yolov3学习之官方训练代码实现
以 YOLOv3(yolov3.yaml)作为模型架构,COCO128(coco128.yaml)作为数据集,并采用 416×416 输入图像尺寸为例。
训练入口是train.py的train函数,另外训练还涉及到如下文件:
(1)utils/ 目录下多个文件:
dataloaders.py → 数据加载
loss.py → 损失计算
general.py → 工具函数
torch_utils.py → 设备、EMA 等
loggers/ → 日志记录
callbacks.py → 回调机制
(2)数据与配置:
data/coco128.yaml
data/hyps/hyp.scratch-low.yaml
权重文件(.pt)
其一般训练过程如下:
训练循环开始
↓
数据加载 → 前向传播 → 损失计算
↓ ↓
梯度累积 ← 反向传播 ← 损失计算
↓
参数更新 → 学习率调整
↓
日志记录 → 模型保存
↓
下一个epoch
具体下面展开。
1 训练准备
超参数加载
if isinstance(hyp, str):
with open(hyp, errors="ignore") as f:
hyp = yaml.safe_load(f) # 加载超参数字典
LOGGER.info(colorstr("hyperparameters: ") + ", ".join(f"{k}={v}" for k, v in hyp.items()))
opt.hyp = hyp.copy() # 保存到检查点
数据加载器创建:
# 训练数据加载器
train_loader, dataset = create_dataloader(
train_path,
imgsz,
batch_size // WORLD_SIZE,
gs,
single_cls,
hyp=hyp,
augment=True,
cache=None if opt.cache == "val" else opt.cache,
rect=opt.rect,
rank=LOCAL_RANK,
workers=workers,
image_weights=opt.image_weights,
quad=opt.quad,
prefix=colorstr("train: "),
shuffle=True,
seed=opt.seed,
)
# 验证数据加载器(仅主进程)
if RANK in {-1, 0}:
val_loader = create_dataloader(
val_path,
imgsz,
batch_size // WORLD_SIZE * 2,
gs,
single_cls,
hyp=hyp,
cache=None if noval else opt.cache,
rect=True,
rank=-1,
workers=workers * 2,
pad=0.5,
prefix=colorstr("val: "),
)[0]
模型加载与配置
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # 下载权重
ckpt = torch_load(weights, map_location="cpu") # 加载检查点
model = Model(cfg or ckpt["model"].yaml, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # 创建模型
csd = ckpt["model"].float().state_dict() # FP32状态字典
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # 交集
model.load_state_dict(csd, strict=False) # 加载
LOGGER.info(f"Transferred {len(csd)}/{len(model.state_dict())} items from {weights}")
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # 从头开始创建
freeze = [f"model.{x}." for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # 要冻结的层
for k, v in model.named_parameters():
v.requires_grad = True # 默认训练所有层
if any(x in k for x in freeze):
LOGGER.info(f"freezing {k}")
v.requires_grad = False
训练组件初始化:优化器、学习率调度器、指数移动平均、损失计算器
优化器:
nbs = 64 # 名义批次大小
accumulate = max(round(nbs / batch_size), 1) # 累积梯度步数
hyp["weight_decay"] *= batch_size * accumulate / nbs # 调整权重衰减
optimizer = smart_optimizer(model, opt.optimizer, hyp["lr0"], hyp["momentum"], hyp["weight_decay"])
学习率调度器:
if opt.cos_lr:
lf = one_cycle(1, hyp["lrf"], epochs) # 余弦调度
else:
def lf(x):
"""线性学习率调度函数"""
return (1 - x / epochs) * (1.0 - hyp["lrf"]) + hyp["lrf"] # 线性
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
指数移动平均:
ema = ModelEMA(model) if RANK in {-1, 0} else None
损失计算器:
compute_loss = ComputeLoss(model) # 初始化损失类
2 训练过程
假设 batch_size = 4,输入 4 张 416×416 图像,单batch为例。
步骤 1:数据加载
pbar = enumerate(train_loader)
# 从数据加载器获取当前batch的数据
# imgs: [4, 3, 416, 416] - 批图像
# targets: [N, 6] - 标签,格式为(image_index, class_id, x, y, w, h)
# paths: 图像路径列表
步骤 2:前向传播(Forward Pass)
# 前向传播(使用混合精度训练)
with torch.cuda.amp.autocast(amp):
# 模型前向传播
pred = model(imgs) # forward,获取三个尺度的预测
# 在训练模式下,Detect层直接返回未处理的卷积输出
# 输出是包含3个张量的列表,对应P3/P4/P5三个检测层:
# pred[0]: [4, 255, 52, 52] # P3/8: 52×52网格,检测小目标
# pred[1]: [4, 255, 26, 26] # P4/16: 26×26网格,检测中目标
# pred[2]: [4, 255, 13, 13] # P5/32: 13×13网格,检测大目标
# 255 = 3 anchors × (4坐标偏移 + 1置信度 + 80类别概率)
网络处理流程:
Backbone(Darknet53):提取多尺度特征
P5: (4, 1024, 13, 13) → stride=32
P4: (4, 512, 26, 26) → stride=16
P3: (4, 256, 52, 52) → stride=8
Head(FPN-style Detection):
P5分支:卷积 → 输出 (4, 255, 13, 13)
P4分支:P5上采样 → 与P4拼接 → 卷积 → 输出 (4, 255, 26, 26)
P3分支:P4上采样 → 与P3拼接 → 卷积 → 输出 (4, 255, 52, 52)
训练与推理输出差异:
训练时:返回原始卷积输出,用于损失计算。
推理时:进行坐标解码,输出(x1, y1, x2, y2, confidence, class_id)格式。
步骤 3:损失计算(Loss Computation)
# 损失计算
loss, loss_items = compute_loss(pred, targets.to(device))
# ComputeLoss类内部的核心处理流程:
# 1. 正负样本分配(基于IoU的匹配原则):
# - 对每个真实框,确定其中心点落在哪个网格(i,j)
# - 在该网格的3个锚框中,选择与真实框IoU最大的作为正样本
# - 同一尺度的其他位置作为负样本(如果IoU<ignore_thresh)
# - 每个尺度独立进行样本分配
#
# 2. 损失计算(在编码空间进行,无需坐标解码):
# - 坐标损失:比较预测偏移量(tx,ty,tw,th)与真实偏移量
# - 置信度损失:二元交叉熵,区分前景/背景
# - 分类损失:多标签二元交叉熵,支持多标签分类
#
# 3. 损失加权与缩放(基于文档1第176-179行):
# 总损失 = hyp["box"] × L_box + hyp["obj"] × L_obj + hyp["cls"] × L_cls
# 其中损失权重会根据检测层数、类别数、图像尺寸自动缩放:
# - hyp["box"] *= 3 / nl # 按检测层数缩放
# - hyp["cls"] *= nc / 80 * 3 / nl # 按类别数和层数缩放
# - hyp["obj"] *= (imgsz / 640) ** 2 * 3 / nl # 按图像大小和层数缩放
关键说明:
损失计算在网络的输出空间进行,真实标签已被编码为偏移量格式。
采用"一个真实框匹配一个最佳锚框"的稀疏分配策略。
默认损失权重来自hyp.yaml(如box=0.05, obj=1.0, cls=0.5),但会动态调整。
步骤 4:反向传播与优化
# 反向传播(带梯度缩放)
scaler.scale(loss).backward()
# 梯度累积:累计accumulate个batch的梯度后更新一次
if (i + 1) % accumulate == 0 or i == len(train_loader) - 1:
# 1. 取消梯度缩放,准备梯度裁剪
scaler.unscale_(optimizer)
# 2. 梯度裁剪,防止梯度爆炸(最大梯度范数10.0)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0)
# 3. 参数更新
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
# 4. 更新指数移动平均模型(EMA)
if ema:
ema.update(model)
# 学习率调度(每个batch后更新)
scheduler.step()
优化器:SGD with momentum=0.937
权重衰减:0.0005
初始学习率:hyp[“lr0”](默认0.01)
学习率调度:线性或余弦退火(由opt.cos_lr控制)
步骤 5:验证(Validation)
每轮结束后,在 val 集上运行:
# 每轮训练结束后,在主进程执行验证
if RANK in {-1, 0} and not noval:
# 使用EMA模型进行更稳定的推理
results, maps, _ = validate.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=None, # 验证阶段通常不计算损失
)
# 输出COCO标准评估指标:
# - mAP@0.5: IoU阈值为0.5时的平均精度
# - mAP@0.5:0.95: IoU阈值从0.5到0.95的平均精度
# - precision: 精确率
# - recall: 召回率
使验证阶段的关键差异:
使用EMA模型而非原始模型,提高稳定性。
进行NMS后处理(IoU阈值默认0.65)。
不进行损失计算,只评估检测性能。
步骤 6:保存检查点
# 保存最新检查点
ckpt = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(), # 保存半精度模型
'ema': deepcopy(ema.ema).half(), # 保存EMA模型
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'opt': vars(opt),
'git': GIT_INFO, # git信息
'date': datetime.now().isoformat(),
}
# 保存为last.pt
torch.save(ckpt, last)
# 如果当前模型性能最佳,保存为best.pt
if best_fitness == fi:
torch.save(ckpt, best)
# 定期保存检查点
if (not nosave) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
torch.save(ckpt, w / f'epoch{epoch}.pt')
关键张量维度总结(Batch=4, Img=416)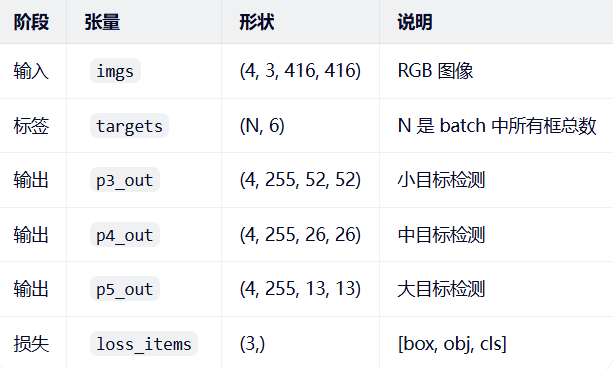
3 小结
以 yolov3.yaml + coco128.yaml + 416x416 为例的训练流程:
加载 128 张 COCO 图像及标签
Mosaic + HSV + Flip 增强 → 416×416 batch
Darknet53 提取多尺度特征(13/26/52)
FPN 融合后输出 3 个尺度的 255 通道预测
基于 anchor-IoU 匹配,计算复合损失
SGD 优化 + EMA 平滑
每轮验证并保存 best/last 模型
这是一个端到端、单阶段、多尺度回归的经典目标检测训练范式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)