Spring AI 对接大模型开发易错点总结与实战解决办法
目录
一、前言
1、SpringAI 的应用背景
随着大模型技术快速落地,企业级 Java 项目智能化改造需求爆发,传统 Spring Boot 生态急需一套标准化框架快速对接各类大模型。Spring AI 作为 Spring 官方推出的 AI 工程框架,深度适配 Spring 全家桶,屏蔽了不同大模型厂商的 API 差异,成为 Java 开发者接入 LLM、向量数据库、RAG 知识库的首选方案,广泛应用于智能问答、业务对话、文档解析、智能助手等开发场景。
2、使用 SpringAI 的便利
Spring AI 依托 Spring Boot 自动装配特性,提供开箱即用的 starter 依赖,无需手动封装 HTTP 请求、拼接复杂请求参数;统一的 ChatClient 流式 API,兼容同步、流式响应、结构化实体返回;同时支持 OpenAI、通义千问、Ollama 本地模型等多厂商适配,内置 RAG、记忆对话、函数调用等通用能力,大幅降低 Java 项目集成大模型的开发门槛。
3、本文目的
很多开发者初次使用 Spring AI 对接大模型时,常会遇到接口连不通、鉴权失败、模型调用无响应、配置报错等各类问题,网上零散资料难以快速定位根因。本文梳理接入阶段高频易错点,逐一分析问题成因并给出可直接落地的配置与代码解决方案,帮助开发者快速避坑、一次性完成 Spring AI 与大模型的对接集成。
二、常见问题及实战解决方案
1、访问地址错误
问题现象
项目启动无报错,但调用大模型接口超时、连接失败、404 访问异常;本地测试正常,部署服务器后无法连通。错误截图如下:
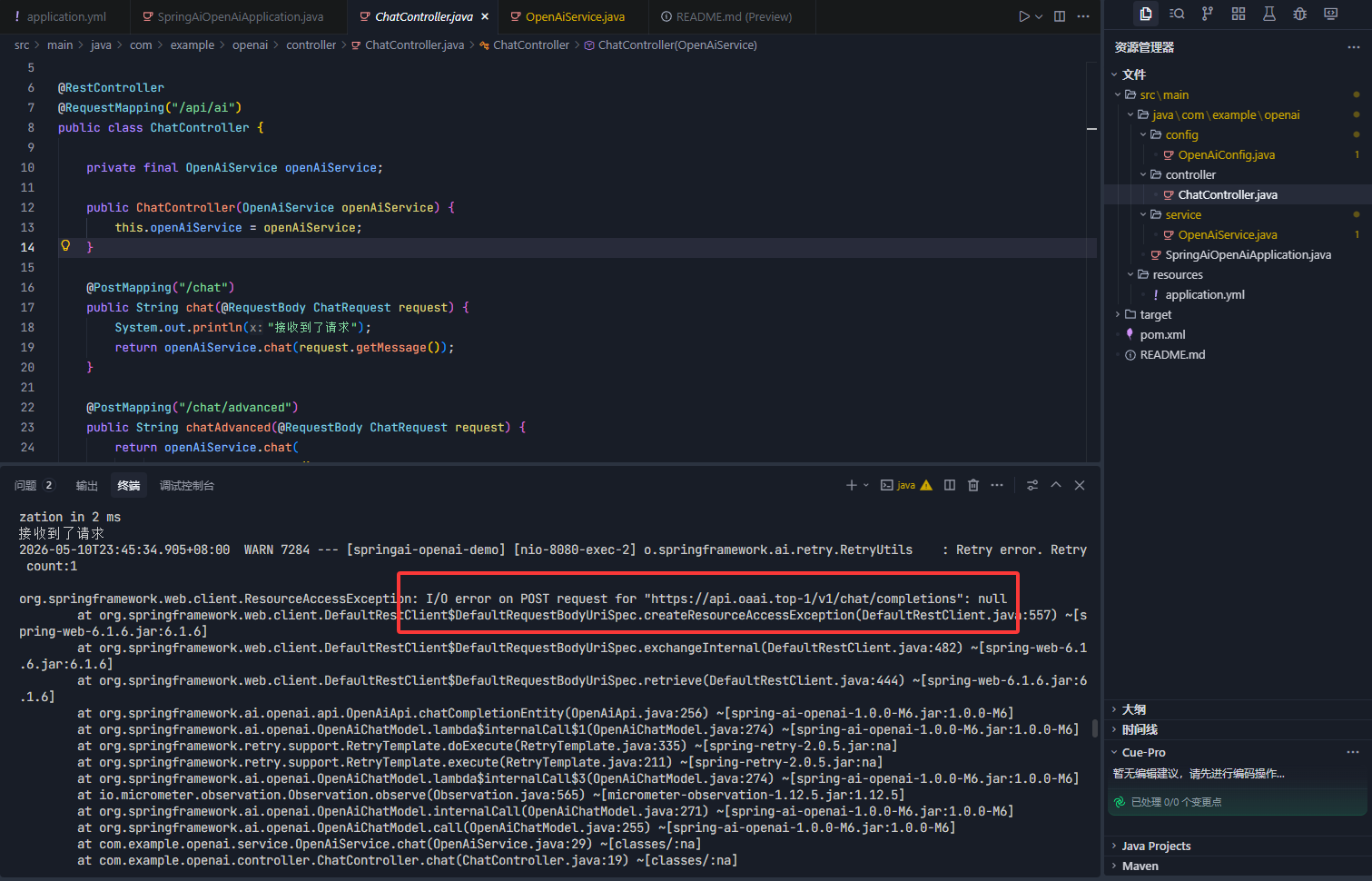
2026-05-10T23:45:34.905+08:00 WARN 7284 --- [springai-openai-demo] [nio-8080-exec-2] o.springframework.ai.retry.RetryUtils : Retry error. Retry count:1
org.springframework.web.client.ResourceAccessException: I/O error on POST request for "https://api.ai.top-1/v1/chat/completions": null
at org.springframework.web.client.DefaultRestClient$DefaultRequestBodyUriSpec.createResourceAccessException(DefaultRestClient.java:557) ~[spring-web-6.1.6.jar:6.1.6]
at org.springframework.web.client.DefaultRestClient$DefaultRequestBodyUriSpec.exchangeInternal(DefaultRestClient.java:482) ~[spring-web-6.1.6.jar:6.1.6]
at org.springframework.web.client.DefaultRestClient$DefaultRequestBodyUriSpec.retrieve(DefaultRestClient.java:444) ~[spring-web-6.1.6.jar:6.1.6]常见原因
- 第三方中转地址、私有部署大模型 BaseURL 填写不完整,缺少
/v1后缀; - 混淆官方地址与本地私有化部署地址,直接使用默认地址对接本地模型;
- 服务器防火墙、网络策略限制出口,无法访问大模型外网接口;
- 多模型适配时未单独配置自定义 BaseURL,沿用默认配置。
实战解决办法
- 严格补全接口地址,主流兼容格式统一配置:
spring:
application:
name: springai-openai-demo
ai:
openai:
api-key: sk-xxx
base-url: your-url
chat:
options:
model: gpt-5.4
temperature: 0.7
server:
port: 8080
logging:
level:
org.springframework.ai: DEBUG
com.example.openai: DEBUG- 本地 Ollama 等私有化模型,指定本机 IP + 端口,不使用localhost;
- 服务器放行外网端口,测试环境优先用 Postman 先通接口,再接入代码;
- 多模型场景通过
mutate()方法动态指定独立 BaseURL,避免配置冲突。
2、Key 相关问题
问题现象
401 鉴权失败、Invalid API Key、权限不足、额度耗尽报错。
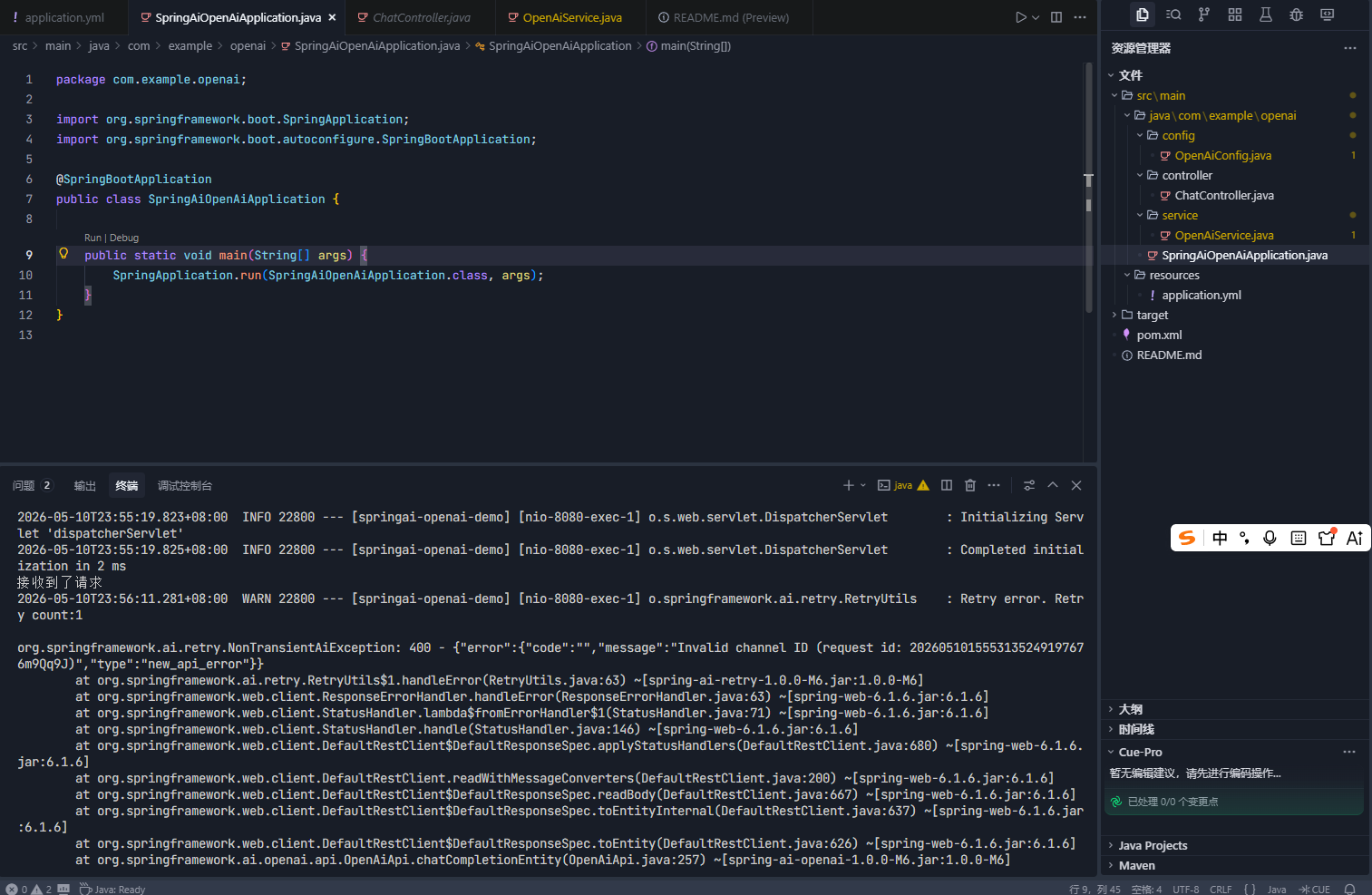
org.springframework.ai.retry.NonTransientAiException: 400 - {"error":{"code":"","message":"Invalid channel ID (request id: 2026051015553135249197676m9Qq9J)","type":"new_api_error"}}
at org.springframework.ai.retry.RetryUtils$1.handleError(RetryUtils.java:63) ~[spring-ai-retry-1.0.0-M6.jar:1.0.0-M6]
at org.springframework.web.client.ResponseErrorHandler.handleError(ResponseErrorHandler.java:63) ~[spring-web-6.1.6.jar:6.1.6]
at org.springframework.web.client.StatusHandler.lambda$fromErrorHandler$1(StatusHandler.java:71) ~[spring-web-6.1.6.jar:6.1.6]
at org.springframework.web.client.StatusHandler.handle(StatusHandler.java:146) ~[spring-web-6.1.6.jar:6.1.6]
at org.springframework.web.client.DefaultRestClient$DefaultResponseSpec.applyStatusHandlers(DefaultRestClient.java:680) ~[spring-web-6.1.6.jar:6.1.6]常见原因
- API Key 复制带空格、换行符,配置存在隐形字符;
- Key 权限不足,未开通对应模型调用权限;
- 密钥泄露被限流、封禁,或账号免费额度用完;
- 配置层级错误,把 api-key 写在错误缩进位置,未生效。
实战解决办法
- 复制 Key 后手动去除首尾空格,优先配置在环境变量中,避免硬编码泄露;
- 登录模型厂商后台,检查 Key 绑定权限、调用额度、接口白名单;
- YAML 配置严格注意缩进,保证层级正确:
这里需要注意的是,关于Key的这种开发模式,特别容易出现以下问题:
密钥直接进代码仓库,极易泄漏
一旦提交到 Git、截图、共享项目,风险很高
后续多人协作时也不利于环境隔离这里我们建议将key改成从环境变量去读取,关键代码如下:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
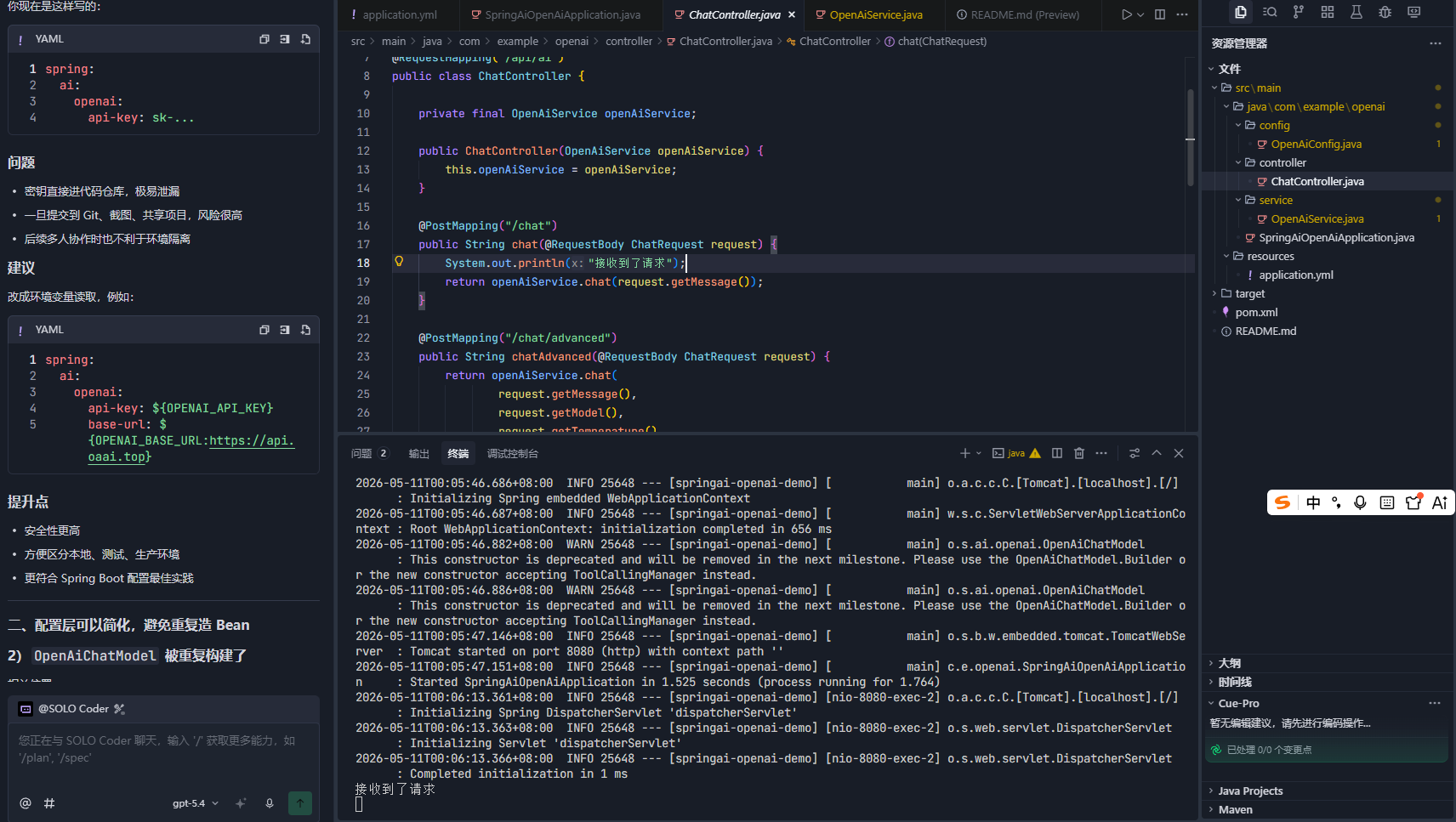
base-url: ${OPENAI_BASE_URL:https://api.oaai.top}这样修改后,安全性更高,方便区分本地、测试、生产环境同时也更符合 Spring Boot 配置最佳实践。当我们将输入正确的key之后可以看到以下结果:
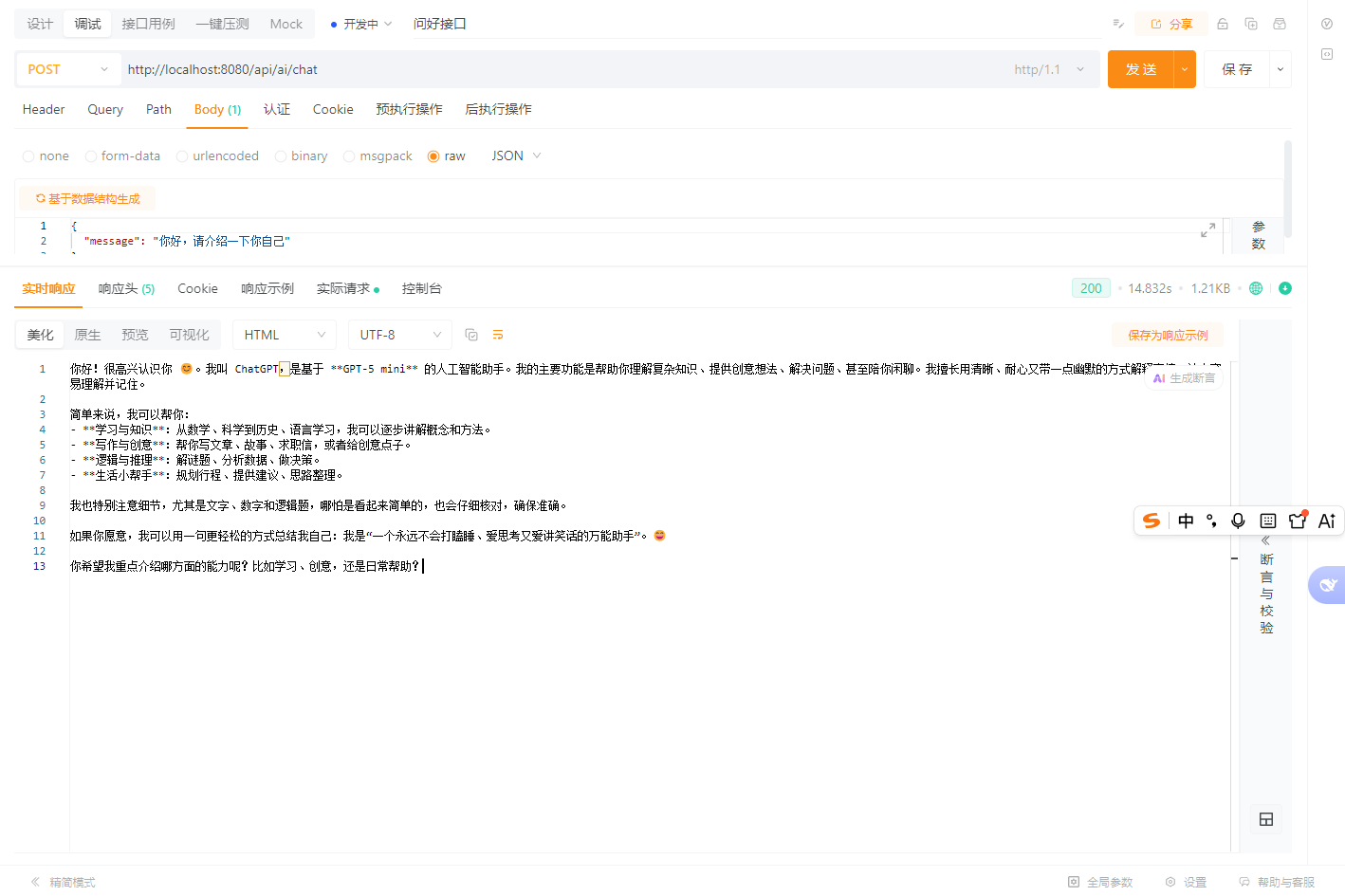
同时在后台也能接收到正确的信息:
3、模型类型问题
问题现象
接口连通但无返回、报错模型不存在、参数不匹配、流式调用失效。有的时候我们会指定大模型类型来请求,比如可以在程序中指定:
@PostMapping("/chat/advanced")
public String chatAdvanced(@RequestBody ChatRequest request) {
return openAiService.chat(
request.getMessage(),
request.getModel(),
request.getTemperature()
);
}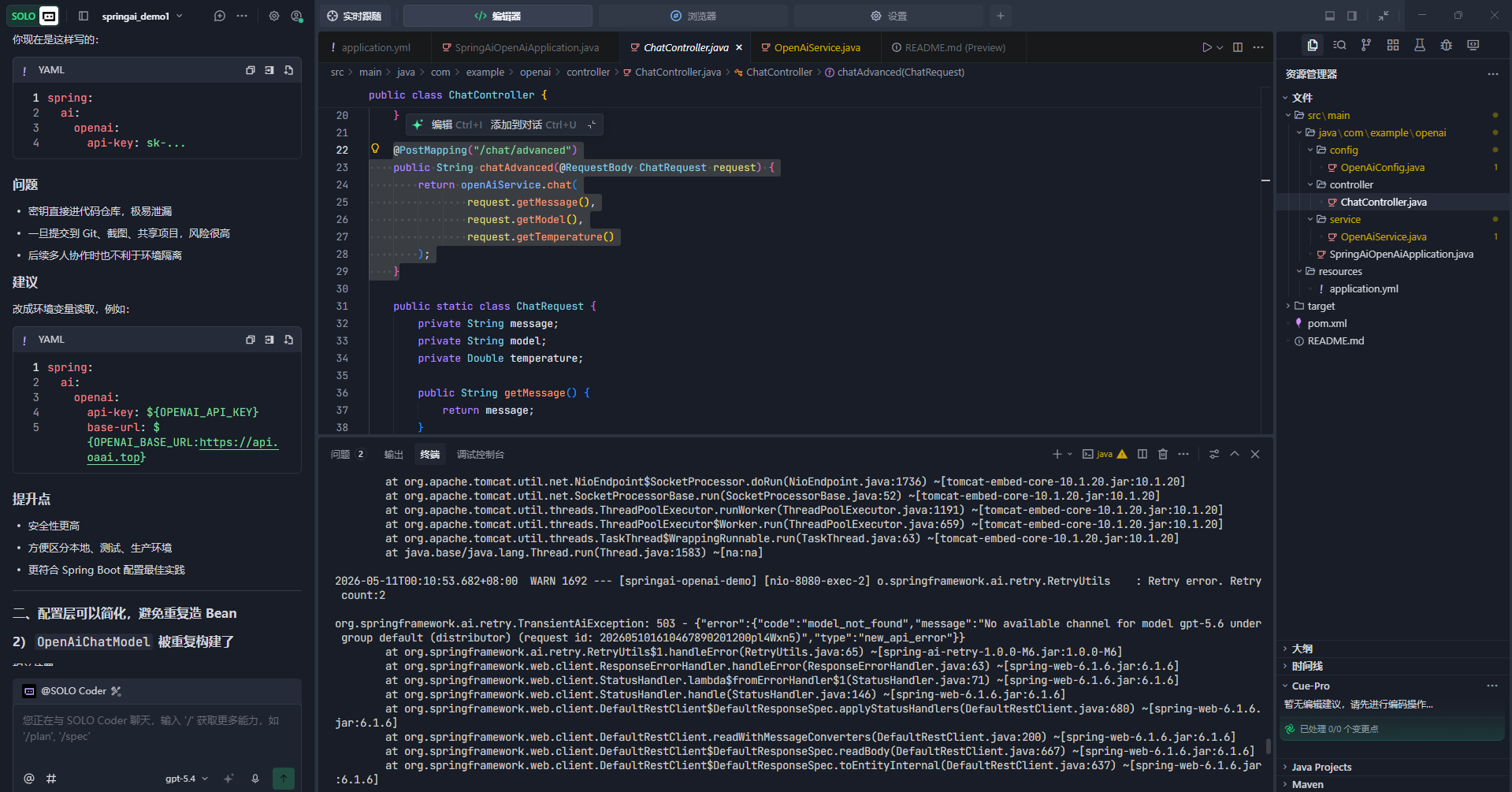
org.springframework.ai.retry.TransientAiException: 503 - {"error":{"code":"model_not_found","message":"No available channel for model gpt-5.6 under group default (distributor) (request id: 202605101610467890201200pl4Wxn5)","type":"new_api_error"}}常见原因
- 未指定模型名称,使用框架默认模型,与厂商实际模型名不匹配;
- 混淆对话模型、嵌入模型类型,用 Chat 接口调用 Embedding 模型;
- 自定义模型名拼写错误,大小写、字符不一致;
- 多模型混用,未隔离不同模型的默认配置参数。
实战解决办法
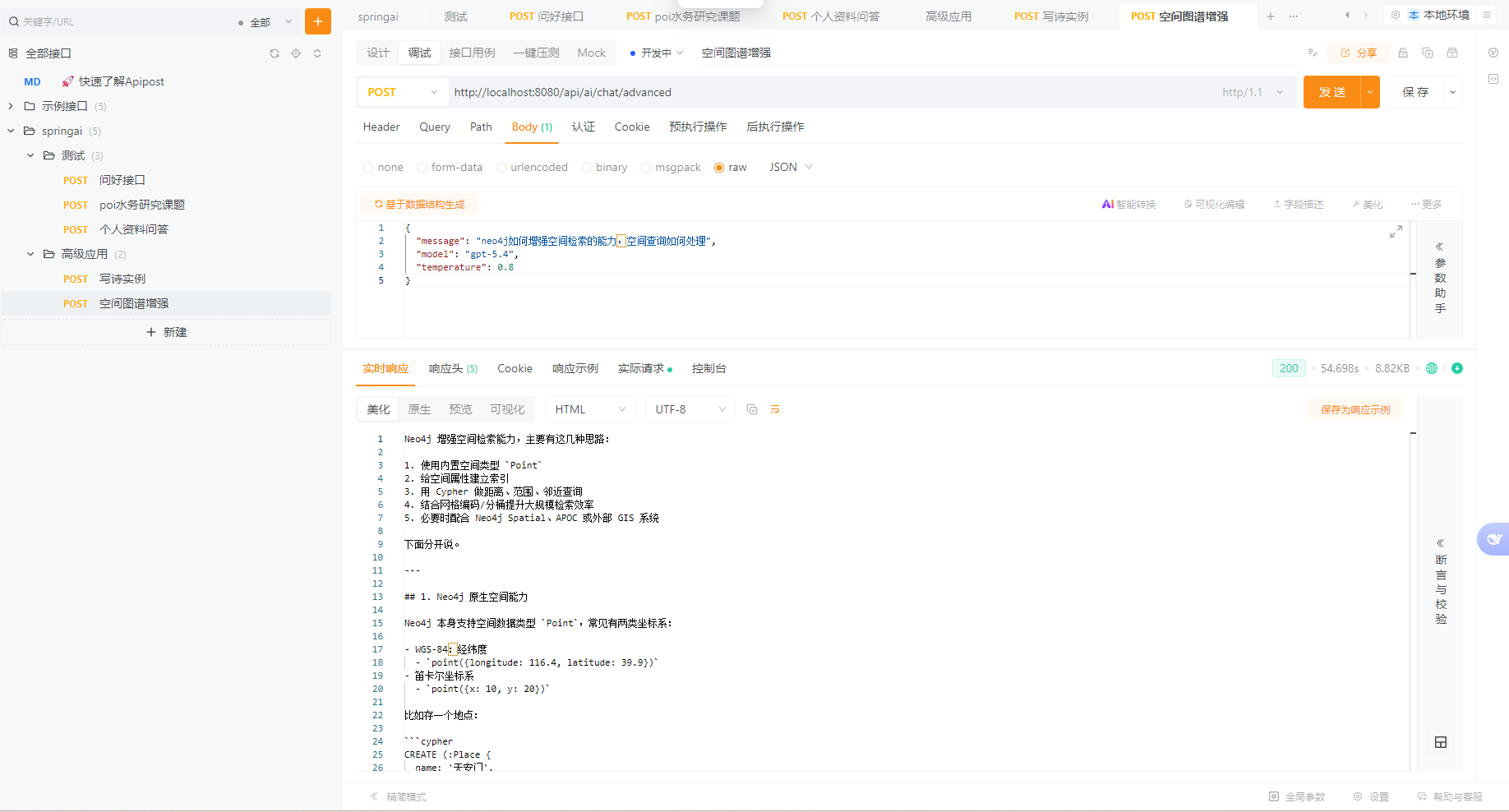
- 显式指定模型名称,配置中固定 model 参数:
{
"message": "neo4j如何增强空间检索的能力,空间查询如何处理",
"model": "gpt-5.4",
"temperature": 0.8
}完善后的展示信息如下:
4、其它常见问题
问题一:依赖版本不兼容
现象:项目启动报错类找不到、方法不存在、依赖冲突。
原因:Spring Boot 版本与 Spring AI 版本不匹配,引入零散依赖缺少核心 starter。
解决方案:统一版本谱系,使用 Spring AI 官方适配的 Boot 版本,只引入官方 starter 依赖,不零散导入单体包。
问题二:超时与上下文长度超限
现象:大文本请求接口超时、直接中断响应。
原因:默认超时时间过短,未配置超时参数;输入 Token 超出模型上下文限制。
解决方案:配置自定义超时时间,拆分长文本分块请求;调整 temperature、max_tokens 参数适配模型限制。
更多常见问题,这里不全部赘述,关于入门初学者的问题简单讲解这几个,供大家参考。
三、总结
以上就是本文的主要内容,本文对Spring AI 对接大模型的绝大多数故障进行了阐述,关于对接的故障,基本上都集中在地址配置、密钥鉴权、模型匹配、版本依赖四大维度,并非复杂代码逻辑问题。只要遵循三个原则即可大幅避坑:一是先 使用接口调试同居 调通接口再写代码,排除网络和地址问题;二是配置标准化,规范 BaseURL、API Key、模型名称的写法与层级;三是版本统一、按需配置,不随意混搭依赖、不混用多模型参数。
掌握本文梳理的易错点和解决方案,开发者可以快速排查对接过程中的各类异常,专注业务功能开发,无需在环境配置和接口联调上浪费大量时间。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)