知识蒸馏11111
如何在保证模型性能同时,保持模型复杂度。引入教师网络指导学生网络进行训练,从而将教师网络丰富的知识迁移到学生网络。
将这一个模型集合的知识压缩到一个single model中,这里使用不同的压缩技术,通过将模型集合中的知识在一个single中,一种新的集合类型:两个组合 (一个或多个的full models + 专家模型-->学着去区分一些细颗粒的类别,而full models并不能区分,比如金毛,柯基)
这些专家模型可以被并行且快速的被训练

introduction
成虫/幼虫-->模型形态 大模型/小模型
大模型:冗余信息集中,提取信息/结构,允许使用大量算力,训练阶段采取
小模型:部署阶段要模型低延迟,受计算资源限制
现在训练和部署我们都采用相同的模型结构,不能很好的满足我们不同阶段的需求。
教师网络?
大模型的形态,训练阶段使用。笨重/复杂的模型-->教师模型,他可以是一种被分开训练的模型的集合或单独的模型
学生网络?
小模型的形态,部署阶段使用。
蒸馏
这个笨重/大的模型训练完成之后,采用另一种训练方式-->蒸馏,可以复杂模型中的知识迁移到小模型当中-->学生网络。
知识?
知识,不是已经训练好的模型和学习到的参数值(导致我们不知道已经训练好参数值的情况,改变模型结构)
知识是学习好的映射关系,输入向量-->映射到输出向量
soft target?
首先是target
1.所有类别都有一定概率,大小不一样而已
2.正确的类别概率更大 最大
3.相似类别拿到的概率也更大
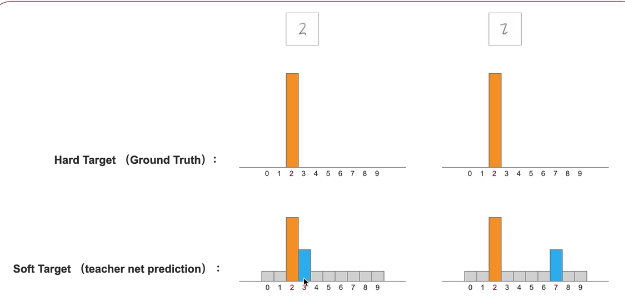
对soft target 第一个2更像3,第二个2更像7 那么对应37概率更大一些
对比hard 信息两更大 用soft target 辅助我们训练student 网络肯定更好一些
那这个soft咋得到呢?通过教师网络的预测结果作为soft target
hard target?
是有ground truth得来的 是一种one hout 的形式,比如图像的object,正确分类拿到100%概率,那么其他的都是0
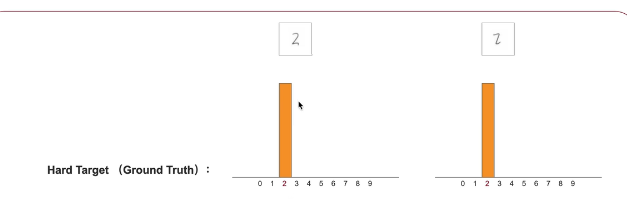
教师网络的预测结果一般是比较准确,可以看做target,所有的类别都有概率值,反应一定信息 ,用作hardtarget
温度T
soft target的弊端就是教师网络的预测结果中类别的概率能为我们提供信息,但是不对的概率接近,对于交叉熵损失函数影响很小。
所以我们的解决方案就是引入一个温度t到softmax中,使得我们通过softmax 计算出来概率值不会特别小;可以这样理解真实标签只告诉你你错了,然后正确答案是什么。一分也不会给你。教师模型会告诉你,你的结果错了,但是过程能得多少分。

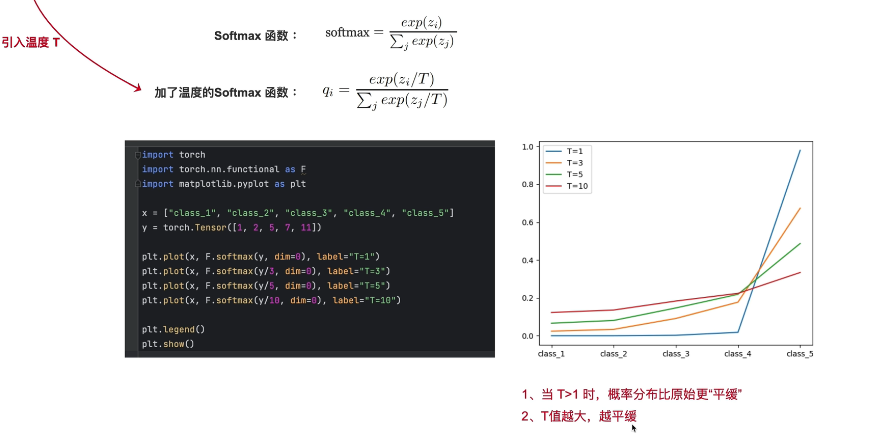
我们引入温度t之后,将t=1,3,5,10 下面的x是对应五个类别,y是对应五个类别的预测结果,就是logit,就是softmax的输入,通过softmax的操作,y分别除135,10
t=1的时候类别概率非常不平均,类别特别大的时候就变得很平缓:
t越大,原本悬殊的logits差距被压缩的越厉害,softmax的输出就越接近“均匀分布”,不会像t=1的时候出现那样0.9999vs0.0001的极端情况。
如果像之前那样平缓,那么学生模型学到的是:“这绝对是第一类,其他两类无关紧要”;如果有了高温t,那么学生模型学到的是:“主要是第一类,但是第二类也有一定的道理,第三类可能性比较小”
这就是蒸馏不仅能让小模型知道正确答案是什么,还知道各种错误答案之间的相对合理性、
损失函数的计算
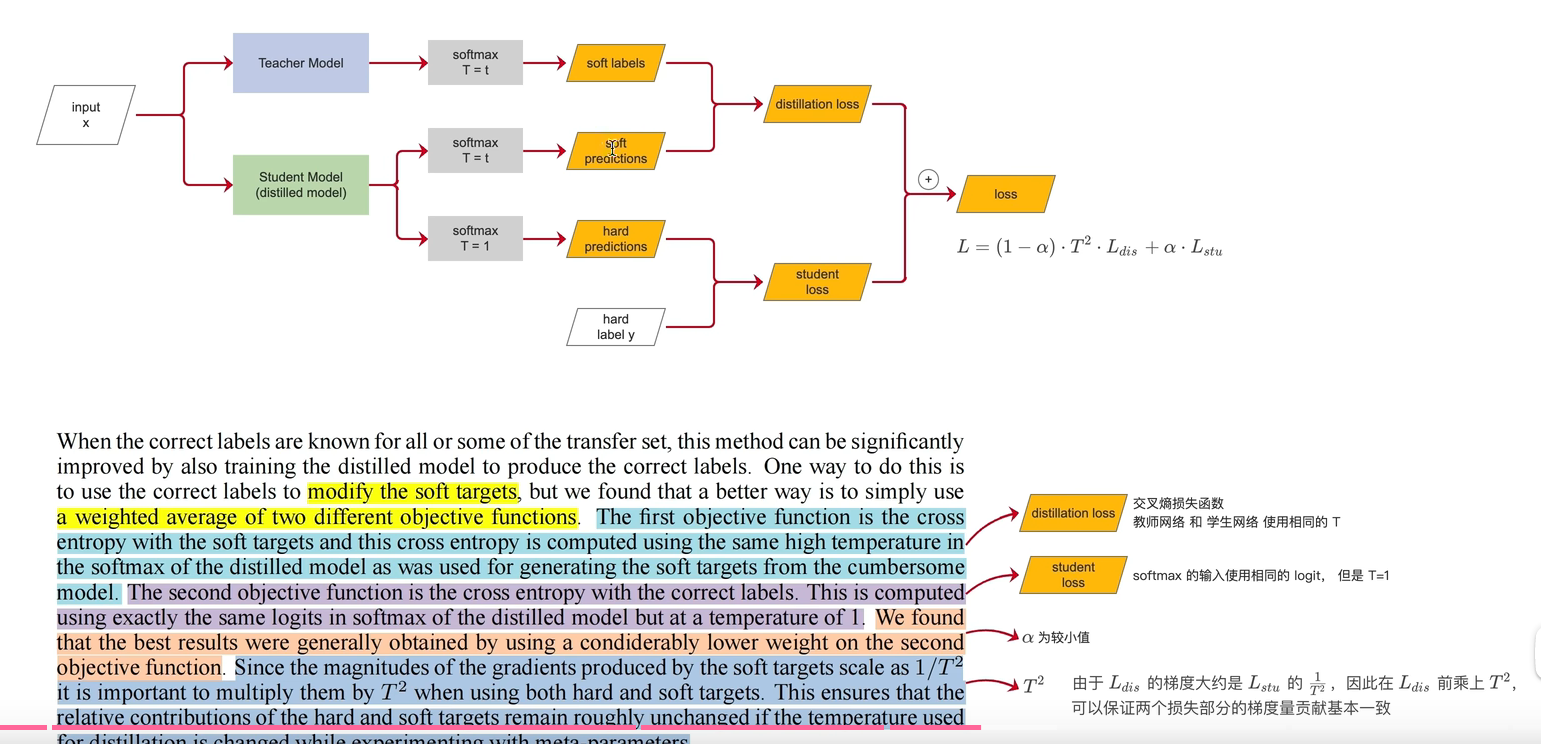
首先准备好一个已经训练好的教师网络,在准备一个数据集(可以用训练教师网络的数据集,也可以单独一个数据集),然后准备学生网络。
数据通过教师网络得到logets,让logit 通过温度t的softmax,拿到soft labels,数据通过学生网络拿到logit,让logit分别通过温度为t的softmax和温度为1的softmax,然后会拿到两个结果分别是soft predictions和hard predictions 这两个soft的预测结果,去计算distillation loss,然后用学生网络hard的预测结果和真实标签计算student loss 将这两个loss做一个加权和,拿到最终的loss值。
下面根据论文的文段看一下细节,教师网络输出soft target 给学生网络提供更多数据信息 那为啥还要使用hard predictions 去计算student loss:虽然教师网络预测结果置信度高,但是不能保证完全正确,下面使用ground truth 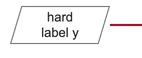 修正教师网络的错误。
修正教师网络的错误。
这里说 这两个不同的目标函数进行加权平均得到最终loss,蓝色的话再描述distillation loss就是softloss 想说明他俩使用的温度是同样t,紫色是student loss 这里是说使用的温度t 的值=1,发现第二个部分的损失函数权重小一点比较好,最后一句是说distillation loss 是student loss的t平方分之1,所以在distillation loss的前面*t平方 这样就能保证这两个部分的损失的t的梯度贡献值基本上一致,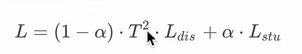 ,
,
t的取值多少合适?取适中值,太大会引入噪声,没用信息会放大,太小,本来就小的更小了,取 适中的值,一般会取20以内的值,加上温度t之后的soft targets的概率,在各个类别的分布是什么样的,在概率上体现信息 ,同时大家在概率上还有差别
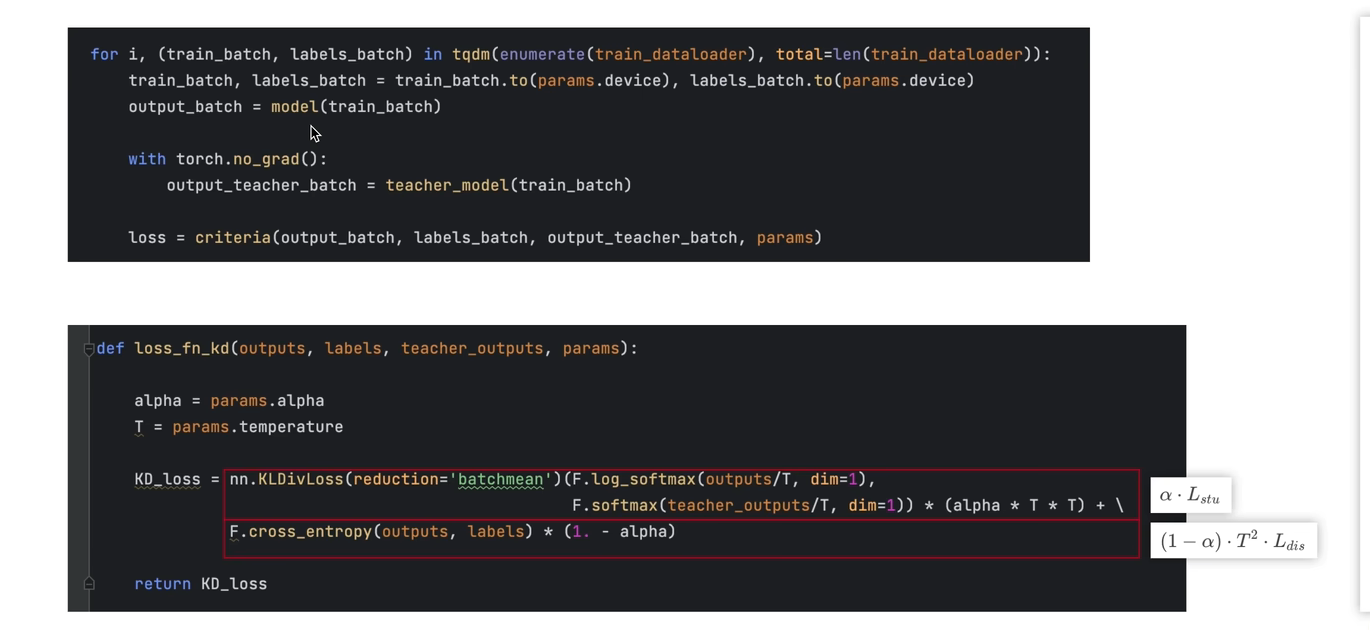
关键代码片段:
第一类两个model ,一个是model-学生网络,teacher_model-教师网络,循环中得到了训练数据和标签,这个标签就是gound truth,之后要拿来计算hard loss,拿到数据标签之后传入到学生网络和教师网络 分别收到logit,教师的参数固定不要调整。将学生网络输出logits,ground truth,教师网络输出logit,以及一些超参数params,传入损失函数中去,也就是下面的那个函数loss-fn-kd
超参数就有alpha和t 接下来就可以计算损失函数:hard 和 soft loss,solf使用KL散度
实验

resnet-50 教师网络;resnet-34 学生网络;数据集:flowers;
训练好之后我们把参数都保存下来,供我们之后去做蒸馏使用,单后单独训练resnet34,就是为了和我们蒸馏的这种方式训练出的模型,两个结果进行对比,看看准确率和蒸馏的收敛速度会不会更快些:结果如下: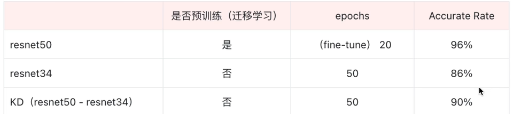 使用蒸馏方法同样训练的epochs,我们拿到的准确率是90%
使用蒸馏方法同样训练的epochs,我们拿到的准确率是90%
最后几轮代码详解:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)