LeWorldModel:基于像素的稳定端到端联合嵌入预测架构
Yann LeCun团队提出LeWorldModel(LeWM),一种仅需两个损失项就能从像素端到端训练联合嵌入预测架构(JEPA)的新型世界模型。关键创新是SIGReg正则化技术,通过强制隐变量符合各向同性高斯分布防止表征崩溃,相比现有方法大幅简化训练(仅1个超参数)。实验显示,仅1500万参数的LeWM在2D/3D任务中比大模型快48倍,且能有效理解物理规律。该模型以数学简洁性突破工程复杂度,为自主智能系统提供了高效可扩展的解决方案。

https://arxiv.org/html/2603.19312v1
这篇由 Yann LeCun 团队(纽约大学、Mila 等机构)于 2026 年 3 月发布的论文介绍了一种名为 LeWorldModel (LeWM) 的新型世界模型。
它的核心贡献在于:首次实现了仅靠两个损失项,就能从原始像素(Pixels)中稳定地、端到端地训练出联合嵌入预测架构(JEPA)。
1. 背景:JEPA 与“崩溃”难题
在 AI 领域,世界模型(World Models) 的目标是让智能体在“想象空间”中模拟未来。JEPA (Joint Embedding Predictive Architecture) 是一种备受推崇的架构,它不在像素层面做预测(太浪费计算量),而是在紧凑的**隐空间(Latent Space)**进行预测。
然而,JEPA 极其脆弱,容易发生表征崩溃 (Representation Collapse):
-
什么是崩溃? 编码器为了偷懒,把所有不同的图片都映射成同一个向量。这样预测器无论怎么猜都是对的,但这个模型完全废了。
-
现状: 为了防止崩溃,之前的模型(如 PLDM)需要极其复杂的调节,涉及 6 个以上的超参数和复杂的梯度停止(Stop-gradient)等技巧。
2. LeWorldModel 的核心创新:化繁为简
LeWM 最大的突破在于它将复杂的训练过程简化为只有 2 个损失项,且只需要调节 1 个有效超参数 ($\lambda$)。
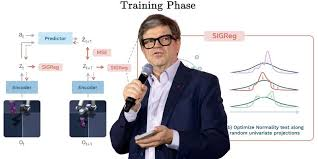
A. 训练管线 (Training Pipeline)
-
Encoder (编码器):将当前帧 $o_t$ 转化为隐变量 $z_t$。
-
Predictor (预测器):根据当前状态 $z_t$ 和动作 $a_t$,预测下一时刻的隐变量 $\hat{z}_{t+1}$。
-
End-to-End:所有参数同时更新,没有冻结层。
B. 两大损失函数
-
预测损失 ($\mathcal{L}_{pred}$):
使用均方误差(MSE)让预测值 $\hat{z}_{t+1}$ 逼近真实的编码值 $z_{t+1}$。
$$\mathcal{L}_{pred} = \| \hat{z}_{t+1} - z_{t+1} \|_2^2$$
-
SIGReg 正则化项 (关键防崩溃机制):
这是论文的神来之笔。它引入了 Sketched-Isotropic-Gaussian Regularizer。其逻辑是:强制隐变量的分布符合各向同性高斯分布。
-
实现方式:将高维隐变量投影到多个随机方向上,对每个投影进行一维的正态性检验。如果分布够“乱”、够像高斯分布,特征的多样性就得到了保证,从而杜绝了崩溃。
-
3. 惊人的性能数据
LeWM 虽然只有 1500 万参数(非常轻量),但在 2D 和 3D 控制任务中表现极强:
-
规划速度:比基于大视觉模型(如 DINOv2)的世界模型快 48 倍。
-
训练效率:单块 GPU 几小时内即可完成训练。
-
稳定性:超参数搜索从“多维超空间”退化到了“简单二分查找”。
4. 物理理解力的“降维打击”
研究者不仅测试了 LeWM 跑任务的能力,还深入探测了它的“三观”(对物理世界的理解):
-
线性探测 (Probing):
虽然 LeWM 没学过坐标,但通过隐变量,我们可以轻而易举地线性解析出 Agent 的位置、方块的角度等物理量。其精度甚至能与经过海量数据预训练的 DINOv2 媲美。
-
惊讶度评估 (Violation-of-Expectation, VoE):
模仿发展心理学的方法,给模型看一些“不符合物理常识”的画面(比如物体突然瞬移)。
-
结果显示:当发生物理违规时,LeWM 的“惊讶值”(预测误差)会瞬间飙升;而仅仅是颜色改变等视觉干扰,模型表现得非常淡定。这说明它捕捉到了世界的本质动态规律。
-
5. 总结:通往自主智能的一小步
LeWorldModel 证明了:简单的数学原理(高斯正则化)可以取代复杂的工程技巧(EMA、Stop-gradient)。
它为未来的自主智能系统提供了一个高效的“大脑模版”:
-
低成本:普通实验室甚至个人开发者都能跑。
-
高性能:实时规划速度极快。
-
懂物理:不仅仅是像素的堆砌,而是理解了力的相互作用。
一句话解读: 这是一篇典型的“LeCun 式”论文——用简洁的数学美感挑战复杂的启发式工程。如果你想在 2026 年训练一个自己的世界模型,LeWM 可能是目前的最佳起点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)