推理等多种类型
- 质量要求: 需要确保指令明确、输出准确,覆盖多样化场景
4. 强化学习
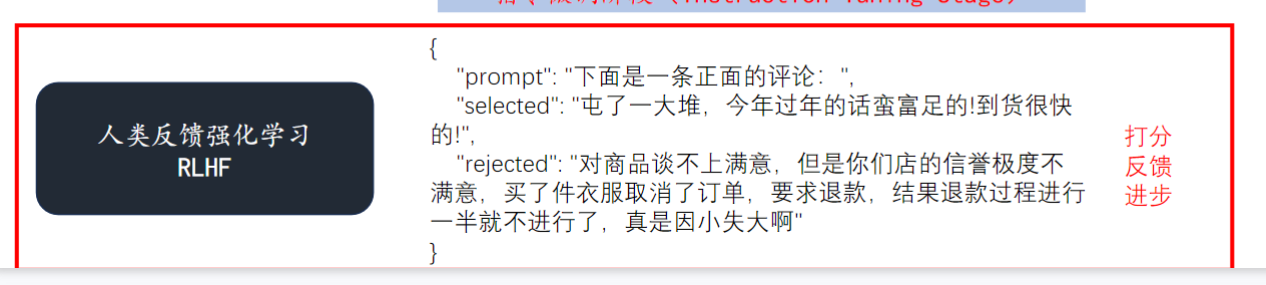
1)损失函数优化

- 基本流程:
- 输入相同prompt生成多个响应
- 人工对响应进行偏好排序
- 使用PPO算法优化模型
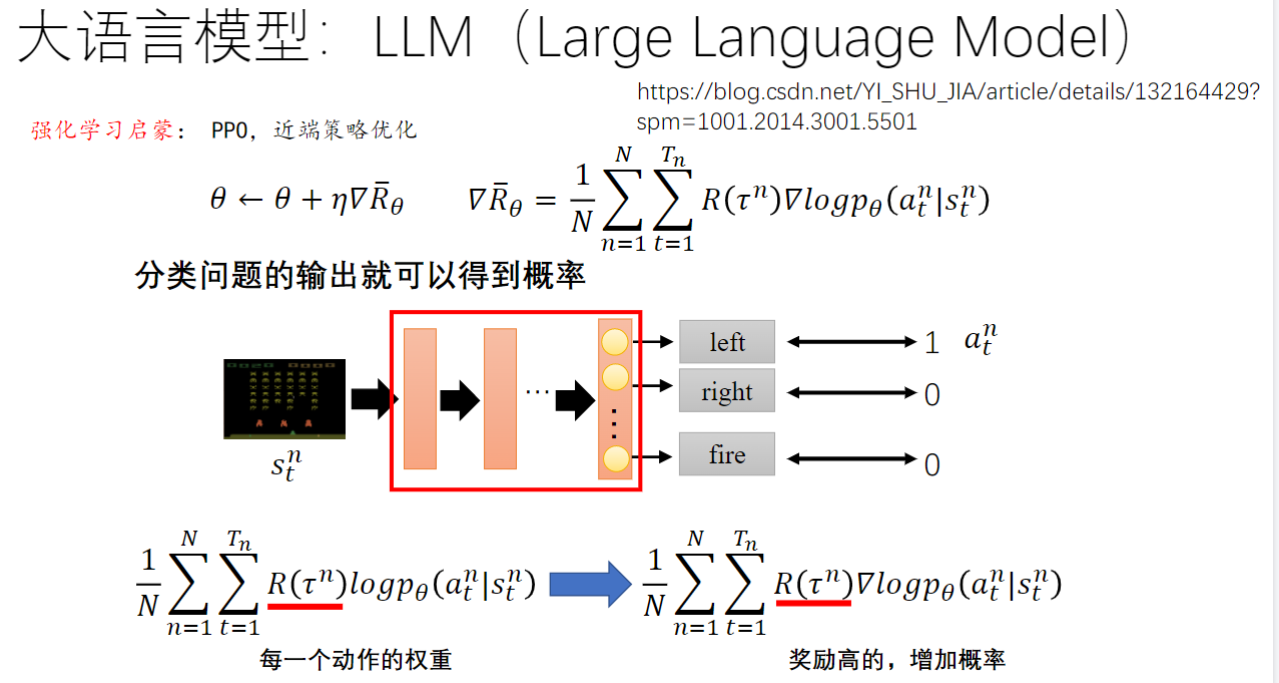
- 算法原理: 采用近端策略优化(PPO),更新公式为
θ←θ+η∇Rˉθ\theta \leftarrow \theta + \eta \nabla \bar{R}_\thetaθ←θ+η∇Rˉθ
- 奖励机制: 通过人类反馈构建奖励函数,高奖励动作的概率会被增强
- 技术特点: 将NLP任务转化为强化学习问题,使用
R(τn)logpθ(atn∣stn)R(\tau^n)\log p_\theta(a_t^n|s_t^n)R(τn)logpθ(atn∣stn)
作为梯度权重
八、总结
- 技术演进: 当前架构(RoPE、MoE等)并非理论最优,而是实验验证的有效方案
- 实践局限: 普通研究者难以从头训练大模型,主要进行微调工作
- 未来方向: 模型改进仍存在大量探索空间,新架构可能带来突破
九、知识小结
|
知识点 |
核心内容 |
技术要点/关键改进 |
难度系数 |
|
Transformer架构基础 |
Encoder-Decoder结构,BERT与GPT的区别 |
BERT使用双向编码器,GPT仅用解码器 |
⭐⭐ |
|
大模型核心改进 |
六大结构变化提升模型性能 |
激活函数→SwishGLU,位置编码→RoPE,注意力机制→MLA,前馈网络→MoE,归一化→RMS Norm |
⭐⭐⭐⭐ |
|
混合专家模型(MoE) |
动态路由机制实现计算量优化 |
稀疏激活(仅激活部分专家)、负载均衡损失函数、常驻专家+动态专家组合 |
⭐⭐⭐⭐ |
|
旋转位置编码(RoPE) |
相对位置关系的矩阵旋转表示 |
正交矩阵乘法实现位置敏感,qk计算时引入相对位置差 |
⭐⭐⭐ |
|
多头潜在注意力(MLA) |
KV缓存压缩技术 |
低秩分解存储CKV,矩阵吸收优化,RoPE兼容性处理 |
⭐⭐⭐⭐ |
|
训练三阶段 |
NTP→SFT→RLHF渐进式优化 |
指令微调需人工重构数据,RLHF采用PPO算法+人类评分 |
⭐⭐⭐⭐ |
|
强化学习(RLHF) |
近端策略优化(PPO)实现 |
奖励函数设计,情景-动作概率建模,策略梯度更新 |
⭐⭐⭐⭐ |
|
关键技术对比 |
传统Transformer vs 大模型架构 |
计算量减少80%(MoE),长序列处理能力提升(RoPE),显存优化(MLA) |
⭐⭐⭐ |
|
行业现状 |
计算资源瓶颈与创新方向 |
多卡通信成本成为主要瓶颈,中国AI算力受限催生算法创新 |
⭐⭐ |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)