大模型应用:智能体知识库动态迭代架构与大模型数据集全链路版本管理实战.135
一、前言
在大模型与智能体深度落地的产业场景中,静态固化的知识库、无规范管控的训练数据集,已经无法满足业务实时性、准确性、稳定性的核心诉求。企业业务规则变更、行业政策调整、实时舆情数据迭代、用户对话场景新增,都要求智能体依托的知识库具备动态增量更新、自动校验清洗、冷热数据分层能力;而支撑大模型微调、预训练、RAG 检索增强的原始数据集,若缺失严谨版本管理,会出现训练混乱、效果退化、溯源困难、故障无法回滚等严重问题。
今天我们结合实际经验,从基础概念切入,循序渐进拆解智能体知识库动态迭代底层逻辑和技术原理,同步讲解大模型数据集版本管理规范和应用落地细节,合完整的代码示例,兼顾理论深度梳理核心技术体系,建立标准化认知框架。

二、核心概念
1. 知识库基础定义
智能体知识库是赋能 AI 智能体实现专业领域问答、任务执行、逻辑推理、知识检索的结构化 + 非结构化数据容器,常见形态包含向量知识库、结构化业务库、文档解析库、规则配置库四大类。
传统初代智能体知识库采用静态部署模式,一次性导入全部文档与知识条目后长期不更新,仅依靠人工线下重新上传全量数据完成迭代,耗时冗长且无法匹配实时业务节奏。
2. 智能体动态知识库
核心核心特质是自动化、周期性、增量化、可校验。系统能够实时监听外部数据源变动,例如企业内部 OA 文档更新、行业官方公告发布、用户高频问题沉淀、实时业务日志汇总,经过格式统一、内容清洗、语义校验、向量 Embedding 生成、分区入库等全自动化流程,完成知识的新增、修改、过期淘汰、冗余合并。
动态迭代知识库核心能力:监听变更→自动清洗→增量向量化→冷热分层→监控复盘
从架构分层来看,动态知识库分为五层标准架构,并逐层递进:
- 1. 原始数据层:承载 PDF、Word、网页文本、数据库表单等原生素材;
- 2. 清洗加工层:完成去重、敏感词过滤、分段切片、语义纠错;
- 3. 向量索引层:依托嵌入模型生成高密度语义向量,构建FAISS等高效检索索引;
- 4. 服务调用层:对接大模型 RAG 接口,实现实时知识召回;
- 5. 监控迭代层:统计知识调用命中率、无效知识占比、过期知识数量,驱动下一轮迭代优化。
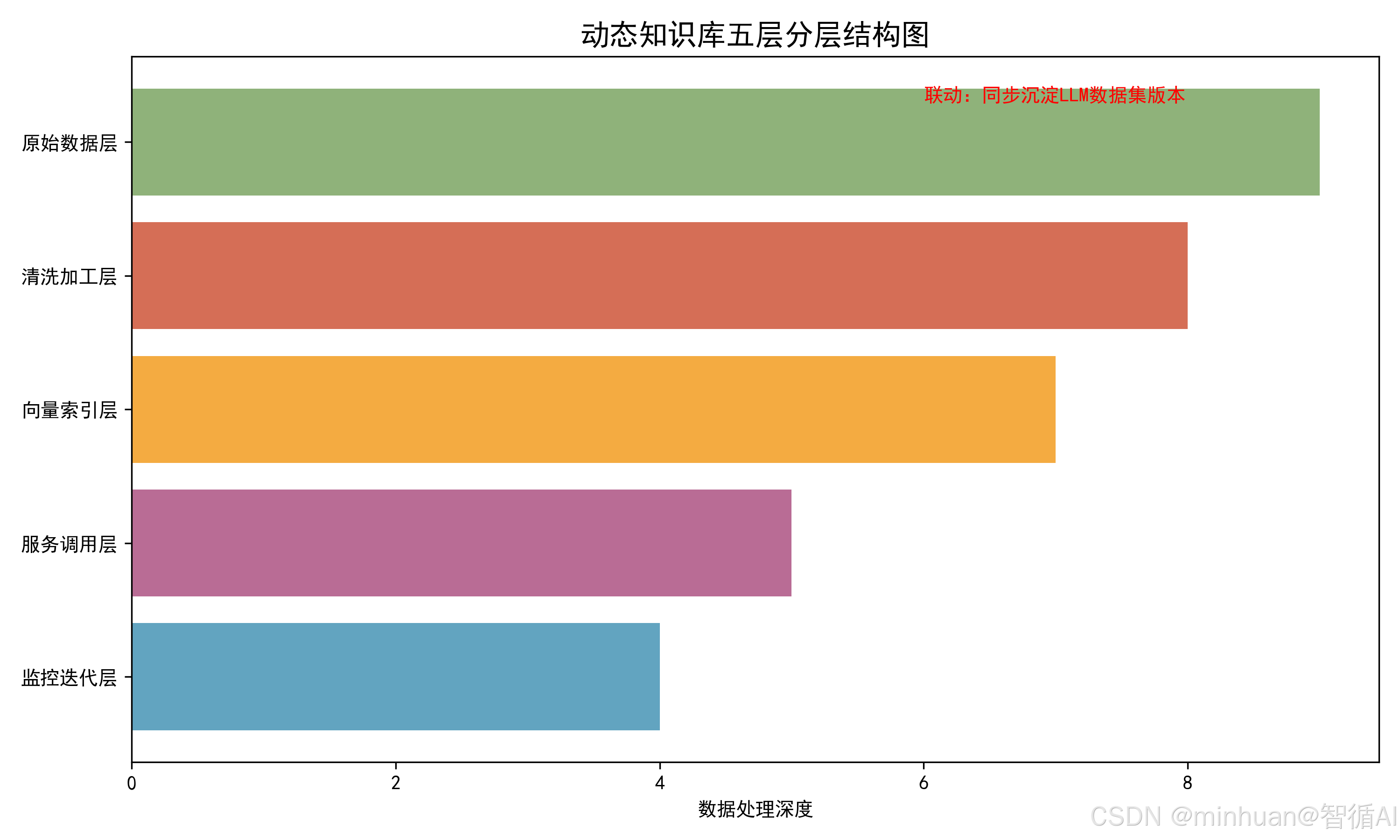
核心价值:不用停机、不用全量重构,业务无感实时更新领域知识;解决大模型原生时间截止、知识陈旧短板;适配政策变动、业务规则迭代、用户高频问题沉淀场景。
技术依赖:文本切片策略、本地嵌入模型、向量数据库增量写入、消息队列或目录监听机制、语义相似度校验体系。
3. 大模型数据集版本管理定义
大模型数据集涵盖基础预训练语料、SFT 监督微调数据集、DPO 偏好优化数据集、RAG 检索测试数据集、领域评测基准数据集五大类型。
数据集版本管理,借鉴软件工程 Git 版本控制思想,结合 AI 数据特殊性形成标准化管控体系;版本管理的核心目标:
- 1. 记录每一轮数据新增、删减、修正、清洗的全链路变更记录;
- 2. 固化数据快照、溯源数据来源、支持任意版本快速回滚;
- 3. 区分基线版本、迭代版本、应急版本。
无版本管理的数据集在生产环境会出现典型痛点:
- 1. 多次微调混用不同批次语料,模型能力震荡波动;
- 2. 数据污染无法定位源头;合规审查无法追溯语料来源;
- 3. 多人协作标注数据集出现覆盖冲突;
- 4. 模型效果劣化后无法精准还原最优数据基线。
标准化数据集版本管理:
- 会定义版本编号规则、数据指纹校验、元数据存档、分层存储策略、版本依赖关系绑定;
- 同时联动知识库迭代数据,形成“知识库实时更新→同步沉淀高质量样本→归档为全新数据集版本→微调优化大模型”的闭环链路。
4. 二者协同逻辑
- 知识库动态迭代 → 沉淀高质量问答、知识片段 → 归档增量数据集新版本
- 新版本数据集微调 LLM → 提升语义匹配、降低幻觉、优化检索精度
- 统一版本标签串联全程:定位问题快速区分,如知识过期、向量异常、数据版本劣化
- 闭环效果:智能体实时新知可用 + 大模型底层认知稳步迭代,摆脱静态固化缺陷。
三、基础原理
1. 向量知识库基础
动态迭代落地的核心底座是向量数据库与文本嵌入技术;文本 Embedding 嵌入模型(all-MiniLM、bge-m3 等)能够将非结构化自然语言文本,映射为固定维度高密度浮点向量,语义相近的文本在向量空间中距离更近。智能体所有业务知识切片后都会生成唯一语义向量,存入如FAISS之类的向量引擎。
知识动态迭代依赖向量增量写入机制:
- 无需重建全量索引,仅对新增文档切片生成向量追加入库;对过期知识通过主键筛选批量标记删除;对修正后的知识先作废旧向量,再写入新语义向量。
- 同时引入向量分区策略,按照业务场景、更新时间、热度值划分分区,高频热点知识分区优先加载至内存,冷数据落地磁盘存储,平衡检索速度与存储成本。
除此之外,知识切片规则直接影响迭代效果,常规采用固定长度滑动窗口切片 + 语义边界切片结合模式,避免语义割裂,保障大模型 RAG 检索时召回知识完整连贯,这也是动态迭代前期数据预处理的核心基础工序。
2. 数据集基础构成
标准dmx数据集包含元信息、主体数据、校验信息三大板块:
- 元信息涵盖数据采集时间、来源渠道、标注人员、清洗版本、合规标签;
- 主体数据根据用途分为纯预训练长文本、SFT 问答对、多轮对话样本、拒绝安全样本;
- 校验信息包含MD5数据指纹、数据长度分布统计、敏感内容筛查结果。
3. 数据指纹
数据指纹是版本管理的基础核心,任意一份数据集打包完成后,通过MD5、SHA256 算法生成全局唯一校验值,若后续数据出现篡改、缺失、冗余,指纹会直接变化,快速识别数据异常。
同时基础知识体系中需要区分增量数据集与全量数据集:
- 全量数据集用于大模型完整重新训练或微调,体量庞大;
- 增量数据集依托知识库动态迭代新增的优质样本,体量轻便,适合小步快跑迭代优化模型,降低算力消耗与训练成本。
4. 版本控制与AI适配改造
传统Git仅适配代码文本管理,无法支撑GB级海量 AI 数据集、向量知识库索引文件管控,因此行业衍生出 DVC(Data Version Control)专为大数据、模型、数据集设计版本工具,兼容 Git 提交逻辑,同时支持大文件快照存储、云端仓库同步、版本分支管理。
- 基础版本规范包含:主版本.次版本.迭代批次.质控等级,例如 V2.3.10.A 代表第 2 基线版本、3 次功能优化、10 轮知识库增量迭代、A 级高质量质控。
- 同时区分三大分支:Main 稳定基线分支、Dev 迭代开发分支、Hotfix 应急修复分支。
- 知识库每完成一轮动态迭代闭环,同步触发 DVC 对关联训练样本打标签归档;
- 大模型微调产出新权重,绑定对应数据集版本 + 知识库迭代编号,实现全链路可追溯。
5. RAG联动迭代基础逻辑
智能体最终输出答案质量,由大模型底座能力 + 知识库实时新鲜知识双向决定:
- 静态知识库会出现知识滞后,大模型原生训练知识截止时间固定,无法覆盖新政策、新业务;
- 动态迭代机制实时补充新知识,数据集版本管理沉淀优质知识样本优化模型底层认知。
基础知识层面必须理解:检索增强弥补模型实时性短板,版本管控弥补数据混乱短板,二者叠加才能让智能体长期稳定输出精准、合规、时效性内容。
6. 示例:文本向量与MD5指纹校验
import hashlib
import json
import os
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
# 模拟一个本地数据库/缓存文件,用于存储已处理过的文件指纹
CACHE_DB_FILE = "knowledge_base_index.json"
cache_dir = "D:\\modelscope\\hub"
embedding_model_dir = snapshot_download(
model_id="sentence-transformers/all-MiniLM-L6-v2",
cache_dir=cache_dir,
revision="master"
)
# 加载通用语义Embedding模型,对齐医疗RAG编码标准
model = SentenceTransformer(embedding_model_dir)
# --- 核心模块 1:计算 MD5 指纹 ---
def calculate_md5(file_path: str) -> str:
"""
计算文件内容的哈希值。
作用:只要文件内容改动一个标点,MD5 就会完全不同。
"""
md5_obj = hashlib.md5()
try:
with open(file_path, 'rb') as f:
# 分块读取,防止大文件撑爆内存
while chunk := f.read(4096):
md5_obj.update(chunk)
return md5_obj.hexdigest()
except FileNotFoundError:
return ""
# --- 核心模块 2:生成文本语义向量 ---
def get_text_embedding(text: str):
"""
生成向量。这是昂贵的操作(耗时/耗算力)。
"""
emb = model.encode(text, normalize_embeddings=True)
return emb.tolist() # 转换为列表以便 JSON 存储
# --- 核心模块 3:知识库管理器 (体现 MD5 价值的地方) ---
class KnowledgeBaseManager:
def __init__(self):
self.cache_db = self._load_cache()
def _load_cache(self):
if os.path.exists(CACHE_DB_FILE):
with open(CACHE_DB_FILE, 'r', encoding='utf-8') as f:
return json.load(f)
return {}
def _save_cache(self):
with open(CACHE_DB_FILE, 'w', encoding='utf-8') as f:
json.dump(self.cache_db, f, ensure_ascii=False, indent=2)
def process_file(self, file_path: str, content: str):
"""
处理文件的逻辑:
1. 先算 MD5。
2. 对比 MD5 是否存在于缓存中。
3. 如果存在且一致 -> 跳过(省钱省时)。
4. 如果不一致 -> 重新向量化 -> 更新缓存。
"""
current_md5 = calculate_md5(file_path)
# 场景 A:文件未变,直接使用旧向量
if file_path in self.cache_db and self.cache_db[file_path]['md5'] == current_md5:
print(f"✅ [跳过] {file_path} 内容未变动,复用历史向量。")
return self.cache_db[file_path]['vector']
# 场景 B:文件是新的或已修改,执行昂贵的向量化计算
print(f"⚡ [处理] {file_path} 检测到变动,正在进行向量化计算...")
vector = get_text_embedding(content)
print(f"向量维度:{len(vector)}")
# 更新缓存
self.cache_db[file_path] = {
"md5": current_md5,
"vector": vector
}
self._save_cache()
return vector
# --- 模拟运行演示 ---
if __name__ == "__main__":
# 模拟一个临时文件
demo_file = "temp_knowledge.txt"
demo_content = "2026年企业智能体知识库需支持实时动态增量迭代更新"
# 1. 写入文件
with open(demo_file, 'w', encoding='utf-8') as f:
f.write(demo_content)
kb_manager = KnowledgeBaseManager()
# --- 第一次运行 ---
print("--- 第 1 次运行 ---")
kb_manager.process_file(demo_file, demo_content)
# --- 第二次运行 (文件未动) ---
print("\n--- 第 2 次运行 (文件未动) ---")
kb_manager.process_file(demo_file, demo_content)
# --- 第三次运行 (修改了文件内容) ---
print("\n--- 第 3 次运行 (修改内容) ---")
modified_content = "2026年企业智能体知识库需支持实时动态增量迭代更新【已修正】"
with open(demo_file, 'w', encoding='utf-8') as f:
f.write(modified_content)
kb_manager.process_file(demo_file, modified_content)
# 清理测试文件
os.remove(demo_file)输出结果:
--- 第 1 次运行 ---
⚡ [处理] temp_knowledge.txt 检测到变动,正在进行向量化计算...
向量维度:384--- 第 2 次运行 (文件未动) ---
✅ [跳过] temp_knowledge.txt 内容未变动,复用历史向量。--- 第 3 次运行 (修改内容) ---
⚡ [处理] temp_knowledge.txt 检测到变动,正在进行向量化计算...
向量维度:384
基础嵌入与指纹校验模块加载完毕
四、智能体知识库动态迭代
1. 动态迭代基础原理
知识库动态迭代核心围绕数据监听 - 预处理质检 - 向量生成 - 索引更新 - 效果监控 - 闭环优化六大原理展开。
- 1. 数据源监听原理:基于定时轮询 + 消息队列双模式,监听本地文档目录、企业数据库、API 接口推送数据,识别文件新增、修改、删除动作,捕捉知识变动触发迭代任务;
- 2. 内容归一化原理:异构格式(PDF、Excel、网页、纯文本)统一转换为标准纯文本编码,消除格式差异化干扰;
- 3. 语义质控原理:依托大模型轻量校验接口,过滤无效乱码、重复冗余、逻辑错误、违规敏感内容,保障入库知识合规有效;
- 4. 增量向量更新原理:对比新旧文本语义相似度,仅对差异内容切片生成新 Embedding,旧有效向量保留不重复计算,节省算力与存储资源;
- 5. 冷热分层存储原理:根据知识调用频次、时间衰减因子打分,高分热点常驻内存向量索引,低分冷数据归档压缩存储;
- 6. 迭代反馈原理:统计智能体问答过程中知识召回命中率、精准率、无答案触发率,反向判定当前知识库哪些板块知识缺失、过期,自动生成下一轮迭代优先级清单。
2. 标准化执行流程
2.1 数据源感知采集
- 系统配置多源监听节点,定时扫描指定文件夹、业务数据库表单、第三方知识推送接口;
- 记录文件名称、修改时间、内容摘要,筛选出发生变更的增量原始数据;
- 过滤未改动静态文件,减少无效计算负载,同时记录数据来源元标签,为后续版本溯源打底。
2.2 多维度清洗与语义切片
- 原始异构数据统一解析提取纯文本,完成去空格、去乱码、脱敏遮挡敏感信息;
- 采用混合切片策略,短句语义完整不拆分、长文本按固定窗口 + 语义句号边界截断,单切片长度控制在 300-600 字符区间,兼顾语义完整性与检索灵活性;
- 同步完成重复文本聚类去重,保留唯一标准知识原文。
2.3 嵌入生成与增量入库
- 调用本地化嵌入模型生成标准化语义向量,连接向量数据库,执行比对;逻辑;
- 存在同主题过期知识则标记软删除,全新知识直接创建索引入库,修改类知识覆盖关联向量快照;
- 同步同步写入 MySQL 结构化记录表,存储知识 ID、迭代批次、向量版本、更新时间、质控得分。
2.4 实时服务对接生效
- 迭代完成无需重启智能体服务,向量数据库热加载新索引分区;
- RAG 检索接口毫秒级感知新知识,大模型在对话推理时可直接召回最新迭代知识;
- 保障业务侧无感知平滑更新,杜绝停机维护影响线上业务运转。
2.5 运行监控与迭代复盘
- 全天统计知识调用日志,计算核心指标:知识召回 Top1 命中率、无效知识占比、过期知识触发次数、新增知识使用频率;
- 每日生成迭代质量报表,识别薄弱知识板块,自动规划次日增量采集范围,形成永久循环迭代闭环
3. 迭代过程细节说明
- 软删除机制替代物理删除是核心工程优化点,物理删除会破坏向量索引连续性、重建成本极高,软删除仅修改状态标记,检索时过滤作废条目即可;
- 语义相似度阈值动态可调,通用场景 0.75 为基准阈值,金融、医疗高精度领域上调至 0.85;
- 迭代任务优先级队列设计,紧急政策公告、核心业务规则置顶加急处理,常规文档低优先级后台静默迭代。
4. 示例:知识库增量监听 + 向量入库
import time
import os
from sentence_transformers import SentenceTransformer
import numpy as np
from modelscope import snapshot_download
cache_dir = "D:\\modelscope\\hub"
embedding_model_dir = snapshot_download(
model_id="sentence-transformers/all-MiniLM-L6-v2",
cache_dir=cache_dir,
revision="master"
)
model = SentenceTransformer(embedding_model_dir)
# 模拟存储结构
knowledge_base = {
"meta_version": "V1.8.5",
"vec_data": [],
"text_map": {}
}
def monitor_data_dir(folder_path: str, interval=10):
"""监听目录变更,模拟动态迭代触发"""
from datetime import datetime
while True:
file_list = [f for f in os.listdir(folder_path) if f.endswith(".txt")]
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"[{current_time}] 当前待处理知识文件:{file_list}")
for file in file_list:
full_path = os.path.join(folder_path, file)
with open(full_path, "r", encoding="utf-8") as f:
content = f.read().strip()
# 生成向量并入库
emb = model.encode(content, normalize_embeddings=True)
uuid_id = str(time.time())
knowledge_base["vec_data"].append(emb)
knowledge_base["text_map"][uuid_id] = {"text":content,"update_time":time.time(),"status":"valid"}
complete_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"[{complete_time}] 文件{file}完成增量向量入库,迭代版本:{knowledge_base['meta_version']}")
time.sleep(interval)
if __name__ == "__main__":
# 本地新建knowledge文件夹放置txt知识即可测试
if not os.path.exists("knowledge"):
os.mkdir("knowledge")
monitor_data_dir("knowledge", interval=15)输出结果:
[2026-03-31 09:43:24] 当前待处理知识文件:[]
[2026-03-31 09:43:39] 当前待处理知识文件:[]
[2026-03-31 09:43:54] 当前待处理知识文件:[]
[2026-03-31 09:44:09] 当前待处理知识文件:[]
[2026-03-31 09:44:24] 当前待处理知识文件:[]
[2026-03-31 09:44:39] 当前待处理知识文件:[]
[2026-03-31 09:44:54] 当前待处理知识文件:['新增语料.txt']
[2026-03-31 09:44:54] 文件新增语料.txt完成增量向量入库,迭代版本:V1.8.5
五、大模型数据集版本管理
1. 数据集版本管理基础原理
数据集版本管理依托快照固化、指纹校验、分支隔离、依赖绑定、回滚复原五大核心原理运行:
- 快照固化原理:指对每一轮完成清洗、标注、筛选的最终数据集,完整封存目录结构、样本内容、元数据说明,形成不可随意修改的固定快照;
- 指纹校验:通过 SHA256 全域哈希值锁定数据集唯一性,任何字节改动都会触发指纹告警,保障数据安全合规;
- 分支隔离原理:复用 DVC+Git 协同架构,开发分支测试新增数据效果、主干分支留存稳定训练基线、热修复分支处理数据污染紧急问题,多分支互不干扰;
- 依赖绑定原理:将数据集版本、知识库迭代批次、大模型权重版本三者编号强关联,形成“知识迭代批次 D12→数据集 V3.2→模型权重Llama-FT-V3.2”绑定关系;
- 回滚复原原理:预先归档历史全量快照与增量补丁,模型微调劣化、数据异常时一键退回历史可靠版本,快速止损线上业务风险。
同时底层兼顾分层存储原理,冷历史全量数据集归档低成本对象存储,高频迭代增量数据集存放高速 SSD 存储,平衡存储成本与调取速度,适配大模型训练高吞吐读取需求。
2. 数据集版本全生命周期流程
2.1 数据归集对齐
- 拉取知识库动态迭代沉淀的优质问答样本、领域标准知识片段,整合历史标注语料、公开基准评测数据;
- 统一规范样本格式,使用JSONL 标准格式适配主流 LLM 微调框架,统一编码、统一字段命名,剔除格式混乱无效样本,完成跨来源数据归一化对齐处理。
2.2 多层级清洗质控
- 第一层基础过滤:去重、清理超长或过短无效文本、屏蔽违规敏感词;
- 第二层语义过滤:大模型校验逻辑错误、逻辑冲突、事实失真样本;
- 第三层统计过滤:分析样本长度分布、领域分布、正负样本比例,剔除分布异常噪声数据;
- 清洗完成后生成清洗日志存档,绑定初始版本标签。
2.3 指纹生成与 DVC版本快照
- 对整体数据集文件夹计算全局 SHA256 指纹,编写 version_meta.json 记录版本号、迭代来源、知识库关联编号、清洗规则、样本总量、正负比例;
- 通过DVC提交快照关联Git记录,推送至远程数据仓库,固化当前全部数据状态,杜绝本地文件丢失篡改风险。
2.4 分支调度与模型关联训练
- 开发分支使用新版增量数据集做小批量微调实验,验证模型语义匹配、知识应答、推理稳定性;
- 效果达标后合并至主干稳定版本,生成正式商用模型权重;
- 若实验出现模型幻觉上升、回答偏差扩大,直接放弃当前数据集版本,切换历史稳定快照重新迭代。
2.5 版本归档与长效溯源
- 所有历史版本按时间线、迭代类型分类归档,建立可视化版本谱系图,记录每版数据集优化点、缺陷问题、适配模型场景;
- 日常训练、评测、上线全流程标注依赖数据集版本,出现问题可秒级溯源定位根因是数据偏差还是模型结构缺陷。
3. 增量差分管理与合规管控
- 海量全量数据集重复存储浪费存储空间,行业通用差分版本技术:仅存储当前版本与基线版本差异样本,相同内容不重复备份,极大节省云端存储成本;
- 同时接入合规审计模块,每条样本标记版权来源、采集合规性、脱敏等级,满足企业商用、行业监管对 AI 数据合规的硬性要求;
- 版本编号严格递进,禁止覆盖历史版本,保障迭代全程可审计、可复盘、可追溯。
4. 示例:数据集 DVC 基础信息生成
import os
import hashlib
import json
from datetime import datetime
def get_dir_sha256(folder_path):
sha_obj = hashlib.sha256()
for root, _, files in os.walk(folder_path):
for file in sorted(files):
f_path = os.path.join(root, file)
with open(f_path, "rb") as f:
while chunk := f.read(4096):
sha_obj.update(chunk)
return sha_obj.hexdigest()
def save_dataset_version(folder, version_tag, knowledge_iter_id):
"""生成数据集版本元文件"""
total_file = sum(len(fs) for _,_,fs in os.walk(folder))
sha_code = get_dir_sha256(folder)
meta = {
"version": version_tag,
"link_knowledge_iter": knowledge_iter_id,
"total_files": total_file,
"sha256_fingerprint": sha_code,
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"status": "stable/dev"
}
with open("dataset_version_meta.json","w",encoding="utf-8") as f:
json.dump(meta,f,ensure_ascii=False,indent=4)
print("数据集版本元数据&指纹生成完成")
if __name__ == "__main__":
if not os.path.exists("llm_dataset"):
os.mkdir("llm_dataset")
save_dataset_version("llm_dataset","V3.2.7","KD20260330-01")输出结果:
数据集版本元数据&指纹生成完成
数据集版本构建完成,全局哈希:0621f6313874a6eb1eca097b61589a04e24f7f503f01712df3a0b46886e40ff3
六、动态迭代的意义和价值
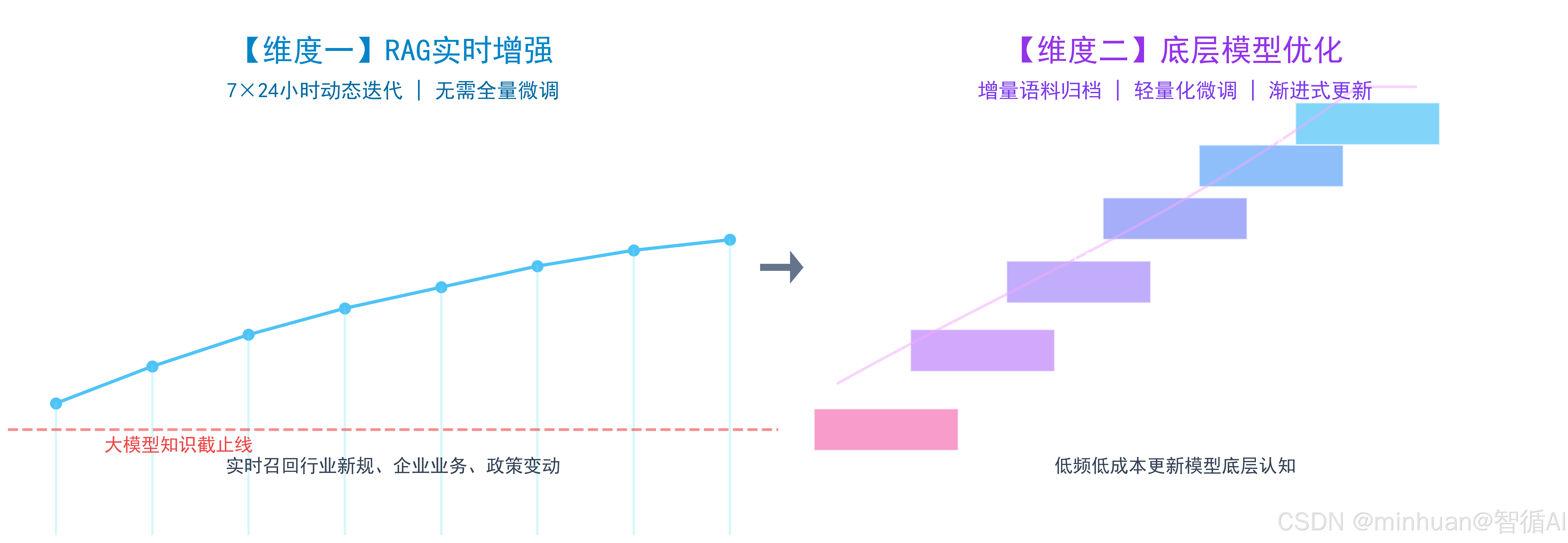
1. 补齐大模型知识时效性短板
- 主流大模型都存在知识截止时间固化问题,模型训练完成后无法自主获取行业新规、企业内部最新业务流程、实时政策变动。
- 智能体知识库动态迭代机制 7×24 小时不间断补充新鲜领域知识,依托 RAG 架构实时召回增强生成,无需频繁全量微调大模型即可保障应答时效性;
- 迭代沉淀的优质新知识样本,通过标准化数据集版本管控归档为增量语料,低频低成本完成模型轻量化微调,渐进式更新模型底层认知,从实时增强 + 底层优化双维度补齐时效短板,让大模型摆脱知识陈旧滞后的固有缺陷。
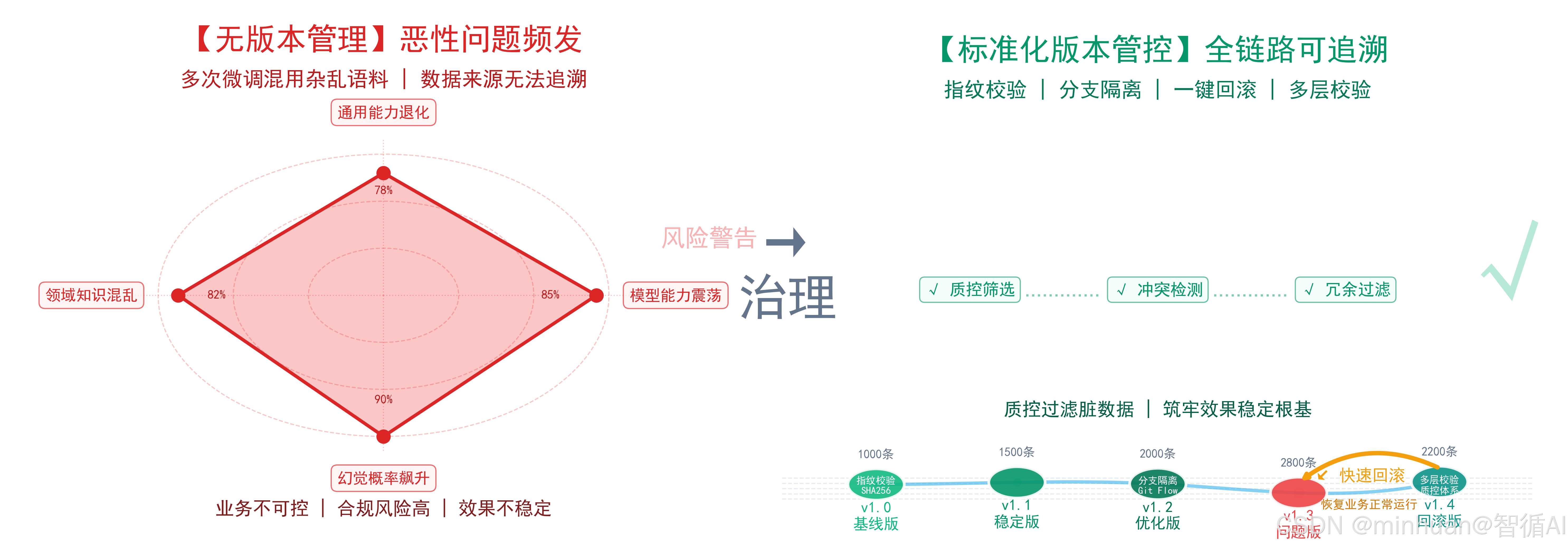
2. 保障模型训练稳定性与效果
- 若无数据集版本管理,多次微调混用杂乱语料,极易出现模型能力震荡、通用能力退化、领域知识混乱、幻觉概率飙升等恶性问题。
- 标准化版本快照、分支隔离、指纹校验体系,严格规范每一轮训练数据来源与内容基线;
- 一旦微调后大模型对话质量下滑、逻辑推理错乱、合规风险上升,技术人员无需全盘排查,直接依据版本关联关系定位数据集问题,一键回滚至历史稳定版本,快速止损恢复业务正常运行。
- 知识库动态迭代的质控筛选逻辑,天然过滤错误、冗余、冲突知识,沉淀进入数据集的样本均经过多层校验,从源头降低脏数据流入训练环节的概率,筑牢大模型效果稳定的数据根基。
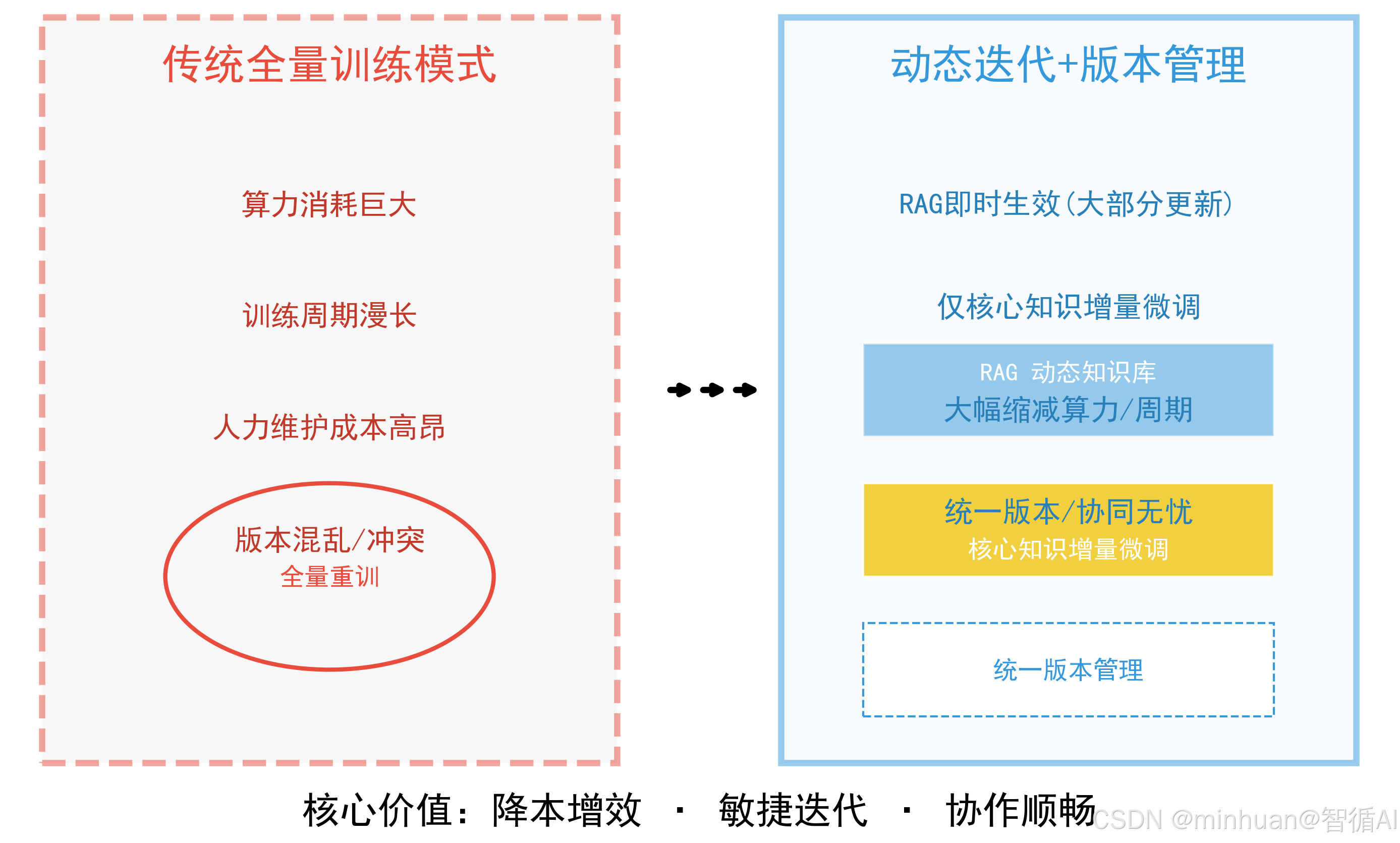
3. 降低算力成本与运维成本
- 传统模式为适配新知识频繁全量重新训练大模型,算力消耗巨大、训练周期漫长、人力维护成本高昂;
- 动态迭代知识库优先通过 RAG 即时生效绝大多数知识更新需求,仅核心沉淀知识整理为轻量化增量数据集微调模型,大幅缩减训练算力投入与迭代周期。
- 版本管理体系统一规范数据存储、归档、溯源、协作流程,多人团队协同标注、清洗、训练时不会出现文件覆盖、版本冲突、数据混乱问题,简化工程运维链路,降低中大型 AI 智能体项目落地与长期维护复杂度。
4. 构建全链路合规溯源
政企商用大模型、行业垂直智能体对数据合规、行为溯源具备极高要求。知识库每一次动态迭代记录来源、时间、质控日志;数据集每一个版本留存指纹、元信息、依赖关系;大模型权重绑定知识批次 + 数据版本,形成 “原始数据→知识迭代→数据集归档→模型训练→线上推理” 全链路溯源链条。
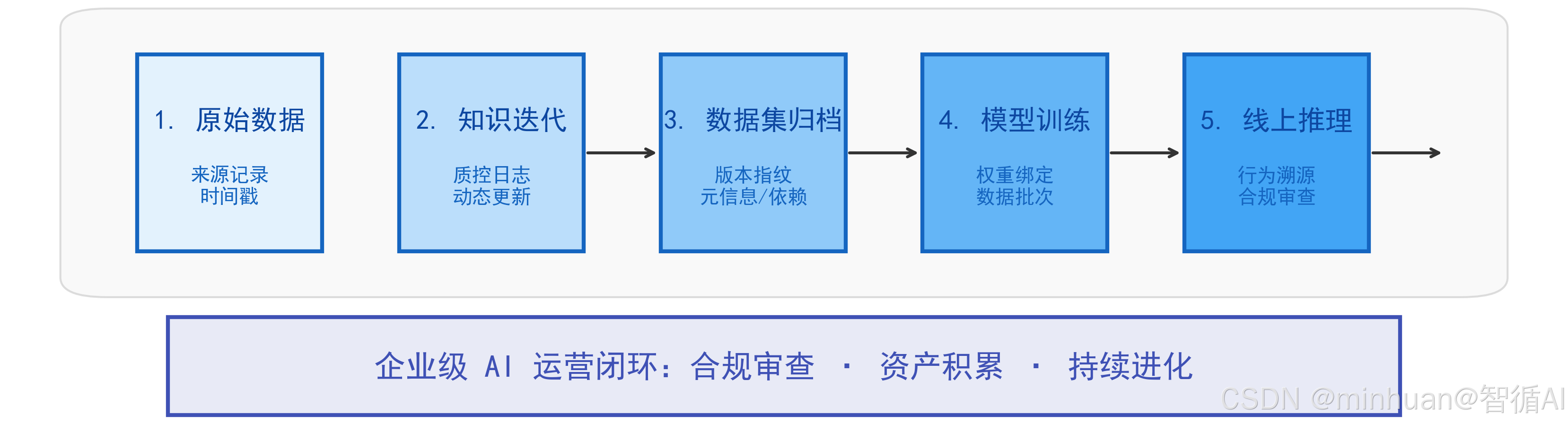
既满足监管合规审查硬性标准,又能够长期积累高质量迭代数据资产,让大模型与智能体随着业务运转持续自我优化、稳步进化,形成可持续发展的 AI 运营闭环,这也是企业级大模型应用从 demo 原型走向成熟商业化落地的关键基石。
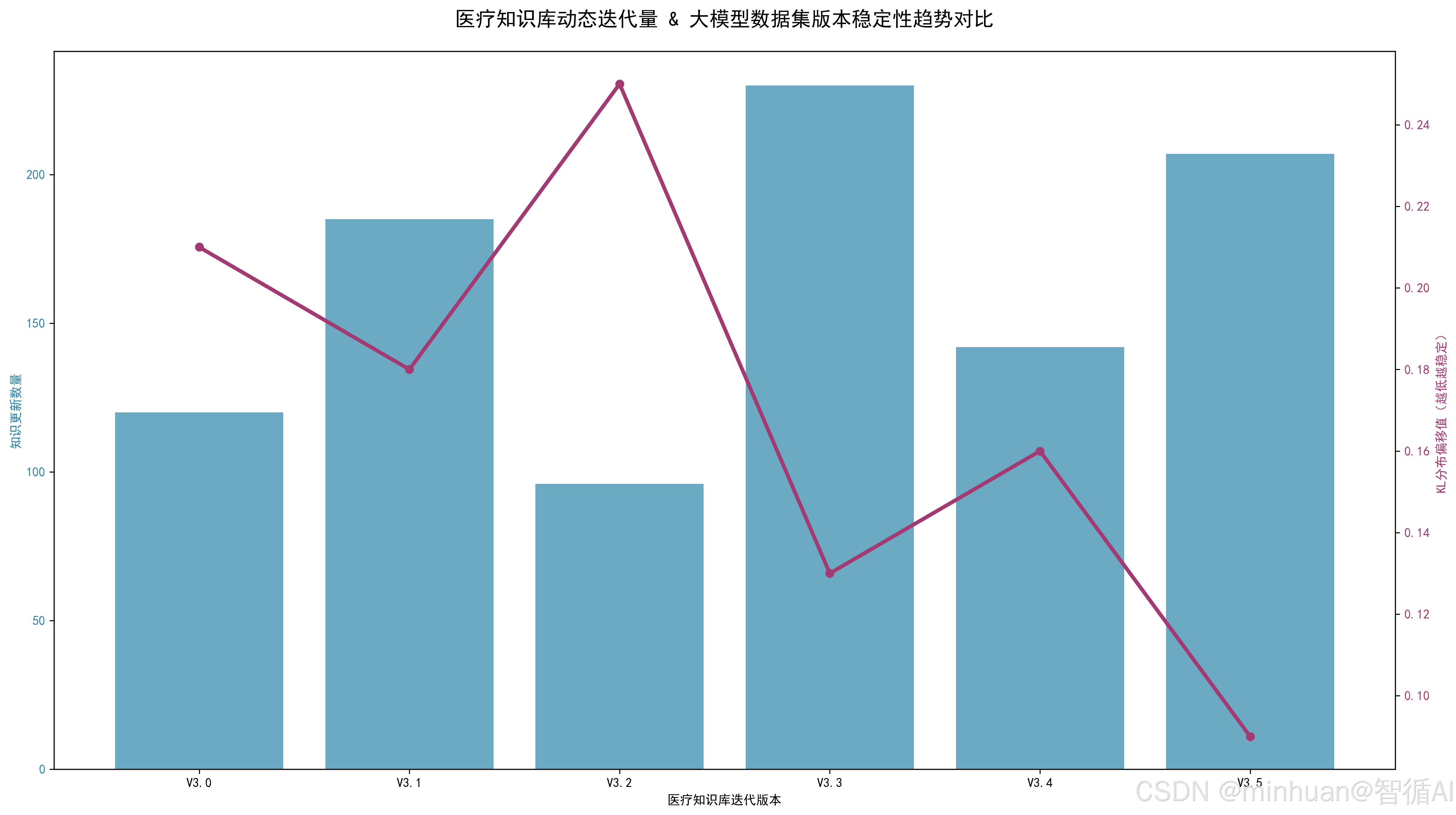
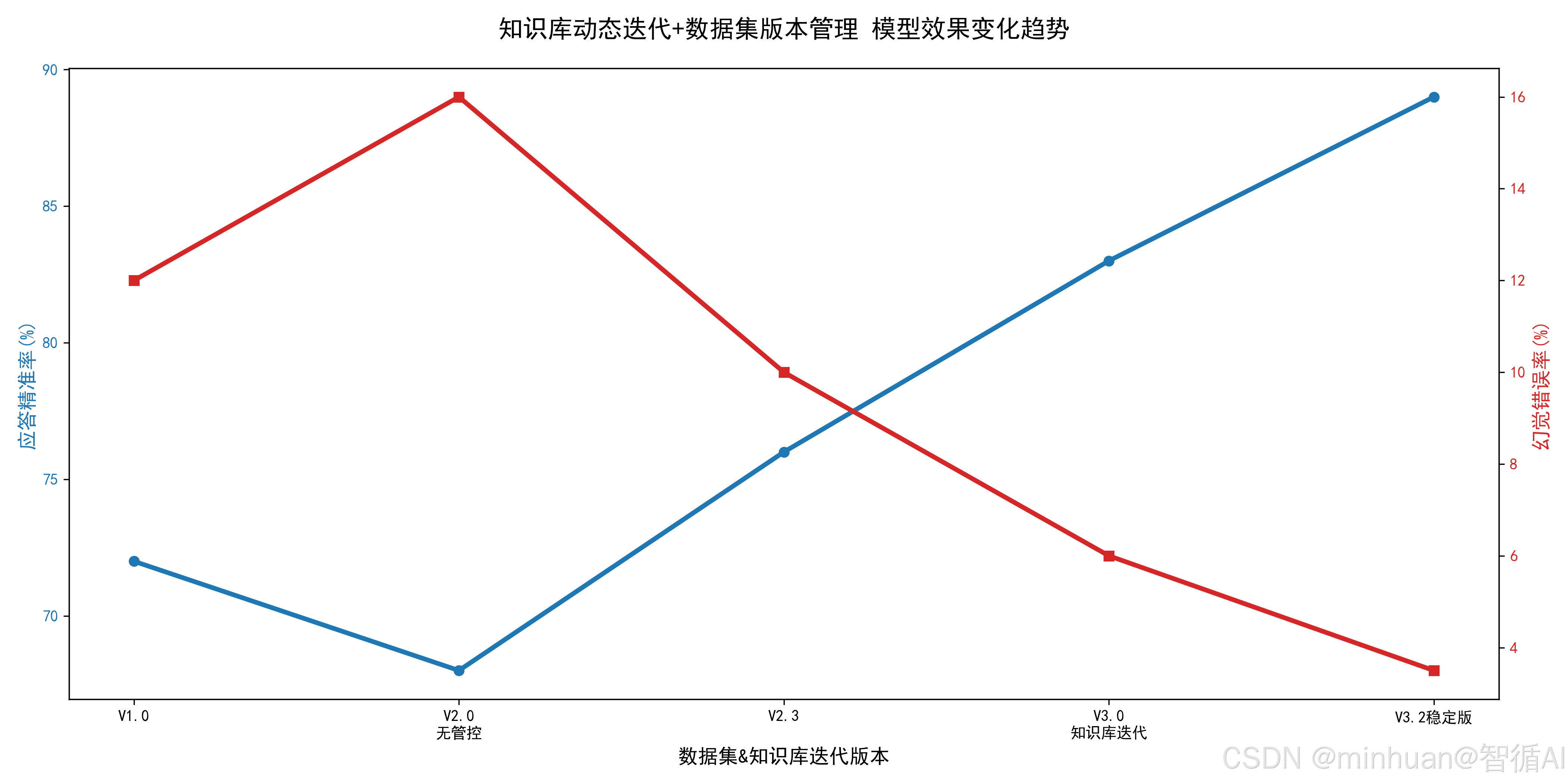
模型版本迭代效果趋势图:
七、总结
智能体动态知识库和传统静态库最大不同,是支持多源监听、增量更新、冷热分层和闭环监控,不用每次全量重构。通过向量嵌入、自动清洗、语义切片,让知识能实时更新,大模型通过 RAG 就能用到最新内容,保证回答新鲜准确。整个流程从数据采集、切片清洗、向量入库,到服务热生效、效果复盘,形成全自动闭环。
大模型数据集版本管理则用DVC+Git、数据指纹、分支快照、差分存储,解决数据乱、易篡改、难溯源、不能回滚的问题。每批数据都会生成唯一指纹、打版本标签、做分支隔离,训练出问题能快速回滚到稳定版本,保证模型效果不波动。
总的来说,这样既解决大模型知识过时的问题,用 RAG 实时补新知、用增量数据轻量微调;又通过严格版本管控减少幻觉、稳定效果、节省算力。前端靠动态知识库保证回答准确实时,后端靠数据集版本管理守住模型质量,两者配合让 AI 系统可以自主迭代、持续进化,真正满足企业级落地稳定、高效、合规、低成本的长期需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)