李沐课代码部分——续集
十二、权重衰退
之所以我们要利用权重衰退,本质上来说就是为了提防这样的情况出现:
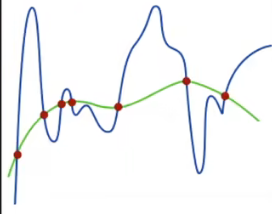
解释一下的话就是——明明能非常“优雅”地只是用较为平滑但变化幅度不会太大的曲线就可以把这7个点全部串起来,但倘若我们不对w这个权重进行限制,我们的模型很容易【对一道非常简单的题玩出花来】(换句话说就是把一些数据学到根本没必要达到的程度。用较为专业的措辞就是——过拟合)
公式展示如下:
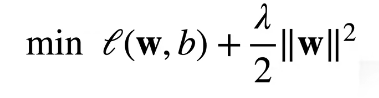
完整代码展示:
import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
# from torch import nn
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
"""---------------- 1. 合成数据 ----------------"""
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5# 200表示200维
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = synthetic_data(true_w, true_b, n_train)
test_data = synthetic_data(true_w, true_b, n_test)
train_iter = d2l.load_array(train_data, batch_size)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
"""---------------- 2. 初始化参数 ----------------"""
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
"""---------------- 3. L2 惩罚 ----------------"""
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
"""---------------- 4. 训练函数 ----------------"""
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
with torch.no_grad():
train_loss = d2l.evaluate_loss(net, train_iter, loss)
test_loss = d2l.evaluate_loss(net, test_iter, loss)
animator.add(epoch + 1, (train_loss, test_loss))
print('w的L2范数是:', torch.norm(w).item())
plt.show()
"""---------------- 5. 运行实验 ----------------"""
train(lambd=0) # 无正则化——过拟合
train(lambd=3) # 有权重衰退——泛化更好具体机制解析:
1. 合成数据中的* 0.01——是对我们生成的w这个200行1列的向量中的每个1通过这个广播机制乘以0.01
2. l2_penalty函数中的算法:是L^2范数,或者说是L2范数的计算公式——之所以这样写,是因为方便后续求导(train函数)时直接消掉下面的式子里w前的系数
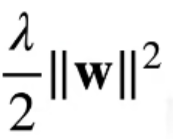
||w|| = √(Σwᵢ²)
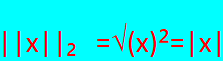
3. train函数的解析:
1. w, b = init_params()
是调用我们前面定义的函数,用于初始化超参数
2. net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
这是python的一个语法糖,用于临时定义一个函数而不费地方(内存),让我们只需要一行便可以定义一个急需用的函数。它等价于如下形式——
def net(X):
return d2l.linreg(X, w, b)
loss = d2l.squared_loss
这行代码大家应该很熟悉,虽然看起来有点区别。它本质上就是这样的——
def squared_loss(y_hat, y):
return (y_hat - y.reshape(y_hat.shape)).pow(2) / 2 # 依旧是除以二以便后续求导(梯度下降)时消掉2这个系数
4. animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
xlim = [5, num_epochs]的意思是我们只画第5轮之后的答案,前面的因为波动太大所以不画
5. for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w) # 公式的代码形式,是整个训练的核心
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
with torch.no_grad():
train_loss = d2l.evaluate_loss(net, train_iter, loss)
test_loss = d2l.evaluate_loss(net, test_iter, loss)
animator.add(epoch + 1, (train_loss, test_loss))
print('w的L2范数是:', torch.norm(w).item())
这部分是真正开始训练的循环,with用法表示临时禁止在构建计算图时传梯度,换句话说就是提高我们的安全性。然后就是到animator上面,我们每跑一组数据就把损失结果画在图上,然后打印出来此时的w的L2范数是多少,最后通过plt.show()将图画出来
十三、丢弃法
它是跟权重衰退不一样的提升模型鲁棒性的方法。
完整代码展示:
import torch
from torch import nn
from d2l import torch as d2l
from matplotlib import pyplot as plt
"""1. 定义丢弃函数"""
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
"""之所以写assert是因为要提前拦截非法输入"""
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.Tensor(X.shape).uniform_(0, 1) > dropout).float()
# mask是一个与X形状相同的张量,其值来自伯努利分布
return mask * X / (1.0 - dropout)
"""2. 初始化数据"""
num_inputs, num_outputs, num_hidden1, num_hidden2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
"""3. 定义神经网络"""
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hidden1, num_hidden2, is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hidden1)
self.lin2 = nn.Linear(num_hidden1, num_hidden2)
self.lin3 = nn.Linear(num_hidden2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用丢弃法
if self.training: H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training: H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
"""4. 初始化网络"""
net = Net(num_inputs, num_outputs, num_hidden1, num_hidden2)
"""5. 训练网络"""
if __name__ == '__main__':
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
plt.show()具体机制解析:
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
"""之所以写assert是因为要提前拦截非法输入"""
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.Tensor(X.shape).uniform_(0, 1) > dropout).float()
# mask是一个与X形状相同的张量,其值来自伯努利分布
return mask * X / (1.0 - dropout)
1. assert的用法,其实我们从后续紧跟着的不等式可以推断出——是保证dropout这个变量【对应数学里的p这个概率】的值在0到1之间,实际上assert的用法也是如此
2. mask的用法,不是掩码,而是一种布尔判断(一样通过后续的内容推断出来)
具体分点来说就是:
1. 先创建一个跟X形状相同的新张量(未初始化的)
2. .uniform_(0, 1):是对这个我们刚创建的新张量通过原地操作(in-place)填充[0, 1)区间内(注意!是左闭右开区间!)
3. >dropout的判断:大于则为True,反之则为False,比如dropout = 0.4,那么0.6的位置为True——每个神经元保留的概率为70%
换句话说,我们原来就是通过.uniform_(0, 1)来实现“抽奖”(创建奖池),然后每个神经元【虽然不是它自己抽,但程序会替神经元决定去留——通过如上所述的“抽奖”】通过>dropout的判断来“抽奖”,抽到比dropout大的话,这个神经元就保留,反之则丢弃。
4. .float()的转变:毕竟我们整个模型训练都涉及到梯度下降、参数更新……所以还是转成float省事,万一有隐性的数据格式兼容问题呢是不是?所以,还是转成float更省心。
def __init__(self, num_inputs, num_outputs, num_hidden1, num_hidden2, is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hidden1)
self.lin2 = nn.Linear(num_hidden1, num_hidden2)
self.lin3 = nn.Linear(num_hidden2, num_outputs)
self.relu = nn.ReLU()
在解释整个类之前,我要先说明一点:这里的Net类,是有继承nn.Module这个父类的
这就涉及到super的用法了——super(Net, self)返回一个代理对象,代表着它继承的nn.Module父类,它后面加的.__init__()这个方法实际上就是继承自nn.Module这个父类所有的方法
之后的就是线性层——nn.Linear(num_inputs, num_hidden1)就是在定义一个全连接层
格式如下:nn.Linear(in_features, out_features)
其中的in_features必须匹配上一层的输入,out_features是输入到下一层的输出或者是最后的输出(如果没有下一层的话)
最后一行的 self.relu = nn.ReLU()就是在定义激活函数(用ReLU函数——![]() )
)
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用丢弃法
if self.training: H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training: H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
这个函数就是在复现这段表达:
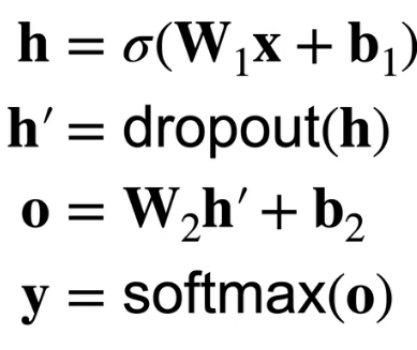
loss = nn.CrossEntropyLoss(reduction='none')
这就是交叉熵(损失)的表达形式——cross-Entropy(loss)(封装为函数版)
关于reduction的讲解——
reduction 值 |
行为 | 返回形状(假设 batch_size=N) |
|---|---|---|
'mean'(默认) |
对所有样本损失求平均 | 标量([] 或 torch.Size([])) |
'sum' |
对所有样本损失求和 | 标量 |
'none' |
不汇总,保留每个样本的损失 | [N](一维张量,长度=批大小) |
net.parameters()
生成一个generator对象,是数据生成器,直接用于循环、训练中

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)